回归分析测试题-21页文档资料
回归分析练习题与参考答案

回归分析练习题与参考答案1 下面是7个地区2000年的人均国内生产总值(GDP)与人均消费水平的统计数据:求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间与预测区间。
解:(1)回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%% %注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%% (4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
模型摘要模型R R 方调整的R 方估计的标准差1 .998(a) 0.996 0.996 247.303a. 预测变量:(常量), 人均GDP(元)。
%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%% (5)F检验:Anova b模型平方与df 均方 F Sig.1 回归81444968.680 1 81444968.680 1331.692 .000a残差305795.034 5 61159.007总计81750763.714 6a. 预测变量: (常量), 人均GDP。
回归分析练习题及参考答案
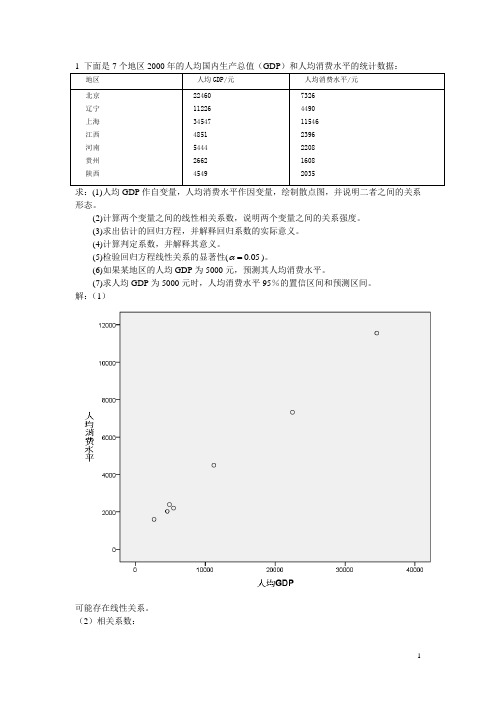
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:地区人均GDP/元人均消费水平/元北京辽宁上海江西河南贵州陕西 224601122634547485154442662454973264490115462396220816082035求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
回归分析练习题与参考答案

回归分析练习题与参考答案1 下面是7个地区2000年的人均国内生产总值(GDP)与人均消费水平的统计数据:求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间与预测区间。
解:(1)%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
模型摘要模型R R 方调整的R 方估计的标准差1 .998(a) 0.996 0.996 247.303a. 预测变量:(常量), 人均GDP(元)。
%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%% (5)F检验:Anova b模型平方与df 均方 F Sig.1 回归81444968.680 1 81444968.680 1331.692 .000a残差305795.034 5 61159.007总计81750763.714 6a. 预测变量: (常量), 人均GDP。
b. 因变量: 人均消费水平回归系数的检验:t检验%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%% %注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型 非标准化系数标准化系数t 显著性B 标准误 Beta1(常量) 734.693 139.540 5.2650.003 人均GDP (元)0.3090.0080.99836.4920.000a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% (6)某地区的人均GDP 为5000元,预测其人均消费水平为734.6930.30950002278.693y =+⨯=(元)。
回归研究分析测试题

回归分析测试题————————————————————————————————作者:————————————————————————————————日期:回归分析测试题A 卷 一、 选择题:1.炼钢时钢水的含碳量与冶炼时间有( )A.确定性关系B.相关关系C.函数关系D.无任何关系2.对相关性的描述正确的是( ) A .相关性是一种因果关系 B .相关性是一种函数关系C .相关性是变量与变量之间带有随机性的关系D .以上都不正确 3.∑=ni i i y x 1等于( )A.121)(y x x x n +++ΛB.121)(x y y y n +++ΛC.Λ++2211y x y xD.n n y x y x y x +++Λ22114.设有一个回归方程为x y5.22-=,则变量x 增加一个单位时( )A .y 平均增加2.5个单位 B.y 平均增加2个单位C.y 平均减少2.5个单位D.y 平均减少2个单位5.x 与y 之间的线性回归方程a bx y +=必定过( )A.(0,0)点B.(0,x )点C.(0,y )D.(y x ,)6.某化工厂为预测某产品的回收率y ,需要研究它和原料有效成分含量x 之间的相关关系,现取了8对观测值,计算得5281=∑=i ix,22881=∑=i iy,478812=∑=i ix,184981=∑=i i i y x ,则y 与x 的回归方程是( )A.x y 62.247.11+=B.x y 62.247.11+-=C.62.247.11+=x yD.x y 62.247.11-=7.