北邮考研概率论与数理统计7.6(0-1)分布参数的区间估计(1)
概率论与数理统计 第7章.ppt

即 S 2是 2 的无偏估计,故通常取S 2作 2的估计量.
例3 设总体 X 服从参数为 的指数分布, 概率密度
x 1 e , f ( x; ) 0,
x 0, 其他.
其中参数 0, 又设 X 1 , X 2 ,, X n 是来自总体 X 的 样本, 试证 X 和 nZ n[min( X 1 , X 2 ,, X n )] 都是 的无偏估计.
行到其中有15只失效时结束试验, 测得失效时 间(小时)为115, 119, 131, 138, 142, 147, 148, 155,
158, 159, 163, 166, 167, 170, 172.
试求电池的平均寿命 的最大似然估计值 .
解
n 50, m 15,
s( t15 ) 115 119 170 172 (50 15) 172
总体 X 的 k 阶矩 k E ( X k )的相合估计量, 进而若待估参数 g( 1 , 2 ,, n ), 其中g 为连续 ˆ g( 函数, 则 的矩估计量 ˆ1 , ˆ 2 , , ˆ n ) g( A1 , A2 ,
, An ) 是 的相合估计量.
第三节
估计量的评选标准
一、问题的提出
二、无偏性 三、有效性 四、相合性 五、小结
一、问题的提出
从前一节可以看到, 对于同一个参数, 用不 同的估计方法求出的估计量可能不相同. 而且, 很明显, 原则上任何统计量都可以作为未知参数 的估计量. 问题 (1)对于同一个参数究竟采用哪一个估计量好? (2)评价估计量的标准是什么? 下面介绍几个常用标准.
如果不能得到完全样本, 就考虑截尾寿命试验.
3. 两种常见的截尾寿命试验
概率论与数理统计完整课件第七章参数估计PPT课件

n
L(1,2,,k ) L(x1, x2,, xk ;1,2,,k ) f (xi ;1,2,,k ) i 1
将其取对数,然后对1,2 ,,k 求偏导数,得
ln L(1, 2 ,, k ) 0 1
ln L(1, 2 ,, k ) 0 k
该 方 程 组 的 解 ˆi ˆi (x1, x2,, xn),i 1,2,,k ,即 为 i 的 极
§1 参数的点估计
设总体 X 的分布函数 F(x;) 形式已知,其中θ 是待估计的参数,点估计问题就是利用样本 (X1, X 2,, X n ) ,构造一个统计量ˆ ˆ(X1, X2,, Xn) 来估 计θ,我们称ˆ(X1, X2,, Xn )为θ的点估计量,它是 一个随机变量。将样本观测值 (x1, x2 ,, xn ) 代入估计 量 ˆ(X1, X2,, Xn ) , 就 得 到 它 的 一 个 具 体 数 值 ˆ(x1, x2,, xn ) ,这个数值称为θ的点估计值.
如果样本中白球数为0,则应估计p=1/4,而不估计 p=3/4.因为具有X=0的样本来自p=1/4的总体的 可能性比来自p=3/4的总体的可能性要大.一般当 X=0,1时,应估计p=1/4;而当X=2,3时,应估计 p=3/4.
第10页/共71页
定义:设总体 X 的分布类型已知,但含有未知参数θ. (1)设离散型总体 X 的概率分布律为 p(x; ) ,则样本 (X1, X2,, Xn ) 的联合分布律
~~ 2n1nLeabharlann ini1n1x(i xix
x
)
2
由微积分知识易验证以上所求为μ与σ2的极大似然 估计.
