大数据中的语义识别(DOC)
非结构化数据分析与处理技术研究

非结构化数据分析与处理技术研究近年来,随着互联网和电子技术的飞速发展,数据已经成为了企业经营和科学研究的重要资源,其价值不断提高。
数据分析已经成为了企业决策和科学研究的重要手段。
然而,大数据时代的来临,使得数据的性质和规模都发生了很大的变化。
非结构化数据的分析和处理技术成为当前数据处理和分析的重要研究方向。
1. 非结构化数据的概念及类型非结构化数据指的是没有固定格式的数据,例如文本、图片、音频、视频等,因此非结构化数据难以用传统的关系型数据库进行存储和处理。
非结构化数据来源广泛,包括社交媒体、在线新闻、博客文章、视频和音频等。
2. 非结构化数据分析技术研究非结构化数据分析技术研究可以分为两个方向:文本分析和图像分析。
(1)文本分析文本分析技术是将非结构化文本数据中蕴含的信息进行自动提取、索引和语义理解的技术。
文本分析技术主要包括文本分类、文本聚类、情感分析、命名实体识别和知识图谱构建等。
(2)图像分析图像分析技术是将非结构化图像数据中蕴含的信息进行自动识别、分类和理解的技术。
图像分析技术主要包括图像分类、目标检测、图像分割、图像识别和图像语义理解等。
3. 非结构化数据处理技术研究非结构化数据处理技术研究主要包括如下几个方面:(1)文本预处理文本预处理是非结构化数据分析中的一个重要环节,主要包括分词、去停用词、词性标注、词向量化和tf-idf等。
分析方法的准确性和效率与文本预处理环节密不可分。
(2)数据挖掘和机器学习算法非结构化数据处理中,最常用的数据挖掘和机器学习算法包括朴素贝叶斯分类器、支持向量机、贝叶斯网络、决策树和深度学习等。
这些算法可以用于非结构化数据的特征提取、分类、群组化和模式挖掘等。
(3)自然语言处理(NLP)自然语言处理(NLP)是处理自然语言文本和语音的分支学科,主要包括自动语音识别、机器翻译、自然语言生成和问答系统。
NLP可以应用于文本生成、文本语义分析、情感分析和智能问答等。
基于深度学习的多模态数据融合与特征提取研究

基于深度学习的多模态数据融合与特征提取研究摘要:深度学习在近年来取得了显著的突破,并在各个领域得到广泛应用。
随着互联网的快速发展和大数据的普及,多模态数据的获取越来越容易。
多模态数据融合和特征提取是深度学习在多模态数据应用中的两个重要任务。
本文将对基于深度学习的多模态数据融合与特征提取进行探讨与研究。
引言:在现实生活中,我们常常遇到各种类型的数据,例如图像、文本、语音等。
多模态数据指的是包含了两种或多种不同类型数据的集合。
与传统的单一模态数据相比,多模态数据在表达能力和丰富性上更加强大。
因此,多模态数据的融合与特征提取具有重要的研究意义和应用价值。
一、多模态数据融合的方法多模态数据融合是将多个模态的数据进行有机结合,以实现更全面、准确的信息传递和表达。
基于深度学习的多模态数据融合方法通常包括以下几种:1. 基于特征融合的方法:该方法通过提取不同模态数据的特征,并将这些特征融合在一起,形成一个综合的特征向量。
常用的特征融合方法包括将特征进行拼接、求和、平均等操作。
深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)可以用于特征提取和融合。
2. 基于神经网络的方法:该方法通过构建一个端到端的神经网络模型,将多模态数据输入到网络中,并通过网络学习模态间的相关性,从而实现多模态数据的融合。
常见的深度学习模型包括多通道卷积神经网络(MC-CNN)、多输入多输出循环神经网络(MIMO-RNN)等。
3. 基于注意力机制的方法:该方法通过引入注意力机制,使网络能够自动学习不同模态数据的重要性权重,并根据权重对不同模态数据进行加权融合。
注意力机制可以通过深度学习模型自动学习得到,也可以通过先验知识进行设计。
