2020年(工作分析)NC工作流程及文件格式详细分析
nc程序讲解

nc程序讲解
NC程序是数控机床上的一种控制程序,用于指导机床按照预定的路径和速度来加工工件。
下面是对NC程序的一些讲解:
1. 基本结构:NC程序由一系列代码组成,每个代码代表一条指令。
代码由字母和数字组成,用于指示机床的运动、速度、切削参数等。
2. G代码:G代码是NC程序中常用的指令,用于控制机床的运动。
例如,G01表示直线插补,G02表示顺时针圆弧插补,G03表示逆时针圆弧插补。
3. M代码:M代码也是NC程序中常用的指令,用于控制机床的辅助功能,如切削液开关、主轴开关等。
例如,M03表示主轴正转,M08表示冷却液打开。
4. X、Y、Z轴:X、Y、Z轴是机床常用的三个坐标轴,用于确定工件在空间中的位置。
NC程序中的指令可以通过改变这些轴的数值来控制机床的运动。
5. F速度:F速度是NC程序中用于控制机床进给速度的参数,单位通常是毫米/分钟或英寸/分钟。
较大的F值表示机床运动更快,而较小的F值表示机床运动更慢。
6. 变量:NC程序中可以使用变量来存储和调用数值。
例如,使用变量来指定切削深度或加工轨迹中的半径。
这样可以方便地修改和调整程序。
7. 循环:NC程序中可以使用循环来重复执行一段代码。
这样可
以减少重复的工作,并提高工作效率。
循环可以根据不同的条件进行控制,例如根据计数器的值或输入信号的状态。
总体来说,NC程序是编程语言中的一种特殊形式,用于指导数控机床的运动和加工工件。
通过合理编写和调整NC程序,可以实现高效、精确的加工过程。
[新版文件]2020年岗位分析及其步骤与程序
![[新版文件]2020年岗位分析及其步骤与程序](https://img.taocdn.com/s3/m/d63bf45ced630b1c58eeb547.png)
岗位分析及其步骤与程序岗位分析岗位分析,顾名思义是指对某单位的全部工作的各构成因素进行分析研究,并将其结果制作成工作说明书和岗位责任制的过程。
岗位分析涉及对岗位内容进行系统的审查,以明确任务的性质,工作条件,必要的责任和所需要的技能。
它包括:岗位名称分析,定员变动分析,工作规范分析,工作人员的必备条件分析等工作内容。
岗位分析的步骤一、确定工作岗位岗位分析首先要收集和研究有关工作机构的一般情况,确定每一工作岗位在其组织机构中的位置。
为此,分析人员通常从组织结构或可能的组织工作程序图入手调查,工作程序图可以帮助分析人员了解工作过程。
不过,依靠工作程序图或组织结构图确定工作岗位之间的职能关系和明确各项任务的目的,经常可能是不完全的。
因而还需要有其它一些资料的补充。
包括操作和培训手册,人员补充规定(一般应说明工作的要求),其它有关的规则或领导的要求,当然,还有工作说明书。
二、工作岗位情况的搜集在首先确定工作岗位之后,应开始研究每一工作岗位的情况,并将其本质内容记录下来。
为了保证对所有工作岗位情况能进行系统地搜集,需要准备规范的工作岗位分析表格,其中包括一些精心选择的有关问题。
这种表格不一定重新设计,可根据确定的工作岗位测评计划,对原来有关企业各种情况的规范表格进行修改后使用。
工作岗位的特征通常包括工作人员做什么,怎样做和为什么做,工作条件如何,资格条件的要求是什么等几个基本内容。
为此,分析人员在调查中通常要了解下列基本工作要素。
(一)工作岗位1、谁做这工作,工作名称是什么?2、工作的基本任务是什么?3、怎样完成任务,使用什么设备?4、为什么执行这些任务,工作中各项任务同其他工作任务之间的关系是什么?5、任职人员对同事,设备负有责任是什么?6、工作条件(工作时间、噪音、气温、光线等)如何?(二)圆满完成工作所要求的资格条件1、知识。
2、技能,包括经验3、受教育水平。
4、身体条件5、智力水平6、能力(创造能力和应变能力)三、将调查所得的信息加以筛选,由工作说明书给予准确、清楚和完整的记录。
nc文件格式标准

nc文件格式标准NC文件格式标准是一种通用的数控程序文件格式。
它包含数控刀具路径,加工参数信息以及控制码等内容。
NC文件格式标准是数控系统中使用的主要文件格式之一,它对数控机床的数控加工过程至关重要。
在本文中,我们将通过几个步骤来阐述NC文件格式标准。
