试验统计学实验一
辅修统计学实验课1要求与数据

辅修统计学实验课要求与数据时间地点11、13、14周周1 9-12节信息楼427实验1时间11周周一(2015.11.16)实验内容图表制作、描述性统计分析统计软件Excel, PHstat, Spss实验要求1.逐步熟悉统计软件(Excel, PHstat, Spss),掌握原始数据与统计分析结果的存储、调用和呈现方法。
2.掌握借助于统计软件进行描述性统计分析的方法:编制频数分布表,绘制直方图、茎叶图、箱线图、散点等图形,计算均值、标准差、分位数、峰度、偏度等数据数字特征。
3.完成并提交指定练习题。
试验方法详见《统计实验讲义》,周晓东。
练习题:1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果见“直方图.xml”sheet2,用Excel制作一张频数分布表;以及条形图。
并同时使用SPSS绘制条形图。
2.某行业管理局所属40个企业2002年的产品销售收入数据(单位:万元)见“直方图.xml”sheet3。
要求:1) 根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;2) 如果按规定:销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
3.某百货公司连续40天的商品销售额(单位:万元)见“直方图.xml”sheet4。
要求:根据上面的数据进行适当的分组,编制频数分布表,并使用不同的工具绘制直方图。
4.为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果见“茎叶图.xml”sheet3。
1)利用计算机对上面的数据进行排序;2)以组距为10进行等距分组,整理成频数分布表,并绘制直方图。
3)制做茎叶图,并与直方图作比较。
5.A,B两个班学生的数学考试成绩数据见“茎叶图.xml”sheet4。
卫生统计学第1-5次实验内容
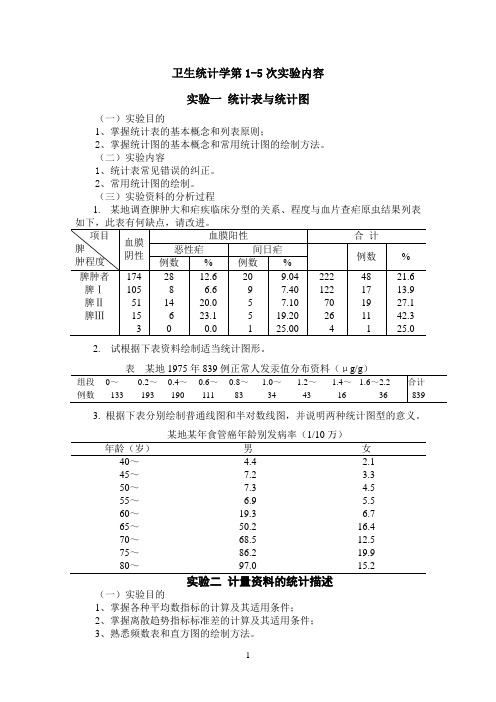
卫生统计学第1-5次实验内容实验一统计表与统计图(一)实验目的1、掌握统计表的基本概念和列表原则;2、掌握统计图的基本概念和常用统计图的绘制方法。
(二)实验内容1、统计表常见错误的纠正。
2、常用统计图的绘制。
(三)实验资料的分析过程1.某地调查脾肿大和疟疾临床分型的关系、程度与血片查疟原虫结果列表2.试根据下表资料绘制适当统计图形。
3. 根据下表分别绘制普通线图和半对数线图,并说明两种统计图型的意义。
某地某年食管癌年龄别发病率(1/10万)年龄(岁)男女40~ 4.4 2.145~7.2 3.350~7.3 4.555~ 6.9 5.560~19.3 6.765~50.2 16.470~68.5 12.575~86.2 19.980~97.0 15.2实验二计量资料的统计描述(一)实验目的1、掌握各种平均数指标的计算及其适用条件;2、掌握离散趋势指标标准差的计算及其适用条件;3、熟悉频数表和直方图的绘制方法。
(二)实验内容1、编制大样本定量资料的频数分布表,了解资料的分布规律;2、算术均数、几何均数、中位数、极差、标准差的计算,医学参考值范围的制订。
(三)实验资料的分析过程1、某地100例30-40岁健康男子血清总胆固醇值(mg/dl )测定结果如下: 202 165 199 234 200 213 155 168 189 170 188 168 184 147 219 174 130 183 178 174 228 156 171 199 185 195 230 232 191 210 195 165 178 172 124 150 211 177 184 149 159 149 160 142 210 142 185 146 223 176 241 164 197 174 172 189 174 173 205 224 221 184 177 161 192 181 175 178 172 136 222 113 161 131 170 138 248 153 165 182 234 161 169 221 147 209 207 164 147 210 182 183 206 209 201 149 174 253 252 156(1)编制频数分布表并画出直方图;(2)根据频数表计算均值和中位数,并说明用哪一个指标比较合适; (3)计算百分位数5P 、25P 、75P 和95P 。
《统计学》上机实验报告(一)

《统计学》实验报告一姓名:王璐专业:财政学(税收方向)学号:2010128107日期:2012年10 月9 日地点:实验中心701实验项目一描述性统计、区间估计在EXCEL里的实现一、实验目的1、掌握利用EXCEL菜单进行数据的预处理;2、掌握利用EXCEL进行描述性统计;3、掌握利用EXCEL进行区间估计。