二、多模态数据特征提取的方法特征提取在深度学习中起着至关重要的作用,它能够将数据转化为可供机器学习和模式识别算法使用的高层次数据表示。
在多模态数据中,不同模态数据的特征提取方法如下所示:1. 图像特征提取:图像是一种常见的多模态数据类型,它包含了丰富的视觉信息。
text2sql范例

text2sql范例(原创实用版)目录1.Text2SQL 的背景和意义2.Text2SQL 的实现方法和技术3.Text2SQL 的应用场景和案例4.Text2SQL 的未来发展趋势和挑战正文一、Text2SQL 的背景和意义随着互联网和大数据时代的到来,数据处理和分析已经成为各行各业的重要环节。
在众多数据处理技术中,SQL(结构化查询语言)以其简洁明了的语法和强大的数据操作功能,成为数据库领域的通用语言。
然而,对于非技术人员来说,编写 SQL 语句无疑是一项复杂且具有挑战性的任务。
为了降低数据处理的门槛,Text2SQL 技术应运而生。
Text2SQL,即文本到结构化查询语言,是一种将自然语言描述转换为 SQL 语句的技术。
通过 Text2SQL 技术,用户可以用自然语言描述数据查询需求,系统将自动生成相应的 SQL 语句。
这无疑极大地降低了数据处理的难度,使得更多的人能够进行数据分析和挖掘。
二、Text2SQL 的实现方法和技术Text2SQL 的实现可以分为以下几个关键步骤:1.语义分析:通过自然语言处理技术,识别用户的查询意图,例如筛选、排序、分组等。
2.语法转换:将自然语言描述转换为 SQL 语法,如将“筛选出年龄大于 30 的用户”转换为“SELECT * FROM users WHERE age > 30”。
3.语义校验:对生成的 SQL 语句进行语义校验,确保其符合数据库的操作规范。
4.代码生成:根据用户需求和 SQL 语法生成对应的 SQL 代码。
Text2SQL 的实现需要依赖自然语言处理、语义分析、机器学习等先进技术。
目前,学术界和工业界已经提出了许多针对 Text2SQL 的研究方法和模型,如基于规则的方法、基于模板的方法、基于深度学习的方法等。
三、Text2SQL 的应用场景和案例Text2SQL 技术在许多场景中都有广泛的应用,例如:1.数据分析:企业数据分析师可以用 Text2SQL 技术快速地编写 SQL 查询语句,提高工作效率。
大数据参考文献
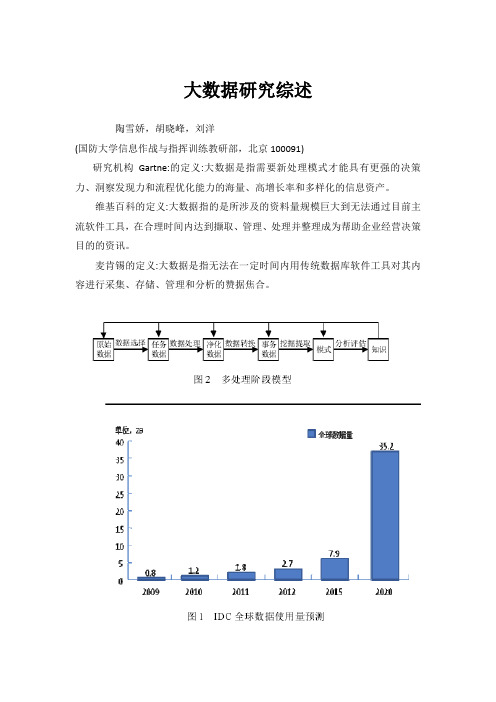
大数据研究综述陶雪娇,胡晓峰,刘洋(国防大学信息作战与指挥训练教研部,北京100091)研究机构Gartne:的定义:大数据是指需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
维基百科的定义:大数据指的是所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理并整理成为帮助企业经营决策目的的资讯。
麦肯锡的定义:大数据是指无法在一定时间内用传统数据库软件工具对其内容进行采集、存储、管理和分析的赞据焦合。
数据挖掘的焦点集中在寻求数据挖掘过程中的可视化方法,使知识发现过程能够被用户理解,便于在知识发现过程中的人机交互;研究在网络环境卜的数据挖掘技术,特别是在Internet上建立数据挖掘和知识发现((DMKD)服务器,与数据库服务器配合,实现数据挖掘;加强对各种非结构化或半结构化数据的挖掘,如多媒体数据、文本数据和图像数据等。
5.1数据量的成倍增长挑战数据存储能力大数据及其潜在的商业价值要求使用专门的数据库技术和专用的数据存储设备,传统的数据库追求高度的数据一致性和容错性,缺乏较强的扩展性和较好的系统可用性,小能有效存储视频、音频等非结构化和半结构化的数据。
目前,数据存储能力的增长远远赶小上数据的增长,设计最合理的分层存储架构成为信息系统的关键。
5.2数据类型的多样性挑战数据挖掘能力数据类型的多样化,对传统的数据分析平台发出了挑战。
