计量经济学第四章练习题及参考解答
《计量经济学》习题(第四章)

《计量经济学》习题(第四章)第四章习题⼀、单选题1、如果回归模型违背了同⽅差假定,最⼩⼆乘估计量____A .⽆偏的,⾮有效的 B.有偏的,⾮有效的C .⽆偏的,有效的 D.有偏的,有效的2、Goldfeld-Quandt ⽅法⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性3、DW 检验⽅法⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性4、在异⽅差性情况下,常⽤的估计⽅法是____A .⼀阶差分法 B.⼴义差分法C .⼯具变量法 D.加权最⼩⼆乘法5、在以下选项中,正确表达了序列⾃相关的是____j i u x Cov D j i x x Cov C ji u u Cov B ji u u Cov A j i j i j i j i ≠≠≠≠≠=≠≠,0),(.,0),(.,0),(.,0),(.6、如果回归模型违背了⽆⾃相关假定,最⼩⼆乘估计量____A .⽆偏的,⾮有效的 B.有偏的,⾮有效的C .⽆偏的,有效的 D.有偏的,有效的7、在⾃相关情况下,常⽤的估计⽅法____A .普通最⼩⼆乘法 B.⼴义差分法C .⼯具变量法 D.加权最⼩⼆乘法8、White 检验⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性9、Glejser 检验⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性10、简单相关系数矩阵⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性2222)(.)(.)(.)(.σσσσ==≠≠i i i i x Var D u Var C x Var B u Var A12、所谓不完全多重共线性是指存在不全为零的数k λλλ,,,21 ,有____1112211221221122.0.0..k k k k k x x x k k k k A x x x v B x x x C x x x v e D x x x v e v λλλλλλλλλλλλ++++=+++=∑?++++=++++=式中是随机误差项13、设21,x x 为解释变量,则完全多重共线性是____0.(021.0.021.22121121=+=++==+x x e x D v v x x C e x B x x A 为随机误差项)14、⼴义差分法是对____⽤最⼩⼆乘法估计其参数 11211211121121)()1(....-------+-+-=-++=++=++=t t t t t t t t t t t t t t t u u x x y y D u x y C u x y B u x y A ρρβρβρρρβρβρββββ15、在DW 检验中要求有假定条件,在下列条件中不正确的是____A .解释变量为⾮随机的 B.随机误差项为⼀阶⾃回归形式C .线性回归模型中不应含有滞后内⽣变量为解释变量D.线性回归模型为⼀元回归形式16、在下例引起序列⾃相关的原因中,不正确的是____A.经济变量具有惯性作⽤B.经济⾏为的滞后性C.设定偏误D.解释变量之间的共线性17、在DW 检验中,当d 统计量为2时,表明____A.存在完全的正⾃相关B.存在完全的负⾃相关C.不存在⾃相关D.不能判定18、在DW 检验中,当d 统计量为4时,表明____A.存在完全的正⾃相关B.存在完全的负⾃相关C.不存在⾃相关D.不能判定19、在DW 检验中,当d 统计量为0时,表明____A.存在完全的正⾃相关C.不存在⾃相关D.不能判定20、在DW 检验中,存在不能判定的区域是____A. 0﹤d ﹤l d ,4-l d ﹤d ﹤4B. u d ﹤d ﹤4-u dC. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l dD. 上述都不对21、在修正序列⾃相关的⽅法中,能修正⾼阶⾃相关的⽅法是____A. 利⽤DW 统计量值求出ρB. Cochrane-Orcutt 法C. Durbin 两步法D. 移动平均法22、在下列多重共线性产⽣的原因中,不正确的是____A.经济本变量⼤多存在共同变化趋势B.模型中⼤量采⽤滞后变量C.由于认识上的局限使得选择变量不当D.解释变量与随机误差项相关23、在DW 检验中,存在正⾃相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d24、逐步回归法既检验⼜修正了____A .异⽅差性 B.⾃相关性 C .随机解释变量 D.多重共线性25、设)()(,2221i i i i i ix f u Var u x y σσββ==++=,则对原模型变换的正确形式为____ )()()()(.)()()()(.)()()()(..212222122121i i i i i i i i i i i i i i i i i i i i i i i i x f u x f x x f x f y D x f u x f x x f x f y C x f u x f x x f x f y B u x y A ++=++=++=++=ββββββββ 26、在修正序列⾃相关的⽅法中,不正确的是____A.⼴义差分法B.普通最⼩⼆乘法C.⼀阶差分法D. Durbin 两步法27、在检验异⽅差的⽅法中,不正确的是____A. Goldfeld-Quandt ⽅法B. spearman 检验法C. White 检验法28、在DW 检验中,存在零⾃相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d29.如果模型中的解释变量存在完全的多重共线性,参数的最⼩⼆乘估计量是()A .⽆偏的 B. 有偏的 C. 不确定 D. 确定的30. 已知模型的形式为u x y 21+β+β=,在⽤实际数据对模型的参数进⾏估计的时候,测得DW 统计量为0.6453,则⼴义差分变量是( )A. 1t t ,1t t x 6453.0x y 6453.0y ----B. 1t t 1t t x 6774.0x ,y 6774.0y ----C. 1t t 1t t x x ,y y ----D. 1t t 1t t x 05.0x ,y 05.0y ----31. 