线性回归方程a bx y +=有一组独立的观测数据),(11y x ,),(,),,(22n n y x y x Λ,则系数b 的值为( )A.∑∑==---ni ini i iy yy y x x121)())(( B.∑∑==--ni ini i ixy y x x121))((C.∑∑==---ni ini i ix xy y x x121)())(( D.∑∑==--ni ini iy yx x 1212)()(8.已知x 、y 之间的一组数据:则y 与x 的线性回归方程a bx y +=必过点( )A .(2,2) B.(1.5, 0) C. (1, 2) D.(1.5, 4) 二、填空题:9.线性回归方程a bx y +=中,b 的意义是.10.有下列关系:(1)人的年龄与他(她)拥有的财富之间的关系;(2)曲线上的点与该点的坐标之间的关系;(3)苹果的产量与气候之间的关系;(4)森林中的同一种树木,其断面直径与高度之间的关系;(5)学生与他(她)的学号之间的关系.其中有相关关系的是 . 11.若施化肥量x 与水稻产量y 的回归直线方程为2505+=x y ,当施化肥量为80kg 时,预计的水稻产量为 . 12.已知线性回归方程{}),19,13,7,5,1(455.1∈+=x x y 则=y . 13.对于线性回归方程25775.4+=x y ,当28=x 时,y 的估计值x 0 1 2 3 y 1 3 5 7是 .三、解答题:14.为了研究三月下旬的平均气温(x C 0)与四月二十号前棉花害虫化蛹高峰日(y )的关系,某地区观察了1996年至2001年的情况,得到下面的数据:年份 1996 1997 1998 1999 2000 2001 x 24.4 29.6 32.9 28.7 30.3 28.9 y 19 6 1 10 1 8(1)据气象预测,该地区在2002年三月下旬平均气温为27C 0,试估计 2002年四月化蛹高峰日为哪天? (2)对变量y x 、进行相关性判断. B 卷一、选择题:1.变量y 与x 之间的回归方程( ) A.表示y 与x 之间的函数关系 B.表示y 与x 之间的不确定性关系 C.反映y 与x 之间真实关系的形式D.反映y 与x 之间的真实关系达到最大限度的吻合 2.对于相关系数r ,叙述正确的是( )A.r r ),,0(+∞∈越大,相关程度越大,反之,相关程度越小B.r r ),,(+∞-∞∈越大,相关程度越大,反之,相关程度越小C.1≤r,且r越接近于1,相关程度越大,r 越接近于0,相关程度越小D.以上说法都不对3.由一组样本数据),(11y x ,),(,),,(22n n y x y x Λ得到的回归直线方程a bx y +=,那么下面说法不正确的是( )A .直线a bx y +=必经过点),(y xB .直线a bx y +=至少经过点),(11y x ,),(,),,(22n n y x y x Λ中的一个点C .直线a bx y +=的斜率为∑∑==--ni ini ii x n xyx n yx 1221D.直线a bx y +=和各点),(11y x ,),(,),,(22n n y x y x Λ的偏差[]∑=+-ni i ia bx y12)( 是该坐标平面上所有直线与这些点的偏差中最小的直线4.三点(3,10),(7,20),(11,24)的回归方程是( ) A.x y 42347+= B x y 47423+= C.42347-=x y D.x y 47423-=5.为了考察两个变量x 和y 之间的线性相关性,甲、乙两位同学各自独立做了10次和15次试验,并且利用线性回归方法,求得回归直线分别是1l 、2l .已知两人得的试验中,变量x 和y 的数据的平均值都相等,且分别都是t s 、,那么下列说法正确的是( )A .直线1l 和2l 一定有公共点),(t sB .直线1l 和2l 相交,但交点不一定是),(t sC .必有21||l lD .1l 与2l 必定重合6.一位母亲记录了她儿子3到9岁的身高,建立了她儿子身高y 与年龄x 的回归直线方程x y 19.793.73+=,并预测儿子10岁时的身高,则下列的叙述正确的是( ) A .她儿子10岁时的身高一定是145.83cm B .她儿子10岁时的身高在145.83cm 以上 C .她儿子10岁时的身高在145.83cm 左右 D .她儿子10岁时的身高在145.83cm 以下7.工人工资(元)依劳动生产率(千元)变化的回归方程为x y 8050+=,下列判断正确的是()A.劳动生产率为1000元时,工资为130元B.劳动生产率提高1000元时,工资提高80元C.劳动生产率提高1000元时,工资提高130元D.当月工资为250元时,劳动生产率为2000元8.下列说法中错误的是( )A.如果变量x 与y 之间具有线性相关关系,则我们根据试验数据得到的点(i i y x ,)(=i 1,2,n ,Λ)将散布在某一条直线附近B. 如果变量x 与y 之间不具有线性相关关系,则我们根据试验数据得到的点(i i y x ,)(=i 1,2,n ,Λ)不能写出一个线性方程C. 