天津理工大学数据库(李玉坤)实验四
天津理工大学数据结构实验报告4

附录(可包括源程序清单或其它说明)#include <stdio.h>#include <string>#define MAX_NAME 10#define MAX_INFO 80typedef char InfoType;typedef char V ertexType[MAX_NAME]; // 字符串类型#define MAX_VERTEX_NUM 20typedef enum{unvisited,visited}VisitIf;typedef struct EBox{VisitIf mark; // 访问标记int ivex,jvex; // 该边依附的两个顶点的位置struct EBox *ilink,*jlink; // 分别指向依附这两个顶点的下一条边InfoType *info; // 该边信息指针}EBox;typedef struct{V ertexType data;EBox *firstedge; // 指向第一条依附该顶点的边}V exBox;typedef struct{V exBox adjmulist[MAX_VERTEX_NUM];int vexnum,edgenum; // 无向图的当前顶点数和边数}AMLGraph;typedef int QElemType;typedef struct QNode{// 单链表的链式存储结构QElemType data; //数据域struct QNode *next; //指针域}QNode,*QueuePtr;typedef struct{QueuePtr front,//队头指针,指针域指向队头元素rear; //队尾指针,指向队尾元素}LinkQueue;// 若G中存在顶点u,则返回该顶点在无向图中位置;否则返回-1int LocateV ex(AMLGraph G,V ertexType u){int i;for(i=0;i<G.vexnum;++i)if(strcmp(u,G.adjmulist[i].data)==0)return i;return -1;}int CreateGraph(AMLGraph *G){ // 采用邻接表存储结构,构造无向图G int i,j,k,l,IncInfo;char s[MAX_INFO];V ertexType va,vb;EBox *p;printf("请输入无向图G的顶点数,边数: ");scanf("%d,%d",&(*G).vexnum,&(*G).edgenum);printf("请输入%d个顶点的值(<%d个字符):\n",(*G).vexnum,MAX_NAME);for(i=0;i<(*G).vexnum;++i){ // 构造顶点向量scanf("%s",(*G).adjmulist[i].data);(*G).adjmulist[i].firstedge=NULL;}printf("请顺序输入每条边的两个端点(以空格作为间隔):\n");for(k=0;k<(*G).edgenum;++k){// 构造表结点链表scanf("%s%s%*c",va,vb); // %*c吃掉回车符i=LocateV ex(*G,va); // 一端j=LocateV ex(*G,vb); // 另一端p=(EBox*)malloc(sizeof(EBox));p->mark=unvisited; // 设初值p->ivex=i;p->jvex=j;p->info=NULL;p->ilink=(*G).adjmulist[i].firstedge; // 插在表头(*G).adjmulist[i].firstedge=p;p->jlink=(*G).adjmulist[j].firstedge; // 插在表头(*G).adjmulist[j].firstedge=p;}return 1;}V ertexType* GetVex(AMLGraph G,int v){ // 返回v的值if(v>=G.vexnum||v<0)exit(0);return &G.adjmulist[v].data;}// 返回v的第一个邻接顶点的序号。
天津理工大学计算机专业数据库实验二

实验报告学院(系)名称:计算机与通信工程学院姓名范学号2009 专业计算机科学与技术班级中加4班实验项目数据库控制与编程课程名称数据库系统概论课程代码实验时间2011年11月29日实验地点主校区7—219批改意见成绩教师签字:一.实验目的以一种开发环境为例,使学生初步掌握通过编程的方式对数据库进行操作,为进行数据库课程设计做准备。
二.实验工具软硬件环境编写访问数据库的应用程序来对数据库进行各种数据操作,编程工具由导师指定,学生可以使用指导老师指定的工具,也可自己选择编程工具。
软件环境:Windows 2000MS SQL Server硬件环境:P4 2.4GHz 256内存三.实验内容和要求所有的SQL操作均在自己建立的TEMP数据库里进行,根据以下要求认真填写实验报告,并且提交源程序,保证可正确编译运行。
使用SQL对数据进行完整性控制,用实验验证:当操作违反了完整性约束条件的时候,系统是如何处理的。