在具体运⽤加权最⼩⼆乘法时,如果变换的结果是x u x x x 1xy 21+β+β=,则Var(u)是下列形式中的哪⼀种?( )A. 2σxB. 2σ2x B. 2σx D. 2σLog(x)32. 在线性回归模型中,若解释变量1x 和2x 的观测值成⽐例,即有i 2i 1kx x =,其中k 为⾮零常数,则表明模型中存在( )A. 异⽅差B. 多重共线性C. 序列⾃相关D. 设定误差33. 已知DW 统计量的值接近于2,则样本回归模型残差的⼀阶⾃相关系数ρ近似等于( ) A. 0 B. –1 C. 1 D. 4⼆、多项选择1、能够检验多重共线性的⽅法有____A.简单相关系数法B. DW检验法C. 判定系数检验法D. ⽅差膨胀因⼦检验E.逐步回归法2、能够修正多重共线性的⽅法有____A.增加样本容量B.岭回归法C.剔除多余变量E.差分模型3、如果模型中存在异⽅差现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的⽅差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是⽆偏的4、能够检验异⽅差的⽅法是____A. gleiser检验法B. White检验法C. 图形法D. spearman检验法E. DW检验法F. Goldfeld-Quandt检验法5、如果模型中存在序列⾃相关现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的⽅差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是⽆偏的6、检验序列⾃相关的⽅法是____A. gleiser检验法B. White检验法C. 图形法D. DW检验法E. Goldfeld-Quandt检验法7、能够修正序列⾃相关的⽅法有____A. 加权最⼩⼆乘法B. Durbin两步法C. ⼴义最⼩⼆乘法D. ⼀阶差分法E. ⼴义差分法8、Goldfeld-Quandt检验法的应⽤条件是____A. 将观测值按解释变量的⼤⼩顺序排列B. 样本容量尽可能⼤C. 随机误差项服从正态分布D. 将排列在中间的约1/4的观测值删除掉9、在DW检验中,存在不能判定的区域是____A. 0﹤d﹤l dB. u d﹤d﹤4-u dC. l d﹤d﹤u dD. 4-u d﹤d﹤4-l dE. 4-l d﹤d﹤4。
计量经济学(第四版)习题及参考答案解析详细版

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
庞皓第三版计量经济学练习题及参考解答(完整版)
百户拥有 家用汽车量(辆) Y 37.71 20.62 23.32 18.60 19.62 11.15 11.24
北 京 天 津 河 北 山 西 内蒙古 辽 宁 吉 林
黑龙江 上 海 江 苏 浙 江 安 徽 福 建 江 西 山 东 河 南 湖 北 湖 南 广 东 广 西 海 南 重 庆 四 川 贵 州 云 南 西 藏 陕 西 甘 肃 青 海 宁 夏 新 疆
5 6 7 8 9 10 11 12 根据上表资料:
2.56 3.54 3.89 4.37 4.82 5.66 6.11 6.23
1678 1640 1620 1576 1566 1498 1425 1419
(1)建立建筑面积与建造单位成本的回归方程; (2)解释回归系数的经济意义; (3)估计当建筑面积为 4.5 万平方米时,对建造的平均单位成本作区间预测。
650 m 2.23 5.4772 1 5.0833 650 m 30.1250
2.4 假设某地区住宅建筑面积与建造单位成本的有关资料如表 2.11: 表 2.11 建筑地编号 1 2 3 4 某地区住宅建筑面积与建造单位成本数据 建筑面积(万平方米)X 0.6 0.95 1.45 2.1 建造单位成本(元/平方米)Y 1860 1750 1710 1690
(1)消费支出 C 的点预测值;
(2)在 95%的置信概率下消费支出 C 平均值的预测区间。 (3)在 95%的置信概率下消费支出 C 个别值的预测区间。
【练习题 2.3 参考解答】 (1)当 X f 1000 时,消费支出 C 的点预测值;
ˆ 50 0.6 X =50+0.6*1000=650 C i i
e2 ˆ2 i n 1 ˆ
2
计量经济学4-7章单选、多选题带答案

18、设 x1 , x2 为解释变量,则完全多重共线性是( A )
1 A.x12x2 0
B.x1ex2 0
C.x11 2x2v0(v为随机误差 D.x1 项 ex2 ) 0
19、多重共线性是一种( A
A、样本现象
C.被解释变量现象
) B.随机误差现象
D.总体现象
20、广义差分法是对(
A .y t 1 2 x t u t C .y t 1 2 x t u t
B . fy(ixi)f(1 xi)2
xi ui f(xi) f(xi)
D .yif(xi)1f(xi)2xif(xi)uif(xi)
45、对模型进行对数变换,其原因是( B )
A.能使误差转变为绝对误差 B.能使误差转变为相对误差. C.更加符合经济意义 D.大多数经济现象可用对数模型表示
46、在修正异方差的方法中,不正确的是( D )
A. 广义差分法 C. 普通最小二乘法
)的一个特例 B. 广义最小二乘法. D. 两阶段最小二乘法
25、设 i 为随机误差项,则一阶自相关是指( B )
A .co t,s v ) 0 ((t s)
B .u tu t 1t
C .u t2 6、1 在u t序 1 列 自2 相u t关 2 的 情t况下,参数估计值D 仍.u 是t无 偏2 的u t, 1 其 原t因
B. Cochrane-Orcutt法 D. 移动平均法
36、违背零均值假定的原因是(
A.变量没有出现异常值
B
.
C.变量为正常波动
) B.变量出现了异常值
D.变量取值恒定不
37、在下列多重共线性产生的原因中,不正确的是( D )