第21页/共71页
• 例:设总体X具有均匀分布,其概率密度函数为
p(x;)
北邮概率论与数理统计参数估计的评选标准 (7.3)

§7.3 估计量的评选标准由点估计提法可以看出,估计的概念相当广泛,并且用不同的估计方法往往会得出不同的估计.如果不对估计的好坏加以明确,估计是没有意义的.评价估计量的优劣并不简单,这首先需要明确衡量优良性的标准.这些标准不是唯一的,也不是绝对的.从不同角度出发可以提出不同的标准.下面我们讨论评价估计优劣的一些常用的标准. (一)均方误差同一参数的估计有多种,那么什么样的估计算是好的甚至是最好的?这就涉及优良性标准.从直观上看,估计量与被估计量越接近越好.当我们用)(ˆX θ估计θ时,评价该估计好坏的一个自然的度量是|)(ˆ|θθ-X ,但由于θ是未知的,样本又具有随机性,因而这种自然度量在实际中是不可行的,为了消除随机性的影响,可以考虑对它求平均|)(ˆ|θθ-X E ,出于数学处理上的方便,最常用的标准是由下式给出的均方误差.2))(ˆ()ˆ(θθθθ-=X E MSE 例7.3.1设n X X ,,1 为来自正态总体),(2σμN 的简单随机样本, (1) 若μ已知,考虑2σ的两个估计量:∑=---=n i i X n 1221)(11ˆμσ,∑=-=n i i X n 1220)(1ˆμσ, 求这两个估计量的均方误差,并比较它们的大小; (2)若μ未知,考虑2σ的两个估计量:∑=---=n i i X X n 1221)(11ˆσ,∑=-=n i i X X n 1220)(1ˆσ, 求这两个估计量的均方误差, 并比较它们的大小.解:(1)先求20ˆσ的均方误差,由于220)ˆ(σσ=E ,所以])([1)ˆ()ˆ(1222022∑=-==n i i X D n D M S E μσσσ, 又∑=-ni iX122)(1μσ~)(2n χ,故n XD ni i2])(1[122=-∑=μσ,即得4122])([σμn X D ni i =-∑=,从而知nMSE 4202)ˆ(2σσσ=,或])([1)ˆ()ˆ(1222022∑=-==ni i X D n D MSE μσσσ n X D nni i 41222)(1σμ=-=∑=, (这里用到了:若X ~),(2σμN ,则⎩⎨⎧-=-为奇数,为偶数,k k k X E k k0,!)!1()(σμ从而422)(σμ=-X D )再求21ˆ-σ的均方误差,}])({)1(1)ˆ(212222212∑=-+---=ni i n X E n MSE σσμσσ 424122)1(12}])([{)1(1σσμ-+=+--=∑=n n X D n ni i , 易见对任意的02>σ,总有>-)ˆ(212σσMSE )ˆ(202σσMSE , 思考题:考虑∑=-+=n i i kX k n 122)(1ˆμσ(k 为整数),计算)ˆ(22k MSE σσ并找出k 为何值时均方误差最小.(2)先求21ˆ-σ的均方误差,由于221)ˆ(σσ=-E ,所以 ])([)1(1)ˆ()ˆ(12221212∑=----==ni i X X D n D MSE σσσ又∑=-ni i X X122)(1σ~)1(2-n χ,故)1(2])(1[122-=-∑=n X XD ni iσ, 即得412)1(2])([σ-=-∑=n X X D ni i ,从而知12)ˆ(4212-=-n MSE σσσ,再求20ˆσ的均方误差,}])1()({1)ˆ(21222222∑=----=ni i n X X E n MSE σσσσ 42412212}])([{1σσn n X X D n ni i -=+-=∑=, 易见对任意的02>σ,总有>-)ˆ(212σσMSE )ˆ(202σσMSE . 