熟悉存储过程的建立及使用,熟悉带输入参数和输出参数的存储过程。
I.使用SQL对数据进行完整性控制,用实验验证:当操作违反了完整性约束条件的时候,系统是如何处理的。
II.熟悉存储过程的建立及使用,熟悉带输入参数和输出参数的存储过程。
a)查询学生表中的所有学生,并实现调用。
b)修改学号为@sno学生的姓名,性别,年龄,系别,并实现调用。
c)向学生表中插入学生,并实现调用。
d)查询姓名为@sname选修的数据库课程的成绩,并实现调用。
e)查询选修了课程名为@cname并且成绩高于该门课程平均分的学生学号和成绩,并实现调用。
III.利用指定的编程语言完成一个简单程序,要求具有对数据的增加、修改和删除操作;基于一个给定的java应用程序,熟悉掌握建立ODBC和利用ODBC来凝结数据库的编程方法,建立一个应用程序,具有向学生、课程、选课表增加修改删除记录的功能,选取其中一个功能用存储过程实现。
需要接取程序运行界面。
《数据库原理》实验4

实验四:数据库综合查询一、实验目的1.掌握SELECT语句的基本语法和查询条件表示方法;2.掌握查询条件种类和表示方法;3.掌握连接查询的表示及使用;4.掌握嵌套查询的表示及使用;5.了解集合查询的表示及使用。
二、实验环境已安装SQL Server 2008 企业版的计算机;具有局域网环境,有固定IP;三、实验学时2学时四、实验要求1.了解SELECT语句的基本语法格式和执行方法;2.了解连接查询的表示及使用;3.了解嵌套查询的表示及使用;4.了解集合查询的表示及使用;5.完成实验报告;五、实验内容及步骤以数据库原理实验2数据为基础,请使用T-SQL 语句实现进行以下操作:1.查询以‘DB_’开头,且倒数第3个字符为‘s’的课程的详细情况;2.查询名字中第2个字为‘阳’的学生姓名和学号及选修的课程号、课程名;3.列出选修了‘数学’或者‘大学英语’的学生学号、姓名、所在院系、选修课程号及成绩;4.查询缺少成绩的所有学生的详细情况;5.查询与‘张力’(假设姓名唯一)年龄不同的所有学生的信息;6.查询所选课程的平均成绩大于张力的平均成绩的学生学号、姓名及平均成绩;7.按照“学号,姓名,所在院系,已修学分”的顺序列出学生学分的获得情况。
其中已修学分为考试已经及格的课程学分之和;8.列出只选修一门课程的学生的学号、姓名、院系及成绩;9.查找选修了至少一门和张力选修课程一样的学生的学号、姓名及课程号;10.只选修“数据库”和“数据结构”两门课程的学生的基本信息;11.至少选修“数据库”或“数据结构”课程的学生的基本信息;12.列出所有课程被选修的详细情况,包括课程号、课程名、学号、姓名及成绩;13.查询只被一名学生选修的课程的课程号、课程名;14.检索所学课程包含学生‘张向东’所学课程的学生学号、姓名;15.使用嵌套查询列出选修了“数据结构”课程的学生学号和姓名;16.使用嵌套查询查询其它系中年龄小于CS系的某个学生的学生姓名、年龄和院系;17.使用ANY、ALL 查询,列出其他院系中比CS系所有学生年龄小的学生;18.分别使用连接查询和嵌套查询,列出与‘张力’在一个院系的学生的信息;19.使用集合查询列出CS系的学生以及性别为女的学生名单;20.使用集合查询列出CS系的学生与年龄不大于19岁的学生的交集、差集;21.使用集合查询列出选修课程1的学生集合与选修课程2的学生集合的交集;22.思考题:按照课程名顺序显示各个学生选修的课程(如200515001 数据库数据结构数学);六、出现问题及解决办法如:某些查询操作无法执行,如何解决?1、查询以‘DB_’开头,且倒数第三个字符为‘s’的课程的详细情况select * from coursewhere cname like 'DB\_%s__'2、查询名字中第二个字为“阳”的学生姓名和学号及选修的课程号、课程名select student.sno ,student.sname ,o,cname from student,course,scwhere sname like '_阳%'and student.sno=sc.sno and o=o 3、列出选修了‘数学’或‘大学英语’的学生学号、姓名、select student.sno,sname,sdept,o,cname,grade from student,sc,coursewhere student.sno=sc.sno and o=o andsc.sno in(select sc.sno from sc,course where (cname='大学英语'or cname='数学')and o=o group by sc.sno)select student.sno,sname,sdept,cno,grade from student,scwhere Cno in (select Cno from coursewhere cname='数学'or cname='大学英语')and sc.sno=student.sno4、查询缺少成绩的所有学生的详细情况; select *from student,scwhere Grade is null and