设x 、y 是具有线性相关关系的两个变量,且y 关于x 的线性回归方程为a bx y +=,b 叫做回归方程的系数D. 为使求出的线性回归方程有意义,可先用画出散点图的方法来判断变量x 与y 之间是否具有线性相关关系二、填空题:9.在下列各量与量的关系中,既不是相关关系,也不是函数关系的为 .(只填序号)(1)正方体的体积与棱长间的关系;(2)一块农田的水稻产量与浇水量之间的关系;(3)人的身高与血型;(4)家庭的支出与收入;(5)A 家庭的用电量和 B 家庭的用电量10.设两个变量x 和y 之间具有线性相关关系.它们的相关系数是r ,y 关于x 的回归直线的斜率是b ,纵截距是a ,那么必有 (填符号关系)11.假设y 与x 之间具有如下的双曲线相关关系:xba y +=1,作变换u = ,=v ,则模型可转化为线性回归模型:bv a u +=.12.已知具有线性相关关系的变量x 和y , 测得一组数据如下表:若已求得它们的线性回归方程中的系数为 6.5,则这条线性回归方程为 .13.人的身高x (单位:cm)与体重y (单位:kg)满足线性回归方程712.85849.0-=x y ,若要找到体重为41.638kg 的人, 是在身高150cm 的人中(填“一定”,“不一定”).三、解答题:x 2 4 5 6 8 y 10 20 40 30 5014.下表提供了某厂节能降耗技术改造后生产甲产品过程中记录的产量x (吨)与相应的生产能耗y (吨标准煤)的几组对照数据.x3 4 5 6Y 2.5 3 4 4.5(1)请画出上表数据的散点图;(2)求出y 关于x 的线性回归方程a bx y +=;(3)已知该厂技改前100吨甲产品的生产能耗为90吨标准煤.试根据(2)求出的线性回归方程,预测生产100吨甲产品的生产能耗比技改前降低多少吨标准煤?参考答案 A 卷一、选择题:1.B 炼钢时钢水的含碳量与冶炼时间之间虽有一定联系,但不能用一个函数关系来准确地表示,所以具有相关性,故选B.2.C 函数关系是一种因果关系,而相关性不一定是因果关系,也可能是伴随关系,故选C.3.D 由求和符号定义即知选D.4.C 因为回归方程中x 系数为5.2-,所以x 每增加一个单位,y 平均减少2.5个单位,故选C.5.D 因为y 与x 的线性回归方程必过点(y x ,).故选D.6.A 由已知得, 5.6=x ,5.28=y5281=∑=i ix,22881=∑=i iy,478812=∑=i ix,184981=∑=i i i y x , ,所以,由最小二乘法确定的回归方程的系数为62.288812281=--=∑∑==i ii ii x xyx yx b , 47.115.662.25.28=⨯-=-=x b y a .因此,所求的线性回归方程为 47.1162.2+=x y .故选A. 7.C 由最小二乘法求线性回归方程的推导过程知选C.8. D y 与x 的线性回归方程必过点(y x ,),而5.1=x , ,4=y 故选D. 二、填空题:9.x 每增加一个单位,y 平均增加b 个单位.10.(1)、(3)、(4). 判断两个变量间是否具有相关性,就是判断它们之间有没有科学的,真实的某种关系.易知(1)(3)(4)是具有相关性的,(2)是函数关系,(5)不具有相关性,因为学生与学号之间没有必然联系. 11.650kg 由线性回归方程得 650250805=+⨯=y .12.y =58.5 因为线性回归方程455.1+=x y 经过点(y x ,),由x =9知y =58.513.390 由线性回归方程得 3902572875.4=+⨯=y . 三、解答题:14.解:(1)由已知数据计算得, ,13.29=x ,5.7=y5130612=∑=i ix,6.122261=∑=ii i yx ,所以,由最小二乘法确定的回归方程的系数为2.266612261-=--=∑∑==i i i ii x x yx yx b ,6.7113.29)2.2(5.7=⨯--=-=x b y a .因此,所求的线性回归方程为 6.712.2+-=x y .当27=x 时, 2.126.71272.2=+⨯-=y .据此,可估计该地区2002年4月12日或13日为化蛹高峰日.(2) 因为 9342.0)6)(6(66161222261=---=∑∑∑===i i i i i ii y y x x yx yx r .据此可以得出,变量y 与x 存在线性相关关系.B 卷 一、选择题:1.D 由线性回归方程的意义知选D.2.C 由线性相关系数的定义知选C.3.B 线性回归方程反映变量y 与x 之间的真实关系达到最大限度的吻合,即使绝大多数点在回归直线附近,但并非一定要经过这些点.故选B.4.B 由已知有 ,7=x ,18=y43431=∑=ii i yx , 179312=∑=i i x ,所以,由最小二乘法确定的回归方程的系数为∑∑==--=31223133i i i ii x x yx yx b =47147179378434=--42374718=⨯-=-=x b y a 因此,所求的线性回归方程为 42347+=x y . 故选B.5.A 线性回归直线方程为a bx y +=.而x b y a -=,即a bs t bs t a +=-=,,所以(t s ,)在回归直线上.