102增强型微粒群优化算法及其在软测量中的应用
【系统仿真学报】_智能优化算法_期刊发文热词逐年推荐_20140727

1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
Hale Waihona Puke 科研热词 推荐指数 遗传算法 11 进化算法 3 蚁群算法 3 自适应 3 粒子群优化 3 神经网络 3 路径规划 2 粒子群优化算法 2 特征选择 2 混沌 2 支持向量机 2 多目标 2 变异 2 参数优化 2 pid控制 2 高维 1 鞅 1 非线性预测 1 非线性模型预测控制 1 非线性动态摩擦力 1 铜闪速熔炼 1 鉴频器 1 鉴相器 1 量化因子 1 配料优化 1 适应度函数 1 连续域 1 进化计算 1 载波跟踪 1 软约束 1 转速辨识 1 车辆优化调度 1 路由 1 超紧致耦合 1 蚁群优化 1 荷电状态 1 自适应计算 1 自适应网格算法 1 自适应神经模糊推理系统 1 自适应模糊系统 1 自适应模糊控制 1 群体智能 1 编码方式 1 紧耦合 1 粒子群算法 1
萤火虫算法智能优化粒子滤波

第42卷第1期自动化学报Vol.42,No.1 2016年1月ACTA AUTOMATICA SINICA January,2016萤火虫算法智能优化粒子滤波田梦楚1薄煜明1陈志敏1,2吴盘龙1赵高鹏1摘要针对粒子滤波(Particlefilter,PF)重采样导致的粒子贫化以及需要大量粒子才能进行状态估计的问题,本文结合粒子滤波的运行机制,对萤火虫算法的寻优方式进行修正,设计了新的萤火虫位置更新公式和荧光亮度计算公式,并在此基础上提出了萤火虫算法智能优化粒子滤波.该方法引入了萤火虫群体的优胜劣汰机制以及萤火虫个体的吸引和移动的行为,使粒子群智能地向高似然区域移动,提高了粒子群的整体质量.实验表明该方法提高了粒子滤波的预测精度,同时大大降低了状态值预测所需的粒子数量.关键词粒子滤波,萤火虫算法,粒子贫化,状态估计引用格式田梦楚,薄煜明,陈志敏,吴盘龙,赵高鹏.萤火虫算法智能优化粒子滤波.自动化学报,2016,42(1):89−97DOI10.16383/j.aas.2016.c150221Firefly Algorithm Intelligence Optimized Particle Filter TIAN Meng-Chu1BO Yu-Ming1CHEN Zhi-Min1,2WU Pan-Long1ZHAO Gao-Peng1Abstract Given the particle impoverishment due to particlefilter(PF)resampling and given the need of a large number of particles for state estimate,the optimization mode offirefly algorithm is revised in combination with the operating mechanism of particlefilter,and a new update formula offirefly position is designed as well.On this basis,an intelligent optimized particlefilter offirefly algorithm is proposed.By means offirefly group s mechanism of survival of thefittest and individualfirefly s attraction and movement behaviors,this algorithm enables the particle swarm to move toward the high likelihood region with the purpose of improving the total mass of particle swarm.The experiment has shown that the algorithm has upgraded the prediction accuracy of particle swarm and substantially reduced the quantity of the particles required by the prediction of state value.Key words Particlefilter(PF),firefly algorithm,particle impoverishment,state estimationCitation Tian Meng-Chu,Bo Yu-Ming,Chen Zhi-Min,Wu Pan-Long,Zhao Gao-Peng.Firefly algorithm intelligence optimized particlefilter.Acta Automatica Sinica,2016,42(1):89−97非线性系统广泛存在于实际工程应用中,例如工业控制、目标跟踪、故障检测等,并且在系统中还可能存在非高斯噪声,这些因素会降低基于卡尔曼理论框架的常规滤波算法的性能[1−2].粒子滤波(Particlefilter,PF)[3]是一种基于蒙特卡罗思想的滤波技术,由于其状态函数和观测函数没有做非线性及非高斯的假设,因此粒子滤波可以不受系统非线性和非高斯噪声的限制.针对粒子滤波的权值退化问题,可以采用重采样方法进行解决[4].但是重采样算法仅复制大权值样本[5−6],会导致粒子的贫化收稿日期2015-04-13收修改稿日期2015-09-14Manuscript received April13,2015;accepted September14, 2015国家自然科学基金(61501521,U1330133,61473153,61403421,61 203266),国防重点预研资助项目(40405070102)资助Supported by National Natural Science Foundation of China (61501521,U1330133,61473153,61403421,61203266)and Key Defense Advanced Research Project of China(40405070102)本文责任编委王占山Recommended by Associate Editor WANG Zhan-Shan1.南京理工大学自动化学院南京2100942.