参考维基知识库版权许可模式研究
大模型与知识库结合技术方案

大模型与知识库结合技术方案引言随着人工智能技术的不断发展,大模型与知识库结合的技术方案被广泛应用于各个领域。
大模型可以通过深度学习算法对海量数据进行训练,具备强大的语义理解和生成能力。
而知识库则是存储了大量的结构化数据和实体关系的数据库,提供了丰富的知识背景和语义信息。
将大模型与知识库相结合,可以进一步提升智能系统的理解能力和应用能力。
一、大模型的特点与应用大模型一般是指参数量非常庞大的深度学习模型,如BERT、GPT 等。
这些模型通过在海量数据上进行训练,可以学习到丰富的语义信息和语言规律。
大模型在自然语言处理、机器翻译、语音识别等领域具有广泛的应用。
1. 自然语言处理大模型在自然语言处理中发挥着重要作用。
通过对海量文本的学习,大模型可以理解各种语义关系和上下文信息,从而实现文本分类、情感分析、命名实体识别等任务。
2. 机器翻译大模型在机器翻译中也有着广泛的应用。
通过对双语语料进行训练,大模型可以学习到源语言和目标语言之间的对应关系,从而实现高质量的自动翻译。
3. 语音识别大模型在语音识别中也发挥着重要作用。
通过对大量语音数据的学习,大模型可以学习到语音的声学特征和语言模式,从而实现准确的语音识别。
二、知识库的特点与应用知识库是一种存储结构化数据和实体关系的数据库,如百科、维基百科等。
知识库提供了丰富的知识背景和语义信息,可以为大模型提供有价值的参考和补充。
1. 实体识别与关系抽取知识库中存储了大量的实体和实体之间的关系,可以为大模型提供实体识别和关系抽取的训练数据。
通过结合知识库的语义信息,大模型可以更准确地识别文本中的实体,并抽取实体之间的关系。
2. 问答系统知识库可以被用来构建问答系统,通过将问题映射到知识库中的实体和关系,系统可以给出准确的回答。
大模型可以通过学习知识库中的问答数据,提升问答系统的准确性和覆盖范围。
3. 智能推荐知识库中的数据可以用于构建个性化的推荐系统。
通过分析用户的兴趣和偏好,结合知识库中的实体关系,大模型可以为用户提供个性化的推荐服务。
中文维基蹒跚上路

中文维基蹒跚上路作者:李响来源:《计算机世界》2009年第24期中文维基蹒跚上路相对于美国维基网络的发展,中国的维基才进入用户接受期。
中文维基还需要克服市场格局压力、用户使用习惯等困难,并找出合适的商业模式,才能进入更快速的发展。
“维基型网站正在成为构建本土知识的基础设施。
”6月7日,互联网实验室总裁刘兴亮在“中国维基行业发展高峰论坛暨《2009中国维基发展报告》发布仪式”上表示,维基型网站构建的,不仅仅是一个全球化的知识体,还构建了一个庞大的“维基社会”,它将在加强话语权的智慧实力方面体现出新的战略优势,为中国增强知识实力提供一种选择。
不过,《2009中国维基发展报告》(下简称“《报告》”)同时指出,与维基在美国的相对成熟发展状态相比,我国的维基产业仍处于早期的用户接受阶段。
那么,在中国特有的网络环境下,市场环境还会给维基产业的发展带来哪些阻力; 中文维基又将走向哪里?如何跨越鸿沟?维基的概念始于1995年,创建者沃德•坎宁安(Ward Cunningham)最初的意图是建立一个知识库工具,方便社区的交流。
直到2001年独立的维基网站Wikipedia诞生以来,维基才在美国开始加速发展起来,并逐渐发展出多种不同的形态,形成了维基百科网站、主题性维基社区、问答性维基社区和维基新闻网站4种发展趋势。
“随着Wikipedia的成熟发展,美国维基产业已经跨出‘百科全书’层面,正处于从‘大众社区’向‘社会应用’层面过渡的时期。
”《报告》指出,维基的应用和发展主要分为3个层次:以知识为核心的维基百科全书、大众参与的维基社区,以及维基思维更广泛的社会实践。
