实验 改进的KMeans算法实现车牌字符的分割
k-means算法

k-means算法k-means算法是无监督学习领域最为经典的算法之一。
接触聚类算法,首先需要了解k-means算法的实现原理和步骤。
本文将对k-means算法的基本原理和实现实例进行分析。
希望对喜欢机器学习的童鞋们,有一定的帮助和启发。
首先看看wiki上对k-means算法的基本阐述。
k-means clustering is a method of vectorquantization, originally from signalprocessing, that is popular for clusteranalysis in data mining. k-means clusteringaims to partition n observations into kclusters in which each observation belongs tothe cluster with the nearest mean, serving asa prototype of the cluster.可以看出,k-means算法就是将 n 个数据点进行聚类分析,得到 k 个聚类,使得每个数据点到聚类中心的距离最小。
而实际上,这个问题往往是NP-hard的,以此有许多启发式的方法求解,从而避开局部最小值。
值得注意的是,k-means算法往往容易和k-nearest neighbor classifier(k-NN)算法混淆。
后者是有监督学习的分类(回归)算法,主要是用来判定数据点属于哪个类别中心的。
A simple example for k-means clusteringk-means算法有很多应用:•图像分割(Image Segmentation)•基因分割数据聚类分析(Clustering GeneSegementation Data)•新闻聚类分析(News Article Clustering)•语言聚类分析(Clustering Languages)•物种分析(Species Clustering)•异常检测(Anomaly Detection)•\cdots数学描述给定数据集 X=\{x^{(1)},x^{(2)},\cdots,x^{(n)}\} ,其中每个数据样本 x^{(i)}\in \mathbb{R}^d . k-mean算法旨在将 n 个数据点划分为 k(k\leq n) 个聚类集合\bm{S}=\{S_1,S_2,\cdots,S_k\} ,使得每个聚类集合中的样本点与聚类中心的距离平方和最小(WCSS, within-cluster sum of squares),i.e. 方差最小。
K-MEANS算法(K均值算法)

k-means 算法一.算法简介k -means 算法,也被称为k -平均或k -均值,是一种得到最广泛使用的聚类算法。
它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,类间独立。
这一算法不适合处理离散型属性,但是对于连续型具有较好的聚类效果。
二.划分聚类方法对数据集进行聚类时包括如下三个要点:(1)选定某种距离作为数据样本间的相似性度量k-means 聚类算法不适合处理离散型属性,对连续型属性比较适合。
因此在计算数据样本之间的距离时,可以根据实际需要选择欧式距离、曼哈顿距离或者明考斯距离中的一种来作为算法的相似性度量,其中最常用的是欧式距离。
下面我给大家具体介绍一下欧式距离。
假设给定的数据集 ,X 中的样本用d 个描述属性A 1,A 2…A d 来表示,并且d 个描述属性都是连续型属性。
数据样本x i =(x i1,x i2,…x id ), x j =(x j1,x j2,…x jd )其中,x i1,x i2,…x id 和x j1,x j2,…x jd 分别是样本x i 和x j 对应d 个描述属性A 1,A 2,…A d 的具体取值。
样本xi 和xj 之间的相似度通常用它们之间的距离d(x i ,x j )来表示,距离越小,样本x i 和x j 越相似,差异度越小;距离越大,样本x i 和x j 越不相似,差异度越大。
欧式距离公式如下:(2)选择评价聚类性能的准则函数k-means 聚类算法使用误差平方和准则函数来评价聚类性能。
给定数据集X ,其中只包含描述属性,不包含类别属性。
假设X 包含k 个聚类子集X 1,X 2,…X K ;{}|1,2,...,m X x m total ==(),i j d x x =各个聚类子集中的样本数量分别为n 1,n 2,…,n k ;各个聚类子集的均值代表点(也称聚类中心)分别为m 1,m 2,…,m k 。
加权k-means算法

