样本量估算
样本量估算公式
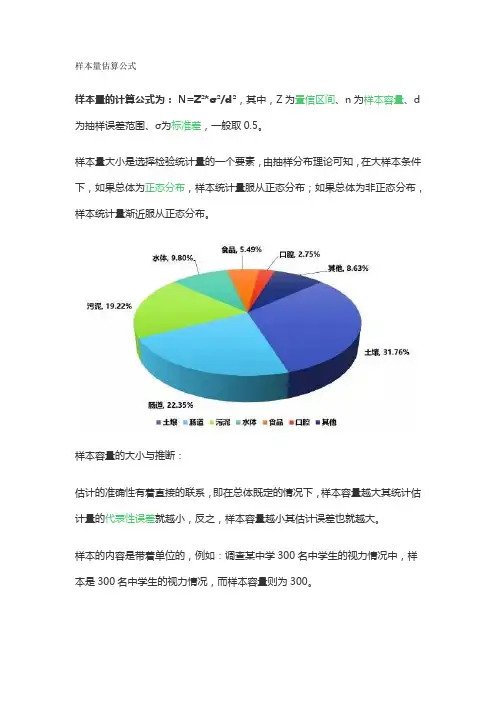
样本量估算公式
样本量的计算公式为: N=Z²*σ²/d²,其中,Z为置信区间、n为样本容量、d 为抽样误差范围、σ为标准差,一般取0.5。
样本量大小是选择检验统计量的一个要素,由抽样分布理论可知,在大样本条件下,如果总体为正态分布,样本统计量服从正态分布;如果总体为非正态分布,样本统计量渐近服从正态分布。
样本容量的大小与推断:
估计的准确性有着直接的联系,即在总体既定的情况下,样本容量越大其统计估计量的代表性误差就越小,反之,样本容量越小其估计误差也就越大。
样本的内容是带着单位的,例如:调查某中学300名中学生的视力情况中,样本是300名中学生的视力情况,而样本容量则为300。
样本容量的大小涉及到调研中所要包括的单元数,样本容量是对于研究的总体而言的,是在抽样调查中总体的一些抽样,比如:中国人的身高值为一个总体,随机取一百个人的身高,这一百个人的身高数据就是总体的一个样本,某一个样本中的个体的数量就是样本容量。
样本量估算(八)多组率的样本量计算——两两比较

样本量估算(八)多组率的样本量计算——两两比较在统计学中,多组率的样本量计算是指在进行两两比较时,为每一对比较确定所需的样本量。
这种样本量计算常用于医学、社会科学和市场调研等领域中,用于确定两个或多个组之间存在差异的最小样本量。
在进行多组率的样本量计算时,首先需要确定以下几个参数:1.α(显著性水平):通常设置为0.05,表示在2.5%的显著性水平下检验假设。
2.1-β(统计功效):通常设置为0.80,表示希望在80%的情况下能够检测到真实的差异。
3.预计的组间差异(与比较的特定指标相关):这个差异一般由现有的研究或相关文献提供。
4.参与者的数量:最好是根据研究的目的来确定样本量,以便能够检测到具有实际意义的差异。
在进行两两比较时,最常见的方法是使用二项式分布的方法计算每个比较所需的样本量。
例如,在进行两个比例的比较时,可以使用以下公式计算样本量:n=(Zα/2+Zβ)^2*(P1(1-P1)/N1+P2(1-P2)/N2)/(P1-P2)^2其中,n为每个组的样本量,Zα/2和Zβ是标准正态分布的上分位数,P1和P2是两个组的预计比例,N1和N2是每个组的总体大小。
此外,还有其他方法和公式可用于计算多组率的样本量。
例如,当需要比较三个或更多组时,可以使用ANOVA(方差分析)方法或多重比较校正方法来进行样本量计算。
在进行多组率的样本量计算时,还应该考虑到以下几个因素:1.选择适当的效应大小:样本量计算是基于预期的组间差异,因此需要选择一个合理的实际效应大小,以便计算出更准确的样本量。
2.考虑到非响应率和丢失率:在样本量计算中需要考虑到非响应率和丢失率,以确保样本量可以满足研究目的。
3.考虑到数据的分布:样本量计算通常假设数据服从特定的分布,例如二项分布或正态分布。
在实际计算中,需要根据数据的实际分布情况进行适当的调整。
4.考虑到实际可行性:在计算样本量之前,需要评估研究的可行性,包括研究时间、研究经费等方面的限制。
探索性研究样本量估算

探索性研究样本量估算
探索性研究的样本量估算可以采用以下几种方法:
1. 基于个人经验和专业判断:根据研究者的经验和专业判断,估算出适当的样本量。
这种方法常用于早期或初步的研究,用来获取初步的数据和洞察。
2. 多重催化矩阵(multicatalyst matrix):该方法将多个输入因素组合,估算可能的样本量。
将每个因素的不同水平进行组合,以确定涉及每个因素组合的样本量。