思考题:考虑∑=-+=n i i kX X k n 122)(1ˆσ(k 为整数),计算)ˆ(22k MSE σσ并找出k 为何值时均方误差最小.(二) 无偏性均方误差可分解成两部分:2))(ˆ()ˆ(θθθθ-=X E MSE 2ˆˆ]-)(E [)(r Va θθθ+= 若偏差0ˆ==θθθ-)(E )b(,那么均方误差就等于方差.这样的估计量叫做无偏估计量.因此有如下义.定义 设θ为待估参数,参数空间为Θ,),,,(ˆˆ21nX X X θθ=为θ的估计量,若对于任意Θ∈θ,总有θθθ=)ˆ(E , 则称),,,(ˆˆ21n X X X θθ=为θ的无偏估计量,或者说),,,(ˆˆ21n X X X θθ=作为θ的估计量具有无偏性.又若0=∞→)b(lim n θ,称θˆ是θ的渐近无偏估计.例7.3.2 设总体X 的均值为μ,方差为2σ,n X X ,,1 是来自该总体的简单随机样本.则(i )样本均值X 为总体均值μ的无偏估计; (ii )样本均值2S 为总体均值2σ的无偏估计;思考题:样本标准差S 是否是总体标准差σ的无偏估计?如果不是,在正态模型下如何修改使之为无偏估计.例7.3.3 设n X X ,,1 是来自总体),(2σμN 的简单随机样本,求解下面问题(1)2σ的两个常用估计量∑=-=n i i nX X n S 122)(1,∑=--=n i i X X n S 122)(11中哪个是无偏估计?(2) 若22bS X a T +=为2μ的无偏估计,确定b a ,. 解:(1)略(2) 2222222)()1()()()(σμσσμna b a b n a S bE X aE T E ++=++=+=, 由无偏性定义知 对2,σμ∀,有 222)(μσμ=++na b a 从而得nb a 1,1-==。
北邮考研概率论与数理统计6.1随机样本(1)

数理统计学是一门关于数据收集、整理、分析和推断的科学。
第7页
第6章 样本及抽样分布
§6.1 总体与样本 §6.2 样本数据的整理与显示
§6.3 统计量及三大抽样分布
第8页
§6.1
总体与个体
总体的三层含义:
• 研究对象的全体; • 数据; • 分布
一个问题总有明确的研究对象和数量指标,对其做试验或观察.
2.若总体的密度函数为p(x),则其样本的(联 合)密度函数是什么?
第24页
由于是简单随机抽样. 根据定义得: 若 X1 , X 2 ,, X n 为 F 的一个样本,
则样本( X1, X 2 ,, X n )的联合分布函数为
F * ( x1 , x2 , , xn ) F ( xi ).
第14页
6.1.2 样本
样本的定义
为了了解总体的分布,我们从总体中随机地抽
取n个个体,记其指标值为 x1 , x2 ,, xn,则
x1 , x2 ,, xn 称为总体的一个样本,n 称为样本容
量,或简称样本量,样本中的个体称为样品。
样本具有两重性
第15页
• 一方面,由于样本是从总体中随机抽取的,抽 取前无法预知它们的数值,因此,样本是随机 变量,用大写字母 X1, X2, …, Xn 表示; • 另一方面,样本在抽取以后经观测就有确定的 观测值,因此,样本又是一组数值。此时用小 写字母 x1, x2, …, xn 表示是恰当的。 简单起见,无论是样本还是其观测值,样本一般 用 X1, … Xn 表示,应能从上下文中加以区别。
X P
0 1p
1 p
不同的p反映总体的差异。第一个工厂的产品质量优于第二个。
第12页 例2 在二十世纪七十年代后期,美国消费 者购买日产SONY彩电的热情高于购买美产 SONY彩电,原因何在? 原因在于总体的差异上!
