编译实验报告+源代码
编译linux实验报告

编译linux实验报告
编译Linux实验报告
在计算机科学领域,Linux操作系统一直被广泛使用。
它是一个开放源代码的操作系统,具有稳定性和安全性。
在本次实验中,我们将学习如何编译Linux内核,并撰写实验报告以记录我们的实验过程和结果。
实验目的:
1. 了解Linux内核的编译过程
2. 熟悉编译工具和技术
3. 掌握编译过程中可能遇到的问题和解决方法
实验步骤:
1. 下载Linux内核源代码
2. 解压源代码并配置编译环境
3. 使用make命令编译内核
4. 安装编译后的内核
5. 测试新内核的稳定性和功能
实验结果:
经过一系列的操作,我们成功地编译了Linux内核,并将其安装到我们的计算机上。
新内核的稳定性和功能得到了验证,证明我们的编译过程是成功的。
实验总结:
通过本次实验,我们不仅了解了Linux内核的编译过程,还学习了如何使用编译工具和技术。
在实验过程中,我们遇到了一些问题,但通过查阅资料和尝试不同的解决方法,最终成功地完成了编译过程。
这次实验为我们提供了宝贵的
经验,也增强了我们对Linux操作系统的理解和掌握。
总的来说,编译Linux内核的实验是一次有意义的学习过程,我们通过实践提升了自己的技能和知识水平。
希望在未来的学习和工作中,能够运用这些经验和技能,为我们的计算机科学之路增添更多的成就和贡献。
编译原理实验参考原代码
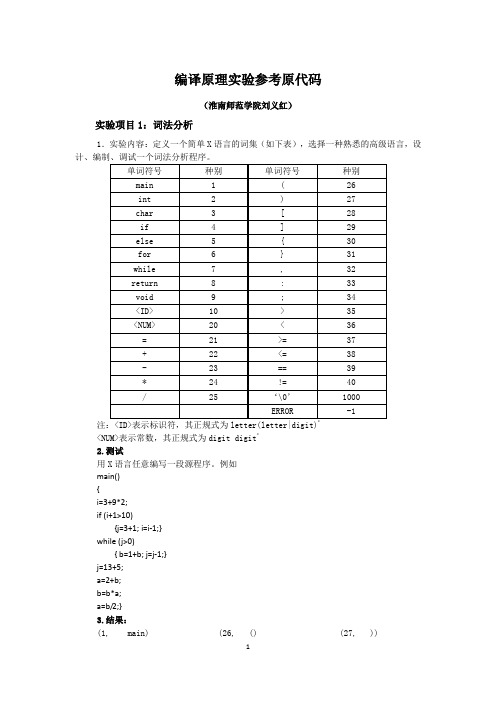
"Waiting for your expanding."
SCAN.C //词法分析器源程序
#include "globals.h" #include "scan.h"
void Do_Tag(char *strSource); void Do_Digit(char *strSource); void Do_EndOfTag(char *strSource); void Do_EndOfDigit(); void Do_EndOfEqual(char *strSource); void Do_EndOfPlus(char *strSource); void Do_EndOfSubtraction(char *strSource); void Do_EndOfMultiply(char *strSource); void Do_EndOfDivide(char *strSource); void Do_EndOfLParen(char *strSource); void Do_EndOfRParen(char *strSource); void Do_EndOfLeftBracket1(char *strSource); void Do_EndOfRightBracket1(char *strSource); void Do_EndOfLeftBracket2(char *strSource); void Do_EndOfRightBracket2(char *strSource); void Do_EndOfColon(char *strSource); void Do_EndOfComma(char *strSource); void Do_EndOfSemicolon(char *strSource); void Do_EndOfMore(char *strSource); void Do_EndOfLess(char *strSource); void Do_EndOfEnd(char *strSource); void Do_EndOfNEqual(char *strSource); void PrintError(int nColumn,int nRow,char chInput); void scaner(void);
文本编辑器c++实验报告附源代码

四川大学软件学院实验报告学号:1043111051 姓名:王金科专业:软件工程班级:2010级5班课程名称数据结构实验课时8实验项目文本编辑器实验时间12到14周实验目的了解c++类的封装和KMP算法。
Windows平台 VC6.0++实验环境实验内容(算法、程序、步骤和方法)部分函数创建思想:创建过程如下:a、定义LinkList指针变量*temp: LinkList *temp;b、定义文本输入变量ch,记录文本行数变量j,记录每行字符数变量i;c、申请动态存储空间:head->next=(LinkList *)malloc(sizeof(LinkList));d、首行头指针的前驱指针为空:head->pre=NULL;首行指针:temp=head->next;首行指针的前驱指针也为空:temp->pre=NULL;定义没输入字符时文章长度为0:temp->length=0;初始化为字符串结束标志,防止出现乱码:for(i=0;i<80;i++)temp->data[i]='\0';e、利用循环进行文本输入for(j=0;j<LINK_INIT_SIZE;j++)// 控制一页{ for(i=0;i<80;i++) //控制一行{ ch=getchar(); //接收输入字符temp->data[i]=ch; //给temp指向的行赋值····temp->length++;//行中字符长度加1if(ch=='#'){NUM=j; break; //文章结束时,Num来记录整个文章的行数}}}在字符输入的过程中,如果在单行输入的字符超过了80个字符,则需要以下操作:输入字符数大于80,重新分配空间建立下一行temp->next=(LinkList *)malloc(sizeof(LinkList)) ;给temp的前驱指针赋值:temp->next->pre=temp;temp指向当前行:temp=temp->next;将下一行初始化为字符串结束标志,防止出现乱码:for(i=0;i<80;i++)temp->data[i]='\0';记录整个文章的行数:temp->row=NUM+1;返回指向最后一行指针:return temp;文本输入部分到此结束。
编译原理实验报告——词法分析器(内含源代码)

编译原理实验(一)——词法分析器一.实验描述运行环境:vc++2008对某特定语言A ,构造其词法规则。
该语言的单词符号包括:12状态转换图3程序流程:词法分析作成一个子程序,由另一个主程序调用,每次调用返回一个单词对应的二元组,输出标识符表、常数表由主程序来完成。
二.实验目的通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;使学生掌握编译程序设计的基本方法和步骤;能够设计实现编译系统的重要环节。
同时增强编写和调试程序的能力。
三.实验任务编制程序实现要求的功能,并能完成对测试样例程序的分析。
四.实验原理char set[1000],str[500],strtaken[20];//set[]存储代码,strtaken[]存储当前字符char sign[50][10],constant[50][10];//存储标识符和常量定义了一个Analyzer类class Analyzer{public:Analyzer(); //构造函数 ~Analyzer(); //析构函数int IsLetter(char ch); //判断是否是字母,是则返回 1,否则返回 0。
int IsDigit(char ch); //判断是否为数字,是则返回 1,否则返回 0。
void GetChar(char *ch); //将下一个输入字符读到ch中。
void GetBC(char *ch); //检查ch中的字符是否为空白,若是,则调用GetChar直至ch进入一个非空白字符。
void Concat(char *strTaken, char *ch); //将ch中的字符连接到strToken之后。
int Reserve(char *strTaken); //对strTaken中的字符串查找保留字表,若是一个保留字返回它的数码,否则返回0。
void Retract(char *ch) ; //将搜索指针器回调一个字符位置,将ch置为空白字符。
编译链接执行实验报告(3篇)

第1篇一、实验目的1. 理解编译、链接和执行的基本概念和过程。
2. 掌握使用编译器、链接器和执行器完成程序编译、链接和执行的基本操作。
3. 学习调试程序,解决编译、链接和执行过程中出现的问题。
二、实验环境1. 操作系统:Windows 102. 编译器:Microsoft Visual Studio 20193. 链接器:Microsoft Visual Studio 20194. 执行器:Windows 10自带三、实验内容1. 编译程序2. 链接程序3. 执行程序4. 调试程序四、实验步骤1. 编译程序(1)创建一个名为“HelloWorld.c”的源文件,内容如下:```cinclude <stdio.h>int main() {printf("Hello, World!\n");return 0;}```(2)打开Microsoft Visual Studio 2019,创建一个控制台应用程序项目。
(3)将“HelloWorld.c”文件添加到项目中。
(4)在项目属性中设置编译器选项,选择C/C++ -> General -> Additional Include Directories,添加源文件所在的目录。
(5)点击“生成”按钮,编译程序。
2. 链接程序(1)在Microsoft Visual Studio 2019中,点击“生成”按钮,生成可执行文件。
(2)查看生成的可执行文件,路径通常在项目目录下的“Debug”或“Release”文件夹中。
3. 执行程序(1)双击生成的可执行文件,或在命令行中运行。
(2)查看输出结果,应为“Hello, World!”。
4. 调试程序(1)在Microsoft Visual Studio 2019中,点击“调试”按钮。
(2)程序进入调试模式,可以设置断点、观察变量等。
(3)运行程序,观察程序执行过程,分析问题原因。