加权k-means算法
加权K-means算法是一种改进的K-means算法,它在计算簇心点时考虑了每个样本点的重要性。
加权K-means算法根据每个样本点的重要程度为其分配不同的权重,使得权重较大的样本点在计算簇心点时具有更大的影响力。
通过为样本点分配不同的权重,加权K-means 算法能够更好地处理具有不同重要性的数据,从而得到更加准确和可靠的聚类结果。
加权K-means算法的实现步骤如下:
1.初始化:选择K个样本点作为初始簇心点,并为每个样本点分配一个权重值。
2.分配样本点到簇:根据每个样本点到各个簇心点的距离,将样本点分配到最近的簇中。
3.计算新的簇心点:根据每个簇中样本点的权重和坐标,计算新的簇心点。
权重较大的样本点对计算簇心点时的贡献更大。
4.更新权重:根据每个样本点到新计算的簇心点的距离,更新样本点的权重。
5.重复步骤2-4直到满足停止条件(例如,达到预设的最大迭代次数或簇心点收敛)。
6.输出结果:最终得到的K个簇心点和每个样本点的簇标签即为加权K-means算法的输出结果。
需要注意的是,加权K-means算法的权重值可以是人为设定的,也可以通过其他算法或启发式方法计算得到。
另外,由于加权K-mea
ns算法需要为每个样本点分配权重,因此对于大规模数据集,加权K -means算法可能需要更多的计算资源和时间。
【方法】车牌自动识别系统中字符分割方法研究

【关键字】方法1 绪论1.1问题的提出和研究背景车辆牌自动识别(Automated License Plate Recognition,ALPR)技术作为交通管理自动化的重要手段,其任务是分析、处理汽车监控图像,自动识别汽牌照号,并进行相关智能化数据库管理。
ALPR 系统可以广泛应用于高速公路电子收费站、出入控制、公路流量监控、失窃车辆查询、停车场车辆管理、公路稽查入监测黑牌机动车、监控违章车辆的电子警察等需要牌照认证的重要场合。
尤其在高速公路收费系统中,实现不停车收费技术可提高公路系统的运行效率。
人们一般将车牌识别系统划分为三大部分[1],首先将车牌从经过预处理的图像中定位出来,然后对车牌中的字符进行准确的切分,最后对分割好的字符进行识别"如何从复杂图像中将待识别的信息进行准确有效的定位与分割就是自动识别的关键1.2 ALPR系统简介车辆牌自动识别系统,总体来说是图像处理技术与牌照本身特点的有机结合,也包括小波分析、神经网络、数学形态学、模糊理论等数学知识的有效运用。
一个车牌自动识别系统基本包括:图像预处理、牌照定位、牌照校正、牌照字符分割、字符识别及结果输出等。
图1-1为系统的流程框图:图1-1 车辆牌照自动识别流程1.3 ALPR关键技术:1.图像采集:用一个摄像机摄取车辆前视图或后视图。
2.图像处理:对采集到的图像进行增强,恢复,变换。
目的是突出车牌的特征,以便更好的提取车牌。
3.车牌定位:在采样的图像中找到车牌的位置。
4.车牌字符分割:对获得的车牌分离出单个字符(包括汉字、字母和数字等)5.字符识别:对分割得到的字符进行归一化处理,转化为文本存入到数据库或直接显示出来。
由此可见,车牌识别系统在硬件上一般包含一台PC机,摄像头,图像采集设备,相应的图像处理软件,以及汽车到来的检测装置。
1.4国内外研究现状和发展趋势牌照识别技术自1988年以来,人们就对它进行了广泛的研究,目前国内外己经有众多的算法,一些实用的ALPR技术也开始用于车流监控、出入控制、电子收费、移动稽查等场合。
基于改进K均值的图像分割算法

基于改进K均值的图像分割算法蒋大宇【摘要】图像分割在模式识别过程中占有重要地位,如何对图像中感兴趣的目标进行有效的分割是计算机视觉和图像分析的重点和难点.K均值算法在图像分割中具有快速、分割效果好等特点,但其聚类结果易受到初值的影响并且K值的选取也限制了该方法的应用.在基于K均值聚类的基础上,将并行二分的思想引入算法中,并在图像分割中得以应用.通过实验证实,提出的方法在保证图像分割效果的基础上,耗时大大减小.【期刊名称】《哈尔滨商业大学学报(自然科学版)》【年(卷),期】2013(029)005【总页数】4页(P575-578)【关键词】图像分割;模式识别;图像分析;K均值;并行二分【作者】蒋大宇【作者单位】哈尔滨工程大学信息与通信工程学院,哈尔滨150001【正文语种】中文【中图分类】TP391图像分割技术在图像工程中占有重要的地位,是处于图像分析和图像处理之间的重要步骤,也为后续的处理奠定基础.图像分割是指依据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一个区域内,表现出一致性或相似性,而在不同的区域间表现出明显的不同[1].