关系数据库中XML全文检索系统的研究与实现
一种基于词与简单路径XML索引系统的设计

摘要信息来建立索 引。文献 。 。中的 Lr 索引通过采用两个 oe 附加 的索 引结 构 Bne idx和 Ln e i x向前 向后遍历来 解决 D t d a -
auds中的一些 问题 。L r 索引 由四个 索引结构 组成 ,它 gie oe 们 是值索引 ( i e )用 于查 找满 足查询 条件 的所 有原 子 Vn x d 对象 ;标 签索引 ( idx Ln e)用 于查找 已知 结点 的父 亲结点 ; 边索引 ( idx Bn e )用于查找 由一标 签 连接起 来 的父 子结 点 对 ;路径索引 ( idx 可 以根 据路 径 找到所 有该 路径 可 Pne )
树 , 】 看哪些结点符合 检索 要求 , 使查 询效率低下。 致
近年来 ,为了 解 决 这 个 问 题 ,利 用 索 引 技 术 来 优 化
X ML的查询口 ,取得了一定的进展 ,一些 索引技术 相继被 】
提出 ,例 如 D t u e[ ,T i ee [ ,L r 引E ] 。 aa i s8 - n xs9 oe索 gd ] d ] l等 0 文献随 中的 D t uds 一种从 根结 点为 起始 的精 练路径 a gie 是 a 结构摘要 。路径 中边 的标签 串联在一 起形成 的字 符 串路 径
维普资讯
中 国人 民公 安 大学 学报 (自然科 学版 )
2 0 第 2期 N . 00 Junl f hns ep ’ P bi S cryU i ri ( cec n eh o g) 望 0 6年 o22( ora o ieeP olS ul e u t n es SineadTc nl y C e c i v t y o 塑 墨
据允许指定不 同 的显示方 式 ,使得 它可 以方便 地 与 WWW 技术相结合 ,可 以在 It t n me 网上广泛地应用 。 e
万方数据知识服务平台介绍

多语种分析——中、外文文献统计
建立不同知识组织体系的映射——建立中图分类法、学科专业分类、专 利IPC分类之间的映射,支持不同文献类型的混合统计分析
用户权限
机构用户
机构用户首次试用,开通3个 月免费试用期
个人用户
个人用户注册后可免费试用5次, 认证后可免费试用15次
用户权限
利用万方分析,
亮
点
坚实的资源基础
多类型、多语种、可持续
资
源
新平台在原有基础上增加了4千万 余条中文期刊论文元数据、150万
条中文学位论文元数据以及230万
条会议论文元数据;同时新增了万 方自有视频资源和来自25个合作数 据库的元数据资源。截至2018年1 月,新平台共有约2.1亿条论文元 数据与2.4亿条引文数据,旧平台 目前共有约1.5亿条论文元数据与 2.4亿条引文数据
文献管理
文献管理
在万方智搜进行收藏、购买、添加标 签等操作,即可将文献同步至万方书 案 万方书案默认将文献按不同操作分为 “我的收藏”、“我的标签”、“我
的笔记”、“我的购买”等
此外,用户还可以对全部文献进行自 定义分类
在线阅读
在线阅读
对于添加至万方书案的文献,个人付费购 买后可永久免费在线阅读 提供高亮、创建笔记、文内搜索、添加标 签功能,还可一键下载、导出或分享文献
Hadoop
SolrCloud
提供开放接口服务,支持用户二 次开发
机构中心
机构管理员中心
管理机构账户 开设漫游账号 查看使用统计 账号到期/余额预警
catalogue
五
万方分析 WFStats
——学科发展与学术影响统计分析
万方数据知识服务平台使用方法

3.检索方式
3.1学科分类导航:选择单个检索库(学术期刊、学位论文、会议论文)进入单库
学科导航界面。 (1)学术期刊导航界面:根据学科分类显示该分类下的刊名列表
(2)学位论文导航界面
根据学科、专业目录提供该分类下的学位Байду номын сангаас文全文链接。
