约束线性回归模型

实验三:滞后变量模型
(验证性实验)
一、实验名称和性质
二、实验目的
1、掌握滞后变量回归模型参数估计及检验方法。
三、实验的软硬件环境要求
硬件环境要求:
科学计算与经济分析实验室,计算机网络设备,需要连接Internet
使用的软件名称、版本号以及模块
带Windows操作系统以及EViews应用演示软件。
四、知识准备
前期要求掌握的知识:
(1)理解分布滞后模型及其在实际经济问题中应用;
实验流程:
滞后模型设定→滞后模型的参数估计→格兰杰因果检验→结论
五、实验材料和原始数据
数据1:表5.1给出了中国电力行业基本建设投资X与发电量Y的相关资料,建立一个多项式分布滞后模型来考察两者的关系。
表5.1 :中国电力工业固定资产投资与发电量
资料来源:电力固定资产固定资产投资来自《中国电力统计年鉴》,发电量来自《中国统计年鉴》。
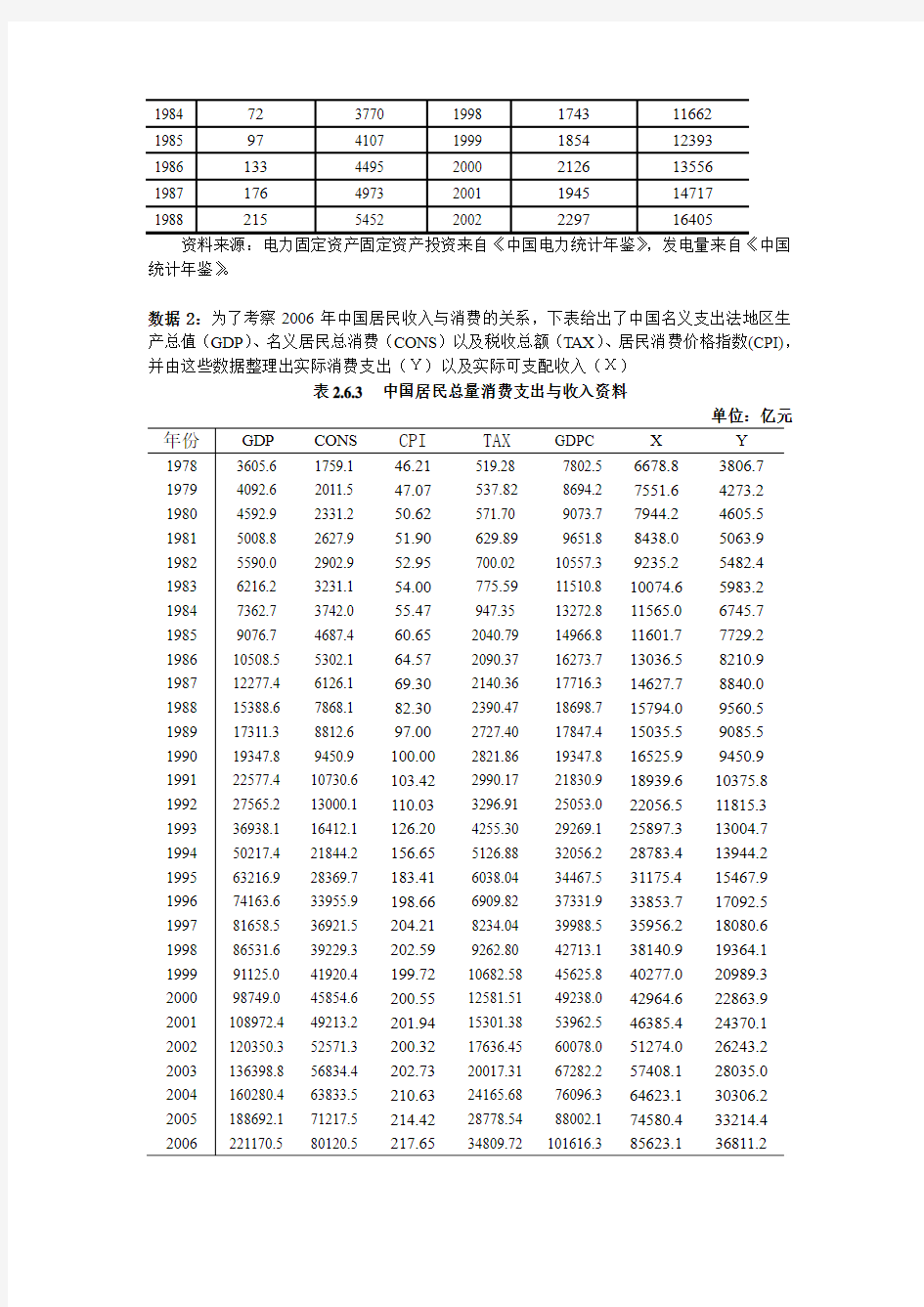
数据2:为了考察2006年中国居民收入与消费的关系,下表给出了中国名义支出法地区生产总值(GDP)、名义居民总消费(CONS)以及税收总额(TAX)、居民消费价格指数(CPI),并由这些数据整理出实际消费支出(Y)以及实际可支配收入(X)
表2.6.3 中国居民总量消费支出与收入资料
单位:亿元年份GDP CONS CPI TAX GDPC X Y
19783605.6 1759.1 46.21519.28 7802.5 6678.83806.7 19794092.6 2011.5 47.07537.828694.2 7551.64273.2 19804592.9 2331.2 50.62571.70 9073.7 7944.24605.5 19815008.8 2627.9 51.90629.899651.8 8438.05063.9 19825590.0 2902.9 52.95700.02 10557.3 9235.25482.4 19836216.2 3231.1 54.00775.5911510.8 10074.65983.2 19847362.7 3742.0 55.47947.35 13272.8 11565.06745.7 19859076.7 4687.4 60.652040.79 14966.8 11601.77729.2 198610508.5 5302.1 64.572090.37 16273.7 13036.58210.9 198712277.4 6126.1 69.302140.36 17716.3 14627.78840.0 198815388.6 7868.1 82.302390.47 18698.7 15794.09560.5 198917311.3 8812.6 97.002727.40 17847.4 15035.59085.5 199019347.8 9450.9 100.002821.86 19347.8 16525.99450.9 199122577.4 10730.6 103.422990.17 21830.9 18939.610375.8 199227565.2 13000.1 110.033296.91 25053.0 22056.511815.3 199336938.1 16412.1 126.204255.30 29269.1 25897.313004.7 199450217.4 21844.2 156.655126.88 32056.2 28783.413944.2 199563216.9 28369.7 183.416038.04 34467.5 31175.415467.9 199674163.6 33955.9 198.666909.82 37331.9 33853.717092.5 199781658.5 36921.5 204.218234.04 39988.5 35956.218080.6 199886531.6 39229.3 202.599262.80 42713.1 38140.919364.1 199991125.0 41920.4 199.7210682.58 45625.8 40277.020989.3 200098749.0 45854.6 200.5512581.51 49238.0 42964.622863.9 2001108972.4 49213.2 201.9415301.38 53962.5 46385.424370.1 2002120350.3 52571.3 200.3217636.45 60078.0 51274.026243.2 2003136398.8 56834.4 202.7320017.31 67282.2 57408.128035.0 2004160280.4 63833.5 210.6324165.68 76096.3 64623.130306.2 2005188692.1 71217.5 214.4228778.54 88002.1 74580.433214.4 2006221170.5 80120.5 217.6534809.72 101616.3 85623.136811.2
数据来源:李子奈《计量经济学(第三版)》P.56表2.6.2
六、实验内容及步骤
(一)电力投资分布滞后模型的建立与参数估计
1、 建立数据文件,建立工作文件的方法是点击File/New/Workfile,选择新建对象类型为工作文件,选择数据类型,建立工作文件,建立新序列,建立空组。创建两个个序列X(基本建设投资)、Y(发电量)并输入数据。进入界面后输入数据如图5-1,5-2所示。;
图 5-1 工作文件
2、模型设定。为了测算电力行业固定资产投资增长与发电量增长间的关系变动关系,建立如下双对数线性模型:∑=-++
=s
i t i t i
t X Y 0