第一步:了解NC文件格式标准NC文件格式标准是由美国机器工程师协会(AGMA)制定的一种标准。
其设计目的是为了保证数控机床的通用性和互操作性。
NC文件格式标准主要由以下几个部分组成:1.文件头:文件头包含文件版本信息,机器参数,工件参数等信息。
2.加工方案:加工方案定义工件的加工数据。
3.刀具信息:刀具信息包括刀具型号、刃数、长度和直径等信息。
4.控制码:控制码包含数控加工中的程序控制语句和系统控制语句。
第二步:使用NC文件格式标准NC文件格式标准已被广泛应用于数控机床的编程和操作。
使用NC文件格式标准可以将加工参数和程序信息传输到数控系统中,以便数控系统按照程序指令来控制机器的运动。
NC文件格式标准是数控机床开发和制造过程中的核心要素之一。
第三步:NC文件格式标准的进一步应用除了数控机床的编程和操作,NC文件格式标准还可以应用于多种问题中。
例如:1.数控加工仿真和验证:NC文件格式标准可用于数控加工仿真和验证,可通过仿真和验证来提高制造过程的效率和精度。
2.工艺规划和优化:NC文件格式标准可以帮助工程师确定加工方案,以优化加工效率和质量。
3.产品开发和生产:NC文件格式标准可以用于产品设计和制造的过程中,从而提高产品的一致性和质量。
总结NC文件格式标准是数控机床编程和操作中的核心要素。
了解NC 文件格式标准可以让数控机床编程人员更好地控制数控加工过程中的程序和参数。
在未来,NC文件格式标准还将应用于更多领域,帮助制造业更好地实现数字化转型。
工作分析具体步骤与说明

工作分析具体步骤与说明1. 引言工作分析是一种通过系统地收集、分析和描述工作内容、工作环境、工作要求和工作特征的方法,用于揭示工作岗位的本质和特点,为组织制定有效的人力资源管理策略提供依据。
本文将介绍工作分析的具体步骤和说明,以帮助读者了解和应用这个重要的人力资源管理工具。
2. 工作分析的步骤工作分析过程主要包括以下几个步骤:2.1 目标设定在进行工作分析之前,需要明确分析的目标是什么。
目标设定应包括确定分析的岗位或职位、确定分析的范围和内容、确定分析的时间和资源限制等。
2.2 收集信息收集信息是工作分析中非常重要的一步,主要包括以下几个方面的内容:•工作任务:收集关于岗位的具体任务描述,包括每天需要完成的具体工作,工作内容的复杂程度以及特殊要求等。
•工作环境:收集工作岗位所处的环境因素,包括物理环境(如工作场所、设备等)和社会环境(如团队合作、工作压力等)。
•工作要求:收集工作对员工的要求,包括技能、知识、经验、资格等方面。
•工作特征:收集工作的特点和特性,如决策权、责任范围、工作自主性等。
2.3 数据分析和整理在收集到信息之后,需要对数据进行分析和整理,以形成可供分析和理解的数据结果。
可以使用表格、图表、文字描述等形式进行呈现。
2.4 数据验证在数据分析和整理完成后,需要进行数据的验证,以保证数据的准确性和可信度。
可以采用访谈、观察、问卷调查等方法与工作相关人员进行沟通,核实数据的准确性。
2.5 结果产出根据数据分析和验证的结果,生成工作分析报告或其他形式的结果产出,以便于后续的人力资源管理和决策过程。
3. 工作分析的说明工作分析是为组织提供有效的人力资源管理工具和决策依据的重要方法。
以下是工作分析的一些重要说明:•精确度和可靠度:工作分析的结果应具有高度的精确度和可靠度,因为这些结果会直接影响到后续的人力资源管理决策和操作。
•持续性和适应性:工作分析是一个持续的过程,因为工作内容、环境、要求和特征都可能随着时间的推移而发生变化。
nc系统使用工作总结

nc系统使用工作总结
NC系统使用工作总结。
NC系统是数控系统的简称,它是一种通过计算机控制机床和其他工业设备的
自动化系统。
在现代制造业中,NC系统已经成为生产过程中不可或缺的一部分。
作为一名NC系统操作员,我在过去的一段时间里积累了一些使用经验,现在我想
把这些经验总结成一篇文章,与大家分享。
首先,我要强调的是对NC系统的基本操作和维护。
在使用NC系统时,我们
需要熟悉各种控制按钮和指令,了解每个功能的作用和使用方法。
此外,定期对
NC系统进行维护和保养也是非常重要的,这样可以确保系统的稳定性和可靠性。
其次,我想谈谈在实际工作中遇到的一些常见问题及解决方法。
在操作NC系