北邮概率论与数理统计区间估计(7.4)

§7.4 区间估计参数的区间估计与参数的点估计一样,是参数估计的重要方法。
参数的点估计给出了一个具体值,但这个具体值不会是参数的精确值,而是一个近似值。
尽管近似的精度可以用均方误差给出评估,但我们还是无法知道估计值与真值相差多少。
区间估计在一定程度上解决了这个问题。
区间估计就是通过两个统计量及覆盖概率给出参数的另一种形式的估计。
当有样本值后,可以把未知参数估计在一定的范围内,并且可以给出这种估计的可信程度。
在某些具体问题中区间估计可能比点估计更具实用价值,并且区间估计还是度量点估计精度的最直观的方法。
因此区间估计是一种应用非常广泛的估计形式。
7.4.1 区间估计的概念设θ是未知参数,n x x x ,...,,21是样本,所谓区间估计就是要找两个统计量),...,,(ˆˆ21n L L x x x θ=θ和),...,,(ˆˆ21n U U x x x θ=θ,使得),...,,(ˆ21n L x x x θ),...,,(ˆ21n U x x x θ<,并构造一个随机区间)ˆ,ˆ(U L θθ,在有了样本值后把θ估计在区间)ˆ,ˆ(U L θθ内。
由于样本的随机性,随机区间)ˆ,ˆ(U L θθ覆盖θ有一定的概率,自然要求随机区间)ˆ,ˆ(U L θθ覆盖θ的概率)ˆˆ(UL P θθθ<<尽可能大,但这必然导致区间长度增大,而过长的区间又会导致给出的区间估计无意义。
为解决此矛盾,Neyman 建议采取一种折中方案:在使得覆盖θ的概率达到一定要求的前提下,寻找“精确度”尽量高的区间估计. 因此我们把)ˆ,ˆ(U L θθ覆盖θ的的概率事先指定,这就引入置信区间的概念。
定义 设θ是总体的一个参数,假设有两个统计量),...,,(ˆˆ21n L L x x x θ=θ和),...,,(ˆˆ21n U U x x x θ=θ,若对任意Θ∈θ,有 )ˆˆ(UL P θθθ<<α-≥1 则称随机区间),ˆ(U L θθ为θ的置信水平为α-1的置信区间,UL θθ,ˆ分别称为θ的置信水平为α-1的(双侧)置信下限和置信上限。
7.6 (0-1)分布参数的区间估计

补充例题
∑ X i − np i =1
n
nX − np = np(1 − p ) np(1 − p )
近似地服从 N ( 0,1) 分布, 于是有
nX − np P − zα / 2 < < zα / 2 ≈ 1 − α , np(1 − p )
而不等式 − zα / 2
nX − np < < zα / 2 np(1 − p )
2 2 (n + zα / 2 ) p2 − (2nX + zα / 2 ) p + nX 2 < 0, 等价于
记
p1 =
− b − b − 4ac , 2a 2a
2
− b + b2 − 4ac p2 = , 2a 2a
2 2 = n + zα / 2 , b = −( 2nX + zα / 2 ), c = nX 2 . 其中 a
平为1 − α 的置信区间 .
− b − b2 − 4ac − b + b2 − 4ac , , 2a 2a
2 2 其中 a = n + zα / 2 , b = −( 2nX + zα / 2 ), c = nX 2 .
推导过程 因为(0–1)分布的均值和方差分别为 分布的均值和方差分别为 因为 µ = p, σ 2 = p(1 − p), 因为容量n 较大, 设 X 1 , X 2 ,L, X n 是一个样本 , 因为容量 较大 由中心极限定理知 中心极限定理知
2 a = n + zα / 2= 103.84,
(完整版)(0-1)分布参数的区间估计
对给定的置信水平1 ,确定分位数t (n 1)
使
P{ X S
n
t (n 1)}
1
即
P{ X t (n 1)
S }1
n
于是得到 的置信水平为 1 的单侧置
信区间为
[ X t (n 1)
S , ] n
即 的置信水平为 1 的单侧置信下限为
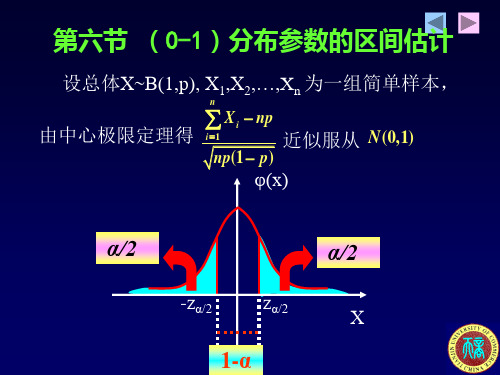
第六节 (0-1)分布参数的区间估计
设总体X~B(1,p), X1,X2,…,Xn 为一组简单样本,
n
由中心极限定理得
Xi np
i 1
近似服从
N (0, 1)
np(1 p)
φ(x)
α/2
α/2
-zα/2
zα/2
X
1-α
n
Xi np
故
P{ Z / 2
i 1
np(1
p)
P{ ˆ1} 1
则称区间 [ˆ1, )是 的置信水平为 1 的 单侧置信区间. ˆ1 称为单侧置信下限.