中国卫星海上测控部江阴2144311.School of Automation,Nanjing University of Science and Technology,Nanjing2100942.China Satellite Maritime Tracking and Controlling Department,Jiangyin214431现象[7−8],即高权值粒子被多次复制,小权值粒子被直接舍弃.虽然较小权值的粒子对于目标状态估计的贡献有限,但是却代表着一定的状态信息,重采样阶段对粒子的舍弃,必将影响到状态估计的精度.针对粒子滤波的样本贫化问题,国内外学者进行了大量研究,文献[9]提出了基于权值选择的粒子滤波,该方法从大量粒子中选择权值较大的粒子用于下一时刻的状态估计,可以减轻粒子的贫化程度,但容易导致粒子权值的退化.文献[10]提出了确定性重采样粒子滤波算法,该算法避免对低权重粒子的盲目舍弃,从而确保粒子的多样性.文献[11]提出了饱和粒子滤波改进算法,根据不同系统的特点选择特定的重采样方法使粒子逼近真实值.但上述两种方法依然是基于传统重采样的框架,未能彻底解决粒子贫化的问题.基于群智能优化思想的PF是现代粒子滤波发展的一个崭新方向[12],将粒子滤波中的粒子视为生物集群中的个体,利用模拟生物集群的运动规律使粒子的分布更加合理.由于基于群智能优化的粒子滤波主要是对粒子的分布进行迭代寻优[13−14],并不90自动化学报42卷涉及对低权重粒子的舍弃,因此可以从根本上解决粒子的贫化现象.国内外学者已成功将蚁群算法、粒子群算法、遗传算法等经典群智能优化算法与粒子滤波进行结合,并在此基础上提出了各种改进算法.文献[15]将粒子群优化算法和蚁群优化算法的优化思想共同作用到粒子滤波的样本更新中,实现粒子之间信息共享,从而增强了算法的全局寻优能力.文献[16]提出了自适应粒子群优化改进粒子滤波算法,自适应地控制邻域粒子的数量,提高了样本分布的合理性和滤波的精度.文献[17]提出了基于遗传算法的粒子滤波,避免了粒子搜索区域的盲目扩大和粒子的早熟,提高了滤波算法的效率.萤火虫算法[18]由剑桥大学Yang于2009年提出,作为最新的群智能优化算法之一,该算法具有更好的收敛速度和收敛精度,且易于工程实现,但由于萤火虫算法自身运行机制的特殊性,将萤火虫算法与粒子滤波进行直接融合会存在难以避免的问题,例如粒子交互会导致运算复杂度的大幅增加、局部最优现象会导致鲁棒性的降低等,因此,目前国内外关于将萤火虫算法与PF进行融合的报道较少. 2014年,文献[19]虽然提出了基于人工萤火虫群优化的粒子滤波算法,但该算法只是利用了萤火虫算法的粒子转移公式用来重组样本,没有进行粒子的迭代寻优,并不是真正意义上的群智能优化粒子滤波算法,此外该算法仍然需要抛弃低权重的粒子,无法从根本上解决粒子的贫化现象.针对上述问题,本研究对萤火虫算法的位置更新机制和荧光亮度更新机制进行改进,利用全局最优信息指导粒子集的整体移动,成功地将萤火虫群优化思想和粒子滤波进行结合,避免粒子交互带来的运算复杂度的明显增加,同时很好地提高了粒子滤波的精度.1粒子滤波算法粒子滤波是贝叶斯估计基于抽样理论的一种近似算法,它将蒙特卡罗和贝叶斯理论结合在一起[20],其基本思想是在状态空间中寻找一组随机样本对条件后验概率密度进行近似,用样本均值代替原先需要根据后验概率密度函数所进行的积分运算,从而获得最小的方差估计.假定非线性动态过程表示如下:x k=f(x k−1,v k−1)(1)y k=h(x k,w k)(2)其中,x k为状态值,f(·)为状态函数,v k−1为系统噪声,y k为观测值,h(·)为观测函数,w k为量测噪声.设状态初始概率密度为p(x0|y0)=p(x0),则状态预测方程为p(x k|y1:k−1)=p(x k|x k−1)p(x k−1|y1:k−1)d x k−1(3)状态的更新方程为p(x k|y1:k)=p(y k|x k)p(x k|y1:k−1)p(y k|y1:k−1)(4)p(y k|y1:k−1)=p(y k|x k)p(x k|y1:k−1)d x k(5)设已知且易采样的重要性函数为q(x0:k|y1:k),将其改写成q(x0:k|y1:k)=q(x0)kj=1q(x j|x0:j−1,y1:j)(6)则权值公式为w k=p(y1:k|x0:k)p(x0:k)q(x k|x0:k−1,y1:k)q(x0:k−1,y1:k)=w k−1p(y k|x k)p(x k|x k−1)q(x k|x0:k−1,y1:k)(7)从p(x k−1|y1:k−1)中采样N个样本点{x ik−1}Ni=1,则概率密度为p(x k−1|y1:k−1)=Ni=1w ik−1δ(x k−1−x ik−1)(8)其中,δ(·)为狄拉克函数.概率密度更新公式为w ik=w ik−1p(y k|x ik)p(x ik|x ik−1)q(x ik|x ik−1,y k)(9)状态输出x k=Ni=1w ikx ik(10)从上述过程可以看出,从k=0时刻开始,粒子滤波系统首先对样本进行初始化.系统确定目标状态的先验概率,给每个粒子赋予相应的初始值.在下一时刻,系统首先进行状态转移,每个粒子按照设置的状态转移方程对自身的状态进行传播,然后进行系统观测,得到观测值,计算所有粒子的权重.最后进行粒子加权,从而得到后验概率的输出,同时样本经过重采样后继续进行系统状态的转移,构成了一个循环跟踪系统.2人工萤火虫群算法萤火虫算法是通过模拟萤火虫的群体行为构造出的一类随机优化算法[21].其仿生原理是:用搜索空间中的点模拟自然界中的萤火虫个体,将搜索和1期田梦楚等:萤火虫算法智能优化粒子滤波91优化过程模拟成萤火虫个体的吸引和移动过程,将求解问题的目标函数度量成个体所处位置的优劣,将个体的优胜劣汰过程类比为搜索和优化过程中用好的可行解取代较差可行解的迭代过程.目前公认的萤火虫算法有两种版本,一种是由印度学者Krishnanand等于2006年提出,称为GSO(Glowworm swarm optimization)[22];另一种由剑桥学者Yang等于2010年提出,称为FA(Fire-fly algorithm)[23].两种算法的仿生原理相同,但在具体实现方面有一定差异.考虑到与粒子滤波算法的相容性,本研究以FA为基础进行改进和扩展.在FA中,萤火虫发出光亮的主要目的是作为一个信号系统,以吸引其他的萤火虫个体,其假设为:1)萤火虫不分性别,它将会被吸引到所有其他比它更亮的萤火虫那去;2)萤火虫的吸引力和亮度成正比,对于任何两只萤火虫,其中一只会向着比它更亮的另一只移动,然而,亮度是随着距离的增加而减少的;3)如果没有找到一个比给定的萤火虫更亮,它会随机移动.如上所述,萤火虫算法包含两个要素,即亮度和吸引度.亮度体现了萤火虫所处位置的优劣并决定其移动方向,吸引度决定了萤火虫移动的距离,通过亮度和吸引度的不断更新,从而实现目标优化.