链表习题高考真题
C程序设计(链表)习题与答案

一、单选题1、链表不具有的特点是()。
A.不必事先估计存储空间B.插入、删除不需要移动元素C.可随机访问任一元素D.所需空间与线性表长度成正比正确答案:C2、链接存储的存储结构所占存储空间()。
A.分两部分,一部分存放结点值,另一部分存放结点所占单元数B.只有一部分,存放结点值C.分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针D.只有一部分,存储表示结点间关系的指针正确答案:C3、链表是一种采用()存储结构存储的线性表。
A.网状B.星式C.链式D.顺序正确答案:C4、有以下结构体说明和变量的定义,且指针p指向变量a,指针q指向变量b,则不能把结点b连接到结点a之后的语句是()。
struct node {char data;struct node *next;} a,b,*p=&a,*q=&b;A.(*p).next=q;B.p.next=&b;C.a.next=q;D.p->next=&b;正确答案:B5、下面程序执行后的输出结果是()。
#include <stdio.h>#include <stdlib.h>struct NODE {int num; struct NODE *next;};int main(){ struct NODE *p,*q,*r;p=(struct NODE*)malloc(sizeof(struct NODE));q=(struct NODE*)malloc(sizeof(struct NODE));r=(struct NODE*)malloc(sizeof(struct NODE));p->num=10; q->num=20; r->num=30;p->next=q;q->next=r;printf("%d",p->num+q->next->num);return 0;}A.30B.40C.10D.20正确答案:B6、下面程序执行后的输出结果是()。
第08章指针和链表真题
历年真题(指针)一、2003年1月10.以下定义语句中,错误的是(A ) int a{}={1,2}; (B ) char *a[3];(C ) char s[10]=”text ”; (D ) int n=5,a[n];14.下列语句执行后的结果是 。
y=5;p=&y;x=*p++;(A )x=5,y=5 (B )x=5,y=6(C )x=6,y=5 (D )x=6,y=615. 执行下面的语句后,表达式*(p[0]+1)+**(q+2)的值为 。
int a[]={5,4,3,2,1};*p[]={a+3,a+2,a+1,a};**q=p;(A )8 (B )7 (C )6 (D )516. 经过下面的语句int I,a[10],*p;定义后,下列语句中合法的是 。
(A )p=100; (B )p=a[5];(C )p=a+2; (D )p=&(i+2);29. 有如下程序main(){ char ch[2][5]={“6937”, “8254”},*p[2];int i,j,s=0;for(i=0;i<2;i++) p[i]=ch[i];for(i=0;i<2;i++)for(j=0;p[i][j]>‟0‟;j+=2)s=10*s+p[i][j]-…0‟;printf(“%d\n ”,s);}该程序的输出结果是 。
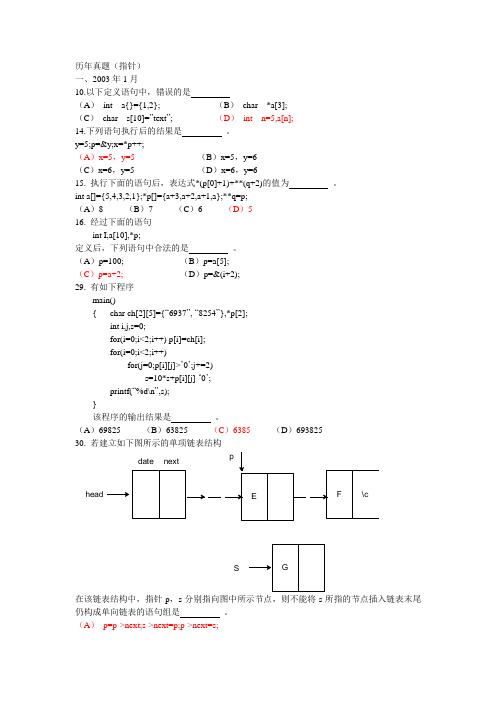
(A )69825 (B )63825 (C )6385 (D )69382530. 若建立如下图所示的单项链表结构date nextheadS在该链表结构中,指针p ,s 分别指向图中所示节点,则不能将s 所指的节点插入链表末尾仍构成单向链表的语句组是 。
(A ) p=p->next;s->next=p;p->next=s;(B)p=p->next;s->next=p->next;p->next=s;(C)s->next=NULL;p =p->next;p->next=s;(D)p=(*p).next;(*s).next=(*p).next; (*p).next=s;试卷二试题二:把下列程序补充完整实现两个字符串的比较,即自己写个strcmp函数,函数原型为:int strcmp(char *p1,char *p2)设p1指向字符串s1,p2指向字符串s2,要求:当s1=s2时,返回值为0。
第2章习题(带答案)

第2章习题(带答案)1.链表不具有的特点是A.可随机访问任一个元素B.插入删除不需要移动元素C.不必事先估计存储空间D.所需空间与线性表长度成正比2.在一个具有n个结点的单链表中查找值为某的某结点,若查找成功,则平均比较个结点。
A.nB.n/2C.(n-1)/2D.(n+1)/23.在单链表中P所指结点之后插入一个元素某的主要操作语句序列是=(node某)malloc(izeof(node));、->data=某;、->ne某t=p->ne某t、p->ne某t=。
4.在单链表中查找第i个元素所花的时间与i成正比。
(√)5.在带头结点的双循环链表中,任一结点的前驱指针均不为空。
(√)6.用链表表示线性表的优点是()。