又若统计量 ˆ2 ˆ2( X1, X2, , Xn) 满足
P{ ˆ2 } 1
则称区间(,ˆ2 ]是 的置信水平为 1 的 单侧置信区间. ˆ2 称为单侧置信上限.
解 一级品率p是(0-1)分布的参数.
n 100, x 0.6, z /2 1.96
p的1-α置信区间: (0.5, 0.69)
第七节 单侧置信区间
设 是 一个待估参数,给定 0,
若由样本X1,X2,…Xn确定的统计量
ˆ1 ˆ1( X1, X2, , Xn) 满足
X t (n 1)
S n
将样本值代入得
理学概率论与数理统计参数估计区间估计

的分布,确定常数a, b,使得
P(a <U(T, )<b) = 1
5. 对“a<S(T, )<b”作等价变形,得到如下形式
即
于是
就是 的100(1)%的置信区间.
一、区间估计的基本概念
可见,确定区间估计很关键的是要寻找一个 待估参数 和估计量T 的函数U(T, ), 且U(T, ) 的分布为已知, 不依赖于任何未知参数 . 而这与总体分布有关,所以,总体分布的形式是 否已知,是怎样的类型,至关重要.
一、区间估计的基本概念
需要指出的是,给定样本,给定置信水平 , 置信区间也不是唯一的.
对同一个参数,我们可以构造许多置信区间.
1.在概率密度为单峰且对称的情形,当a =-b时 求得的置信区间的长度为最短.
2.即使在概率密度不对称的情形,如 2分布,
F分布,习惯上仍取对称的分位点来计算未知参数的 置信区间.
寻找一个待估参数和 统计量的函数 ,要求 其分布为已知.
寻找未知参 数的一个良 好估计.
有了分布,就可以求出 U取值于任意区间的概率.
一、区间估计的基本概念
对于给定的置信水平, 根据U的分布,确定一 个区间, 使得U取值于该区间的概率为置信水平.
对给定的置信水平 查正态分布表得
为什么 这样取?
使
一、区间估计的基本概念
参数估计
第四节 参数的区间估计
一、区间估计的基本概念
前面,我们讨论了参数点估计. 它是用样本算 得的一个值去估计未知参数. 但是,点估计值仅仅 是未知参数的一个近似值,它没有反映出这个近似 值的误差范围,使用起来把握不大. 区间估计正好 弥补了点估计的这个缺陷 .
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
解:此处n=120,x=36/120=0.3 而u0.975=1.96,于
是p的0.95(双侧)置信下限和上限分别为
pˆL 0.3 1.96
0.3 0.7 0.218 120
pˆU 0.3 1.96
0.3 0.7 0.382 120
故所求的置信区间为 [0.218,0.382]
置信区间长u1度 2 不n超过d0,只需要
即可,从而
u1 2
n d0
(6.5.12)
n
u1 d0
2
2
第13页
这是一类常见的寻求样本量的问题。比
如,若取d0=0.04, =0.05,则
。
n
u0.975 0.04
2
1.96 0.04
2
2401
这表明,要使综艺节目收视率p的0.95置 信区间的长度不超过0.04,则需要对 2401个用户作调查。
二、典型例题
第5页
例1 设从一大批产品的100个样品中, 得一级品60个,
求这批产品的一级品率 p 的置信水平为0.95的置信
区间.