从数学角度对萤火虫算法的主要参数进行如下描述:1)萤火虫的相对荧光亮度为I=I0×e−γr ij(11)其中,I0为萤火虫的最大萤光亮度,与目标函数值相关,目标函数值越优自身亮度越高;γ为光强吸收系数,荧光会随着距离的增加和传播媒介的吸收逐渐减弱;r ij为萤火虫i与j之间的空间距离.2)萤火虫的吸引度为β=β0×e−γr2ij(12)其中,β0为最大吸引度;γ为光强吸收系数;r ij为萤火虫i与j之间的距离.3)萤火虫i被吸引向萤火虫j移动的位置更新公式如式(13)所示:x i=x i+β×(x j−x i)+α×rand−12(13)其中,x i,x j为萤火虫i和j所处的空间位置;α∈[0,1]为步长因子;rand为[0,1]上服从均匀分布的随机数.3基于萤火虫算法智能优化的粒子滤波(F A-PF)传统的粒子滤波重采样方法通过删除小权值粒子集来避免粒子匮乏的现象,但经过多次迭代后,将带来粒子的贫化问题.针对以上问题,本研究提出利用萤火虫算法对粒子滤波进行优化的思想.萤火虫算法先将萤火虫群体随机分布在解空间中,每个萤火虫个体由于所处位置不同,其发出的荧光亮度也不同,通过比较荧光亮度,亮度高的萤火虫可以吸引亮度低的萤火虫向自身移动,移动的距离主要取决于吸引度的大小和步长的大小.根据式(4)来计算更新后的位置.这样通过多次移动后,所有个体都将聚集在亮度最高的萤火虫的位置上,从而实现最终的寻优.从上述运行机制看,可以考虑利用FA的群智能性优化粒子滤波的样本,但如果直接将萤火虫群优化思想与粒子滤波直接进行融合,会导致许多的问题(具体分析在第4.1节和第4.2节中).因此需要对萤火虫算法的内部寻优机制进行修正和改进.3.1改进位置更新公式针对FA-PF位置更新方式的设计,本文从运算复杂度和全局寻优能力两方面进行研究分析.1)在标准萤火虫群优化算法的寻优机制中,萤火虫根据其邻域中各个萤火虫的荧光素浓度来决定其移动方向,从位置更新公式可以看出,要完成该步骤,粒子滤波需要用粒子i(i=1,2,···,N,i=j)和其余粒子j(j=1,2,···,N,j=i)进行交互运算,这将使粒子滤波运算复杂度提高一阶,会严重影响滤波的实时性.2)在标准萤火虫算法的位置更新机制中,完成每次交互,都需根据最大吸引度、光强吸收系数以及距离等参数重新计算粒子i和每个粒子j之间的吸引度,这又从另外一个方面提高了粒子滤波的运算复杂度.3)萤火虫算法与其他群智能优化算法一样,都存在出现局部极值现象的可能性.Yang也意识到了这个问题,因此在位置更新公式中增加了扰动项α×(rand−1/2),该方法可以一定程度上降低局部极值出现的概率,但现有的研究均表明,在群智能优化算法中仅简单地增加rand扰动项来克服局部极值现象,效果并不理想.针对以上问题,本研究对萤火虫群优化算法的位置更新公式进行改进,设置粒子目标函数的计分板,将各个迭代子时刻的粒子目标函数值与计分板的目标函数值进行对比,从而得到当前滤波时刻所有粒子所经历的全局最优值,用全局最优值代替粒子j与粒子i进行信息交互.为此,重新定义萤火虫算法的位置更新公式:定义1.修正位置更新公式.x ik=x ik+β×gbest k−x ik+92自动化学报42卷α×rand−12(14)其中,x ik为序号为i的粒子在k时刻的状态值,β为粒子间的吸引度,α为步长因子,rand是[0,1]之间的随机数,gbest k为全局最优值.从理论上分析,首先,由于粒子群的全局最优值只有一个,因此粒子滤波中的粒子i只需与全局最优值进行对比,避免了高一阶的交互运算和对粒子间吸引度的重复计算,该阶段的运算复杂度可由原先的O(N2)减少至O(N),从而确保了滤波算法的实时性.其次,用全局最优值代替粒子j与粒子i进行信息交流,实质上是用全局最优值来指导粒子群的整体运动,可以明显提高萤火虫优化部分的全局寻优能力,从而可以明显降低出现局部极值的概率.最后,该改进思路可以使滤波算法用更少的迭代次数和粒子数寻找到更优值,这又从另一个方面明显减少粒子滤波的运算复杂度,更易于工程实现.3.2改进荧光亮度更新公式标准萤火虫算法中,每一只萤火虫都需要和其他的萤火虫对比在当前所处位置的荧光亮度,亮度高的萤火虫可以吸引亮度低的萤火虫向自己移动,若将该方式直接应用于粒子滤波,这会再次增加粒子滤波的运算复杂度.同时,本研究考虑到若要确保滤波器的精度,需在萤火虫的自适应迭代寻优中引入最新的观测值,因此本研究提出修正的荧光度计算公式.定义2.修正荧光亮度计算公式I=abs(z new−z pred(i))(15)其中,I为修正后的荧光亮度,z new为滤波器最新的观测值,z pred为滤波器预测的观测值.从修正后荧光亮度计算公式可以看出,其利用观测值和每个粒子的预测观测值进行对比,由于每个时刻的观测值只有一个,因此可以避免每一个粒子和其他的粒子对比在当前所处位置的荧光亮度所带来的运算复杂度.若要将修正荧光亮度计算公式扩充到多维情况下,其核心思路是求出预测观测值和最新观测值在多维空间中的空间差值,例如红外目标跟踪中的二维坐标信息,目标的预测坐标值为(x p,y p),最新观测坐标值为(x o,y o),则修正荧光亮度计算公式可以设计为I=abs(x p−x o)+abs(y p−y o)(16)如果是雷达目标跟踪中的三维坐标信息,目标的预测坐标值为(x p,y p,z p),最新观测坐标值为(x o, y o,z o),则修正荧光亮度计算公式可以设计为I=abs(x p−x o)+abs(y p−y o)+abs(z p−z o)(17) 3.3可行性分析修正后的萤火虫算法与原始萤火虫算法相比,其用全局最优值来代替粒子间的相互对比,这会提高萤火虫算法的全局寻优能力,且明显减少运算复杂度;但是辩证地说,这也降低了萤火虫算法的局部寻优能力,而上述修正萤火虫算法的特点是非常适用于粒子滤波的,首先,FA-PF是在标准粒子滤波的基础上进行萤火虫算法迭代寻优,而粒子滤波中状态值的分布本身就有一定的准确性,因此局部寻优能力的降低对粒子滤波影响不是很大;其次,FA-PF本身的迭代次数不是很多,因此其需要很强的全局寻优能力来指导粒子移动,而这正是修正萤火虫算法的特点;最后,修正萤火虫算法在运算实时性方面优势明显,这也是粒子滤波所迫切需要的.综上,本文提出的萤火虫算法智能优化粒子滤波是可行的.3.4算法具体实现和步骤步骤1.在初始时刻,采样N个粒子{x i,i= 1,···,N}作为算法的初始粒子.重要性密度函数用式(18)表示x ik∼qx ik|x ik−1,z k=px ik|x ik−1(18)步骤2.模拟萤火虫优化思想的吸引行为和移动行为.1)计算粒子i和全局最优值之间的吸引度.β=β0×e−γr2i(19)其中,β0为最大吸引度,γ为光强吸收系数,r i为粒子i与全局最优值gbest k之间的空间距离.2)根据吸引度更新粒子的位置.x ik=x ik+β×gbest k−x ik+α×rand−12(20)步骤3.