Spark_shell学习日志
常用shell脚本指令

常用shell脚本命令1、显示包含文字aaa的下一行的内容:sed -n '/aaa/{n;p;}' filename2、删除当前行与下一行的内容:sed -i '/aaa/{N;d;}' filename3、删除当前行与下两行的内容:sed -i '/aaa/{N;N;d;}' filename依次类推,删除三行,则为{N;N;N;d;},分析知:N为next4、得出以空格为分割的字符串中单词的个数,即统计个数:awk ' { print NF } '如显示字符串VALUE中的单词个数,其中VALUE为:aaa bbb ccc ddd ee f则执行 echo $VALUE | awk ' { print NF } ' 后的结果为65、在linux中建立一个文件与另一文件的链接,即符号链接ln -s /var/named/chroot/etc/named.conf named.conf这要就建立了当前目录的文件named.conf对/var/named/chroot/etc/named.conf 的符号链接。
即操作named.conf就意味着操作实际文件/var/named/chroot/etc/named.conf ,这时用ll命令查看的结果如:lrwxrwxrwx 1 root root 32 Mar 22 12:29 named.conf ->/var/named/chroot/etc/named.conf注意:当用sed来通过named.conf来删除一部分信息时,会将符号链接的关系丢掉,即会将named.conf变成一个实际文件。
所以需对实际文件进行删除操作。
6、显示指定字符范围内的内容:如:显示文件test.txt中字符#test begin与#test end之间所有的字符sed -n "/#test begin/,/#test end/p" test.txt或 awk "/#test begin/,/#test end/" test.txt在日常系统管理工作中,需要编写脚本来完成特定的功能,编写shell脚本是一个基本功了!在编写的过程中,掌握一些常用的技巧和语法就可以完成大部分功能了,也就是2/8原则.1. 单引号和双引号的区别单引号与双引号的最大不同在于双引号仍然可以引用变量的内容,但单引号内仅是普通字符,不会作变量的引用,直接输出字符窜。
shell脚本100例、练习使用

shell脚本100例、练习使⽤1、编写hello world脚本#!/bin/bashecho"hello world"2、通过位置变量创建linux系统账户和密码#!/bin/bash#$1是执⾏脚本第⼀个参数 $2是执⾏脚本第⼆个参数useradd "$1"echo"$2" | passwd --stdin "$1"#测试脚本[root@template-host sh1]# sh2.sh aaa 123Changing password for user aaa.passwd: all authentication tokens updated successfully.#测试登录[root@template-host sh1]# su - aaa[aaa@template-host ~]$3、每周五使⽤tar命令备份 /var/log下的所有⽇志⽂件#!/bin/bashtar -czPf log-`date +%y%m%d`.tar.gz /var/log #加P是因为如果不加会出现错误:tar: Removing leading `/' from member names date和+之间注意有空格。
修改系统参数[root@template-host sh1]# crontab -e00 03 * * 5 /data/sh1/3.sh4、⼀键部署LNMP(RPM包版本)#!/bin/bash#此脚本需要提前配置yum源,否则⽆法配置成功。
本脚本使⽤于7.4yum -y install httpdyum -y install mariadb mariadb-devel mariadb-serveryum -y install php php-mysqlsystemctl start httpd mariadb #启动httpd、mariadbsystemctl enable httpd mariadb #加⼊开机⾃启动systemctl status httpd mariadb #查看是否成功5、实时监控本机硬盘内存剩余空间,剩余内存空间⼩于500M,根分区剩余空间⼩于1000M时,发送警报信息到命令⾏#!bin/bash#提取分区剩余空间单位:kbdisk_size=$(df / | awk'/\//{print $4}')#提取内存空间单位Mmem_size=$(free -m | awk'/Mem/{print $4}')while :doif [ $disk_size -le 512000 -o $mem_size -le 1024 ];thenecho"警报:资源不⾜"sleep5fidone6、随机⽣成⼀个100以内的随机数,提⽰⽤户猜数字,提⽰⽤户猜⼤了、猜⼩了、猜对了,直⾄⽤户猜对,脚本结束。
Spark实践——用Scala和Spark进行数据分析

Spark实践——⽤Scala和Spark进⾏数据分析本⽂基于《Spark ⾼级数据分析》第2章⽤Scala和Spark进⾏数据分析。
完整代码见1.获取数据集数据集来⾃加州⼤学欧⽂分校机器学习资料库(UC Irvine Machine Learning Repository),这个资料库为研究和教学提供了⼤量⾮常好的数据源,这些数据源⾮常有意义,并且是免费的。
我们要分析的数据集来源于⼀项记录关联研究,这项研究是德国⼀家医院在 2010 年完成的。
这个数据集包含数百万对病⼈记录,每对记录都根据不同标准来匹配,⽐如病⼈姓名(名字和姓⽒)、地址、⽣⽇。
每个匹配字段都被赋予⼀个数值评分,范围为 0.0 到 1.0,分值根据字符串相似度得出。
然后这些数据交由⼈⼯处理,标记出哪些代表同⼀个⼈哪些代表不同的⼈。
为了保护病⼈隐私,创建数据集的每个字段原始值被删除了。
病⼈的 ID、字段匹配分数、匹配对标⽰(包括匹配的和不匹配的)等信息是公开的,可⽤于记录关联研究下载地址:1. (需FQ)2. (已解压,block_1.csv 到 block_10.csv)2.设置Spark运⾏环境,读取数据读取数据集3.处理数据⾸先按 is_match 字段聚合数据,有两种⽅式可以进⾏数据聚合,⼀是使⽤ groupby 函数,⼆是使⽤ Spark Sql之后使⽤ describe 函数获取每个字段的最值,均值等信息// 获取每⼀列的最值,平均值信息val summary = parsed.describe()summary.show()summary.select("summary", "cmp_fname_c1", "cmp_fname_c2").show()按此⽅式获取匹配记录和不匹配记录的 describe// 获取匹配和不匹配的信息val matches = parsed.where("is_match = true")val misses = parsed.filter($"is_match" === false)val matchSummary = matches.describe()val missSummary = misses.describe()matchSummary .show()missSummary .show()可以看到这个数据不⽅便进⾏操作,可以考虑将其转置,⽅便使⽤sql对数据进⾏分析。
