递归算法 java
用Java语言实现八皇后问题的递归和非递归算法设计

2 0 第 3期 0 7年
计 算 机 与 现 代 化 J U N IY IN A H A I A J U XA D IU S
总第 19期 3
文章编号 :0 62 7 (0 7 0 - 3 -4 10 —45 20 )30 0 01
( O , bet r ne rga mi 是一种 新兴 的程 O P O jc O etdPorm n i g)
序设计方法 , 和一种新 的程序设 计规范( a d m) pr i , ag 其基本 思想 是使 用对 象 、 、 承 、 类 继 封装 、 消息 等基 本 概念来 进行 程序 设 计 。从 现 实 世 界 中客 观 存 在 的事
用 Jv 语 言 实现 八 皇后 问题 的递 归 和 非递 归算 法 设 计 aa
樊 艳 芬 , 琪 云 吴 周 , 帅
( . 西 师 范 大 学 计 算机 信 息 工程 学 院 , 西 南 昌 3 02 2 1江 江 3 02:.渐 江 湖 州 师 范 学 院计 算 机 信 息工 程 学 院 , 江 湖 州 33 0 ; 浙 10 0 3 .上饶 师 范 学 院数 学 与 计 算机 系 , 江西 上 饶 34 0 ) 3 0 1
返 回的 , 这种 技术称 为 回溯 。它 允许 系统地 尝试 某 一 点上 的所有 路 径 , 管有 一 些 尝 试 不 能 产 生 任 何 结 尽 果 。使 用 回溯总 能返 回到某个 点 , 个点 可 以提供 成 这
秀的 面 向对 象 程 序设 计 语 言。“ 向对 象 编程 ” 面
功解 决 问题 的其他 路径 。 回溯被用 于人 工智 能领 域 , 而 且经常 用 它来解 决八 皇后 问题 … 。
1 问题 描 述
斐波那契数列(递归、非递归算法)

斐波那契数列(递归、⾮递归算法)题⽬斐波那契数,亦称之为斐波那契数列(意⼤利语: Successione di Fibonacci),⼜称黄⾦分割数列、费波那西数列、费波拿契数、费⽒数列,指的是这样⼀个数列:1、1、2、3、5、8、13、21、……在数学上,斐波那契数列以如下被以递归的⽅法定义:F0=0,F1=1,Fn=Fn-1+Fn-2(n>=2,n∈N*),⽤⽂字来说,就是斐波那契数列由 0 和 1 开始,之后的斐波那契数列系数就由之前的两数相加。
限制时间限制:1秒空间限制:32768Kpackage com.algorithm;import java.util.Scanner;/*** ⼤家都知道斐波那契数列,现在要求输⼊⼀个整数n,请你输出斐波那契数列的第n项。
n<=39* @⽇期:2018年6⽉30⽇下午10:11:43* @作者:Chendb*/public class Fibonacci {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt();System.out.println(fibonacciRecursion(n));System.out.println(fibonacci(n));}/*** 递归算法* @param n* @return*/public static int fibonacciRecursion(int n) {if (n < 1) {return 0;}if( n == 1 || n == 2) {return 1;}return fibonacciRecursion(n-1) + fibonacciRecursion(n-2);}/*** ⾮递归算法* @param n* @return*/public static int fibonacci(int n) {if (n < 1) {return 0;}if( n == 1 || n == 2) {return 1;}int result = 1;int preResult = 1; // n - 2项int currentResult = 1; // n - 1项for (int i = 3; i <= n; i++) {result = preResult + currentResult; // n = f(n-1) + f(n-2)preResult = currentResult; // f(n-2) = f(n-1)currentResult = result; // f(n-1) = n}return result;}}View Code。
汉诺塔算法

汉诺塔算法汉诺塔算法的递归实现C++源代码#include <fstream>#include <iostream>using namespace std;ofstream fout(“out.txt”);void Move(int n,char x,char y){fout<<“把”<<n<<“号从”<<x<<“挪动到”<<y<<endl;}void Hannoi(int n,char a,char b,char c){if(n==1)Move(1,a,c);else{Hannoi(n-1,a,c,b);Move(n,a,c);Hannoi(n-1,b,a,c);}}int main(){fout<<“以下是7层汉诺塔的解法:”<<endl;Hannoi(7,…a‟,…b‟,…c‟);fout.close();cout<<“输出完毕!”<<endl;return 0;}●汉诺塔算法的递归实现C源代码:#include<stdio.h>void hanoi(int n,char A,char B,char C){if(n==1){printf(“Move disk %d from %c to %c\n”,n,A,C); }else{hanoi(n-1,A,C,B);printf(“Move disk %d from %c to %c\n”,n,A,C); hanoi(n-1,B,A,C);}}main(){int n;printf(“请输入数字n以解决n阶汉诺塔问题:\n”);scanf(“%d”,&n);hanoi(n,…A‟,…B‟,…C‟);}●汉诺塔算法的非递归实现C++源代码#include <iostream>using namespace std;//圆盘的个数最多为64const int MAX = 64;//用来表示每根柱子的信息struct st{int s[MAX]; //柱子上的圆盘存储情况int top; //栈顶,用来最上面的圆盘char name; //柱子的名字,可以是A,B,C中的一个int Top()//取栈顶元素{return s[top];}int Pop()//出栈{return s[top–];}void Push(int x)//入栈{s[++top] = x;}} ;long Pow(int x, int y); //计算x^yvoid Creat(st ta[], int n); //给结构数组设置初值void Hannuota(st ta[], long max); //移动汉诺塔的主要函数int