Python正则表达式实现原理_光环大数据Python培训
python正则表达式匹配结尾

python正则表达式匹配结尾Python作为一种功能强大的编程语言,其正则表达式模块为处理文本提供了便捷的工具。
正则表达式是一种用于描述或匹配字符串模式的字符串处理技术。
在Python中,我们可以使用正则表达式来匹配字符串的起始、结尾或中间部分。
本文将重点介绍如何使用Python正则表达式匹配结尾。
要在Python中匹配字符串的结尾,我们可以使用以下语法:```re.search(pattern, string, flags=0)```其中,`pattern`表示正则表达式的模式,`string`表示要匹配的文本,`flags`为可选参数,表示正则表达式的修饰符。
以下是一个简单的示例:```pythonimport retext = "Hello, I am a professional writer."pattern = r"bwriterb"match = re.search(pattern, text)if match:print("匹配成功:", match.group())else:print("匹配失败")```在这个例子中,我们使用正则表达式`bwriterb`来匹配文本结尾的单词"writer"。
`b`表示单词边界,`writer`是我们要匹配的单词。
如果匹配成功,程序将输出匹配到的文本:"匹配成功:writer"。
正则表达式匹配结尾在许多场景下具有实用价值,例如:1.提取文本中的关键词:可以使用正则表达式匹配文本结尾的关键词,便于后续的文本分析和处理。
2.删除文本末尾的无用内容:有时,文本末尾可能存在无用的标点符号、空格等,可以使用正则表达式匹配并删除它们。
需要注意的是,在使用正则表达式匹配结尾时,要确保匹配的模式与实际需求相符,避免出现误匹配或漏匹配的情况。
python 正则表达式 模糊匹配和精确匹配 -回复

python 正则表达式模糊匹配和精确匹配-回复Python正则表达式是一种强大的工具,用于在字符串中进行模式匹配和替换操作。
它基于一组特定的语法规则,可以实现模糊匹配和精确匹配。
在本文中,我们将深入探讨这两种匹配方法,并通过一些示例来解释它们的使用。
一、模糊匹配在正则表达式中,模糊匹配是指根据特定的模式查找字符串中的一部分内容。
它可以通过以下几种方式实现。
1.点(.)匹配任意字符:点是正则表达式的一个元字符,它可以匹配任意字符,但是不能匹配换行符。
例如,正则表达式"a.b" 可以匹配"acb"、"a5b"、"ab" 等。
2.星号(*)匹配0个或多个字符:星号是正则表达式的一个元字符,它表示前面的字符可以出现0次或多次。
例如,正则表达式"ab*c" 可以匹配"ac"、"abc"、"abbc" 等。
3.问号(?)匹配0个或1个字符:问号是正则表达式的一个元字符,它表示前面的字符可以出现0次或1次。
例如,正则表达式"ab?c" 可以匹配"ac"、"abc" 等。
4.加号(+)匹配1个或多个字符:加号是正则表达式的一个元字符,它表示前面的字符可以出现1次或多次。
例如,正则表达式"ab+c" 可以匹配"abc"、"abbc" 等。
5.花括号({})匹配指定次数的字符:花括号是正则表达式的一个元字符,它表示前面的字符可以出现指定的次数。
例如,正则表达式"a{2}b" 可以匹配"aab",但不匹配"ab"。
以上是模糊匹配的几种常见方式,你可以根据实际需求选择合适的模式。
二、精确匹配精确匹配是指根据特定的模式查找字符串中完全一致的内容。
python正则表达式re.findall 详细解说

Python正则表达式:`re.findall()`函数的使用re.findall()是Python的正则表达式模块re的一个函数。
这个函数用于查找字符串中所有匹配的子串,并返回一个包含所有匹配结果的列表。
如果没有找到任何匹配的子串,它将返回一个空列表。
re.findall()的语法如下:re.findall(pattern, string, flags=0)参数说明:pattern:一个字符串,包含了你想要匹配的正则表达式。
string:你想要在其中查找匹配项的字符串。
flags:一个可选参数,用于指定正则表达式的标志。
例如,你可以使用re.IGNORECASE来使匹配不区分大小写。