学习笔记_cshell
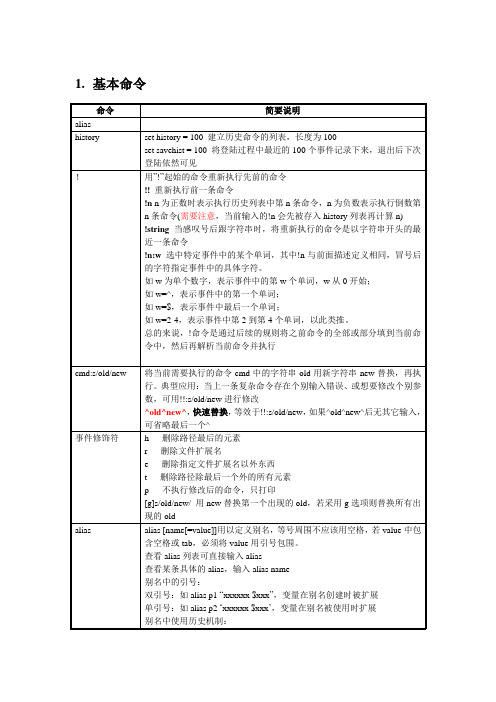
1.基本命令2.表达式表达式可由常量、变量和以下运算符组成,其中部分是涉及文件而不是数值表达式遵守以下规则:1)shell将丢失参数或零参数看作是0;2)所有的结果都是十进制数;3)除了!=和==外,运算符的参数都是数字;4)用户必须将表达式的每个元素与比邻的元素用空格分开,除非相邻元素是&、/、<、>等。
3.shel变量格式序列结果%U 命令运行用户代码所消耗的时间,单位是C P U秒(用户模式)%S 命令运行系统代码所消耗的时间,单位是C P U秒(核心模式)%E 命令所消耗的Wa l l时钟时间(整个时间)%P 任务周期内C P U所耗费的时间百分比,按照( % U + % S ) / % E计算%W 命令进程交换到磁盘的次数%X 命令使用的平均共享代码内存量,单位是千字节%D 命令使用的数据代码内存量,单位是千字节%K 命令使用整个内存内存量,就是% X + % D,单位是千字节%M 命令使用的最大内存量,单位是千字节%F 主页错误数(不得不脱离磁盘读取的内存页)%I 输入操作数%O 输出操作数作为开头的shell变量4.控制结构if(expression) simple-command只对简单命令起作用,对管道或命令列表无效。
可以用if….then控制结构来执行更复杂的命令除逻辑表达式外,用户可以用表达式来返回基于文件状态的值如下:如果指定的文件不存在或不可访问,csh将表达式的值算作0。
否则如果测试结果是true,则表达式的值为1;如果为false,则表达式的值为0。
goto labelgoto命令将控制传送给开始于label的表达式。
onintr label中断处理当用户在脚本执行过程中按下中断键,shell将把控制传递给以label:开始的语句。
该语句可以让用户在其被中断时正常终止脚本。
if…then…else形式1if(expression) thencommandsendif形式2if(expression) thencommandselsecommandsendif形式3if(expresstion) thencommandselse if(expresstion) thencommands...elsecommandsendifforeachforeach loop-index(argument-list)commandsendwhilewhile(expresstion)commandsendbreak/continue可以用break中断foreach或while,这些语句在传递控制前执行命令行中剩下的命令。
hdp 常用命令

hdp 常用命令HDP常用命令HDP(Hortonworks Data Platform)是一套开源的大数据平台,提供了一系列常用命令来管理和操作数据。
本文将介绍HDP常用命令的使用方法和注意事项,帮助读者更好地理解和应用HDP。
一、HDFS命令1. hdfs dfs -ls:列出HDFS中的文件和目录。
该命令用于查看HDFS中的文件结构,可以查看文件的权限、大小、修改时间等信息。
2. hdfs dfs -mkdir:在HDFS中创建目录。
使用该命令可以在HDFS中创建新的目录,方便组织和管理文件。
3. hdfs dfs -put:将本地文件上传到HDFS中。
该命令可以将本地文件复制到HDFS中,实现数据的备份和共享。
4. hdfs dfs -get:将HDFS中的文件下载到本地。
使用该命令可以将HDFS中的文件复制到本地,方便进行数据分析和处理。
5. hdfs dfs -rm:删除HDFS中的文件或目录。
该命令用于删除HDFS中的文件或目录,需要谨慎操作,避免误删数据。
二、YARN命令1. yarn application -list:列出YARN中正在运行的应用程序。
该命令可以查看当前YARN集群中正在运行的应用程序,包括应用程序的ID、名称、状态等信息。
2. yarn application -kill:终止正在运行的应用程序。
使用该命令可以终止指定的应用程序,可以通过应用程序的ID或名称来指定要终止的应用程序。
3. yarn logs -applicationId:查看应用程序的日志。
该命令用于查看指定应用程序的日志信息,可以帮助用户排查应用程序运行中的问题。
三、Hive命令1. hive -e "SQL语句":执行Hive中的SQL语句。
该命令可以直接在命令行中执行Hive中的SQL语句,方便用户进行数据查询和分析。
2. hive -f "脚本文件":执行Hive脚本。
Spark经典论文笔记---ResilientDistributedDatasets:AF。。。

Spark经典论⽂笔记---ResilientDistributedDatasets:AF。
Spark 经典论⽂笔记Resilient Distributed Datasets : A Fault-Tolerant Abstraction for In-Memory Cluster Computing为什么要设计spark现在的计算框架如Map/Reduce在⼤数据分析中被⼴泛采⽤,为什么还要设计新的spark?Map/Reduce提供了⾼级接⼝可以⽅便快捷的调取计算资源,但是缺少对分布式内存有影响的抽象。
这就造成了计算过程中需要在机器间使⽤中间数据,那么只能依靠中间存储来保存中间结果,然后再读取中间结果,造成了时延与IO性能的降低。
虽然有些框架针对数据重⽤提出了相应的解决办法,⽐如Pregel针对迭代图运算设计出将中间结果保存在内存中,HaLoop提供了迭代Map/Reduce的接⼝,但是这些都是针对特定的功能设计的不具备通⽤性。
针对以上问题,Spark提出了⼀种新的数据抽象模式称为RDD(弹性分布式数据集),RDD是容错的并⾏的数据结构,并且可以让⽤户显式的将数据保存在内存中,并且可以控制他们的分区来优化数据替代以及提供了⼀系列⾼级的操作接⼝。
RDD数据结构的容错机制设计RDD的主要挑战在与如何设计⾼效的容错机制。
现有的集群的内存的抽象都在可变状态(啥是可变状态)提供了⼀种细粒度(fine-grained)更新。
在这种接⼝条件下,容错的唯⼀⽅法就是在不同的机器间复制内存,或者使⽤log⽇志记录更新,但是这两种⽅法对于数据密集(data-intensive⼤数据)来说都太昂贵了,因为数据的复制及时传输需要⼤量的带宽,同时还带来了存储的⼤量开销。
与上⾯的系统不同,RDD提供了⼀种粗粒度(coarse-grained)的变换(⽐如说map,filter,join),这些变换对数据项应⽤相同的操作。
Spark机器学习库MLlib编程实践
Spark机器学习库MLlib编程实践
⼀、实验⽬的
(1)通过实验掌握基本的 MLLib 编程⽅法;
(2)掌握⽤ MLLib 解决⼀些常见的数据分析问题,包括数据导⼊、成分分析和分类和预测等。
⼆、实验平台
操作系统:Ubuntu16.04
JDK 版本:1.7 或以上版本
Spark 版本:2.1.0
数据集:下载 Adult 数据集(/ml/datasets/Adult),该数据集也可以直接到本教程官⽹的“下载专区”的“数据集”中下载。