student.sno=sc.sno5、查询与‘张力’(假设姓名唯一)年龄不同的所有学生的信息; select * from student where sage <>(select sage from student where sname='张力')6、查询所选课程的平均成绩大于张力的平均成绩的学生学号、姓名及平均成绩select student.sno,sname,平均成绩=AVG(grade) from student ,scwhere student.sno=sc.sno group by student.sno,snamehaving AVG(Grade)>(select AVG(Grade)from sc,student where sname='张力'and student.sno=sc.sno)7、按照‚学号,姓名,所在院系,已修学分‛的顺序列出学生学分的获得情况。
天津理工大学数据结构实验报告3

实验(三)实验名称二叉树的遍历软件环境 Windows98/2000, VC++6.0或turbo C硬件环境PⅡ以上微型计算机实验目的 理解二叉树的逻辑特点,掌握二叉链表存储结构,掌握二茬树遍历算法的递归与非递归实现实验内容(应包括实验题目、实验要求、实验任务等)二叉树的遍历利用二叉链表作为存储结构建立一棵二叉树,每个结点中存放一种水果名(例如apple、orange、banana等,并要求从键盘输入),结点数不少于5个。
要求分别以先序、中序和后序进行遍历,输出遍历结果。
并编写一递归算法,交换该二叉树中所有结点的左、右孩子。
实验过程与实验结果(可包括实验实施的步骤、算法描述、流程、结论等)实验步骤及算法描述和流程:1. 创建二叉链表的结点存储结构及数据的输入输出函数因为每个结点所存储的数据类型为字符串,却无法使用字符串和String等数据类型,所以使用单链表作为结点所存储的数据类型。
1.1 数据的输入函数indata( )当输入的字符不为'0'时,以尾插法将数据插入单链表。
1.2 数据的输出函数直接输出单链表。
2. 生成二叉链表利用先序遍历生成二叉链表:2.1 用单链表s记录输入的数据2.2 若单链表s为空,则二叉链表结点为空,否则根节点=s,利用递归调用分别生成根节点的左子树和右子树2.3 返回二叉链表3. 先序遍历、中序遍历、后序遍历二叉链表3.1 先序遍历:访问根节点,左子树,右子树的顺序3.2 中序遍历:访问左子树,根节点,右子树的顺序3.3 后序遍历:访问左子树,右子树,根节点的顺序利用递归调用分别用以上三种顺序遍历二叉链表。
4. 交换二叉链表的左右孩子当二叉链表的结点左孩子或者右孩子都不为空时,利用递归调用,分别交换左子树很右孩子的左右孩子,最后将根节点的左右孩子指针交换。
5. 主函数5.1 调用生成二叉链表的函数,从键盘输入二叉链表的各个结点5.2 分别调用先序遍历、中序遍历、后序遍历二叉链表函数,输出所有结点5.3 交换二叉链表的左右孩子5.4 重复5.2结论: 输入各个结点:apple、pear、orange、banana、peach、grape、watermelon 先序遍历输入与输入一致 中序遍历输出:orange、pear、banana、apple、grape、peach、watermelon 后序遍历输出:orange、banana、pear、grape、watermelon、peach、apple 交换二叉树的左右孩子后 先序遍历输出:apple、peach、watermelon、grape、pear、banana、orange编程中出现的问题:输入的二叉链表左右子树必须对称,如果不对称,交换二叉树的左右子树后,程序出错,不知道出错在哪,没有调试成功。
面向论文检索的同名作者区分方法

Lee et al.[1]认为主要挑战来自于数据输入的错误,
包括检索词格式输入的错误以及输入标准的缺失, 作 者 的 同 名 问 题 以 及 出 版 地 点 缩 写 的 问 题 等 。在 这些问题中作者同名问题因其固有的难度,已经引
起数字图书馆研究者的极大关注。 在现实世界中会有这样的情形。当用户希望
中的同一个人,然而却被列为两个条目;2 ) 当选择
* 收 稿 日 期 =2016年 8 月 1 1 日,修 回 日 期 =2016年 9 月 2 5 日 基 金 项 目 :国家自然科学基金项目(编 号 : 61170027); 天津市应用基础与前沿技术研究计划(编 号 :15JCYBJC46500)
本 文 所 要 解 决 的 问 题 是 :对 于 一 个 论 文 集 ,当
N 用户输 入 作 者 名 称 时 ,将会返回所有作者中包 N 含 此 名 字 的文 章 ,本文所要解决的问题就是对
个 问 题 上 花 费 了 大 量 的 时 间 ,尝 试 了 多 种 方 法 。
Lizhu Zhou et al•提出了一种称为GHOST的解决 问题的框架[2]。 Tang Jie et al.使用了一种统一的
i 引言
随着互联网的发展,很多数字学术图书馆随之
产生,如 DBLP,CitSeer,PubMed, ACM DL, IEEE D L ,知 网 、万 方 等 。这 些 数 字 学 术 图 书 馆 为 文 献 检