从数据库的观点看,挖掘算法的有效性和可伸缩性是实现数据挖掘的关键,而现有的算法往往适合常驻内存的小数据集,大型数据库中的数据可能无法同时导入内存,随着数据规模的小断增大,算法的效率逐渐成为数据分析流程的瓶颈。
要想彻底改变被动局面,需要对现有架构、组织体系、资源配置和权力结构进行重组。
5.3对大数据的处理速度挑战数据处理的时效性随着数据规模的小断增大,分析处理的时间相应地越来越长,而大数据条件对信息处理的时效性要求越来越高。
AI智能问答是什么原理

AI智能问答是什么原理AI智能问答(Artificial Intelligence Question Answering)是一种基于人工智能技术的问答系统,其原理是通过对大数据的分析和处理,结合自然语言处理和机器学习算法,实现对用户提出的问题进行理解和回答。
本文将介绍AI智能问答系统的基本原理及其应用。
一、AI智能问答系统的基本原理AI智能问答系统的基本原理是将问题理解和回答两个过程进行分解,并通过不同的算法进行处理。
1. 问题理解问题理解是AI智能问答系统中的关键环节,包括问题的解析、语义理解和意图识别等。
在问题解析阶段,系统对用户提出的问题进行分析,识别关键词和实体,且去除无意义的停用词。
然后,通过语义理解,系统可以分析问题的语义结构和逻辑关系,理解用户的意图。
同时,意图识别可以将问题分类,确定该问题属于哪个领域或主题,从而更好地回答问题。
2. 回答生成回答生成是AI智能问答系统中的另一个重要环节,主要通过检索式和生成式两种方式进行回答。
- 检索式回答:这种方式通过在预先构建的知识库或数据集中搜索并匹配与问题最相关的答案。
系统根据问题的关键词,比较问题和答案之间的相似度,并返回最相关的答案作为回答。
这种方式的优点是速度快、准确度高,但受限于已有的知识库和数据。
- 生成式回答:这种方式根据问题的语义和上下文生成答案。
系统会使用机器学习、自然语言生成等技术,通过对大量语料和模型的训练,生成与问题相关的答案。
这种方式的优点是能够生成更加灵活、具有逻辑连贯性的答案,但受限于语义解析和模型训练的准确度。
二、AI智能问答系统的应用AI智能问答系统具有广泛的应用领域,可用于智能客服、在线教育、法律咨询、医疗健康等领域。
1. 智能客服AI智能问答系统可以应用于在线客服平台,通过自动回答用户提出的问题,提供高效、准确的客服支持。
系统能够解决诸如订单查询、商品咨询等常见问题,减轻人工客服的工作负担,并提高用户的满意度。
(完整版)大数据时代的数据概念分析及其他

大数据时代的数据概念分析及其他一、概念:"大数据"是一个体量特别大,数据类别特别大的数据集,并且这样的数据集无法用传统数据库工具对其内容进行抓取、管理和处理。
"大数据"首先是指数据体量(volumes)?大,指代大型数据集,一般在10TB?规模左右,但在实际应用中,很多企业用户把多个数据集放在一起,已经形成了PB级的数据量;其次是指数据类别(variety)大,数据来自多种数据源,数据种类和格式日渐丰富,已冲破了以前所限定的结构化数据范畴,囊括了半结构化和非结构化数据。
接着是数据处理速度(Velocity)快,在数据量非常庞大的情况下,也能够做到数据的实时处理。
最后一个特点是指数据真实性(Veracity)高,随着社交数据、企业内容、交易与应用数据等新数据源的兴趣,传统数据源的局限被打破,企业愈发需要有效的信息之力以确保其真实性及安全性。
百度概念:大数据(bigdata),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过目前主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。
大数据的4V特点:Volume、Velocity、Variety、Veracity。
研究机构Gartner概念:"大数据"是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