据介绍,美国维基产业已经到达第二个层次和第三个层次的过渡时期,而从维基应用层面而言,美国市场正处于大众化发展的早期。
相比美国,中国的维基产业发展就滞后得多了。
“目前中国维基产业的核心仍处于维基百科全书为主的第一层,从应用层面看,也处于市场接受期。
”刘兴亮告诉记者。
高校图书馆2.0信息服务模式研究

原因有多方面, 其中一个主要原因就是 : 长期 以 来高校图书馆的信息服务过于注重对学科专家掌握 的学科信息线索进行 收集 、 整理及利用 , 忽视了读者
的参 与 和 评 价 。一 方 面 图 书 馆 与 读 者 之 间 缺 乏 互 动, 信息 资源 以馆藏 资源 为 主 , 者作 为信 息 资源 的 读 被动 接受 者 , 人 资源往 往被 孤立 , 以发 挥群 体 的 个 难
第2 8卷
第1 6期
甘肃 科技
Ga u S i n e a c oo y ns ce c nd Te hn l g
l 2 No 1 f 8 - .6
A
21 0 2年 8月
2 1 02
高 校 图 书馆 2 O信 息 服 务 模 式 研 究 .
余少瑛
( 广东金融学 院 图书馆 , 广东 广州 50 2 ) 15 1
首先 , 提供 个人 知 识 积 累 平 台 。读 者 可 将科 研
3 高校 图书馆 2 O视角下 的信 息服务 . 模 式
随 着 近 年 来 各 高 校 图 书 馆 普 遍 注 重 数 字 化 建 设, 资源 范 围被拓 宽 、 资源 数 量 激增 、 务 手 段 多 样 服
过程中发现和收集的信息资源以符合维基的方式进 行组织 和存 放 , 并可供 他人 进行修 改 和完善 , 以形 成 有关 概念 和知识 主题 的具 有知识 层级 的知 识库 。
社 会化 。通过 开放 的系 统 架 构 , 读者 在 互 联 网上 将
的浏览 线 索进 行组 织 , 借助博 客 、 基等 技术 手段 聚 维
读 者既是 资源 接收 者 也 是 资 源建 设 的 主体 , 自主在 门户 中发 布 自己 的研 究成 果 、 点 , 观 进而实 现 资源 的
【国家社会科学基金】_国家数字图书馆_基金支持热词逐年推荐_【万方软件创新助手】_20140813

推荐指数 12 5 4 3 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 3ห้องสมุดไป่ตู้ 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
开放存取出版 建设管理 建设对策与建议 应用开发接口 应用 层次分析法 对象识别 孤本 复合图书馆 图书馆评估 图书馆法 单点登录模型 医学数据挖掘 区域 劳动要素 动力机制 分析 内容分析 典型系统 关键组件 关系抽取方法 公益性 公共图书馆 元数据模型 元数据定制 元数据值 元数据 值构成部分 信息资源建设政策 信息网络传播权 信息组织 信息素养人 信息科学 信息生态系统 信息生态学 信息生态 信息服务模式 信息政策 信息抽取 信息利用 信息公平 信息交流 保障体系 体系 事实抽取 书目情报服务 主题抽取 主题发现 一致性检测 web图书馆 unisist模型 sparql sondergaard模型 ontology查询
评价工具 证明力 设计原则 许可原则 计算机取证 规划建设 规划 联盟采购 网页重现 网页变化监测 网络资源长期保存 网络计量学 网络生态 网络影响力 网络安全 网络信息资源保存 网络信息保存 网络信息 网络伦理评价 网站重建 网站恢复 编目 维基 结构模式 结构化检索 经济信息安全 组织结构 组织 系统集成 管理系统 管理制度 策略 科研机构 社交软件 社交网络 知识组织系统 知识社区 知识搜索 知识产权 相关度算法 电子资源采购 电子证据 生物医学 生命周期管理 理论模型 版权 流程 泛在图书馆 法律法规 模糊概念 标签 标准规范 标准 查询翻译