所以直线1l 和2l 一定有公共点(t s ,),应选A.6.C 由线性回归方程求出的值是估计出的一个最有可能出现的结果,并非一定出现. 7.B 回归直线斜率为80,所以x 每增加1,y 增加80,即劳动生产率提高1000元时,工资提高80元.根据线性回归直线方程,只能求出相应于x 的估计值,故A 错,应选B.8.B 根据线性回归直线方程的求法,即使变量y 与x 之间不具有线性相关关系, 也能根据试验数据得到的点(i i y x ,)(=i 1,2,n ,Λ)写出一个线性方程,但此时的方程已不能反映变量y 与x 之间的吻合关系.二、填空题:9.(3)、(5) 因为(1)是函数关系;(2)、(4)是相关关系.10.b 、r 符号相同. 因为∑∑==--=ni ini ii x n xyx n yx b 1221,∑∑∑===---=ni ni i ini ii y y x xyx n yx r 112221)()(11. y u 1=, xv 1= 12.5.25.6-=x y 由题可知30 ,5==y x ,又已知5.6=b5.2 -=-=x b y a 所以, 所以5.25.6-=x y13.不一定 根据线性回归直线方程,只能求出相应于x 的估计值y .因此填“不一定”.三、解答题:14. 解:(1)画出散点图(略).(2)由对照数据,计算得 5.6641=∑=i i i y x , 86412=∑=i i x , ,5.4=x ,5.3=y所以,由最小二乘法确定的回归方程的系数为∑∑==--=41224144i ii ii x x yx yx b =7.05.44865.35.445.662=⨯-⨯⨯- 35.05.47.05.3=⨯-=-=x b y a .因此,所求的线性回归方程为 0.70.35y x =+.(3)由(2)的回归方程及技改前生产100吨甲产品的生产能耗,得降低的生产能耗为:65.19)35.01007.0(90=+⨯-(吨标准煤).。
回归分析练习题及参考答案..讲课讲稿

求:(1)人均GDP 作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP 为5000元,预测其人均消费水平。
(7)求人均GDP 为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%人均GDP对人均消费的影响达到99.6%。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
模型摘要模型R R 方调整的R 方估计的标准差1 .998(a) 0.996 0.996 247.303a. 预测变量:(常量), 人均GDP(元)。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(5)F检验:回归系数的检验:t检验注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.99836.4920.000a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(6)某地区的人均GDP为5000元,预测其人均消费水平为734.6930.30950002278.693y=+⨯=(元)。
回归分析练习题(有标准答案)

回归分析练习题(有答案)作者:日期:1.1回归分析的基本思想及其初步应用一、选择题1.某同学由x 与y 之间的一组数据求得两个变量间的线性回归方程为均值为2,数据y 的平均值为3,则()A .回归直线必过点(2,3)C 点(2,3)在回归直线上方B.回归直线一定不过点(2,3)D 点(2,3)在回归直线下方y bx a ,已知:数据x 的平2.在一次试验中,测得(x, y)的四组值分别是A (1,2),B(2,3),C(3,4),D(4,5),则丫与X 之间的回归直线方程为()A.$x1B .$ x 2C$2x1D.$ x 13.在对两个变量x ,y 进行线性回归分析时,有下列步骤:①对所求出的回归直线方程作出解释;③求线性回归方程;④求未知参数;②收集数据(X j 、y i ),i 1,2,…,n ;⑤根据所搜集的数据绘制散点图)如果根据可行性要求能够作岀变量A.①②⑤③④Bx, y 具有线性相关结论,则在下列操作中正确的是(C.②④③①⑤D .②⑤④③①.③②④⑤①4.下列说法中正确的是()B人的知识与其年龄具有相关关系D 根据散点图求得的回归直线方程都是有意义的A.任何两个变量都具有相关关系C.散点图中的各点是分散的没有规律5.给出下列结论:2 2(1)在回归分析中,可用指数系数R 的值判断模型的拟合效果,R 越大,模型的拟合效果越好;(2)在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好;(3)在回归分析中,可用相关系数r 的值判断模型的拟合效果,较合适带状区域的宽度越窄,说明模型的拟合精度越高.A.y 平均增加1.5个单位B.A. 1B )个..2r 越小,模型的拟合效果越好;(4)在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域中,说明这样的模型比y 平均增加2个单位C.y 平均减少1.5个单位C.3DD.y 平均减少2个单位.4以上结论中,正确的有(6.