从数据的类别上看,"大数据"指的是无法使用传统流程或工具处理或分析的信息。
它定义了那些超出正常处理范围和大小、迫使用户采用非传统处理方法的数据集。
亚马逊网络服务(AWS)、大数据科学家JohnRauser提到一个简单的定义:大数据就是任何超过了一台计算机处理能力的庞大数据量。
研发小组对大数据的定义:"大数据是最大的宣传技术、是最时髦的技术,当这种现象出现时,定义就变得很混乱。
" Kelly说:"大数据是可能不包含所有的信息,但我觉得大部分是正确的。
数据处理年度总结(3篇)
第1篇一、前言随着信息技术的飞速发展,数据处理已经成为各行各业不可或缺的一部分。
在过去的一年里,我国数据处理领域取得了显著的成绩,不仅推动了科技创新,也为经济社会发展提供了强有力的支撑。
本文将回顾本年度数据处理领域的发展情况,总结取得的成果,并展望未来的发展趋势。
二、数据处理领域的发展现状1. 数据处理技术不断进步本年度,我国数据处理技术取得了显著的突破。
在数据采集、存储、传输、分析等方面,新技术不断涌现,为数据处理提供了更加高效、便捷的手段。
(1)大数据技术:大数据技术在各领域的应用越来越广泛,包括金融、医疗、教育、交通等。
本年度,我国大数据技术取得了以下进展:- 大数据存储技术:分布式存储、云存储等技术得到了广泛应用,提高了数据存储的效率和安全性。
- 大数据计算技术:MapReduce、Spark等分布式计算框架不断优化,提高了大数据处理的性能。
- 大数据可视化技术:ECharts、D3.js等可视化工具得到了广泛应用,使得大数据分析结果更加直观易懂。
(2)人工智能技术:人工智能技术在数据处理领域的应用日益深入,包括数据清洗、特征提取、模式识别等。
本年度,我国人工智能技术在以下方面取得了进展:- 深度学习:深度学习技术在图像识别、语音识别等领域取得了显著成果。
- 自然语言处理:自然语言处理技术在语义理解、情感分析等领域取得了突破。
2. 数据处理应用领域不断拓展本年度,我国数据处理应用领域不断拓展,涵盖了各个行业和领域。
(1)金融领域:金融行业对数据处理的依赖程度越来越高,包括风险控制、欺诈检测、信用评估等。
(2)医疗领域:医疗行业的数据处理技术不断进步,包括医疗影像分析、疾病预测等。
(3)教育领域:教育行业的数据处理技术得到了广泛应用,包括在线教育、个性化学习等。
(4)交通领域:交通行业的数据处理技术不断进步,包括智能交通、自动驾驶等。
三、数据处理取得的成果1. 技术创新成果本年度,我国在数据处理领域取得了一系列技术创新成果,包括:- 大数据存储与计算技术:分布式存储、云存储、分布式计算等技术得到了广泛应用。
AI智能问答是什么原理
AI智能问答是什么原理AI智能问答(Artificial Intelligence Question and Answering)是指利用人工智能技术,通过计算机自动理解和回答人类提出的问题的一种应用。
它通过结合自然语言处理、知识图谱、机器学习、推理以及大数据等技术,能够快速准确地给出用户满意的答案。
一、自然语言处理自然语言处理(Natural Language Processing,简称NLP)是AI智能问答的核心技术之一。
这一技术能够帮助计算机理解和处理人类自然语言的方式和规则。
在智能问答中,NLP技术主要包括分词、词性标注、实体识别、句法分析、语义理解等步骤。
通过这些步骤,计算机能够将用户提出的问题转化为机器可以理解和处理的形式。
二、知识图谱知识图谱(Knowledge Graph)是AI智能问答中的另一个重要组成部分。
它是将海量的结构化和半结构化的数据整合起来,形成一个具有语义连结的知识网络。
通过知识图谱,计算机可以获取到丰富的知识,并且能够根据问题的匹配程度进行相关度排序,快速找到答案。
三、机器学习机器学习(Machine Learning)是AI智能问答的关键技术之一。