让我们通过一个例子来说明re.findall()的使用:import retext = "The quick brown fox jumps over the lazy dog"pattern = "o"matches = re.findall(pattern, text)print(matches) # 输出:['o', 'o', 'o', 'o']在这个例子中,我们在文本字符串"The quick brown fox jumps over the lazy dog" 中查找所有的'o' 字符,并打印出结果。
re.findall()返回一个列表,其中包含所有匹配的字符'o'。
你也可以使用正则表达式来匹配更复杂的模式。
例如,你可以使用\d+来匹配一个或多个数字:import retext = "The quick brown fox jumps over the lazy dog. The dog is 3 years old."pattern = "\d+"matches = re.findall(pattern, text)print(matches) # 输出:['3']在这个例子中,我们查找文本中所有的数字,并打印出结果。
python 正则 多个条件

python 正则 多个条件Python正则表达式可以使用多个条件来匹配字符串。
在正则表达式中,可以使用一些特殊字符来定义条件。
例如, '|' 字符可以用于表示或操作,表示满足其中任意一个条件即可。
另外,可以使用圆括号() 来创建一个捕获组,用于分组条件。
正则表达式中的条件可以包括字母、数字、特殊字符和元字符等。
字母和数字表示常见的字符条件,而特殊字符和元字符则表示更复杂的条件。
例如, '.' 表示匹配任意字符,而 '\d' 则表示匹配数字字符。
当我们需要同时满足多个条件时,可以使用正则表达式的特殊字符来实现。
例如,通过使用 '|' 字符来连接多个条件,我们可以表示满足其中一个条件即可。
另外,使用圆括号创建捕获组,可以将多个条件分为一个整体。
以下是一个示例正则表达式,用于匹配同时满足多个条件的情况:```pythonimport repattern = r'(apple|banana|cherry) [\d]+'text = "I have an apple 123."result = re.findall(pattern, text)print(result)```上述代码中,正则表达式`'(apple|banana|cherry) [\d]+'`表示匹配以`apple`、`banana`或`cherry`开头,后面跟随一个或多个数字的字符串。
在字符串`"I have an apple 123."`中,满足这些条件的部分是`"apple 123"`,所以最终的匹配结果是`['apple 123']`。
通过在正则表达式中使用多个条件,并结合特殊字符和元字符,我们可以灵活地实现对字符串的匹配和提取。
在实际应用中,可以根据具体需求灵活运用这些条件,以达到所需的匹配结果。
python正则表达式匹配指定的字符开头和指定的字符结束

python正则表达式匹配指定的字符开头和指定的字符结束⼀,使⽤python的re.findall函数,匹配指定的字符开头和指定的字符结束代码⽰例:1import re2# re.findall函数;匹配指定的字符串开头和指定的字符串结尾(前后不包含指定的字符串)3 str01 = 'hello word'4 str02 = re.findall('(?<=e).*?(?=r)',str01)5print(str02)输出结果:1 ['llo wo']⼆,使⽤python的re.findall函数,匹配指定的字符开头和指定的字符结束(前后包含指定的字符串)注意:在 re.findall()的第⼀个参数中输⼊的为 'h.*o' 可以匹配到相同的值直到最后⼀个值;代码⽰例:1import re2# re.findall函数;匹配指定的字符串开头和指定的字符串结尾(前后包含指定的字符串)3 str01 = 'hello word'4 str02 = re.findall('h.*o',str01)5print(str02)输出结果:1 ['hello wo']如果参数为 'h.*?o',则只匹配到第⼀个值1import re2# re.findall函数; .*? 如果匹配的字符中有多个相同的匹配结尾值的3 str01 = 'hello word'4 str02 = re.findall('h.*?o',str01)5print(str02)输出结果:1 ['hello']import re# re.findall函数;匹配指定的字符串开头和指定的字符串结尾(前后包含指定的字符串)str01 = 'hello word'str02 = re.findall('h.*o',str01)print(str02)。
