武汉大学研究生课程-数据挖掘-2015级研究生试题
数据挖掘试题参考答案

大学课程《数据挖掘》试题参考答案范围:∙ 1.什么是数据挖掘?它与传统数据分析有什么区别?定义:数据挖掘(Data Mining,DM)又称数据库中的知识发现(Knowledge Discover in Database,KDD),是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。
数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。
区别:(1)数据挖掘的数据源与以前相比有了显著的改变;数据是海量的;数据有噪声;数据可能是非结构化的;(2)传统的数据分析方法一般都是先给出一个假设然后通过数据验证,在一定意义上是假设驱动的;与之相反,数据挖掘在一定意义上是发现驱动的,模式都是通过大量的搜索工作从数据中自动提取出来。
即数据挖掘是要发现那些不能靠直觉发现的信息或知识,甚至是违背直觉的信息或知识,挖掘出的信息越是出乎意料,就可能越有价值。
在缺乏强有力的数据分析工具而不能分析这些资源的情况下,历史数据库也就变成了“数据坟墓”-里面的数据几乎不再被访问。
也就是说,极有价值的信息被“淹没”在海量数据堆中,领导者决策时还只能凭自己的经验和直觉。
因此改进原有的数据分析方法,使之能够智能地处理海量数据,即演化为数据挖掘。
∙ 2.请根据CRISP-DM(Cross Industry Standard Process for Data Mining)模型,描述数据挖掘包含哪些步骤?CRISP-DM 模型为一个KDD工程提供了一个完整的过程描述.该模型将一个KDD工程分为6个不同的,但顺序并非完全不变的阶段.1: business understanding: 即商业理解. 在第一个阶段我们必须从商业的角度上面了解项目的要求和最终目的是什么. 并将这些目的与数据挖掘的定义以及结果结合起来.2.data understanding: 数据的理解以及收集,对可用的数据进行评估.3: data preparation: 数据的准备,对可用的原始数据进行一系列的组织以及清洗,使之达到建模需求.4:modeling: 即应用数据挖掘工具建立模型.5:evaluation: 对建立的模型进行评估,重点具体考虑得出的结果是否符合第一步的商业目的.6: deployment: 部署,即将其发现的结果以及过程组织成为可读文本形式.(数据挖掘报告)∙ 3.请描述未来多媒体挖掘的趋势随着多媒体技术的发展,人们接触的数据形式不断地丰富,多媒体数据库的日益增多,原有的数据库技术已满足不了应用的需要,人们希望从这些媒体数据中得到一些高层的概念和模式,找出蕴涵于其中的有价值的知识。
(完整版)数据挖掘_概念和技术[第三版]部分习题答案解析
![(完整版)数据挖掘_概念和技术[第三版]部分习题答案解析](https://img.taocdn.com/s3/m/89e3bb26240c844768eaee79.png)
1.4 数据仓库和数据库有何不同?有哪些相似之处?答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据。
它用表组织数据,采用ER数据模型.相似:它们都为数据挖掘提供了源数据,都是数据的组合.1。
3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。
使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。
答:特征化是一个目标类数据的一般特性或特性的汇总。
例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade point aversge)的信息,还有所修的课程的最大数量.区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较.最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。
关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件.例如,一个数据挖掘系统可能发现的关联规则为:major(X,“computing science”) ⇒ owns(X, “personal computer”)[support=12%, confidence=98%] 其中,X 是一个表示学生的变量。
这个规则指出正在学习的学生,12%(支持度)主修计算机科学并且拥有一台个人计算机。
这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度).分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。
数据挖掘汇总(题库含答案)
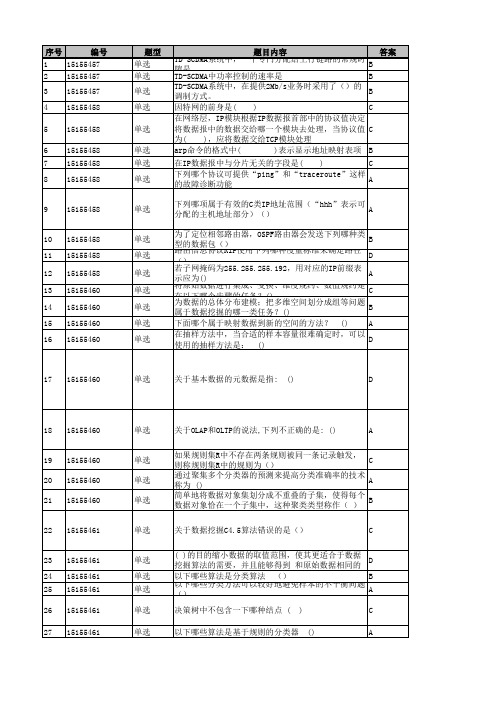
单选
单选 单选 单选
单选
单选 单选 单选 单选 单选
关于OLAP和OLTP的说法,下列不正确的是: ()
A
如果规则集R中不存在两条规则被同一条记录触发, 则称规则集R中的规则为()
C
通过聚集多个分类器的预测来提高分类准确率的技术 称为 ()
A
简单地将数据对象集划分成不重叠的子集,使得每个 数据对象恰在一个子集中,这种聚类类型称作( )
在抽样方法中,当合适的样本容量很难确定时,可以 使用的抽样方法是: ()
D
17 15155460
单选
关于基本数据的元数据是指: ()
D
18 15155460
19 15155460 20 15155460 21 15155460
22 15155461
23 15155461 24 15155461 25 15155461 26 15155461 27 15155461
多选
关于TCP协议,描述正确的是哪些?