多年来经过诸多学者的不懈努力,已经提出上千种的图像分割算法,并且每年还不断有新的算法产生,尽管已经提出了很多用于图像分割和特征提取的方法,但由于图像的种类繁多和复杂多样性,设计一种通用和有效的分割算法仍然具有重要的意义.目前图像分割方法主要有:阈值法、区域提取法、聚类法和边缘检测法四类[2].在聚类法的图像分割中,K均值算法的应用的最为广泛,因其算法具有很好的伸缩性,可以处理大像素的图像,然而缺点也十分突出,聚类结果受初值的影响而变得不稳定[3].为了让KM获得稳定的聚类,学者们提出了许多改进方案,其中以高质量的层次聚类算法为K均值提供初值是最受认可的策略,可是高质量的层次聚类往往是因为较高的计算复杂度而使得改进的K均值失去了伸缩性,不再适合处理规模稍大的数据[4].本文设计了一个新的KM改进方案——并行二分K-Means(Parallel Bisecting K-Means,PBKM),该方法既可以保留K均值的伸缩性,又能大幅提高KM的算法效率.1 并行二分K均值1.1 并行二分思想首先将数据集一分为二得到两个簇,然后以每个簇为起点再一分为二,如此重复,第r次获得2r个簇.这个切分过程与细胞在分裂过程中的增长速度一样,最底层的数据称之为叶子节点.细胞分裂式的二分给予每个簇均等的切分机会,在每次迭代过程都要对所有的簇进行切分,这个过程具有并行的特点.PBKM采用二分思想对数据对象进行聚类,其过程在于每次迭代需要更新待切分簇的数量和大小,算法描述如下:1)输入待聚类数据集,并初始化n、k;2)计算迭代的次数R=[lg k/lg2]+1;3)for r=1 to R计算并更新待切分簇的数量M=2r-1;计算并更新待切分簇的大小nd=n/2r-1;form=1toM调用K-means(nd,2)对簇进行二分;4)计算叶子结点数量M=2R;5)把M个叶子结点合并到k个;6)输出数据对象的类别标签.虽然PBKM算法在聚类过程中调用了KM算法,但整个过程仍然简洁明了,容易程序实现.1.2 PBKM的时间复杂度分析PBKM第r次切分给出 m个簇,m=2r,令2R-1≤ k≤2R,R为迭代的次数.通常完全二叉树的叶子结点数m >k,此时需要将叶子结点进行部分合并,是叶子节点数降到k即可完成聚类.对于PBKM的时间复杂度分析需要考虑二分的迭代计算和叶子结点合并等两个过程的时间开销.第r次的并行切分,需要切分m个簇,此时待切分簇的大小为nd,时间开销为:因为二分时m=2r-1,nd= n/2r-1,k'=2,有:执行R次迭代的时间为:当k<nd时,需要将叶子结点部分合并,所以PBKM算法的总体时间开销为:nd=2R,nd比k略大,需要合并的叶子结点并不多,因此合并的时间开销T(nd)也不大.当n很大时,例如对大规模数据进行聚类,T(nd)可以忽略不计.因为需要合并的叶子结点不多,也就是nd和k差别不大,此时合并的时间复杂度接近于 O(nd2).当2×R×n≫nd2,有:也就是说,n≫2R/(2×R)时,叶子结点合并的时间相对很少,可以忽略T(nd).式(6)给出的条件是十分宽松的,通常规模的数据集都可以满足因此可以说PBKM算法中的叶子结点合并不会显著增加整个聚类过程的时间开销.R的计算如下:2 基于PBKM的图像分割算法在描述像素点的时候我们希望尽可能的不丢失像素信息,这里把每一个像素点分别用其在RGB和HIS颜色空间上进行描述,为了更全面的描述像素的特征,在对像素特性进行描述时还加入了灰度值.这样每一个像素点就拥有了7个属性,我们就用这7维的行向量来代表该像素点.对于一个像素为256×256的小图片,其像素点已达到216,按照提出的预处理方法,实际聚类的数据规模达到了216×7.这样看来图像的像素数据对于聚类问题来说属于大规模的数据集.用聚类的法进行图像分割,首先将图像中的像素点用一个多维的向量表示,也就是将每个像素点映射到多维的特征空间中,然后根据这些像素点在特征空间的聚集情况对特征空间进行聚类,达到分割的目的,再把多维特征空间中的分割结果映射回原图像空间,进而得到原图像的分割结果.基于PBKM的图像分割的过程如下:1)对于原始的图像I0进行预处理,I0含有m×n个像素点,经预处理后变成了待聚类的数据I1,I1的数据规模达到了m×n×7;2)对待聚类数据I1进行PBKM聚类,得到一组聚类标签 Idex[m×n,1]3)将得到的聚类标签Idex,还原回原图像大小m×n;4)对还原的图像进行边缘检测得到图像分割的轮廓,从而实现图像分割.需要指出的是在第3步结束后,根据实际问题的需要可以添加一些后续的优化处理,例如开、闭运算、膨胀、腐蚀等,然后在进行边缘检测,可以得到更好的分割结果.3 对比试验与结果分析3.1 试验设计与数据源本文以自然彩色图像作为试验的对象来研究图像分割.试验的硬件环境为:CPU Core 2 Quad Q6600 2.4G,Internal memory 4G,Hard disk Hitachi HDP 725050GLA360 500G.