统时,有时会遇到程序错误、设备故障等情况,这就需要我们有一定的技术水平和经验来及时解决。
通过不断的学习和实践,我逐渐积累了一些应对这些问题的方法,比如检查程序错误、调整设备参数等。
另外,我还想分享一些提高工作效率的经验。
在使用NC系统时,我们可以通
过合理的工艺规划、优化程序编写等方式来提高工作效率。
同时,及时记录和总结工作中的经验和教训,也是提高工作效率的关键。
总的来说,NC系统的使用工作需要我们不断学习和积累经验,只有这样才能
更好地应对各种工作挑战。
我相信,通过不断的努力和实践,我会在NC系统的使
用工作中取得更好的成绩。
希望我的经验总结能够对大家有所帮助。
NC数控程序文档流程管理

NC数控程序文档流程管理NC数控程序文档流程管理是指对数控程序文档进行全面管理,包括创建、审查、修改、发布和存档等环节,以确保数控程序的质量和安全性。
下面是一个包括创建、审查、修改、发布和存档等环节的NC数控程序文档流程管理的详细介绍。
一、创建阶段:1.了解需求:在创建NC数控程序文档之前,首先要与相关部门或人员进行沟通,明确数控程序的需求和要求,包括数控设备的类型、工件的材料和形状、加工工艺等方面的要求。
2.设计NC程序:根据需求,进行数控程序的设计,包括加工路径、加工刀具、切削参数等方面的内容。
同时,要确保程序的合理性和准确性。
3.编写NC代码:根据设计好的NC程序,编写对应的NC代码。
在编写过程中,要严格按照数控编程规范进行,包括代码的格式、注释的添加、英寸和公制长度单位的转换等。
4.验证和调试:在编写完NC代码后,要进行验证和调试,以确保程序的正确性和可靠性。
可以通过模拟器进行验证,通过实际机床进行调试。
二、审查阶段:1.内部审查:由专业的数控工程师对NC程序进行内部审查,主要包括代码的正确性、加工路径的合理性、切削参数的正确性等方面的审查。
审查结果要进行记录,包括审查意见和建议。
2.客户审查:将程序提交给客户进行审查,客户可以对程序进行审查和修改。
客户审查的结果要进行记录,包括审查意见和建议。
三、修改阶段:1.根据内部审查和客户审查的意见,对NC程序进行修改。
修改时要注意保持程序的完整性和可读性,并且要对修改部分进行注释,以方便后期的维护和修改。
2.修改后的程序要进行全面测试,以确保修改的正确性和可靠性。
四、发布阶段:1.最终编译:对修改后的程序进行最终编译和生成机床可执行的程序文件。
编译时要注意选择正确的机床控制器和机床型号,以确保生成的程序文件与实际机床相匹配。
2.发布和分发:将最终生成的程序文件发布和分发给相关人员,包括操作工、现场维护人员等。
发布时要注明程序的版本信息和相关说明。
nc文件的读取解析

nc文件的读取解析NC文件格式简介NC(Numerical Control)文件是一种用于数控机床的文本文件格式,它存储了机床执行的指令。
NC文件包含一系列代码,这些代码指定了机床的运动、速度和工具操作。
NC文件的结构一个典型的NC文件包含以下主要部分:头段:指定文件版本、机床类型和其他一般信息。
程序段:包含机床执行的实际指令。
注释段:包含非指令性信息,例如注释或操作员说明。
NC指令NC指令使用G代码和M代码指定机床动作。
G代码:控制机床的运动,例如G00(快速移动)、G01(线性插补)和G02(圆弧插补)。
M代码:控制机床的其他功能,例如M03(主轴开启)、M05(主轴停止)和M06(刀具更换)。
解析NC文件解析NC文件涉及将文本指令转换为机床可以理解的内部表示。
此过程通常使用称为NC解析器的软件组件来完成。
NC解析步骤NC解析通常涉及以下步骤:词法分析:将NC文件分成符号(令牌),例如关键字和数字值。
语法分析:检查令牌并验证它们是否符合NC语法的规则。
语义分析:将令牌解释为机床指令。
代码生成:将机床指令转换为可执行的内部表示。
工具和库用于解析NC文件的工具和库包括:CNCjs:一个开源JavaScript库,用于解析和生成NC代码。
nc-parser:一个Python库,用于解析和编辑NC文件。
G-code Ripper:一个在线工具,用于可视化和解析NC代码。
最佳实践解析NC文件时,遵循以下最佳实践可以确保准确性和可靠性:使用经过测试和维护的解析器。