A;C
多选
多选 多选 多选 多选
下面SNMP协议,下面哪两个表述是正确的?
A;D
TD-SCDMA系统中功率控制步长可为
A;B;C
通过数据挖掘过程所推倒出的关系和摘要经常被称 为:()
A;B
以下哪些学科和数据挖掘有密切联系?()
A;D
在聚类分析当中,( 簇。
)等技术可以处理任意形状的 A;D
)的时候,
A
BIRCH是一种( )
B
下面列出的条目中,哪些是数据仓库的基本特征: A;C;D
下面哪些属于可视化高维数据技术 ()
A;B;C;E
对于OSPF协议,你认为哪些是正确的?
数据挖掘概念与技术_课后题答案汇总汇总

数据挖掘——概念概念与技术Data MiningConcepts and T echniques习题答案第1章引言1.1 什么是数据挖掘?在你的回答中,针对以下问题:1.2 1.6 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。
使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。
解答:�特征化是一个目标类数据的一般特性或特性的汇总。
例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade pointaversge)的信息,还有所修的课程的最大数量。
�区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如,具有高 GPA 的学生的一般特性可被用来与具有低 GPA 的一般特性比较。
最终的描述可能是学生的一个一般可比较的轮廓,就像具有高 GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。
�关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。
例如,一个数据挖掘系统可能发现的关联规则为:major(X, “computing s cience”) ⇒ owns(X, “personalcomputer”) [support=12%, confid ence=98%]其中,X 是一个表示学生的变量。
这个规则指出正在学习的学生,12%(支持度)主修计算机科学并且拥有一台个人计算机。
这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度)。
�分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。
它们的相似性是他们都是预测的工具:分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值。
�聚类分析的数据对象不考虑已知的类标号。
《数据挖掘》试题与答案

一、解答题(满分30 分,每题 5 分)1.如何理解数据发掘和知识发现的关系?请详尽论述之第一从数据源中抽取感兴趣的数据,并把它组织成适合发掘的数据组织形式;而后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到公司的智能系统中。
知识发现是一个指出数据中有效、崭新、潜伏的、有价值的、一个不行忽略的流程,其最终目标是掌握数据的模式。
流程步骤:先理解要应用的领域、熟习有关知识,接着成立目标数据集,并专注所选择的数据子集;再作数据预办理,剔除错误或不一致的数据;而后进行数据简化与变换工作;再经过数据发掘的技术程序成为模式、做回归剖析或找出分类模型;最后经过解说和评论成为实用的信息。
2.时间序列数据发掘的方法有哪些,请详尽论述之时间序列数据发掘的方法有:1)、确立性时间序列展望方法 : 对于安稳变化特点的时间序列来说,假定未来行为与此刻的行为有关,利用属性此刻的值展望未来的值是可行的。
比如,要展望下周某种商品的销售额,能够用近来一段时间的实质销售量来成立展望模型。
2)、随机时间序列展望方法 :经过成立随机模型,对随机时间序列进行剖析,能够展望未来值。
若时间序列是安稳的,能够用自回归(Auto Regressive,简称AR) 模型、挪动回归模型(Moving Average,简称MA) 或自回归挪动均匀(Auto Regressive Moving Average,简称 ARMA) 模型进行剖析展望。