软件环境为:Windows 2003+Matlab2007b.本文在上述环境中实现了实验算法和实验验证工作.测试图全部取自Berkeley图像分割库[5-6].为了对本文图像分割算法的性能进行评测,本文进行了两组实验,对PBKM算法的有效性和高效性进行了验证.3.2 算法的有效性验证为了验证PBKM算法在图像分割领域的有效性,本文将基于PBKM图像分割算法的分割结果和人工分割结果进行了比对,为了更直观的看到分割过程及效果,在图1中列出了原始图像、基于PBKM方法的聚类结果、边缘检测得到的轮廓还有人工分割的结果.其中第一行的三幅图像是在Berkeley分割库中随机抽取的大小为481×321的原始图像;第二行为原始图像经过PBKM聚类算法得到的聚类标签,通过灰度的方式显示的分割结果;第三行是图像聚类结果经边缘检测得到的分割轮廓;第四行是人工分割得到的轮廓,是检验分割算法好坏的一个重要参考指标.从图1中三幅图像的分割情况对比可以看出:1)PBKM算法的分割结果和人工分割的结果具有较强的相似性,说明了PBKM算法对于图像的分割结果和人的主观视觉感知具有较强的一致性;2)三幅图在图像主体的分割上与人工分割几乎完全吻合,第1幅图中房子的轮廓、棱角、门窗、屋顶的十字架,第二幅图中鸟的轮廓、树枝的形状,第三幅图中两只鸟的轮廓等都得到了较好的分割,这说明PBKM方法用于图像分割能较好的识别图像中的主体,能满足图像后续处理的要求(图像理解、图像识别等).3)在图像的细节部分的分割中,该算法得到的轮廓和人工分割得到的轮廓有一定的出入.例如在第一幅图圆顶屋旁边的电线,在人工分割中体现出来了,但本文方法没有进行分割;第2幅图,在分割时对鸟的胸部和脚进行了分割,而人工分割只分割鸟的轮廓,不对细节进行分割;在第3幅图中,本文算法在大鸟的尾部进行的分割和人工分割有出入.这些差异的存在恰好体现了图像分割的难度所在.人工分割只是作为检验图像分割算法的一个参考并不是标准答案,其中人的主观因素占很大部分.总体上来讲PBKM算法的分割结果和多数人的视觉感知想吻合,证明了PBKM的有效性.图1 三幅真实图像的分割结果人工分割的对比3.3 对比试验为了对PBKM算法用于图像分割的性能、分割效率给出评价,将PBKM算法和K -均值算法进行了对比,PBKM算法和K-均值都能处理大规模的数据,我们在图像库中找到了一个1 024×768像素的图像,对图像进行对比试验得到的分割结果如图2所示,两种方法的运行时间由表1给出.图2 两种算法分割的轮廓对比图表1 两种分割算法的运行时间对比PBKM分割4.625 ~4.925从图2中可以看出两种方法在大像素的图像上都可以应用,充分说明了两种方法都适合处理大规模的数据集,从图2中可以看出两种方法对于原图的分割几乎一样,无论是云的形状、雨伞、照相的人还是山的形状.并且两种方法对于图像细节处的分割进行的很好,从(B)、(C)中可以看出雨伞的形状、照相人的轮廓、几乎连山的大概形状都分割出来了,最难能可贵的是就连雨伞上面的小头都能分割出来,说明了两种方法都可以应用在大像素的图像分割上.从表1中能直观的发现,我们的方法PBKM在分割质量上和K均值几乎一样,但是所消耗的时间只占K均值方法的64%左右,这样的结果充分的体现出了PBKM 算法在处理大规模像素图像分割时的优势.4 结语本文针对K均值方法在图像分割中的不足,提出了一种基于改进K均值算法的PBKM算法,通过实验证实PBKM算法在图像分割领域具有很强的应用性,特别是对大规模像素图像的分割,能得到很好的结果,并且耗时较少.参考文献:[1]CHENG H D,JIANGX H,SUNH,etal.Color image segmentation;advances and prospects[J].Pattern Recognition,2001,34(12):2259-2281.[2]何俊,葛红,王玉峰.图像分割算法研究综述[J].计算机工程与科学,2009,31(12):58-61.[3]TAN P N,STEINBACH M,KUMAR V.Introduction to Data Mining [M].北京:机械工业出版社,2010:492-495.[4]CUTTING D R,PEDERSEN JO,KARGER D,etal.Scatter/Gather:A Cluster-based Approach to Browsing Large Document Collections[C]//Proceedings of the Fifteenth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,[S.l.]:[s.n.],1992:318 -329.[5]MARTIN D,FOWLKESC,TAL D,etal.A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proceeding of theInternational Conference on Computer Vision,Los Alamitos,California:IEEE Society Press,2001,416 -423.[6]肖刚.基于小波域软阈值的指纹分割方法研究[J].哈尔滨商业大学学报:自然科学版,2012,28(2):231-234.。