它是通过让计算机从训练数据中进行学习和总结,从而让计算机具备智能问答的能力。
在智能问答中,机器学习主要用于构建问题-答案匹配模型,通过学习问题和答案的关联性,实现智能的答案推理和匹配。
四、推理推理(Reasoning)是AI智能问答的重要环节。
它通过逻辑和推理规则,通过对问题和知识之间的逻辑关系进行推断,从而给出合理的答案。
在智能问答中,推理技术能够进一步提高答案的准确性和全面性。
五、大数据大数据(Big Data)技术在AI智能问答中也起着关键作用。
大数据技术能够从海量的数据中挖掘有用信息,帮助智能问答系统更好地理解和回答用户的问题。
通过分析和对比大批量的问题和答案数据,可以提高系统的智能程度和准确性。
AI智能问答技术的原理是将多种相关的技术整合起来,形成一个高度智能化的问答系统。
人工智能技术在播音主持中的运用
人工智能技术在播音主持中的运用人工智能(AI)驱动的智能化变革,正在前所未有地颠覆着人们的生活方式和工作模式。
据了解,人工智能(AI)在2018年处于炒作周期顶峰,但是到目前为止,在大数据、云计算、深度学习等技术的快速推动下,AI又进入了一个新的发展阶段,应用场景逐渐明朗,社会效益和经济价值逐渐显现,其能力和应用范围都得到了极大的拓展提升。
在这个过程中,AI在广播电视行业的内嵌度也在不断加强,其中一个重要的应用领域就是播音主持。
传统的播音主持主要依赖人的理解感受、语音语速、语言处理、表达能力和现场把控能力等来完成,而AI的运用可能会在这些方面带来新的可能性和挑战。
语音和文本处理是AI在播音主持中的重要应用之一,如语音合成、语音识别、自然语言理解等技术可以使机器具有一定的语言表达能力和感知理解能力。
此外,深度学习等先进技术的运用也进一步增强了机器的语言处理能力,使其可以更好地理解和生成语音和文本内容。
然而,AI在播音主持中的运用还面临着许多挑战,如:如何保证语音的质量和情感表达,如何进行内容编排和适应性调整以及如何处理直播过程中的突发状况和与受众互动等问题。
这些挑战不仅涉及到技术,还涉及到人文、行业规范和用户需求等多个方面。
随着AI技术的进一步发展,AI在播音主持中将会得到更加广泛的应用和更深入的研究,进而推动广播电视行业的发展。
总之,AI在播音主持中的运用是一个极具挑战和赋能融合的过程,值得我们进一步研究和探索。
1.人工智能技术概述及其在语音和文本处理中的运用1.1 人工智能的基本原理和主要技术人工智能(AI)是指通过人工制造的系统实现对人类智能的模拟和扩展。
这类系统能对环境进行感知,主要原理涉及到各种计算模型和算法,如搜索和优化、逻辑推理、模式识别、神经网络等。
AI的主要技术包括机器学习、深度学习、自然语言处理(NLP)和强化学习。
机器学习是AI的一个核心领域,它的目标是开发和实现能从数据中学习和改善的算法。
29_语义网的本体建模技术
语义网的本体建模技术第一部分语义网的基本概念和特性 (2)第二部分本体建模在语义网中的作用 (5)第三部分本体建模的基本原理和方法 (9)第四部分常用的本体建模工具和技术 (13)第五部分本体建模在语义网应用中的实例分析 (15)第六部分本体建模面临的挑战和问题 (19)第七部分本体建模的未来发展趋势和前景 (22)第八部分本体建模对语义网发展的影响和贡献 (26)第一部分语义网的基本概念和特性语义网的基本概念和特性随着互联网的迅速发展,人们对于信息的需求越来越高。
传统的搜索引擎已经无法满足人们对于精确、个性化的信息检索需求。
为了解决这个问题,语义网应运而生。
语义网是一种基于本体建模技术的互联网应用模式,它旨在使计算机能够理解、处理和表达人类语言的含义,从而实现更加智能、高效的信息检索和管理。
本文将对语义网的基本概念和特性进行简要介绍。
一、语义网的基本概念1.语义网的定义语义网(Semantic Web)是一种基于本体建模技术的互联网应用模式,它旨在使计算机能够理解、处理和表达人类语言的含义,从而实现更加智能、高效的信息检索和管理。