3. 探索性因子分析(Exploratory Factor Analysis, EFA):EFA是一种数据降维技术,可以帮助确定需要观察的主要变量。
通过对因素分析结果的解释,可以估算出样本所需的最小样本量。
4. 功能模型选择:基于预测模型的方法,根据研究者选择的模型和所需的效应大小,估算出样本量。
可以通过模拟或假设检验进行样本量估算。
5. 规范化指数(Coefficient of Normalization):该方法通过将研究评价的主要指标与参考样本进行比较,估算出样本所需的最小样本量。
值得注意的是,探索性研究的样本量估算方法并不是唯一的,研究者可以根据自身的研究目的和数据特点选择适合的方法进行样本量估算。
此外,还应考虑研究的时间和资源限制,以及可能的损失函数和可信度分析,来优化样本量的选择。
多个样本均数的样本量估算方法

多个样本均数的样本量估算方法多个样本均数的样本量估算方法1. 引言在统计学中,样本量的估算是进行实证研究时的重要步骤之一。
当我们想要对一个或多个总体参数进行推断时,需要选择合适的样本量以获得可靠的结果。
而在研究中涉及到多个样本均数时,如何估算合适的样本量就成为一个关键问题。
本文将介绍多个样本均数的样本量估算方法。
2. 多个样本均数的样本量估算方法在实际的研究中,我们往往需要比较多个群体或处理之间的均值差异。
我们可能要比较两种不同的治疗方法在患者中的疗效,或者比较不同城市的空气质量指标。
为了估算到合适的样本量,我们需要考虑以下几个因素:2.1 效应大小效应大小是指不同群体或处理之间的均值差异。
一般来说,效应大小越大,样本量就越小,因为较大的效应大小意味着我们可以更容易地发现差异。
相反,如果效应大小较小,样本量需要增加以增加统计显著性的能力。
2.2 显著性水平显著性水平是我们对于差异是否真实存在的信心水平。
通常我们选择的显著性水平为0.05或0.01。
选择较小的显著性水平会导致需要更大的样本量,因为我们要求更高的置信度来支持我们的结论。
2.3 统计功效统计功效是指检验能够检测到差异的能力。
通常我们选择的统计功效为0.8或0.9,即80%或90%的概率能够检测到真实存在的差异。
较高的统计功效要求较大的样本量。
2.4 方差方差是影响样本量估算的一个重要因素。
方差反映了数据的离散程度,较大的方差意味着样本量需要增大。
如果预先没有方差的估计,通常可以进行一个小规模的前期研究来估计方差。
根据上述因素,我们可以使用统计学中的样本量估算方法来计算合适的样本量。
以下是一种常用的多个样本均数的样本量估算方法:3. 样本量估算方法示例假设我们想要比较A、B、C三种不同的染料对纺织品色牢度的影响,我们希望能够发现三种染料之间的均值差异。
我们已经知道了染料A的均值为μ1,标准差为σ1;染料B的均值为μ2,标准差为σ2;染料C的均值为μ3,标准差为σ3。
统计学估算样本量

统计学估算样本量一、样本量估算的基本概念在进行统计研究时,我们希望通过对样本的观察来推断总体的特征。
样本量的大小直接影响到我们对总体特征的估计精度和推断的准确性。
样本量估算是为了确定一个合适的样本容量,使得对总体参数的估计误差在一定范围内。
二、样本量估算的方法样本量的估算是根据研究目标、总体特征、假设检验的要求等因素综合考虑得出的。
常用的样本量估算方法有如下几种:1.常用的样本量估算方法之一是基于置信区间的方法。
在进行统计推断时,我们希望能够给出一个对总体参数的估计范围,即置信区间。
样本量的大小与置信区间的宽度有关,当我们希望估计的精度更高时,需要增加样本容量。
2.另一种常用的样本量估算方法是基于假设检验的方法。
