统计学论文(1)
统计学分析论文统计学数据分析

统计学分析论文统计学数据分析统计学分析论文篇1浅析加强统计学习提高统计分析水平【关键词】统计分析统计学习企业提高一、统计分析的重要性和作用完整的统计分析工作,通常都是通过综合运用统计数据进行统计分析工作,统计工作的作用是非常突出的,它可以充分发挥统计信息的咨询和监督职能,提高统计服务质量水平。
从而使统计分析在统计工作中占据着非常重要的地位。
从某种意义上说,统计分析的水平,在一定程度上可以反映一个单位的统计工作水平,是衡量一个单位统计水平的重要标志,对一个单位的统计分析有重要的阶段性作用。
通过统计分析,统计部门可以发挥优势,发挥与统计部门相关的整体功能的发挥,可以发现统计工作中的新问题,然后进行改革和创新统计工作,可以锻炼和培养出具有高素质的统计专业队伍力量,在统计工作中创造新优势,形成核心竞争力,人才一直是企业竞争的关键因素,综合力量的对比,最终也体现到人才的竞争上面,因此,对于统计工作来说也是一样,要重视对统计专业人才的培养,这样才能保证统计分析工作的正常进行。
二、统计分析技术统计分析技术的核心在于是不是有突破,即:研究的内容是新的,方法也是新的。
这里的统计分析技术强调的是创新,新的内容,新的方法,新的理念,等等,只有创新才能进行发展,才会有新的突破。
要求的新的内容:要定量分析,把握好经济发展的脉搏,对统计分析技能进行分析和了解,提高预警,预测能力,了解政策取向,在新的形势下,我们必须增加可以反映统计时间的因素,在统计分析中,时间要素很重要,有时候会对结果产生很大的影响。
四句话级别上做文章,抓迹象,看趋势,了解主要矛盾进行定量分析,了解自然现象的统计分析新方法的应用。
统计分析的过程应注意的一些问题。
垂直指数对比,各种相关的目标,反映客观经济现象是好还是坏,大小,速度等,揭露矛盾,找出差距,然后对经济现象进行比较分析。
通过国家,区域经济类型之间的所属单位之间的在同一时间不同的相关指标的具体比较分析。
统计方面论文优秀范文参考

统计方面论文优秀范文参考统计学工作是一项注重数据的准确、及时的基础性工作,是各级政府制定经济决策的重要依据。
下文是店铺为大家整理的关于统计方面论文的内容,欢迎大家阅读参考!统计方面论文篇1浅议金融稳健统计与金融监管摘要:我国商业银行资本充足率估计偏高,因此影响了对金融稳定性的衡量。
本文讨论了在金融危机背景下我国应如何从金融监管的角度应对商业银行资本充足率偏低的问题。
近些年来,随着市场经济的深入发展,中国的财政金融体制发生了巨大的变化,加入WTO后,中国面临着金融风险相互传递所带来的风险。
这对于构建稳健的金融体系造成了前所未有的挑战。
一、金融稳健统计在衡量金融稳定性中的地位:20世纪90年代以来,金融风暴在全球经济体系中造成了巨大的危害性。
随着金融业趋向全球化,全球金融市场之间的联系和依赖加强,金融风险在国家之间相互转移、扩散的趋势也在增强。
此时,在国际化的背景下,金融稳健统计成为了新时期维护国家经济稳定、提高金融体系稳定性的必然要求。
在货币与金融统计中,对金融稳定性的审慎分析包括金融监管统计和金融稳健统计。
其中,金融监管统计是从微观层面上,对单个金融机构的风险进行监管和统计,衡量的是个体风险;而金融稳健统计则是从宏观层面上,对各个金融机构的集体行为对宏观经济运行产生的影响进行分析和统计,衡量的是整个金融体系的风险,即系统风险。