数据从美国 1994 年⼈⼝普查数据库抽取⽽来,可⽤来预测居民收⼊是否超过 50K$/year。
该数据集类变量为年收⼊是否超过50k$,属性变量包含年龄、⼯种、学历、职业、⼈种等重要信息,值得⼀提的是,14 个属性变量中有 7 个类别型变量。
三、实验内容和要求
1.数据导⼊
从⽂件中导⼊数据,并转化为 DataFrame。
2.进⾏主成分分析(PCA)
对 6 个连续型的数值型变量进⾏主成分分析。
PCA(主成分分析)是通过正交变换把⼀组相关变量的观测值转化成⼀组线性⽆关的变量值,即主成分的⼀种⽅法。
PCA 通过使⽤主成分把特征向量投影到低维空间,实现对特征向量的降维。
请通过 setK()⽅法将主成分数量设置为 3,把连续型的特征向量转化成⼀个 3 维的主成分。
3.训练分类模型并预测居民收⼊在主成分分析的基础上,采⽤逻辑斯蒂回归,或者决策树模型预测居民收⼊是否超过50K;对 Test 数据集进⾏验证。
4.超参数调优
利⽤ CrossValidator 确定最优的参数,包括最优主成分 PCA 的维数、分类器⾃⾝的参数等。
Quick Start - Spark 3.5.1 Documentation
Quick Start - Spark 3.5.1 Documentation!"Interactive Analysis with the Spark Shell#"Basics#"More on Dataset Operations#"Caching!"Self-Contained Applications!"Where to Go from HereThis tutorial provides a quick introduction to using Spark. We will first introduce the API through Spark’s interactive shell (in Python or Scala), then show how to write applications in Java, Scala, and Python.To follow along with this guide, first, download a packaged release of Spark from the Spark website. Since we won’t be using HDFS, you can download a package for any version of Hadoop.Note that, before Spark 2.0, the main programming interface of Spark was the Resilient Distributed Dataset (RDD). After Spark 2.0, RDDs are replaced by Dataset, which is strongly-typed like an RDD, but with richer optimizations under the hood. The RDD interface is still supported, and you can get a more detailed reference at the RDD programming guide. However, we highly recommend you to switch to use Dataset, which has better performance than RDD. See the SQL programming guide to get more information about Dataset. Interactive Analysis with the Spark ShellBasicsSpark’s shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively. It is available in either Scala (which runs on the Java VM and is thus a good way to use existing Java libraries) or Python. Start it by running the following in the Spark directory:!"!"Or if PySpark is installed with pip in your current environment:Spark’s primary abstraction is a distributed collection of items called a Dataset. Datasets can be created from Hadoop InputFormats (such as HDFS files) or by transforming other Datasets. Due to Python’s dynamic nature, we don’t need the Dataset to be strongly-typed in Python. As a result, all Datasets in Python are Dataset[Row], and we call it DataFrame to be consistent with the data frame concept in Pandas and R. Let’s make a new DataFrame from the text of the README file in the Spark source directory:>>>textFile=spark.read.text("README.md")You can get values from DataFrame directly, by calling some actions, or transform the DataFrame to get a new one. For more details, please read the API doc.>>>textFile.count()# Number of rows in this DataFrame126>>>textFile.first()# First row in this DataFrameRow(value=u'# Apache Spark')Now let’s transform this DataFrame to a new one. We call filter to return a new DataFrame with a subset of the lines in the file.