已知直线回归方程为y7.2 1.5x ,则变量x 增加一个单位时()下面的各图中,散点图与相关系数r 不符合的是()\ 1V ||一1,— 1 < r<(>■r?■* ■■■■* ■..* .**打4X(7UV1)D.'8.一位母亲记录了儿子39岁的身高,由此建立的身高与年龄的回归直线方程为据此可以预测这个孩子10岁时的身高,则正确的叙述是(A.身高一定是145.83cm C.身高低于145.00cm BD)7.19x 73.93,.身高超过146.00cm身高在145.83cm左右9.(A)预报变量在x轴上,解释变量在y轴上(B)解释变量在x轴上,预报变量在y轴上(C)(D)在画两个变量的散点图时,下面哪个叙述是正确的()可以选择两个变量中任意一个变量在x轴上可以选择两个变量中任意一个变量在y轴上10.两个变量y与x的回归模型中,通常用R2来刻画回归的效果,则正确的叙述是(22)A.R越小,残差平方和小2B.R越大,残差平方和大2c.R于残差平方和无关D.R越小,残差平方和大211.两个变量y与x的回归模型中,分别选择了4个不同模型,它们的相关指数R2如下,其中拟合效果最好的模型是()A.模型1的相关指数R2为0.98 B.模型2的相关指数R2为0.802 2C.模型3的相关指数R为0.50 D.模型4的相关指数R为0.2512.回归直线上相应位置的差异的是A.总偏差平方和B.C.回归平方和13.回归直线方程为残差平方和D.相关指数R2在回归分析中,代表了数据点和它在()工人月工资(元)依劳动生产率(千元)变化的60 90x,下列判断正确的是()A.劳动生产率为1000元时,工资为50元B.劳动生产率提高1000元时,工资提高150元C.劳动生产率提高1000元时,工资提高90元D.劳动生产率为1000元时,工资为90元14.下列结论正确的是()①函数关系是一种确定性关系;②相关关系是一种非确定性关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法;④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法.A.①② E.①②③ C.①②④ D.①②③④15.已知回归直线的斜率的估计值为中心为(4,5),则回归直线方程为()1.23,样本点的A.$ 1.23x 4B.$ 1.23x 5C.$ 1.23x 0.08D.y 0.08x 1.2316.在比较两个模型的拟合效果时,甲、乙两个模型的相关指数果好的模型是 __________.17.在回归分析中残差的计算公式为 ____________.18.线性回归模型y bx a e(a和b为模型的未知参数)中,e称为_________________.19.若一组观测值(X1,yJ(X2,y2)…(Xn,y“)之间满足yi=bXi+a+e(i=1、2.…n)若恒为0,则氏为______________R2的值分别约为0.96和0.85,则拟合效20.调查某市出租车使用年限x 和该年支出维修费用y (万元),得到数据如下:使用年限x 维修费用y(求线性回归方程;n22.233.845.556. 567.0(2)由(1)中结论预测第10年所支出的维修费用.i 1(X i x) (y iy).n(X ii 1x)2bx21.以下是某地搜集到的新房屋的销售价格闵屋面积Ey 和房屋的面积x 的数据:11524.Q1102 1. CIB-413G29.21口丘22t 肖年愉梧(1)画岀数据对应的散点图;(2)求线性回归方程,并在散点图中加上回归直线;(3)据(2)的结果估计当房屋面积为150m2时的销售价格(4)求第2个点的残差。
回归分析题库

2013-2014学年度学校11月月考卷试卷副标题1.某工厂生产某种产品的产量x (吨)与相应的生产能耗y (吨标准煤)有如下几组样据相关性检验,这组样本数据具有线性相关关系,通过线性回归分析,求得其回归直线的斜率为0.7,则这组样本数据的回归直线方程是 A .y =0.7x +0.35 B .y =0.7x +1 C .y =0.7x +2.05 D .y =0.7x +0.45 【答案】A . 【解析】;即b +⨯=5.47.05.3,解得35.0=b ,即线性回归方程为0.70.35y x =+.考点:线性回归方程.2. 已知研究x 与y 之间关系的一组数据如下表所示,则y 对x 的回归直线方程a bx y+=ˆA .(2,2)B ..(1,2) D 【答案】D 【解析】试题分析:由题可知,y 对x 的回归直线方程a bx y +=ˆ必过定点由表格可知,,所以a bx y+=ˆ必过点 考点:线性回归方程的定义得到的回归方程为a bx y+=ˆ.若9.7=a ,则x 每增加1个单位,y 就( ). A .增加4.1个单位 B .减少4.1个单位C .增加2.1个单位D .减少2.1个单位 【答案】B 【解析】将其代入a bx y+=ˆ,解得,4.1ˆ-=b 得回归方程为,9.74.1ˆ+-=x y 则x 每增加1个单位,y 就减少4.1个单位. 考点:回归方程.93.7319.7ˆ+=x y,给出下列结论: ①y 与x 具有正的线性相关关系;②回归直线过样本的中心点(42,117.1);③儿子10岁时的身高是83.145cm ;④儿子年龄增加1周岁,身高约增加19.7cm. 