统计学贾俊平第八版
贾俊平 统计学 第3章 用统计量描述数据

3-6
第 3 章 用统计量描述数据
3.1 水平的度量
3.1.1 平均数 3.1.2 中位数和分位数 3.1.3 用哪个值代表一组数据?
3.1 水平的度量 3.1.1 平均数
统计学
STATISTICS (第四版)
平均数
(mean)
1. 2. 3. 4.
也称为均值,常用的统计量之一 消除了观测值的随机波动 易受极端值的影响 根据总体数据计算的,称为平均数,记为; 根据样本数据计算的,称为样本平均数, 记为x
2013-8-15
方法1:定义算法
方法2:较准确算法
(SPSS的算法)
3 - 19
统计学
STATISTICS (第四版)
四分位数的计算
(位置的确定)
n 1 2 1 2
方法3:
Q位置
其中[ ]表示中位数的位置取整。这样计算出的四分位数的 位置,要么是整数,要么在两个数之间0.5的位置上 方法4: Excel给出的四分位数位置的确定方法
对于k234该不等式的含义是至少有75的数据落在平均数加减2个标准差的范围之内至少有89的数据落在平均数加减3个标准差的范围之内至少有94的数据落在平均数加减4个标准差的范围之内323比较几组数据的离散程度离散系数32差异的度量离散系数coefficient标准差与其相应的均值之比对数据相对离散程度的测度消除了数据水平高低和计量单位的影响计算公式为离散系数例题分析例37评价哪名运动员的发挥更稳定发挥比较稳定的运动员是塞尔维亚的亚斯娜舍卡里奇和中国的郭文珺发挥不稳定的运动员蒙古的卓格巴德拉赫蒙赫珠勒和波兰的莱万多夫斯卡萨贡名运动员射击成绩的误差图例题分析graphserrorbarsimpledatachartaresummariesseparatevariables变量选入errorbarsbarsrepresentstandarddeviationsmultiplier框内输入所需的标准差倍数ok例子33分布形状的度量skewness统计学家kpearson于1895年首次提出
统计学(贾俊平)人大精品PPT课件

现象在不同时间上取值的平均数,又称序时平均数 说明现象在一段时期内所达到的一般水平 不同类型的时间序列有不同的计算方法
11 - 11
经济、管理类 基础课程
统计学
绝对数序列的序时平均数
(计算方法)
时期序列
n
计算公式:
Y Y1 Y2 Yn
Yi
i 1
n
n
【例11.1】 根据表11.1中的国内生产总值 序列,计算各年度的平均国内生产总值
3. 平均数时间序列
一系列平均数按时间顺序排列而成
11 - 9
经济、管理类 基础课程
统计学
时间序列的水平分析
11 - 10
经济、管理类 基础课程
统计学
发展水平与平均发展水平
(概念要点)
1. 发展水平
现象在不同时间上的观察值 说明现象在某一时间上所达到的水平 表示为Y1 ,Y2,… ,Yn 或 Y0 ,Y1 ,Y2 ,… ,Yn
2. 形式上由现象所属的时间和现象在不同时 间上的观察值两部分组成
3. 排列的时间可以是年份、季度、月份或其 他任何时间形式
11 - 6
经济、管理类 基础课程
统计学
时间序列
(一个例子)
年份
1990 1991 1992 1993 1994 1995 1996 1997 1998
11 - 7
表11- 1 国内生产总值等时间序列
经济、管理类 基础课程
统计学
时间序列的分类
1. 绝对数时间序列
一系列绝对数按时间顺序排列而成
时间序列中最基本的表现形式
反映现象在不同时间上所达到的绝对水平
分为时期序列和时点序列 • 时期序总量的排序
统计学贾俊平第8章 假设检验