>>>linesWithSpark=textFile.filter(textFile.value.contains("Spark"))We can chain together transformations and actions:>>>textFile.filter(textFile.value.contains("Spark")).count()# How many lines contain "Spark"?15Spark’s primary abstraction is a distributed collection of items called a Dataset. Datasets can be created from Hadoop InputFormats (such as HDFS files) or by transforming other Datasets. Let’s make a new Dataset from the text of the README file in the Spark source directory: scala>val textFile=spark.read.textFile("README.md")textFile:org.apache.spark.sql.Dataset[String]=[value:string]You can get values from Dataset directly, by calling some actions, or transform the Dataset to get a new one. For more details, please read the API doc.scala>textFile.count()// Number of items in this Datasetres0:Long=126// May be different from yours as README.md will change over time, similar to other outputsscala>textFile.first()// First item in this Datasetres1:String=#Apache SparkNow let’s transform this Dataset into a new one. We call filter to return a new Dataset with a subset of the items in the file.scala>val linesWithSpark=textFile.filter(line=>line.contains("Spark"))linesWithSpark:org.apache.spark.sql.Dataset[String]=[value:string]We can chain together transformations and actions:scala>textFile.filter(line=>line.contains("Spark")).count()// How many lines contain "Spark"?res3:Long=15More on Dataset OperationsDataset actions and transformations can be used for more complex computations. Let’s say we want to find the line with the most words:!"!">>>from pyspark.sql import functions as sf>>>textFile.select(sf.size(sf.split(textFile.value,"\s+")).name("numWords")).agg(sf.max(sf.col("numWords"))).collect() [Row(max(numWords)=15)]This first maps a line to an integer value and aliases it as “numWords”, creating a new DataFrame. agg is called on that DataFrame to find the largest word count. The arguments to select and agg are both Column, we can use df.colName to get a column from a DataFrame. We can also import pyspark.sql.functions, which provides a lot of convenient functions to build a new Column from an old one.One common data flow pattern is MapReduce, as popularized by Hadoop. Spark can implement MapReduce flows easily: >>>wordCounts=textFile.select(sf.explode(sf.split(textFile.value,"\s+")).alias("word")).groupBy("word").count() Here, we use the explode function in select, to transform a Dataset of lines to a Dataset of words, and then combine groupBy and count to compute the per-word counts in the file as a DataFrame of 2 columns: “word” and “count”. To collect the word counts in our shell, we can call collect:>>>wordCounts.collect()[Row(word=u'online',count=1),Row(word=u'graphs',count=1),...]scala>textFile.map(line=>line.split(" ").size).reduce((a,b)=>if(a>b)a else b)res4:Int=15This first maps a line to an integer value, creating a new Dataset. reduce is called on that Dataset to find the largest word count. The arguments to map and reduce are Scala function literals (closures), and can use any language feature or Scala/Java library. For example, we can easily call functions declared elsewhere. We’ll use Math.max() function to make this code easier to understand: scala>import ng.Mathimport ng.Mathscala>textFile.map(line=>line.split(" ").size).reduce((a,b)=>Math.max(a,b))res5:Int=15One common data flow pattern is MapReduce, as popularized