金融稳健统计,是一个国家检测宏观金融风险、维护金融稳定的重要工作。
其核算基础是《国民经济核算》《国际会计准则》和《巴塞尔协议》,在对金融机构业务经营、信用状况的监控方面,金融稳健统计遵循审慎性原则,坚持《巴塞尔协议》中的CAMELS标准,它包括五项考核指标,即:资本充足状况,资产质量,收益与利润状况,流动性和对市场的敏感程度。
金融稳健统计涉及的统计对象包括存款机构部门、非银行金融机构、企业部门、住户部门、金融市场和房地产市场。
其中,对一国金融稳定影响最大的当属存款机构部门。
统计学论文(数据分析)

统计学论文(数据分析)统计学论文(数据分析)引言概述:统计学论文是一种重要的学术研究形式,它通过收集、整理和分析数据来揭示数据背后的规律和趋势。
数据分析是统计学论文的核心内容,它可以帮助我们了解数据的特征、关系和趋势,从而为决策提供科学依据。
本文将从数据收集、数据清洗、数据分析方法、结果解释和结论总结五个方面,详细介绍统计学论文中的数据分析过程。
一、数据收集:1.1 选择合适的数据源:在进行数据分析之前,首先需要确定数据的来源。
可以从公共数据库、调查问卷、实验记录等多种渠道获取数据。
1.2 确定数据采集方法:根据研究目的和数据特点,选择合适的数据采集方法。
可以采用观察、实验、调查等方法收集数据。
1.3 确保数据的可靠性和有效性:在数据收集过程中,应注意确保数据的可靠性和有效性。
可以通过多次观察、重复实验、合理设计问卷等方式提高数据的质量。
二、数据清洗:2.1 数据筛选和去除异常值:在数据分析之前,需要对数据进行清洗,筛选出符合研究目的的数据,并去除异常值,以保证数据的准确性和可靠性。
2.2 数据缺失值处理:在数据收集过程中,可能会出现数据缺失的情况。
对于缺失值,可以采用插补方法或者删除缺失数据的方式进行处理。
2.3 数据标准化和转换:为了方便数据的比较和分析,可以对数据进行标准化和转换。
常见的方法包括z-score标准化、对数转换等。
三、数据分析方法:3.1 描述性统计分析:描述性统计分析是对数据进行整体描述和总结的方法。
可以通过计算平均值、标准差、频数等指标,来了解数据的分布和变异情况。
3.2 探索性数据分析:探索性数据分析是通过可视化和图表分析等方法,发现数据中的模式和关系。
可以使用散点图、箱线图、直方图等图表来展示数据的特征。
3.3 推断性统计分析:推断性统计分析是通过对样本数据进行推断,来推断总体的特征和关系。
可以使用假设检验、方差分析、回归分析等方法进行推断。
四、结果解释:4.1 解释分析结果:在数据分析完成后,需要对分析结果进行解释。
统计学教学论文(5篇)

统计学教学论文(5篇)统计学教学论文(5篇)统计学教学论文范文第1篇对于统计学来说,其主要内容是学习统计的方法。
由于该科目的学习内容属于较为有用的理论学问,因此,要针对这一点向高职院校的同学进行学习思想的灌输。
要让同学熟悉到,学习统计学,并非是一项纯粹的理论学习,它在现实中的应用是多方面的。
而学会统计学,再学习本专业的其他专业课程的时候,就会倍感轻松。
转变同学为了学习而学习的态度,让同学明白,来到高职院校学习的目的是为了学习一种生存的技能,而并非是学习枯燥的理论学问而学习统计。