A. 经济变量大多存在共同变化趋势 B. 模型中大量采用滞后变量 C. 由于认识上的局限使得选择变量不当 D. 解释变量与随机误差项相关.
庞皓《计量经济学》(第4版)章节题库-第4章 多重共线性【圣才出品】

第4章 多重共线性一、选择题1.下列哪项回归分析中很可能出现多重共线性问题?( )A.“资本投入”“劳动投入”两个变量同时作为生产函数的解释变量B.“消费”作为被解释变量,“收入”作解释变量的消费函数C.“本期收入”和“前期收入”同时作为“消费”的解释变量的消费函数D.“每亩施肥量”“每亩施肥量的平方”同时作为“小麦亩产”的解释变量的模型【答案】C【解析】产生多重共线性的主要原因有:①经济变量相关的共同趋势;②模型设定不谨慎;③样本资料的限制。
C项中“本期收入”和“前期收入”两个解释变量之间很可能存在线性相关性,导致模型中很可能会出现多重共线性问题。
2.在线性回归模型Y i=β0+β1X i1+β2X i2+β3X i3+u i中,如果X3i=2X1i+3X2i,则表明模型中存在( )。
A.异方差B.多重共线性C.序列相关D.设定误差【答案】B【解析】当存在不全为0的c i使c i X i1+c2X i2+…+c k X ik=0(i=1,2,…,n),即某一个解释变量可以用其他解释变量的线性组合表示,则称为解释变量间存在完全共线性,模型的回归系数估计值不存在。
本题中,存在c i 不等于0,使得X 3i -2X 1i -3X 2i =0,因此模型存在完全多重共线性。
3.对于模型Y i =β0+β1X 1i +β2X 2i +μi ,与r 12=0相比,当r 12=0.5时,估计量Error!1的方差Var (1)将是原来的( )倍。
A .1.00B .1.33C .1.45D .2.00【答案】B【解析】在二元线性回归模型中,()221211ˆ1i Var r X σβ=⋅-∑多重共线性使参数估计量的方差增大,方差膨胀因子为VIF (1)=1/(1-r 2),所以当r 12=0.5时,方差将是原来的1/(1-r 122)=1/(1-0.52)=1.33倍。
4.下列各项中,不属于解决多重共线性的方法的是( )。
《计量经济学》习题(第四章)

第四章 习 题一、单选题1、如果回归模型违背了同方差假定,最小二乘估计量____A .无偏的,非有效的 B.有偏的,非有效的C .无偏的,有效的 D.有偏的,有效的2、Goldfeld-Quandt 方法用于检验____A .异方差性 B.自相关性C .随机解释变量 D.多重共线性3、DW 检验方法用于检验____A .异方差性 B.自相关性C .随机解释变量 D.多重共线性4、在异方差性情况下,常用的估计方法是____A .一阶差分法 B.广义差分法C .工具变量法 D.加权最小二乘法5、在以下选项中,正确表达了序列自相关的是____j i u x Cov D j i x x Cov C ji u u Cov B ji u u Cov A j i j i j i j i ≠≠≠≠≠=≠≠,0),(.,0),(.,0),(.,0),(.6、如果回归模型违背了无自相关假定,最小二乘估计量____A .无偏的,非有效的 B.有偏的,非有效的C .无偏的,有效的 D.有偏的,有效的7、在自相关情况下,常用的估计方法____A .普通最小二乘法 B.广义差分法C .工具变量法 D.加权最小二乘法8、White 检验方法主要用于检验____A .异方差性 B.自相关性C .随机解释变量 D.多重共线性9、Glejser 检验方法主要用于检验____A .异方差性 B.自相关性C .随机解释变量 D.多重共线性10、简单相关系数矩阵方法主要用于检验____A .异方差性 B.自相关性C .随机解释变量 D.多重共线性11、所谓异方差是指____2222)(.)(.)(.)(.σσσσ==≠≠i i i i x Var D u Var C x Var B u Var A12、所谓不完全多重共线性是指存在不全为零的数k λλλ,,,21 ,有____1112211221221122.0.0..k k k k k x x x k k k k A x x x v B x x x C x x x v e D x x x v e v λλλλλλλλλλλλ++++=+++=∑⎰++++=++++=式中是随机误差项13、设21,x x 为解释变量,则完全多重共线性是____0.(021.0.021.22121121=+=++==+x x e x D v v x x C e x B x x A 为随机误差项) 14、广义差分法是对____用最小二乘法估计其参数11211211121121)()1(....-------+-+-=-++=++=++=t t t t t t t t t t t t tt t u u x x y y D u x y C u x y B u x y A ρρβρβρρρβρβρββββ15、在DW 检验中要求有假定条件,在下列条件中不正确的是____A .解释变量为非随机的 B.随机误差项为一阶自回归形式C .线性回归模型中不应含有滞后内生变量为解释变量D.线性回归模型为一元回归形式16、在下例引起序列自相关的原因中,不正确的是____A.经济变量具有惯性作用B.经济行为的滞后性C.设定偏误D.解释变量之间的共线性17、在DW 检验中,当d 统计量为2时,表明____A.存在完全的正自相关B.存在完全的负自相关C.不存在自相关D.不能判定18、在DW 检验中,当d 统计量为4时,表明____A.存在完全的正自相关B.存在完全的负自相关C.不存在自相关D.不能判定19、在DW 检验中,当d 统计量为0时,表明____A.存在完全的正自相关B.存在完全的负自相关C.不存在自相关D.不能判定20、在DW 检验中,存在不能判定的区域是____A. 0﹤d ﹤l d ,4-l d ﹤d ﹤4B. u d ﹤d ﹤4-u dC. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l dD. 上述都不对21、在修正序列自相关的方法中,能修正高阶自相关的方法是____A. 利用DW 统计量值求出ρˆ B. Cochrane-Orcutt 法 C. Durbin 两步法 D. 移动平均法22、在下列多重共线性产生的原因中,不正确的是____A.经济本变量大多存在共同变化趋势B.模型中大量采用滞后变量C.由于认识上的局限使得选择变量不当D.解释变量与随机误差项相关23、在DW 检验中,存在正自相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d24、逐步回归法既检验又修正了____A .异方差性 B.自相关性 C .随机解释变量 D.多重共线性25、设)()(,2221i i i i i i x f u Var u x y σσββ==++=,则对原模型变换的正确形式为____ )()()()(.)()()()(.)()()()(..212222122121i i i i i i i i i i i i i i i i i i i i i i i i x f u x f x x f x f y D x f u x f x x f x f y C x f u x f x x f x f y B u x y A ++=++=++=++=ββββββββ26、在修正序列自相关的方法中,不正确的是____A.广义差分法B.普通最小二乘法C.一阶差分法D. Durbin 两步法27、在检验异方差的方法中,不正确的是____A. Goldfeld-Quandt 方法B. spearman 检验法C. White 检验法D. DW 检验法28、在DW 检验中,存在零自相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d29.如果模型中的解释变量存在完全的多重共线性,参数的最小二乘估计量是( )A .无偏的 B. 有偏的 C. 不确定 D. 确定的30. 已知模型的形式为u x y 21+β+β=,在用实际数据对模型的参数进行估计的时候,测得DW 统计量为0.6453,则广义差分变量是( )A. 1t t ,1t t x 6453.0x y 6453.0y ----B. 1t t 1t t x 6774.0x ,y 6774.0y ----C. 1t t 1t t x x ,y y ----D. 1t t 1t t x 05.0x ,y 05.0y ----31. 在具体运用加权最小二乘法时,如果变换的结果是x u x x x 1xy 21+β+β=,则Var(u)是下列形式中的哪一种?( )A. 2σxB. 2σ2x B. 2σx D. 2σLog(x)32. 在线性回归模型中,若解释变量1x 和2x 的观测值成比例,即有i 2i 1kx x =,其中k 为非零常数,则表明模型中存在( )A. 异方差B. 多重共线性C. 序列自相关D. 设定误差33. 已知DW 统计量的值接近于2,则样本回归模型残差的一阶自相关系数ρˆ近似等于( ) A. 0 B. –1 C. 1 D. 4二、多项选择1、能够检验多重共线性的方法有____A.简单相关系数法B. DW 检验法C. 判定系数检验法D. 方差膨胀因子检验E.逐步回归法3、能够修正多重共线性的方法有____A.增加样本容量B.岭回归法C.剔除多余变量D.逐步回归法E.