其中,正确结论的个数是A.1B.2C. 3D. 4 【答案】B 【解析】试题分析:线性回归方程为ˆy=7.19x +73.93, ①7.19>0,即y 随x 的增大而增大,y 与x 具有正的线性相关关系,①正确;②回归直线过样本的中心点为(6,117.1),②错误;③当x=10时,ˆy=145.83,此为估计值,所以儿子10岁时的身高的估计值是145.83cm 而不一定是实际值,③错误;④回归方程的斜率为7.19,则儿子年龄增加1周岁,身高约增加7.19cm ,④正确, 故应选:B考点:回归分析的基本概念.5.已知变量x 与y 3 3.5,则 由该观测数据算得的线性回归方程可能是( )A .y =-2x +9.5B .y =2x -2.4C .y =-0.3x -4.4D .y =0.4x +2.3【答案】A 【解析】试题分析:因为变量x 与y 负相关,所以可以排除B 、D ,3 3.5,代入A 符合,C 不符合,故正确选项为A.考点:本题考查数据的回归直线方程,回归直线方程恒过样本点的中心.6.对两个变量y 和x 进行回归分析,得到一组样本数据:11(,)x y ,22(,)x y ,…,(,)n n x y ,则下列说法中不正确的是( )A .由样本数据得到的回归方程y bx a =+必过样本中心(,)x yB .残差平方和越小的模型,拟合的效果越好C .用相关指数R 2来刻画回归效果,R 2越小,说明模型的拟合效果越好D .若变量y 和x 之间的相关系数为0.9362r =-,则变量y 和x 之间具有线性相关关系【答案】C 【解析】试题分析:样本中心点(,)x y 一定在回归直线上,故A 正确;残差平方和越小的模型,拟合效果越好,故B 正确;2R 越大拟合效果越好,故C 错误. 考点:变量的相关关系.7.在一组样本数据),(,),,(),,(2211n n y x y x y x ),,,,221不全相等(n x x x n ≥的散点图中,若所有样本点),(i i y x ),,2,1(n i =都在直线131+=x y 上,则这组样本数据的样 本相关系数为( )A . 1-B .0C .1D .31 【答案】C 【解析】试题分析:散点图中所有样本点都在一条直线上说明两变量的相关性越强。
回归分析试题答案
诚信应考 考出水平 考出风格浙江大学城市学院2011 — 2012 学年第一学期期末考试卷《 回归分析 》开课单位: 计算分院 ;考试形式:开卷(A4纸一张);考试时间:2011年01月6日; 所需时间: 120 分钟一.计算题(10分。
)1,考虑过原点的线性回归模型1,1,2,...,i i i y x i n βε=+=误差1,...,n εε仍满足基本假定。
求1β的最小二乘估计。
并求出1β 的期望和方差,写出1β的分布。
1221111111121,1,2,...,ˆ()()2()0ˆi i i nni i i i i i ni i i i ni ii nii y x i n Q y yy x Qy x x x yxβεββββ======+==-=-∂=--=∂=∑∑∑∑∑解:第1页共 6 页二. 证明题(本大题共2小题,每小题7分,共14分。
)1,证明:(1)22()1var()[1]i i xxx x e n L σ-=--(2)2211ˆˆ()2n i ii y y n σ==--∑是2σ的无偏估计。
011111122ˆˆˆ()()1()()1var()var[()()]()1var()var((()))()12cov[,(())](1(i i i i i nn i i j j jj j xx ni i i j j j xx ni i j j j xx ni i j j j xxe y y y x x x x y y x x y n L x x e y x x y n L x x y x x y n L x x y x x y n L x n ββσσ======-=----=----=-+--=++---+-=++∑∑∑∑∑解(1):222122222221212211)()1())2()()()11(12()]()1[1]1ˆˆ(2)()(())21ˆ[()]2()111var()[1]2212n i i j j xx xxi i xx xxi xx ni i i ni i i n n i i i i xx x x x x x L n L x x x x n L n L x x n L E E y y n E y y n x x e n n n L n σσσσσ=====----+--=++-+-=--=--=---==----=-∑∑∑∑∑22(11)n σσ--=三.填空题.(每空2分,共46分)1.为了研究家庭收入和家庭消费的关系,通过调查得到数据如下:6.22893,29.12349,43008,97.29,5422=====∑∑∑xy yxy x1)用最小二乘估计求出线性回归方程的参数估计值0ˆβ= 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
测试题1.下列说法中错误的是()A.如果变量x与y之间存在着线性相关关系,则我们根据试验数据得到的点(i=1,2,3,…, n)将散布在一条直线附近B.如果两个变量x与y之间不存在线性相关关系,那么根据试验数据不能写出一个线性方程。