计算机编译原理实验报告

编译原理实验报告实验一词法分析设计一、实验功能:1、对输入的txt文件内的内容进行词法分析:2、由文件流输入test.txt中的内容,对文件中的各类字符进行词法分析3、打印出分析后的结果;二、程序结构描述:(源代码见附录)1、分别利用k[],s1[],s2[],s3[]构造关键字表,分界符表,算术运算符表和关系运算符表。
2、bool isletter(){} 用来判断其是否为字母,是则返回true,否则返回false;bool isdigit(){} 用来判断其是否为数字,是则返回true,否则返回false;bool iscalcu(){} 用来判断是否为算术运算符,是则返回true,否则返回false;bool reserve(string a[]){} 用来判断某字符是否在上述四个表中,是则返回true,否则返回false;void concat(){} 用来连接字符串;void getn(){} 用来读取字符;void getb(){} 用来对空格进行处理;void retract(){}某些必要的退格处理;int analysis(){} 对一个单词的单词种别进行具体判断;在主函数中用switch决定输出。
三、实验结果四、实验总结词法分析器一眼看上去很复杂,但深入的去做就会发现并没有一开始想象的那么困难。
对于一个字符的种别和类型可以用bool函数来判断,对于关键字和标示符的识别(尤其是3b)则费了一番功夫,最后对于常数的小数点问题处理更是麻烦。
另外,这个实验要设定好时候退格,否则将会导致字符漏读甚至造成字符重复读取。
我认为,这个实验在程序实现上大体不算困难,但在细节的处理上则需要好好地下功夫去想,否则最后的程序很可能会出现看上去没有问题,但实际上漏洞百出的状况。
将学过的知识应用到实际中并不简单,只有自己不断尝试将知识转化成程序才能避免眼高手低,对于知识的理解也必将更加深刻。
实验二LL(1)分析法一、实验原理:1、写出LL(1)分析法的思想:当一个文法满足LL(1)条件时,我们就可以为它构造一个不带回溯的自上而下的分析程序,这个分析程序是有一组递归过程组成的,每个过程对应文法的一个非终结符。
源代码编译

源代码编译【实验名称】:源代码编译【实验环境】:RedhatA:192.168.18.1 255.255.255.0Windows Xp:192.168.18.100 255.255.255.0 网关:192.168.18.1 【实验目标】:1. 重新编译安装2.iptables编译安装【实验步骤】:重新编译安装RedhatA:1.修改内存为512MB2..取消多余模块(nfslock)-----ntsysv3.挂载光盘:Layer7.isoMount /dev/cdrom /media/4.跳转到src下解压文件释放内核源码包,Cd /usr/srctar zxvf /media/linux-2.6.28.10.tar.gztar zxvf /media/netfilter-Laryer7-v2.22.tar.gz5. 合并并打补丁Cd linux-2.6.28.10/patch -p1 < ../netfilter-layer7-v2.22/kernel-2.6.25-2.6.28-layer7-2.22.patch6.配置内核编译参数cp /boot/config-2.6.18-164.el5 .config7.在源码目录中执行―make menuconfig‖命令⑴选择networking support -→⑵选择networking options-→⑶选择networking packet filtering framwork -→⑷选择Core netfilter configuration-→①<M>netfilter connection traceking support②<M>laryer7③<M>―time‖ match support④<M>"string" match support⑤<M>"connlimit" match support"⑥<M>―iprange‖ address range match support⑦<M>―state‖ match support⑧<M>"mac" address match support⑨选择exit后退⑸选择IP netfilter configuration①选择<M>IPv4 connection tracking support (require for NAT)”②<M>Full NAT③选择exit退出并保存(YES)8.编译内核的模块文件、执行程序--------make9.安装编译好的模块文件-----执行make modules__install 命令查看配置:ll /lib/ modulesll /lib/ modules/2.6.28.10/ll /boot10.安装编译好的内核执行程序-----执行make install 命令11.查看配置----cat /etc/grup.conf12.重启(reboot)长按“↓”选择linux-2.6.28.1013.以root登录,用命令:uname –r 查看版本重新编译安装iptables工具RedhatA:1.挂载光盘Layer7.iso拷贝iptables文件和layer7文件到根下cp /media/iptables-1.4.7.tar.bz2 。