语义网的核心思想是通过为网络上的数据添加语义标签,使得计算机能够理解这些数据的含义,从而实现对数据的智能处理和分析。
2.语义网的目标语义网的主要目标是实现互联网上信息的智能化处理和管理。
具体来说,语义网希望实现以下几个方面的目标:(1)提高信息检索的准确性和相关性:通过为网络上的数据添加语义标签,使得计算机能够理解这些数据的含义,从而提高信息检索的准确性和相关性。
(2)实现信息的个性化推荐:通过对用户的兴趣和需求的深入理解,为用户提供个性化的信息推荐服务。
(3)实现知识的共享和重用:通过本体建模技术,实现知识的统一表示和管理,从而促进知识的共享和重用。
(4)支持智能决策:通过对大量语义化数据的分析和挖掘,为用户提供智能决策支持。
二、语义网的特性1.结构化数据语义网的核心是结构化数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大数据中的语义识别【摘要】数据管理是一个在商业和政府中变得越来越重要的课题。
数据质量代表一个很大的挑战,因为数据质量不高所带来的间接损失是非常大的。
大数据是企业决策的基础,但是单纯的数据量的积累不会对企业产生任何益处,只有建立适当的分析模型,并运用相应的技术手段,对大量的数据进行有效地深加工,发现隐含在大量数据中的信息并加以利用,进而指导企业做出相关决策,才能将大数据的真正效用发挥到极致。
高质量的数据是大数据发挥效能的前提和基础,强大、高端的数据分析技术是大数据发挥效能的重要手段。
【关键词】数据量,大数据,数据质量分析,数据词典,正则表达式对大数据进行有效分析的前提是必须要保证数据的质量,专业的数据分析工具只有在高质量的大数据环境中才能提取出隐含的、准确的、有用的信息,否则,即使数据分析工具再先进,在大数据环境中也却只能提取出毫无意义的“垃圾”信息,那大数据的意义又何在?因此数据质量在大数据环境下尤其重要。
为提高数据质量,现在提出为数据添加语义的方法,帮助用户识别大数据的模式。
这种方法的独特性在于利用了数据的语义价值,检测完数据后,通过数据语义分析提出一个数据模型,这样就可以对数据更方便的处理。
1. 数据语义介绍在商业管理中,职业经理人必须有一个统一的视野和有价值较大的信息,从而在恰当的时机做出正确的决策。
数据质量管理在企业中已经非常重要了,目的是通过使用指示器这个易于交流,廉价而又计算方便的技术,来提供高精度,全面而又及时的信息。
在大数据时代包含多种数据源的信息的质量成为了一个巨大的挑战。
数据质量和语义方面很少加入论文文献。
现在的困难是用语义学提高数据质量。
在制定纠正数据中的错误的策略时,对数据模式的误解将是我们成功解决问题的重大障碍。
频繁的使用元数据不足于让我们正确的理解数据的真正含义。
对于一个给定的数据源S,我们的方法是提出一个语义数据分析来得到对数据定义的更好的了解,并且提高对错误数据的检测和纠正。
但是没有可用的模式来理解数据的意义,更别说纠正错误了。
目前很少有数据工具能够将字符串“pekin ”(法语’北京’的意思)识别为“Beijing ”,也不能将“Londres ”(法语‘伦敦’的意思)识别“ Lon don”。
为了解这些代表同个类别和子类别信息的字符串,还需要其他的信息。
另外还有一些相似的情况,如要将167C的语义理解为16摄氏度。
令S为一个非结构化数据集,多个种类数据相结合的结果,S还可以看作是字符串的集合,其中的内容用分号隔开并且由列项表示其包含的内容,每一项记录S的一个数据架构。
我们定义的S并没有明确的结构,这会导致一个语义数据操作问题。
S 可能包含不一致的内容,这种情况下需要回答三个疑问:什么是字符串语义?应当使用什么样的语言?什么样的值是能够使用的,什么样的是不能使用的(即值的有效性和无效性)?图1中给出了一个S的样本图1 :数据源S的样本可以看到数据源S中有几个列项组成,S被记为(Coli, i = 1;7)这种形式。