对输入的NC文件进行彻底验证。
在执行指令之前进行模拟,以验证机床的预期行为。
记录解析和执行过程,以便进行故障排除和审核。
NC操作方法及流程
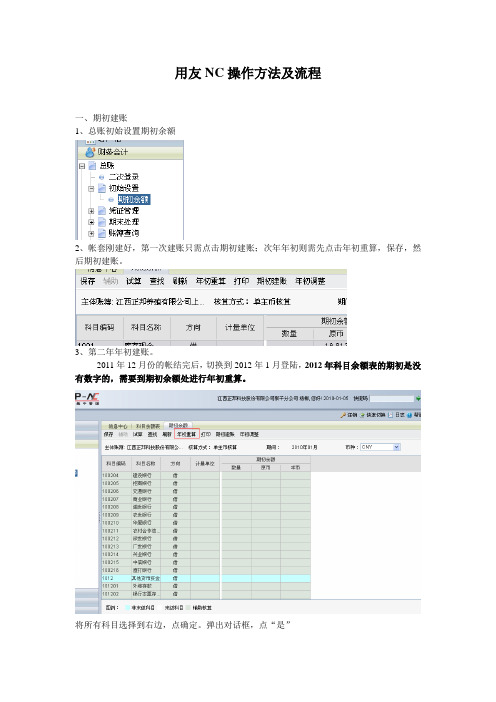
用友NC操作方法及流程一、期初建账1、总账初始设置期初余额2、帐套刚建好,第一次建账只需点击期初建账;次年年初则需先点击年初重算,保存,然后期初建账。
3、第二年年初建账。
2011年12月份的帐结完后,切换到2012年1月登陆,2012年科目余额表的期初是没有数字的,需要到期初余额处进行年初重算。
将所有科目选择到右边,点确定。
弹出对话框,点“是”然后试算看下是否平衡,平衡后点:期初建账,一直“下一步”到“建账”完成为止。
2012年期初余额就会自动转过来、以上图示是以2010年年初建账为例。
二、报账中心1、设置审批流客户化→流程配置→审批流定义→应收应付报账中心1)差旅费报销单增加→选择HR人员或角色→工具箱→分别选取开始、转移、虚活动、结束→按经营授权表设置比如出纳的审批流为:2)费用报销单(审批流定义同上)2、单据录入财务管理→报账中心→日常业务→单据处理→单据录入选择单据类型1)费用报销单增加→增行根据实际业务要求填写2)差旅费报销单(操作方法同上)3、单据管理该节点可修改、查询已保存或暂存的单据1)查询双击打开单据管理节点,进入单据管理界面,如图:点击查询,弹出如下对话框:选择需要查询单据的条件,点击确定,进入查询后界面:2)修改双击需要修改的单据,进入单据操作界面,如下:选择单据操作里面的修改,进行编辑,然后保存。
3)审核4、签字确认5、凭证生成三、总账1、制单打开财务会计→总账→凭证管理→制单节点,如图:双击打开,进入如下界面:点击增加,进入按照单据填写摘要,并编制会计分录;如为现金或银行存款业务,还需定义现金流量。
2、审核打开财务会计→总账→凭证管理→审核节点,进入如下界面:点击查询,输入需要审核的单据的条件,如图所示:然后确定,进入查询后界面:选中需要审核的单据,点击审核。
3、记账同审核。
4、结账5、打开财务会计→总账→期末处理→结账节点,进入如下界面:连续点击下一步,出现以下界面:点击结账,确定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Nutch Crawler工作流程及文件格式详细分析Crawler和Searcher两部分被尽是分开,其主要目的是为了使两个部分可以布地配置在硬件平台上,例如Crawler和Searcher分别被放置在两个主机上,这样可以极大的提高灵活性和性能。
一、总体介绍:1、先注入种子urls到crawldb2、循环:•generate 从crawldb中生成一个url的子集用于抓取•fetch 抓取上一小的url生成一个个segment•parse 分析已抓取segment的内容•update 把已抓取的数据更新到原先的crawldb3、从已抓取的segments中分析出link地图4、索引segment文本及inlink锚文本二、相关的数据结构:Crawl DB● CrawlDb 是一个包含如下结构数据的文件:<URL, CrawlDatum>● CrawlDatum:<status, date, interval, failures, linkCount, ...>● Status:{db_unfetched, db_fetched, db_gone,linked,fetch_success, fetch_fail, fetch_gone}爬虫Crawler:Crawler的工作流程包括了整个nutch的所有步骤--injector,generator,fetcher,parseSegment, updateCrawleDB,Invert links,Index ,DeleteDuplicates, IndexMergerCrawler涉及的数据文件和格式和含义,和以上的各个步骤相关的文件分别被存放在物理设备上的以下几个文件夹里,crawldb,segments,indexes,linkdb,index五个文件夹里。