C语言实验报告参考源代码

printf("last: %d\n",n);} /*最后出局者的编号*/
实验 7 函数及其应用
第二个错误:if( fabs(x1-x0)<=0.00001 ) 应改为:if( fabs(x1-x0)>=0.00001 ) 因只有 fabs(x1-x0)>=0.00001 才须递归。 4.设计一个程序,判断一个整数n 是否是素数。 具体要求如下: (1)编制一个函数int prime(number),判断整数number 是否是素数。 (2)编制主函数,由键盘输入整数number,调用(1)中的函数,若返回值为真则是素 数,否则不是素数。 (3)分别用以下数据运行该程序:103,117。
printf("\n");
}
/*打印处理后矩阵,此时第 1 列上的元素为每行的最大数*/
}
5.猴子选大王问题:n 个人围坐一圈,并顺序编号 1~n,从 1 号开始数,每数到 m 个 就让其出局,重复...。求最后出局者的编号。当 n=50,m=3 时 ,答案为 11
具体要求如下: (1)使用一维数组存放每个人的编号,每数到 m 个数就让其出局,出局者编号为 0。 (2)使用 for 循环嵌套实现。 【程序源代码】 #include "stdio.h" main() {int a[51],i,j,m=0,n; for(i=1;i<=50;i++)a[i]=i;/*为了符合习惯,数组下标从 1 开始,下标就是编号*/ for(j=1;j<=50/3;j++) /*外层循环最多循环 50/3 次*/
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程设计报告( 2013-- 2014年度第1学期)名称:编译技术课程设计B题目:简单编译程序的设计与实现院系:计算机系班级:XXX学号:XXX学生姓名:XXX指导教师:XXX设计周数:XXX成绩:日期:XX 年XX 月实验一.词法分析器的设计与实现一、课程设计(综合实验)的目的与要求1.1 词法分析器设计的实验目的本实验是为计算机科学与技术专业的学生在学习《编译技术》课程后,为加深对课堂教学内容的理解,培养解决实际问题能力而设置的实践环节。
通过这个实验,使学生应用编译程序设计的原理和技术设计出词法分析器,了解扫描器的组成结构,不同种类单词的识别方法。
能使得学生在设计和调试编译程序的能力方面有所提高。
为将来设计、分析编译程序打下良好的基础。
1.2 词法分析器设计的实验要求设计一个扫描器,该扫描器是一个子程序,其输入是源程序字符串,每调用一次识别并输出一个单词符号。
为了避免超前搜索,提高运行效率,简化扫描器的设计,假设该程序设计语言中,基本字(也称关键词)不能做一般标识符用,如果基本字、标识符和常数之间没有确定的运算符或界符作间隔,则用空白作间隔。
单词符号及其内部表示如表1-1所示,单词符号中标识符由一个字母后跟多个字母、数字组成,常数由多个十进制数字组成。
单词符号的内部表示,即单词的输出形式为二元式:(种别编码,单词的属性值)。
表1-1 单词符号及其内部表示二、设计(实验)正文1.词法分析器流程图2.词法分析器设计程序代码// first.cpp : 定义控制台应用程序的入口点。
//#include"stdafx.h"#include<iostream>#include<string>using namespace std;int what(char a){if((int(a)>=48)&&(int(a)<=57)){return 0;//0-9数字}elseif((int(a)>=97)&&(int(a)<=122)){return 1;//a-z的字母}else{return 2;//其他的标点符号}}void scan(char a[],int &m,char zc[100][100],int &n){char zh[100];int b=0,weizhi,r=0;int zbbm;//-----------------------------检测整形常数while(a[m]==' '){cout<<"遇到空格"<<endl;m++;}if(what(a[m])==0){while(what(a[m])==0){b=b*10+int(a[m])-48;m++;}zbbm=7;cout<<"("<<zbbm<<","<<b<<")"<<endl;}else//----------------------------------检测字符型if(what(a[m])==1){if((a[m]=='b')&&(a[m+1]=='e')&&(a[m+2]=='g')&&(a[m+3]=='i')&&(a[m+4]=='