数据库原理实验报告

数据库原理实验报告一、实验目的本次数据库原理实验旨在通过实际操作和实践,深入理解数据库的基本概念、原理和技术,掌握数据库设计、创建、管理和操作的方法,提高解决实际问题的能力和数据处理的技能。
二、实验环境本次实验使用的软件环境为 Microsoft SQL Server 2019,操作系统为 Windows 10。
硬件环境为一台具备 8GB 内存、Intel Core i5 处理器的计算机。
三、实验内容与步骤(一)数据库设计1、需求分析根据给定的业务场景,明确数据库需要存储的信息和数据之间的关系。
例如,对于一个学生管理系统,需要存储学生的基本信息、课程信息、成绩信息等,并且要确定这些信息之间的关联,如学生与课程的选课关系、课程与成绩的对应关系等。
2、概念设计使用 ER 图(EntityRelationship Diagram,实体关系图)对需求进行建模,清晰地表示出实体(如学生、课程)、属性(如学生的学号、姓名)和实体之间的关系(如选课关系)。
3、逻辑设计将 ER 图转换为关系模式,确定表的结构,包括表名、列名、数据类型、主键和外键等。
例如,学生表(学号,姓名,年龄,性别),课程表(课程号,课程名,学分),选课表(学号,课程号,成绩)。
(二)数据库创建1、启动 SQL Server 2019 数据库管理系统。
2、使用 CREATE DATABASE 语句创建数据库,指定数据库的名称、文件存储位置和初始大小等参数。
3、在创建的数据库中,使用 CREATE TABLE 语句创建各个表,按照逻辑设计的结果定义表的结构。
(三)数据插入1、使用 INSERT INTO 语句向表中插入数据,确保数据的完整性和准确性。
例如,向学生表中插入学生的信息:INSERT INTO Students (StudentID, Name, Age, Gender) VALUES (1, '张三', 20, '男')。
数据库实验四报告

《数据库原理与应用》实验报告实验名称:班级:学号:姓名:一、实验目的(1)了解Oracle数据库中的用户管理,模式,权限管理和角色管理。
(2)掌握为用户分配权限的方法。
(3)了解为不同用户分配不同权限的目的及原因。
二、实验过程1.用系统帐户sys登录数据库,分别创建数据库内部用户user_one和user_two,创建时自己为用户分配帐户口令。
语句:create user user_oneidentified by 123456default tablespace userstemporary tablespace tempquota unlimited on users;create user user_twoidentified by 123456default tablespace userstemporary tablespace tempquota unlimited on users;执行结果:2.为了使两位用户登录数据库请为其授予相应的权限。
语句:grant create session to user_one;grant create session to user_two;执行结果:3.授予用户user_one在自己模式下创建表的权限,在任何模式下删除表的权限,授予用户user_two可以在任何模式下创建表的权限,查询任何模式下表中数据的权限和在任何模式下创建视图的权限。
语句:grant create table,drop any table to user_one;grant create any table,create any view,select any table to user_two;执行结果:4.分别用user_one和user_two登录,写出相应的SQL语句验证为其授予的权限。
(如果建立的表中有主键约束,需要预先授予user_one和user_two用户create any index的权限。
天津理工大学数据库实验四:查询优化
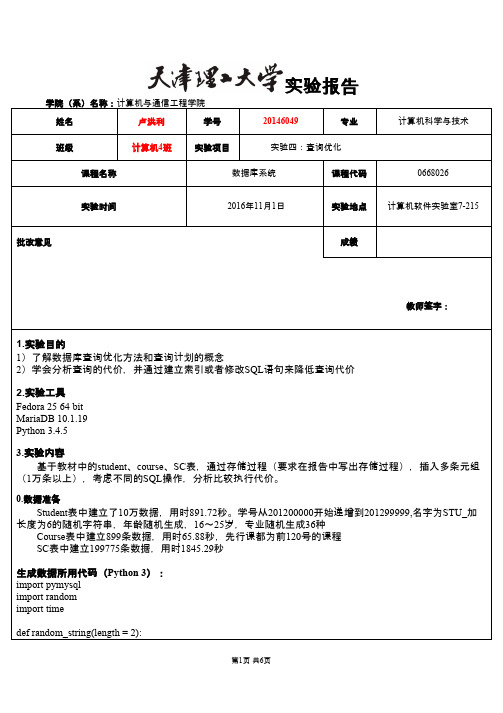
实验报告学院(系)名称:计算机与通信工程学院姓名卢洪利学号20146049专业计算机科学与技术班级计算机4班实验项目实验四:查询优化课程名称数据库系统课程代码0668026实验时间2016年11月1日实验地点计算机软件实验室7-215 批改意见成绩教师签字:1.实验目的1)了解数据库查询优化方法和查询计划的概念2)学会分析查询的代价,并通过建立索引或者修改SQL语句来降低查询代价2.实验工具Fedora 25 64 bitMariaDB 10.1.19Python 3.4.53.实验内容基于教材中的student、course、SC表,通过存储过程(要求在报告中写出存储过程),插入多条元组(1万条以上),考虑不同的SQL操作,分析比较执行代价。
0.数据准备Student表中建立了10万数据,用时891.72秒。