二、实验要求1、EXCEL环境与数据预处理的操作;2、描述性统计,包括统计图表的绘制;数据分组处理;集中趋势描述、离散程度描述、分布形状描述。
3、区间估计,包括总体均值、总体比例、总体方差的区间估计计算。
三、实验内容(一)分类数据的描述性统计实验数据:餐厅服务质量和价位评价.XLS顾客服务质量评价的频数表(按性别分)、条形图、饼图(二)数值性数据的描述性统计实验数据:城乡居民储蓄数据.XLS随着生活水平的逐渐提高,居民的储蓄存款也在日益增加,数据2.XLS是自1990年~2006年城乡居民人民币储蓄存款额,储蓄存款包括定期和活期(单位:元)。
利用EXCEL,对数据2.XLS作如下分析:1、城乡居民人民币活期存款的众数、中位数和均值是多少?2、城乡居民人民币定期存款的方差和标准差是多少?3、定期存款和活期存款相比,哪种数据的变动性更大?(三)总体参数的区间估计1、成绩分析。
实验数据:期末成绩.XLS1假设学生的各门期末考试成绩均服从正态分布,选定一门课程,并给出该门课程平均成绩的置信水平为95%的区间估计。
2、顾客满意度分析。
某超市为了了解顾客对其服务的满意度,随机抽取了其会员中的50个样品进行电话调查,如果有38个顾客对此超市的服务表示满意,试求对该超市服务满意的顾客比例的95%置信区间。
四、实验结果(一)分类数据的描述性统计A顾客服务质量评价频数表(按性别分)评价等级男女极好45 21很好98 52好49 35一般20 11差9 10B条形图C.饼状图2(二)数值性数据的描述性统计解答:1.众数:无中位数:11615.9 均值:18553.592.方差:887955495.60 标准差:29798.583.活期存款的离散系数=标准差/均值=0.963602定期存款的离散系数=标准差/均值=0.696094因为0.963602>0.696094 所以,活期存款的变动性更大(三)总体参数的区间估计解答:1.根据区间估计的计算公式:均值±半径由题可得,均值=71.89474,半径=1.312076,得出最终结果,置信区间为:(70.5827,73.2068)2.根据总体比例的区间估计公式:比例±半径由题可得,比例 p=38/50=0.76,半径=0.1184 ,得出最终结果,置信区间为:(0.6416,0.8784)五、实验心得我个人认为自己的动手能力比较差,所以在做上机实验前,心里略有担心。
统计学实验报告 一

⑥选中组距和频数,插入一个折线图,将名字改为灯泡耐用时间折线图。
(3)21--30学号同学绘制第二产业国内生产总值的线图。
本人学号为25,所以绘制第二产业国内生产总值的折线图。首先选中第二产业国内生产总值的数据区域,然后选中工具栏中的插入-图标,选择折线图,即可绘制线图。
3选中血型和出现的频数区域,点击工具栏中的插入,即可插入一个折线图。
(2)试将以上数据整理成组距数列,并绘制次数分布直方图和次数分布折线图。
①将题目中的表格复制到一个新的Excel中。
②选中表格中全部数据区域,在工具栏的“开始”一栏中点击“替换”,将表格中的空格全部替换掉。
③根据数据区域计算出合适的组距,并写下来。
我院任课教师有实验课的均要求有实验报告,每个实验项目要求有一份实验报告,实验报告按照格式书写完毕后,经辅
导实验的教师批改后按照实验室收集存档。
在第一节课时,觉得这门课对我来说应该不难,里边有很多内容早在大一时候便就已经学过了,因此便在不知不觉中不想再听老师的讲解,慢慢地却发现里边讲的好多内容我都不懂,老师在上课过程中的一系列操作问题我都不懂。渐渐地我终于意识到我该好好地听老师讲课,我虽然懂得一些操作,但都是平时经常用的一些基础的操作,很多的高级应用操作我都还没有接触到,而且缺乏实践经验。孰能生巧,一个人理论上再完善,没有通过大量的练习,在遇到问题时往往会不知所措。通过这门课的学习我意识到学习与实践的重要性,在以后的学习中我一定要多练习,多实践,以求自己对知识掌握得更好。以下是该门课程的主要学习内容和我的一点感悟。
3、能熟练地运用Excel创建统计表和统计图。
3.实验内容
练习一、数据的筛选与排序
统计学实验报告

统计学实验报告姓名:田媛学号:20092771 班级:营销0901 成绩:一、实验步骤总结:成绩:实验一:数据的搜集与整理1.数据收集:(1)间接数据的搜集。
有两种方法,一种是直接进入网站查询数据,另一种是使用百度等搜索引擎。
(2)直接数据的搜集。
直接统计数据可以通过两种途径获得:一是统计调查或观察,二是实验。
统计调查是取得社会经济数据的最主要来源,它主要包括普查、重点调查、典型调查、抽样调查、统计报表等调查方式。
2.数据的录入:数据的录入是将搜集到的数据直接输入到数据库文件中。
数据录入既要讲究效率,又要保证质量。
3.数据文件的导入:Excel数据文件的导入是将别的软件形成的数据或数据库文件,转换到Excel工作表中。
导入的方法有二,一是使用“文件-打开”菜单,二是使用“数据-导入外部数据-导入数据”菜单,两者都是打开导入向导,按向导一步步完成对数据文件的导入。
