航空公司客户价值分析Kmeans
航空公司客户价值分析-航空公司客户价值分析实战

航空公司客户价值分析作者:柳睿来源:《财讯》2018年第09期航空市场竞争的加煎和航空业的发展,要求国内航空公司必须利用大量数据中隐含的知识才能抓住时机。
如此,客户是企业至关重要的成功因素和利润来源。
将数据挖掘、机器学习技术应用于客户关系管理,能够为企业提供经营和决策的量化依据,使企业能够把握重点,分轻重急缓,有效利用有限资源,拓展利润上升空间。
针对客户关系管理中客户价值这一问题,通过对航空公司现有数据仓库中客户信息的分析,本文采用RFM模型得到必要指标变量,再运用Kmeans算法对RFM所褥出的指标进行聚类,将客户群逊分为价值不同的五类客户群,并对每个客户群进行分析和总结,提出了针对每类客户群的营销策略。
RMF模型客户价值分析 Kmeans背景介绍航空公司同样也面临这样的何如划分客户群的问题,而客户细分就是能够解决这种问题的关键。
国内某航空公司市场面临旅客流失、资源为充分利用等经营危机。
因此本文的日标足利用某航空公司的会员档案信息和其航班乘坐记录,通过建市合理的客户价值评估模型,对客户进行分群,分析比较不同客户群的客户价值,并制定相应的个性化营销策略。
本文运用RFM 模型对客户分类。
数据描述与预处理(1)数据统计分析原始数据含有44个变量属性,我们对原始数据有个初步的描述理解。
由数据可知男性在观测窗几内飞行次数远超与女性。
会员级别为4的客户飞行次数最多,其次足会员级别为5的客户,会员级别为6的客户飞行次数最少,可以知道级别越高(4级最高,6级最低)飞行次数越多,可能是由于级别越高,得到的折扣率相对较高。
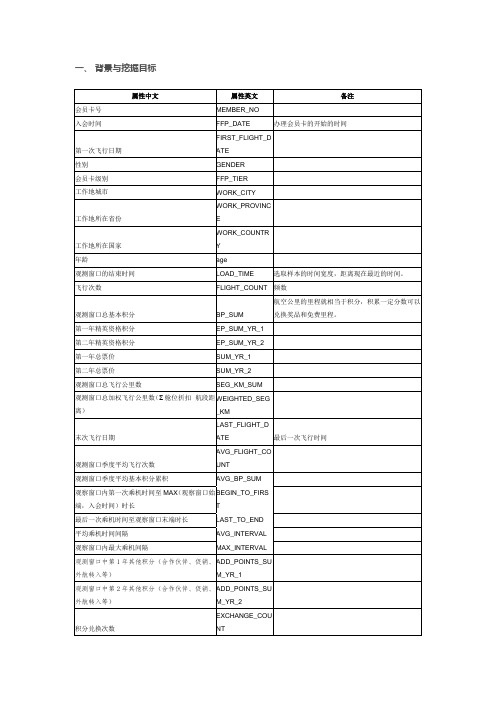
(2)数据预处理在本案例中,以2014年3月31日为结束时间,选取宽度为两年的时间段作为分析观测窗口(也就是时间间隔为2012年4月1H至2014年3月31日),抽取观测窗几以内有乘机记录的所有客户的详细数据形成历史数据,并将数据分为三个维度,分别是客户基本信息、乘机信息和积分信息,总共包含会员卡号、入会时间、年龄、工作地所在省份、观测窗口的结束时间、乘机积分、飞行公里数等44个变量属性。
Python数据分析与应用-第章-航空公司客户价值分析

航空公司客户数据说明
续表
思考
原始数据中包含40多个特征,利用这些特征做些什么呢?我们又该 从哪些角度出发呢?