在进行假设检验时,我们需要根据研究目标和假设的检测效应大小来确定样本量。
通常情况下,当我们希望检测到一个较小的效应时,需要增加样本容量。
3.此外,还有一些特殊的样本量估算方法,如基于方差分析、回归分析等。
这些方法根据具体的研究设计和分析方法来确定样本量。
三、样本量估算的注意事项在进行样本量估算时,需要注意以下几点:1.合理选择统计方法。
样本量估算方法的选择应根据研究目标和分析方法来决定,确保估算结果的准确性和可靠性。
2.注意样本的代表性。
样本应该尽可能代表总体的特征,避免出现样本选择偏差,否则样本量估算的结果可能不准确。
3.考虑实际可行性。
在进行样本量估算时,需要考虑实际可行性和研究资源的限制,避免过高或过低的样本容量。
4.定期进行样本量检查。
在实施研究过程中,应根据实际情况定期对样本量进行检查和调整,以确保研究结果的可靠性。
四、总结样本量的估算是统计学中重要的一部分,合理的样本量能够保证研究结果的可靠性和有效性。
在进行样本量估算时,需要根据研究目标、总体特征、假设检验的要求等因素综合考虑。
合理选择估算方法、注意样本的代表性、考虑实际可行性和定期进行样本量检查是进行样本量估算的关键要点。
样本量估算

样本量估算
样本量估算指的是在一项研究中需要招募多少参与者,以达到足够的统计学力量来回答研究问题。
样本量的大小取决于多个因素,包括研究的类型、目的、研究假设的大小、研究问题的类型和分析方法等。
在估算样本量时,需要考虑以下因素:
1. 样本的方差大小:当目标是检测两组之间的差异时,方差越大,则需要更大的样本量。
2. 置信度:样本量的大小受置信度的影响。
通常置信度为95%或99%。
3. 效应大小:一般来说,如果实际的效应大小增加,则需要更少的样本量。
4. 误差范围:需确定研究误差大小,通常用于指定结果估计值的置信区间。
假设在进行一项研究时,我们需要得出两组之间的差异,置信度为95%,实际的效应大小为0.5,研究误差范围为正负0.1。
基于这些条件,我们可以使用样本量计算公式来估算样本量:
n = 2 * (Z值 + Zβ值)^2 * σ^2 / Δ^2
其中,n表示要招募的样本量;Z值和Zβ值分别是计算置信度和功效所用的标准正态分布的值;Δ表示研究组之间的期望差异。
假设σ为0.5,则:
- 当期望的差异值为0.5时,n= 364
- 当期望的差异值为0.8时,n = 170
- 当期望的差异值为1.0时,n = 109
这意味着,为了达到95%的置信度和80%的功效,我们需要至少在每组招募109个参与者来完成我们的研究。
但是,样本量的大小仍然要考虑其它因素,如样本选择和可接受的误差范围。
因此,我们建议在设计研究时仔细考虑这些因素,在设置样本量时,结合实际情况和研究成本来做合理规划。
最低样本量的估算公式
最低样本量的估算公式
在进行样本量估算时,通常会考虑诸多因素,如总体方差、显著性水平、置信度等。
然而,在某些情况下,我们需要尽可能地减少数据采集的成本和时间,因此需要寻找最低样本量的估算公式。
最低样本量的估算公式基于以下假设:
1. 样本来自于一个正态分布的总体;
2. 总体方差未知,但样本方差可用作总体方差的估计量;
3. 期望误差为给定值(通常为总体均值的一定比例)。
根据这些假设,我们可以得到最低样本量的估算公式:
n = (Zα/2 ×σ/ε)
其中,n为最低样本量;Zα/2为给定显著性水平下的标准正态分布的分位数;σ为样本方差的平方根,作为总体方差的估计量;ε为期望误差,即总体均值的一定比例。
需要注意的是,这个公式只适用于正态分布的总体,如果样本来自于一个非正态分布的总体,或者总体方差已知,那么需要使用其他的样本量估算方法。