大数据参考文献
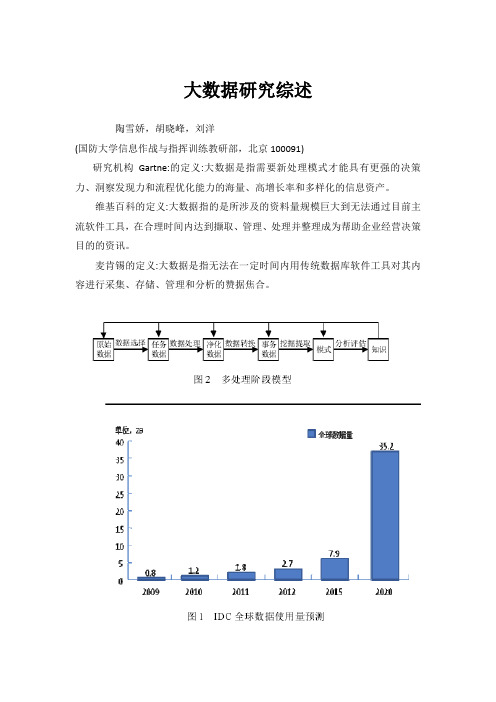
大数据研究综述陶雪娇,胡晓峰,刘洋(国防大学信息作战与指挥训练教研部,北京100091)研究机构Gartne:的定义:大数据是指需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
维基百科的定义:大数据指的是所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理并整理成为帮助企业经营决策目的的资讯。
麦肯锡的定义:大数据是指无法在一定时间内用传统数据库软件工具对其内容进行采集、存储、管理和分析的赞据焦合。
数据挖掘的焦点集中在寻求数据挖掘过程中的可视化方法,使知识发现过程能够被用户理解,便于在知识发现过程中的人机交互;研究在网络环境卜的数据挖掘技术,特别是在Internet上建立数据挖掘和知识发现((DMKD)服务器,与数据库服务器配合,实现数据挖掘;加强对各种非结构化或半结构化数据的挖掘,如多媒体数据、文本数据和图像数据等。
5.1数据量的成倍增长挑战数据存储能力大数据及其潜在的商业价值要求使用专门的数据库技术和专用的数据存储设备,传统的数据库追求高度的数据一致性和容错性,缺乏较强的扩展性和较好的系统可用性,小能有效存储视频、音频等非结构化和半结构化的数据。
目前,数据存储能力的增长远远赶小上数据的增长,设计最合理的分层存储架构成为信息系统的关键。
5.2数据类型的多样性挑战数据挖掘能力数据类型的多样化,对传统的数据分析平台发出了挑战。
从数据库的观点看,挖掘算法的有效性和可伸缩性是实现数据挖掘的关键,而现有的算法往往适合常驻内存的小数据集,大型数据库中的数据可能无法同时导入内存,随着数据规模的小断增大,算法的效率逐渐成为数据分析流程的瓶颈。
要想彻底改变被动局面,需要对现有架构、组织体系、资源配置和权力结构进行重组。
5.3对大数据的处理速度挑战数据处理的时效性随着数据规模的小断增大,分析处理的时间相应地越来越长,而大数据条件对信息处理的时效性要求越来越高。
【国家社会科学基金】_知识库构建_基金支持热词逐年推荐_【万方软件创新助手】_20140808

2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
科研热词 推荐指数 知识库 4 领域本体 1 问答系统 1 问答知识 1 虚词 1 藏语 1 英汉双语短语级平行语料 1 自然语言处理 1 联合虚拟参考咨询 1 网络舆情 1 网络案情分析 1 类别知识 1 知识转移 1 理论 1 模式 1 本体知识库 1 方法 1 情感评价 1 图书馆服务 1 图书馆 1 命名实体识别 1 句法分析 1 参考咨询 1 博弈分析 1 公共物品 1 信息融汇 1 信息经济 1 信息咨询服务 1 俄语计算语言学 1 人地关系 1 triz 1 cssci 1 bisecting k-means clustering算法 1
推荐指数 6 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
科研热词 面向学习活动 课程群 知识管理 知识标引 知识构建 知识服务 知识库 知识工作流 模式识别 模块化 核心技术 智能处理 教育信息化 教学系统设计 多代理 古籍整理 产品研发 中文信息处理
推荐指数 5 3 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13
