hadoop配置和启动详细步骤
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
最详细的Hadoop入门教程

最详细的Hadoop⼊门教程前⾔Hadoop 在⼤数据技术体系中的地位⾄关重要,Hadoop 是⼤数据技术的基础,对Hadoop基础知识的掌握的扎实程度,会决定在⼤数据技术道路上⾛多远。
这是⼀篇⼊门⽂章,Hadoop 的学习⽅法很多,⽹上也有很多学习路线图。
本⽂的思路是:以安装部署 Apache Hadoop2.x 版本为主线,来介绍 Hadoop2.x 的架构组成、各模块协同⼯作原理、技术细节。
安装不是⽬的,通过安装认识Hadoop才是⽬的。
本⽂分为五个部分、⼗三节、四⼗九步。
第⼀部分:Linux环境安装Hadoop是运⾏在Linux,虽然借助⼯具也可以运⾏在Windows上,但是建议还是运⾏在Linux系统上,第⼀部分介绍Linux环境的安装、配置、Java JDK安装等。
第⼆部分:Hadoop本地模式安装Hadoop 本地模式只是⽤于本地开发调试,或者快速安装体验 Hadoop,这部分做简单的介绍。
第三部分:Hadoop伪分布式模式安装学习 Hadoop ⼀般是在伪分布式模式下进⾏。
这种模式是在⼀台机器上各个进程上运⾏ Hadoop 的各个模块,伪分布式的意思是虽然各个模块是在各个进程上分开运⾏的,但是只是运⾏在⼀个操作系统上的,并不是真正的分布式。
第四部分:完全分布式安装完全分布式模式才是⽣产环境采⽤的模式,Hadoop 运⾏在服务器集群上,⽣产环境⼀般都会做HA,以实现⾼可⽤。
第五部分:Hadoop HA安装HA是指⾼可⽤,为了解决Hadoop单点故障问题,⽣产环境⼀般都做HA部署。
这部分介绍了如何配置Hadoop2.x的⾼可⽤,并简单介绍了HA的⼯作原理。
安装过程中,会穿插简单介绍涉及到的知识。
希望能对⼤家有所帮助。
第⼀部分:Linux环境安装第⼀步、配置 Vmware NAT ⽹络⼀、Vmware ⽹络模式介绍参考:/collection4u/article/details/14127671⼆、NAT模式配置NAT是⽹络地址转换,是在宿主机和虚拟机之间增加⼀个地址转换服务,负责外部和虚拟机之间的通讯转接和IP转换。
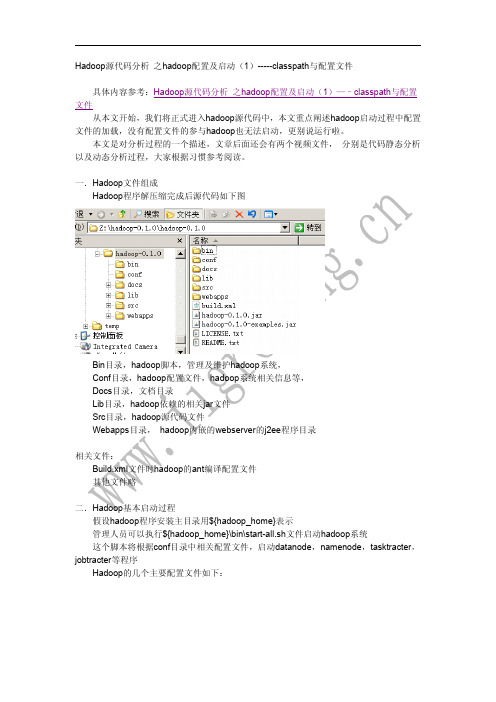
Hadoop源代码分析_之hadoop配置及启动(1)-----classpath与配置文件
* strings. If no such property is specified, then <code>null</code> * is returned. Values are whitespace or comma delimted. */ public String[] getStrings(String name) {
我们打开hadoop的源代码项目(eclipse的java项目)
如下图,我们打开如上目录及java源代码文件
双击左侧 main函数的节点, 然后右面显示相关源代码, 然后在 “runAndWait(new Configuration());”函数调用处,右击鼠标,弹出相关对话框,选择“open Declaration” 选项, 可以直接使用快捷方式 F3按键,可以快速到达相关源代码处 代码如下: private static void runAndWait(Configuration conf) throws IOException {
String valueString = get(name); // 重点语句,负责初始化相关代码,我们需要跟踪进入相 关代码
if (valueString == null) return null;
StringTokenizer tokenizer = new StringTokenizer (valueString,", \t\n\r\f"); List values = new ArrayList(); while (tokenizer.hasMoreTokens()) {
Hadoop的安装与配置

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。
简述启动和关闭hadoop集群的方式以及使用的相关指令。

简述启动和关闭hadoop集群的方式以及使用的相关指令。
Hadoop是一个开源的分布式数据处理框架,通常用于存储和处理大规模的数据集。