那么各个步骤和流程是怎么,各个文件夹里又是放着什么呢?观察Crawler类可以知道它的流程./nutch crawl urls -dir ~/crawl -depth 4 -threads 10 -topN 20001、Injector injector = new Injector(conf);Usage: Injector <crawldb> <url_dir>首先是建立起始url集,每个url都经过URLNormalizers、filter和scoreFilter三个过程并标记状态。
首先经过normalizer plugin,把url进行标准化,比如basic nomalizer的作用有把大写的url标准化为小写,把空格去除等等。
然后再经过的plugin 是filter,可以根据你写的正则表达式把想要的url留下来。
经过两个步骤后,然后就是把这个url进行状态标记,每个url都对应着一个 CrawlDatum,这个类对应着每个url在所有生命周期内的一切状态。
细节上还有这个url处理的时间和初始时的分值。
同时,在这个步骤里,会在文件系统里生成如下文件crawlDB\current\part-00000 这个文件夹里还有.data.crc , .index.crc, data, index四个文件● MapReduce1: 把输入的文件转换成DB格式In: 包含urls的文本文件Map(l ine) → <url, CrawlDatum>; status=db_unfetchedReduce() is identity;Output: 临时的输出文件夹● MapReduce2: 合并到现有的DBInput: 第一步的输出和已存在的DB文件Map() is identity.Reduce: 合并CrawlDatum成一个实体(entry)Out: 一个新的DB2、Generator generator = new Generator(conf);//Generates a subset of a crawl db to fetchUsage: Generator <crawldb> <segments_dir> [-force] [-topN N][-numFetchers numFetchers] [-adddays numDays] [-noFilter]在这个步骤里,Generator一共做了四件事情,1、给前面injector完成的输出结果里按分值选出前topN个url,作为一个fetch 的子集。
2、根据第一步的结果检查是否已经选取出一些url,CrawlDatum的实体集。
3、再次转化,此次要以url的host来分组,并以url的hash来排序。
4、根据以上的步骤的结果来更新crawldb(injector产生)。
● MapReduce1: 根据要求选取一些要抓取的urlIn: Crawl DB 文件Map() → if date≥now, invert to <CrawlDatum, url>Partition 以随机的hash值来分组Reduce:compare() 以 CrawlDatum.linkCount的降序排列output only top-N most-linked entries● MapReduce2: 为下一步抓取准备Map() is invert; Partition() by host, Reduce() is identity.Out: 包含<url,CrawlDatum> 要并行抓取的文件3、 Fetcher fetcher = new Fetcher(conf);//The fetcher. Most of the work is done by pluginsUsage: Fetcher <segment> [-threads n] [-noParsing]这个步骤里,Fetcher所做的事情主要就是抓取了,同时也完成一些其它的工作。
首先,这是一个多线程的步骤,默认以10个线程去抓取。
根据抓取回来后的结果状态来进行不同的标记,存储,再处理等等行为。
输入是上一步骤Generator产生的segment文件夹,这个步骤里,考虑到先前已经按照ip 或host来patition了,所以在此就不再把input文件进行分割了。
程序继承了SequenceFileInputFormat重写了 inputFormat来达到这点。