2011年 科研热词 框架 非核心框架元素 语法信息库 语义 规则 藏语动词 藏文信息处理 学术资源网络模型 学术评价 学术期刊 关联分析 中文信息处理 cssci本体 推荐指数 2 1 1 1 1 1 1 1 1 1 1 1 1
知识共享许可协议(署名/by)

协议文本署名 3.0中国大陆本作品(定义如下)的提供是以适用“知识共享公共许可协议”(简称“CCPL”或“许可”)为前提的。
本作品受《中华人民共和国著作权法》以及其他可适用法律的保护。
对本作品的使用不得超越本许可协议授权的范围。
如您行使本许可授予的使用本作品的权利,就表明您接受并同意遵守本许可协议的所有条款。
鉴于本许可为合同,在您接受这些条款和规定的前提下,许可人授予您本许可所包括的权利。
第一条定义1. 本作品:指根据本许可协议提供的以任何方式和形式(包括以数字形式)表达之文学、艺术和科学领域的作品,例如:书籍、手册等文字作品;讲课、演讲、讲道及其他同类性质的作品;戏剧或音乐戏剧作品;曲艺作品;舞蹈作品及哑剧作品;配词或不配词的音乐作品;电影作品和以类似摄制电影的方法创作的作品;素描、绘画、书法、建筑、雕塑、雕刻或版画等作品;摄影作品以及以类似摄影的方法创作的作品;杂技艺术作品;实用艺术作品;与地理、地形、建筑或科学有关的插图、地图、设计图、草图及立体的造型作品;以及法律、行政法规规定的其他文学艺术作品。
为本许可协议之目的,本协议有关“本作品”的规定适用于表演、录音制品及广播电视节目。
2. 原始作者:就文学或艺术作品而言,指创作本作品的自然人或依法视为本作品作者的法人或其他组织。
为本许可之目的,下述情形下的自然人、法人或其他组织适用本许可有关“原始作者”的规定:(1)就表演而言,指演员、歌唱家、音乐家、舞蹈家和其他表演、演唱、演说、朗诵、演奏、表现或者以其它方式表演文学、艺术作品或民间文学艺术的人员;(2)就录音制品而言,指首次将表演的声音或其他声音录制下来的自然人、法人或其他组织;(3)就广播电视节目而言,指传播广播电视节目的组织;(4)作者身份不明的,指行使作品著作权(除署名权外)的作品原件所有人(比如出版社)。
3. 演绎作品:指基于本作品,或基于本作品与其他已存在的作品而创作的作品,例如翻译、改编、编曲或对文学、艺术和科学作品的其他变更,包括以摄制电影的方法对作品的改编,或其他任何对本作品进行改造、转换、或改编后的形式,包含任何可确认为源自原始作品的修改形式。
本体论在知识库构建中的应用研究

本体论在知识库构建中的应用研究在知识库构建中,本体论的应用越来越受到重视。
本体论是指一种对现实世界或某个特定领域中对象和概念进行描述和建模的方法,旨在构建一种可被计算机理解的结构化知识表示形式。
本体论的应用可以帮助知识库中的信息更加准确、清晰地表达,从而提高知识库的质量和可用性。
1. 本体论的起源与发展本体论最早是由哲学家约翰·洛克所提出,用于探讨人类思维和理解的本质。
后来随着计算机科学和人工智能领域的发展,本体论也被引入到了知识表示和知识管理领域。
现代本体论已经形成了一套完整的理论框架,包括本体的组成结构、本体语言、本体的构建和应用等方面。
2. 本体论在知识库构建中的作用知识库是指一种用于存储和管理知识的系统,它可以为用户提供快速、准确、可靠的信息服务。
在构建知识库时,我们需要对知识进行描述和分类,这就需要使用本体论来对知识进行建模。
本体论可以帮助我们明确知识库中的概念和关系,从而更好地组织和管理知识。
在知识库中,本体论的应用可以有以下几个方面:2.1. 概念建模本体论可以帮助我们将知识库中的概念进行抽象和分类,从而形成一种标准化和可重复使用的概念模型。
例如,对于医学领域的知识库,我们可以使用本体论来定义“疾病”、“症状”、“治疗方法”等概念,并对它们之间的关系进行描述和建模。
2.2. 知识表示通过本体论,我们可以将知识库中的信息表示为一组本体实体(如“汽车”、“手表”等)和本体属性(如“颜色”、“品牌”等)。