车牌图像的字符分割
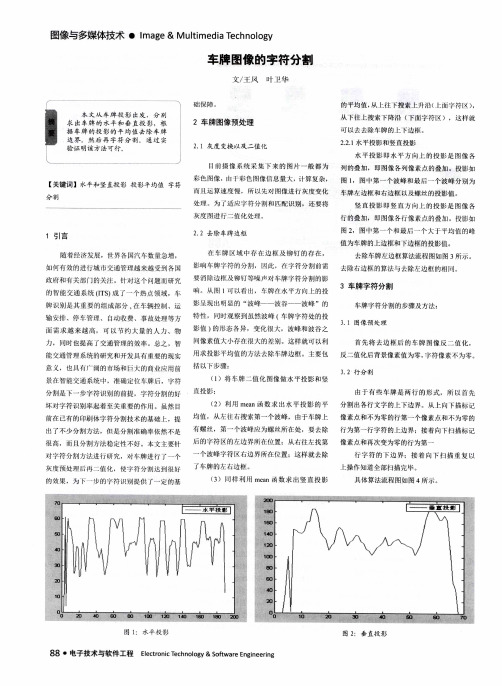
由于有些 车牌 是两 行的形 式,所 以首 先 分割出各行文字的上下边界。从 上向下描标 记 像素点和不为零的行第一个像 素点和不为零的 行为第一行字符的上边界;接着向下扫描标记 像素点和再次变为零的行为第 一
行 字 符 的 下 边 界 ; 接 着 向 下 扫 捕 重 复 以 上操作知道全部扫描完毕。
( 3 ) 同样 利 用 me a n函 数 求 出 竖 直 投 影
具体算法流程图如图 4所示。
图 1 : 水 平 投 影
图2 :垂 直投 影
8 8 ・电子技 术与软 件工 程
E l e c t r o n i c T e c h n o l o g y &S o f t w a r e E n g i n e e r i n g
处 理 。 为 了 适 应 字 符 分 割 和 匹 配 识 别 , 还 要将 竖 直 投 影 即 竖 直 方 向 上 的 投 影 是 图 像 各
灰度图进 行二值 化处理 。
行的叠加 ,即图像 行像 素点 的叠加 。投影如 图2 ,图中第一个和最后一个 大 于平均值的峰 值 为车牌 的上边框和下边框的投影值 。
影值 ) 的形态各异 ,变化 很大,波峰和波谷之 间像素值大小存在很大 的差别 这样就可 以利 用求投影平均值 的方法 去除车牌边框 。主要包
括 以下 步 骤 :
首先 将去边 框后 的车 牌 图像反 二值化 , 反二值化后背景像 素值 为零 , 字符像素不为零。
3 . 2 行 分 割
景在智能交通 系统 中,准确 定位车牌 后,字符 分割是下一步字符识别 的前提 ,字符分割的好 坏对字符识别率起着至关重要的作用 。虽然 目 前在 已有的印刷体字符分割技术的基础上 .提
使用kmeans算法
使用kmeans算法进行图像分割一、引言图像分割是计算机视觉领域中的一个重要问题,它旨在将一幅图像划分成多个子区域,每个子区域具有相似的特征。
其中,kmeans算法是一种常用的聚类算法,可以用于图像分割。
本文将介绍如何使用kmeans算法进行图像分割。
二、kmeans算法简介1. 原理kmeans算法是一种基于距离度量的聚类算法。
其基本思想是将n个样本划分为k个簇,使得每个样本都属于距离最近的簇,并且每个簇的中心点(质心)尽可能接近。
具体实现过程如下:(1)随机选择k个中心点;(2)将每个样本归属到距离最近的中心点所在的簇;(3)重新计算每个簇的中心点;(4)重复步骤2和3直到收敛。
2. 优缺点优点:(1)简单易实现;(2)对大数据集有较好的可扩展性;(3)能够处理高维数据。
缺点:(1)需要预先设定簇数k;(2)对初始值敏感,容易陷入局部最优解;(3)不适用于非凸形状的簇。
三、使用kmeans算法进行图像分割1. 数据准备首先,需要将待分割的图像转换为n行3列的矩阵,其中n为像素点数。
每一行代表一个像素点的RGB值。
可以使用Python中的PIL库或OpenCV库读取和处理图像。
2. 算法实现使用Python中的sklearn库中的KMeans类实现kmeans算法。
具体实现过程如下:(1)导入KMeans类:from sklearn.cluster import KMeans;(2)初始化KMeans类:kmeans = KMeans(n_clusters=k);(3)训练模型:kmeans.fit(data);(4)获取聚类结果:labels = bels_。
其中,参数n_clusters表示簇数k,data为待分割图像转换后得到的数据矩阵。
3. 结果可视化将聚类结果转换为图像格式,并可视化展示。
可以使用Python中的matplotlib库或OpenCV库实现。
四、总结本文介绍了kmeans算法及其在图像分割中的应用。
车牌字符分割及识别算法研究的开题报告
车牌字符分割及识别算法研究的开题报告一、选题背景与意义随着车辆数量的增多,交通管理越来越复杂,车牌识别技术已成为现代交通管理中不可或缺的手段。