两者都可以被选为null hypothesis
18
All rights reserved
假设的陈述
若FDA 选择以下的方式: H0:新药对于大众没有益处不应该上市 H1:新药对于大众有益处 此时药厂必须举证推翻H0,否则FDA不会核准 新药上市 由于这种假设方式,美国的新药上市过程十 分冗长,但好处为有害药物要上市十分困难
建立的原假设与备择假设应为
H0: 1000
H1: 1000
27
All rights reserved
双侧检验和单侧检验
假设
H0 H1
研究的问题
双侧检验 左侧检验 右侧检验
= 0
0
0
≠0
< 0
> 0
28
All rights reserved
H1: 1500
25
All rights reserved
双侧检验和单侧检验
一项研究表明,改进生产工艺后,会使产品的废 品率降低到2%以下。检验这一结论是否成立
研究者总是想证明自己的研究结论(废品率降 低)是正确的
备择假设的方向为“<”(废品率降低)
建立的原假设与备择假设应为
H0: 2%
13
All rights reserved
假设的陈述
备择假设 (alternative hypothesis)
与原假设对立的假设,也称“研究假设” 这与原假设为互斥 研究者想收集证据予以支持的假设。总是 有不等号: , 或 表示为 H1
例如,H1: < 某特定值 如 H1: < 3.5
4
All rights reserved
统计学贾俊平期末考试模拟试题二

模拟试题二. 单项选择题(每小题2 分,共20 分)一辆新购买的轿车,在正常行使条件下,一年内发生故障的次数及相应的概率如下表所示:故障次数()0123概率()正好发生1 次故障的概率为()A.B.C.D.要观察200 名消费者每月手机话费支出的分布状况,最适合的图形是()A.饼图B.条形图C.箱线图D.直方图从某种瓶装饮料中随机抽取10 瓶,测得每瓶的平均净含量为355 毫升。
已知该种饮料的净含量服从正态分布,且标准差为 5 毫升。
则该种饮料平均净含量的90%的置信区间为()A.B.C.D.根据最小二乘法拟合线性回归方程是使()A.B.C.D.项调查表明,大学生中因对课程不感兴趣而逃课的比例为20%。
随机抽取由200 名学生组成的一个随机样本,检验假设,,得到样本比例为。
检验统计量的值为()A.B.D.在实验设计中,将种“处理”随机地指派给试验单元的设计称为()A.试验单元B.完全随机化设计C.随机化区组设计D.因子设计某时间序列各期观测值依次为10、24、37、53、65、81,对这一时间序列进行预测适合的模型是()A.直线模型B.二次曲线模型C.指数曲线模型D.修正指数曲线模型在因子分析中,变量的共同度量反映的是()A.第个公因子被变量的解释的程度B.第个公因子的相对重要程度C.第个变量对公因子的相对重要程度D.变量的信息能够被第个公因子所解释的程度如果要检验两个独立总体的分布是否相同,采用的非参数检验方法是()A.Mann-Whitney 检验B.Wilcoxon 符号秩检验C.Kruskal-Wallis 检验D.Spearman 秩相关及其检验在二元线性回归方程中,偏回归系数的含义是()A.变动一个单位时,的平均变动值为B.变动一个单位时,因变量的平均变动值为C.在不变的条件下,变动一个单位时,的平均变动值为D.在不变的条件下,变动一个单位时,的平均变动值为价格(元)7658754需求量(公斤)75807060658590根据上表数据计算得:,,,。
统计学第四章习题答案 贾俊平
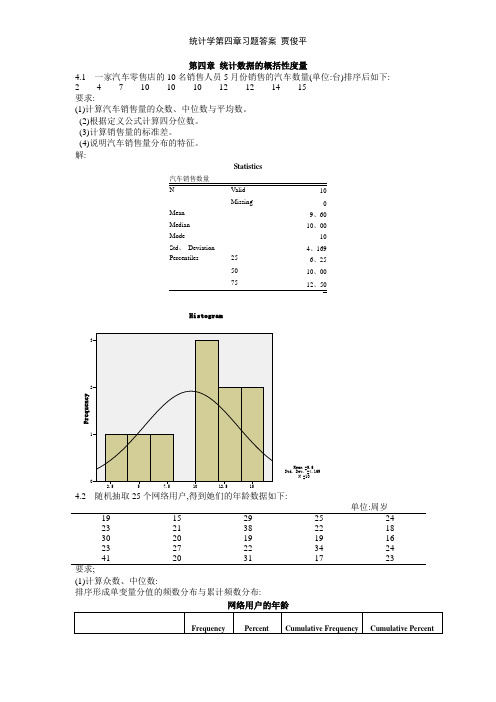
第四章 统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下: 2 4 7 10 10 10 12 12 14 15 要求:(1)计算汽车销售量的众数、中位数与平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量 10 Missing0 Mean 9、60 Median 10、00Mode10 Std 、 Deviation 4、169 Percentiles25 6、25 50 10、00 75单位:周岁19 15 29 25 24 23 21 38 22 18 30 20 19 19 16 23 27 22 34 24 41 20 3117 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布与累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6、25,因此Q1=19,Q3位置=3×25/4=18、75,因此Q3=27,或者,由于25与27都只有一个,因此Q3也可等于25+0、75×2=26、5。
(3)计算平均数与标准差;Mean=24、00;Std、Deviation=6、652(4)计算偏态系数与峰态系数:Skewness=1、080;Kurtosis=0、773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6、652、呈右偏分布。
如需瞧清楚分布形态,需要进行分组。
1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4、3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图::一种就是所有颐客都进入一个等待队列:另—种就是顾客在三千业务窗口处列队3排等待。
统计学PPT完整袁卫贾俊平