这种表示方式可以使得知识库中的信息更加清晰、准确,并且能够被计算机识别和处理。
2.3. 知识推理本体论还可以帮助我们实现知识推理,即基于本体定义的事实和规则,自动地推导出新的知识。
例如,在一个交通出行的知识库中,我们可以定义“地铁”和“公交车”之间的关系为“都可以作为公共交通工具”,这样,在用户查询“哪种交通工具可以到达某个地点”时,系统就可以根据这个规则自动推理出答案。
3. 本体论应用案例分析3.1. ProtégéProtégé是一个知名的本体论工具,它可以帮助用户创建、编辑、存储和管理本体。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
维基知识库版权许可模式研究黄永2012-9-25 8:13:24 来源:《数字图书馆论坛》(京)2011年11期【英文标题】Research on Copyright Licenses of Wiki Knowledge Database【作者简介】黄永,男,硕士研究生,广东医学院东莞校区图书馆助理馆员,研究方向为信息产权管理。
E-mail:,东莞523808【内容提要】文章从GNU自由文档许可证以及创作共用两种主流的开放内容版权许可模式出发,分析维基知识库的版权管理模式,并探讨了两种许可模式在现行版权制度下的兼容性。
The article analyzes the copyright management mechanism of the Wiki Knowledge based on two main trends and contents with no restriction of copyright licenses-the GFDL model and CC model, and discusses the compatibility of these two models in the existing copyright system.【关键词】维基/知识库/版权许可Wiki/Knowledge base/Copyright licenses引言随着数字革命和互联网时代的到来,在全球范围内以分散的方式和相对低廉的成本创作新的作品或者演绎作品成为可能。
传统版权制度下版权授权模式在某种程度上已经不适应,甚至会阻碍作品的传播和使用。
尤其是在新的传播方式和传播技术日新月异的数字时代,传统的版权授权模式已经不能满足公众自由获取信息的需要,甚至在很大程度上影响了学术交流。
因此,在现行版权制度的框架之下,寻求一种可以使用户自由使用他人作品,并授权他人自由使用和传播作品的机制,解决数字环境下版权作品的授权问题就成为了版权产业界和学术界关注的焦点。
进入20世纪末,随着开放存取运动的蓬勃发展,以Wiki技术为基础的维基系统和维基网站的出现,传统的版权许可模式在新形势下发生了新的变化,涌现了像GNU自由文档许可证(GNU Free Documentation License,简称GFDL)、创作共用(Creative Commons,简称CC)许可协议、APSL许可证(Apple Public Source License)等版权许可模式,这些新的版权许可模式是在网络环境下维系版权专有与信息资源共享平衡机制的有效尝试。
2009年5月维基百科宣布在其一直使用的GNU自由文档许可证的基础上新增创作共用/署名—相同方式共享协议(Creative Commons Attribution/Share Alike License),本文亦以其所采用的GNU自由文档许可证和创作共用许可证这两种主要的开放内容许可协议为例,探析维基知识库的版权解决方案。