by Hadoop. Spark can implement MapReduce flows easily: scala>val wordCounts=textFile.flatMap(line=>line.split(" ")).groupByKey(identity).count()wordCounts:org.apache.spark.sql.Dataset[(String, Long)]=[value:string, count(1):bigint]Here, we call flatMap to transform a Dataset of lines to a Dataset of words, and then combine groupByKey and count to compute the per-word counts in the file as a Dataset of (String, Long) pairs. To collect the word counts in our shell, we can call collect: scala>wordCounts.collect()res6:Array[(String, Int)]=Array((means,1),(under,2),(this,3),(Because,1),(Python,2),(agree,1),(cluster.,1),...) CachingSpark also supports pulling data sets into a cluster-wide in-memory cache. This is very useful when data is accessed repeatedly, such as when querying a small “hot” dataset or when running an iterative algorithm like PageRank. As a simple example, let’s mark our linesWithSpark dataset to be cached:!"!">>>linesWithSpark.cache()>>>linesWithSpark.count()15>>>linesWithSpark.count()15It may seem silly to use Spark to explore and cache a 100-line text file. The interesting part is that these same functions can be used on very large data sets, even when they are striped across tens or hundreds of nodes. You can also do this interactively by connecting bin/pyspark to a cluster, as described in the RDD programming guide.scala>linesWithSpark.cache()res7:linesWithSpark.type=[value:string]scala>linesWithSpark.count()res8:Long=15scala>linesWithSpark.count()res9:Long=15It may seem silly to use Spark to explore and cache a 100-line text file. The interesting part is that these same functions can be used on very large data sets, even when they are striped across tens or hundreds of nodes. You can also do this interactively by connecting bin/spark-shell to a cluster, as described in the RDD programming guide.Self-Contained ApplicationsSuppose we wish to write a self-contained application using the Spark API. We will walk through a simple application in Scala (with sbt), Java (with Maven), and Python (pip).!"!"!"Now we will show how to write an application using the Python API (PySpark).If you are building a packaged PySpark application or library you can add it to your setup.py file as:install_requires=['pyspark==3.5.1']As an example, we’ll create a simple Spark application, SimpleApp.py:"""SimpleApp.py"""from pyspark.sql import SparkSessionlogFile="YOUR_SPARK_HOME/README.md"# Should be some file on your systemspark=SparkSession.builder.appName("SimpleApp").getOrCreate()logData=spark.read.text(logFile).cache()numAs=logData.filter(logData.value.contains('a')).count()numBs=logData.filter(logData.value.contains('b')).count()print("Lines with a: %i, lines with b: %i"%(numAs,numBs))spark.stop()This program just counts the number of lines containing ‘a’ and the number containing ‘b’ in a text file. Note that you’ll need to replace YOUR_SPARK_HOME with the location where Spark is installed. As with the Scala and Java examples, we use a SparkSession to create Datasets. For applications that use custom classes or third-party libraries, we can also add code dependencies to spark-submit through its --py-files argument by