差分模型3、如果模型中存在异方差现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的方差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是无偏的4、能够检验异方差的方法是____A. gleiser检验法B. White检验法C. 图形法D. spearman检验法E. DW检验法F. Goldfeld-Quandt检验法5、如果模型中存在序列自相关现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的方差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是无偏的6、检验序列自相关的方法是____A. gleiser检验法B. White检验法C. 图形法D. DW检验法E. Goldfeld-Quandt检验法7、能够修正序列自相关的方法有____A. 加权最小二乘法B. Durbin两步法C.广义最小二乘法D. 一阶差分法E.广义差分法8、Goldfeld-Quandt检验法的应用条件是____A. 将观测值按解释变量的大小顺序排列B. 样本容量尽可能大C. 随机误差项服从正态分布D. 将排列在中间的约1/4的观测值删除掉9、在DW检验中,存在不能判定的区域是____A. 0﹤d﹤l dB. u d﹤d﹤4-u dC. l d﹤d﹤u dD. 4-u d﹤d﹤4-l dE. 4-l d﹤d﹤4。
计量经济学第4章课后答案
17CHAPTER 4SOLUTIONS TO PROBLEMS4.2 (i) and (iii) generally cause the t statistics not to have a t distribution under H 0.Homoskedasticity is one of the CLM assumptions. An important omitted variable violates Assumption MLR.3. The CLM assumptions contain no mention of the sample correlations among independent variables, except to rule out the case where the correlation is one.4.3 (i) While the standard error on hrsemp has not changed, the magnitude of the coefficient has increased by half. The t statistic on hrsemp has gone from about –1.47 to –2.21, so now the coefficient is statistically less than zero at the 5% level. (From Table G.2 the 5% critical value with 40 df is –1.684. The 1% critical value is –2.423, so the p -value is between .01 and .05.)(ii) If we add and subtract 2βlog(employ ) from the right-hand-side and collect terms, we havelog(scrap ) = 0β + 1βhrsemp + [2βlog(sales) – 2βlog(employ )] + [2βlog(employ ) + 3βlog(employ )] + u = 0β + 1βhrsemp + 2βlog(sales /employ ) + (2β + 3β)log(employ ) + u ,where the second equality follows from the fact that log(sales /employ ) = log(sales ) – log(employ ). Defining 3θ ≡ 2β + 3β gives the result.(iii) No. We are interested in the coefficient on log(employ ), which has a t statistic of .2, which is very small. Therefore, we conclude that the size of the firm, as measured by employees, does not matter, once we control for training and sales per employee (in a logarithmic functional form).(iv) The null hypothesis in the model from part (ii) is H 0:2β = –1. The t statistic is [–.951 – (–1)]/.37 = (1 – .951)/.37 ≈ .132; this is very small, and we fail to reject whether we specify a one- or two-sided alternative.4.4 (i) In columns (2) and (3), the coefficient on profmarg is actually negative, although its t statistic is only about –1. It appears that, once firm sales and market value have been controlled for, profit margin has no effect on CEO salary.(ii) We use column (3), which controls for the most factors affecting salary. The t statistic on log(mktval ) is about 2.05, which is just significant at the 5% level against a two-sided alternative.18(We can use the standard normal critical value, 1.96.) So log(mktval ) is statistically significant. Because the coefficient is an elasticity, a ceteris paribus 10% increase in market value is predicted to increase salary by 1%. This is not a huge effect, but it is not negligible, either.(iii) These variables are individually significant at low significance levels, with t ceoten ≈ 3.11 and t comten ≈ –2.79. Other factors fixed, another year as CEO with the company increases salary by about 1.71%. On the other hand, another year with the company, but not as CEO, lowers salary by about .92%. This second finding at first seems surprising, but could be related to the “superstar” effect: firms that hire CEOs from outside the company often go after a small pool of highly regarded candidates, and salaries of these people are bid up. More non-CEO years with a company makes it less likely the person was hired as an outside superstar.4.7 (i) .412 ± 1.96(.094), or about .228 to .596.(ii) No, because the value .4 is well inside the 95% CI.