1、GNU自由文档许可证(GFDL)1.1GNU自由文档许可证进入互联网时代之后,知识的传播速度也越来越快,而广大作者也希望自己的作品能够在世界范围内自由传播而不受版权的限制,而传统版权模式在保护知识在互联网上自由传播过程中却显得苍白无力。
如果作者盲目放弃自己部分版权,势必引起不必要的麻烦和纠纷。
基于这个原因,Richard Stallman①设计出了与传统的“copyright”相对立的“copyleft”许可证。
“copyleft”是由自由运动所发展的概念,是一种新的授权方式,除了允许使用者自由使用、复制、修改,还要求使用者改作后的衍生作品都以相同的授权方式[1]。
copyleft虽然是一种反版权制度,但它符合版权制度的规定,使用copyleft的作品也是有版权的。
Richard Stallman于1985年10月建立自由软件基金会(FSF)之后,主要提出了两个copyleft许可证:GPL许可证(GNU General Public License)和GFDL许可证(GNU Free Documentation License)。
GPL许可证主要用于软件作品,而GFDL许可证主要用于文字作品。
由此可见,GNU自由文档许可证是一个“反版权”(copyleft)或者称作版权属左的协议。
GNU自由文档许可证是由美国自由软件基金会为了GNU计划于2000年发布的,它是对GNU通用公共协议的补充。
自GNU自由文档许可证初始版本发布以来,经过维基媒体基金会、自由软件基金会的不断讨论、修改,终于形成了目前的1.3版(见表3)。
目前,世界上最著名、最成功使用GFDL的项目,是维基百科(Wikipedia)。
1.2GNU自由文档许可证具体内容(1)GNU自由文档许可证的适用范围由于GNU自由文档许可证主要用于文字作品,因此可以用于任何媒体上的任何手册以及其他文档,只需要作品版权的所有者声明自己的作品是使用该协议的条款发布的[2]。
作品使用该协议发布之后,可以在世界范围内免费、无限制地使用,公众的任何一个人都是该协议的许可对象,如果用户复制、修改或者发布了这些在版权法保护下的文档,就表示用户已经接受了该协议。
(2)GNU自由文档许可证的具体内容GNU自由文档许可证的内容主要涉及原样复制、大量复制、修正、合并文档、文档合集、独立作品汇集、翻译与协议终止方面的具体版权规定(详见表2)。
2、“创作共用”许可协议(Creative Commons Licenses)2.1“创作共用”理论的产生互联网的快速发展,使作品传播的速度越来越快,传统的版权法对作品使用的限制越来越严,在传统版权模式下,我们最常见的版权声明方式就是“保留所有权利”(All Rights Reserved),每个作者都习惯性地在自己作品后面声明“保留所有权利”,其实这些作品中大部分都是作者在别人创作的基础上进行的再创作[3]。
这样不仅导致原作品作者的权利得不到尊重,而且导致更多优秀作品(包括文学、艺术以及其他数字作品)无法发挥其最大价值或更加广泛地传播[4]。
随着互联网的不断发展以及知识交流重要性的凸显,这种保留所有权利的版权模式已经严重限制了文化自由创作的发展,越来越多的作者开始意识到他们创作作品的目的不是获取经济利益,而是让自己的作品得到更大范围的传播和使用,因此他们也不需要保留作品的所有权利。
在这种思潮的影响下,他们更趋向于在自己作品的声明中选择“保留部分权利”或者“不保留权利”。
“创作共用”理论就是在这种情况下产生的。
2.2“创作共用”协议的定义“创作共用”协议(Creative Commons Licenses,也有译作知识共享协议),由在2001年发起,并由其主席劳伦斯·莱斯格(Lawrence Lessig)以及关注自由文化议题的专家学者创设,并于2002年12月16日提出,旨在保护网上数字作品(文学、美术、音乐等)的许可授权机制[5]。