packaging them into a .zip file (see spark-submit --help for details). SimpleApp is simple enough that we do not need to specify any code dependencies.We can run this application using the bin/spark-submit script:# Use spark-submit to run your application$ YOUR_SPARK_HOME/bin/spark-submit \--master local[4] \SimpleApp.py...Lines with a: 46, Lines with b: 23If you have PySpark pip installed into your environment (e.g., pip install pyspark), you can run your application with the regular Python interpreter or use the provided ‘spark-submit’ as you prefer.# Use the Python interpreter to run your application$ python SimpleApp.py...Lines with a: 46, Lines with b: 23We’ll create a very simple Spark application in Scala–so simple, in fact, that it’s named SimpleApp.scala:/* SimpleApp.scala */import org.apache.spark.sql.SparkSessionobject SimpleApp{def main(args:Array[String]):Unit={val logFile="YOUR_SPARK_HOME/README.md"// Should be some file on your systemval spark=SparkSession.builder.appName("Simple Application").getOrCreate()val logData=spark.read.textFile(logFile).cache()val numAs=logData.filter(line=>line.contains("a")).count()val numBs=logData.filter(line=>line.contains("b")).count()println(s"Lines with a: $numAs, Lines with b: $numBs")spark.stop()}}Note that applications should define a main() method instead of extending scala.App. Subclasses of scala.App may not work correctly.This program just counts the number of lines containing ‘a’ and the number containing ‘b’ in the Spark README. Note that you’ll need to replace YOUR_SPARK_HOME with the location where Spark is installed. Unlike the earlier examples with the Spark shell, which initializes its own SparkSession, we initialize a SparkSession as part of the program.We call SparkSession.builder to construct a SparkSession, then set the application name, and finally call getOrCreate to get the SparkSession instance.Our application depends on the Spark API, so we’ll also include an sbt configuration file, build.sbt, which explains that Spark is a dependency. This file also adds a repository that Spark depends on:name:="Simple Project"version:="1.0"scalaVersion:="2.12.18"libraryDependencies+="org.apache.spark"%%"spark-sql"%"3.5.1"For sbt to work correctly, we’ll need to layout SimpleApp.scala and build.sbt according to the typical directory structure. Once that is in place, we can create a JAR package containing the application’s code, then use the spark-submit script to run our program.# Your directory layout should look like this$ find .../build.sbt./src./src/main./src/main/scala./src/main/scala/SimpleApp.scala# Package a jar containing your application$ sbt package...[info] Packaging {..}/{..}/target/scala-2.12/simple-project_2.12-1.0.jar# Use spark-submit to run your application$ YOUR_SPARK_HOME/bin/spark-submit \--class"SimpleApp"\--master local[4] \target/scala-2.12/simple-project_2.12-1.0.jar...Lines with a: 46, Lines with b: 23This example will use Maven to compile an application JAR, but any similar build system will work.We’ll create a very simple Spark application, SimpleApp.java:/* SimpleApp.java */import org.apache.spark.sql.SparkSession;import org.apache.spark.sql.Dataset;public