ln ln μβ
α
3、方程估计:点击主菜单quick/estimate equation …,得到如图5-2界面,在Equation Specification 窗口中输入变量log(y) c pdl(log(x),7,2)。
图5-2 估计方程窗口 其中Pdl 是指在2阶阿尔蒙多项式变换下,模型滞后期数为7期,由于开始无法预知滞后期,因此需多次试验,本例中滞后期为7期,估计结果经济意义比较合理。估计结果如图5-3所示:
图5-3 分布滞后模型估计结果
由计算结果可知,2阶阿尔蒙多项式为:210006.0020.00244.0709.6?ln t t t t W W W Y +-+=,7
10?,,?,?βββ 的估计值分别为0.139,0.089,…,0.043。
七、实验内容及步骤
1.下表列出了中国某年按行业分的全部制造业国有企业及规模以上制造企业非国有企业的
工业生产总值Y ,资产合计K 及职工人数L 。
序号 工业总产值Y/亿元 资产合计K/亿元 职工人数L/万人 1 3722.70 3078.22 113 2 1442.52 1684.43 67 3 1752.37 2742.77 84 4 1451.29 1973.82 27 5 5149.30 5917.01 327 6
2291.16 1758.77 120
7 1345.17 939.10 58 8 656.77 694.94 31 9 370.18 363.48 16 10 1590.36 2511.99 66 11 616.71 973.73 58 12 617.94 516.01 28 13 4429.19 3785.91 61 14 5749.02 8688.03 254 15 1781.37 2798.90 83 16 1243.07 1808.44 33 17 812.70 1118.81 43 18 1899.70 2052.16 61 19 3692.85 6113.11 240 20 4732.90 9228.25 222 21 2180.23 2866.65 80 22 2539.76 2545.63 96 23 3046.95 4787.90 222 24 2192.63 3255.29 163 25 5364.83 8129.68 244 26 4834.68 5260.20 145 27 7549.58 7518.79 138 28 867.91 984.52 46 29 4611.39 18626.94 218 30 170.30 610.91 19 31 325.53 1523.19 45
设定模型为:
μβαe L AK Y =
(1) 利用上述资料,进行回归分析
(2) 中国该年的制造业总体呈现规模报酬不变状态吗?1=+βα
简单线性回归模型
第二章 简单线性回归模型 一、单项选择题 1.影响预测误差的因素有( ) A .置信度 B .样本容量 C .新解释变量X 0偏离解释变量均值的程度 D .如果给定值X 0等于X 的均值时,置信区间越长越好。 2.OLS E 的统计性质( ) A .线性无偏性 B .独具最小方差性 C .线性有偏 D .β∧ 是β的一致估计 3.OLSE 的基本假定( ) A .解释变量非随机 B .零均值 C .同方差 D .不自相关 4.F 检验与拟合优度指标之间的关系( ) A . 21111n p p R --?? ?- ?-?? B . 21111n p p R --?? ?- ?-?? C . 2111n p p R -???- ?-?? D . 2111n p p R -???- ?-?? 5.相关分析和回归分析的共同点( ) A .都可表示程度和方向 B .必须确定解释(自)变量和被解释(因)变量 C .不用确定解释(自)变量和被解释(因)变量 D .都研究变量间的统计关系 6.OLS E 的基本假设有( ) A .解释变量是随机的 B .随机误差项的零均值假设
C .随机误差项同方差假设 D .随机误差项线性相关假设 7.与 2 ()() 1 ()1i i i n x x y y i n x x i - --==∑∑ 等价的式子是( ) A .2 2 1()1i i i n x y nx y i n x n x i -=-=∑∑ B .2()1()1i i i n x x y i n x x i --==∑∑ C .2()1()1i i i n x x x i n x x i -=-=∑∑ D .xy xx L L 8.下列等式正确的是( ) A .SSR=SST+SSE B .SST=SSR+SSE C .SSE=SSR+SST D .SST=SST ×SSE 9.无偏估计量i β的方差是( ) A . 2 1 () n j j X X σ=-∑ B . 2 2 1 ()n j j X X σ=-∑ C . 2 () n j j X X σ=-∑
多元线性回归模型的各种检验方法.doc
对多元线性回归模型的各种检验方法 对于形如 u X X X Y k k +++++=ββββΛΛ22110 (1) 的回归模型,我们可能需要对其实施如下的检验中的一种或几种检验: 一、 对单个总体参数的假设检验:t 检验 在这种检验中,我们需要对模型中的某个(总体)参数是否满足虚拟假设0 H :j j a =β,做出具有统计意义(即带有一定的置信度)的检验,其中j a 为某个给定的已知数。特别是,当j a =0时,称为参数的(狭义意义上的)显著性检验。如果拒绝0H ,说明解释变量j X 对 被解释变量Y 具有显著的线性影响,估计值j β?才敢使 用;反之,说明解释变量j X 对被解释变量Y 不具有显 著的线性影响,估计值j β?对我们就没有意义。具体检验 方法如下: (1) 给定虚拟假设 0H :j j a =β;