(3)会议论文导航界面
提供学科分类下的会议名录列表
3.2主题检索
3.2.3专业检索
适用于熟练掌握CQL检索技术的专业检索人员使用。 注意可供检索字段和可排序字段提示。
3.3机构导航(1)学位论可根据学校所在地提供高校导航(2)会议论文可根据主办单位级别和类型提供机构名录导航
3.4整刊检索
刊物检索 a.刊物快速查找
刊物检索
c.地区导航检索
4.检索结果优化
二次 检索
步骤四:浏览检索结果,查看并下载文献全文。
9.2如何快速查找相关文献? 通过主题词热链接(在摘要中以蓝色字体显示)、参考文献、相似文献、 引证文献、相关检索词、相关专家和相关机构均可直接链接和扩展到与 本篇文献相同或相近的文献记录。
热链
9.3如何阅读整本期刊? a.刊名检索 从主页选择“学术期刊”库进入期刊论文检索界面;点击按钮实现左侧 检索区“期刊论文检索”与“期刊检索”之间的变换;
6.文献查看与下载 点击文章题名,可查看详细摘要信息、引文链接、文献扩展链接; 点击“查看全文”可直接打开PDF全文在线浏览和内容编辑; 点击图标可直接下载PDF格式全文;
下载 全文
详细 信息
进入期刊列表
7.知识网络引文分析
可实现引文分析和文献扩展链接。通过梳理分析文献之间、知识单元之 间的关系,构成系统的知识网络,以有效发掘和利用资源,扩展知识层 面,实现知识更新和工作创新。
TRSD全文数据库系统

元数据(meta-data)和全文(full-text)的联合查询。 实时动态索引:数据增删改时快速同步更新索引,无需重建整个索引,也无需局部重建
索引。即数据增删改后立即能够被检索。 自动分库(Partitioning):充分利用多库并行检索技术,进一步提高了检索速度;使得
支持精确检索,准确报告检索记录数;支持估算检索,快速返回部分结果,并
对结果集进行估算;同时支持对结果进行补充检索与重新估算。
支持短语级别(INCLUDE 函数)和词级别(LIKE 函数)的“相似性”检索,
INCLUDE 函数支持 CHAR 字段的运算。
TOP N 剪裁排序时,LIKE 和 INCLUDE 函数具有“匹配度自适应调节”功能,
请求的独立的“超时”设置,允许检索被“中断”后返回已经得到的结果。
支持基于 BIT 字段的虚拟逻辑字段的检索,并支持其实体字段之间的逻辑关系
与排序加权。
实现 “同字段”的限定运算,支持复杂条件下的检索需求。
4
TRS 全文数据库系统 软件产品说明书(SPD)
安 系统提供多种权限级别的用户管理。具有系统级、数据库级、记录级和字段级
处
客户端支持以下三种字符集:GB18030 编码,BIG5 编码,UTF8 编码;开发接 口支持 UCS2/UTF16。方便了多语言检索应用程序的开发。
理 内嵌汉语分词:统计建立了大量歧义排除规则,有效提高了分词准确性,同时
与
在不确定情况下采取冗余切分,极大地提高了查全率和查准率。
智 除汉语外,还支持藏文(含扩展集 A 和 B)、蒙文、维文、彝文等少数民族语
搜索引擎技术分析
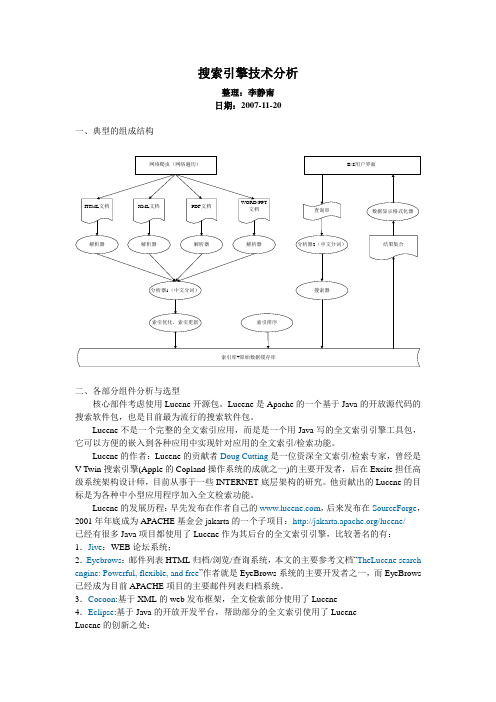
搜索引擎技术分析整理:李静南日期:2007-11-20一、典型的组成结构二、各部分组件分析与选型核心部件考虑使用Lucene开源包。
Lucene是Apache的一个基于Java的开放源代码的搜索软件包,也是目前最为流行的搜索软件包。
Lucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。
Lucene的作者:Lucene的贡献者Doug Cutting是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些INTERNET底层架构的研究。
他贡献出的Lucene的目标是为各种中小型应用程序加入全文检索功能。