项目目标
结合目前航空公司的数据情况,可以实现以下目标。 Ø Ø Ø 借助航空公司客户数据,对客户进行分类。 对不同的客户类别进行特征分析,比较不同类别客户的客户价值。 对不同价值的客户类别提供个性化服务,制定相应的营销策略。
航空公司客户价值分析
2019/1/23
目录
1
了解航空公司现状与客户价值分析 预处理航空客户数据 使用K-Means算法进行客户分群 小结
2
3
4
分析航空公司现状
1. 行业内竞争
民航的竞争除了三大航空公司之间的竞争之外,还将加入新崛起的各类小型航空公司、民营航空公司, 甚至国外航空巨头。航空产品生产过剩,产品同质化特征愈加明显,于是航空公司从价格、服务间的竞争逐 渐转向对客户的竞争。
新增信息抽取
目录
1
了解航空公司现状与客户价值分析 预处理航空客户数据 使用K-Means算法进行客户分群 小结
2
3
4
处理数据缺失值与异常值
航空公司客户原始数据存在少量的缺失值和异常值,需要清洗后才能用于分析。 通过对数据观察发现原始数据中存在票价为空值,票价最小值为0,折扣率最小值为0,总飞行公里数大于 0的记录。票价为空值的数据可能是客户不存在乘机记录造成。 处理方法:丢弃票价为空的记录。 其他的数据可能是客户乘坐0折机票或者积分兑换造成。由于原始数据量大,这类数据所占比例较小,对 于问题影响不大,因此对其进行丢弃处理。 处理方法:丢弃票价为0,平均折扣率不为0,总飞行公里数大于0的记录。
python数据分析与挖掘实战---航空公司客户价值分析

python数据分析与挖掘实战---航空公司客户价值分析航空公司客户价值分析⼀、背景与挖掘⽬标客户关系管理是企业的核⼼问题,关键在于客户的分类:区别⽆价值客户,⾼价值客户,针对不同客户群体有的放⽮投放具体服务⽅案,实现企业利润最⼤化的⽬标。
各⼤航空公司采取优惠措施喜迎更多客户,国内航司⾯对客户流失和资源未完全利⽤等危机,因此建⽴⼀个客户价值评估模型来实现对客户的分类。
⼆、分析⽅法与过程本次的分析⽬的在于客户价值识别,客户价值识别最常⽤的模型是RFM模型:R(最近消费时间间隔)F(消费频率)M(消费⾦额)。
飞机票价取决于飞⾏距离和仓位等级,消费同等⾦额票价的旅客对航司的价值不⼀定相同:购买短程头等舱的旅客和购买长途经济舱的旅客,明显前者对航司的贡献更⼤。
所以对M(消费⾦额)建模时要进⾏修改:⽤⾥程数平均值M和仓位折扣系数平均值C来代替消费的⾦额。
同时,考虑旅客中,加⼊会员的时间越长,客户的潜在价值⼀般越⾼,所以定义⼀个客户关系长度L,作为区分客户的另⼀指标。
接下来针对LRFMC模型,对客户进⾏区分。
LRFMC模型:(1)客户关系长度L:航空公司会员时间的长短。
(2)是消费时间间隔R。
(3)消费频率F。
(4) 飞⾏⾥程M。
(5) 折扣系数的平均值C。
LRFMC模型指标含义:(1) L:会员⼊会时间距观测窗⼝结束的⽉数。
(2) R:客户最近⼀次乘坐公司飞机距离观测窗⼝结束的⽉数。
(3) F:客户在观测窗⼝内乘坐公司飞机的次数。
(4) M:客户在观测窗⼝内累计的飞⾏⾥程碑。
(5) C:客户在观测窗⼝内乘坐仓位所对应的折扣系数的平均值。
⽅法:本案例采⽤聚类的⽅法,通过对航空公司客户价值的LRFMC模型的五个指标进⾏K-Means聚类,识别客户价值。
三、数据描述给出所有属性的基本信息,共25个属性,均⽆⼤量缺失现象或缺失现象很少。
四、建模1、数据探索分析对数据进⾏缺失值分析与异常值分析,分析出数据的规律以及异常值查找每列属性观测值个数,最⼤值,最⼩值。
利用KMeans聚类进行航空公司客户价值分析

利⽤KMeans聚类进⾏航空公司客户价值分析准确的客户分类的结果是企业优化营销资源的重要依据,本⽂利⽤了航空公司的部分数据,利⽤Kmeans聚类⽅法,对航空公司的客户进⾏了分类,来识别出不同的客户群体,从来发现有⽤的客户,从⽽对不同价值的客户类别提供个性化服务,指定相应的营销策略。
⼀、分析⽅法和过程1.数据抽取——>2.数据探索与预处理——>3。