A.便于随机存取C.便于插入与删除B.花费的存储空间比顺序表少D.数据元素的物理顺序与逻辑顺序相同7.在双向链表中删除P所指结点的主要操作语句序列是p->prior->ne某t=p->ne某t;、p->ne某t->prior=p->prior;、free(p);8.下述哪一条是顺序存储结构的优点?()A.存储密度大B.插入运算方便C.删除运算方便D.可方便地用于各种逻辑结构的存储表示9.若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一个结点。
则采用()存储方式最节省运算时间。
A.单链表B.双链表C.单循环链表D.带头结点的双循环链表10.对任何数据结构链式存储结构一定优于顺序存储结构。
(某)11.对于双向链表,在两个结点之间插入一个新结点需修改的指针共4个,单链表为____2___个。
12.以下数据结构中,()是非线性数据结构A.树B.字符串C.队列D.栈13.若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用()存储方式最节省时间。
A.顺序表B.双链表C.带头结点的双循环链表D.单循环链表14.“线性表的逻辑顺序和物理顺序总是一致的。
链表练习题及答案

1、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.删除p结点的直接后继的语句是11,3,14b.删除p结点的直接前驱的语句是10,12,8,11,3,14c.删除p结点的语句序列是10,7,3,14d.删除首元结点的语句序列是12,10,13,14e.删除尾元结点的语句序列是9,11,3,14(1)p=p->next;(2) p->next=p;(3)p->next=p->next->next;(4)p=p->next->next;(5)while(p)p=p->next;(6)whlie(Q->next){p=Q;Q=Q->next;}(7)while(p->next!=Q)p=p->next;(8)while(p->next->next!=Q)p=p->next;(9)while(p->next->next)p=p->next;(10)Q=p;(11)Q=p->next;(12)p=L;(13)L=L->next;(14)free(Q);2、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.在p结点后插入s结点的语句序列是4,1b.在p结点前插入s结点的语句序列是7,11,8,4,1c.在表首插入s结点的语句序列是5,12d.在表尾插入s结点的语句序列是7,9,4,1或11,9,1,61.p-> next =s;2.p-> next=p-> next-> next;3.p->next=s->next;4.s->next=p-> next;5.s-> next=L;6.s->next=NULL;7.q=p ;8.while(p->next!=q) p=p->next;9.while(p->next!=NULL) p=p->next;10.p =q;11.p=L;12.L=s;13.L=P;3、已知P结点是某双向链表的中间结点,从下列提供的答案中选择合适的语句序列a.在P结点后插入S结点的语句序列是12,7,3,6b.在P结点前插入S结点的语句序列是13,8,5,4c.删除p结点的直接后继结点的语句序列是15,1,11,18d.删除p结点的直接前驱结点的语句序列是16,2,10,18e.删除p结点的语句序列是9,14,171.P->next=P->next->next;2.P->priou=P->priou->priou;3.P->next=S;4.P->priou=S;5.S->next=P;6.S->priou=P;7.S->next=P->next;8.S->priou=P->priou;9.P->priou->next=P->next;10.P->priou->next=P;11.P->next->priou=P;12.P->next->priou=S;13.P->priou->next=S;14.P->next->priou=P->priou;15.Q=p->next;16.Q=P->priou;17.free(P);18.free(Q);。
历年链表考题与答案

历年链表考题及答案[2005秋II.14]设已建立了两条单向链表,这两链表中的数据已按从小到大的次序排好,指针h1和h2分别指向这两条链表的首结点。
链表上结点的数据结构如下:structnode{intdata;node*next;};以下函数node*Merge(node*h1,node*h2)的功能是将h1和h2指向的两条链表上的结点合并为一条链表,使得合并后的新链表上的数据仍然按升序排列,并返回新链表的首结点指针。
算法提示:首先,使newHead和q都指向首结点数据较小链表的首结点,p指向另一链表首结点。
其次,合并p和q所指向的两条链表。
在q不是指向链尾结点的情况下,如果q 的下一个结点数据小于p指向的结点数据,则q指向下一个结点;否则使p1指向q的下一个结点,将p指向的链表接到q所指向的结点之后,使q指向p所指向的结点,使p指向p1所指向的链表。
直到p和q所指向的两条链表合并结束为止。
注意,在合并链表的过程中,始终只有两条链表。