Lucene的发展历程:早先发布在作者自己的,后来发布在SourceForge,2001年年底成为APACHE基金会jakarta的一个子项目:/lucene/已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有:1.Jive:WEB论坛系统;2.Eyebrows:邮件列表HTML归档/浏览/查询系统,本文的主要参考文档“TheLucene search engine: Powerful, flexible, and free”作者就是EyeBrows系统的主要开发者之一,而EyeBrows 已经成为目前APACHE项目的主要邮件列表归档系统。
3.Cocoon:基于XML的web发布框架,全文检索部分使用了Lucene4.Eclipse:基于Java的开放开发平台,帮助部分的全文索引使用了LuceneLucene的创新之处:大部分的搜索(数据库)引擎都是用B树结构来维护索引,索引的更新会导致大量的IO操作,Lucene在实现中,对此稍微有所改进:不是维护一个索引文件,而是在扩展索引的时候不断创建新的索引文件,然后定期的把这些新的小索引文件合并到原先的大索引中(针对不同的更新策略,批次的大小可以调整),这样在不影响检索的效率的前提下,提高了索引的效率。
常用的检索语言

常用的检索语言
常用的检索语言包括SQL(Structured Query Language)和XPath(XML Path Language)。
SQL是一种用于管理和操作关系型数据库的语言。
它可以用于创建数据库表、插入、更新和删除数据,以及执行查询操作。
通过使用SQL,用户可以使用简单的语句从数据库中检索信息,并根据特定的条件对数据进行过滤和排序。
XPath是一种用于在XML文档中定位和选择节点的语言。
XML是一种标记语言,用于存储和表示数据。
XPath允许用户使用路径表达式来选择文档中的特定节点或一组节点。
这些路径表达式可以根据节点的名称、属性、位置和关系等进行定义,以便准确地定位所需的节点。
总的来说,SQL用于管理和操作关系型数据库,而XPath用于在XML 文档中定位和选择节点。
两者都是常用的检索语言,用于从数据源中获取所需的信息。
智能检索及跨库检索技术在数据库建设中的运用
技术推广智能检索及跨库检索技术在数据库建设中的运用王琳(柳州铁道职业技术学院,广西柳州545616)摘要:本文分别对智能检索技术和跨库检索技术在数据库建设当中的应用进行了分析,并将其与传统的数据检索库建设以及相关技术结合阐述,希望能够为有关行业未来的优化和数据库建设提供参考&关键词:智能检索;跨库检索;数据库建设1智能检索技术在数据库建设当中的运用1.1传统关系数据检索技术随着我国计算机水平提升以及211工程落实,高校图书馆掀起了一股自动化检索的热潮口+。
随着这种环境的推动,几乎各大高校都进购了自动化检索系统。
但此类系统普遍涉及底层数据库结构,即传统关系型数据库。
常见的自动化软件主要有国外的IN-NOPAC升级版Lilllenium以及国内的MELINETS 等。
分析一个图书馆自动化软件的价值,主要可以从以下几个方面入手,即底层数据库、系统结构、语言处理、检索和机制等。
12智检索全文检索数据库是专业处理各类海量信息的数据库管理系统。
它的工作原理是以代码形式对资料内容进行储存,并与计算机结合进行后续的检索查询和信息处理工作。
自改革开放以来,投入市场中运行的数据库产品逐年增加,但占据市场份额超过90%的凤毛麟角,大部分产品是关系型和对象关系型。
与传统的数据库相比较而言,此种数据库不需要工作人员进行大量的标引工作,而是可以根据用户输入的关键词展开多角度的检索,因此被称为智能检索。
1.3智能检索机制与关系数据库相比,非结构化数据库检索机制的优势在于灵活性高。