4.数据的筛选:数据的筛选是从大数据表单中选出分析所要用的数据。
Excel中提供了两种数据的筛选操作,即“自动筛选”和“高级筛选”。
5.数据的排序:Excel的排序功能主要靠“升序排列”(“降序排列”)工具按钮和“数据-排序”菜单实现。
在选中需排序区域数据后,点击“升序排列“(“降序排列”)工具按钮,数据将按升序(或降序)快速排列。
6.数据文件的保存:保存经过初步处理的Excel数据文件。
可以使用“保存”工具按钮,或者“文件-保存”菜单,还可以使用“文件-另存为”菜单。
实验二:描述数据的图标方法1.频数频率表:(一)Frequency函数使用方法举例:假设工作表里列出了考试成绩。
这些成绩为79、85、78、85、83、81、95、88 和97,并分别输入到单元格A1:A9。
这一列考试成绩就是data_array。
Bins_array 是另一列用来对考试成绩分组的区间值。
在本例中,bins_array 是指C4:C6 单元格,分别含有值70、79 和89。
统计学原理实验指导书

百度文库- 让每个人平等地提升自我!统计学原理实验指导书经济学院编二○○八年二月统计学原理实验一数据的整理与显示一、实验目的通过本次实验,掌握用EXCEL对数据进行整理、加工、作图,以发现数据中的一些基本特征,为进一步分析提供思路。
二、实验性质必修,基础层次三、主要仪器及试材计算机及EXCEL软件四、实验内容1.数据的预处理2.品质数据的整理与显示3.数值型数据的整理与显示五、实验学时2学时六、实验方法与步骤1.开机;2.找到“统计学原理实验一数据”,打开EXCEL文件;3.按要求完成上机作业,并把文件用自己学号命名保存供老师检查;4.完成实验报告,注意要对每个习题的结论与统计学解释写在实验报告上。
七、上机作业演示题:A、B两个班学生的数学考试成绩数据见“统计学原理实验一”文件的“book3.演示”。
①将两个班的考试成绩用一个公共的分组体系编制分布表;并计算出累积频数和累积频率;②绘制复式条形图、环形图、雷达图;③分析比较两个班考试成绩的分布特点及差异;比较两个班考试成绩分布的特点3.01.某行业管理局所属40个企业2002年的产品销售收入数据(单位:万元):105 117 97 124 119 108 88 129 114 105 123 116 115 110 115 100 87 107 119 103 103 137 138 92 118 120 112 95 142 136 146 127 135 117 113 104 125 108 126 152 105 117 9711910888129114105123116115110115100871071191031031371389211812011295142136146127135117113104125108126见“统计学原理实验一”文件的“book3.01”。
要求:①根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;②如果按规定:销售收入在125万元以上为先进企业,115~125万元为良好企业,105~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
11-12统计学实验报告(实验一、实验二)

三、《统计学实验》教材第79页第(4)题。
四、已知1998-2008年重庆国内生产总值数据如下(按当年价格计算,单位:亿元)。
年份
第一产业国内生产总值
第二产业国内生产总值
第三产业国内生产总值
1998
300.89
558.87
580.80
1999
286.16
386.38
1500.97
1564.79
2007
482.39
1892.10
1748.02
2008
575.40
2433.27
2087.99
要求:(1)绘制第一、二、三产业国内生产总值的线图。
(2)根据其中任意二年的国内生产总值数据,绘制环形图。
五、《统计学实验》教材第79页第(3)题。
题号
得分
二
三
四
五
①经济学②管理学③工学④理学⑤其他
4.你的性别为()
①男②女
得到的调查数据见表1
表1调查数据
问卷
号
问题
1
问题
2
问题
3
问题
4
问卷
号
问题
1
问题
2
问题
3
问题
4
1
2
2
1
1
17
1
2
1
1
2
1
2
2
1
18
1
2
1
1
3
3
2
4
2
19
3
2
4
1
4
3
2
1
2
统计学实验报告

统计学实验报告实验内容:Excel在描述统计中的应用Excel在相关与回归中的应用班级:组员:实验一、Excel在描述统计中的应用实验目的:通过实践训练,使学生能够利用“直方图”工具计算频率分布并制作直方图,利用“描述统计”工具对原始数据进行统计分析,计算分组数据的平均值和方差。
