EViews 6.0 beta在面板数据模型估计中的应用
Eviews面板数据之随机效应模型

随机效应模型的估计原理说明与豪斯曼检验在面板数据的计量分析中,如果解释变量对被解释变量的效应不随个体和时间变化,并且解释被解释变量的信息不够完整,即解释变量中不包含一些影响被解释变量的不可观测的确定性因素,可以将模型设定为固定效应模型,采用反映个体特征或时间特征的虚拟变量(即知随个体变化或只随时间变化)或者分解模型的截距项来描述这些缺失的确定性信息。
但是,固定效应模型也存在一定的不足。
例如固定效应模型模型中包含许多虚拟变量时,减少了模型估计的自由度;实际应用中,固定效应模型的随机误差项难以满足模型的基本假设,易于导致参数的非有效估计。
更为重要的是,它只考虑了不完整的确定性信息对被解释变量的效应,而未包含不可观测的随机信息的效应。
为了弥补这一不足,Maddala(1971)将混合数据回归的随机误差项分解为截面随机误差分量、时间随机误差分量和个体时间随机误差分量三部分,讨论如下随机效应模型或双分量误差分解模型(1):12Kit k kit i t it k y x u v w ββ==++++∑ (1)2~(0,)i u u N σ表示个体随机误差分量; 2~(0,)t v v N σ表示时间随机误差分量;2~(0,)it w w N σ表示个体时间(或混合)随机误差分量。
如果模型(1)中只存在截面随机误差分量i u 而不存在时间随机误差分量t v ,则称为个体随机效应模型,否则称为个体时间小于模型。
或者称为但分了误差分解模型。
下面来介绍这两种模型:1.个体随机效应模型当利用面板数据研究拥有拥有充分多个体的总体经济特征时,若利用总体数据的固定效应模型就会损失巨大的自由度,使得个体截距项的估计不具有有效性。
这时,可以在总体中随机抽取N 个样本,利用这N 个样本的个体随机效应模型:12Kit k kit i itk y x u w ββ==+++∑ (2)推断总体的经济规律。
其中,个体随机误差项i u 是属于第i 个个体的随机干扰分量,并在整个时间范围(t=1,2,…,T)保持不变,其反映了不随时间变化的不可观测随机信息的效应。
eviews面板数据实例分析(包会)-