目前,车牌识别技术已广泛应用于智能交通系统、停车场管理等领域,尤其在车辆安全检测和追踪、交通违法行为的识别等方面具有非常重要的应用价值。
车牌识别技术的关键就是字符分割和识别,因此本课题将重点研究车牌字符分割及识别算法。
通过对车牌进行有效的字符分割,能够准确快速地识别车辆信息,提高交通管理效率,确保道路畅通,维护公共安全。
二、研究内容及思路1. 车牌字符分割算法研究车牌字符分割是车牌识别的重要步骤,其目的是将车牌图像中的字符区域分割出来。
车牌字符分割算法的研究是本课题的重点之一。
在此基础上,我们将探讨如何对分割出的字符进行有效的识别和匹配,以保证车牌信息的准确性和可靠性。
2. 车牌字符识别算法研究车牌字符识别技术是车牌图像处理的核心问题之一,其目的是将车牌图像中的字符信息自动识别出来。
本课题将通过深入研究神经网络算法、模式识别算法等相关技术,构建有效的字符识别模型。
通过训练这个模型,能够快速而准确地识别出车牌中的字符信息。
三、研究方法1. 数据采集本课题将采用公开数据集进行研究,如CCPD、车牌字符数据集等。
同时,还将根据实际情况采集一些本地车牌图像进行测试和验证。
2. 图像处理技术本课题将应用多种图像处理技术,包括图像增强、二值化、边缘检测、形态学处理等,以有效处理车牌图像。
3. 算法开发本课题将基于Python平台,运用相关算法对车牌图像进行处理、字符分割和字符识别,在此基础上通过对实验结果进行分析,优化算法传统算法的表现,提高算法的准确率和稳定性。
四、预期研究成果1. 建立车牌字符分割及识别算法本课题将建立车牌字符分割算法和字符识别算法。
通过完整的实验流程,优化相关算法,建立出相应的模型以及算法,实现车牌字符的准确分割和识别,并进行实验验证。
2. 测试和结果分析本课题将基于实际数据和公开数据集进行测试,在此基础上对模型进行优化,并对结果进行分析和总结,得出相关结论,为实际应用提供参考。
kmeans聚类算法实验心得
kmeans聚类算法实验心得
kmeans聚类算法是一种常用的无监督学习算法,可以将数据集分成多个类别。
在实验中,我使用Python语言实现了kmeans聚类算法,并对其进行了测试和分析。
我使用Python中的sklearn库中的make_blobs函数生成了一个随机数据集,该数据集包含了1000个样本和4个特征。
然后,我使用kmeans算法对该数据集进行了聚类,将其分成了4个类别。
通过可视化的方式,我发现kmeans算法能够很好地将数据集分成4个类别,并且每个类别的中心点都能够很好地代表该类别。
接着,我对kmeans算法进行了参数调优。
我发现,kmeans算法的聚类效果很大程度上取决于初始中心点的选择。
因此,我尝试了多种不同的初始中心点选择方法,包括随机选择、均匀分布选择和kmeans++选择。
通过实验,我发现kmeans++选择方法能够获得最好的聚类效果。
我对kmeans算法进行了性能测试。
我使用Python中的time库对kmeans算法的运行时间进行了统计,并且将其与sklearn库中的kmeans算法进行了比较。
结果显示,我实现的kmeans算法的运行时间比sklearn库中的kmeans算法要长,但是两者的聚类效果相当。
总的来说,kmeans聚类算法是一种非常实用的无监督学习算法,可以用于数据集的聚类和分类。
在实验中,我通过对kmeans算法的实现、参数调优和性能测试,深入了解了该算法的原理和应用,对于以后的数据分析工作有很大的帮助。
最大类间方差车牌字符分割的模板匹配算法
来判断车牌是否水平。方法如下:
首先对二值化的车牌从下向上作行扫描并记录每行的
0、1 跳跃次数,当某一行的 0、1 跳跃次数大于 9(7 个字符
和两条垂直边框)时,认为找到字符串的下边界(假设车牌
水平)。将该行的 0、1 跳跃次数与其前 3 行的平均 0、1 跳跃
次数按照下面的公式计算并作出判别。
∑n i
思想,将车牌字符串看作一个模板,而这个模板的特征有 2 个:(1)模板大小是一个特征量:因为已经得到了字符串的高
度数据,由上面的字符串结构特征可知根据字符串的高度可 以确定其它部分的尺寸;(2)模板内字符区域边缘最丰富,而
字符间隔区域理论上没有边缘(圆点除外)。 这 2 个特征就是定位的依据。具体定位方法如下:
1 字符分割预处理
1.1 牌照图像二值化 在对车牌进行分割之前首先应该对车牌进行二值化。在
此采用基于空间分布的最大类间方差二值化算法[3],二值化 效果见图 1。
(a)车牌原图像
(b)二值化结果 图 1 二值化算法效果
1.2 车牌倾斜度检测 在后面的字符分割算法中要求字符串水平,所以要先检
测车牌是否水平。本文采用基于行扫描的跳跃点数目变化率
(2)将字符串模板在字符串上从左向右滑动,同时分别统
计各个位置处所有字符区域内“1”点的数量 nchar 和和所有