(iii) Yes, because 1 is well outside the 95% CI.4.8 (i) With df = 706 – 4 = 702, we use the standard normal critical value (df = ∞ in Table G.2), which is 1.96 for a two-tailed test at the 5% level. Now t educ = −11.13/5.88 ≈ −1.89, so |t educ | = 1.89 < 1.96, and we fail to reject H 0: educ β = 0 at the 5% level. Also, t age ≈ 1.52, so age is also statistically insignificant at the 5% level.(ii) We need to compute the R -squared form of the F statistic for joint significance. But F = [(.113 − .103)/(1 − .113)](702/2) ≈ 3.96. The 5% critical value in the F 2,702 distribution can be obtained from Table G.3b with denominator df = ∞: cv = 3.00. Therefore, educ and age are jointly significant at the 5% level (3.96 > 3.00). In fact, the p -value is about .019, and so educ and age are jointly significant at the 2% level.(iii) Not really. These variables are jointly significant, but including them only changes the coefficient on totwrk from –.151 to –.148.(iv) The standard t and F statistics that we used assume homoskedasticity, in addition to the other CLM assumptions. If there is heteroskedasticity in the equation, the tests are no longer valid.4.11 (i) Holding profmarg fixed, n rdintensΔ = .321 Δlog(sales ) = (.321/100)[100log()sales ⋅Δ] ≈ .00321(%Δsales ). Therefore, if %Δsales = 10, n rdintens Δ ≈ .032, or only about 3/100 of a percentage point. For such a large percentage increase in sales,this seems like a practically small effect.(ii) H 0:1β = 0 versus H 1:1β > 0, where 1β is the population slope on log(sales ). The t statistic is .321/.216 ≈ 1.486. The 5% critical value for a one-tailed test, with df = 32 – 3 = 29, is obtained from Table G.2 as 1.699; so we cannot reject H 0 at the 5% level. But the 10% criticalvalue is 1.311; since the t statistic is above this value, we reject H0 in favor of H1 at the 10% level.(iii) Not really. Its t statistic is only 1.087, which is well below even the 10% critical value for a one-tailed test.1920SOLUTIONS TO COMPUTER EXERCISESC4.1 (i) Holding other factors fixed,111log()(/100)[100log()](/100)(%),voteA expendA expendA expendA βββΔ=Δ=⋅Δ≈Δwhere we use the fact that 100log()expendA ⋅Δ ≈ %expendA Δ. So 1β/100 is the (ceteris paribus) percentage point change in voteA when expendA increases by one percent.(ii) The null hypothesis is H 0: 2β = –1β, which means a z% increase in expenditure by A and a z% increase in expenditure by B leaves voteA unchanged. We can equivalently write H 0: 1β + 2β = 0.(iii) The estimated equation (with standard errors in parentheses below estimates) isn voteA = 45.08 + 6.083 log(expendA ) – 6.615 log(expendB ) + .152 prtystrA(3.93) (0.382) (0.379) (.062) n = 173, R 2 = .793.The coefficient on log(expendA ) is very significant (t statistic ≈ 15.92), as is the coefficient on log(expendB ) (t statistic ≈ –17.45). The estimates imply that a 10% ceteris paribus increase in spending by candidate A increases the predicted share of the vote going to A by about .61percentage points. [Recall that, holding other factors fixed, n voteAΔ≈(6.083/100)%ΔexpendA ).] Similarly, a 10% ceteris paribus increase in spending by B reduces n voteAby about .66 percentage points. These effects certainly cannot be ignored.While the coefficients on log(expendA ) and log(expendB ) are of similar magnitudes (andopposite in sign, as we expect), we do not have the standard error of 1ˆβ + 2ˆβ, which is what we would need to test the hypothesis from part (ii).(iv) Write 1θ = 1β +2β, or 1β = 1θ– 2β. Plugging this into the original equation, and rearranging, givesn voteA = 0β + 1θlog(expendA ) + 2β[log(expendB ) – log(expendA )] +3βprtystrA + u ,When we estimate this equation we obtain 1θ≈ –.532 and se( 1θ)≈ .533. The t statistic for the hypothesis in part (ii) is –.532/.533 ≈ –1. Therefore, we fail to reject H 0: 2β = –1β.21C4.3 (i) The estimated model isn log()price = 11.67 + .000379 sqrft + .0289 bdrms (0.10) (.000043) (.0296)n = 88, R 2 = .588.Therefore, 1ˆθ= 150(.000379) + .0289 = .0858, which means that an additional 150 square foot bedroom increases the predicted price by about 8.6%.(ii) 2β= 1θ – 1501β, and solog(price ) = 0β+ 1βsqrft + (1θ – 1501β)bdrms + u= 0β+ 1β(sqrft – 150 bdrms ) + 1θbdrms + u .