学号从201200000开始递增到201299999,名字为STU_加长度为6的随机字符串,年龄随机生成,16~25岁,专业随机生成36种Course表中建立899条数据,用时65.88秒,先行课都为前120号的课程SC表中建立199775条数据,用时1845.29秒生成数据所用代码(Python 3):import pymysqlimport randomimport timedef random_string(length = 2):chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"str = ''if length == 2:chars = "BCEGHI"for i in range(1, length+1):str += chars[random.randint(0, len(chars)-1)]return strdef generate_name():return "STU_" + random_string(6)def generate_dept():return random_string(2)def generate_age():return random.randint(16, 25)def generate_sno(num):return 201200000 + numdef generate_sex():r = random.randint(0, 1)if r == 0:return "M"elif r == 1:return "F"def insert_student(db, cursor):for i in range(0, 100000):sno = generate_sno(i)sname = generate_name()sage = generate_age()ssex = generate_sex()sdept = generate_dept()print(sno, sname, sage, ssex, sdept)try:cursor.execute('insert into Student VALUES ("%d", "%s", "%s", "%d", "%s")' % \ (sno, sname, ssex, sage, sdept))mit()except:db.rollback()def insert_sc(db, cursor):for i in range(0, 50000):sno = generate_sno(random.randint(1, 100000))cno = random.randint(101, 999)grade = random.randint(0, 100)try:print(sno, cno, grade)cursor.execute('insert into SC VALUES ("%d", "%d", "%d")' % \(sno, cno, grade))mit()except Exception as e:print(e)db.rollback()def insert_course(db, cursor):for i in range(1, 201):no = 100 + iname = random_string(random.randint(5, 29))credit = random.randint(1, 20)try:print("No." + str(i))cursor.execute('insert into Course VALUES ("%d", "%s", "%d", NULL )' % \ (no, name, credit))mit()except:print("No. " + str(i) + "failed!")db.rollback()for i in range(300, 900):no = 100 + ipno = random.randint(1, 20) + 100name = random_string(random.randint(5, 29))credit = random.randint(1, 20)try:print("No." + str(i))cursor.execute('insert into Course VALUES ("%d", "%s", "%d", "%d" )' % \ (no, name, credit, pno))mit()except:print("No. " + str(i) + "failed!")db.rollback()if __name__ == "__main__":db = pymysql.connect("localhost", "root", "root", "STU")cursor = db.cursor()t1 = time.time()# insert_student(db, cursor)# insert_course(db, cursor)insert_sc(db, cursor)t2 = time.time()db.close()print(t1)print(t2)print(t2-t1)1.