字 符 间 隔 区 域 内 “1” 点 的 数 量 nspace , 并 计 算 其 差 值
( nchar - nspace )。
—194—
(3)比较各个位置处( nchar - nspace )值的大小,设字符串
前一行的纵坐标Y2。坐标区间[Y2, Y1]内的行即是车牌的字符 串位置。至此可以将字符串分割出来,同时获得字符的精确
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验 改进的K-Means算法实现车牌字符的分割 车牌识别的一般过程:车牌定位--- >字符分割--- > 字符识别。本实验实现了前两步。 车牌定位从大体上分为两种,基于灰度和基于底纹,本程序结合了以上两种方法实现了车牌精确定位,即先基于灰度图像得到一个大概的位置,然后再根据底纹实现精确定位。不失一般性,本人设计了只针对蓝底白字(车牌有四种:蓝底白字、黑底白字、白底黑字、黄底黑字)的车牌设计了算法,现实中,蓝底白字占了车牌的绝大多数。 字符分割是本实验的重点。车牌分割有很多方法, 如神经网络算法、水平投影、点阵结构等。因为车牌识别要求是实时,要求具有很快的响应速度。所以字符分割这一步对车牌字符的最终识别和整个程序运行效率有很重要的影响,本实验基于K-Means聚类算法思想实现了字符分割,因为车牌规定是7位的,所以K取7。另外本实验对K-Means算法进行了改进,充分考虑了初始点的设置及迭代结束条件。实验结果证明这种改进的K-Means算法实现车牌字符分割是快速、有效的。 整个算法用VC++6.0实现。
一、实验目的 (1)掌握图像数据挖掘的基本方法 (2)K-Means聚类算法完成车牌字符分割(重点)
二、实验内容 基本功能要求: (1)实现车牌的精确定位 (2)对K-Means聚类算法进行改进,即如何进行初始点和迭代条件的确定,快速完成车牌字符分割。
三、算法设计 本算法分为二部分,车牌定位和字符分割。车牌定位的各个函数、算法思想是图像处理和模式识别课程中重要讨论的内容,这里只作了简单介绍。本实验着重讨论如何基于K-MEANS算法思想实现车牌字符分割。
程序执行流程如下:
1、车牌定位 读取车牌图片 定位车牌位置 K-Means分割字符(1)读取车牌图片 用OnBmpopen()函数实现
(2)车牌定位的各函数说明
车牌的定位由一系列函数完成, 各函数说明如下: OnRgbtogray();//彩色转成灰度 为了降低计算复杂度,一般将彩色转换为灰度,公式:gray = 0.3*red + 0.59*green + 0.11*blue(数字图像处理 岗萨雷斯)
Onjunhenghua();//均衡化 为了增强图像对比,采用了均衡化操作(图像工程(上) 章毓晋)
OnBianYuanJianChe();//边缘检测 此函数利用了Sobel算子检测车牌和字符的边缘(数字图像处理 岗萨雷斯)。因为粗略定位需要是根据这些边缘来定位的。
OnEzbz();//二值化 用数组记录图片的可能区域
OnHxqy();//粗略定位,给出候选区域 根据记录的信息完成车牌的粗略定位,之所以说是“粗略”是因为车牌周围的点是车牌识别的噪音,所以根据车牌的边缘来实现精确定位是很难的。
OnQyqd();//基于纹理定位 根据上一步的结果,得到了车牌的大概位置,再根据车牌的底色为蓝色(对于其它三种情况分类判断即可,本实验只针对蓝色底纹)这一特点,可以实现车牌的精确定位。判别条件如下: hl=2*b-r-g>80 r表示像素的红色分量,g表示绿色分量,b表示蓝色分量 (这里的80是根据不断实验得出的阀值)
2、K-Means 聚类算法实现车牌字符分割 改进的K-Means算法实现步骤: Step1 每个字符代表一个类。因为车牌有7个字符(如图所示)组成,故设置7个聚类中心,
为了能在较少的次数下收敛,对K-Means进行了改进,即类的初始点不是随机选取,而是根据车牌的特点取值,如:
灰度转换 均衡化 边缘检测 二值化 粗略定位 基于纹理定位 对于车牌字符横坐标: oldposition[0][0]=left+width/12;//第一个字符位置离车牌左边约1/12*车牌宽度 oldposition[i][0]=oldposition[i-1][0]+2*width/15;//后一个字符离前一个字符约1/15宽度 对于车牌字符纵坐标 oldposition[i][1]=bottom+height/2;//每一个车牌的纵坐标大约是车牌高度的一半 这样设置的理由:由于车牌的像素坐标都是整数,所以坐标用整型变量,这大大提高了算法执行效率。以上设置保证了初始点在各类内,如图所示:红点代表初始点的大概位置,这样设置初始点后,只要经过几次迭代就会收敛。即中心会移到各字符的中心位置。