简单讲就是关系数据库能够实现的简单、字段以及组合等检索形式,非结构化的数据库也能够实现。
不仅如此,非结构化的数据库还能实现中英文混合检索、全文检索等高级检索方式,更倾向专业检索软件发展。
当下经常使用的有词索引和字索引2大类,从字面意思理解就是一类以词为单位做原始数据进行索引,另一类是以字为原始数据展开索引。
2类索引方式优势不同,词索引的优势在于作者简介:王琳(1983-),男,本科,高级工程师,研究方向:计算机技术应用。
TRS全文数据库介绍
• • •
结构化数据:SQL查询 非结构化数据:全文检索和搜索引擎 但用户的数据在很多情况下是结构化数据+非结 构化数据+半结构化数据
SEARCH
Search Application Services
Core Indexing Server
Content Capture & Index
DATABASE
26获得国家科技进步二等奖,电子工业部科技进步一等 奖 • 2001年国家推荐的12个优秀软件产品之一 • 拥有UNDP援建的中文信息处理研究中心
– 和国内外多所大学、研究机构建立了长期合作研 究关系
• 清华大学(中文智能语言处理) • 香港中文大学(信息检索)
“TRS has the best technology in Chinese Text Retrieval area in China. It is one of the strongest software development firms in China.” -Dr. Kaifu Li, VP of Microsoft, and formerly Managing Director of Microsoft Research Institute.
– 企业搜索软件第一名 – 主要竞争对手均为国 际知名厂商
Autonomy 8.5% IBM 8.8% 微软 10.4%
Oracle 7.6%
其他 30.8%
2007年中国企业搜索产品 市场主力厂商份额结构
TRS 33.9%
深厚的科研基础和积累
• 拥有自主核心技术和知识产权,研发力量强大
– 在信息检索、知识挖掘和中文信息处理方面具有 国内外领先的研究能力和研究成果
数据库系统的工作流程
数据库系统的工作流程概述数据库系统是计算机科学领域中非常重要的一个应用,它用于存储和管理大量结构化数据。
数据库系统的工作流程包括数据的获取、存储、处理和检索等多个环节。
本文将深入探讨数据库系统的工作流程,介绍每个环节的具体内容和技术。
数据获取数据获取是数据库系统的第一步,它涉及到从不同来源获取数据并导入数据库中。
数据获取的方式有很多种,常见的包括:1.手动输入数据:用户可以通过命令行界面或者图形界面手动输入数据并导入到数据库中。
2.从文件中导入数据:用户可以将数据存储在文件中,然后通过数据库系统提供的导入功能将数据从文件中导入数据库。
3.通过网络爬虫收集数据:用户可以利用网络爬虫程序自动从互联网中收集数据,并将收集到的数据导入数据库。
数据存储数据存储是数据库系统的核心功能之一,它负责将数据保存在持久化存储介质中,以便长期保存和管理。
常见的数据存储方式有以下几种:1.关系数据库:关系数据库是使用表格来组织数据的一种数据库管理系统。
它采用了关系模型,通过建立表格和表格之间的关联关系来存储数据。
2.NoSQL数据库:NoSQL数据库是一种非关系型数据库,它不使用表格来组织数据。
NoSQL数据库可以存储半结构化数据和非结构化数据,适用于存储大数据和实时处理等场景。
3.文件系统:文件系统是一种简单的数据存储方式,它将数据以文件的形式保存在磁盘上。
文件系统适合存储小规模数据和非结构化数据。
数据处理数据处理是数据库系统的另一个重要环节,它负责对存储在数据库中的数据进行各种计算、查询和分析操作。
常见的数据处理操作包括:1.数据插入:数据插入是将新的数据添加到数据库中的操作,用户可以通过INSERT语句将数据插入到数据库的表中。