(iii) From part (ii), we run the regressionlog(price ) on (sqrft – 150 bdrms ), bdrms ,and obtain the standard error on bdrms . We already know that 1ˆθ= .0858; now we also getse(1ˆθ) = .0268. The 95% confidence interval reported by my software package is .0326 to .1390(or about 3.3% to 13.9%).C4.5 (i) If we drop rbisyr the estimated equation becomesn log()salary = 11.02 + .0677 years + .0158 gamesyr (0.27) (.0121) (.0016)+ .0014 bavg + .0359 hrunsyr (.0011) (.0072)n = 353, R 2= .625.Now hrunsyr is very statistically significant (t statistic ≈ 4.99), and its coefficient has increased by about two and one-half times.(ii) The equation with runsyr , fldperc , and sbasesyr added is22n log()salary = 10.41 + .0700 years + .0079 gamesyr(2.00) (.0120) (.0027)+ .00053 bavg + .0232 hrunsyr (.00110) (.0086)+ .0174 runsyr + .0010 fldperc – .0064 sbasesyr (.0051) (.0020) (.0052) n = 353, R 2 = .639.Of the three additional independent variables, only runsyr is statistically significant (t statistic = .0174/.0051 ≈ 3.41). The estimate implies that one more run per year, other factors fixed,increases predicted salary by about 1.74%, a substantial increase. The stolen bases variable even has the “wrong” sign with a t statistic of about –1.23, while fldperc has a t statistic of only .5. Most major league baseball players are pretty good fielders; in fact, the smallest fldperc is 800 (which means .800). With relatively little variation in fldperc , it is perhaps not surprising that its effect is hard to estimate.(iii) From their t statistics, bavg , fldperc , and sbasesyr are individually insignificant. The F statistic for their joint significance (with 3 and 345 df ) is about .69 with p -value ≈ .56. Therefore, these variables are jointly very insignificant.C4.7 (i) The minimum value is 0, the maximum is 99, and the average is about 56.16. (ii) When phsrank is added to (4.26), we get the following:n log() wage = 1.459 − .0093 jc + .0755 totcoll + .0049 exper + .00030 phsrank (0.024) (.0070) (.0026) (.0002) (.00024)n = 6,763, R 2 = .223So phsrank has a t statistic equal to only 1.25; it is not statistically significant. If we increase phsrank by 10, log(wage ) is predicted to increase by (.0003)10 = .003. This implies a .3% increase in wage , which seems a modest increase given a 10 percentage point increase in phsrank . (However, the sample standard deviation of phsrank is about 24.)(iii) Adding phsrank makes the t statistic on jc even smaller in absolute value, about 1.33, but the coefficient magnitude is similar to (4.26). Therefore, the base point remains unchanged: the return to a junior college is estimated to be somewhat smaller, but the difference is not significant and standard significant levels.(iv) The variable id is just a worker identification number, which should be randomly assigned (at least roughly). Therefore, id should not be correlated with any variable in the regression equation. It should be insignificant when added to (4.17) or (4.26). In fact, its t statistic is about .54.23C4.9 (i) The results from the OLS regression, with standard errors in parentheses, aren log() psoda =−1.46 + .073 prpblck + .137 log(income ) + .380 prppov (0.29) (.031) (.027) (.133)n = 401, R 2 = .087The p -value for testing H 0: 10β= against the two-sided alternative is about .018, so that we reject H 0 at the 5% level but not at the 1% level.(ii) The correlation is about −.84, indicating a strong degree of multicollinearity. Yet eachcoefficient is very statistically significant: the t statistic for log()ˆincome β is about 5.1 and that forˆprppovβ is about 2.86 (two-sided p -value = .004).(iii) The OLS regression results when log(hseval ) is added aren log() psoda =−.84 + .098 prpblck − .053 log(income ) (.29) (.029) (.038) + .052 prppov + .121 log(hseval ) (.134) (.018)n = 401, R 2 = .184The coefficient on log(hseval ) is an elasticity: a one percent increase in housing value, holding the other variables fixed, increases the predicted price by about .12 percent. The two-sided p -value is zero to three decimal places.