此外,最低样本量的估算公式只是一个估计值,实际采样时可能需要根据具体情况进行调整。
- 1 -。
调查量表样本量的估算
调查量表样本量的估算方法、技巧与实际应用在进行市场调查、社会科学研究或医学研究时,调查量表样本量的估算是一个至关重要的环节。
合理的样本量能够确保调查结果的代表性和可靠性,同时避免资源的浪费。
本文将详细介绍调查量表样本量的估算方法、技巧以及实际应用,帮助研究者更好地设计和实施调查。
一、调查量表样本量的估算方法1. 根据总体大小估算当总体大小(N)已知时,可以使用以下公式来估算样本量(n):n = N ×(1 + Z^2 ×p ×(1-p))其中,Z是对应于所需置信水平(通常为95%)的标准正态分布的分位数,p是预期的响应比例(以小数形式),(1-p)是未响应的比例。
2. 根据总体比例估算当总体比例(p)未知时,可以使用以下公式来估算样本量:n = (Z^2 ×p ×(1-p)) / (E^2)其中,E是允许的误差范围(以小数形式),Z是标准正态分布的分位数,p是预期的响应比例。
3. 根据效应大小估算在医学研究中,样本量的估算通常基于效应大小(Δ)。
效应大小是指处理效应与控制效应之间的差异。
样本量可以通过以下公式估算:n = 2 ×(Z^2 + Δ^2) / (E^2)其中,Δ是效应大小,Z是标准正态分布的分位数,E是允许的误差范围。
二、调查量表样本量的估算技巧1. 考虑总体异质性在估算样本量时,需要考虑总体的异质性。
如果总体中各个单位的响应概率差异较大,需要增加样本量以确保结果的可靠性。
2. 适当增加样本量在调查设计中,适当增加样本量可以提高结果的精确度和可靠性。
但是,也要避免样本量过大,以免造成资源的浪费。
3. 考虑无响应率在调查中,可能会有一部分受访者不参与调查。
因此,在估算样本量时,需要考虑无响应率,并相应地增加样本量。
4. 使用专业软件现代统计软件(如SPSS、SAS、R等)提供了样本量估算的功能。
研究者可以使用这些软件来帮助估算样本量。
样本量的估算方法
样本量的估算方法引言在实施研究项目时,样本量的估算是一个重要的步骤。
准确估算样本量对于确保研究结果的可靠性和有效性至关重要。
本文将介绍一些常用的样本量估算方法。
1. 常见的样本量估算方法1.1. 参数估计法参数估计法是一种常见的样本量估算方法,它基于对所研究总体参数的估计。
在使用参数估计法时,需确定研究中的主要参数,并通过合适的统计模型对其进行估计。
然后,根据所容忍的误差范围和置信水平,可以计算出所需的样本量。
1.2. 效应量估算法效应量估算法是另一种常用的样本量估算方法。
它关注的是待研究变量之间的差异大小。
研究的效应量越大,所需的样本量越小,反之亦然。
通过对已有文献中的效应量进行分析,可以得出对应于所研究效应量的样本量估算。
1.3. 推断力估算法推断力估算法是一种基于显著性检验的样本量估算方法。
它基于预先设定的显著性水平和所期望的统计效应大小,在保证所研究假设能够被充分检验的前提下,通过计算所需的样本量。
2. 样本量估算的重要性准确估算样本量对于研究的可靠性和有效性具有重要意义。
确保样本量足够可以提高研究结果的可靠性,避免假阳性或假阴性结果的出现。
同时,充分估算样本量可以避免资源的浪费,确保研究的高效性。
结论在实施研究项目时,样本量的估算是至关重要的一步。
参数估计法、效应量估算法和推断力估算法是常用的样本量估算方法。
准确估算样本量可以提高研究结果的可靠性和有效性,同时也可以避免资源的浪费。
因此,在研究设计之初,进行样本量估算是非常重要的。
样本量估算