[函数](4分)node*Merge(node*h1,node*h2){node*newHead,*p,*p1;//使newHead和q指向首结点数据较小链表的首结点,p指向另一链表首结点if((27)){newHead=h1;p=h2;}//h1->data<h2->dataelse{newHead=h2;p=h1;}node*q=newHead;//合并两条链表while(q->next){if(q->next->data<p->data)(28);//q=q->nextelse{(29);//p1=q->nextq->next=p;q=p;p=p1;}}q->next=p;(30);//returnnewNead}[2005春II.11]设已建立一条单向链表,指针head指向该链表的首结点。
结构体与链表习题附答案

结构体与链表习题附答案一、选择题1、在说明一个结构体变量时系统分配给它的存储空间是().A)该结构体中第一个成员所需的存储空间B)该结构体中最后一个成员所需的存储空间C)该结构体中占用最大存储空间的成员所需的存储空间D)该结构体中所有成员所需存储空间的总和。
2.设有以下说明语句,则以下叙述不正确的是()tructtu{inta;floatb;}tutype;A.truct是结构体类型的关键字B.tructtu是用户定义的结构体类型C.tutype是用户定义的结构体类型名D.a和b都是结构体成员名3、以下对结构体变量tu1中成员age的合法引用是()#includetructtudent{intage;intnum;}tu1,某p;p=&tu1;A)tu1->ageB)tudent.ageC)p->ageD)p.age4、有如下定义:Structdate{intyear,month,day;};Structworklit{Charname[20];Chare某;Structdatebirthday;}peron;对结构体变量peron的出生年份进行赋值时,下面正确的赋值语句是()Aworklit.birthday.year=1978Bbirthday.year=1978Cperon.birthday .year=1958Dperon.year=19585、以下程序运行的结果是()#include”tdio.h”main(){tructdate{intyear,month,day;}today;printf(“%d\\n”,izeof(truct date));}A.6B.8C.10D.126、对于时间结构体tructdate{intyear,month,day;charweek[5];}则执行printf(“%d\\n”,izeof(tructdate))的输出结果为(A.12B.17C.18D.207、设有以下语句:tructt{intn;charname[10]};tructta[3]={5,“li”,7,“wang”,9,”zhao”},某p;p=a;则以下表达式的值为6的是()A.p++->nB.p->n++C.(某p).n++D.++p->n8、设有以下语句,则输出结果是()tructLit{intdata;tructLit某ne某t;};tructLita[3]={1,&a[1],2,&a[2],3,&a[0]},某p;p=&a[1];printf(\printf(\printf(\}A.131B.311C.132D.2139、若有以下语句,则下面表达式的值为1002的是()tructtudent{intage;intnum;};tructtudenttu[3]={{1001,20},{1002,19},{1003,21}};)tructtudent某p;p=tu;A.(p++)->numB.(p++)->ageC.(某p).numD.(某++p).age10、下若有以下语句,则下面表达式的值为()tructcmpl某{int某;inty;}cnumn[2]={1,3,2,7};cnum[0].y/cnum[0].某某cnum[1].某;A.0B.1C.3D.611、若对员工数组进行排序,下面函数声明最合理的为()。
习题3(链表)
习题3(链表)一、选择题(1)链接存储的存储结构所占存储空间( A )。
A)分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针B)只有一部分,存放结点值C)只有一部分,存储表示结点间关系的指针D)分两部分,一部分存放结点值,另一部分存放结点所占单元数(2)线性表若采用链式存储结构时,要求内存中可用存储单元的地址( D )。
A)必须是连续的B)部分地址必须是连续的C)一定是不连续的D)连续或不连续都可以(3)线性表L在( B )情况下适用于使用链式结构实现。
A)需经常修改结点值B)需不断删除插入C)含有大量的结点D)结点结构复杂(4)单链表的存储密度( C )。
A)大于1 B)等于1 C)小于1 D)不能确定(5)若指定有n个元素的向量,则建立一个有序单链表的时间复杂性的量级是( C )。
A)O(1) B)O(n) C)O(n2) D)O(nlog2n)(6)在单链表中,要将s所指结点插入到p所指结点之后,其语句应为( D )。
A)s->next=p+1; p->next=s; B)(*p).next=s; (*s).next=(*p).next;C)s->next=p->next; p->next=s->next; D)s->next=p->next; p->next=s;(7)在双向链表存储结构中,删除p所指的结点时须修改指针( A )。