main(void){int n;cin >> n; //输入圆盘的个数st ta[3]; //三根柱子的信息用结构数组存储Creat(ta, n); //给结构数组设置初值long max = Pow(2, n) - 1;//动的次数应等于2^n - 1 Hannuota(ta, max);//移动汉诺塔的主要函数system(“pause”);return 0;}void Creat(st ta[], int n){ta[0].name = …A‟;ta[0].top = n-1;//把所有的圆盘按从大到小的顺序放在柱子A上for (int i=0; i<n; i++)ta[0].s[i] = n - i;//柱子B,C上开始没有没有圆盘ta[1].top = ta[2].top = 0;for (int i=0; i<n; i++)ta[1].s[i] = ta[2].s[i] = 0;//若n为偶数,按顺时针方向依次摆放 A B Cif (n%2 == 0){ta[1].name = …B‟;ta[2].name = …C‟;}else//若n为奇数,按顺时针方向依次摆放 A C B{ta[1].name = …C‟;ta[2].name = …B‟;}}long Pow(int x, int y){long sum = 1;for (int i=0; i<y; i++)sum *= x;return sum;}void Hannuota(st ta[], long max){int k = 0; //累计移动的次数int i = 0;int ch;while (k < max){//按顺时针方向把圆盘1从现在的柱子移动到下一根柱子ch = ta[i%3].Pop();ta[(i+1)%3].Push(ch);cout << ++k << “: “ <<“Move disk “ << ch << ” from “ << ta[i%3].name <<” to “ << ta[(i+1)%3].name << endl;i++;//把另外两根柱子上可以移动的圆盘移动到新的柱子上if (k < max){//把非空柱子上的圆盘移动到空柱子上,当两根柱子都为空时,移动较小的圆盘if (ta[(i+1)%3].Top() == 0 ||ta[(i-1)%3].Top() > 0 &&ta[(i+1)%3].Top() > ta[(i-1)%3].Top()){ch = ta[(i-1)%3].Pop();ta[(i+1)%3].Push(ch);cout << ++k << “: “ << “Move disk “<< ch << ” from “ << ta[(i-1)%3].name<< ” to “ << ta[(i+1)%3].name << endl;}else{ch = ta[(i+1)%3].Pop();ta[(i-1)%3].Push(ch);cout << ++k << “: “ << “Move disk “<< ch << ” from “ << ta[(i+1)%3].name<< ” to “ << ta[(i-1)%3].name << endl;}}}}。
主方法,递归法

主方法,递归法
"主方法" 和 "递归法" 通常在算法和数据结构的课程中提到,尤其是在介绍
排序算法的时候。
在这里,我将对它们进行简要的解释:
1. 主方法(Master Method):这是用于分析某些特定的分治算法(如快
速排序和归并排序)的时间复杂度的方法。
主方法主要基于递归关系的分析,以及对于最坏、平均和最好情况下的时间复杂度估计。
2. 递归法(Recursive Method):这是一种解决问题的方法,其中问题被
分解为更小的子问题,然后这些子问题的解被用来解决原始问题。
递归是许多算法(包括排序算法)的核心思想,因为它允许我们处理大规模数据集,通过将它们分解为更小的部分来简化问题。
在排序算法中,递归通常与分治策略一起使用。
例如,快速排序就是一个使用递归和分治的例子。
快速排序的基本思想是选择一个"主元",然后将数组分为两部分,左边的元素都比主元小,右边的元素都比主元大。
然后对这两部分递归地进行排序。
如果你是在询问编程中的方法或函数,那么"主方法"可能是指某个特定语言或框架的主要入口点,如Java的`public static void main(String[] args)`。
在这种情况下,"递归法"可能是指一种通过反复调用自身来解决问题的编程技术。
希望这能帮到你!如果你有关于这两个概念的具体问题或需要更详细的解释,请告诉我!。
FP-Tree算法详细过程(Java实现)
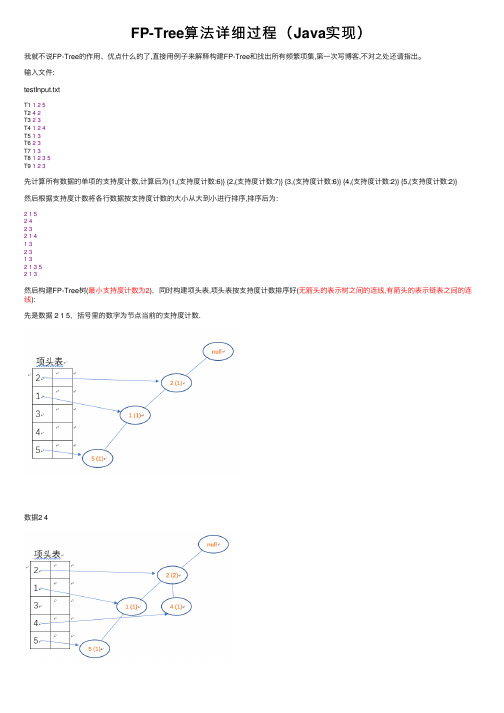
FP-Tree算法详细过程(Java实现)我就不说FP-Tree的作⽤、优点什么的了,直接⽤例⼦来解释构建FP-Tree和找出所有频繁项集,第⼀次写博客,不对之处还请指出。
输⼊⽂件:testInput.txtT1 125T2 42T3 23T4 124T5 13T6 23T7 13T8 1235T9 123先计算所有数据的单项的⽀持度计数,计算后为{1,(⽀持度计数:6)} {2,(⽀持度计数:7)} {3,(⽀持度计数:6)} {4,(⽀持度计数:2)} {5,(⽀持度计数:2)}然后根据⽀持度计数将各⾏数据按⽀持度计数的⼤⼩从⼤到⼩进⾏排序,排序后为:21524232141323132135213然后构建FP-Tree树(最⼩⽀持度计数为2),同时构建项头表,项头表按⽀持度计数排序好(⽆箭头的表⽰树之间的连线,有箭头的表⽰链表之间的连线):先是数据 2 1 5,括号⾥的数字为节点当前的⽀持度计数.数据2 4数据2 3数据 2 1 4数据 1 3数据 2 3数据 1 3数据 2 1 3 5数据 2 1 3构建完成后,从项透表的最后⼀个项5开始,从树周为5的节点向上遍历,找出条件模式基有{2 (1),1 (1)}和{2 (1),1 (1),3 (1)}两个条件模式基,由于3的⽀持度计数⼩于最⼩⽀持度计数,在构建的时候不能加⼊树中,所以构建后的项头表和条件FP-Tree树为:因为其条件FP-Tree为单路径,所以只要找出{2 (2),1 (2)}的所有⼦项集加上后缀{5 (2)}即可,得出3个频繁项集{2(2),1(2),5(2)}、{2(2),5(2)}、{1(2),5(2)}.然后是4,条件模式基为{2(1)}和{2(1),1(1)},1⼩于最⼩⽀持度计数,不参与树的构造,遍历得出频繁项集{2(2),4(2)}然后是3,条件模式基为{2(2),1(2)}、{2(2)}、{1(2)}由于该条件FP-Tree不是单路径,所以应该遍历该项头表,即从1开始,此时后缀为3遍历时,⾸先将项头表的1与其前⼀次后缀连接,得到⼀个频繁项集{1(4),3(4)},⽀持度计数为1在树中出现的总次数,1-频繁项集也是如此得到,因为那时前⼀次后缀为空;然后得到1的条件模式基为{2(2)},因为只有⼀个,所以可以直接遍历其所有⼦项加上此时的后缀13构成⼀个频繁项集{2(2),1(2),3(2)},⽀持度计数为条件模式基的⽀持度计数如果有两个条件模式基,则继续构建树,直到条件模式基为1个或树只有⼀条路径然后是1,条件模式基为{2(4)},遍历后得到{2(4),1(4)}最后是2,⽆条件模式基总结我在写代码的时候难点主要在构建条件FP-Tree然后找频繁项这⾥,我⼀开始并没有⽤构建条件FP-Tree来找频繁项,⽽是通过第⼀次的条件模式基,然后找出各项的所有条件模式基的⼦项,将满⾜⽀持度计数的并不重复的加⼊挑选出来,⽀持度计数需要与某项的所有条件模式基进⾏⽐较,若包含在该条件模式基中,则加上该条件模式基的⽀持度计数.