原始数据:指直接从各个调查单位搜集的、尚未经过 整理的统计数据资料,也称一手数据。
次级数据:指那些已经加工整理过的,往往是公开发表 的数据,也称二手数据。
如从报纸杂志、统计年鉴、会计报表上取得的数据 。
(四)数据的来源
1. 从政府机构、各种行业组织、公司和企业所公布的 数据中获取。
总体群数R=16 样本群数r=4 样本容量
A D E
B F G
CM L
J K
H
N P
O
I
LP HD
nndnpnl nh
适合:比简单随机抽样的方法能节约更多的成本,特别 当总体的分布地域非常辽阔 时。
四、有关数据调查的几个问题
调查的目的 判断调查误差的大小
调 登记性误差:登记、汇总、过录时产生的误差,
4. 进行一次调查。它对所调查人们的行为不进行任 何控制,仅提出诸如出生年月、爱好、消费习惯、对 某一事件的看法和其他特征方面的问题,然后对他们 回答的结果进行整理、编码、列表和分析。
调查方 案的主 要内容
确定调查目的 确定调查对象和调查单位 拟订调查提纲 确定调查时间
编制调查的组织计划
三、数据搜集的组织方式
连续型变量的数据可以取介于两个数 值之间的任意数值。
如销售额、经济增长率等。
3. 数据的四个等级 定类数据 也称定名数据,这种数据只对事物的某
种属性和类别进行具体的定性描述。
例如,对人口按性别划分为男性和女性 两类。
定类数据
能够进行的唯一运算是计数,即计算每一 个类型的频数或频率(即比重)。
定序数据,也称序列数据,是对事物所具 有的属性顺序进行描述。
查 误
以及无回答误差和测量误差等
贾俊平版统计学课件 第8章