一、利用直方图工具计算频率分布并制作直方图资料:某班31名学生家庭人均纯收入与生活费支出如下:家庭人均纯收入如下:18000 2000 5000 100000 20000 7000 40000 30000 20000 9000 8000 40000 40000 30000 2500 30000 30000 30000 6000 6000 20000 7000 7000 8000 6000 36000 2500 10000 6000 7000 6000生活费支出如下:1000 500 600 1200 1000 650 1400 800 1000 800 1000 2000 2000 800 500 800 800 500 540 700 800 650 600 800 500 800 450 500 500 700 500 要求:1、以0、500、800、1000、1500为组限计算生活费支出的频数和累计频率;以0、5000、10000、20000、40000为组限计算家庭人均纯收入的频数和累计频率。
2、作出生活费支出、家庭人均纯收入的直方图3、计算生活费支出、家庭人均纯收入的平均值、中位数、方差、标准差、95%置信区间。
实验步骤:把生活费支出输入A1中,把组限输入B1中,将数据输入到表格。
1、执行菜单命令“工具”——“数据分析”2、选择“直方图”,单击“确定”按钮,弹出“数据分析”,输入区蜮:选择A1选项,按住左键不放拖到A32;接受区蜮:选择B1选项,按住左键不放拖到B6;选中“标志”复选框,选中“输出区蜮”并选择C1指定输出区蜮,选中“累计百分率”复选框和“图表输出”复选框3、单击“确定”按钮,得到各组频数和累计频率以及直方图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、数据分析结果如下表:
表1 水稻F2代株高数据的基本特征数
基本特征数计算结果
平均数x109.7131667cm
离均差平方和SS720022.226cm2
方差S21202.040444cm2
标准差S34.67045492cm
变异系数CV31.6009974%
最大值max177.6cm
最小值min24.4cm
极差R153.2cm
样本大小n600
峰值g2-0.589380069
偏斜度g1-0.6121756
分析:根据上表结果,在水稻F2代株高调查中,共抽取了600个样本。
样本中最大值为177.6cm,最小值为24.4cm,极差为153.2cm;变异系数为31.6009974%;其峰值为-0.589380069,为一个小于0的值,说明其次数分布曲线比正态分布低,为低润峰;其偏斜度为-0.6121756,小于0,说明该次数分布曲线不对称,且峰往右边偏。
表2 玉米单交种株高数据的基本特征数
基本特征数计算结果
平均数x229.2075cm
离均差平方和SS68065.63625cm2
方差S2113.6321139cm2
标准差S10.65983649cm
变异系数CV 4.6507363%
最大值max257.8cm
最小值min200.3cm
极差R57.5cm
样本大小n600
峰值g2-0.112906602
偏斜度g10.005430104
分析:根据上表结果,在玉米单交种株高调查中,共抽取了600个样本。
样本中最大值为257.8cm,最小值为200.3cm,极差为57.5cm;变异系数为4.6507363%;其峰值为-0.112906602,小于0,说明其次数分布曲线比正态分布低,为低润峰;其偏斜度为0.005430104,大于0,说明该次数分布曲线不对称,且峰往左边偏。
2、比较两组数据变异程度的大小:
水稻F2代株高:CV1=31.6009974%
玉米单交种株高:CV2=4.6507363%
水稻F2代株高的变异比玉米单交种株高的变异大。
3、次数分布表与次数分布图
表3 水稻F2代株高的次数分布表
组限组中值(X)次数( f )
≤30.924.45
30.9~43.937.420
43.9~56.950.449
56.9~69.963.450
69.9~82.976.422
82.9~95.989.420
95.9~108.9102.466
108.9~121.9115.483
121.9~134.9128.4138
134.9~147.9141.489
147.9~160.9154.443
160.9~173.9167.411
>173.9 180.44
合计600
图1 水稻F2代株高的次数分布图
华南农业大学实验报告
专业班次13草业科学组别201330800119 题目科学型计算器和Excel在数据姓名熊姣日期2014.11.22 统计方面的使用方法
表4 玉米单交种株高的次数分布表
组限组中值(X)次数( f )
≤202.8 200.3 4
202.8~207.8 205.3 12
207.8~212.8 210.3 24
212.8~217.8 215.3 44
217.8~222.8 220.3 77
222.8~227.8 225.3 107
227.8~232.8 230.3 120
232.8~237.8 235.3 88
237.8~242.8 240.3 62