(2) 计算统计量 )?(?)?()(?j j j j j j Se a Se E t βββββ-=-= 的数值; 11?)?(++-==j j jj jj j C C Se 1T X)(X ,其中σβ (3) 在给定的显著水平α下(α不能大于1.0即 10%,也即我们不能在置信度小于90%以下的前提下做结论),查出双尾t (1--k n )分布的临界值2/αt ; (4) 如果出现 2/αt t >的情况,检验结论为拒绝 0H ;反之,无法拒绝0H 。 t 检验方法的关键是统计量 )?(?j j j Se t βββ-=必须服从已 知的t 分布函数。什么情况或条件下才会这样呢?这需要我们建立的模型满足如下的条件(或假定): (1) 随机抽样性。我们有一个含n 次观测的随机样(){}n i Y X X X i ik i i ,,2,1:,,,,21ΛΛ=。这保证了误差u 自身的随机性,即无自相关性,
多元线性回归模型的案例分析
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下:
SAS学习系列25. 非线性回归
25. 非线性回归 现实世界中严格的线性模型并不多见,它们或多或少都带有某种程度的近似;在不少情况下,非线性模型可能更加符合实际。 对变量间非线性相关问题的曲线拟合,处理的方法主要有: (1)首先确定非线性模型的函数类型,对于其中可线性化问题则通过变量变换将其线性化,从而归结为前面的多元线性回归问题来解决; (2)若实际问题的曲线类型不易确定时,由于任意曲线皆可由多项式来逼近,故常可用多项式回归来拟合曲线; (3)若变量间非线性关系式已知(多数未知),且难以用变量变换法将其线性化,则进行数值迭代的非线性回归分析。 (一)可变换为线性的非线性回归
在很多场合,可以对非线性模型进行线性化处理,尤其是可变换为线性的非线性回归,运用最小二乘法进行推断,对线性化后的线性模型,可以应用REG过程步进行计算。 例1 有实验数据如下: 试分别采用指数回归(y =ae bx)方法进行回归分析。 代码: data exam25_1; input x y; cards; 1.1 109.95 1.2 40.45 1.3 20.09 1.4 24.53 1.5 11.02 1.6 7.39 1.7 4.95 1.8 2.72 1.9 1.82 2 1.49 2.1 0.82 2.2 0.3 2.3 0.2 2.4 0.22 ; run; proc sgplot data = exam25_1; scatter x = x y = y; run; proc corr data = exam25_1; var x y; run;
data new1; set exam25_1; v = log(y); run; proc sgplot data = new1; scatter x = x y = v; title'变量代换后数据'; run; proc reg data = new1; var x v; model v = x; print cli; title'残差图'; plot residual. * predicted.; run; data new2; set exam25_1; y1 = 14530.28*exp(-4.73895*x); run; proc gplot data = new2; plot y*x=1 y1*x=2 /overlay; symbol v=dot i=none cv=red; symbol2i=sm color=blue; title'指数回归图'; 运行结果:
多元线性回归模型实验报告 计量经济学
实验报告 课程名称金融计量学 实验项目名称多元线性回归模型班级与班级代码 实验室名称(或课室) 专业 任课教师xxx 学号:xxx 姓名:xxx 实验日期:2012年5 月3日 广东商学院教务处制
姓名xxx 实验报告成绩 评语: 指导教师(签名) 年月日说明:指导教师评分后,实验报告交院(系)办公室保存
多元线性回归模型 一、实验目的 通过上机实验,使学生能够使用 Eviews 软件估计可化为线性回归模型的非线性模型,并对线性回归模型的参数线性约束条件进行检验。二、实验内容 (一)根据中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L进行回归分析。(二)掌握可化为线性多元非线性回归模型的估计和多元线性回归模型的线性约束条件的检验方法 (三)根据实验结果判断中国该年制造业总体的规模报酬状态如何?三、实验步骤 (一)收集数据 下表列示出来中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L。 序号工业总产值Y (亿元) 资产合计K (亿元) 职工人数L (万人)序号 工业总产 值Y(亿元) 资产合计K (亿元) 职工人数L (万人) 1 3722.7 3078.2 2 11 3 17 812.7 1118.81 43 2 1442.52 1684.4 3 67 18 1899.7 2052.16 61 3 1752.37 2742.77 8 4 19 3692.8 5 6113.11 240 4 1451.29 1973.82 27 20 4732.9 9228.2 5 222 5 5149.3 5917.01 327 21 2180.23 2866.65 80 6 2291.16 1758.7 7 120 22 2539.76 2545.63 96 7 1345.17 939.1 58 23 3046.95 4787.9 222 8 656.77 694.94 31 24 2192.63 3255.29 163 9 370.18 363.48 16 25 5364.83 8129.68 244 10 1590.36 2511.99 66 26 4834.68 5260.2 145 11 616.71 973.73 58 27 7549.58 7518.79 138 12 617.94 516.01 28 28 867.91 984.52 46 13 4429.19 3785.91 61 29 4611.39 18626.94 218 14 5749.02 8688.03 254 30 170.3 610.91 19 15 1781.37 2798.9 83 31 325.53 1523.19 45 16 1243.07 1808.44 33 表1