“创作共用”协议自发布以来,已经被越来越多的地区和国家采纳并翻译成各种语言,各国根据本国著作权法律的规定对“创作共用”进行了小幅度的修改。
“创作共用”协议创立之初用于开放网络文学和艺术作品,现在已经被各个国家应用于各个领域[6]。
美国、澳大利亚、加拿大、法国、德国、日本等国家都纷纷实施了这一协议。
我国于2006年3月29日发布了中国大陆版Creative Commons系列许可协议,标志着“创作共用”协议中国本地化的完成,极大地推动了我国开放获取运动和知识共享的进程④。
2.3“创作共用”协议的许可方式“创作共用”协议从本质上讲就是现行版权法下的一种授权许可协议,除作者在其作品后作特殊说明之外,任何人都可以免费拷贝、分发、讲授、表演某个网站或者某个知识库的任何作品(文字、图片、声音、视频等)[7]。
该约定如下:(1)注明引用资料出处和作者,如引用自某处,作者为某某;(2)非商业用途,即用户不能为了经济利益擅自改动或者删除原作者名并将作品发表在商业媒体上;(3)如果用户需要在某作品内容基础上进行再创作,那么作者就应该按照与原来作品协议完全相同的协议发布最终作品。
在以上最基本的协议基础上,“创作共用”还提供了四种可供选择的许可条件(见表3)。
在1.0版的“创作共用”协议中,通过对这四种许可条件的结合使用,形成了11种组合方式⑤:(1)署名;(2)署名—禁止派生作品;(3)署名—禁止派生作品—非商业利用;(4)署名—非商业利用;(5)署名—非商业利用—相同方式共享;(6)署名—相同方式共享;(7)禁止派生作品;(8)禁止派生作品—非商业利用;(9)非商业利用;(10)非商业利用—相同方式共享;(11)相同方式共享。
这些组合方式构成了从松到紧的授权限制,给予创作者更加便利、更加灵活地选择。
作者可以通过对文字和图标、法律文本、机器代码等的许可,把自己的作品与法律基础相关联,这样就可以有效保护自己作品在网络上的传播与共享[4]。
但由于绝大多数的作者要求对其作品保留署名,因此在创作共用2.0以上的版本,有5种没有署名条款的协议被淘汰,原有的11种许可方式被简化为6种(见表4)。
在这6种组合中,最宽松的是第一种——署名许可方式,限制性最强的是第三种。
另外,创作共用还提供“奠基人版权”(Founder's Copyright,标记为创作共用/FC)协议⑥及用于音乐、影片、摄影作品的拼贴混合创作的特别取样授权(Sampling Plus)和非商业特别取样授权(Noncommercial Sampling Plus)。
所以可以说,创作共用并不是一种许可证,而是一系列许可证的集合。
需要注意的是,对应不同的司法管辖区,创作共用许可证有不同的地区版本。
另外,创作共用许可证一直在修订,最新的是3.0版,但是一部分地区还在使用2.5版。
譬如:本文采用创作共用署名2.5中国大陆版许可证(Creative Commons Attribution 2.5 China Mainland License)授权。
3、GNU自由文档许可证与创作共用协议的兼容GNU自由文档许可协议(GFDL)和创作共用协议(CC)自产生以来,在平衡作者私人利益和社会公众利益方面发挥着特有的作用,也逐渐被用户所接受,成为互联网时代的两种重要授权许可模式。
从其应用领域来分析,GNU自由文档许可证经历了从最初主要用于软件文档的授权许可,至后来大量用于非软件文档的发展变迁;而创作共用则是针对互联网上文学、美术、音乐等作品的许可授权机制[3]。
但随着互联网的不断发展,这两种许可模式也出现了新的变化。
在新的网络环境下,这两种许可模式是否兼容逐渐成为学界关注的焦点。
3.1GNU自由文档许可证与创作共用协议的兼容GNU自由文档许可协议和创作共用协议作为两种不同的授权许可模式,并不是所有的许可协议都属于copyleft的规范。