class SimpleApp{public static void main(String[]args){String logFile="YOUR_SPARK_HOME/README.md";// Should be some file on your systemSparkSession spark=SparkSession.builder().appName("Simple Application").getOrCreate();Dataset<String>logData=spark.read().textFile(logFile).cache();long numAs=logData.filter(s->s.contains("a")).count();long numBs=logData.filter(s->s.contains("b")).count();System.out.println("Lines with a: "+numAs+", lines with b: "+numBs);spark.stop();}}This program just counts the number of lines containing ‘a’ and the number containing ‘b’ in the Spark README. Note that you’ll need to replace YOUR_SPARK_HOME with the location where Spark is installed. Unlike the earlier examples with the Spark shell, which initializes its own SparkSession, we initialize a SparkSession as part of the program.To build the program, we also write a Maven pom.xml file that lists Spark as a dependency. Note that Spark artifacts are tagged with a Scala version.<project><groupId>edu.berkeley</groupId><artifactId>simple-project</artifactId><modelVersion>4.0.0</modelVersion><name>Simple Project</name><packaging>jar</packaging><version>1.0</version><dependencies><dependency><!-- Spark dependency --><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.5.1</version><scope>provided</scope></dependency></dependencies></project>We lay out these files according to the canonical Maven directory structure:$ find ../pom.xml./src./src/main./src/main/java./src/main/java/SimpleApp.javaNow, we can package the application using Maven and execute it with ./bin/spark-submit.# Package a JAR containing your application$ mvn package...[INFO] Building jar: {..}/{..}/target/simple-project-1.0.jar# Use spark-submit to run your application$ YOUR_SPARK_HOME/bin/spark-submit \--class"SimpleApp"\--master local[4] \target/simple-project-1.0.jar...Lines with a: 46, Lines with b: 23Other dependency management tools such as Conda and pip can be also used for custom classes or third-party libraries. See also Python Package Management.Where to Go from HereCongratulations on running your first Spark application!!"For an in-depth overview of the API, start with the RDD programming guide and the SQL programming guide, or see “Programming Guides” menu for other components.!"For running applications on a cluster, head to the deployment overview.!"Finally, Spark includes several samples in the examples directory (Scala, Java, Python, R). You can run them as follows: # For Scala and Java, use run-example:./bin/run-example SparkPi# For Python examples, use spark-submit directly:./bin/spark-submit examples/src/main/python/pi.py# For R examples, use spark-submit directly:./bin/spark-submit examples/src/main/r/dataframe.R。
Shell脚本-从入门到精通
ex4if.sh,chkperm.sh,chkperm2.sh, name_grep,tellme,tellme2,idcheck.sh
第22页,共74页。
ex4if.sh
#!/bin/bash # scriptname: ex4if.sh
# echo -n "Please input x,y: "
echo echo –e "Hello $LOGNAME, \c"
echo "it's nice talking to you." echo "Your present working directory is:" pwd # Show the name of present directory
echo
then
# 那么
commands1 # 执行语句块 commands1
elif expr2 # 若expr1 不真,而expr2 为真
then
# 那么
commands2 # 执行语句块 commands2
... ...