非线性回归分析
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果: 通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度明显高于
中级计量经济学讲义_第六章带有线性约束的多元线性回归模型及其假设检验
第六章 带有线性约束的多元线性回归模型及其假设检验 在本章中,继续讨论第五章的模型,但新的模型中,参数β满足J 个线性约束集,R β=q ,矩阵R 有和β相一致的K 列和总共J 个约束的J 行,且R 是行满秩的,我们考虑不是过度约束的情况,因此,J <K 。 带有线性约束的参数的假设检验,我们可以用两种方法来处理。第一个方法,我们按照无约束条件求出一组参数估计后,然后我们对求出的这组参数是否满足假设所暗示的约束,进行检验,我们在本章的第一节中讨论。 第二个方法是我们把参数所满足的线性约束和模型一起考虑,求出参数的最小二乘解,尔后再作检验,后者就是参数带有约束的最小二乘估计方法,我们在本章的第二节中讨论。 第一节 线性约束的检验 从线性回归模型开始, εβ+=X y (1) 我们考虑具有如下形式的一组线性约束, J K JK J J K K K K q r r r q r r r q r r r =+++=+++=+++βββββββββ 22112 222212********* 这些可以用矩阵改写成一个方程 q R =β (2) 作为我们的假设条件0H 。 R 中每一行都是一个约束中的系数。矩阵R 有和β相一致的K 列和总共J 个约束的J 行,且R 是行满秩的。因此,J 一定要小于或等于K 。R 的各行必须是线性无关的,虽然J =K 的情况并不违反条件,但其唯一决定了β,这样的约束没有意义,我们不考虑这种情况。 给定最小二乘估计量b ,我们的兴趣集中于“差异”向量d=Rb -q 。d 精确等于0是不可能的事件(因为其概率是0),统计问题是d 对0的离差是否可归因于抽样误差或它是否是显著的。
经典线性回归模型
2 经典线性回归模型 §2.1 概念与记号 1.线性回归模型是用来描述一个特定变量y 与其它一些变量x 1,…,x p 之间的关系。 2. 称特定变量y 为因变量 (dependent variable )、 被解释变量 (explained variable )、 响应变量(response variable )、被预测变量(predicted variable )、回归子 (regressand )。 3.称与特定变量相关的其它一些变量x 1,…,x p 为自变量(independent variable )、 解释变量(explanatory variable )、控制变量(control variable )、预测变量 (predictor variable )、回归量(regressor )、协变量(covariate )。 4.假定我们观测到上述这些变量的n 组值:( ) ip i i x x y , , , 1 L (i=1,…,n)。称 这n 组值为样本(sample )或数据(data )。 §2.2 经典线性回归模型的假定 假定 2.1(线性性(linearity)) i ip p i i x x y e b b b + + + + = L 1 1 0 (i=1,…,n)。 (2.1) 称方程(2.1)为因变量y 对自变量x 1,…,x p 的线性回归方程(linear regression equation ),其中 ( ) p , k k , , 1 0 L = b 是待估的未知参数(unknown parameters ), ( ) n i i , , 1 L = e 是满足一定限制条件的无法观测的误差项(unobserved error term ) 。称自 变量的函数 ip p i x x b b b + + + L 1 1 0 为回归函数(regression function )或简称为回归 (regression )。称 0 b 为回归的截距(ntercept),称 ( ) p k k , , 1 L = b 为自变量的回归系数 (regression coefficients ) 。某个自变量的回归系数表示在其它条件保持不变的情况下,
简单线性回归分析思考与练习参考答案