(iv) Adding log(hseval ) makes log(income ) and prppov individually insignificant (at even the 15% significance level against a two-sided alternative for log(income ), and prppov is does not have a t statistic even close to one in absolute value). Nevertheless, they are jointly significant at the 5% level because the outcome of the F 2,396 statistic is about 3.52 with p -value = .030. All of the control variables – log(income ), prppov , and log(hseval ) – are highly correlated, so it is not surprising that some are individually insignificant.(v) Because the regression in (iii) contains the most controls, log(hseval ) is individually significant, and log(income ) and prppov are jointly significant, (iii) seems the most reliable. It holds fixed three measure of income and affluence. Therefore, a reasonable estimate is that if the proportion of blacks increases by .10, psoda is estimated to increase by 1%, other factors held fixed.。
计量经济学作业 第四章
计量经济学作业第四章7.下表给出了2000年中国部分省市城镇居民每个家庭平均全年可支配收入(X)地区可支配收入消费性支出地区可支配收入消费性支出北京10349.69 8493.49 河北5661.16 4348.47天津8140.50 6121.04 山西4724.11 3941.87内蒙古5129.05 3927.75 河南4766.26 3830.71辽宁5357.79 4356.06 湖北5524.54 4644.50吉林4810.00 4020.87 湖南6218.73 5218.79黑龙江4912.88 3824.44 广东9761.57 8016.91上海11718.01 8868.19 陕西5124.24 4276.67江苏6800.23 5323.18 甘肃4916.25 4126.47浙江9279.16 7020.22 青海5169.96 4185.73山东6489.97 5022.00 新疆5644.86 4422.93 (2)检验模型是存在异方差;(3)如果存在异方差性,试采用适当的方法伏击模型参数。
解:(1)采用Eviews,用OLS估计的结果如下:人均消费支出与可支配收入的线性模型为:Y =272.36+0.76X 2R=0.9831,F=1048.912,D.W.=1.1893。
(2)残差图如下所示,由图可以认为可能存在异方差性。
做进一步的统计检验,采用怀特检验。
得:2e=-180998.9+49.42846X-0.002115X怀特统计量:n 2R=20*0.632606=12.65212>自由度为2的卡方分布的相应临界值5.99。
即拒绝同方差性的原假设。
因此存在异方差性。
(3)采用加权最小二乘法对原模型进行回归估计,得:由输出结果可知,人均消费支出与可支配收入的线性模型为Y=415.6603+0.729026X。
2R=0.999895,DW=1.545424,F=1056.477可以看出,加权最小二乘估计结果与不加权OLS估计结果有较大区别。
计量经济学第四版习题及参考答案
计量经济学第四版习题及参考答案Document number【AA80KGB-AA98YT-AAT8CB-2A6UT-A18GG】计量经济学(第四版)习题参考答案潘省初第一章 绪论试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 计量经济模型中为何要包括扰动项为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
什么是时间序列和横截面数据 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
估计量和估计值有何区别估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础略,参考教材。
请用例中的数据求北京男生平均身高的99%置信区间NSS x ==45= 用?=,N-1=15个自由度查表得005.0t =,故99%置信限为 x S t X 005.0± =174±×=174±也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在至厘米之间。
计量经济学精要习题参考答案(第四版)
计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH2检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第四章练习题及参考解答4.1 假设在模型i i i iu X X Y +++=33221βββ中,32X X 与之间的相关系数为零,于是有人建议你进行如下回归:ii i i i i u X Y u X Y 23311221++=++=γγαα(1)是否存在3322ˆˆˆˆβγβα==且?为什么? (2)111ˆˆˆβαγ会等于或或两者的某个线性组合吗? (3)是否有()()()()3322ˆvar ˆvar ˆvar ˆvarγβαβ==且? 练习题4.1参考解答:(1) 存在3322ˆˆˆˆβγβα==且。
因为()()()()()()()23223223232322ˆ∑∑∑∑∑∑∑--=iiiii iii iii x x x x x xx y x x y β当32X X 与之间的相关系数为零时,离差形式的032=∑i i x x有()()()()222223222322ˆˆαβ===∑∑∑∑∑∑iiiiiiii xx y x x x x y 同理有:33ˆˆβγ= (2) 111ˆˆˆβαγ会等于或的某个线性组合 因为12233ˆˆˆY X X βββ=--,且122ˆˆY X αα=-,133ˆˆY X γγ=- 由于3322ˆˆˆˆβγβα==且,则 11222222ˆˆˆˆˆY Y X Y X X αααββ-=-=-=11333333ˆˆˆˆˆY Y X Y X X γγγββ-=-=-=则 1112233231123ˆˆˆˆˆˆˆY Y Y X X Y X X Y X X αγβββαγ--=--=--=+- (3) 存在()()()()3322ˆvar ˆvar ˆvar ˆvarγβαβ==且。
因为()()∑-=22322221ˆvarr x iσβ当023=r 时,()()()22222232222ˆvar 1ˆvar ασσβ==-=∑∑iixr x 同理,有()()33ˆvar ˆvar γβ=4.2在决定一个回归模型的“最优”解释变量集时人们常用逐步回归的方法。
在逐步回归中既可采取每次引进一个解释变量的程序(逐步向前回归),也可以先把所有可能的解释变量都放在一个多元回归中,然后逐一地将它们剔除(逐步向后回归)。
加进或剔除一个变量,通常是根据F 检验看其对ESS 的贡献而作出决定的。
根据你现在对多重共线性的认识,你赞成任何一种逐步回归的程序吗?为什么?练习题4.2参考解答:根据对多重共线性的理解,逐步向前和逐步向后回归的程序都存在不足。
逐步向前法不能反映引进新的解释变量后的变化情况,即一旦引入就保留在方程中;逐步向后法则一旦某个解释变量被剔出就再也没有机会重新进入方程。
而解释变量之间及其与被解释变量的相关关系与引入的变量个数及同时引入哪些变量而呈现出不同,所以要寻找到“最优”变量子集则采用逐步回归较好,它吸收了逐步向前和逐步向后的优点。
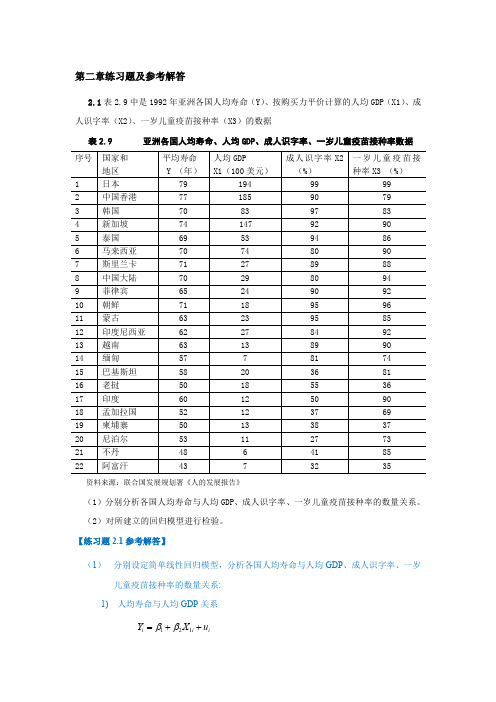
4.3 下表给出了中国商品进口额Y 、国内生产总值GDP 、居民消费价格指数CPI 。
表4.11 中国商品进口额、国内生产总值、居民消费价格指数资料来源:《中国统计年鉴》,中国统计出版社2000年、2008年。
请考虑下列模型:i t t t u CPI GDP Y ++=ln ln ln 321βββ+1)利用表中数据估计此模型的参数。
2)你认为数据中有多重共线性吗? 3)进行以下回归:it t i t t i t t v CPI C C GDP v CPI B B Y v GDP A A Y 321221121ln ln ln ln ln ln ++=+=+=++根据这些回归你能对数据中多重共线性的性质说些什么?4)假设数据有多重共线性,但32ˆˆββ和在5%水平上个别地显著,并且总的F 检验也是显著的。