C.设x,y是具有线性相关关系的两个变量,且回归直线方程是,则叫回归系数D.为使求出的回归直线方程有意义,可用线性相关性检验的方法判断变量x与y之间是否存在线性相关关系2.在一次试验中,测得(x,y)的四组值分别是(1,2),(2,3),(3,4),(4,5),则y与 x之间的回归直线方程是()A.B. C.D.3.回归直线必过点()A.(0,0)B. C. D.4.在画两个变量的散点图时,下面叙述正确的是()A.预报变量在轴上,解释变量在轴上B.解释变量在轴上,预报变量在轴上C.可以选择两个变量中任意一个变量在轴上D.可以选择两个变量中任意一个变量在轴上5.两个变量相关性越强,相关系数r()A.越接近于0 B.越接近于1 C.越接近于-1 D.绝对值越接近16.若散点图中所有样本点都在一条直线上,解释变量与预报变量的相关系数为()A.0 B.1 C.-1 D.-1或17.一位母亲记录了她儿子3到9岁的身高,数据如下表:年龄(岁)3456789身高(94.8104.2108.7117.8124.3130.8139.0由此她建立了身高与年龄的回归模型,她用这个模型预测儿子10岁时的身高,则下面的叙述正确的是()A.她儿子10岁时的身高一定是145.83B.她儿子10岁时的身高在145.83以上C.她儿子10岁时的身高在145.83左右D.她儿子10岁时的身高在145.83以下8.两个变量有线性相关关系且正相关,则回归直线方程中,的系数()A.B.C.D.能力提升:9.一个工厂在某年每月产品的总成本y(万元)与该月产量x(万件)之间有如下数据:x 1.08 1.12 1.19 1.28 1.36 1.48 1.59 1.68 1.80 1.87 1.98 2.07 y 2.25 2.37 2.40 2.55 2.64 2.75 2.92 3.03 3.14 3.26 3.36 3.50(1)画出散点图;(2)求每月产品的总成本y与该月产量x之间的回归直线方程。
10.某工业部门进行一项研究,分析该部分的产量与生产费用之间的关系,从这个工业部门内随机抽选了10个企业作样本,有如下资料:产量x(千件)40424855657988100120140生产费用y(千元)150140160170150162185165190185(1)计算x与y的相关系数;(2)对这两个变量之间是否线性相关进行相关性检验;(3)设回归直线方程为,求系数,。
综合探究:11.一只红铃虫的产卵数y和温度x有关。
现收集了7对观测数据列于表中,试建立y与x之间的回归方程。
温度x/℃21232527293235产卵数y/个711212466115325参考答案:基础达标:1.B尽管两个变量x与y之间不存在线性相关关系,但是由试验数据仍可求出回归直线方程中的和,从而可写出一个回归直线方程。
2.A由回归直线经过样本点的中心,由题中所给出的数据,将,代入中适合,故选A。
3.D回归直线,必然经过样本点的中心,其坐标为,故选D。
4.B5.D6.B7.C8.A9.解析:(1)画出的散点图如图所示:(2),,,∴,。
所以所求回归直线方程为。
10.解析:(1)制表:1401501600225006000 2421401764196005880 3481602304256007680 4551703025289009350565150422522500975067916262412624412798788185774434225162808100165100002722516500912019014400361002280010140185196003422525900合计777165770903277119132938,,,,∴,即x与y的相关系数r≈0.808。
(2)因为,所以可以认为x与y之间具有很强的线性相关关系。
(3),。
综合探究:11.解析:散点图如图所示:由散点图可以看出:这些点分布在某一条指数函数的图象的周围。
现在,问题变为如何估计待定参数c1和c2,我们可以通过对数变换把指数关系变为线性关系。
令,则变换后样本点应该分布在直线(,)的周围。
这样,就可以利用线性回归模型来建立y和x之间的非线性回归方程了。
由题中所给数据经变换后得到如下的数据表及相应的散点图x21232527293235z 1.946 2.398 3.045 3.178 4.190 4.745 5.784由图可看出,变换后的样本点分布在一条直线的附近,因此可以用线性回归方程来拟合。
计算得,,,。
设所示的线性回归方程为,则有,,得到线性回归方程,因此红铃虫的产卵数对温度的非线性回归方程为。
总结升华:(1)在散点图中,样本点并没有分布在某个带状区域内,因此两个变量不呈线性相关关系,所以不能直接利用线性回归方程来建立两个变量之间的关系。
根据已有的函数知识,可以发现样本点分布在一条指数函数曲线的周围,其中c1和c2是待定参数。
(2)选择适当的非线性回归方程。
然后通过变量代换,将非线性回归方程化为线性回归方程,并由此来确定非线性回归方程中的未知参数。