第10章 简单线性回归分析 思考与练习参考答案 一、最佳选择题 1.如果两样本的相关系数21r r =,样本量21n n =,那么( D )。 A. 回归系数21b b = B .回归系数12b b < C. 回归系数21b b > D .t 统计量11r b t t = E. 以上均错 2.如果相关系数r =1,则一定有( C )。 A .总SS =残差SS B .残差SS =回归 SS C .总SS =回归SS D .总SS >回归SS E. 回归MS =残差MS 3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )正确。 A .ρ=0时,r =0 B .|r |>0时,b >0 C .r >0时,b <0 D .r <0时,b <0 E. |r |=1时,b =1 4.如果相关系数r =0,则一定有( D )。 A .简单线性回归的截距等于0 B .简单线性回归的截距等于Y 或X C .简单线性回归的残差SS 等于0 D .简单线性回归的残差SS 等于SS 总 E .简单线性回归的总SS 等于0 5.用最小二乘法确定直线回归方程的含义是( B )。 A .各观测点距直线的纵向距离相等 B .各观测点距直线的纵向距离平方和最小 C .各观测点距直线的垂直距离相等 D .各观测点距直线的垂直距离平方和最小 E .各观测点距直线的纵向距离等于零 二、思考题 1.简述简单线性回归分析的基本步骤。 答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。 2.简述线性回归分析与线性相关的区别与联系。
案例分析报告(一元线性回归模型)
案例分析报告(2014——2015学年第一学期) 课程名称:预测与决策 专业班级:电子商务1202 学号: 2204120202 学生姓名:陈维维 2014 年 11月
案例分析(一元线性回归模型) 我国城镇居民家庭人均消费支出预测 一、研究目的与要求 居民消费在社会经济的持续发展中有着重要的作用,居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。从理论角度讲,消费需求的具体内容主要体现在消费结构上,要增加居民消费,就要从研究居民消费结构入手,只有了解居民消费结构变化的趋势和规律,掌握消费需求的热点和发展方向,才能为消费者提供良好的政策环境,引导消费者合理扩大消费,才能促进产业结构调整与消费结构优化升级相协调,才能推动国民经济平稳、健康发展。例如,2008年全国城镇居民家庭平均每人每年消费支出为11242.85元,最低的青海省仅为人均8192.56元,最高的上海市达人均19397.89元,上海是黑龙江的2.37倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我研究的对象是各地区居民消费的差异。居民消费可分为城镇居民消费和农村居民消费,由于各地区的城镇与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城镇居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。 所以模型的被解释变量Y选定为“城镇居民每人每年的平均消费支出”。 因为研究的目的是各地区城镇居民消费的差异,并不是城镇居民消费在不同时间的变动,所以应选择同一时期各地区城镇居民的消费支出来建立模
第七章 带有线性约束的多元线性回归模型及其假设检验(金融计量-浙大 蒋岳祥)
第七章 带有线性约束的多元线性回归模型及其假设检验 在本章中,继续讨论第五章的模型,但新的模型中,参数β满足J 个线性约束集,R β=q ,矩阵R 有和β相一致的K 列和总共J 个约束的J 行,且R 是行满秩的,我们考虑不是过度约束的情况,因此,J <K 。 带有线性约束的参数的假设检验,我们可以用两种方法来处理。第一个方法,我们按照无约束条件求出一组参数估计后,然后我们对求出的这组参数是否满足假设所暗示的约束,进行检验,我们在本章的第一节中讨论。 第二个方法是我们把参数所满足的线性约束和模型一起考虑,求出参数的最小二乘解,尔后再作检验,后者就是参数带有约束的最小二乘估计方法,我们在本章的第二节中讨论。 第一节 线性约束的检验 从线性回归模型开始, εβ+=X y (1) 我们考虑具有如下形式的一组线性约束, J K JK J J K K K K q r r r q r r r q r r r =+++=+++=+++βββββββββ 22112 22221211 1212111 这些可以用矩阵改写成一个方程 q R =β (2) 作为我们的假设条件0H 。 R 中每一行都是一个约束中的系数。矩阵R 有和β相一致的K 列和总共J 个约束的J 行,且R 是行满秩的。因此,J 一定要小于或等于K 。R 的各行必须是线性无关的,虽然J =K 的情况并不违反条件,但其唯一决定了β,这样的约束没有意义,我们不考虑这种情况。 给定最小二乘估计量b ,我们的兴趣集中于“差异”向量d=Rb -q 。d 精确等于0是不可能的事件(因为其概率是0),统计问题是d 对0的离差是否可归因于抽样误差或它是否是显著的。
SAS讲义 第三十四课非线性回归分析
第三十四课 非线性回归分析 现实世界中严格的线性模型并不多见,它们或多或少都带有某种程度的近似;在不少情况下,非线性模型可能更加符合实际。由于人们在传统上常把“非线性”视为畏途,非线性回归的应用在国内还不够普及。事实上,在计算机与统计软件十分发达的令天,非线性回归的基本统计分析已经与线性回归一样切实可行。在常见的软件包中(诸如SAS 、SPSS 等等),人们已经可以像线性回归一样,方便的对非线性回归进行统计分析。因此,在国内回归分析方法的应用中,已经到了“更上一层楼”,线性回归与非线性回归同时并重的时候。 对变量间非线性相关问题的曲线拟合,处理的方法主要有: ● 首先决定非线性模型的函数类型,对于其中可线性化问题则通过变量变换将其线 性化,从而归结为前面的多元线性回归问题来解决。 ● 若实际问题的曲线类型不易确定时,由于任意曲线皆可由多项式来逼近,故常可 用多项式回归来拟合曲线。 ● 若变量间非线性关系式已知(多数未知),且难以用变量变换法将其线性化,则进 行数值迭代的非线性回归分析。 一、 可变换成线性的非线性回归 在实际问题中一些非线性回归模型可通过变量变换的方法化为线性回归问题。例如,对非线性回归模型 ()t i t i t i t ix b ix a y εα+++=∑=2 1 0sin cos (34.1) 即可作变换 t t t t t t t t x x x x x x x x 2sin ,2cos ,sin ,cos 4321==== 将其化为多元线性回归模型。