计算并对比荧光亮度值,更新全局最优值.gbest k∈x1k,x2k,x3k,···,x Nk|I(x)=maxI(x1k),I(x2k),I(x3k),···,I(x Nk)(21)步骤4.从荧光度计算公式可以看出,荧光度值随预测观测值与真实观测值的差值呈反方向变化,本文设置迭代终止阈值为0.01,当荧光度函数值大于0.01时,则算法停止迭代,否则继续迭代至最大迭代次数.当算法符合设定的阈值ε时,说明粒子已经分布在真实值附近,或者达到最大迭代次数时,此时停止优化.否则转入步骤2.1期田梦楚等:萤火虫算法智能优化粒子滤波93步骤5.权重补偿及更新.萤火虫算法与PF结合的核心思路是对PF中的每一个粒子都进行萤火虫迭代寻优操作,使得粒子沿目标状态后验密度值更高的方向移动,提高粒子对状态估计的准确性.但萤火虫算法改变了各粒子在状态空间的位置,此时粒子集所表示的分布密度函数不再是p(x k|y1:k−1),这样贝叶斯滤波的理论基础会丢失.因此,本文借鉴文献[24]的思想,在粒子位置更新的同时对权重进行补偿及更新,其具体方式如下:w ik =p(x k=s ik|z1:k−1)q(s ik)p(z k|x k=s ik)(22)其中,s ik为k时刻的粒子i,q(·)为重要性函数.在权重补偿之后,优化前后的粒子集至少从理论上讲是服从同一分布的,即p(x k|y1:k−1),从而保持了贝叶斯滤波的理论基础.步骤6.进行归一化.w ik =w ikNi=1w ik(23)步骤7.状态输出.x=Ni=1w ikx ik(24)上述思路充分利用了整个粒子集中的有效信息,有利于粒子跳出局部极值,减少算法的迭代次数浪费在状态值变化不明显的情形,使得改进算法更多地由于达到初始设置的阈值ε而停止优化,减少了算法迭代至最大迭代次数才停止的概率,从而进一步提高了运算速度.在有效粒子样本的数量上,上述方式可以增加粒子的多样性,从而提高粒子样本的质量.由于萤火虫算法的收敛能力较强,因此我们在FA-PF中通过设置最大迭代次数和终止阈值的方式对算法的迭代次数进行限制,使得粒子群整体向真实区域移动,但又避免最终收敛,具体原因如下:1) FA-PF的核心思想是让粒子集对高似然区域有更合理的覆盖,既要有一定广度,保证能在下一时刻能捕获真实值,又要有一定集中度以保证采样效率,并不是要将粒子全部集中在真实值附近.如果所有的粒子均集中在真实值附近,反而会降低粒子的多样性.2)如果迭代次数过多,会造成FA-PF的运算复杂度较PF有明显提高,这会降低FA-PF的实时性. 4仿真实验实验硬件条件为英特尔i5-4200U处理器、8G 内存,软件环境为Matlab2010b,选取单变量非静态增长模型,仿真对象的过程模型和量测模型如下:过程模型:x(t)=0.5x(t−1)+25x(t−1)1+[x(t−1)]2+8cos[1.2(t−1)]+w(t)(25)量测模型:z(t)=x(t)220+v(t)(26)式中,w(t)和v(t)为零均值高斯噪声.由于该系统是高度非线性,并且似然函数呈双峰状,因此,传统的滤波方法很难处理此系统.设系统噪声方差Q= 1和Q=10,量测噪声方差R=1,滤波时间步数为50,在萤火虫算法中,一般设置最大吸引度为[0.8, 1]区间内的常数,本文设置最大吸引度为0.85;步长因子一般设置为[0,1]之间的常数,步长因子越高,则全局寻优能力越强,但会降低收敛精度;步长因子越低,则局部寻优能力越强,但会降低收敛速度,本文设置步长因子为0.4.此外,光强吸收系数一般情况下设置为1.上述设置均是在参考现有文献通常参数设置的基础上,经过多次实验得到.根据前期研究,目前较为通用的设置为最大吸引度为1、步长因子为0.3、最大光强吸收系数为1,萤火虫算法FA在群智能优化算法中,所需设置的参数相对较少,一般情况下该通用设置可以使得FA-PF在多数非线性问题中均取得优于PF的效果,但不一定是最佳效果,因此需要在上述通用设置的基础上利用数值法进行参数微调,这样可以取得最佳效果.本文利用PF和FA-PF 对该非线性系统进行状态估计和跟踪.均方根误差公式为RMSE=1TTt=1(x t− x t)212(27)为了证明FA-PF的优势,这里在仿真实验中将FA-PF同时和PF以及粒子群优化粒子滤波(Par-ticle swarm optimized particlefilter,PSO-PF)[25]进行对比测试.在PSO-PF部分,设置学习因子c1 =c2=2,惯性权重线性递减,其最大值为0.9,最小值为0.3.4.1精度测试1)当粒子数N=20、Q=1时,仿真结果如图1和图2所示.2)当粒子数N=50、Q=1时,仿真结果如图3和图4所示.3)当粒子数N=100、Q=1时,仿真结果如图5和图6所示.94自动化学报42卷图1滤波状态估计(N =20,Q =1)Fig.1State estimation of filter (N =20,Q =1)图2滤波误差绝对值(N =20,Q =1)Fig.2Absolute value of filter error (N =20,Q =1)图3滤波状态估计(N =50,Q =1)Fig.3State estimation of filter (N =50,Q =1)图4滤波误差绝对值(N =50,Q =1)Fig.4Absolute value of filter error (N =50,Q =1)图5滤波状态估计(N =100,Q =1)Fig.5State estimation of filter (N =100,Q =1)图6滤波误差绝对值(N =100,Q =1)Fig.6Absolute value of filter error (N =100,Q =1)1期田梦楚等:萤火虫算法智能优化粒子滤波95表1实验结果对比Table1Comparison of simulation results参数RMSE运算时间(s)PF PSO-PF FA-PF PF PSO-PF FA-PFN=20,Q=1 6.5276 4.6309 4.28620.09280.12590.1108N=50,Q=1 5.5987 4.2807 4.10670.11670.14920.1367N=100,Q=1 4.7243 4.1109 4.09290.12450.19770.1674N=20,Q=107.8860 5.3516 5.02350.09470.12840.1162N=50,Q=10 6.2733 4.8920 4.70430.11500.15760.1425N=100,Q=10 5.3569 4.5583 4.54810.12330.20310.1739从图1∼6中可以看出,相对于标准PF和PSO-PF,本文提出的FA-PF算法具有更精确的状态值预测精度,这是因为FA-PF在PF的基础上,通过迭代寻优的粒子状态更新方式提高了粒子分布的合理性.