▽与原假设对立的假设称备择假设,记为 H1 ,用 、 或 表示。 对于新生儿体重的例子,可以表示为
H 0 : 3190
H1 : 3190
(2)确定检验统计量及其分布
▽用于检验假设的统计量称为检验统计量
▽根据 H 0 及相应条件选择适当的统计量,并确定统计量
的分布 对于新生儿体重的例子,可利用 x 0 构造检验统计量. 若新生儿体重为正态分布 N ( , 2 ) ,且 已知,则在 H 0 为真 时,用 z 作为检验统计量,并且
H 0 : 3190 H1 : 3190
并已知 x 3210, 80, n 100 ,则
z0 x 0
n
3210 3190 80 100
2.5
于是
p 2Pz z0 2 0.00621 0.01242
双侧检验的P值
/ 2
/ 2 拒绝
▽犯第二类错误的概率为 。
表8-1 假设检验中各种可能结果的概率
实际情况
H 0 为真 H 0 不真
决策
接受 H 0
1
拒绝 H 0
1
假设检验中的两类错误(决策结果)
H0: 无罪
假设检验就好像一场审判过程 统计检验过程
陪审团审判
实际情况 裁决 无罪 无罪 有罪 正确 错误 有罪 错误 正确 接受H0 拒绝H0 决策
若p-值 /2, 不能拒绝 H0 若p-值 < /2, 拒绝 H0
8.1.6 假设检验的形式
研究的问题 假设
双侧检验
H0 H1
左侧检验
右侧检验
= 0 ≠0
贾俊平《统计学》第8章 假设检验

备择假设的方向为“ 备择假设的方向为“<”,称为左侧检验 备择假设的方向为“ 备择假设的方向为“>”,称为右侧检验
双侧检验与单侧检验
(假设的形式) 假设的形式)
以总体均值的检验为例
假设
原假设 备择假设
双侧检验
H0 : =0 H1 : ≠0
单侧检验 左侧检验
H0 : ≥0 H1 : <0
右侧检验
提出假设
(结论与建议) 结论与建议)
1. 原假设和备择假设是一个完备事件组,而且 原假设和备择假设是一个完备事件组, 相互对立
在一项假设检验中, 在一项假设检验中, 原假设和备择假设必有一 个成立, 个成立,而且只有一个成立
2. 先确定备择假设,再确定原假设 先确定备择假设, 3. 等号“=”总是放在原假设上 等号“ 4. 因研究目的不同,对同一问题可能提出不同 因研究目的不同, 的假设(也可能得出不同的结论) 的假设(也可能得出不同的结论)
1、某厂生产的化纤度服从正态分布, 纤维度的均值为1.4。某天测得25根纤维的 纤维度的均值为1.4。某天测得25根纤维的 均值为1.39,检验与原来设计的标准均值 均值为1.39,检验与原来设计的标准均值 相比是否有所变化,则假设形式是?
2、某一贫困地区估计营养不良人数高 达20%,然而有人认为这个比例实际上还 20%,然而有人认为这个比例实际上还 要高,要经验该说法是否正确,则假设形 式为?
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学贾俊平第八版
统计学是现代社会中非常重要的一门科学,贾俊平的统计学第八版是学习统计学的一本非常优秀的教材。
本文将从几个方面介绍贾俊平第八版的特点以及学习该教材的步骤。
一、贾俊平第八版的特点
1. 整合性:贾俊平第八版将统计学的各个分支融合在一起,形成了一个系统而完整的统计学体系。
2. 深入浅出:贾俊平第八版的语言简单易懂,通过丰富的实例和图表,帮助读者更好地理解统计学的各个概念和原理。
3. 应用性强:贾俊平第八版的内容充满了统计学在现实生活中的应用,能够帮助读者更好地应用统计学方法解决实际问题。
二、学习贾俊平第八版的步骤
1. 扎实基础:在学习统计学之前,要先掌握一些基础数学知识,如数据的集中趋势、离散程度、概率和统计分布等。
2. 系统学习:贾俊平第八版的内容比较系统完整,应该按照书中的章节顺序进行有条理地学习。
3. 查漏补缺:学习中如果遇到不懂的地方,可以通过网络搜索或参考其他统计学教材进行查漏补缺。
4. 做题巩固:做题是检验自己掌握程度的有效方式,大量做题可以帮助巩固学习的内容。
三、总结
贾俊平第八版的统计学是一部非常优秀的统计学教材,具有系统性、深入浅出和应用性强的特点。
对于学习统计学的人来说,应该掌握基础数学知识,系统有条理地学习,及时查漏补缺,做题巩固。
通过学习贾俊平第八版可以更好地掌握统计学的基本原理和应用技巧。