一般地,若非线性模型的表达式为 ()()()t m m t t t x g b x g b x g b b y ++++= 22110 (34.2) 则可作变量变换 ()()() t m m t t t t t x g x x g x x g x ===* 2*21*1,,, (34.3) 将其化为线性回归模型的表达式,从而用前面线性模型的方法来解决,其中(34.3)中的x t 也 可为自变量构成的向量。 这种变量变换法也适用于因变量和待定参数 b i 。如 ()[]1exp 2132211-++=t t t t t x x b x b x b a y (34.4) 时上式两边取对数得 ()1ln ln 2132211-+++=t t t t t x x b x b x b a y (34.5) 现作变换 1,ln ,ln 2130*-===t t t t t x x x a b y y (34.6) 则可得线性表达式
线性回归模型的研究毕业论文
线性回归模型的研究毕业论文 1 引言 回归分析最早是由19世纪末期高尔顿(Sir Francis Galton)发展的。1855年,他发表了一篇文章名为“遗传的身高向平均数方向的回归”,分析父母与其孩子之间身高的关系,发现父母的身高越高或的其孩子也越高,反之则越矮。他把儿子跟父母身高这种现象拟合成一种线性关系。但是他还发现了个有趣的现象,高个子的人生出来的儿子往往比他父亲矮一点更趋向于平均身高,矮个子的人生出来的儿子通常比他父亲高一点也趋向于平均身高。高尔顿选用“回归”一词,把这一现象叫做“向平均数方向的回归”。于是“线形回归”的术语被沿用下来了。 回归分析中,当研究的因果关系只涉及因变量和一个自变量时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。此外,回归分析中,又依据描述自变量与因变量之间因果关系的函数表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。按照参数估计方法可以分为主成分回归、偏最小二乘回归、和岭回归。 一般采用线性回归分析,由自变量和规定因变量来确定变量之间的因果关系,从而建立线性回归模型。模型的各个参数可以根据实测数据解。接着评价回归模型能否够很好的拟合实际数据;如果不能够很好的拟合,则重新拟合;如果能很好的拟合,就可以根据自变量进行下一步推测。 回归分析是重要的统计推断方法。在实际应用中,医学、农业、生物、林业、金融、管理、经济、社会等诸多方面随着科学的发展都需要运用到这个方法。从而推动了回归分析的快速发展。 2 回归分析的概述 2.1 回归分析的定义 回归分析是应用极其广泛的数据分析方法之一。回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。 2.2 回归分析的主要容
差分约束系统详解
差分约束系统 在一个差分约束系统(system of difference constraints)中,线性规划矩阵A的每一行包含一个1和一个-1,A的其他所有元素都为0。因此,由Ax≤b给出的约束条件是m个差分约束集合,其中包含n个未知量,对应的线性规划矩阵A为m行n列。每个约束条件为如下形式的简单线性不等式:xj-xi≤bk。其中1≤i,j≤n,1≤k≤m。 例如,考虑这样一个问题,寻找一个5维向量x=(xi)以满足: 这一问题等价于找出未知量xi,i=1,2,…,5,满足下列8个差分约束条件:x1-x2≤0 x1-x5≤-1 x2-x5≤1 x3-x1≤5 x4-x1≤4 x4-x3≤-1 x5-x3≤-3 x5-x4≤-3 该问题的一个解为x=(-5,-3,0,-1,-4),另一个解y=(0,2,5,4,1),这2个解是有联系的:y中的每个元素比x中相应的元素大5。
引理:设x=(x1,x2,…,xn)是差分约束系统Ax≤b的一个解,d为任意常数。则 x+d=(x1+d,x2+d,…,xn+d)也是该系统Ax≤b的一个解。 约束图 在一个差分约束系统Ax≤b中,m X n的线性规划矩阵A可被看做是n顶点,m条边的图的关联矩阵。对于i=1,2,…,n,图中的每一个顶点vi对应着n个未知量的一个xi。图中的每个有向边对应着关于两个未知量的m个不等式中的一个。 给定一个差分约束系统Ax≤b,相应的约束图是一个带权有向图G=(V,E),其中 V={v0,v1,…,vn},而且E={ (vi,vj) : xj-xi≤bk是一个约束}∪{ (v0,v1) , (v0,v2) , … , (v0,vn) }。引入附加顶点v0是为了保证其他每个顶点均从v0可达。因此,顶点集合V由对应于每个未知量xi的顶点vi和附加的顶点v0组成。边的集合E由对应于每个差分约束条件的边与对应于每个未知量xi的边(v0,vi)构成。如果xj-xi≤bk是一个差分约束,则边(vi,vj)的权 w(vi,vj)=bk(注意i和j不能颠倒),从v0出发的每条边的权值均为0。 定理:给定一差分约束系统Ax≤b,设G=(V,E)为其相应的约束图。如果G不包含负权回路,那么x=( d(v0,v1) , d(v0,v2) , … , d(v0,vn) )是此系统的一可行解,其中d(v0,vi)是约束图中v0到vi的最短路径(i=1,2,…,n)。如果G包含负权回路,那么此系统不存在可行解。 差分约束问题的求解 由上述定理可知,可以采用Bellman-Ford算法对差分约束问题求解。因为在约束图中,从源点v0到其他所有顶点间均存在边,因此约束图中任何负权回路均从v0可达。如果Bellman-Ford算法返回TRUE,则最短路径权给出了此系统的一个可行解;如果返回FALSE,则差分约束系统无可行解。 关于n个未知量m个约束条件的一个差分约束系统产生出一个具有n+1个顶点和n+m条边的约束图。因此采用Bellman-Ford算法,可以再O((n+1)(n+m))=O(n^2+nm)时间内将系