最后贴出我的Java代码(注意:我的代码是针对单项为"1 2 4"、"a v c d"这种单个字符的,若处理的数据为"啤酒开瓶器抹布"需要修改代码):MyFrequentItem.javapublic class MyFrequentItem {//每项中含有的元素private String array;//该项的⽀持度计数private int support;//该项的长度,即第⼏项集private int arrayLength;public MyFrequentItem(String array,int support) {this.array=array;this.support=support;arrayLength=array.length();}public String getArray() {return array;}public void setArray(String array) {this.array = array;}public int getSupport() {return support;}public void setSupport(int support) {this.support = support;}public int getArrayLength() {return arrayLength;}public void setArrayLength(int arrayLength) {this.arrayLength = arrayLength;}}View CodeFP_tree.javaimport java.io.BufferedReader;import java.io.File;import java.io.FileReader;import java.util.ArrayList;import java.util.Arrays;import java.util.Collections;import parator;import java.util.HashMap;/**** @author⽯献衡**/class FP_Node{//树String item;int supportCount;ArrayList<FP_Node> childNode;FP_Node parent;public FP_Node(String item,int supportCount,FP_Node parent) {this.item=item;this.supportCount=supportCount;this.parent = parent;childNode = new ArrayList<FP_Node>();}}class LinkedListNode{//链表,同⼀条链表存储的TP_Node节点的item相同FP_Node node;LinkedListNode next;public LinkedListNode(FP_Node node) {this.node=node;next=null;}}public class FP_tree {//⽂件位置private String filePath;//存储从⽂件中读取的数据private String[][] datas;//Integer代表频繁项集的项数,String表⽰频繁项集各项组成的字符串private HashMap<Integer, HashMap<String,MyFrequentItem>> myFrequentItems;//单项出现的次数,⽤来排序HashMap<String, Integer> signalCount;//最⼩⽀持度计数private int minSupportCount;//最⼩置信度private double minConf;//记录的总条数private int allDataCount;//强规则ArrayList<String> strongRules;//弱规则ArrayList<String> weakRules;private MyFrequentItem frequentItem;;public FP_tree(String filePath,int minSupportCount) {this.minSupportCount = minSupportCount;this.filePath = filePath;strongRules = new ArrayList<String>();weakRules = new ArrayList<String>();myFrequentItems = new HashMap<Integer, HashMap<String,MyFrequentItem>>();//读取数据readFile();}/*** .读取⽂件中的数据储存到datas*/private void readFile() {ArrayList<String[]> list = new ArrayList<String[]>();try {String string;FileReader in = new FileReader(new File(filePath));BufferedReader reader = new BufferedReader(in);while((string=reader.readLine())!=null) {list.add(string.substring(3).split(" "));}allDataCount = list.size();datas = new String[allDataCount][];list.toArray(datas);reader.close();in.close();list.clear();} catch (Exception e) {// TODO: handle exception}}public void startTool(double minConf){this.minConf = minConf;//扫描并且排序scanAndSort();//初始化myFrequentItemsfor(int i=1;i<=signalCount.size();i++) {myFrequentItems.put(i, new HashMap<String, MyFrequentItem>());}HashMap<String, Integer> originList = new HashMap<String, Integer>();//将datas的每条记录转换成⼀条排序好的字符串和它的⽀持度的形式//如记录{2,1,5}转换成215和1,就如条件模式基以及其⽀持度计数String s;for(String[] strs : datas) {s = "";for (String string : strs) {s+=string;}if(originList.containsKey(s))originList.put(s,originList.get(s)+1);elseoriginList.put(s,1);}//构造TP树,同时构造链表以及找出所有频繁项fp_Growth(originList, signalCount, "",Integer.MAX_VALUE);int n = signalCount.size();HashMap<String, MyFrequentItem> map = new HashMap<String, MyFrequentItem>(); String string;//输出各频繁项集的频繁项,包括它们的⽀持度计数for(int i=1;i<=n;i++) {map = myFrequentItems.get(i);System.out.println(i+"-项频繁项集为:");for (MyFrequentItem myFrequentItem : map.values()) {System.out.print("{");string = myFrequentItem.getArray();for(int j=0;j<myFrequentItem.getArrayLength();j++) {System.out.print(string.charAt(j)+",");}System.out.print("(⽀持度计数:"+myFrequentItem.getSupport()+")} ");}System.out.println();}//计算k-频繁项集中各频繁项的置信度int k=3;if(myFrequentItems.get(k).size()!=0) {for (MyFrequentItem frequentItem : myFrequentItems.get(k).values()) {relevance(frequentItem);}}}/*** .计算该最⼤频繁项集与其⼦项集的关联性* @param index 频繁集中的第index个* @param k 项频繁集*/private void relevance(MyFrequentItem myFrequentItem2) {//该项的⽀持度int support = myFrequentItem2.getSupport();//该频繁项的元素拼接成的字符串String nowFrequentString = myFrequentItem2.getArray();//找出所有⼦项集childRelevance(nowFrequentString.toCharArray(), 0, "", "", support);System.out.println();for(String weakRule : weakRules) {System.out.println(weakRule);}for(String strongRule : strongRules) {System.out.println(strongRule);}//输出之后清空weakRules.clear();strongRules.clear();}/*** .找出所有⼦项集* @param child* @param k* @param childString 为⼦项集拼接的字符串* @param otherString除⼦项集以外的拼接的字符串* @param support*/private void childRelevance(char[] child,int k,String childString,String otherString,int support) { if(child.length==k) {//空串和其本⾝不计算if(childString.length()==k||childString.length()==0) return;//计算置信度calculateRelevance(childString, otherString, support);}else {childRelevance(child, k+1, childString, otherString+child[k], support);//该字符不要childRelevance(child, k+1, childString+child[k], otherString, support);//该字符要}}/*** .计算置信度* @param childString* @param otherString* @param support*/private void calculateRelevance(String childString,String otherString,int support) {String rule="";//获取⼦频繁项childString的⽀持度计数int childSupport = myFrequentItems.get(childString.length()).get(childString).getSupport();double conf = (double)support/(double)childSupport;rule+="{";for(int m=0;m<childString.length();m++)rule+=(childString.charAt(m)+",");rule+="}-->{";for(int m=0;m<otherString.length();m++) {rule+=(otherString.charAt(m)+",");}rule+=("},confindence(置信度):"+support+"/"+childSupport+"="+conf);if(conf<minConf) {rule+=("由于此规则置信度未达到最⼩置信度的要求,不是强规则");weakRules.add(rule);}else {rule+=("为强规则");strongRules.add(rule);}}/*** .