eviews面板数据实例分析(包会)-Eviews是一种流行的面板数据分析软件,广泛用于经济学及财务学领域。
本文将以一个面板数据实例为例,介绍Eviews的一些基本功能及应用。
数据说明本数据集为横截面面板数据,共包含11个国家(美国、加拿大、英国、法国、德国、意大利、荷兰、比利时、奥地利、瑞典、日本)在1970年至1986年间的年度数据。
变量说明如下:- gdpercap:人均GDP- invest:投资/GDP比率- consump:消费/GDP比率- inflation:通货膨胀率- popgrowth:人口增长率- literacy:成年人识字率- female:女性劳动力占比数据导入及面板设置首先,在Eviews中新建一个工作文件,并将数据导入。
打开数据文件后,我们可以看到数据已经被正确读入。
然后,我们需要将数据设为面板数据。
在Eviews中,选择“View”菜单下的“Structure of Workfile”选项,可以进入工作文件结构设置。
在弹出的窗口中,选择“Panel Data”选项,并按照数据的属性设置面板变量。
在本例中,我们选择“Country”作为单位维度,“Year”作为时间维度。
设置完成后,Eviews会自动进行面板数据检测。
检测结果显示,数据格式符合面板数据要求。
面板数据描述及汇总统计接下来,我们可以对数据进行初步的描述性统计和汇总统计。
选择“Quick”菜单下的“Descriptive Stats”选项,Eviews会自动生成数据的描述性统计报告,展示各变量在不同国家和不同年份的均值、标准差、最小值、最大值等基本信息。
我们也可以手动计算其他统计量。
例如,选择“Proc”菜单下的“Panel Data”选项,可以对选定的变量进行面板数据汇总统计。
下面是在Eviews中计算人均GDP和消费/GDP比率两个变量的面板均值统计结果:面板数据变量之间的相关性分析在分析面板数据时,我们通常需要考虑不同变量之间的相关性。
Eviews实验-面板数据
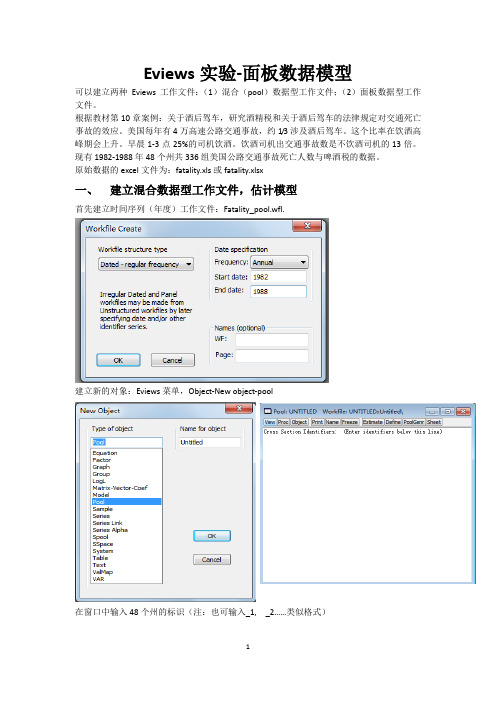
Eviews实验-面板数据模型可以建立两种Eviews工作文件:(1)混合(pool)数据型工作文件;(2)面板数据型工作文件。
根据教材第10章案例:关于酒后驾车,研究酒精税和关于酒后驾车的法律规定对交通死亡事故的效应。
美国每年有4万高速公路交通事故,约1/3涉及酒后驾车。
这个比率在饮酒高峰期会上升。
早晨1-3点25%的司机饮酒。
饮酒司机出交通事故数是不饮酒司机的13倍。
现有1982-1988年48个州共336组美国公路交通事故死亡人数与啤酒税的数据。
原始数据的excel文件为:fatality.xls或fatality.xlsx一、建立混合数据型工作文件,估计模型首先建立时间序列(年度)工作文件:Fatality_pool.wfl.建立新的对象:Eviews菜单,Object-New object-pool在窗口中输入48个州的标识(注:也可输入_1, _2……类似格式)在新建的混合数据库(Pool)窗口的工具栏中点击Sheet键(第2种路径是,点击View键,选Spreadsheet (stacked data)功能),从而打开Series List(列写序列名)窗口,定义时间序列变量“mrall? Beertax?”,其中“?”表示与marll和beertax相关的48个州标识。
点击OK键,从而打开混合数据库(Pool)窗口(图5)。
点击Edit+-键,使EViwes处于可编辑状态,用复制和粘贴的方法输入数据。
(提示:注意excel 数据中的排序)图所示为以时间为序的阵列式排列(stacked data)。
点击Order+-键,还可以变换为以截面为序的阵列式排列。
输入完成后的情形见图。
点击PoolGener可以通过公式用已有的变量生成新变量(注意:输入变量时,不要忘记带变量后缀“?”)如mrall为每万人死亡率,定义死亡人数:vfrall=10000*mrall。
建立新的页面,对1982年的数据进行分析。
面板数据eviews

1, 如果属于第i个个体,i 1, 2, ..., N , 其中 Di = 0, 其他,
个体固定效应模型(3)还可以用多方程表示为 y1t = 1 + X1t ' + 1t, y2t = 2 + X2t ' + 2 t, …
注意: (1)在 EViews 输出结果中i 是以一个不变的常数部分和随个体变化的部分相加而成。 (2)在 EViews 5.0 以上版本个体固定效应对话框中的回归因子选项中填不填 c 输出结 果都会有固定常数项。
案例 1(file:5panel02) :1996-2002 年中国东北、华北、华东 15 个省级 地区的居民家庭固定价格的人均消费(CP)和人均收入(IP)数据。数据 是 7 年的,每一年都有 15 个数据,共 105 组观测值。 人均消费和收入两个面板数据都是平衡面板数据,各有 15 个个体。
11000 10000 9000 8000 7000 6000 5000 4000 3000 2000 2000 4000 6000 8000 10000 12000 IP_I 14000 cp_bj cp_nmg
11000 10000 9000 8000 7000 6000 5000 4000 3000 IP_T 2000 2000 4000 6000 8000 10000 12000 14000 CP_1996 CP_2002
i = 1(对于第 1 个个体或时间序列) = 1, 2, …, T ,t i = 2(对于第 2 个个体或时间序列) = 1, 2, …, T ,t
yN t = N + XN t ' + N t, i = N(对于第 N 个个体或时间序列) = 1, 2, …, T ,t
eviews关于面板数据模型截距,系数,固定效应还是随机效应的选取得检验方法及具体事例