2.数据更新:数据更新是对数据库中已有的数据进行修改的操作,用户可以通过UPDATE语句更新表中的某条数据。
3.数据删除:数据删除是将数据库中已有的数据删除的操作,用户可以通过DELETE语句删除表中的某条数据。
万方数据知识服务平台介绍
数字图书馆事业部
catalogue
二 万方智搜 WFDiscover
聪明的学术资源发现服务
定位
万方智搜——学术资源发现服务
以大数据环境下的知识发现技术为基础,对原有检索系统进行全新升级;通过发现服 务汇聚海量中外文二次文献资源
利用知识组织体系建设成果,提供词表检索、跨语言检索、用户场景感知与精准推送、 知识脉络可视化等智能化服务
各功能系统相对独立、可适应不 同定制要求
提供开放接口服务,支持用户二 次开发
机构中心
机构管理员中心
✓管理机构账户 ✓开设漫游账号 ✓查看使用统计 ✓账号到期/余额预警
catalogue
| 2018-3-3
五 万方分析 WFStats
——学科发展与学术影响统计分析
拓展学术关系
✓ 用户对感兴趣的学者添加关 注后,就可追踪该学者的学 术动态, 了解最新的研究动 向,还可以将学术主页分享 到各类社交软件
✓ 学术圈首页系统会推荐感兴 趣的学者和文献。用户也可 以通过分享学术成果/文辑/ 主页,增加学术影响力
成果书
定制成果汇编
个人成果汇编是万方学术圈 提供给认证用户免费下载个 人成果的权益,用户可以将 已认领的有全文的成果汇编 成成果书,成果书可以免费 下载
万方学术圈——学者交流分享之窗
万方学术圈是对原有学术圈进行全新升级,是基于优质学术内容的轻社交平台
提供学术文献分享、科研档案展示、学者动态追踪、学者成果管理、个人成果汇 编等功能,为学术社交提供新的渠道
通过学术圈的用户数据,构建内容、服务、关系的闭环学术生态网络,实现深度 知识服务
学术主页
发现
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
关系数据库中XML全文检索系统的研究与实现
随着现代信息技术的不断发展,XML已经成为了一种重要的数据交换和存储格式,大量的应用程序都使用XML进行数据的存储和处理。
然而,XML文档通常具有复杂的结构和数据类型,这给全文检索带来了很大的挑战,传统的全文检索技术并不能很好地处理XML文档。
在这样的背景下,XML全文检索系统研究与实现变得异常重要。
本文将探讨关系数据库中XML全文检索系统的研究与实现。
首先,我们需要了解XML全文检索的基本原理。
和传统的全文检索一样,XML全文检索也是通过建立索引来实现的。
不同的是,XML全文检索需要考虑XML文档的结构和属性,将文档的标签、属性和内容都建立索引。
这就需要全文检索系统具有强大的分析、解析和索引建立能力。
关系数据库中XML全文检索系统需要解决的几个难点如下:
1. 如何解析XML文档
XML文档具有复杂的结构和内容,需要使用专业的XML解析器将其解析为数据结构,以便于建立索引。
常用的XML解析器有:SAX、DOM、STAX等。
2. 如何建立索引
XML文档的索引建立需要考虑到文档的标签、属性和内容,建立多个不同的索引表,以提高检索的效率。
索引的建立需要
接合全文检索和信息检索技术,具有一定的难度和复杂度。
3. 如何维护索引表
索引表的维护需要考虑到索引的插入、删除和更新操作。
当XML文档发生变化时,需要对索引表进行相应的更新,以保证检索结果的准确性。
4. 如何实现查询
关系数据库中XML全文检索系统需要提供多种查询方式,如全文检索、精确匹配、模糊匹配等。
此外,还需要支持针对文档的标签、属性和内容进行查询,以实现更加精确的检索。
综上所述,关系数据库中XML全文检索系统的研究与实现具有一定的难度和挑战,需要综合运用全文检索、信息检索和XML技术,以实现系统的高效、准确和可靠。