242.8~247.8 245.3 36
247.8~252.8 250.3 17
252.8~257.8 255.3 9
>257.8 260.3 0
合计600
图2 玉米单交种株高的次数分布图
成绩:教师:日期:
4、分析哪组数据更接近正态分布,为什么。
水稻F2代株高的峰值为-0.589380069,偏斜度为-0.6121756;玉米单交种株高的峰值为-0.112906602,偏斜度为0.005430104;可看出玉米单交种株高的峰值与偏斜度均小于水稻F2代株高,因此玉米单交种的数据更接近正态分布。
另从次数分布图亦可看出玉米单交种株高的分布接近于正态分布。
5、正态分布2χ适合性测验。
表5 水稻F2代株高的正态分布2χ适合性测验 次数O i
累计概率p i 组概率p i 理论数E i 卡方分量 5 0.011506814 0.011506814 6.904088699 0.525131401 20 0.028831625 0.01732481 10.3948862 8.875345944 49 0.06384305 0.035011425 21.00685513 37.30287827 50 0.125415923 0.061572873 36.94372351 4.614216965 22 0.219651063 0.09423514 56.5410843 21.10123142 20 0.345162817 0.125511754 75.3070524 40.61863992 66 0.490643999 0.145481182 87.28870894 5.192070472 83 0.637395186 0.146751187 88.05071227 0.289715935 138 0.76622278 0.128827594 77.29655647 47.67234433 89 0.86464368 0.098420901 59.05254036 15.18732866 43 0.930079305 0.065435625 39.26137491 0.356006828 11 0.967939742
0.037860436 22.71626179 6.042842416 4 0.032060258
19.23615503
12.06792208 600
600
199.8456747
df=13-1-2=10 =2
10,05.0χ18.30703805 =>)(P 2χ 1.73808E-37
=2χ199.8456747
分析:由于卡方分量为199.8456747,大于=210,05.0χ18.30703805。
所以判断差异显
华南农业大学实验报告
专业班次13草业科学 组别201330800119 题目科学型计算器和Excel 在数据 姓 名 熊姣 日期 2014.11.22 统计方面的使用方法
成 绩: 教师: 日期:
著,可以认为资料不服从正态分布。
表6 玉米单交种株高的2χ适合性测验
次数O i
累计概率p i
组概率p i 理论数E i 卡方分量 4 0.006619225 0.006619225 3.971535249 0.000204012 12 0.022308947 0.015689722 9.41383302 0.710471455 24 0.061879116 0.039570169 23.74210145 0.002801423 44 0.142278516 0.0803994 48.2396399 0.372609466 77 0.273890681 0.131612165 78.96729919 0.049010998 107 0.447477247 0.173586566 104.1519394 0.077880921 120 0.631946327 0.18446908 110.681448 0.784552546 88 0.789896744 0.157950417 94.77025006 0.483656906 62 0.898865441 0.108968697 65.38121811 0.174861164 36 0.959434727 0.060569286 36.34157161 0.003210405 17 0.986558554 0.027123828 16.27429664 0.032360561 9 0.996343718
0.009785164 5.871098213 1.667494911 0 0.003656282
2.193769135
2.193769135 600
1 600 6.552883902
df=13-1-2=10
=2
10
,05.0χ18.30703805 =>)(P 2χ0.766873026 =2χ 6.552883902
分析:由于卡方分量为6.552883902,小于=2
10,05.0χ18.30703805。
所以判断差异不显著,可以认为资料服从正态分布。