A)p->next->prior=p->prior; p->prior->next=p->next;B)p->next=p->next->next; p->next->prior=p;C)p->prior->next=p; p->prior=p->prior->prior;D)p->prior=p->next->next; p->next=p->prior->prior;(8)在双向循环链表中,在p指针所指的结点后插入q所指向的新结点,其修改指针的操作是( C )。
数据结构真题及其答案解析
数据结构真题及其答案解析引言在计算机科学领域中,数据结构是一个关键概念。
它是指组织和存储数据的方法和原则。
良好的数据结构可以大大提高算法的效率和性能。
在学习和应用数据结构的过程中,了解和解析真题对于提高对数据结构的理解和应用能力至关重要。
本文将讨论几个典型的数据结构真题,并提供详细的答案解析。
链表题目1. 题目描述:实现一个单向链表,具有以下功能:a) 在链表末尾添加一个元素。
b) 删除链表中指定位置的元素。
c) 返回链表的长度。
解析:这道题要求你实现一个链表数据结构,并完成对应的功能。
为了实现一个单向链表,我们需要定义一个节点类,每个节点包含一个值和指向下一个节点的指针。
在链表的尾部添加一个元素时,我们需要遍历链表直至最后一个节点,然后将新的节点链接到最后一个节点的指针上。
删除链表中指定位置的元素时,我们需要找到该位置的前一个节点,并将其指针指向目标位置的下一个节点。
返回链表的长度则只需要遍历链表并记录节点数即可。
栈题目2. 题目描述:实现一个栈数据结构,具有以下功能:a) 入栈(Push)操作,将一个元素加入栈中。
b) 出栈(Pop)操作,从栈中取出一个元素并将其删除。
c) 返回栈中元素的个数。
解析:栈是一种后进先出(Last In First Out,LIFO)的数据结构,类似于现实生活中的栈。
我们可以使用数组或链表来实现一个栈。
入栈操作将一个元素添加到栈的顶部,而出栈操作则取出栈顶的元素并将其删除。
为了实现这个功能,我们需要维护一个指向栈顶的指针,并更新指针的位置。
返回栈中元素的个数只需要记录当前栈的大小即可。
二叉树题目3. 题目描述:实现一个二叉树数据结构,具有以下功能:a) 添加一个节点到二叉树中。
b) 删除二叉树中指定的节点。
c) 查找指定值在二叉树中的位置。
解析:二叉树是一种由节点组成的层级结构,其中每个节点最多有两个子节点。
为了实现一个二叉树,我们需要定义一个节点类,每个节点包含一个值和指向左右子节点的指针。
链表习题——精选推荐
一选择题1.下述哪一条是顺序存储结构的优点?(a )A.存储密度大B.插入运算方便C.删除运算方便D.可方便地用于各种逻辑结构的存储表示2.下面关于线性表的叙述中,错误的是哪一个?(b )A.线性表采用顺序存储,必须占用一片连续的存储单元。
B.线性表采用顺序存储,便于进行插入和删除操作。
C.线性表采用链接存储,不必占用一片连续的存储单元。
D.线性表采用链接存储,便于插入和删除操作。
3.线性表是具有n个(c)的有限序列(n>0)。
A.表元素B.字符C.数据元素D.数据项E.信息项4.若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用(a )存储方式最节省时间。
A.顺序表B.双链表C.带头结点的双循环链表D.单循环链表5.某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用(d )存储方式最节省运算时间。
A.单链表B.仅有头指针的单循环链表C.双链表D.仅有尾指针的单循环链表6.设一个链表最常用的操作是在末尾插入结点和删除尾结点,则选用( d )最节省时间。
A. 单链表B.单循环链表C. 带尾指针的单循环链表D.带头结点的双循环链表//双循环链表处理所有问题要比其他链表更方便7. 静态链表中指针表示的是(c ). A.内存地址B.数组下标C.下一元素地址D.左、右孩子地址8. 链表不具有的特点是(b )A.插入、删除不需要移动元素B.可随机访问任一元素C.不必事先估计存储空间D.所需空间与线性长度成正比9. 下面的叙述不正确的是(b,c )A.线性表在链式存储时,查找第i个元素的时间同i的值成正比B. 线性表在链式存储时,查找第i个元素的时间同i的值无关C. 线性表在顺序存储时,查找第i个元素的时间同i 的值成正比D. 线性表在顺序存储时,查找第i个元素的时间同i的值无关10.非空的循环单链表head的尾结点p↑满足(a )。
A.p↑.link=head B.p↑.link=NIL C.p=NIL D.p= head 11.循环链表H的尾结点P的特点是(a )。
链表练习题及答案