启动和关闭Hadoop集群是使用Hadoop框架的关键步骤。
本文将一步一步回答如何启动和关闭Hadoop集群,以及使用的相关指令。
一、Hadoop集群启动方式Hadoop集群可以通过两种方式进行启动:单节点启动和多节点启动。
1. 单节点启动单节点启动适用于在本地主机运行Hadoop的开发和测试环境。
在单节点启动方式下,所有Hadoop的组件都运行在一台主机上。
以下是单节点启动Hadoop集群的步骤:1. 安装Java开发环境在启动Hadoop之前,首先需要在机器上安装Java开发环境。
Hadoop依赖于Java来运行。
可以从Oracle官方网站下载并安装Java Development Kit(JDK)。
2. 配置Hadoop环境下载Hadoop的最新版本,并解压到本地目录。
接下来,需要配置Hadoop的环境变量。
打开Hadoop的安装目录,在conf目录下找到hadoop-env.sh文件。
通过编辑这个文件,设置正确的JAVA_HOME 路径。
3. 配置Hadoop集群在启动单节点Hadoop集群之前,需要配置Hadoop集群的相关参数。
打开conf目录下的core-site.xml和hdfs-site.xml文件,分别进行配置。
主要包括配置Hadoop文件系统的URL,配置Hadoop的本地文件夹路径,以及配置Hadoop的端口号等。
4. 格式化Hadoop文件系统在单节点模式下,需要手动初始化Hadoop文件系统。
在Hadoop 的安装目录下,使用命令`bin/hdfs namenode -format` 来格式化文件系统。
5. 启动Hadoop集群在Hadoop的安装目录下,使用命令`sbin/start-all.sh`来启动Hadoop集群。
这个命令会启动Hadoop的所有组件,包括NameNode,DataNode,SecondaryNameNode,以及JobTracker 等。
hadoop集群安装配置的主要操作步骤-概述说明以及解释

hadoop集群安装配置的主要操作步骤-概述说明以及解释1.引言1.1 概述Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。
它提供了高度可靠性、容错性和可扩展性的特性,因此被广泛应用于大数据处理领域。
本文旨在介绍Hadoop集群安装配置的主要操作步骤。
在开始具体的操作步骤之前,我们先对Hadoop集群的概念进行简要说明。
Hadoop集群由一组互联的计算机节点组成,其中包含了主节点和多个从节点。
主节点负责调度任务并管理整个集群的资源分配,而从节点则负责实际的数据存储和计算任务执行。
这种分布式的架构使得Hadoop可以高效地处理大规模数据,并实现数据的并行计算。
为了搭建一个Hadoop集群,我们需要进行一系列的安装和配置操作。
主要的操作步骤包括以下几个方面:1. 硬件准备:在开始之前,需要确保所有的计算机节点都满足Hadoop的硬件要求,并配置好网络连接。
2. 软件安装:首先,我们需要下载Hadoop的安装包,并解压到指定的目录。
然后,我们需要安装Java开发环境,因为Hadoop是基于Java 开发的。
3. 配置主节点:在主节点上,我们需要编辑Hadoop的配置文件,包括核心配置文件、HDFS配置文件和YARN配置文件等。
这些配置文件会影响到集群的整体运行方式和资源分配策略。
4. 配置从节点:与配置主节点类似,我们也需要在每个从节点上进行相应的配置。
从节点的配置主要包括核心配置和数据节点配置。
5. 启动集群:在所有节点的配置完成后,我们可以通过启动Hadoop 集群来进行测试和验证。
启动过程中,我们需要确保各个节点之间的通信正常,并且集群的各个组件都能够正常启动和工作。
通过完成以上这些操作步骤,我们就可以成功搭建一个Hadoop集群,并开始进行大数据的处理和分析工作了。
当然,在实际应用中,还会存在更多的细节和需要注意的地方,我们需要根据具体的场景和需求进行相应的调整和扩展。
hadoop 操作手册

hadoop 操作手册Hadoop 是一个分布式计算框架,它使用 HDFS(Hadoop Distributed File System)存储大量数据,并通过 MapReduce 进行数据处理。
以下是一份简单的 Hadoop 操作手册,介绍了如何安装、配置和使用 Hadoop。
一、安装 Hadoop1. 下载 Hadoop 安装包,并解压到本地目录。