构建树并找出所有频繁项* @param originList 每条路径和该路径的⽀持度计数* @param originCount originList中每个字符的⽀持度计数* @param suffix 后缀*/private void fp_Growth(HashMap<String, Integer> originList,HashMap<String, Integer>originCount,String suffix,int suffixSupport) {FP_Node root = new FP_Node(null, 0, null);//条件FP-Tree的根节点//表头项ArrayList<LinkedListNode> headListNode = new ArrayList<LinkedListNode>();//构建树,并检查是否为单路径树if(treeGrowth(suffix,root, originList, originCount, headListNode)) {//如果是单路径树,直接进⾏递归出所有⼦频繁项String string = "";while(root.childNode.size()!=0) {root = root.childNode.get(0);string+=root.item;}//递归找出所有频繁项findFrequentItem(0, "", string.toCharArray(), suffixSupport, suffix,originCount);}else {//不是单路径树,从最后⼀个表头项的最后⼀个往上找条件模式基findConditional(headListNode, originCount, suffix);}}private boolean treeGrowth(String suffix,FP_Node root,HashMap<String, Integer> originList,HashMap<String, Integer>originCount,ArrayList<LinkedListNode> headListNode) { //链表的当前节点HashMap<String, LinkedListNode> nowNode = new HashMap<String, LinkedListNode>();//表⽰是否找到该字符所在的节点,有则true,否则false并创⼀个新的节点boolean flag;//⽤来记录树是否为单路径boolean isSingle = true;FP_Node treeHead;LinkedListNode listNode;String[] strings;int support;for (String originString : originList.keySet()) {//获取该条件模式基的⽀持度计数support = originList.get(originString);strings = originString.split("");treeHead = root;for(int i=0;i<strings.length; i++) {//⼩于最⼩⽀持度计数的不加⼊树中if(originCount.get(strings[i])<minSupportCount)continue;flag = false;for(FP_Node node : treeHead.childNode) {if(strings[i].equals(node.item)) {flag = true;node.supportCount+=support;treeHead = node;break;}}if(!flag) {//创建新的树节点,同时创建新的链表节点for(int j=i;j<strings.length;j++) {//⼩于最⼩⽀持度计数的不加⼊树中if(originCount.get(strings[j])<minSupportCount)continue;//创建新的树节点FP_Node node = new FP_Node(strings[j], support,treeHead);if(nowNode.containsKey(strings[j])) {//构建链表listNode = new LinkedListNode(node);nowNode.get(strings[j]).next = listNode;nowNode.put(strings[j], listNode);}else {//构建链表listNode = new LinkedListNode(node);headListNode.add(listNode);nowNode.put(strings[j], listNode);}//构建树treeHead.childNode.add(node);treeHead = node;}break;}}}while(root.childNode.size()!=0) {//判断是否为单路径if(root.childNode.size()==1) {root = root.childNode.get(0);}else {isSingle = false;break;}}if(isSingle) return true;Collections.sort(headListNode,new Comparator<LinkedListNode>() {//将链表的头节点按出现的总次数的降序排列@Overridepublic int compare(LinkedListNode o1, LinkedListNode o2) {int p = originCount.get(o2.node.item)-originCount.get(o1.node.item);if(p==0)//如果⽀持度计数相等,按字典序排序return pareTo(o2.node.item);elsereturn p;}});return isSingle;}/*** .找出各项的条件模式基,从headNode后⾯遍历链表的每个节点,* .从每个节点中node开始向树的上⽅遍历,直到根节点停⽌*/private void findConditional(ArrayList<LinkedListNode> hNode,HashMap<String, Integer> originSupport,String suffix) {//当前链表节点LinkedListNode nowListNode;//当前树节点FP_Node nowTreeNode;//条件模式基HashMap<String, Integer> originList;//所有条件模式基中各个事务出现的次数,⽅便条件FP-Tree在构造的时候剪枝HashMap<String, Integer> originCount;String ori;String item;String suf;for(int i=hNode.size()-1;i>=0;i--) {//获取链表头节点nowListNode = hNode.get(i);item = nowListNode.node.item;suf = item+suffix;//树中的单项⽀持度计数必定⼤于或等于最⼩⽀持度计数(构建树的完成的剪枝),所以将该项加其后缀加⼊频繁项集myFrequentItems.get(suf.length()).put(suf, new MyFrequentItem(suf, originSupport.get(item)));originList = new HashMap<String, Integer>();originCount = new HashMap<String, Integer>();int min;while(nowListNode!