n')& &(what(a[m+5])==2)){m=m+5;zbbm=1;cout<<"("<<zbbm<<",-)"<<endl;}//=====检测beginelseif((a[m]=='i')&&(a[m+1]=='f')&&(what(a[m+2])==2)){m=m+2;zbbm=2;cout<<"("<<zbbm<<",-)"<<endl;}//检测ifelseif((a[m]=='t')&&(a[m+1]=='h')&&(a[m+2]=='e')&&(a[m+3]=='n')&&(what(a[m+4])= =2)){m=m+4;zbbm=3;cout<<"("<<zbbm<<",-)"<<endl;}//检测thenelseif((a[m]=='e')&&(a[m+1]=='l')&&(a[m+2]=='s')&&(a[m+3]=='e')&&(what(a[m+4])= =2)){m=m+4;zbbm=4;cout<<"("<<zbbm<<",-)"<<endl;}//检测elseelseif((a[m]=='e')&&(a[m+1]=='n')&&(a[m+2]=='d')&&(what(a[m+3])==2)){m=m+3;zbbm=5;cout<<"("<<zbbm<<",-)"<<endl;}//检测end//----------------------------对未知字符的检测else{int j=0;while(what(a[m])!=2){zh[j]=a[m];m++;j++;}zh[j]='#';if(n==0){j=0;while(zh[j]!='#'){zc[0][j]=zh[j];j++;}zc[0][j]='#';n=1;weizhi=1;}elseif(n>0){int k=0,y=1;while((k<n)&&(y==1)){r=0;while(zc[k][r]!='#'){r++;}if(r!=j){k++;y=1;}elseif(r==j){r=0;while((int(zc[k][r])==int(zh[r]))&&(r<j)){r++;}if(r==j){weizhi=k+1;y=0;}else{k++;y=1;}}}if(y==1){j=0;while(zh[j]!='#'){zc[n][j]=zh[j];j++;}zc[n][j]='#';n=n+1;weizhi=n;}}zbbm=6;//怎么输出地址cout<<"("<<zbbm<<","<<weizhi<<")"<<endl;}}elseif(what(a[m])==2){if(a[m]=='+'){zbbm=8;m++;cout<<"("<<zbbm<<",-)"<<endl;}//检测+elseif(a[m]=='('){zbbm=11;m++;cout<<"("<<zbbm<<",-)"<<endl;}//检测(elseif(a[m]==')'){zbbm=12;m++;cout<<"("<<zbbm<<",-)"<<endl;}//检测)elseif(a[m]=='*'){if(a[m+1]=='*'){zbbm=10;m+=2;}else{zbbm=9;m++;}cout<<"("<<zbbm<<",-)"<<endl;}}}int main(){char zc[100][100];int n=0;cout<<"begin------------1"<<endl;cout<<"if ------------2"<<endl;cout<<"then ------------3"<<endl;cout<<"else ------------4"<<endl;cout<<"end ------------5"<<endl;cout<<"标志符------------6"<<endl;cout<<"整型常数------------7"<<endl;cout<<"+------------8"<<endl;cout<<"*------------9"<<endl;cout<<"**------------10"<<endl;cout<<"(------------11"<<endl;cout<<")------------12"<<endl;cout<<"========================================================="<<endl;cout<<endl;int m=0;char a[100];cout<<"请输入测试语句:";cin.getline(a,100,'\n');cout<<"输出格式为: (种别编码,单词的属性值)"<<endl;while(a[m]!='#'){scan(a,m,zc,n);}return 0;}3.词法分析器运行结果实验二. 算符优先分析的设计与实现一、课程设计(综合实验)的目的与要求2.1 算符优先分析程序设计的实验目的本实验是为计算机科学与技术专业的学生在学习《编译技术》课程后,为加深对课堂教学内容的理解,培养解决实际问题能力而设置的实践环节。