面板数据模型1.面板数据定义。
时间序列数据或截面数据都是一维数据。
例如时间序列数据是变量按时间得到的数据;截面数据是变量在截面空间上的数据。
面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。
面板数据是同时在时间和截面空间上取得的二维数据。
面板数据示意图见图1。
面板数据从横截面(cross section)上看,是由若干个体(entity, unit, individual)在某一时刻构成的截面观测值,从纵剖面(longitudinal section)上看是一个时间序列。
面板数据用双下标变量表示。
例如y i t, i = 1, 2, …, N; t = 1, 2, …, TN表示面板数据中含有N个个体。
T表示时间序列的最大长度。
若固定t不变,y i ., ( i = 1, 2, …, N)是横截面上的N个随机变量;若固定i不变,y. t, (t = 1, 2, …, T)是纵剖面上的一个时间序列(个体)。
图1 N=7,T=50的面板数据示意图例如1990-2000年30个省份的农业总产值数据。
固定在某一年份上,它是由30个农业总产总值数字组成的截面数据;固定在某一省份上,它是由11年农业总产值数据组成的一个时间序列。
面板数据由30个个体组成。
共有330个观测值。
对于面板数据y i t, i = 1, 2, …, N; t = 1, 2, …, T来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data)。
若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data)。
注意:EViwes 3.1、4.1、5.0既允许用平衡面板数据也允许用非平衡面板数据估计模型。
面板数据模型计量经济学EVIEWS建模课件

下载EViews安装程序后,按照提示进行安装,选择 合适的安装路径和组件。
03
安装完成后,需要配置EViews的环境变量和启动选 项。
EViews软件界面与操作
EViews的界面包括菜单栏、工具栏、工作区、状态栏等部分,用户可以通 过菜单栏选择需要的命令和功能。
工作区是用户进行数据分析和模型估计的主要区域,可以显示数据表格、 图形、方程等。
固定效应模型
在固定效应模型中,个体固定效应被包括在内,这意 味着模型将考虑每个个体特有的不随时间变化的特征 对因变量的影响。在EViews中,可以通过在`xtreg`命 令后加上`fe`来指定固定效应模型。解读固定效应模型 的估计结果时,应注意观察固定效应的系数和显著性 水平,以了解不同个体的固定效应对因变量的影响程 度和显著性。
提高估计精度
相对于单一时间序列或横截面数据模型,面板数据模型能够利用更多的信息,提高估计 的精度。
面板数据模型在经济学研究中的挑战与展望
数据质量和可获得性
高质量的面板数据是进行面板数据分 析的前提,但获取高质量的面板数据 存在一定的难度。
动态面板数据分析
模型选择和设定
在应用面板数据模型时,需要合理选 择和设定模型,以避免模型误设导致 的估计偏误。
社会学研究 面板数据模型在社会学研究中用 于分析社会现象和趋势,如人口 变化、教育发展、犯罪率等。
医学研究 面板数据模型在医学研究中用于 分析疾病发病率、流行趋势、治 疗效果等,为医学研究和公共卫 生政策提供依据。
02
EViews软件介绍
EViews软件概述
EViews是一款专门用于计量经济学和时 间序列分析的软件,提供了一系列强大 的统计分析工具和图形化界面,方便用 户进行数据分析和模型估计。
实验(十)面板数据模型 文档讲解

面板数据模型的EViews操作(EViews’ Operation of Panel data Model)Pooled Time Series, Cross-Section DataData ofen contain information on a relatively small number of cross-sectional unit observed over time. For example,you may have time series data on GDP for a number of European nations.Or perhaps you have state level data on unemployment observed over time.We term such data pooled time series,cross-section data.EViews provides a number of specialized tools to help you work with pooled data. EViews will help you manage your data,perform operations in either the the time series or the cross-section dimension,and apply estimation methods that accpunt for the pooled structure of your data. EViews Object that manages time series/cross-section data is called a pool. The experiment will describe how to set up your data to work with,and how to define and work with objects.【实验目的】掌握面板数据模型基本内容的软件操作【实验内容】面板数据模型的实验内容:建立面板数据工作文件;对面板数据的处理;面板数据模型的参数估计一、从Excel数据导入建立一个工作文件1.双击EViews标识,打开EViews主窗口;从EViews主菜单中点击File键,选择open →foreign data as Workfile→单击左键→弹出一个窗口→找到Excel数据表→点击打开→点击下一步→点击完成。
Eviews数据统计与分析教程12章 面板数据(Panel Data)模型