3)、其余方法 : 可用于时间序列展望的方法好多,此中比较成功的是神经网络。
因为大批的时间序列是非安稳的,所以特点参数和数据散布跟着时间的推移而变化。
若是经过对某段历史数据的训练,经过数学统计模型预计神经网络的各层权重参数初值,便可能成立神经网络展望模型,用于时间序列的展望。
3.数据发掘的分类方法有哪些,请详尽论述之分类方法归纳为四种种类:1)、鉴于距离的分类方法 : 距离的计算方法有多种,最常用的是经过计算每个类的中心来达成,在实质的计算中常常用距离来表征,距离越近,相像性越大,距离越远,相像性越小。
(不全)武大真题回忆版

1998一、选择1、世界上第一个地理信息系统产生于:A.中国B.美国C.加拿大D.澳大利亚2、判断点是否在多边形内常用:A.空间内插B.半线理论C.平板技术D.维数变化3、空间集合分析主要完成:A.地形分析B.缓冲区分析C.逻辑运算D.叠置分析4、以线性四*树表示8*8的栅格矩阵时,第6行第5列位置处的栅格的MORTON码值为:A.57B.39C.54D.365、建立空间要素之间的拓扑关系属于____功能A.空间分析B.图形分析C.空间查询D.地图整饰二、简述在栅格数据中提取多边形边界的一般方法三、地理信息系统中的数据输入包含几项内容?输入过程中可能产生的误差有几种?四、图画题给出一个四*树要求画出栅格矩阵,并用线性四*树和二维行程编码表示七、简答题1、地理坐标2、地图投影研究的主要内容3、地理信息系统中的地图投影配置应遵循的原则八、介绍两种商用GIS基础软件的主要特性和适应的场合九、某城市由于人口增长较快,原有的地下基础设施已经不能满足要求,为此须重新进行规划,目的是为了满足今后10—20年内城市人口发展的需要。
现用GIS辅助规划其要求是:1、能随时知道任意地方的地下管线的各类指标2、能随时了解那些管线需要重新建设3、能随时了解任意区域的人口指标4、管线应铺设在道路的两侧、单侧或中央。
5、管线铺设时应距离附近的建筑至少10米6、管线铺设和指标计算应结合地形进行7、输出规划成果,主要包括人口分布图和规划后的底下综合管线图现提供如下条件:1、规划区域的地形图及属性数据2、规划区域的道路图及属性数据3、规划区域的地下综合管线现状图及属性数据4、规划区域的人口分布规划图及属性数据5、规划区域的建筑分布分布图几属性数据6、已提供了由人口计算相应管线的负载的全套公式7、已提供了计算管线各种指标的公式8、所有的图件都已经入库根据以上的条件,设计用地理信息系统实现上述规划要求的方法,分别说明其中使用了哪些数据和GIS的那些主要功能。
2015年武汉大学翻译硕士MTI考研真题解析

2015年武汉大学翻译硕士MTI考研真题解析Shanghai Free Trade Area,bank balance,host university,current account,cash drain,National City Bank of New York,general consulatepay by installment,OPEC,埃博拉病毒,丝路基金,失联,微信,海外追逃,反垄断调查,权力寻租腐败,潜规则,苏格兰独立公投,亚太自贸区,食品安全,科研经费,依法治国,反恐情报中心,段落翻译E–C关于文学作品的作用和意义;C–E是于季羡林的,主要意思是说季羡林为人处事十分认真,然后举了一个例子说他如何认真负责,全文到处都是“季老”,还提到了萧乾。
总的来说,两篇都是文学翻译,特别是中翻英不好翻,很多词汇不知道怎么翻比较好,只能自己发挥,往年喜欢考的《秘密花园》《青鸟》都没有考,悲!1、考试准备的时间问题对于专业课的复习时间没有一个具体的指标,对于专业课基础较好的同学,专业课的复习时间可能会短些,而对于那些基础弱的同学,尤其是跨专业考试的同学,专业课的复习时间必然要长些,但是不管怎么样,每个学科必定是需要一段时间才能掌握透彻,但是在短时间内,经过高强度的复习和科学的指导,也可以取得很好的成绩。
一般而言,专业课复习最好能保留有3个月的复习时间。
2、考试资料的选择不同的学校,考试难度和风格不一样,所以考试的资料难以统一,但是有一些基本的教材,可以由浅入深地引导同学们了解和掌握经济学的基础知识。
这样,复习起来就会事倍功半,比较有效率。