从表1中可以看出,FA-PF在粒子数为20的情况下,无论是在运算时间还是在运算精度上,均优于粒子数为100的PF,说明了FA-PF 可以用很少的粒子数达到所需的精度,且具有很高的精度速度综合性价比.但我们也看到,FA-PF与PSO-PF相比,前者在粒子数为20和50时精度优势更为明显,而当粒子数为100时,两者的精度大致相同,这说明FA-PF更适合在粒子数更少的情况下使用.此外,与PSO-PF相比,FA-PF的位置更新公式的运算操作数相对更少,因此其整体运算时间也是略小于PSO-PF.综上分析,FA-PF具有更高的运算综合效率.从理论上说,粒子滤波的运算复杂度与粒子数呈近似线性关系,但本节仿真测试的目的之一是为了证明FA-PF可以利用很少的粒子数达到所需的精度,因此在实验中设置的粒子数较少,而粒子数从20提高到100所增加的时间远小于仿真程序启动运行等动作的基本时间开销,这里不能体现出近似线性的关系,若在此基础上进一步增加粒子数,则可体现出明显的近似线性的关系.4.2粒子多样性测试为了测试FA-PF运行时的样本多样性,也结合实际应用中滤波器长时间工作的需求,这里将运行步数增加至100.取滤波器在k=10、k=25、k= 95时刻的粒子分布情况,如图7∼9所示.从图7∼9可以看出,标准PF算法的粒子多样性表现较为一般,尤其在滤波后期,粒子分布往往集中在少数的状态值上,降低了粒子的多样性,不利于滤波器的状态估计.而在FA-PF中,粒子在整体向高似然真实区域移动的同时,在低似然区域也合理地保留了部分粒子,其在整个滤波的过程中确保了粒子多样性.此外,FA-PF没有进行传统的重采样,可以避免粒子贫化现象的出现.图7k=10时粒子状态分布情况Fig.7Particle distribution when k=10图8k=25时粒子状态分布情况Fig.8Particle distribution when k=25。
【国家自然科学基金】_优化处理_基金支持热词逐年推荐_【万方软件创新助手】_20140802
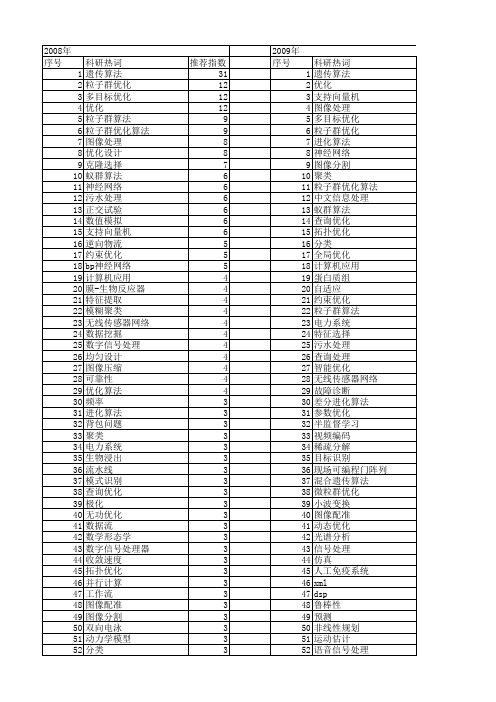
推荐指数 31 12 12 12 9 9 8 8 7 6 6 6 6 6 6 5 5 5 4 4 4 4 4 4 4 4 4 4 4 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
科研热词 遗传算法 粒子群优化 多目标优化 优化 粒子群算法 粒子群优化算法 图像处理 优化设计 克隆选择 蚁群算法 神经网络 污水处理 正交试验 数值模拟 支持向量机 逆向物流 约束优化 bp神经网络 计算机应用 膜-生物反应器 特征提取 模糊聚类 无线传感器网络 数据挖掘 数字信号处理 均匀设计 图像压缩 可靠性 优化算法 频率 进化算法 背包问题 聚类 电力系统 生物浸出 流水线 模式识别 查询优化 极化 无功优化 数据流 数学形态学 数字信号处理器 收敛速度 拓扑优化 并行计算 工作流 图像配准 图像分割 双向电泳 动力学模型 分类
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106
107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160
【系统仿真学报】_进化算法_期刊发文热词逐年推荐_20140723
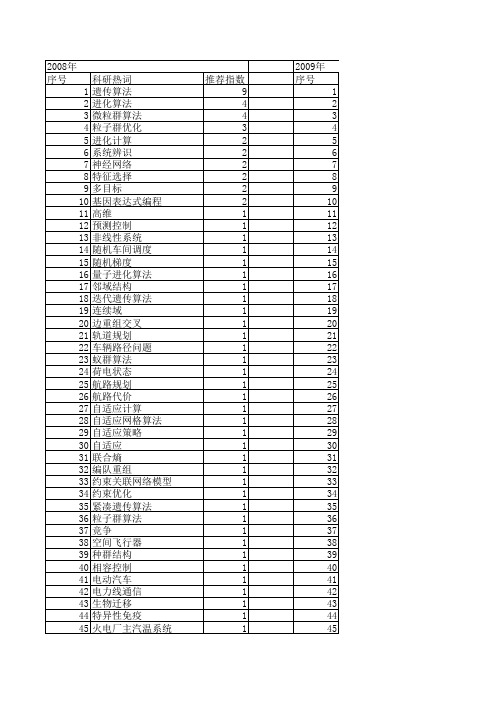
科研热词 遗传算法 进化算法 微粒群算法 粒子群优化 进化计算 系统辨识 神经网络 特征选择 多目标 基因表达式编程 高维 预测控制 非线性系统 随机车间调度 随机梯度 量子进化算法 邻域结构 迭代遗传算法连续域 边重组交叉 轨道规划 车辆路径问题 蚁群算法 荷电状态 航路规划 航路代价 自适应计算 自适应网格算法 自适应策略 自适应 联合熵 编队重组 约束关联网络模型 约束优化 紧凑遗传算法 粒子群算法 竞争 空间飞行器 种群结构 相容控制 电动汽车 电力线通信 生物迁移 特异性免疫 火电厂主汽温系统
2009年 科研热词 差分进化算法 进化算法 遗传算法 多目标优化 航迹规划 粒子群算法 微粒群算法 差分进化 非线性规划 非支配排序 非劣个体 量子进化算法 量子计算 量子染色体 重规划 遗传进化 遗传编程 遗传算子 遗传参数 选择压力 连续空间优化 进化规划算法 边缘提取 软测量 车辆路径问题 跳跃基因 路径重连 负载平衡 负载均衡 设计仿真 补偿阳极 蚁群算法 虚拟战场 菱形思维方法 自适应调整 自适应思维进化算法 自适应 背包问题 群体智能 网关部署 组合优化 约束优化 粒子运动轨迹 粒子发散性 移动计算 推荐指数 7 4 3 3 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
种群多样性 离散粒子群优化算法 神经网络 直觉模糊集 电场防护 电场数值仿真 电压控制 物流配送 点电极 灾变操作 火力分配 混沌搜索算法 混沌搜索 混合整数规划 混合建模 混合差分演化算法 混合 水库优化调度 正交各向异性 模糊规划 模拟电路 梯度矢量流 最小二乘支持向量机 时间窗口 早熟收敛 无线移动网络 无线mesh网 旅行商问题 文化算法 故障诊断 收敛性能 收敛性 支持向量机 控制律重组 拓扑优化 战术编队 惯性权重 微分进化 强化学习 嵌入式 局部收敛 局部开发 尖点灾变模型 小波提升变换 对地攻击 容错控制 实数编码
【国家自然科学基金】_软测量_基金支持热词逐年推荐_【万方软件创新助手】_20140801
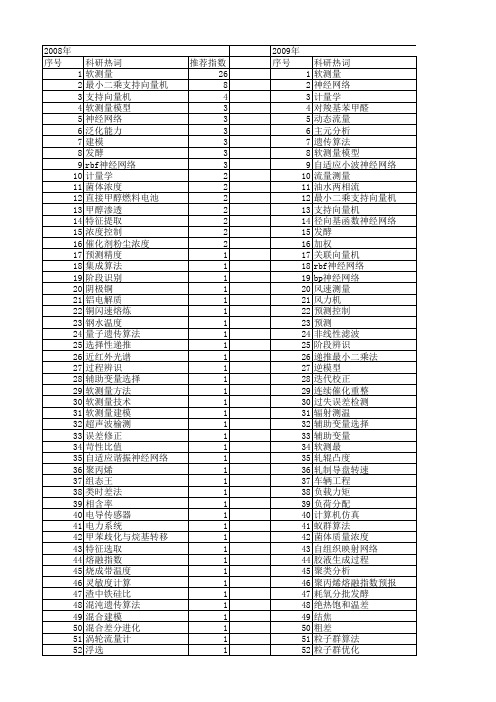
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106
推荐指数 26 8 4 3 3 3 3 3 3 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124
偏最小二乘 偏差校正 信号去噪 估计器 产生式规则 二代小波 乙烯含量 主元分析 不可直接测量量 丁二酸发酵 svr plc lf炉 k均值聚类 elm bp学习算法 adaboost算法 activex技术
科研热词 软测量 最小二乘支持向量机 支持向量机 软测量模型 神经网络 泛化能力 建模 发酵 rbf神经网络 计量学 菌体浓度 直接甲醇燃料电池 甲醇渗透 特征提取 浓度控制 催化剂粉尘浓度 预测精度 集成算法 阶段识别 阴极铜 铝电解质 铜闪速熔炼 钢水温度 量子遗传算法 选择性递推 近红外光谱 过程辨识 辅助变量选择 软测量方法 软测量技术 软测量建模 超声波榆测 误差修正 苛性比值 自适应谐振神经网络 聚丙烯 组态王 类时差法 相含率 电导传感器 电力系统 甲苯歧化与烷基转移 特征选取 熔融指数 烧成带温度 灵敏度计算 渣中铁硅比 混沌遗传算法 混合建模 混合差分进化 涡轮流量计 浮选