# 可以有多个 elif 语句
else
# else 最多只能有一个
commands4 # 执行语句块 commands4
\t 插入tab; \v 与\f相同; \\ 插入\字符; \nnn 插入nnn(八进制)所代表的ASCII字符; --help 显示帮助
--version 显示版本信息
第8页,共74页。
Shell 脚本举例
#!/bin/bash
# This script is to test the usage of read # Scriptname: ex4read.sh echo "=== examples for testing read ===" echo -e "What is your name? \c" read name echo "Hello $name" echo echo -n "Where do you work? "
大数据学习之路
大数据学习之路————一篇送给准备入行大数据的建议大数据学习线路是怎样的?需要学习哪些知识以及工作后工作内容有哪些?我这里通过这篇文章给大家分享一下大数据相关领域的学习线路和知识掌握情况,希望能够帮助到大家!大数据不是某个专业或一门编程语言,实际上它是一系列技术的组合运用。
有人通过下方的等式给出了大数据的定义。
大数据= 编程技巧+ 数据结构和算法+ 分析能力+ 数据库技能+ 数学+ 机器学习+ NLP + OS + 密码学+ 并行编程。
虽然这个等式看起来很长,需要学习的东西很多,但付出和汇报是成正比的,至少和薪资是成正比的。
有这么多知识需要学习,那么该怎么学?如何学?有人简单的将学习线路总结为:入门知识→Java 基础→Scala 基础→Hadoop 技术模块→Hadoop 项目实战→Spark 技术模块→大数据项目实战。
其实这是不准确的,因为大数据也是可以分方向的!点击链接加入群聊【大数据学习交流群】:我想告诉你,每一份坚持都是成功的累积,只要相信自己,总会遇到惊喜;我想告诉你,每一种活都有各自的轨迹,记得肯定自己,不要轻言放弃;我想告诉你,每一个清晨都是希望的伊始,记得鼓励自己,展现自信的魅力。
大数据的三个发展方向:平台搭建/优化/运维/监控、大数据开发/ 设计/ 架构、数据分析/挖掘。
我们先来看一下大数据的4V特征:数据量大,TB->PB数据类型繁多,结构化、非结构化文本、日志、视频、图片、地理位置等;商业价值高,但是这种价值需要在海量数据之上,通过数据分析与机器学习更快速的挖掘出来;处理时效性高,海量数据的处理需求不再局限在离线计算当中。
针对大数据的特点,我们需要掌握的重点知识如下:文件存储:Hadoop HDFS、Tachyon、KFS离线计算:Hadoop MapReduce、Spark流式、实时计算:Storm、Spark Streaming、S4、HeronK-V、NOSQL数据库:HBase、Redis、MongoDB资源管理:YARN、Mesos日志收集:Flume、Scribe、Logstash、Kibana消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid分布式协调服务:Zookeeper集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager数据挖掘、机器学习:Mahout、Spark MLLib数据同步:Sqoop任务调度:Oozie可以说多,也可以说简单。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Spark_shell学习日志——server版linux
Visint 15120408 李尔楠
环境及准备
启动
集群启动:spark-shell --master spark://Master1:7077
单机启动:spark-shell
将各种文件放入hdfs
例子:hadoop fs -put wordCount.txt /data/len/wordCount.txt
在shell中读取文件
val file=sc.textFile("hdfs://211.71.76.177:9000/data/len/wordCount.txt ")
基础类
类和对象
函数式编程
函数可以不依赖类对象和接口单独存在,函数可以作为函数的参数(高阶函数),函数
可以作为函数的返回值
函数赋值给变量
可见变量fun1_v也变成了函数类型,注意上图红色标记处的写法!
匿名函数
匿名函数即没有函数名的函数,可按红色框住的部分将函数赋值给一个变量。
语法:参数名称:类型 =>函数体
高阶函数
首先定义一个匿名函数,然后定义一个函数bigData,其中第一参数为参数为String返回值
为Unit的函数,第二个参数为字符串,函数体将第二个参数传入第一个参数的参数中。
Map函数就是一个典型的高阶函数。
高阶函数的返回值为函数
定义一个函数func_Returned,返回的结果是一个匿名函数,完成的功能是两个数相加,这
样当执行func_Returned时会返回一个Int的函数,用一个变量来接受这个返回值,然后继
续传参,可得到返回值函数的返回值。
如果在函数的函数体中,只使用一次函数的输入参数的值,可以将函数的输入参数的名称省
略,用“_”代替。
闭包
首先定义一个返回值为函数的函数,然后向该函数传参Spark,在该步操作中,content
是局部变量,在执行之后就被销毁,而在后面对返回值函数传参时,还用到了content,这
就超出了后面函数的执行范围,此时为闭包效果——函数执行完成后,其内部的变量依旧可
以被外界访问,这就是闭包,此处的外界只有像如上写法时才使用
Curried函数
一个函数如果有两个参数,则可以将其转换为2个函数,第一个函数接收第一个参数,
第二个接收第二个参数。
两种写法
Reduce
将前两个数相加然后作为第一个数与第三个数相加在作为第一个数与第四个相加………..
集合
一些典型的集合操作
模式匹配
对比java中的switch…case进行理解
按值进行匹配
Match…..case
对类型进行匹配
对集合进行模式匹配
case class
类型参数
泛型类
边界
上边界<:
第一行中的下划线“_”代表的内容被定义为CompressionCodec类型,或者是他的子类型。
所以下划线代表的内容可以定义为如上任何一种子类型。
下边界>:
即定义的泛型类必须为某类型或该类型的父类。
视图界定 View Bounds——<%
即通过隐式转换将一个内容适应于一个范围中,即某类或某类的子类
上下文bounds
这里调用bigger并没有传参数,参数是通过上下文隐式转换过来的