由于目前国内研究生考试的难度水平大致还是处于中初级水平,因此基本上还是可以列出一个有效的资料清单:(1) 报考学校的指定书目(必备)(2) 历年的考试题目历年题是专业课的关键,而融会贯通则是关键中的关键。
考研的专业课考题大体有两种类型,一种是认知性质的考题,另一种是理解与应用型的,而且以后一种居多。
数据挖掘与知识发现技术考核试卷

4.在数据挖掘中,______是指数据集中的记录没有重复出现。()
5.在大数据分析中,______技术可以处理海量数据的存储和计算问题。()
6.常用于文本分析的______模型可以识别文本中的潜在主题分布。()
7.在数据挖掘中,______是一种无监督学习任务,旨在发现数据中的潜在模式。()
C.潜在狄利克雷分配
D.独立成分分析
17.以下哪些算法可以用于文本分类?()
A.朴素贝叶斯
B.支持向量机
C.决策树
D.聚类算法
18.以下哪些是数据挖掘中的隐私问题?()
A.数据泄露
B.数据隐私保护
C.数据匿名化
D.数据共享
19.以下哪些方法可以用于异常检测?()
A.箱线图
B.密度估计
C.机器学习模型
D.数据分析
8.以下哪个模型不是机器学习模型?()
A.线性回归模型
B.逻辑回归模型
C.决策树模型
D.数据流模型
9.在数据挖掘中,以下哪个概念表示数据之间的相互依赖关系?()
A.相关性
B.独立性
C.因果关系
D.非线性关系
10.以下哪个算法不是基于距离的聚类算法?()
A. K-均值
B.层次聚类
C.密度聚类
10. C
11. B
12. D
13. A
14. C
15. D
16. D
17. D
18. C
19. B
20. D
二、多选题
1. ABCD
2. ABC
3. AB
4. ABC
5. ABC
6. ABC
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
武汉大学计算机学院
2015级研究生“数据仓库和数据挖掘”课程期末考试试题
要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。
每张答题纸都要写上姓名和学号。
一、单项选择题(每小题2分,共20分)
1、下面关于数据仓库的叙述中(B )是错误的。
A.OLAP分为ROLAP、MOLAP和HOLAP
B.星型模式下的维表是规范化的,而雪花模式下的不需要规范化
C.在查询效率方面,星型模式效率更高
D.在事实星座模式中有多个事实表,且它们共享相同的维表
2、下面关于维的叙述中(C)是错误的。
A.维是人们观察数据的特定角度
B.维的层次性是由观察数据细致程度不同造成的
C.“某年某月某日”是时间维的层次错(“某年某月某日”是在时间维上位置的描述)
D.“月、季、年”是时间维的层次对(日、月、季、年是时间维的层次)
3、可以对按季度汇总的销售数据进行(B),来观察按月汇总的数据。
A.上卷
B.下钻
C.切片
D.切块
4、可以对按城市汇总的销售数据进行(A ),来观察按国家汇总的数据。
A.上卷
B.下钻
C.切片
D.切块
5、将原始数据进行集成和变换等处理是在以下(C)步骤的任务。
A.频繁模式挖掘
B.分类和预测
C.数据预处理
D.数据流挖掘
6、当不知道数据所带标签时,可以使用(B)技术促使带同类标签的数据与带其他标签的数据相分离。
A.分类
B.聚类
C.关联分析
D.隐马尔可夫链
7、建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的(C)任务。
A.根据内容检索
B.建模描述
C.预测建模
D.寻找模式和规则
8、利用信息增益方法作为属性选择度量建立决策树时,已知某训练样本集的4个条件属性的信息增益分别为:G(收入)=0.940位,G(职业)=0.151位,G(年龄)=0.780位,G(信誉)=0.048位,则应该选择(A )属性作为决策树的测试属性。
选信息增益最大的
A.收入
B.职业
C.年龄
D.信誉
9、以下关于前馈神经网络的叙述中正确的是(C)。
A.前馈神经网络只能有3层错
B.前馈神经网络中存在反馈错
C.前馈神经网络中每一层只接受来自前一层单元的输入
D.以上都是正确的
10、以下(A )不是影响聚类算法结果的主要因素。
A.已知类别的样本的质量
B.聚类结束条件
C.描述属性的选取