【系统仿真学报】_算法_期刊发文热词逐年推荐_20140722

3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92
93 94 95 96 97 98 99 100 101 102 103 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
【国家自然科学基金】_局部算法_基金支持热词逐年推荐_【万方软件创新助手】_20140802
差分进化 多目标 图像增强 变异 信赖域 人工智能 bp网络 预测 边缘提取 车辆路径问题 角点检测 蚂蚁算法 蚁群优化 网格 粗糙集 电力系统 特征提取 混沌优化 模糊推理 最小二乘支持向量机 无功优化 惯性权重 差分进化算法 局部特征 局部放电 局部收敛 局部搜索算法 小生境 多样性 协同进化 共轭梯度法 信息检索 优化设计 优化算法 人工神经网络 人工免疫系统 人工免疫 bp算法 非采样contourlet变换 非线性规划 非线性系统 非线性互补问题 降维 量子粒子群优化算法 进化计算 自适应遗传算法 聚类算法 聚类分析 群体智能 维数约简 粒子群优化(pso) 粒子滤波 立体视觉 移动自组网
107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160
科研热词 遗传算法 神经网络 蚁群算法 粒子群优化 粒子群优化算法 局部搜索 旅行商问题 粒子群算法 小波变换 流形学习 故障诊断 模拟退火算法 图像处理 全局优化 自适应 特征提取 模拟退火 无线传感器网络 差分进化 收敛性 优化 混沌优化 混沌 支持向量机 多目标优化 人脸识别 调度 聚类分析 聚类 电力系统 特征点 混合算法 数字水印 差分进化算法 图像分割 bp神经网络 组合优化 粒子群 微粒群优化 局部保持投影 小生境 启发式算法 克隆选择 量子遗传算法 进化算法 软测量 聚类算法 禁忌搜索 文化算法 惯性权重 微粒群算法 图像配准
【国家自然科学基金】_权重函数_基金支持热词逐年推荐_【万方软件创新助手】_20140730
科研热词 粒子群算法 权重 惯性权重 遗传算法 粗糙集 粒子滤波 熵权 权重函数 层次分析法 多目标优化 选址 超几何函数 脱机签名鉴定 粒子群优化算法 粒子群优化 种群多样性 目标识别 汉明权重函数 模糊模型 概率权重矩法 权重系数 排序 指标体系 微粒群算法 属性约简 多属性决策 商业银行 光方向耦合器 偏差函数 信用风险评估 优化 代价函数 topsis s函数 高阶统计矩 高斯链网络模型 高层体系结构 风险叠加 风险函数 颜色直方图 项目相似度 非马尔可夫记忆函数 非线性转子轴承 非线性 集对分析 隶属函数 随机加工时间 随机交通均衡 降水 队形控制 阈上小色差 钢筋混凝土结构
综合权重 绝对偏差 组合规则 组合权重 约束处理 红外湍流退化图像 红外探测器 索风营水电站 算法 策略 竞争性知识传播网络 立体匹配 突水预测 突水规则 空间插值 稳态优化 稳健设计 离散粒子群 离散增量 离差 神经网络 矿井突水 短程硝化 相对差异函数 相似性度量 相似度函数 相似度 直方图 盲检测 目标选取 目标跟踪 目标函数 电阻管式炉 理论框架 特征选择 特征提取 物理规划 物流配送中心 物元模型 物元分析 熵值法 灰色系统 灰色关联度 溶剂脱水塔 混沌时间序列 混沌序列 混合阚值 混合模型 混合多属性决策 混合ddm算法 流域水安全管理 泵站系统 汽车产品 水质评价
科研热词 惯性权重 自适应 粒子群优化 证据理论 粒子滤波 粒子群算法 粒子群优化算法 综合评价 神经网络 直觉模糊集 目标识别 文本分类 多属性群决策 信息熵 预警模型 隶属函数 金属矿山 评价 脉冲噪声 群决策 综合评判 细节保护 组合优化 特征提取 熵权 潜势度 泥石流 模糊评价 模糊综合评价 模糊数学 模糊层次分析法 模式识别 梯度方向直方图 期望最大化 数据融合 排序函数 指标体系 多目标决策 多属性决策 多准则决策 在线分级特征选择 可拓理论 加权算术平均算子 加权中值滤波 前景理论 决策 冲突证据 优化 vague集 gauss混合模型 d-s证据理论 鲁棒性
【国家自然科学基金】_优化算法_基金支持热词逐年推荐_【万方软件创新助手】_20140801
水电站 智能优化 预测控制 特征选择 无功优化 仿真 视频编码 结构优化 率失真优化 机组组合 有限元 最小二乘支持向量机 文化算法 数学模型 改进遗传算法 微粒群优化 图像配准 全局收敛性 量子遗传算法 计算机应用 虚拟企业 节能 自适应遗传算法 聚类分析 生产调度 混合算法 梯级水电站 最优化 克隆选择 鲁棒性 车辆路径问题 蚂蚁算法 群体智能 网络安全 网格 系统辨识 移动机器人 生产计划 独立分量分析 特征提取 模糊控制 服务质量 无约束优化 惯性权重 人工免疫系统 非线性规划 非线性系统 非线性 软测量 路由 路径优化 负载均衡 群集智能 群智能
科研热词 遗传算法 优化 蚁群算法 粒子群优化算法 多目标优化 粒子群算法 粒子群优化 优化设计 神经网络 无线传感器网络 模拟退火算法 全局优化 支持向量机 优化算法 自适应 混合遗传算法 bp神经网络 参数优化 旅行商问题 进化算法 组合优化 算法 微粒群算法 混沌 模糊控制 收敛性 调度 约束优化 无功优化 数据挖掘 数值模拟 进化计算 运筹学 启发式算法 车辆路径问题 电力系统 预测 故障诊断 拓扑优化 优化调度 仿真 人工神经网络 近似算法 路径规划 自适应遗传算法 粒子群 禁忌搜索 模拟退火 改进遗传算法 蚁群优化 聚类 服务质量
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
贪婪算法 网络优化 网格 粒子群优化(pso) 禁忌搜索算法 矢量量化 率失真优化 物流配送 灵敏度分析 梯级水电站 最小生成树 智能优化算法 早熟收敛 早熟 旋转算法 投资组合 建模 并行遗传算法 工作流 定位 图像配准 图像压缩 免疫遗传算法 鲁棒优化 需水预测 随机需求 量子进化算法 量子粒子群优化 迭代算法 软约束 设计结构矩阵 计算机视觉 计算机应用 视频编码 蚁群优化算法 节点定位 航空、航天推进系统 自适应变异 背包问题 聚类算法 结构优化 线搜索 线性矩阵不等式 空间索引 移动代理 种群多样性 码率控制 目标函数 电压稳定 混沌遗传算法 混合粒子群算法 正交设计 模糊优化 模型预测控制