(3)由散点图来挑选一种跟数据拟合得最好的函数时,往往有回归分析撰稿吕宝珠审稿谷丹责编:严春梅课程标准的要求(1)理解回归分析是对具有相关关系的两个变量进行统计分析的一种常用的方法;理解解释变量与预报变量的相关关系是一种非确定性关系;(2)能读或画出两个变量的散点图,并能根据散点图来粗略判断两个变量是否线性相关;(3)理解线性回归模型;(4)理解样本相关系数是衡量两个变量之间线性相关性强弱的参数的意义,了解样本相关系数的具体计算公式.(5)了解解释变量和随机变量的组合效应的含义及表示总的效应的参数:总偏差平方和;了解样本的数据点和它在回归直线上相应位置的残差是随机误差的效应的意义及随机误差的效应(即各个样本的各个点的随机误差的效应的平方和)的参数:残差平方和;了解表示解释变量效应的参数:回归平方和;了解刻画回归效果的相关指数的含义及计算公式。
(有关计算公式只要求了解含义,不须记忆下来,考试时会给出相关公式的).(6)了解残差分析的方法及意义,会读或会作残差图.重点和难点分析内容精讲1.相关关系:当自变量一定时,因变量的取值带有一定的随机性的两个变量之间的关系称为相关关系相关关系与函数关系的异同点如下:相同点:均是指两个变量的关系。
不同点:函数关系是一种确定的关系;而相关关系是一种非确定关系;函数关系是自变量与因变量之间的关系,这种关系是两个非随机变量的关系;而相关关系是非随机变量与随机变量的关系.2.回归分析:一元线性回归分析:对具有相关关系的两个变量进行统计分析的方法叫做回归分析。
通俗地讲,回归分析是寻找相关关系中非确定性关系的某种确定性。
对于线性回归分析,我们要注意以下几个方面:(1)回归分析是对具有相关关系的两个变量进行统计分析的方法。
两个变量具有相关关系是回归分析的前提。
(2)散点图是定义在具有相关系的两个变量基础上的,对于性质不明确的两组数据,可先作散点图,在图上看它们有无关系,关系的密切程度,然后再进行相关回归分析。
(3)求回归直线方程,首先应注意到,只有在散点图大至呈线性时,求出的回归直线方程才有实际意义,否则,求出的回归直线方程毫无意义。
3.散点图:表示具有相关关系的两个变量的一组数据的图形叫做散点图.散点图形象地反映了各对数据的密切程度。
粗略地看,散点分布具有一定的规律。
4. 回归直线设所求的直线方程为,其中a、b是待定系数.,,相应的直线叫做回归直线,对两个变量所进行的上述统计分析叫做回归分析。
5.相关系数:相关系数是因果统计学家皮尔逊提出的,对于变量y与x的一组观测值,把=叫做变量y与x之间的样本相关系数,简称相关系数,用它来衡量两个变量之间的线性相关程度.6.相关系数的性质:≤1,且越接近1,相关程度越大;且越接近0,相关程度越小.7.显著性水平:显著性水平是统计假设检验中的一个概念,它是公认的小概率事件的概率值。
它必须在每一次统计检验之前确定。
8.显著性检验:由显著性水平和自由度查表得出临界值,显著性水平一般取0.01和0.05,自由度为n-2,其中n是数据的个数在“相关系数检验的临界值表”查出与显著性水平0.05或0.01及自由度n-2(n为观测值组数)相应的相关数临界值r0.05或r0.01;例如n=7时,r0.05=0.754,r0.01=0.874 求得的相关系数r和临界值r0.05比较,若r>r0.05,上面y与x是线性相关的,当≤r0.05或r0.01,认为线性关系不显著。
典型例题:1.一个工厂在某年里每月产品的总成本y(万元)与该月产量x (万件)之间由如下一组数据:X 1.08 1.12 1.19 1.28 1.36 1.48 1.59 1.68 1.80 1.87 1.98 2.07Y 2.25 2.37 2.40 2.55 2.64 2.75 2.92 3.03 3.14 3.26 3.36 3.50 1)画出散点图;2)检验相关系数r的显著性水平;3)求月总成本y与月产量x之间的回归直线方程.解析:i123456789101112xi1.08 1.12 1.19 1.28 1.36 1.48 1.59 1.68 1.80 1.87 1.982.07yi2.25 2.37 2.40 2.55 2.64 2.75 2.923.03 3.14 3.26 3.36 3.50x i yi2.432.2642.8563.2643.5904.074.6435.0905.6526.0966.6537.245,,,,1)画出散点图:2)在“相关系数检验的临界值表”查出与显著性水平0.05及自由度12-2=10相应的相关数临界值=0.576<0.997891, 这说明每月产品的总成本y(万元)与该 r0.05月产量x(万件)之间存在线性相关关系。
3)设回归直线方程,利用,计算a,b,得b≈1.215, ,∴回归直线方程为:2.在7块并排、形状大小相同的试验田上进行施化肥量对水稻产量影响的试验,得数据如下(单位:kg)施化肥量x15202530354045水稻产量y330345365405445450455 1)画出散点图;2)检验相关系数r的显著性水平;3)求月总成本y与月产量x之间的回归直线方程。
解析:1)画出散点图如下:2)检验相关系数r 的显著性水平: i 1 2 3 4 5 6 7 x i 15 20 25 30 35 40 45 y i 330 345 365 405 445 450 455 x i y i49506950912512150155751800020475,,,,,在“相关系数检验的临界值表”查出与显著性水平0.05及自由度7-2=5相应的相关数临界值r 0.05=0.754<0.9733,这说明水稻产量与施化肥量之间存在线性相关关系。