建模与应⽤传统的识别客户价值应⽤最⼴泛的模型主要通过3个指标(最近消费时间间隔(Recency)、消费频率(Frequency)和消费⾦额(Monetary))来进⾏客户细分,识别出价值⾼的客户,简称RFC模型。
点击查看在RFC模型中,消费⾦额表⽰在⼀段时间内,客户购买产品的总⾦额。
但是不适⽤于航空公司的数据处理。
因此我们⽤客户在⼀段时间内的累计飞⾏⾥程M和客户在⼀定时间内乘坐舱位的折扣系数C代表消费⾦额。
再在模型中增加客户关系长度L,所以我们⽤LRFMC模型。
因此本次数据挖掘的主要步骤:1).从航空公司的数据源中进⾏选择性抽取与新增数据抽取分别形成历史数据和增量数据2).对步骤1)中形成的两个数据集进⾏数据探索分析和预处理,包括数据缺失值和异常值分析。
即数据属性的规约、清洗和变换3).利⽤步骤2)中的处理的数据进⾏建模,利⽤Python下Sklearn库中提供的KMeans⽅法,进⾏聚类4)。
针对模型的结果进⾏分析。
⼆。
数据处理1.下⾯是本次试验数据集的⼀部分截图,数据集抽取2012-4-1到2014-3-31内乘客的数据,⼀个62988条数据。
包括了会员卡号、⼊会时间、性别、年龄等44个属性。
2.数据探索分析:主要是对数据进⾏缺失值分析与异常值的分析。
通过发现原始数据中存在票价为空值,票价最⼩值为0,折扣率最⼩值为0、总飞⾏公⾥数⼤于0的记录。
其Python代码如下:def explore(datafile,exploreoutfile):"""进⾏数据的探索@Dylan:param data: 原始数据⽬录:return: 探索后的结果"""data=pd.read_csv(datafile,encoding='utf-8')explore=data.describe(percentiles=[],include='all').T####包含了对数据的基本描述,percentiles参数是指定计算多少分位数explore['null']=len(data)-explore['count'] ##⼿动计算空值数explore=explore[['null','max','min']]####选取其中的重要列explore.columns=['空值数','最⼤值','最⼩值']"""describe()函数⾃动计算的字段包括:count、unique、top、max、min、std、mean。
基于数据挖掘的航空公司客户价值分析

基于数据挖掘的航空公司客户价值分析第一章:绪论随着互联网时代的到来,航空公司已经成为了交通运输的主要方式。
然而,随着市场竞争加剧,如何提高客户留存率并提高收益成为了航空公司面临的重要问题。
此时,数据挖掘技术的应用则成为了解决这一问题的有力工具。
本文基于数据挖掘技术对航空公司客户价值进行分析,旨在为航空公司提供客户保留和收益提高的参考依据。
第二章:相关理论2.1 数据挖掘数据挖掘是一种自动化地探索海量数据,以找到其中隐藏的知识或规律的技术。
它是一种将大量数据集为基础的、自动化的山寨思考和提取模式的过程,是从大规模的天外数据集中提取先于知识或者信息,可以用这些信息来开发事物和创新构思。
2.2 客户价值客户价值是指企业通过对客户需求的了解,能够为客户提供的满足需求的产品和服务所创造的价值。
客户价值可分为现金价值和未来价值,其中现金价值是指客户在一定时间内购买产品或服务所带来的现金收益,未来价值则是指客户对企业的长期价值,如忠诚度。
第三章:相关方法3.1 K-Means聚类算法K-Means聚类算法是一种最常用的无监督学习算法,将簇内数据的方差和最小化是该算法的主要目标。
该算法以簇中心为依据,将数据逐个进行分类,使得彼此属于同一个类簇的数据离其所处的中心点最近。
3.2 决策树算法决策树算法是一种基于树形结构的算法,该算法通过树形结构,进行自上而下的逐一判断选择,最终将数据集分为驱动选择的不同类型。
该算法常用于分类和预测模型,比如说在金融领域,可以用该算法预测客户是否具有逾期风险。