python正则表达式与JSON-正则表达式匹配数字、非数字、字符、非字符、贪婪模式、非贪。。。

python正则表达式与JSON-正则表达式匹配数字、⾮数字、字符、⾮字符、贪婪模式、⾮贪。
1、正则表达式:⽬的是为了爬⾍,是爬⾍利器。
正则表达式是⽤来做字符串匹配的,⽐如检测是不是电话、是不是email、是不是ip地址之类的2、JSON:外部数据交流的主流格式。
3、正则表达式的使⽤re python 内置的模块,可以进⾏正则匹配re.findall(pattern,source)pattern:正则匹配规则-也叫郑泽表达式source:需要查找的⽬标源import rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("Java",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['Java', 'Java']4、正则表达式的应⽤查数字⽤概括字符集:\dimport rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("\d",a)print res# Project/python_ToolCodes/test10.py"# ['0', '7', '8', '6']⽤另外⼀种匹配模式-字符集:[0-9]import rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("[0-9]",a)print res# Project/python_ToolCodes/test10.py"# ['0', '7', '8', '6']其中"Java"叫普通字符,"/d" 源字符查⾮数字⽤概括字符集:\Dimport rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("\D",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['C', 'C', '+', '+', 'J', 'a', 'v', 'a', 'C', '#', 'P', 'y', 't', 'h', 'o', 'n', 'J', 'a', 'v', 'a', 'S', 'c', 'r', 'i', 'p', 't']⽤另外⼀种匹配模式-字符集:[^0-9]import rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("[^0-9]",a)print res# Project/python_ToolCodes/test10.py"# ['C', 'C', '+', '+', 'J', 'a', 'v', 'a', 'C', '#', 'P', 'y', 't', 'h', 'o', 'n', 'J', 'a', 'v', 'a', 'S', 'c', 'r', 'i', 'p', 't']正则表达式的罗列:https:///item/正则表达式/1700215?fr=aladdin,挨个练习是没有必要的,⽤到去查即可4、匹配模式源字符+普通字符混合模式[]中的或操作#coding=utf-8import rea = "abc,acc,adc,aec,afc,ahc"#匹配acc和afcres = re.findall("a[cf]c",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['acc', 'afc']取反操作:^#coding=utf-8import rea = "abc,acc,adc,aec,afc,ahc"#取出⾮(acc和afc)的字符res = re.findall("a[^cf]c",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['abc', 'adc', 'aec', 'ahc']取范围操作:-#coding=utf-8import rea = "abc,acc,adc,aec,afc,ahc"#取出acc,adc,aec,afc(中间字符是c到f范围的)res = re.findall("a[c-f]c",a)print res#[Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" #['acc', 'adc', 'aec', 'afc']匹配数字和字母:概括字符集匹配:\wimport rea = "abc&cba"res = re.findall("\w",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['a', 'b', 'c', 'c', 'b', 'a']使⽤字符集匹配:[A-Za-Z0-9]import rea = "abc123&cba321"res = re.findall("[A-Za-z0-9]",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['a', 'b', 'c', '1', '2', '3', 'c', 'b', 'a', '3', '2', '1']显然,是\w是不匹配⾮字母和数字的,⽐如“&”符号匹配⾮单词⾮数字字符概括字符集:\Wimport rea = "abc123&cba321"res = re.findall("\W",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['&']使⽤字符集匹配:^A-Za-z0-9import rea = "abc123&cba321"res = re.findall("[^A-Za-z0-9]",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['&']空格、制表符、换⾏符号之类的匹配:\simport rea = "python 111\tjava&67p\nh\rp"res = re.findall("\s",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # [' ', '\t', '\n', '\r']匹配量词:匹配出python Java php必须三个⼀组:[a-z]{3}import rea = "python 1111java678php"res = re.findall("[a-z]{3}",a)print res[Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" ['pyt', 'hon', 'jav', 'php']可以3-6个⼀组:因为最长python 为6 最短PHP为3:[a-z]{3,6}import rea = "python 1111java678php"res = re.findall("[a-z]{3,6}",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['python', 'java', 'php']疑问:为什么3个能匹配匹配到pyt的时候为什么不终⽌?因为正则表达式的数量词分为贪婪和⾮贪婪模式,默认情况下,python 认为是贪婪模式的。
python3 中文正则

python3 中文正则Python3 中的中文正则表达式正则表达式是一种强大的文本匹配工具,它可以在字符串中搜索特定的模式。
在Python3中,我们可以使用正则表达式库re来实现中文正则表达式的匹配。
本文将介绍Python3中的中文正则表达式的基本语法和常用的匹配方法。
一、中文字符的匹配在正则表达式中,我们可以使用\u4e00-\u9fa5来匹配所有的中文字符。
其中\u4e00表示第一个汉字“一”,\u9fa5表示最后一个汉字“龥”。
例如,我们可以使用正则表达式r"[\u4e00-\u9fa5]"来匹配一个字符串中的所有中文字符。
在实际应用中,我们可能需要对中文字符进行更精确的匹配。
例如,我们可以使用正则表达式r"[\u4e00-\u9fa5]{2,4}"来匹配一个字符串中长度为2到4的连续中文字符。
二、中文词语的匹配除了单个的中文字符,我们还可以使用正则表达式来匹配中文词语。
例如,我们可以使用正则表达式r"[\u4e00-\u9fa5]{2,4}匹配"来匹配一个字符串中长度为2到4的连续中文词语。
三、中文标点符号的匹配除了中文字符和中文词语,我们还可以使用正则表达式来匹配中文标点符号。
例如,我们可以使用正则表达式r"[\u3000-\u303f\u4e00-\u9fa5]"来匹配一个字符串中的中文标点符号。
四、中文数字的匹配在中文中,数字也有自己的表示方式。
例如,“一”代表1,“二”代表2,以此类推。
我们可以使用正则表达式来匹配中文数字。
例如,我们可以使用正则表达式r"[\u4e00-\u9fa5零一二三四五六七八九十百千万亿]+"来匹配一个字符串中的中文数字。
五、中文正则表达式的使用方法在Python3中,我们可以使用re库来实现中文正则表达式的匹配。