单表查询(1)直接查询:查询student表中年龄在20岁以上的学生记录select * from Student where Sage > 20;50248 rows in set (0.13 sec)10万条数据中,匹配数据50248条,耗时0.13秒(2)建立索引后,再查询:查询student表中年龄在20岁以上的学生记录MariaDB [STU]> create index STU_INDEX_OF_AGE on Student(Sage);Query OK, 0 rows affected (0.50 sec)建立索引耗时0.50秒MariaDB [STU]> select * from Student where Sage>20;50248 rows in set (0.13 sec)耗时没有发生变化,猜测MariaDB提前为Sage建立了索引,证明猜测:MariaDB [STU]> show index from Student;| Table | Non_unique | Key_name | Seq_in_index | Column_name || Student | 0 | PRIMARY | 1 | Sno || Student | 1 | STU_INDEX_OF_AGE | 1 | Sage |当前拥有主键的索引和刚刚建立的索引,说明上面的猜测是错的(3)表中元组数量少,查询结果所占比例大:查询student表中年龄在20岁以上的学生记录为了满足查询结果所占比例大,根据生成的数据,查询17岁以上的学生:MariaDB [STU]> select * from Student where Sage>17;79851 rows in set (0.17 sec)匹配数据79851条,耗时0.17秒(4)表元组数量多,查询结果所占比例小:查询student表中年龄在20岁以上的学生记录为了满足查询结果所占比例大,根据生成的数据,查询23岁以上的学生:MariaDB [STU]> select * from Student where Sage>23;20124 rows in set (0.10 sec)匹配数据20124条,耗时0.10秒(5)分析以上四种SQL查询的执行效率,并做总结:a.总数据一定时,查询结果所占比例小更省时b.MariaDB本身优化足够,在当前的实验环境下,手动建立索引的优化效果不明显2. 多表查询基于student、course、SC表,按照以下要求,实现多表查询,并分析比较执行效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告
学院(系)名称:计算机与通信工程学院
姓名吴学号201 专业计算机科学与技术
班级二班实验项目数据库设计与查询优化
课程名称数据库系统概论课程代码0660096
实验时间2016/12/8 实验地点7-216
批改意见成绩
教师签字:
一、实验目的
⏹了解教材中介绍的ER图等数据库设计方法
⏹了解基本的数据库优化方法
二、实验的软硬件环境
软件环境:Windows 2000 MS SQL Server
硬件环境:P4 2.4GHz 256内存
三、实验内容
考虑单表查询、连接查询、嵌套查询3种SQL操作,从以下方面进行优化,并分析优化结果。
(1)单表查询。
比较建立索引以后的查询效率
⏹查询student表中所有学生信息所需要的时间
⏹对于student1表,不按照姓名创建索引,查询某个姓名,所需要的时间。
⏹对于student1表,按照姓名创建索引,查询某个姓名,所需要的时间。
⏹对于student1表,不按照系别创建索引,查询某个系所有学生,所需要的
时间。
⏹对于student1表,按照系别创建索引,查询某个系所有学生,所需要的时
间。
查询student表中所有学生信息所需要的时间
对于student1表,不按照姓名创建索引,查询某个姓名,所需要的时间
对于student1表,按照姓名创建索引,查询某个姓名,所需要的时间
对于student1表,按照系别创建索引,查询某个系所有学生,所需要的时间
对于student1表,不按照系别创建索引,查询某个系所有学生,所需要的时间
(2)连接查询
查询选修某门课程的学生姓名。
比较在student、course、SC三个表建立索引和不建立索引的情况
不建立索引的情况
建立索引的情况
(3)针对不同属性查询
⏹比较两个查询“查询某门课程选修的学生”和“某个学生选修的课程”
的查询时间效率,并分析原因(两个查询均用连接查询、嵌套查询分别实
现).
⏹查询某门课程选修的学生(连接查询)
查询某门课程选修的学生(嵌套查询)
(4)数据库概念模式设计(选作)
⏹自己选定一种场景或一个应用问题,为之设计数据库的概念模式(ER图),
要求不少于6个实体,实体之间有一对多、多对多关系。
并将其转化为关
系模式,并标示出每个关系模式的主键。
(提示:学生管理系统、图书馆
管理系统、仓库管理系统、网上商城等)
四、实验过程及结果
1.实验所基于的表
Course1
SC1
Student1
五、问题及体会
本次试验清楚的展示给了我们做每种查询所用的时间,可以直观的比较每种查询的优缺点。
还有,对于大数据,尽可能的建立索引,这样会大大节约时间和空间,有了索引后,查询效率会成倍的提升,在今后的使用过程中,一定要养成良好的习惯。