D.对象的相似性度量
二、(20分)假定某大学教务部门已经建立有教务管理系统,现在要创建一个数据仓库,至少包含以下分析功能:
(1)分析全校各个专业各个省份学生的基础课程成绩为优秀的人数情况。
(2)分析全校各个专业中年龄在16岁以下学生的人数情况。
(3)分析全校各个学院所有课程的不及格的人数情况。
完成如下任务:
(1)根据你的思考设计该数据仓库的模式图,包含每个维表和事实表的结构。
(15分)(2)指出你设计的数据仓库属于哪种模式。
(5分)
三、(20分)某个食品连锁店每周的事务记录如表1所示,每个事务表示在一项收款机业务中卖出的商品项集,假定min_sup=40%,min_conf=40%,使用Apriori算法生成的强关联规则。
见ppt 5章-例5.1(apriori算法)
表1 一个事务记录表
解:(1)由I={面包、果冻、花生酱、牛奶、啤酒}的所有项目直接产生1-候选C1,计
(2)组合连接L1中的各项目,产生2-候选集C2,计算其支持度,取出支持度小于supmin
至此,所有频繁集都被找到,算法结束,
所以,confidence({面包}→{花生酱})=(4/5)/(3/5)=4/3> confmin
confidence({ 花生酱}→{面包})=(3/5)/(4/5)=3/4> confmin 所以,关联规则{面包}→{花生酱}、{ 花生酱}→{面包}均是强关联规则。
四、(20分)对于如表2所示的决策表(U,C∪D),C={a,b,c,d},D={ e },回答以下问题:
(1)求POS C(D),判断该决策表是否是协调的。
(10分)
(2)采用分辨矩阵求其所有相对属性约简和核。
(10分)
表2 一个决策表
解:(1)C={a,b,c,d},D={e},
U/C={{1},{2},{3},{4},{5},{6},{7},{8}}(按C属性集划分的等价类)
U/D={{1,4,5},{2,3},{6,7,8}}(按D属性集划分的等价类)
{1,4,5}集合关于U/C的下近似为{1,4,5}
{2,3}集合关于U/C的下近似为{2,3}
{6,7,8}集合关于U/C的下近似为{6,7,8}
所以有POS C(D)={1,4,5}∪{2,3}∪{6,7,8}={1,2,3,4,5,6,7,8}=U,则该决策表是协调的。
分辨矩阵中元素d ij的计算过程是:若第i行与第j行的D值相同,则d ij=φ(空),否则d ij=第i行与第j行不同条件属性值的属性集。
如第1行与第3行的D值不同,C中不同值的条件属性为b、d,所以d13=bd。
由于分辨矩阵是对称的,所以只需求上或下三角部分。
f(D)=(b∨c∨d)∧(b∨d)∧(a∨b∨c)∧(a∨b∨c)∧(a∨b∨c∨d)∧…(分辨矩阵中所有非空项的与)=b∧(a∨d)=(a∧b)∨(b∧d),两个属性约简为{a,b}、{b,d}。
核={a,b}∩{b,d}={b}。
五、(20分)回答以下问题:
(1)按照算法的主要思路,聚类算法分为哪几种常见的类型?BIRCH和DBSCAN算法分别属于什么类型?(10分)
按照聚类分析方法的主要思路,可以被归纳为如下几种:
划分法:基于一定标准构建数据的划分。
层次法:对给定数据对象集合进行层次的分解。
密度法:基于数据对象的相连密度评价。
网格法:将数据空间划分成为有限个单元的网格结构,基于网格结构进行聚类。
模型法:给每一个簇假定一个模型,然后去寻找能够很好的满足这个模型的数据集。
基于层次聚类算法:BIRCH; 基于密度聚类算法:DBSCAN;
(2)简要说明决策树分类算法中常用的选择测试属性和停止划分样本的方式,以及神经网络算法中常用的迭代终止条件。
(10分)
如何选择测试属性?测试属性的选择顺序影响决策树的结构甚至决策树的准确率。
ID3算法主要是给出了通过信息增益的方式来选择测试属性。
C4.5用信息增益率来选择属性,提高了衡量属性划分数据的广度和均匀性。
如何停止划分样本?从根结点测试属性开始,每个内部结点测试属性都把样本空间划分为若干个(子)区域,一般当某个(子)区域的样本同类时,就停止划分样本,有时也通过阈值提前停止划分样本。
迭代结束条件:当某次扫描训练集迭代结束时,所有ΔWij 都小于某个指定阈值,或未正确分类的样本百分比小于某个指定阈值,或进行的迭代次数超过预先指定的迭代次数时,训练终止。