=null) {//从链表保存的树节点的⽗节点开始向上遍历nowTreeNode = nowListNode.node.parent;//获取该节点的⽀持度计数min = nowListNode.node.supportCount;//⽤来保存该条件模式基ori = "";while(nowTreeNode!=null&&nowTreeNode.item!=null) {if(originCount.containsKey(nowTreeNode.item)) {//如果条件模式基有如21和2这样两条及以上的有共同元素的,⽀持度计数叠加originCount.put(nowTreeNode.item, originCount.get(nowTreeNode.item)+min);}else {originCount.put(nowTreeNode.item, min);}//保存条件模式基,按树的上⾯向下的顺序保存ori=nowTreeNode.item+ori;nowTreeNode = nowTreeNode.parent;}if(ori!="")originList.put(ori, min);nowListNode = nowListNode.next;}if(originList.size()!=0) {//条件模式基不为空if(originList.size()==1) {//只有⼀条,直接递归其所有⼦项集for (String modeBasis : originList.keySet()) {findFrequentItem(0, "", modeBasis.toCharArray(), originList.get(modeBasis), suf,null);}}else {//构建条件FP-Treefp_Growth(originList, originCount,suf,originSupport.get(item));}}}}/**** @param j 当前指向的modeBasis中的位置* @param child 当前⼦项* @param modeBasis 条件模式基中各个字符或单路径树各个节点组成的字符串* @param support 该⼦项的所有单项中最⼩的⽀持度计数* @param suffix 后缀,⼦项加上后缀即为新的频繁项* @param originCount 单路径树各个节点的⽀持度计数*/private void findFrequentItem(int j,String child,char[] modeBasis,int support,String suffix,HashMap<String, Integer> originCount) { if(j==modeBasis.length) {if(child.length()!=0) {//⼦项不为空child=child+suffix;frequentItem = new MyFrequentItem(child, support);myFrequentItems.get(child.length()).put(child, frequentItem);}}else {int p = support;//originCount为null时,代表为条件模式基,条件模式基中各项⽀持度计数相等if(originCount!=null)p =originCount.get(String.valueOf(modeBasis[j]));findFrequentItem(j+1, child+modeBasis[j], modeBasis,support<p?support:p,suffix,originCount);//要该字符findFrequentItem(j+1, child, modeBasis,support,suffix,originCount);//不要该字符}}/*** .扫描两遍数据,第⼀遍得出各个事物出现的总次数* .第⼆遍将每条记录中的事务根据出现的总次数进⾏排序*/private void scanAndSort() {//储存单项的总次数signalCount = new HashMap<String, Integer>();String c;for (String[] string : datas) {//第⼀遍扫描,储存每个字符出现的次数for(int i=0;i<string.length;i++) {c = string[i];if(signalCount.containsKey(c)) {signalCount.put(c, signalCount.get(c)+1);}else {signalCount.put(c, 1);}}}for (String[] string : datas) {//第⼆遍扫描,按每个字符出现的总次数的降序进⾏排序Arrays.sort(string,new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {int p = signalCount.get(o2)-signalCount.get(o1);if(p==0)//如果出现的次数相等,按字典序排序return pareTo(o2);elsereturn p;}});}}}View CodeMyClient.javapublic class MyClient {public static void main(String[] args) {String filePath = "src/apriori/testInput.txt";FP_tree tp_tree = new FP_tree(filePath, 2);tp_tree.startTool(0.7);}}View Code输出:1-项频繁项集为:{1,(⽀持度计数:6)} {2,(⽀持度计数:7)} {3,(⽀持度计数:6)} {4,(⽀持度计数:2)} {5,(⽀持度计数:2)}2-项频繁项集为:{2,3,(⽀持度计数:4)} {2,4,(⽀持度计数:2)} {1,3,(⽀持度计数:4)} {2,5,(⽀持度计数:2)} {1,5,(⽀持度计数:2)} {2,1,(⽀持度计数:4)} 