第四章:案例分析本文以某航空公司的客户数据为分析基础,首先对客户进行分类,其次将数据进行分析,从而确定客户的价值,并建立相应的模型,以提高客户的保留率和收益。
4.1 客户分类通过对某航空公司的客户数据进行分析,选用K-means聚类算法对客户进行分类,根据聚类结果将客户分为三类:- 高价值客户:在过去一年中花费最高,是航空公司最重要的客户。
《R语言数据分析》课程教案—03航空公司客户价值分析

第3章航空公司客户价值分析教案一、材料清单(1)《R语言商务数据分析实战》教材。
(2)配套PPT。
(3)引导性提问。
(4)探究性问题。
(5)拓展性问题。
二、教学目标与基本要求1.教学目标结合航空公司客户价值分析的案例,重点介绍数据分析算法中K-Means聚类算法在客户价值分析中的应用。
针对RFM客户价值分析模型的不足,使用K-Means算法构建航空客户价值分析LRFMC模型,详细描述数据分析的整个过程。
2.基本要求(1)熟悉航空公司客户价值分析的步骤与流程。
(2)了解RFM模型的基本原理,以及K-Means算法的基本原理。
(3)构建航空客户价值分析的关键特征。
(4)比较不同类别客户的客户价值,制定相应的营销策略。
三、问题1.引导性提问引导性提问需要教师根据教材内容和学生实际水平,提出问题,启发引导学生去解决问题,提问,从而达到理解、掌握知识,发展各种能力和提高思想觉悟的目的。
(1)客户价值分析是什么?(2)影响航空公司客户价值的相关因素有哪些?(3)航空公司客户价值分析的意义在哪里?2.探究性问题探究性问题需要教师深入钻研教材的基础上精心设计,提问的角度或者在引导性提问的基础上,从重点、难点问题切入,进行插入式提问。
或者是对引导式提问中尚未涉及但在课文中又是重要的问题加以设问。
(1)客户价值分析的使用场景有哪些?(2)航空客户价值分析的步骤与流程有哪些?(3)为何要构建关键特征?3.拓展性问题拓展性问题需要教师深刻理解教材的意义,学生的学习动态后,根据学生学习层次,提出切实可行的关乎实际的可操作问题。
亦可以提供拓展资料供学生研习探讨,完成拓展性问题。
(1)除了K-Means算法,能否使用其他算法进行客户价值分析?(2)构建K-Means模型时,为何要选取3为聚类数?四、主要知识点、重点与难点1.主要知识点(1)了解航空公司现状与客户价值分析。
(2)熟悉航空公司客户价值分析的步骤与流程。
(3)处理数据的缺失值与异常值。
Python数据分析与应用_第7章_航空公司客户价值分析报告

特征名称 最小值 最大值
L 12.17 114.57
R 0.03 24.37
F
M
C
2
368
0.14
213
580717
1.5
大数据挖掘专家
17
标准化LRFMC五个特征
L、R、F、M和C五个特征的数据示例,上图为原始数据,下图为标准差标准化处理后的数据。
LOAD_TIME
FFP_DATE
LAST_ TO_END
1.34
大数据挖掘专家
18
目录
1
了解航空公司现状与客户价值分析
2
预处理航空客户数据
3
使用K-Means算法进行客户分群
4
小结
大数据挖掘专家
19
了解K-Means聚类算法
1. 基本概念
K-Means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足 误差平方和最小标准的k个聚类。算法步骤如下。 ➢ 从n个样本数据中随机选取k个对象作为初始的聚类中心。 ➢ 分别计算每个样本到各个聚类质心的距离,将样本分配到距离最近的那个聚类中心类别中。 ➢ 所有样本分配完成后,重新计算k个聚类的中心。 ➢ 与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转(2),否则转(5)。 ➢ 当质心不发生变化时停止并输出聚类结果。
最大乘机间隔 积分兑换次数 总精英积分
促销积分 合作伙伴积分 总累计积分 非乘机的积分变动次数 总基本积分
6
思考
原始数据中包含40多个特征,利用这些特征做些什么呢?我们又该 从哪些角度出发呢?