【计算机应用】_遗传算法_期刊发文热词逐年推荐_20140723
推荐指数 101 8 6 6 5 5 5 4 4 4 3 3 3 3 3 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106
高维0/1背包问题 高斯变异算子 驱动主义 项目调度 面向服务体系结构 非真实感绘制 非合作博弈 雪花模式 集合 难度系数 随机规划 随机模拟 随机机会约束规划 阵发性心脏病 间歇过程 键合图 铁路 量子计算 量子粒子群算法 量子粒子群优化算法 配送型多级库存 邻苯二酚 遗传规划 遗传编程 遗传算法(ga) 遗传模糊系统 遗传模拟退火算法 遗传变异算子 遗传函数算法 逻辑映射 选择算子 适应度赋值 适应度函数 退火算法 连续过程 进化概率 近似模型 过程神经元网络 过程挖掘 轮询式 转向架 车间调度 路线优化 路由算法 路由优化 路由 路径规划 路径优化 跨世代异物种重组大变异算法 负载均衡 语音识别 评估函数 训练 计算机仿真
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第卷第期控制与决策年月文章编号增强型微粒群优化算法及其在软测量中的应用陈国初俞金寿华东理工大学自动化研究所上海摘要对微粒群优化算法进行分析提出一种增强型微粒群优化算法用和对几种常用函数的优化问题进行测试比较结果表明比更容易找到全局最优解优化效率和优化性能明显提高将用于催化裂化装置主分馏塔粗汽油干点软测量建立了基于算法的粗汽油干点神经网络软测量模型研究结果表明基于的软测量模型比基于的软测量模型具有更高的精度和更好的性能关键词微粒群优化增强型微粒群优化神经网络软测量中图分类号文献标识码引言微粒群优化算法是一种新的进化计算算法简单且具有许多良好的优化性能因而得到广泛的应用但存在容易陷入局部极值的缺陷本文通过分析算法参数对其优化性能的影响提出一种增强型微粒群优化算法并用和对几种函数的优化问题进行测试和比较产品质量指标软测量的研究一直是一个热点问题催化裂化装置在石油二次加工中具有重要的经济意义其操作状况直接关系到炼油装置轻质油品的收率从而影响整个炼油厂的经济效益本文将用于主分馏塔粗汽油干点软测量建立了基于的粗汽油干点神经网络软测量模型并与基于算法的粗汽油干点神经网络软测量模型进行比较结果表明基于的软测量模型比基于的软测量模型具有更好的性能增强型微粒群优化算法标准微粒群优化算法假设在一个维搜索空间中有个微粒组成一微粒群其中第个微粒的空间位置为收稿日期修回日期基金项目教育部博士点专项基金项目作者简介陈国初男江西都昌人博士生从事化工过程建模仿真与智能算法的研究俞金寿男浙江海宁人教授博士生导师从事工业过程建模仿真优化与控制等研究I zZ, ,I zD),第z个微粒所经历的最好位置为P z= (z1,zZ, ,zD),每个微粒的飞行速度为V z=(U z1, U zZ, ,U zD),z=1,Z, ,n.在整个微粒群中,所有微粒经历过的最好位置为P=(1,Z, ,D).每一代微粒的第c维(1c D)根据如下方程变化;U zc=cU zc-6111(zc-I zc)-6Z1Z(c-I zc),(1)I zc=I zc-U zc.(Z)其中;c为惯性权值;61和6Z为加速系数,它们都是正的常数;11和1Z是两个在[0,1 范围内变化的随机数.搜索时,各微粒每一步的位置速度都被最大位置最小位置和最大速度最小速度所限制.2.2EPSO的主要改进措施(1)对c的改进在PSO中,c对算法能否收敛具有重要作用,它使微粒保持运动惯性,使其有扩展搜索空间的趋势,有能力探索新的区域.c值大有利于全局搜索,收敛速度快,但不易得到精确的解;c值小有利于局部搜索,能得到更为精确的解,但收敛速度慢.最初版本的PSO中,c为常数;后来有研究表明[3,6 ;为使算法具有较强的全局搜索能力,开始c应大些,然后逐步减小c,以便获得更精确的解.一般地,开始时c= 1.4,然后逐步线性减小到c=0.35.由PSO微粒的搜索特征不难发现,线性减小c 使其保持较大值和较小值的时间都很短,不能满足开始搜索速度快些搜索后期速度慢些的要求.为此,本文提出惯性权值c随着搜索的进行,不是线性减小而是按余弦规律减小.这样,开始搜索时c能较长时间保持较大值以提高搜索效率,在搜索后期c 又能较长时间保持较小值以提高搜索精度.c的修正公式为c=c min-(c max-c min)>1-cOS((iter-1)T/(MaxStep-1))Z.(3)其中;cmax 为搜索开始时最大的c,cmin为搜索结束时最小的c,iter为迭代所进行的步数,MaxStep为允许最大迭代步数.(Z)对最好微粒和最坏微粒的处理在PSO中,各微粒的飞行都是随机的,当最优微粒飞行一步后,如果适应值变差,下一步就以变差的位置继续飞行,没能发挥最优微粒应有的优势.对于每一步最优微粒的飞行,本文采用试探法使其朝着适应值变优的方向飞行,即最优微粒飞行一步后,如果适应值变好,则以新的位置继续飞行;如果适应值变差,则返回原位置重新搜索.对于每一步的最差微粒,本文用该步的历史全局最优微粒取代.(3)防止陷入局部极值和稳定性变差在PSO中,搜索陷入局部极值往往表现为微粒几乎停止不动.为防止微粒陷入局部极值,本文约定;如果某微粒连续5步近似不动,则重新初始化该微粒的飞行速度.在PSO中,算法稳定性变差往往表现为微粒一直以很快的速度飞行.为改善PSO的搜索稳定性,本文约定;如果某微粒连续5步飞行速度超过某极限值而适应值又得不到改善,则重新初始化该微粒的飞行速度.2.3EPSO算法流程1)初始化设置群体的规模参数维数惯性权值加速系数最大允许迭代次数或适应值限各微粒的初始位置和初始速度等.Z)按预定准则评价各微粒的初始适应值.3)根据式(3)计算惯性权值.4)根据式(1)计算各微粒新的速度.5)判断各微粒的速度,如有必要,则重新初始化微粒速度.6)对各微粒新的速度进行限幅处理.7)根据式(Z)计算各微粒新的位置,并对各微粒新的位置进行限幅处理.8)比较每个微粒的当前适应值和历史最好适应值,若当前适应值更优,则令当前适应值为该微粒历史最好适应值,并保存该微粒的位置为其个体历史最好位置;比较群体所有微粒的当前适应值和群体历史最好适应值,若当前适应值更优,则令当前适应值为历史全局最好适应值,并保存历史全局最优位置.9)对每一步的最好微粒和最差微粒进行处理.10)如果满足停止条件(适应值误差小于设定的适应值误差限或迭代次数超过最大允许迭代次数),则搜索停止,输出历史全局最优位置和历史全局最优适应值即为所求结果;否则,返回3)继续搜索.3测试函数的优化3.1所用测试函数1)F1函数f(I1,I Z)=Z1.5-I1Sin(4TI1)-I Z Sin(Z0TI Z),-3.0I11Z.1, 4.1I Z 5.8.