对这样的情形,我们是否应考虑共线性的问题?练习题4.3参考解答: (1) 参数估计结果如下22ln() 3.060 1.657ln() 1.057ln() (0.337) (0.092) (0.215)0.992 0.991 F 1275.093GDP CPI R R =-+-===进口(括号内为标准误)(2)居民消费价格指数的回归系数的符号不能进行合理的经济意义解释,且且CPI 与进口之间的简单相关系数呈现正向变动。
可能数据中有多重共线性。
计算相关系数:年份商品进口额(亿元)国内生产总值(亿元) 居民消费价格指数(1985=100)1985 1257.8 9016.0 100.0 19861498.3 10275.2 106.5 1987 1614.2 12058.6 114.3 1988 2055.1 15042.8 135.8 1989 2199.9 16992.3 160.2 19902574.3 18667.8 165.2 1991 3398.7 21781.5 170.8 1992 4443.3 26923.5 181.7 1993 5986.2 35333.9 208.4 1994 9960.1 48197.9 258.6 1995 11048.1 60793.7 302.8 199611557.4 71176.6 327.9 1997 11806.5 78973.0 337.1 1998 11626.1 84402.3 334.4 1999 13736.4 89677.1 329.7 2000 18638.8 99214.6 331.0 2001 20159.2 109655.2 333.3 2002 24430.3 120332.7 330.6 2003 34195.6 135822.8 334.6 2004 46435.8 159878.3 347.7 2005 54273.7 183084.8 353.9 2006 63376.9 211923.5 359.2 200773284.6249529.9376.5(3)最大的CI=108.812,表明GDP 与CPI 之间存在较高的线性相关。
(4)分别拟合的回归模型如下:22ln Y 4.09071.2186ln () t= (-10.6458) (34.6222)0.9828 0.9820 1198.698GDP R R F =-+===22ln Y 5.4424 2.6637ln (PI) t= (-4.3412) (11.6809)0.8666 0.8603 136.4437C R R F =-+===22ln() 1.4380 2.2460ln (PI) t=(-1.9582) (16.8140)0.9309 0.9276 282.7107GDP C R R F =-+===单方程拟合效果都很好,回归系数显著,可决系数较高,GDP 和CPI 对进口分别有显著的单一影响,在这两个变量同时引入模型时影响方向发生了改变,这只有通过相关系数的分析才能发现。
(5)如果仅仅是作预测,可以不在意这种多重共线性,但如果是进行结构分析,还是应该引起注意。
4.4 自己找一个经济问题来建立多元线性回归模型,怎样选择变量和构造解释变量数据矩阵X 才可能避免多重共线性的出现?练习题4.4参考解答:本题很灵活,主要应注意以下问题:(1)选择变量时要有理论支持,即理论预期或假设;变量的数据要足够长,被解释变量与解释变量之间要有因果关系,并高度相关。
(2)建模时尽量使解释变量之间不高度相关,或解释变量的线性组合不高度相关。
4.5 克莱因与戈德伯格曾用1921-1950年(1942-1944年战争期间略去)美国国内消费Y 和工资收入X1、非工资—非农业收入X2、农业收入X3的时间序列资料,利用OLSE 估计得出了下列回归方程:37.107 95.0 (1.09) (0.66) (0.17) (8.92) 3121.02452.01059.1133.8ˆ2==+++=F R X X X Y括号中的数据为相应参数估计量的标准误差。
试对上述模型进行评析,指出其中存在的问题。
练习题4.5参考解答:从模型拟合结果可知,样本观测个数为27,消费模型的判定系数95.02=R,F 统计量为107.37,在0.05置信水平下查分子自由度为3,分母自由度为23的F 临界值为3.028,计算的F 值远大于临界值,表明回归方程是显著的。
模型整体拟合程度较高。
依据参数估计量及其标准误,可计算出各回归系数估计量的t 统计量值:01238.1331.0590.4520.1210.91, 6.10,0.69,0.118.920.170.661.09t t t t ========除1t 外,其余的j t 值都很小。
工资收入X1的系数的t 检验值虽然显著,但该系数的估计值过大,该值为工资收入对消费边际效应,因为它为1.059,意味着工资收入每增加一美元,消费支出的增长平均将超过一美元,这与经济理论和常识不符。
另外,理论上非工资—非农业收入与农业收入也是消费行为的重要解释变量,但两者的t 检验都没有通过。
这些迹象表明,模型中存在严重的多重共线性,不同收入部分之间的相互关系,掩盖了各个部分对解释消费行为的单独影响。
4.6 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。
为此,收集了中国能源消费总量Y (万吨标准煤)、国民总收入(亿元)X1(代表收入水平)、国内生产总值 (亿元)X2(代表经济发展水平)、工业增加值(亿元)X3、建筑业增加值(亿元)X4、交通运输邮电业增加值(亿元)X5(代表产业发展水平及产业结构)、人均生活电力消费 (千瓦小时)X6(代表人民生活水平提高)、能源加工转换效率(%)X7(代表能源转换技术)等在1985-2007年期间的统计数据,具体如表4.2所示。
表4.12 1985~2007年统计数据年份能源消费国民总收入国内生产总值 工业增加值 建筑业增加值 交通运输邮电增加值 人均生活电力消费 能源加工转换效率 yX1 X2 X3 X4 X5 X6 X7 1985 76682 9040.7 9016 3448.7 417.9 406.9 21.3 68.29 1986 80850 10274.4 10275.2 3967 525.7 475.6 23.2 68.32 1987 86632 12050.6 12058.6 4585.8 665.8 544.9 26.4 67.48 1988 92997 15036.8 15042.8 5777.2 810 661 31.2 66.54 1989 96934 17000.9 16992.3 6484 794 786 35.3 66.51 1990 98703 18718.3 18667.8 6858 859.4 1147.5 42.4 67.2 1991 103783 21826.2 21781.5 8087.1 1015.1 1409.7 46.9 65.9 199210917026937.326923.510284.514151681.854.666.001993115993 35260 35333.9 14188 2266.5 2205.6 61.2 67.321994122737 48108.5 48197.9 19480.7 2964.7 2898.3 72.7 65.21995131176 59810.5 60793.7 24950.6 3728.8 3424.1 83.5 71.051996138948 70142.5 71176.6 29447.6 4387.4 4068.5 93.1 71.51997137798 77653.1 78973 32921.4 4621.6 4593 101.8 69.231998132214 83024.3 84402.3 34018.4 4985.8 5178.4 106.6 69.441999133831 88189 89677.1 35861.5 5172.1 5821.8 118.2 69.192000138553 98000.5 99214.6 4003.6 5522.3 7333.4 132.4 69.042001143199 108068.2 109655.2 43580.6 5931.7 8406.1 144.6 69.032002151797 119095.7 120332.7 47431.3 6465.5 9393.4 156.3 69.042003174990 135174 135822.8 54945.5 7490.8 10098.4 173.7 69.42004203227 159586.7 159878.3 65210 8694.3 12147.6 190.2 70.712005223319 183956.1 183084.8 76912.9 10133.8 10526.1 216.7 71.082006 246270 213131.7 211923.5 91310.9 11851.1 12481.1 249.4 71.242007 265583 251483.2 249529.9 107367.2 14014.1 14604.1 274.9 71.25资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。