这个类的各种形为都是插件来具体完成的,它只是一个骨架一样为各种插件提供一个平台。
它先根据url来取出具体的 protocol,得到protocolOutput,进而得到状态status 及内容content。
然后,根据抓取的状态status来继续再处理。
再处理时,首先会将这次抓取的内容content、状态status及它的状态标记进行存储。
这个存储的过程中,还会记下抓取的时间,再把segment 存过metadata,同时在分析parsing前经过scoreFilter,再用parseUtil(一系列的parse插件)进行分析,分析后再经过一次score插件的处理。
经过这一系列处理后,最后进行输出(url,fetcherOutput)。
之前讲到根据抓取回来的各种状态,进行再处理,这些状态一共包括12种,比如当抓取成功时,会像上刚讲的那样先存储结果,再判断是否是链接跳转,跳转的次数等等处理。
● MapReduce:抓取In: <url,CrawlDatum>, 以host分区, 以hash值排序Map(url,CrawlDatum) → <url, FetcherOutput>多线程的, 同步的map实现调用已有的协议protocol插件FetcherOutput: <CrawlDatum, Content>Reduce is identityOut: 两个文件: <url,CrawlDatum>, <url,Content>4、 ParseSegment parseSegment = new ParseSegment(conf);//Parse content in a segmentUsage: ParseSegment segment对于这个步骤的逻辑比较简单,只是对抓取后上一步骤存储在segment里的content进行分析parse。
同样,这个步骤的具体工作也是由插件来完成的。
MapReduce: 分析内容In: <url, Content> 抓取来的内容Map(url, Content) → <url, Parse>调用分析插件parser pluginsReduce is identity.Parse: <ParseText, ParseData>Out: 分割成三个文件: <url,ParseText>, <url,ParseData> 和<url,CrawlDatum> 为了outlinks.5、CrawlDb crawlDbTool = new CrawlDb(conf);//takes the output of the fetcher and updates the crawldb accordingly.Usage: CrawlDb <crawldb> (-dir <segments> | <seg1> <seg2> ...) [-force] [-normalize] [-filter] [-noAdditions]这个类主要是根据fetcher的输出去更新crawldb。
map和reduce分别做了两方面的事情,在map里是对url的nomalizer,和filte,在reduce里是对新抓取进来的页面(CrawlDatum)和原先已经存在的进行合并。
MapReduce:合并抓取的和分析后的输出到crawldb里In: <url,CrawlDatum>现有的db加上抓取后的和分析后的输出Map() is identityReduce() 合并所有实体(entry)成一个,以抓取后的状态覆盖原先的db状态信息,统计出分析后的链接数Out: 新的crawl db6.LinkDb linkDbTool = new LinkDb(conf);//Maintains an inverted link map, listing incoming links for each url.Usage: LinkDb <linkdb> (-dir <segmentsDir> | <seg1> <seg2> ...) [-force] [-noNormalize] [-noFilter]这个类的作用是管理新转化进来的链接映射,并列出每个url的外部链接(incoming links)。