链表练习题及答案1、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.删除p结点的直接后继的语句是11,3,14b.删除p结点的直接前驱的语句是10,12,8,11,3,14c.删除p结点的语句序列是10,7,3,14d.删除首元结点的语句序列是12,10,13,14e.删除尾元结点的语句序列是9,11,3,14(1)p=p->next;(2) p->next=p;(3)p->next=p->next->next;(4)p=p->next->next;(5)while(p)p=p->next;(6)whlie(Q->next){p=Q;Q=Q->next;}(7)while(p->next!=Q)p=p->next;(8)while(p->next->next!=Q)p=p->next;(9)while(p->next->next)p=p->next;(10)Q=p;(11)Q=p->next;(12)p=L;(13)L=L->next;(14)free(Q);2、已知L是带表头的单链表,其P结点既不是首元结点,也不是尾元结点,a.在p结点后插入s结点的语句序列是4,1b.在p结点前插入s结点的语句序列是7,11,8,4,1c.在表首插入s结点的语句序列是5,12d.在表尾插入s结点的语句序列是7,9,4,1或11,9,1,61.p-> next =s;2.p-> next=p-> next-> next;3.p->next=s->next;4.s->next=p-> next;5.s-> next=L;6.s->next=NULL;7.q=p ;8.while(p->next!=q) p=p->next;9.while(p->next!=NULL) p=p->next;10.p =q;11.p=L;12.L=s;13.L=P;3、已知P结点是某双向链表的中间结点,从下列提供的答案中选择合适的语句序列a.在P结点后插入S结点的语句序列是12,7,3,6b.在P结点前插入S结点的语句序列是13,8,5,4c.删除p结点的直接后继结点的语句序列是15,1,11,18d.删除p结点的直接前驱结点的语句序列是16,2,10,18e.删除p结点的语句序列是9,14,171.P->next=P->next->next;2.P->priou=P->priou->priou;3.P->next=S;4.P->priou=S;5.S->next=P;6.S->priou=P;7.S->next=P->next;8.S->priou=P->priou;9.P->priou->next=P->next;10.P->priou->next=P;11.P->next->priou=P;12.P->next->priou=S;13.P->priou->next=S;14.P->next->priou=P->priou;15.Q=p->next;16.Q=P->priou;17.free(P);18.free(Q);。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(2)下列程序的功能是实现向head指向的链表中插入新结点s,如图17所示,使该链表按结点的id值保持升序排列。
图17
#include<stdio.h>
#include<stdlib.h>
typedef struct Node{
int id;
char *name;
struct Node *next;
}Node;
void Innode(Node *head,int id,char *str) {
int j=0;
Node *p,*q,*s;
p=head;
while( ④) {
q=p;
p=p->next;
}
s=(Node*)malloc(sizeof(Node));
s->id=id;
s->name=str;
⑤
⑥
}
main()
{
/*省略创建链表head的代码*/ Innode(head,3,”Jone”);
}
36.Merge函数用于将两个升序的链表head1和head2合并成一个链表,并保持合并后链表依然升序。
排序的依据为结构体类型Node中的data成员,合并中不得删除节点。
下面给出Merge函数的主体框架,在空出的五个位置补充该主体框架缺失的代码段。
注意:不能定义新的变量,可不用已定义的某些变量。
typedef struct Node
{
int data;
struct Node *next;
}Node;
Node *Merge(Node *head1,Node *head2)
{
if ( head1==NULL)
return head2;
if(head2==NULL)
return headl;
Node *head=NULL;//head指针用于指向合并后链表的头结点
Node *pl=NULL;
Node *p2=NULL;
if(headl->data<head2->data){
head=headl;
______①______
p2=head2;
}else{
head=head2;
______②______
pl=headl;
}
}
Node *pcurrent=head;
while(p1!=NULL&&p2!=NULL) {
if(pl->data<=p2->data){
pcurrent->next=p1;
______③______
p1=pl->next;
}else{
pcurrent->next=p2;
______④______
p2=p2->next;
}
}
if(pl!=NULL)
______⑤______
if(p2!=NULL)
pcurrent->next=p2;return head;
}。