2. 配置 Hadoop 环境变量,将 Hadoop 安装目录添加到 PATH 中。
3. 配置 Hadoop 集群,包括 NameNode、DataNode 和 JobTracker 等节点的配置。
二、配置 Hadoop1. 配置 HDFS,包括 NameNode 和 DataNode 的配置。
2. 配置 MapReduce,包括 JobTracker 和 TaskTracker 的配置。
3. 配置 Hadoop 安全模式,如果需要的话。
三、使用 Hadoop1. 上传文件到 HDFS,使用命令 `hadoop fs -put local_file_path/hdfs_directory`。
2. 查看 HDFS 中的文件和目录信息,使用命令 `hadoop fs -ls /`。
3. 运行 MapReduce 作业,编写 MapReduce 程序,然后使用命令`hadoop jar my_` 运行程序。
4. 查看 MapReduce 作业的运行结果,使用命令 `hadoop fs -cat/output_directory/part-r-00000`。
5. 从 HDFS 中下载文件到本地,使用命令 `hadoop fs -get/hdfs_directory local_directory`。
6. 在 Web 控制台中查看 HDFS 集群信息,在浏览器中打开7. 在 Web 控制台中查看 MapReduce 作业运行情况,在浏览器中打开四、管理 Hadoop1. 启动和停止 Hadoop 集群,使用命令 `` 和 ``。
hadoop的基本使用

hadoop的基本使用Hadoop的基本使用Hadoop是一种开源的分布式计算系统和数据处理框架,具有可靠性、高可扩展性和容错性等特点。
它能够处理大规模数据集,并能够在集群中进行并行计算。
本文将逐步介绍Hadoop的基本使用。
一、Hadoop的安装在开始使用Hadoop之前,首先需要进行安装。
以下是Hadoop的安装步骤:1. 下载Hadoop:首先,从Hadoop的官方网站(2. 配置环境变量:接下来,需要将Hadoop的安装目录添加到系统的环境变量中。
编辑~/.bashrc文件(或其他相应的文件),并添加以下行:export HADOOP_HOME=/path/to/hadoopexport PATH=PATH:HADOOP_HOME/bin3. 配置Hadoop:Hadoop的配置文件位于Hadoop的安装目录下的`etc/hadoop`文件夹中。
其中,最重要的配置文件是hadoop-env.sh,core-site.xml,hdfs-site.xml和mapred-site.xml。
根据具体需求,可以在这些配置文件中进行各种参数的设置。
4. 启动Hadoop集群:在完成配置后,可以启动Hadoop集群。
运行以下命令以启动Hadoop集群:start-all.sh二、Hadoop的基本概念在开始使用Hadoop之前,了解一些Hadoop的基本概念是非常重要的。
以下是一些重要的概念:1. 分布式文件系统(HDFS):HDFS是Hadoop的核心组件之一,用于存储和管理大规模数据。
它是一个可扩展的、容错的文件系统,能够在多个计算机节点上存储数据。
2. MapReduce:MapReduce是Hadoop的编程模型,用于并行计算和处理大规模数据。
它由两个主要的阶段组成:Map阶段和Reduce阶段。
Map阶段将输入数据切分为一系列键值对,并运行在集群中的多个节点上。
Reduce阶段将Map阶段的输出结果进行合并和计算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.配置jdk
1.1. Alt+p调出sftp窗口
1.2. 上传
说明:
如果是上传的文件夹必须是–r
put -r “path/filename”
1.3. 解压缩
1.4. 配置环境变量vi /etc/profile
让这个文件修改后生效
source /etc/profile
1.5. 查看jdk版本
2.配置ssh免密登录2.1.1.生成公钥和私钥
2.1.2.复制公钥
把公钥复制给需要免密登陆的机器
1把hadoop的hadoop2.6.4.tar.gz文件上传到一台linux系统(主节点)
3.创建一个安装目录
mkdir /root/apps
4.把hadoop-2.6.4解压到这个apps 目录