在S中,观察第四列,“Beijing ”和“London”在语法和语义上都是有效的,但“pekin” 和“Londres”在语法上是有效的,在语义上却是无效的。
COL2列中大多数都是显示的日期信息,因此其中的“ 13”会被认为无效的(语义上的)。
S中不仅有日期信息,还有其他的很多未知信息,这就证明我们需要理解更多的语义并纠正错误的数据。
2. 元信息定义:<meta>元素可提供相关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。
<meta>标签位于文档的头部,不包含任何内容。
<meta>标签的属性定义了与文档相关联的名称/值对。
meta是html语言head区的一个辅助性标签。
<head> <meta http-equiv="content-Type" content="text/html; charset=gb2312" ></head>我们需要深入研究基于语义的新种类的大数据ETL (抽取,转换,加载)这样就能够进行数据分析,数据清理和数据扩充数据分析是数据处理过程的第一步(图2)是数据源用于确定数据质量问题的分析,而且是一种量的分析,包括了叙述性的分析,例如:模式,表,域和数据源的定义。
图2:数据质量管理工具现在的数据分析工具提供了统计数据的分析,并没有解决数据语义方面的分析。
由此这里就介绍一下用于扩充分析过程的语义指示器。
对于语义数据处理,我们提出给每个数据源,一个错误报告,更新的日志和使用元信息的新语义结构。
错误报告包括数据源中的多种异常:同一列中出现一个以上类别和语言, 不一致的数据格式,副本和空值。
更新的日志是一个更新行为的集合,这个集合用于数据源,例如:翻译后的语言,均化后的格式。
这些更新每次覆盖一列。
为了在各列间及时进行更新需要使用函数依赖的概念。
接下来将着重描述语义数据分析过程的细节,尤其是元信息,如图3图:语义的数据分析过程元信息有三个组件组成,Meta-Schema-0ntology (MSO), Meta-Repository (MR) , MR 是由数据词典,正则表达式和指示器列表组成。
2.1 Meta-Schema-O ntology (元模式一体)作为信息集,数据库可以使用不同的方法去描述,这个不同主要是概念和属性。
MSO 是用来存储元结构中所有等价的描述的(图4)图4:MSO统一建模语言类图表MSO是一个能够作为本体进行管理的知识集,本体是一种正式的语言,定义各项内容之间如何结合使用是一种语法。
MSO能够创建很多实例,女口:“person” “organization” 和“Invoice”这三个概念,他们各自都有很多同义词,比方说人的同义词:客户,大人,小孩等,“人”的概念被若干个属性(如:姓名,住址,出生年月)定义,这就暗示人的每个同义词可以用相似的方式定义。
本体使用开放源protege工具来查看的。
(图5)知识可以通过数据库的不同描述而得到演化,可以被表示一个元知识库。
Prenom - synonym Attributes -> FlrstName图5: Proteg e 下的MSO 实例2.2元知识库(MR元知识库包含数据词典,正则表达式和指示器列表。
有效的字符串可以被归为一个类别,这些字符串可以使用多种语言,这样形成的这 些类别的集合可以被视为数据词典。
例如,包含通常描述的机场,大学,餐馆和医院的 名称字符串所组成的的类别,可以成为一个数据词典。
令 catext 为被扩展定义的类别的集合,catext={cati,i=1;n},其中cati 属于{国家,性别,网站,电话 ……},对每个cati ,子类别subcati={catij,j=1;m} 就能够定义了。