Step2 扫描所有字符像素,按照距离最近原则,对车牌像素进行归类:d=(x-oldposition[i][0])2+(y-oldposition[i][1])2 公式中x,y是当前扫描的像素坐标,oldposition[i][0],oldposition[i][1]是聚类中心的x,y坐标,离i类中心坐标最近,就把该像素归到i类,本程序用不同的颜色表示不同的类,如国所示的最后分类结果:
Step3 完成一次归类后,重新计算各类中心坐标: newposition[i][0]=∑xi/n; newposition[i][1]=∑yi/n; 计算: di= |newposition[i][0]- oldposition[i][0]|+ |newposition[i][1]- oldposition[i][1]| D=∑di(i=0,……6) 判断D<= e?若不小于,将新的类中心坐标作为类中心, 返回Step2;否则结束。程序中取e=3,也即它们之间的距离差的平均值小于0.5(3/7取整)时,迭代结束。 ”e”取3的理由:由于每个像素的坐标都是整型的,它们的坐标相差最小值是1个像素点,所以只要保证新类的中心和上次类中心距离差平均小于0.5,就说明找到各类中心,即分割成功。
字符分割算法流程:
四、实验结果分析 车牌字符像素归类 重新计算聚类中心
去掉车牌底色 设置7个类初始点
差值小于给定值 计算新的中心与初 始中心距离的差值
新的中心点作为类中心 结束
开始 1、实验的输入与输出 运行程序(VC++6.0): 双击KmeansDealBmp.exe --- >单击“打开图像”-- >选“测试图片”文件夹中的一幅图片 --- > 单击车牌字符分割处理中的“车牌定位”--- > “K—means”分割字符。
测试1 :(一种颜色代表一种分类)
测试2:
2、实验的结果分析 本人找了20幅有代表性的蓝底白字车牌进行了测试,效果如下: 图片序号 识别效果 K-Means分割效果 迭代次数 1 优 优 2 2 优 优 3 3 差 优 2 4 优 优 2 5 差 差 9 6 优 良 2 7 良 良 3 8 优 优 2 9 优 优 3 10 优 优 2 11 优 优 2 12 差 差 4 13 优 良 2 14 优 优 3 15 优 优 2 16 优 优 3 17 差 差 7 18 优 良 2 19 优 良 2 20 优 优 3
(优:表示完全可以作下一次的字符识别操作 如:
良:表示需要作适当的处理(如残点补缺)才作为下一次的字符识别操作 如:
“粤”字有残缺;
差:表示完全不能识别出来 如: “粤”和“A”是同一种颜色
)
实验结果的几点说明: (1)车牌定位效果差时,分割效果也差,而且迭代次数明显增大,主要是K—Means算法对噪音敏感 如:
只能分割出第5,6,7位字符 (2)平均迭代次数=3 说明算法是快速的。原因:都是基于整型运算,并且初始点的设置离中心点较近。 (3) 分割成功率约90%,只要定位足够好,能去掉车牌周围的噪声,这个比例完全可以提高。 (4) 基于本实验的K—Means聚类分割结果,如再用模板匹配法或其它方法,可识别出字符。即可完成车牌识别的最后一步---字符识别。
五、关键代码说明(全部源码用VC++6.0打开工程文件即可)
一、车牌定位的源代码: void CBmpDisplayView::OnCldw() { OnRgbtogray();//彩色转成灰度 Onjunhenghua();//均衡化 OnBianYuanJianChe();//边缘检测 OnEzbz();//二值化 OnHxqy();//检测候选区域 OnQyqd();//候选区域定位 OnJqdw();//基于纹理定位 }
二、K--Means均值算法的源代码 void CBmpDisplayView::OnJlfg() //K--Means均值分类算法实现,k为7 { int width,height,Dibwidth; BYTE *p_data,b,g,r; CBmpDisplayDoc *pDoc=GetDocument(); ASSERT_VALID(pDoc); p_data=pDoc->ylpBuf ;//图像在内存中的开始位置 height=pDoc->bi.biHeight;//图像高度 width=pDoc->bi.biWidth ;//图像宽度 Dibwidth=pDoc->Dibwidth;//每一行图像像素 LPBYTE temp=new BYTE[height*Dibwidth]; memcpy(temp,p_data,height*Dibwidth); int left=pDoc->newLbpx;//车牌左下角x坐标 int bottom=pDoc->newLbpy ;//车牌左下角y坐标