re库提供了多种函数来进行正则表达式的匹配,常用的函数有:1. re.match(pattern, string):从字符串的起始位置开始匹配正则表达式。
python常用的正则表达式大全
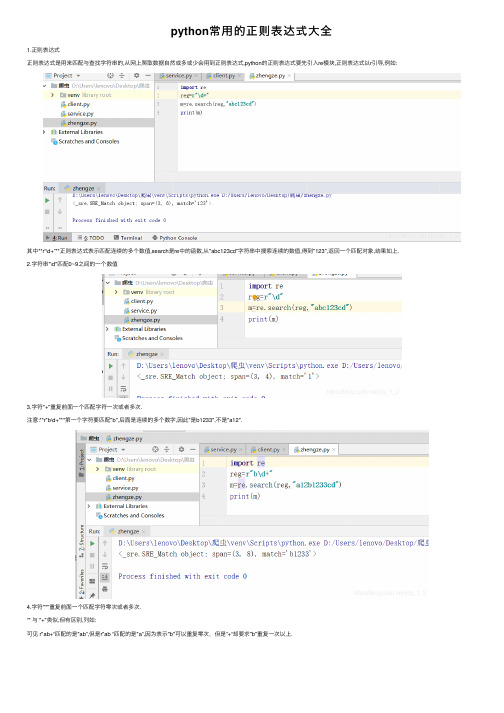
python常⽤的正则表达式⼤全1.正则表达式正则表达式是⽤来匹配与查找字符串的,从⽹上爬取数据⾃然或多或少会⽤到正则表达式,python的正则表达式要先引⼊re模块,正则表达式以r引导,例如:其中**r“\d+”**正则表达式表⽰匹配连续的多个数值,search是re中的函数,从"abc123cd"字符串中搜索连续的数值,得到"123",返回⼀个匹配对象,结果如上.2.字符串"\d"匹配0~9之间的⼀个数值3.字符"+"重复前⾯⼀个匹配字符⼀次或者多次.注意:**r"b\d+"**第⼀个字符要匹配"b",后⾯是连续的多个数字,因此"是b1233",不是"a12".4.字符"*"重复前⾯⼀个匹配字符零次或者多次.“" 与 "+"类似,但有区别,列如:可见 r"ab+“匹配的是"ab”,但是r"ab “匹配的是"a”,因为表⽰"b"可以重复零次,但是”+“却要求"b"重复⼀次以上.5.字符"?"重复前⾯⼀个匹配字符零次或者⼀次.匹配结果"ab”,重复b⼀次.6.字符".“代表任何⼀个字符,但是没有特别声明时不代表字符”\n".结果“.”代表了字符"x".7."|"代表把左右分成两个部分 .结果匹配"ab"或者"ba"都可以.8.特殊字符使⽤反斜杠"“引导,例如”\r"、"\n"、"\t"、"\"分别表⽰回车、换⾏、制表符号与反斜线⾃⼰本⾝.9.字符"\b"表⽰单词结尾,单词结尾包括各种空⽩字符或者字符串结尾.结果匹配"car",因为"car"后⾯是⼀个空格.10."[]中的字符是任选择⼀个,如果字符ASCll码中连续的⼀组,那么可以使⽤"-"字符连接,例如[0-9]表⽰0-9的其中⼀个数字,[A-Z]表⽰A-Z的其中⼀个⼤写字符,[0-9A-z]表⽰0-9的其中⼀个数字或者A-z的其中⼀个⼤写字符.11."^"出现在[]的第⼀个字符位置,就代表取反,例如[ ^ab0-9]表⽰不是a、b,也不是0-9的数字.12."\s"匹配任何空⽩字符,等价"[\r\n 20\t\f\v]"13."\w"匹配包括下划线⼦内的单词字符,等价于"[a-zA-Z0-9]"14."$"字符⽐配字符串的结尾位置匹配结果是最后⼀个"ab",⽽不是第⼀个"ab"15.使⽤括号(…)可以把(…)看出⼀个整体,经常与"+"、"*"、"?"的连续使⽤,对(…)部分进⾏重复.结果匹配"abab","+“对"ab"进⾏了重复16.查找匹配字符串正则表达式re库的search函数使⽤正则表达式对要匹配的字符串进⾏匹配,如果匹配不成功返回None,如果匹配成功返回⼀个匹配对象,匹配对象调⽤start()函数得到匹配字符的开始位置,匹配对象调⽤end()函数得到匹配字符串的结束位置,search虽然只返回匹配第⼀次匹配的结果,但是我们只要连续使⽤search函数就可以找到字符串全部匹配的字符串.匹配找出英⽂句⼦中所有单词我们可以使⽤正则表达式r”[A-Za-z]+\b"匹配单词,它表⽰匹配由⼤⼩写字母组成的连续多个字符,⼀般是⼀个单词,之后"\b"表⽰单词结尾.程序开始匹配到⼀个单词后m.start(),m.end()就是单词的起始位置,s[start:end]为截取的单词,之后程序再次匹配字符串s=s[end:],即字符串的后半段,⼀直到匹配完毕为⽌就找出每个单词.总结到此这篇关于python常⽤正则表达式的⽂章就介绍到这了,更多相关python正则表达式内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Python正则表达式实现原理_光环大数据Python培训
正则表达式便于我们理解使用,但是如何让计算机识别用正则表达式描述的语言呢?仍然以前面的[a|b]*abb为例,计算机如何识别[a|b]*abb的意义呢?首先我们来看判断输入内容是否匹配正则表达式的流程图:
图中一共有4个状态S0, S1, S2, S3,在每个状态基础上输入字符a或者b 就会进入下一个状态。
如果经过一系列输入,最终如果能达到状态S3,则输入内容一定满足正则表达式[a|b]*abb。
为了更清晰表述问题,将上图转换为状态转换表,第一列为当前状态,第二列为输入a后当前状态的跳转,第三列为输入b后当前状态的跳转。
其中S0为起始状态,S3为接受状态,从起始状态起经过一系列输入到达接受状态,那么输入内容即满足[a|b]*abb。
状态abS0S1S0S1S1S2S2S1S3S3S1S0