3-项频繁项集为:{2,1,3,(⽀持度计数:2)} {2,1,5,(⽀持度计数:2)}4-项频繁项集为:5-项频繁项集为:{3,}-->{2,1,},confindence(置信度):2/6=0.3333333333333333由于此规则置信度未达到最⼩置信度的要求,不是强规则{1,}-->{2,3,},confindence(置信度):2/6=0.3333333333333333由于此规则置信度未达到最⼩置信度的要求,不是强规则{1,3,}-->{2,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,}-->{1,3,},confindence(置信度):2/7=0.2857142857142857由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,3,}-->{1,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,1,}-->{3,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{1,}-->{2,5,},confindence(置信度):2/6=0.3333333333333333由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,}-->{1,5,},confindence(置信度):2/7=0.2857142857142857由于此规则置信度未达到最⼩置信度的要求,不是强规则{2,1,}-->{5,},confindence(置信度):2/4=0.5由于此规则置信度未达到最⼩置信度的要求,不是强规则{5,}-->{2,1,},confindence(置信度):2/2=1.0为强规则{1,5,}-->{2,},confindence(置信度):2/2=1.0为强规则{2,5,}-->{1,},confindence(置信度):2/2=1.0为强规则若有不⾜之处,还请指出.。
java rete算法

java rete算法Java RETE算法是一种基于规则的专家系统推理引擎,它是用于构建和管理规则的数据结构和算法。
RETE是一种非常高效的算法,它能够快速处理大规模的规则集合,并在规则条件满足时触发相应的动作。
RETE算法的核心思想是将规则表示为规则网络,其中每个节点表示一个规则条件。
规则条件之间的连接表示规则之间的依赖关系。
当一个规则条件满足时,它的下一个节点就会被激活。
这种递归的激活过程使得RETE算法能够高效地匹配规则条件,并触发相应的动作。
RETE算法的关键步骤包括规则网络的构建和规则匹配过程。
在规则网络的构建过程中,首先需要将规则条件转换为网络节点,并建立节点之间的连接。
当规则被添加或删除时,需要相应地更新规则网络。
规则匹配过程中,首先需要将待推理的事实与规则网络进行匹配,找到所有满足条件的规则。
然后,根据规则的优先级和动作的执行顺序,触发相应的动作。
RETE算法的优势在于它能够高效地处理大规模的规则集合。
由于规则条件之间的连接关系,RETE算法能够减少不必要的规则匹配次数,从而提高推理的效率。
此外,RETE算法还支持规则的动态添加和删除,使得系统能够根据需求灵活地调整规则集合。
在使用RETE算法构建专家系统时,需要遵循一些设计原则。
首先,需要将规则分解为简单的规则条件,以减少规则匹配的复杂度。
其次,需要根据规则条件的特点设计合适的节点类型和连接方式,以提高规则匹配的效率。
此外,还需要考虑规则的优先级和动作的执行顺序,以确保系统的推理结果正确和一致。
除了在专家系统中的应用,RETE算法还可以应用于其他领域,如数据挖掘、模式识别等。
在数据挖掘中,RETE算法可以用于发现数据中的规律和模式。
在模式识别中,RETE算法可以用于匹配和识别模式。
Java RETE算法是一种高效的规则推理引擎,它能够快速处理大规模的规则集合,并在规则条件满足时触发相应的动作。
使用RETE算法可以构建强大的专家系统,帮助人们解决各种复杂的问题。
java实现fp-growth算法
java实现fp-growth算法本⽂參考韩家炜《数据挖掘-概念与技术》⼀书第六章,前提条件要理解 apriori算法。
另外⼀篇写得较好的⽂章在此推荐:0.实验数据集:user2items.csvI1,I2,I5I2,I4I2,I3I1,I2,I4I1,I3I2,I3I1,I3I1,I2,I3,I5I1,I2,I31.算法原理构造FPTree1、⾸先读取数据库中全部种类的项和这些项的⽀持度计数。
存⼊到itTotal链表中。
2、将itTotal链表依照⽀持度计数从⼤到⼩排序3、将itTotal链表插⼊到ItemTb表中4、第⼆便读取数据库中的事务,将事务中的项依照⽀持度计数由⼤到⼩的顺序插⼊到树中。
5、遍历树,将属于同⼀项的结点通过bnode指针连接起来。
本程序中,FP-tree中存储了全部的项集,没有考虑最⼩⽀持度。
仅仅是在FP-growth中挖掘频繁项集时考虑最⼩⽀持度/**** @param records 构建树的记录,如I1,I2,I3* @param header 韩书中介绍的表头* @return 返回构建好的树*/public TreeNode2 builderFpTree(LinkedList<LinkedList<String>> records,List<TreeNode2> header){TreeNode2 root;if(records.size()<=0){return null;}root=new TreeNode2();for(LinkedList<String> items:records){itemsort(items,header);addNode(root,items,header);}String dd="dd";String test=dd;return root;}//当已经有分枝存在的时候,推断新来的节点是否属于该分枝的某个节点。
算法基础(1)之递归、时间空间复杂度
算法基础(1)之递归、时间空间复杂度参考⽬录:我的笔记:递归(recursion)递归是⼀种很常见的计算编程⽅法,现在通过阶乘案例来学习递归demo1:function factorial(num) {if(num === 1) return num;return num * factorial(num - 1); // 递归求n的阶乘,会递归n次,每次递归内部计算时间是常数,需要保存n个调⽤记录,复杂度 O(n)}const view = factorial(100);console.time(1);console.log(view); // 1: 3.568msconsole.timeEnd(1);递归可能会造成栈溢出,在程序执⾏中,函数通过栈(stack——后进先出)这种数据实现的,每当进⼊⼀个函数调⽤,栈就会增加⼀层栈帧,每次函数返回,栈就会减少⼀层栈帧。
由于栈的⼤⼩不是⽆限的,所以,递归调⽤的次数过多,就会导致栈溢出(stack overflow)。
demo2:尾递归// 如果改为尾递归,只需要保留⼀个调⽤记录,复杂度为O(1)function factorial01(n, tntal) {if(n === 1) return tntalreturn factorial(n - 1, n * tntal) // 把每⼀步的乘积传⼊到递归函数中,每次仅返回递归函数本⾝,total在函数调⽤前就会被计算,不会影响函数调⽤}console.time(2)console.log(factorial01(5, 1)) // 120console.timeEnd(2) // 2: 0.14404296875ms栈帧每⼀个栈帧对应着⼀个未运⾏完的函数,栈帧中保存了该函数的返回地址和局部变量。