我们将数据词典定义为三类(类别,信息,语言)(图6)CnkgonlufulliKithnSmliC 3ih'Si ii|nC;ili=Cilv Intb|i=Landnn Inlbj 2=LonJre25 Ctrl L 产 English Cal|S = French Cat 3=CoiininFriimceFrailicr FrarLkrddi Franck1 II ^I: Ji 1 nil Gcuimi lUkliainCatj-piirslNHme Adaim FrunceCat n _AddieNSStfeet SLAxcnik : RueA VCIUK Pine? Pl. English English English FreiithFrench F ICIK I M图6:数据词典样例+ * EmployeeFt Ouwier+f Guest》Clienle* Femme * Cl ent ■ Customer*n ' f Perwrrii\ ' 4 Honmc「*Persaine jConcepl* * Person* 4 Otgjniidbn'* Invoice• * Product | J —+| Order |SVMCunceplAttribiieSYMAlUibuieN DF TIPre nonSurNamo2.2.2 正则表达式(RE通过使用正则表达式来定义一个类别Kati ,从而起到检查字符串的语法和语义的作用,令K a t i n t为此类别的集合。
则R E可以被定义为一个{类别,R E}的集合。
RE={Catregexi/Catregexi (Kati, Regexij); i = 1...p, j = 1...q} 实例如图图7:正则表达式集合实例2.2.3指示器语义数据分析的研究是基于应用数据源的指示器集合,此集合由三种类型的指示器组成:统计指示器{Istati, i = 1;p} ,语法指示器(ISYN1,2)和语义指示器(ISEM1,2),如图8示:图&指示器集合3. 语义数据分析过程先赋予语义数据分析算法一些符号和定义。
每一个属于数据源S的列Ci,都有一个值Vi(i = 1...n )集合,每一个Vi 有一个数据类型,如{String, Number, Date, Boolean}。
定义1、值V的语法有效性:如果v € RE且v ~ w € DD则v是语义有效的。
定义2、值V的语法无效性:如果v ? RE且v ? DD则v是语义无效的。
定义3、主类:令Cati(v)为一个给定属性的语义正确值的数目,若Cati(v)>Catj(v),则Cati(v)是主类,“ Number of categories ”为检测到的类别数量。
定义4、值V的语义有效性:如果v € Cati,则V是语义有效的,且Cati是主类。
定义5、值V的语义无效性:如果v ? Cati,则V是语义无效的,Cati是主类。
3.1算法分析语义数据分析算法的原理是核查值是否属于元数据库,目的是确定V的语法和语义的有效性。
如图9示.Ugoiitlun Semantic data protiluigInput:S a data sourceRE n set regular expressionsDI> a data diction^t y1 a set of indicatorsOutput:T L,k=l,,7 profiling tables Begin S—u■皿Snmpg) "ST csFor each Cj from S' <!“ i=l ・*nstatislicTnilicatDrsff^)se ii nti c Re* c<»^ni ti< mStiii etn i <\) end ForEnd Semantic data profiling图9:语义数据分析算法输入数据源s和一些元信息,算法返回一些表格(Tk, k = 1,7),这些表格包含指示器结果,无效语义数据,有效语义数据,无效语法数据,有效语法数据和新的语义结构。