其实上图就是一个DFA实例(确定有限自动机),下面给出DFA较为严格的定义。
一个确定的有穷自动机(DFA) M 是一个五元组:M = (K, ∑, f, S, Z),其中:
K是一个有穷集,它的每个元素称为一个状态;
∑是一个有穷字母表,它的每个元素称为一个输入符号,所以也称∑为输入符号表;
f是转换函数,是在K×∑→K上的映射,如f(ki, a)→kj,ki∈K,kj ∈K就意味着当前状态为ki,输入符号为a时,将转换为下一个状态kj,我们将kj称作ki的一个后继状态;
S∈K是唯一的一个初态;
Z⊆K是一个状态集,为可接受状态或者结束状态。
DFA的确定性表现在转换函数f:K×∑→K是一个单值函数,也就是说对任
何状态ki∈K和输入符号a∈∑,f(k, a)唯一地确定了下一个状态,因此DFA
很容易用程序来模拟。
下面用字典实现[a|b]*abb的确定有限自动机,然后判断输入字符串是否满
足正则表达式。
123456789101112131415161718192021222324252627282930DFA_func = {0:
{“a”: 1, “b”: 0}, 1: {“a”: 1, “b”: 2}, 2:
{“a”: 1, “b”: 3}, 3: {“a”: 1, “b”:
0} }input_symbol = [“a”, “b”]current_state =
0accept_state = 3strings = [“ababaaabb”, “ababcaabb”, “abbab”]for string in strings: for char in string: if char
not in input_symbol: break else: current_state = DFA_func[current_state][char] if current_state == 3: print string, “—> Match!” else: print string, “—>No
match!” current_state = 0 “”“outputs: ababaaabb —> Match! ababcaabb —>No match! abbab —>No match! ““”
上面的例子可以看出DFA识别语言简单直接,便于用程序实现,但是DFA较
难从正则表达式直接转换。
如果我们能找到一种表达方式,用以连接正则表达式
和DFA,那么就可以让计算机识别正则表达式了。
事实上,确实有这么一种表达
方式,可以作为正则表达式和DFA的桥梁,而且很类似DFA,那就是非确定有限
自动机(NFA)。
还是上面的例子,如果用NFA表示流程图,就如下图所示:
看上去很直观,很有[a|b]*abb的神韵。
它转换为状态转换表如下:
状态abS0S0, S1S0S1ΦS2S2ΦS3S3ΦΦ
NFA的定义与DFA区别不大,M = (K, ∑, f, S, Z),其中:
K是一个有穷集,它的每个元素称为一个状态;
∑是一个有穷字母表,它的每个元素称为一个输入符号,ε表示输入为空,且ε不存在于∑;
f是转换函数,是在K×∑*→K上的映射,∑*说明存在遇到ε的情况,f(ki, a)是一个多值函数;
S∈K是唯一的一个初态;
Z⊆K是一个状态集,为可接受状态或者结束状态。
数学上已经证明:
DFA,NFA和正则表达式三者的描述能力是一样的。
正则表达式可以转换为NFA,已经有成熟的算法实现这一转换。
NFA可以转换为DFA,也有完美的实现。
这里不做过多陈述,想了解详情可以参考《编译原理》一书。
至此,计算机识别正则表达式的过程可以简化为:正则表达式→NFA→DFA。
不过有时候NFA转换为DFA可能导致状态空间的指数增长,因此直接用NFA识别正则表达式。
为什么大家选择光环大数据!
大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请大数据
领域具有多年经验的讲师,提高教学的整体质量与教学水准。
讲师团及时掌握时代的技术,将时新的技能融入教学中,让学生所学知识顺应时代所需。
通过深入浅出、通俗易懂的教学方式,指导学生较快的掌握技能知识,帮助莘莘学子实现就业梦想。
光环大数据启动了推进人工智能人才发展的“AI智客计划”。
光环大数据专注国内大数据和人工智能培训,将在人工智能和大数据领域深度合作。
未来三年,光环大数据将联合国内百所大学,通过“AI智客计划”,共同推动人工智能产业人才生态建设,培养和认证5-10万名AI大数据领域的人才。
参加“AI智客计划”,享2000元助学金!
【报名方式、详情咨询】
光环大数据网站报名:
手机报名链接:http:// /mobile/。