栈帧也叫过程活动记录,是编译器⽤来实现过程/函数调⽤的⼀种数据结构。
从逻辑上讲,栈帧就是⼀个函数执⾏的环境:函数参数、函数的局部变量、函数执⾏完后返回到哪⾥等。
java 结束递归的方法
java 结束递归的方法
在Java中,结束递归的方法通常有两种方式,一种是通过设定递归的终止条件,另一种是使用尾递归优化。
首先,设定递归的终止条件是最常见的方式。
在递归函数中,我们可以通过判断输入参数的值或者其他条件来确定是否需要终止递归。
一旦满足了终止条件,递归就会停止,从而避免无限循环。
例如,如果我们要实现一个递归函数来计算阶乘,我们可以设定当输入参数为1时,递归停止并返回1,这样就能有效地结束递归。
其次,Java并不直接支持尾递归优化,但我们可以手动进行优化。
尾递归是指递归函数在最后一步调用自身,并且不做任何额外操作,这种情况下可以进行优化,避免不必要的递归调用。
我们可以将递归函数的中间结果作为参数传递给下一次递归调用,或者使用循环来替代递归,从而避免递归调用栈的过深,提高性能并避免栈溢出的风险。
总的来说,结束递归的方法在Java中主要是通过设定递归的终止条件和进行尾递归优化来实现的。
这两种方法都能有效地结束递
归,并且在实际编程中都有各自的应用场景。
希望这些信息能够帮助到你。
算法设计与分析考试代码第一章(郑州大学软件学院)
1//郑州大学软件学院算法设计与分析第一章考试代码2//授课老师:王志华34//1. Ackerman函数的递归实现算法。
56import java.util.Scanner;7public class Ackerman {8public static int ack(int n,int m)9{10if(n==1&&m==0) return2;11if(n==0&&m>=0) return1;12if(n>=2&&m==0) return n+2;13return ack(ack(n-1,m),m-1);14}1516public static void main(String [] args)17{18Scanner in = new Scanner(System.in);19int n = in.nextInt();20int m = in.nextInt();21System.out.print(ack(n,m));22}2324}2526//2.全排列的递归实现算法。
2728import java.util.Scanner;29public class allsort {30public static void swap(char a [],int x,int y) 31{32char z=a[x];33a[x]=a[y];34a[y]=z;35}36public static void perm(char a [],int n,int k) 37{38if(n==k)39{40for(int i=0;i<n;i++)41System.out.print(a[i]);42}43else44for(int i=k;i<n;i++)45{46swap(a,i,k);47perm(a,n,k+1);48swap(a,i,k);49}50}5152public static void main(String [] args)53{54Scanner in = new Scanner(System.in);55int x=in.nextInt();56char aaa[] = new char [x];57for(int i=0;i<x;i++)58{59String a = in.next();60char [] aa = a.toCharArray();61aaa[i]=aa[0];62}63perm(aaa,x,0);64}6566}676869//3.整数划分的递归实现算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
递归算法 java
一、递归算法的概念
递归算法是指在解决问题时,调用自身函数来解决子问题的方法。
递归算法通常包含两个部分:基本情况和递归情况。
基本情况是指问题可以直接解决,而不需要再次调用函数;递归情况则是指问题需要进一步拆分为子问题,并通过调用自身函数来解决。
二、递归算法的优点和缺点
优点:
1. 代码简洁易懂:递归算法通常使用较少的代码就能完成任务,并且代码结构清晰易懂。
2. 解题思路清晰:使用递归算法可以将复杂的问题分解为简单的子问题,从而更容易理解和解决。
缺点:
1. 性能较差:由于递归算法需要频繁地调用自身函数,因此会占用大
量的栈空间,导致程序运行速度变慢。
2. 可能会导致栈溢出:如果递归深度过大,可能会导致栈空间不足而导致程序崩溃。
三、Java中实现递归算法的方式
Java中实现递归算法有两种方式:方法递归和尾递归。
方法递归是指在调用自身函数时,没有任何其他语句需要执行;尾递归则是指在调用自身函数时,最后一步操作是调用自身函数。
1. 方法递归
方法递归通常包含两个部分:基本情况和递归情况。
基本情况是指问题可以直接解决,而不需要再次调用函数;递归情况则是指问题需要进一步拆分为子问题,并通过调用自身函数来解决。
例如,下面的代码演示了如何使用方法递归来计算阶乘:
```
public static int factorial(int n) {
if (n == 0) { // 基本情况
return 1;
} else { // 递归情况
return n * factorial(n - 1);
}
}
```
2. 尾递归
尾递归通常包含两个部分:基本情况和尾调用。
基本情况是指问题可以直接解决,而不需要再次调用函数;尾调用则是指最后一步操作是调用自身函数。
例如,下面的代码演示了如何使用尾递归来计算阶乘:
```
public static int factorial(int n, int acc) {
if (n == 0) { // 基本情况
return acc;
} else { // 尾调用
return factorial(n - 1, acc * n);
}
}
```
四、递归算法的应用场景
递归算法在许多问题中都有广泛的应用,例如:
1. 排序算法:快速排序和归并排序等排序算法都使用了递归算法。
2. 树形结构:二叉树、多叉树等树形结构通常使用递归算法来遍历节
点或搜索数据。
3. 图形结构:深度优先搜索和广度优先搜索等图形算法也使用了递归
算法。
4. 组合问题:排列组合、背包问题等组合问题也可以使用递归算法来
解决。
五、总结
递归算法是一种简洁易懂,解题思路清晰的方法,但同时也存在性能
较差和可能会导致栈溢出的缺点。
在Java中实现递归算法有两种方式:方法递归和尾递归。
适当地使用递归算法可以有效地解决许多复杂的
问题。