解 一级品率 p 是(0-1)分布的参数,
n 100, x 60 0.6, 1 0.95,
100 z / 2 z0.025 1.96, 则a n z2 / 2 103.84,
b2 4ac 2a
0.143,
p 的置信水平为0.90的置信区间为 (0.056, 0.143).
第9页
附录
另外一种估计方法及例题。
第10页
设x1,…, xn是来自b(1, p)的样本,有 u
x p对给~&N定(0,1)
p(1 p) / n
,
P
p(x1, pp)通n 过 u1变 2 形 &1,可得到置信区间为
设 X1, X2, , Xn 是一个样本, 因为容量n 较大,
n
由中心极限定理知
Xi np
i 1
nX np
np(1 p) np(1 p)
近似地服从 N (0,1) 分布,
P z / 2
nX np np(1 p)
z
/
2
1
,
第4页
不等式 z / 2
nX np p2 (2nX z2 / 2 ) p nX 2 0,
令
p1 b
b2 4ac , 2a
p2 b
b2 4ac , 2a
其中a n z2 / 2 , b (2nX z2 / 2 ), c nX 2 .
则 p的近似置信水平为1 的置信区间是 ( p1, p2 ).
第12页
例 某传媒公司欲调查电视台某综艺节目收视
率p,为使得 p 的1-置信区间长度不超过
d0,问应调查多少用户?
解:这是关于二点分布比例p的置信区间问题,由(6.5.11)
知,1-的置信区间长度为2u1 2 x 1这 x是 n一个随机变量,
但由于 ,x所以0对,1任 意的观测值有
。这也就
是说x(1p的x)1-0.的52 置 0信.25区间长度不会超过 。现要求p的的
第1页
7.6 大样本置信区间
在样本容量充分大(n>50)时,可以用渐近分布 来构造近似的置信区间。
一个典型的例子是关于比例p 的置信区间。
( 0 1) 分布参数的近似置信区间
一、置信区间公式 二、典型例题
一、置信区间公式
第2页
设有一容量n 50的大样本, 它来自(0 1)分布 的总体 X , X 的分布律为 f ( x; p) px (1 p)1x ,
其1 中1n记 x =2n u21x-(1/2n,x )实 用4n22中, 通1 1常n 略x 去2n /n项x(1,n x于) 是4n可22
将置信区间近似为
x u 2
x (1 x ) , n
x u 2
x (1 x )
n
第11页
例 对某事件A作120次观察,A发生36次。试给
解 n 120, x 9 0.09, 1 0.90,
100 则 a n z2 2 122.71,
b (2n X z2 2 ) (2nx z2 2 ) 24.31,
c n X 2 nx2 0.972,
第8页
于是 p1 b
b2 4ac 2a
0.056,
p2 b
第6页
b (2nX z2 / 2 ) (2nx z2 / 2 ) 123.84,
c nX 2 nx2 36,
于是 p1 b
b2 4ac 0.50, 2a
p2 b
b2 4ac 0.69,
2a
p 的置信水平为0.95的置信区间为 (0.50, 0.69).
第7页
例2设从一大批产品的120个样品中, 得次品9个, 求 这批产品的次品率 p 的置信水平为0.90的置信区间.
x 0, 1, 其中p为未知参数, 则 p的置信度为1 的
置信区间是
b
b2 4ac , 2a
b
b2 2a
4ac
,
其中a n z2 / 2 , b (2nX z2 / 2 ), c nX 2 .
推导过程如下:
第3页
因为(0–1)分布的均值和方差分别为
p, 2 p(1 p),