简单线性回归模型练习题
第二章 简单线性回归模型练习题 一、术语解释 1 解释变量 2 被解释变量 3 线性回归模型 4 最小二乘法 5 方差分析 6 参数估计 7 控制 8 预测 二、填空 1 在经济计量模型中引入反映( )因素影响的随机扰动项t ξ,目的在于使模型更符合( )活动。 2 在经济计量模型中引入随机扰动项的理由可以归纳为如下几条:(1)因为人的行为的( )、社会环境与自然环境的( )决定了经济变量本身的( );(2)建立模型时其他被省略的经济因素的影响都归入了( )中;(3)在模型估计时,( )与归并误差也归入随机扰动项中;(4)由于我们认识的不足,错误的设定了( )与( )之间的数学形式,例如将非线性的函数形式设定为线性的函数形式,由此产生的误差也包含在随机扰动项中了。 3 ( )是因变量离差平方和,它度量因变量的总变动。就因变量总变动的变异来源看,它由两部分因素所组成。一个是自变量,另一个是除自变量以外的其他因素。( )是拟合值的离散程度的度量。它是由自变量的变化引起的因变量的变化,或称自变量对因变量变化的贡献。( )是度量实际值与拟合值之间的差异,它是由自变量以外的其他因素所致,它又叫残差或剩余。 4 回归方程中的回归系数是自变量对因变量的( )。某自变量回归系数β的意义,指的是该自变量变化一个单位引起因变量平均变化( )个单位。 5 模型线性的含义,就变量而言,指的是回归模型中变量的( );就参数而言,指的是回归模型中的参数的( );通常线性回归模型的线性含义是就( )而言的。 6 样本观察值与回归方程理论值之间的偏差,称为( ),我们用残差估计线性模型中的( )。 三、简答题 1 在线性回归方程中,“线性”二字如何理解 2 用最小二乘法求线性回归方程系数的意义是什么 3 一元线性回归方程的基本假设条件是什么 4 方差分析方法把数据总的平方和分解成为两部分的意义是什么 5 试叙述t 检验法与相关系数检验法之间的联系。 6 应用线性回归方程控制和预测的思想。 7 线性回归方程无效的原因是什么 8 回归分析中的随机误差项i ε有什么作用它与残差项t e 有何区别
(完整word版)多元线性回归模型案例分析
多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据
设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024
线性系统的应用
线性系统的应用 在实施中看到一些线性方程的时候!这里讨论的问题提供一闪而过的两个领域中所提到的一章的介绍-网络和经济模式。随后有更多的线性代数的概念在我们处理。我们将许多其他应用程序检查的线性系统。 网络流量 当科学家,工程师,或经济学家通过网络学习一些数量的流动通过网络自然系统形成的线性方程组。城市规划者和交通工程师监控模式的交通流在网格的城市街道的野花。电气科学工程师计算出当前通过电路的流量。科学家分析生产商家从顾客的销售量和结余量的分布。对于许多网络来说,方程式的系统包含在成百甚至上千的变量和方程式中。 一个网络包括一套被称为交叉点或节点,有直线或弧度的叫分支,流量(速率)可以合理的显现出来。 网络流量最基本的假设是总的流量是流入和流出网络流量结合点的总和。举个例子,有30个单位的流量通过其他的分支。包含X1和X2变量的流量从其他分支流出。自从其他分支里的流量被保存后,我们必须有X1+X2=30这个等式。与之相似的方式,其他流量的交界处用一个线性方程描述。网络分析的问题是当部分可知的信息可知时,流量应从其他分支流出。 例1 这有一个交通流量图,一路的流量是在下午较早时
刻的典型,然后决定选择常规的网络模式。 解决方案我们写出方程式以便描述流量而后找出系统的常规解决方案。标签的街的交叉路口下车和位置流量的分支,就像图里描述的那样。设置流出的流量的总和。同时,进入网络的流量总和(500+300+100+400)等于从网络流出的流量和(300+X3+600)这里只是简单的令X3=400.综合这些等式用第一个等式重新排列,我们获得了随之而来的系统的方程式。 X1+X2=800 X2-X3+X4=300 X4+X5=500 X1+ X5=600 X3=400 减少相关的连续增广矩阵就可得到 X1+ X5=600 X2 -X5=200
线性回归模型的研究毕业论文
毕业论文声明 本人郑重声明: 1.此毕业论文是本人在指导教师指导下独立进行研究取得的成果。除了特别加以标注地方外,本文不包含他人或其它机构已经发表或撰写过的研究成果。对本文研究做出重要贡献的个人与集体均已在文中作了明确标明。本人完全意识到本声明的法律结果由本人承担。 2.本人完全了解学校、学院有关保留、使用学位论文的规定,同意学校与学院保留并向国家有关部门或机构送交此论文的复印件和电子版,允许此文被查阅和借阅。本人授权大学学院可以将此文的全部或部分内容编入有关数据库进行检索,可以采用影印、缩印或扫描等复制手段保存和汇编本文。 3.若在大学学院毕业论文审查小组复审中,发现本文有抄袭,一切后果均由本人承担,与毕业论文指导老师无关。 4.本人所呈交的毕业论文,是在指导老师的指导下独立进行研究所取得的成果。论文中凡引用他人已经发布或未发表的成果、数据、观点等,均已明确注明出处。论文中已经注明引用的内容外,不包含任何其他个人或集体已经发表或撰写过的研究成果。对本文的研究成果做出重要贡献的个人和集体,均已在论文中已明确的方式标明。 学位论文作者(签名): 年月