tar –zxvf hadoop-2.6.4.tar.gz /root/apps
5.配置hadoop的环境变量
vi /etc/profile
让prifile文件生效
source /etc/profile
6.进入hadoop的配置文件目录
7.需要配置五个配置文件7.1. c ore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux9:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/apps/hadoopdata</value>
</property>
</configuration>
7.2. h adoop-env.sh
/root/installers/jdk1.8.0_101
7.3. m apred-site.xml
<configuration>
<property>
<name></name>
<value>yarn</value>
</property>
</configuration>
7.4. y arn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>linux9</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7.5. s laves
只配置从节点
8.把配置好的hadoop文件分发到所有的从节点
9.关闭所有集群的防火墙
service iptables stop
10.设置并且同步系统时间
11.格式化这个hdfs
在主节点上
hadoop namenode –format
12.启动hdfs的服务
启动hdfs集群:
start-dfs.sh
jps 查看进程
主节点上会看到
从节点可以看到
start-all.sh
hadoop-daemon.sh start namenode start-dfs.sh
在浏览器上输入http://linux1:50070
13.启动yarn 服务
启动yarn(需要先执行过./sbin/start-dfs.sh)
./sbin/start-yarn.sh # 启动YARN
./sbin/mr-jobhistory-daemon.sh start historyserver 主节点进程
从节点进程
Yan可用户端hosts:8088
14.Hadoop 各种启动和停止脚本
1.启动hdfs集群(使用hadoop的批量启动脚本)
/root/apps/hadoop/sbin/start-dfs.sh
2.停止hdfs集群(使用hadoop的批量启动脚本)
/root/apps/hadoop/sbin/stop-dfs.sh
3.启动单个进程
[root@hadoop01 ~]# /root/apps/hadoop/sbin/hadoop-daemon.sh start namenode
[root@hadoop01 ~]# /root/apps/hadoop/sbin/hadoop-daemon.sh start datanode
4.停止单个进程
[root@hadoop01 ~]# /root/apps/hadoop/sbin/hadoop-daemon.sh stop datanode stopping datanode
[root@hadoop01 ~]# /root/apps/hadoop/sbin/hadoop-daemon.sh stop namenode
5.启动yarn集群(使用hadoop的批量启动脚本)
/root/apps/hadoop/sbin/start-yarn.sh
[root@hadoop01 ~]# /root/apps/hadoop/sbin/start-yarn.sh
6. 启动hadoop上的ResourceManager进程
/root/apps/hadoop/sbin/yarn-daemon.sh start resourcemanager
7.停止yarn
/root/apps/hadoop/sbin/stop-yarn.sh
[root@hadoop01 ~]# /root/apps/hadoop/sbin/stop-yarn.sh
6.停止hadoop上的resourcemanager
/root/apps/hadoop/sbin/yarn-daemon.sh stop resourcemanager。