1.单因素二水平设计定量资料的非劣效性检验时样本量的估算1.1计算公式:非劣效性检验应当采用单侧的检验水准α,假定允许的第二类错误概率不超过β,则非劣效性检验每组需要的样本含量为:22211)/()(2θδβα-+=--L S u u n (1-1)[1]2221)/()(2δβαe s z z n n ⨯+== (1-2)[2] 1.2式中各参数代表的意义,n 为每组样本含量,α-1u 、β-1u 为单侧标准正态离差界值,S 为估计的共同标准差,L δ为非劣界值,且L δ<0,θ 为试验组与对照组总体均值差值的估计值。
说明:单因素二水平设计定量资料的非劣效性检验时样本量的估算公式与上式完全类似,只需将非劣界值L δ(L δ<0)替换成优效界值u δ(u δ>0)即可。
1.3例题:某利尿新药拟进行Ⅱ期临床试验,与阳性药按1:1的比例安排例数,考察24h 新药利尿量(ml )是否不差于阳性药。
根据以往的疗效和统计学的一般要求,取α=0.05,β=0.20,非劣效界值L δ=﹣60ml ,已知两组共同标准差S =180ml ,假定新药与阳性对照药总体利尿量的差值θ=﹣20ml ,问每组需要多少病例?将05.01-u =1.645,20.01-u =0.845,s=180,L δ=﹣60,θ=﹣20代入公式,得:22211)/()(2θδβα-+=--L S u u n =2(1.645+0.845)2×1802/(﹣60﹣(﹣20))2≈251.1,取n=252,即每组需要252例。
2.单因素二水平设计定性资料的非劣效性检验时样本含量的估算2.1计算公式:非劣效性检验应当采用单侧检验,检验水准为α,假定允许的第二类错误概率不超过β,试验组与对照组总体率的差值为C T ππθ-=(T π、C π未知时可用样本频率估计),两组的平均有效率为2/)(C T πππ+=,非劣界值为u δ<0,则在两组样本含量相等的情况下,非劣效性检验每组需要的样本含量为:2211)/()1()(2θδππβα--+=--L u u n (2-1)[1]2合合221/)-1()(2δβαp p z z n n +== (2-2)[2]说明:单因素二水平设计定性资料的优效性检验时样本含量的估计公式与式(2-1)完全类似,只需将非劣界值L δ(L δ<0)替换成优效界值u δ(u δ>0)即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.单因素二水平设计定量资料的非劣效性检验时样本量的估算
1.1计算公式:
非劣效性检验应当采用单侧的检验水准α,假定允许的第二类错误概率不超过β,则非劣效性检验每组需要的样本含量为:
22211)/()(2θδβα-+=--L S u u n (1-1)[1]
2221)
/()(2δβαe s z z n n ⨯+==(1-2)[2] 1.2式中各参数代表的意义,n 为每组样本含量,α-1u 、β-1u 为单侧标准正态离差界值,S 为估计的共同标准差,L δ为非劣界值,且L δ<0,θ为试验组与对照组总体均值差值的估计值。
说明:单因素二水平设计定量资料的非劣效性检验时样本量的估算公式与上式完全类似,只需将非劣界值L δ(L δ<0)替换成优效界值u δ(u δ>0)即可。
1.3例题:某利尿新药拟进行Ⅱ期临床试验,与阳性药按1:1的比例安排例数,考察24h 新药利尿量(ml )是否不差于阳性药。
根据以往的疗效和统计学的一般要求,取α=0.05,β=0.20,非劣效界值L δ=﹣60ml ,已知两组共同标准差S =180ml ,假定新药与阳性对照药总体利尿量的差值θ=﹣20ml ,问每组需要多少病例?