关于毕业论文使用授权的声明 本人在指导老师的指导下所完成的论文及相关的资料(包括图纸、实验记录、原始数据、实物照片、图片、录音带、设计手稿等),知识产权归属华北电力大学。本人完全了解大学有关保存,使用毕业论文的规定。同意学校保存或向国家有关部门或机构送交论文的纸质版或电子版,允许论文被查阅或借阅。本人授权大学可以将本毕业论文的全部或部分内容编入有关数据库进行检索,可以采用任何复制手段保存或编汇本毕业论文。如果发表相关成果,一定征得指导教师同意,且第一署名单位为大学。本人毕业后使用毕业论文或与该论文直接相关的学术论文或成果时,第一署名单位仍然为大学。本人完全了解大学关于收集、保存、使用学位论文的规定,同意如下各项内容:按照学校要求提交学位论文的印刷本和电子版本;学校有权保存学位论文的印刷本和电子版,并采用影印、缩印、扫描、数字化或其它手段保存或汇编本学位论文;学校有权提供目录检索以及提供本学位论文全文或者部分的阅览服务;学校有权按有关规定向国家有关部门或者机构送交论文的复印件和电子版,允许论文被查阅和借阅。本人授权大学可以将本学位论文的全部或部分内容编入学校有关数据 库和收录到《中国学位论文全文数据库》进行信息服务。在不以赢利为目的的前提下,学校可以适当复制论文的部分或全部内容用于学术活动。 论文作者签名:日期: 指导教师签名:日期:
线性回归模型
线性回归模型 1.回归分析 回归分析研究的主要对象是客观事物变量之间的统计关系,它是建立在对客观事物进行大量试验和观察的基础上,用来寻找隐藏在那些看上去是不确定的现象中的统计规律性的方法。回归分析方法是通过建立模型研究变量间相互关系的密切程度、结构状态及进行模型预测的一种有效工具。 2.回归模型的一般形式 如果变量x_1,x_2,…,x_p与随机变量y之间存在着相关关系,通常就意味着每当x_1,x_2,…,x_p取定值后,y便有相应的概率分布与之对应。随机变量y与相关变量x_1,x_2,…,x_p之间的概率模型为 y = f(x_1, x_2,…,x_p) + ε(1) f(x_1, x_2,…,x_p)为变量x_1,x_2,…,x_p的确定性关系,ε为随机误差项。由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。 当概率模型(1)式中回归函数为线性函数时,即有 y = beta_0 + beta_1*x_1 + beta_2*x_2 + …+ beta_p*x_p +ε (2) 其中,beta_0,…,beta_p为未知参数,常称它们为回归系数。当变量x个数为1时,为简单线性回归模型,当变量x个数大于1时,为多元线性回归模型。 3.回归建模的过程 在实际问题的回归分析中,模型的建立和分析有几个重要的阶段,以经济模型的建立为例:
(1)根据研究的目的设置指标变量 回归分析模型主要是揭示事物间相关变量的数量关系。首先要根据所研究问题的目的设置因变量y,然后再选取与y有关的一些变量作为自变量。通常情况下,我们希望因变量与自变量之间具有因果关系。尤其是在研究某种经济活动或经济现象时,必须根据具体的经济现象的研究目的,利用经济学理论,从定性角度来确定某种经济问题中各因素之间的因果关系。(2)收集、整理统计数据 回归模型的建立是基于回归变量的样本统计数据。当确定好回归模型的变量之后,就要对这些变量收集、整理统计数据。数据的收集是建立经济问题回归模型的重要一环,是一项基础性工作,样本数据的质量如何,对回归模型的水平有至关重要的影响。 (3)确定理论回归模型的数学形式 当收集到所设置的变量的数据之后,就要确定适当的数学形式来描述这些变量之间的关系。绘制变量y_i与x_i(i = 1,2,…,n)的样本散点图是选择数学模型形式的重要手段。一般我们把(x_i,y_i)所对应的点在坐标系上画出来,观察散点图的分布状况。如果n个样本点大致分布在一条直线的周围,可考虑用线性回归模型去拟合这条直线。 (4)模型参数的估计 回归理论模型确定之后,利用收集、整理的样本数据对模型的未知参数给出估计是回归分析的重要内容。未知参数的估计方法最常用的是普通最小二乘法。普通最小二乘法通过最小化模型的残差平方和而得到参数的估计值。即 Min RSS = ∑(y_i – hat(y_i))^2 = 其中,hat(y_i)为因变量估计值,hat(beta_i)为参数估计值。 (5)模型的检验与修改 当模型的未知参数估计出来后,就初步建立了一个回归模型。建立回归模型的目的是应用它来研究经济问题,但如果直接用这个模型去做预测、控制和分析,是不够慎重的。因为这个模型是否真正揭示了被解释变量与解释变量之间的关系,必须通过对模型的检验才能决定。统计检验通常是对回归方程的显著性检验,以及回归系数的显著性检验,还有拟合优度的检验,随机误差项的序列相关检验,异方差性检验,解释变量的多重共线性检验等。 如果一个回归模型没有通过某种统计检验,或者通过了统计检验而没有合理的经济意义,就需要对回归模型进行修改。 (6)回归模型的运用 当一个经济问题的回归模型通过了各种统计检验,且具有合理的经济意义时,就可以运用这个模型来进一步研究经济问题。例如,经济变量的因素分析。应用回归模型对经济变量之间的关系作出了度量,从模型的回归系数可发现经济变量的结构性关系,给出相关评价的一些量化依据。 在回归模型的运用中,应将定性分析和定量分析有机结合。这是因为数理统计方法只是从事物的数量表面去研究问题,不涉及事物的规定性。单纯的表面上的数量关系是否反映事物的本质这本质究竟如何必须依靠专门学科的研究才能下定论。 Lasso 在多元线性回归中,当变量x_1,x_2,…,x_3之间有较强的线性相关性,即解释变量间出现严重的多重共线性。这种情况下,用普通最小二乘法估计模型参数,往往参数估计方差太大,使普通最小二乘的效果变得很不理想。为了解决这一问题,可以采用子集选择、压缩估计或降维法,Lasso即为压缩估计的一种。Lasso可以将一些增加了模型复杂性但与模型无关的