EViews统计分析基础教程
二、Pool对象的基本操作
2.Pool对象数据的输入
(2)非堆积数据 在非堆积数据中,给定的截面数据和变量是放在一起的,但 同其他的截面成员和变量的数据是分开的。每一个截面成员 的观测值被放在一纵列中,每一列是截面成员不同时期的样 本观测值。 非堆积数据形式的导入方法与第三章所介绍的数据导入方法 相同。
非堆积数据形式的导入方法与第三章所介绍的数据导入方法相同二pool对象的基本操作3pool对象数据的分析打开pool对象窗口选择工具栏中的viewdescriptivestatistics选项得到下图所示的对话框二pool对象的基本操作3pool对象数据的分析在编辑栏中输入要计算描述统计量的序列名称可以是普通序列也可以是pool序列
EViews统计分析基础教程
二、Pool对象的基本操作
1.Pool对象的建立
在Pool对象的编辑窗口中输入截面成员的标识名称,例如做 中国省际面板数据分析时,选取中部五省份为截面成员,即 湖南、湖北、河南、江西和安徽,分布用字母HN,HB,HE, JX,AH表示。这些截面成员各名称之间可用空格隔开,也 可以通过回车键进行换行,即每一个名称占一行。需注意的 是,截面成员的标识名称的设定需简单,便于操作。通常可 以在截面成员标识名称前加下划线“_”。如下图所示。
EViews统计分析基础教程
二、Pool对象的基本操作
3.Pool对象数据的分析
打开Pool对象窗口,选择工具栏中的 “View”|“Descriptive Statistics…”选项,得到下图所示的对话框。
EViews统计分析基础教程
二、Pool对象的基本操作
3.Pool对象数据的分析
在编辑栏中输入要计算描述统计量的序列名称,可以是普 通序列,也可以是Pool序列; 在“Sample”中选定样本类型; 在“Data organization”中指定计算方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
EViews 6.0 beta在面板数据模型估计中的应用
来自免费的minixi
1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯
2、建立面板数据工作文件workfile
(1)最好不要选择EViews默认的blanaced panel 类型
Moren_panel
(2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件
3、建立pool对象
(1)新建对象
(2)选择新建对象类型并命名
(3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section
Identifiers: (Enter identifiers below this line )输入截面单元名称。,建议采用汉语
拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图
关闭建立的pool对象,它就出现在当前工作文件中。
4、在pool对象中建立面板数据序列
双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet
(展开表)
在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在
序列名后添加“?”。例如,输入GDP?,在GDP后的?的作用是各个截面单元的
占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在
接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。展开表(类似excel)中等待你输入、贴入数据。
5、贴入数据
(1)打开编辑(edit)窗口
(2)贴入数据
(3)关闭pool窗口,赶快存盘见好就收
6、在pool窗口对各个序列进行单位根检验
选择单位根检验
设置单位根检验
单位根检验结果
注意检验方法和两种检验的零假设:
Null: Unit root (assumes common unit root process)各截面有相同的单位根
Null: Unit root (assumes individual unit root process)允许各截面有不同单位根
其中,Levin, Lin & Chu t*检验拒绝含有单位根的零假设,即拒绝非平稳
7、在pool窗口对面板数据组合进行协整检验
选择进行协整检验
协整检验设置对话框,注意有3种检验方法(test type)
协整检验结果,同样要注意两种假定(含有AR,即含有单位根,非协整),两
种零假设都是非协整,小概率事件发生拒绝非协整。
本例题检验的4个序列时协整的,特别提示还要看各个序列的单位根检验是否是
同阶单整的,否则单凭协整检验的结果根据不足。
8、建立混合模型
在pool对象窗口的proc(过程)的下拉式菜单中选择估计打开模型设置窗口。