(4)该函数只有一个全局最大点(11.6Z55,5.7Z5),最大值为38.850 3.它很容易陷入局部极大值38.73Z8,38.6199,38.4Z91,33.0077等,是一个很难的多峰值优化函数.Z)F Z函数378控制与决策第Z0卷该函数在 处取得全局最大值 其第 极大值为 是一个很难的多峰值优化函数函数该函数有无数个极大点 其中只有一个 为全局最大点 最大值为 最大值峰周围有一圈脊 它们的取值均为 因此很容易陷入此处的局部极大点 是一个很难的多峰值优化函数函数该函数有 个局部极小点 其中只有一个 为全局最小点 最小值为 很容易陷入局部极小点函数 只讨论二元情况该函数有一个全局最小点 最小值为 局部极小点为 局部极小值为 优化结果本文同时用 和 对以上函数进行优化 寻优时 和 的微粒个数均为 最大迭代步数均为 惯性权值都从 减小到 迭代时 和 的随机数 和 都相同 加速系数 和 均为 误差限均为 由于 和 都是随机搜索 每次搜索结果可能不同本文对每一测试函数都进行 次独立测试测试结果的统计对比如表 所示表测试结果统计对比序号测试函数算法达最优概率适应值平均值适应值最大值适应值最小值 算法达最优概率适应值平均值适应值最大值适应值最小值 函数 函数由表 可见 在算法参数相同的情况下获得最优解的概率明显高于 比 更容易找到全局最优解 优化效率和优化性能明显提高基于 的神经网络人工神经网络 能根据训练样本的输入输出数据 自动拟合其中复杂的非线性关系 其信息的分布式存储使它具有较强的抗干扰能力 因而在众多领域得到广泛的应用 本文将 用于三层前向网络连接权值和阈值的训练 构造了基于 算法的三层前向网络 用于 主分馏塔粗汽油干点软测量的结构当采用前向网络时 的网络结构与的网络结构相同 所不同的只是学习算法 三层前向网络的结构如图 所示 在 中 先以 的各连接权值和各阈值构成每一微粒的位置参数 根据目标函数计算各微粒的适应值 再用 算法搜索 的最佳权值和最优阈值 一旦搜索完毕 最优微粒的位置就是 的最佳连接权值和最优阈值的组合图三层前向网络结构第 期陈国初等 增强型微粒群优化算法及其在软测量中的应用图中为神经网络的输入为神经元的输入权重和为神经元的输出为神经网络的输出上标为样本号假如输入层节点数为中间层节点数为输出层节点数为输入层节点到中间层节点的连接权值为中间层节点神经元的阈值为中间层节点到输出层节点的连接权值为输出层节点神经元的阈值为则微粒的维数为学习算法流程初始化设置神经网络的结构传递函数目标函数等初始化设置微粒群的规模参数维数惯性权值加速系数最大允许迭代次数或适应值误差限各微粒的初始位置和初始速度等前向计算神经网络直至输出并按预定准则评价各微粒的初始适应值根据式计算惯性权值根据式计算各微粒新的速度判断各微粒的速度如有必要则重新初始化微粒速度对各微粒新的速度进行限幅处理根据式计算各微粒新的位置并对各微粒新的位置进行限幅处理前向计算神经网络直至输出并按预定准则重新评价各微粒的适应值比较每个微粒的当前适应值和历史最好适应值若当前适应值更优则令当前适应值为该微粒历史最好适应值并保存该微粒的位置为其个体历史最好位置比较群体所有微粒的当前适应值和群体历史最好适应值若当前适应值更优则令当前适应值为历史全局最好适应值并保存历史全局最优位置对每一步的最好微粒和最差微粒进行处理若满足停止条件则搜索停止输出历史全局最优位置即为所求神经网络的最佳权值和最优阈值否则返回继续搜索基于的粗汽油干点软测量主分馏塔工艺简介本文以某万吨年的催化裂化装置为背景建立其主分馏塔粗汽油干点软测量模型主分馏塔是的主要分离设备塔的进料直接来自催化裂化反应器其中包括干气液化气汽油柴油循环油以及油浆等这些反应产物进入分馏塔底部与上部回流的循环油浆逆流接触被冷却洗涤后进入第一层塔板经过塔顶循环一中循环二中循环以及塔底循环最终分离得到富气粗汽油柴油回炼油及油浆其工艺流程示意如图所示图主分馏塔工艺流程示意基于的粗汽油干点软测量模型将用于主分馏塔粗汽油干点的软测量建模构建出基于的主分馏塔粗汽油干点软测量模型通过对样本数据的主元分析对主分馏塔的工艺机理分析以及多次测试最终确定本文的软测量模型为由塔顶出口压力塔顶油气出口温度塔顶回流温度顶回流抽出温度层温度层温度一中返塔温度油气进料温度一中回流流量共个输入信号中间层为个节点输出信号为粗汽油干点构成的结构为的神经网络神经元的传递函数均选用双曲正切函数模型的目标函数为其中为粗汽油干点的实际值为粗汽油干点的模型计算值为样本号为样本总数在用寻找神经网络的最佳权值和最优阈值时各参数确定如下微粒个数为最大允许迭代次数为误差限为参数维数为惯性权值从按余弦规律衰变到加速系数均为为了便于比较本文还用算法来训练神经网络模型结构神经元传递函数等与模型完全相同算法的学习速率为动量因子为研究结果与分析比较训练过程与学习结果分析采用经过检错滤波归一化预处理的组训练样本对模型和模型进行训练两种模型学习结果的对比如表所示由表可以看出两种模型的预测值与化验值的拟合程度较好训练过程满足要求并且控制与决策第卷表两种模型学习结果对比模型指标模型模型所占百分比所占百分比均方差绝对误差平均值模型的拟合性能优于模型检验结果与分析采用同样经检错滤波归一化预处理的组未参加训练的检验样本对模型和模型进行检验两种模型检验结果的对比如表所示检验结果与实际化验结果的对比如图所示表两种模型检验结果对比模型指标模型模型所占百分比所占百分比均方差绝对误差平均值图两种模型检验结果对比由表和图可以看出两种模型的外推性较好模型具有较高的预测精度并且模型的外推性能优于模型两种模型性能比较算法在寻找最优权值和最优阈值时单一初始值以梯度下降模式进行而是以一群微粒即很多初始值采用依据自身经验并结合群体经验的有导向的随机搜索模式进行对复杂的炼油装置建立产品质量软测量模型时算法陷入局部极小的概率大大降低比算法更容易找到全局最优解如果模型结构传递函数和样本数据相同基于的模型和基于的模型都能找到最优参数则两种模型的性能拟合性能和外推性能相当算法在训练时反向调节权值采用梯度下降模式需要求出神经元传递函数和目标函数的导数导致它对目标函数和传递函数都有要求隐含层数也不宜过多而在搜索时采用依据自身经验并结合群体经验的随机搜索模式无需求导计算对神经网络的层数模型的目标函数和传递函数等没有限制因而应用更为灵活方便并且范围大为拓宽结语本文提出的是一种改进的它能有效地搜索到全局最优解优化效率和优化性能较有明显的提高将用于粗汽油干点软测量得到的基于的软测量模型比基于的软测量模型具有更高的精度和更好的性能为实现炼油装置产品质量的直接控制进而实现综合控制提供了有利的依据参考文献V MqT俞金寿等软测量技术及其在石油化工中的应用M北京化学工业出版社T M L M Mk kA J林世雄石油炼制工程M第版北京石油工业出版社焦李成神经网络系统理论M西安西安电子科技大学出版社第期陈国初等增强型微粒群优化算法及其在软测量中的应用。