将05.01-u =1.645,20.01-u =0.845,s=180,L δ=﹣60,θ=﹣20代入公式,得:
22211)/()(2θδβα-+=--L S u u n =2
(1.645+0.845)2×1802/(﹣60﹣(﹣20))2≈251.1,取n=252,即每组需要252例。
2.单因素二水平设计定性资料的非劣效性检验时样本含量的估算
2.1计算公式:
非劣效性检验应当采用单侧检验,检验水准为α,假定允许的第二类错误概率不超过β,试验组与对照组总体率的差值为C T ππθ-=
(T π、C π未知时可用样本频率估计),两组的平均有效率为2/)(C T πππ+=,非劣界值为u δ<0,则在两组样本含量相等的情况下,非劣效性检验每组需要的样本含量为:
2211)/()1()(2θδππβα--+=--L u u n (2-1)[1]
2合合221/)-1()(2δβαp p z z n n +==(2-2)[2]
说明:单因素二水平设计定性资料的优效性检验时样本含量的估计公式与式(2-1)完全类似,只需将非劣界值L δ(L δ<0)替换成优效界值u δ(u δ>0)即可。
2.2例题:某新药拟进行Ⅱ期临床试验,与阳性药按1:1的比例安排例数,考察新药临床治愈率是否不差于阳性药。
根据以往的疗效和统计学的一般要求,取α=0.05,β=0.20,非劣界值δ=﹣0.15,平均有效率P=0.80,并假定两组总体有效率相等,问每组需
要多少病例?
代入公式(2-1)或者(2-2)得n=2(1.645+0.845)2×0.8×(1-0.8)/(﹣0.15)2≈88,即每组需要88例。
3.单因素二水平设计定量资料的等效性检验时样本含量的估算
3.1计算公式
对于等效性检验,按照双侧的检验水准α(若等效性检验采用双单侧检验,则没个单侧检验的检验水准为α/2),允许犯第二类错误的概率不超过β,则结果变量为定量变量时等效性检验每组需要的样本含量的计算公式(3-1)[1]为:
1)1(])[()1(])[(2/1222/122-⎪⎭
⎪⎬⎫⎪⎩⎪⎨⎧-++-+⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧-+--=--αασδμμφσδμμφu k kn u k kn power C T C T C T C T 这是一个超越方程。
可通过迭代法求解出满足要求的试验组样本含量T n 。
式中T μ、C μ分别为试验组与对照组的总体均值,未知时可用样本均值代替;δ是等效界值,且δ>0;2/1α-u 为标准正态离差界值;T n 为试验组的样本含量;k 为对照组与试验组样本含量的比值,即T C n n /=k ,或者C n =k T n ;2C σ是试验组与对照组的合并方差,未知时可用样本的合并方差2C S 代替。
power 不小于1-β。
3.2例题:某利尿新药拟进行Ⅱ期临床试验,与阳性药按1:1的比例安排例数,考察24h 新药利尿量(ml )是否相当于阳性药。
根据以往的疗效和统计学的一般要求,取α=0.05,β=0.20,非劣效界值 =﹣60ml ,已知两组共同标准差S=180ml ,假定新药与阳性对照药总体利尿量的差值θ=﹣20ml ,问每组需要多少病例?
k=1,T n =100,代入公式power=Φ(1.183)+Φ(-0.389)-1≈0.8816+0.3483-1=0.2299<0.80,所以T n =100过小,需继续增大样本含量进行迭代尝试……当T n =318时得power=0.8014>0.80.故试验组需要319例,对照组也需要319例。
4.单因素二水平设计定量资料的等效性检验时样本含量的估算
4.1计算公式(4-1)[1]:
1)1()1(])[()1()1(])[(2/122/12-⎪⎭
⎪⎬⎫⎪⎩⎪⎨⎧--++-+⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧--+--=--ααππδππφππδππφu k kn u k kn power T C T T C T 公式中的各参数:双侧检验水准α,允许犯第二类错误的概率不超过β,试验组与对照组总体率的差值为θ=πT -πC (πT 、πC 未知时可用样本频率估计),两组的平均有效率为π=(πT +πC )/2,等效界值为δ>0,对照组与试验组样本含量的比值为k ,即T C n n /=k ,或者C n =k T n 。
power 不小于1-β。
例题:某新药拟进行Ⅱ期临床试验,与阳性药按1:1的比例安排例数,考察新药临床治愈率是否相当于阳性药。
根据以往的疗效和统计学的一般要求,取α=0.05,β=0.20,非劣界值δ=﹣0.15,平均有效率P=0.80,并假定两组总体有效率相等,问每组需要多
少病例?
代入公式(4-1)估算得n≈150,即每组需要样本例数150例。
参考文献:
[1]胡良平主编.SAS实验设计与统计分析,人民卫生出版社,2010年,214-219
[2]刘明芝,周仁郁主编.中医药统计学与软件应用,中国中医药出版社,201-202.。