大数据挖掘专家
7
项目目标
结合目前航空公司的数据情况,可以实现以下目标。
航空公司客户价值分析
RFM模型是衡量客户价值和客户创利能力的重要工具和手段,它通过一个客户的近期购买行为、购买的总体频次以及购买的总体金额三个指标来描述客户的价值状况。
分别为:最近消费时间间隔(Recently)、消费频率(Frequency)、消费金额(Money)。
在RFM模型的基础上,结合具体的业务背景,来对航空公司进行客户价值分析。
我们选择在一定时间内累积的飞行里程数(M)和客户在一定时间内乘坐舱位对应的折扣系数的平均值C来代替消费金额指标。
此外,航空公司会员入会时间的长短在一定时间内会影响客户价值,模型中增加了客户关系长度指标L。
利用客户入会时长L、消费时间间隔R、消费频率F、飞行里程数M以及折扣系数的平均值C来作为航空公司识别客户价值指标,见表1,记为LRFMC模型。
采用聚类分析的方法识别客户价值。
通过对航空公司客户价值LRFMC五个指标进行K-Means聚类,识别最有价值客户。
1、数据抽取以2014年3月31日为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据。
对于后续新增的客户详细信息,以后续新增数据中最新的时间点作为结束时间,采用上述同样的方法进行抽取,形成增量数据。
2、数据探索分析主要是进行缺失值分析和异常值分析,通过对数据的观察,发现原始数据中存在票价为空值,票价最小值为0、折扣率最小值为0、总飞行公里数大于0的记录,这个都是属于缺失值和异常值的范畴。
# 设置工作空间# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间setwd("F:/数据及程序/chapter7/示例程序")# 数据读取datafile <- read.csv('./data/air_data.csv', header = TRUE)# 确定要探索分析的变量col <- c(15:18, 20:29) # 去掉日期型变量# 输出变量最值、缺失情况summary(datafile[, col])#探索缺失数据的模式md.pattern(datafile[,col])#以图形方式描述缺失数据aggr(datafile[,col],number=T)3、数据预处理由于原始数据量比较大,上述被定义为缺失值和异常值的样本量很小,对问题的分学习影响不大,因此选择的是剔除缺失值和异常值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3.3 数据变换
由于原始数据没有直接给出LRFMC五个指标,需要自己计算,具体的计算方式为:
(1)L=LOAD_TIME-FFP_DATE
(2)R=LAST_TO_END
(3)F=FLIGHT_COUNT
(4) M=SEG_KM_SUM
(5)C=avg_discount
数据变换的Python代码如下:
1.def reduction_data(datafile,reoutfile):
2.
data=pd.read_excel(cleanoutfile,encoding='utf-8')
3.
data=data[['LOAD_TIME','FFP_DATE','LAST_TO_END','FLIGH T_COUNT','SEG_KM_SUM','avg_discount']]
4.#
data['L']=pd.datetime(data['LOAD_TIME'])-pd.datetime(d ata['FFP_DATE'])
5.#
data['L']=int(((parse(data['LOAD_TIME'])-parse(data['F FP_ADTE'])).days)/30)
6.####这四行代码费了我3个小时
7. d_ffp=pd.to_datetime(data['FFP_DATE'])
8. d_load=pd.to_datetime(data['LOAD_TIME'])
9. res=d_load-d_ffp
10. data['L']=res.map(lambda
x:x/np.timedelta64(30*24*60,'m'))
11. data['R']=data['LAST_TO_END']
12. data['F']=data['FLIGHT_COUNT']
13. data['M']=data['SEG_KM_SUM']
14. data['C']=data['avg_discount']
15. data=data[['L','R','F','M','C']]
16. data.to_excel(reoutfile)
变换结果如下:
4.1客户聚类
采用kMeans聚类算法对客户数据进行客户分组,聚成5组,Python代码如下:
1.import pandas as pd
2.from sklearn.cluster import KMeans
3.import matplotlib.pyplot as plt
4.from itertools import cycle
5.datafile='./tmp/zscore.xls'
6.k=5
7.classoutfile='./tmp/class.xls'
8.resoutfile='./tmp/result.xls'
9.data=pd.read_excel(datafile)
10.kmodel=KMeans(n_clusters=k,max_iter=1000)
11.kmodel.fit(data)
12.# print(kmodel.cluster_centers_)
13.r1=pd.Series(bels_).value_counts()
14.r2=pd.DataFrame(kmodel.cluster_centers_)
15.r=pd.concat([r2,r1],axis=1)
16.r.columns=list(data.columns)+['类别数目']
17.# print(r)
18.# r.to_excel(classoutfile,index=False)
19.r=pd.concat([data,pd.Series(bels_,index=da
ta.index)],axis=1)
20.r.columns=list(data.columns)+['聚类类别']
21.# r.to_excel(resoutfile,index=False)
对数据进行聚类分群的结果如下表所示:。