二、让统计学的教学理论联系实际如何让同学学好理论学问,让同学将理论与实际相结合,就要看老师如何引导教学。
例如一个大事的统计,通过不同的方法统计计算的结果肯定是不相同的,而最终大事得出的结论应当是相同的。
让同学明白各种统计方法的计算方式,是为了让同学在应对各种各样的大事时实行相应的解决方法,而并非是要同学做过多的无用之功。
统计学在教学的过程中要应当注意课堂与同学的互动,假如同学能够提出问题,就说明同学在课堂上是听讲的,千万不要解决问题的盼望寄予在课后。
由于高职院校的同学学习热忱本就不高,假如把问题留在课下,期盼于同学在课下解决,那是几乎不行能的。
因此对于课堂上同学提出的问题肯定要让同学当堂解决。
在关心同学解决问题的时候,需要留意的是,不要直接告知同学该问题的答案或结论是什么。
要让同学自己去思索,老师所起到的作用是引导同学,启发同学,朝着答案的方向去进行思索。
在叙述理统计学的理论内容的时候,老师可以举出实际例子,让同学清晰明白的学习统计学的统计方法。
三、实施项目教学方法项目教学法是一种特别普遍的统计学教学方法,这种方法可以让同学更加深刻的理解统计学所讲叙述的内容。
在统计学的教学内容中,主要是叙述统计方法统计计算等内容。
在这样的状况下,可以让同学形成小组式学习,4-5人为一个学习小组。
在这个教学方法中值得一提的是,它可以培育同学的团队协作力,这在统计工作中是特别重要的一种力量。
统计学论文(数据分析)
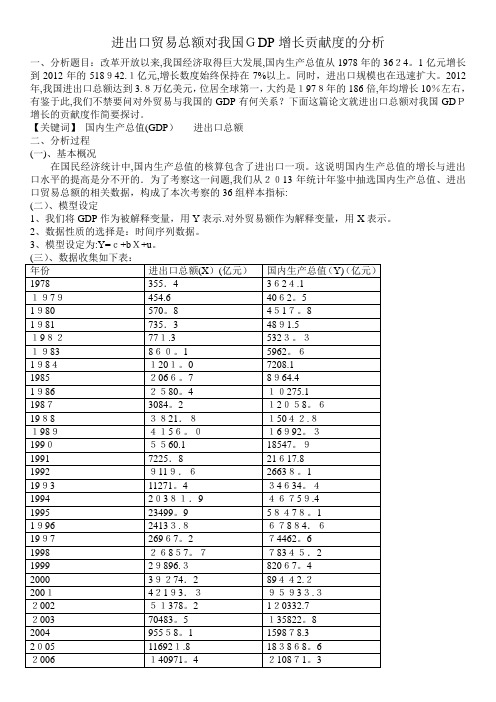
进出口贸易总额对我国GDP增长贡献度的分析一、分析题目:改革开放以来,我国经济取得巨大发展,国内生产总值从1978年的3624。
1亿元增长到2012年的518942.1亿元,增长数度始终保持在7%以上。
同时,进出口规模也在迅速扩大。
2012年,我国进出口总额达到3.8万亿美元,位居全球第一,大约是1978年的186倍,年均增长10%左右,有鉴于此,我们不禁要问对外贸易与我国的GDP有何关系?下面这篇论文就进出口总额对我国GDP增长的贡献度作简要探讨。
【关键词】国内生产总值(GDP)进出口总额二、分析过程(一)、基本概况在国民经济统计中,国内生产总值的核算包含了进出口一项。
这说明国内生产总值的增长与进出口水平的提高是分不开的.为了考察这一问题,我们从2013年统计年鉴中抽选国内生产总值、进出口贸易总额的相关数据,构成了本次考察的36组样本指标:(二)、模型设定1、我们将GDP作为被解释变量,用Y表示.对外贸易额作为解释变量,用X表示。
2、数据性质的选择是:时间序列数据。
3、模型设定为:Y=c+bX+u。
:http://www。
stats。
gov.cn/tjsj/ndsj/((四)、参数估计:我们用Eviews做回归分析.假定模型中随机项满足基本假定,可用OLS(最小二乘估计)法估计其参数。
具体操作:用EVie ws软件,估计结果为:表2:Dependent Variable:YMethod:Least SquaresDate: 12/14/13Time: 21:43Sample:1978 2013Includedobservations:36cient Error51 00 7X 1.428362 0。
179077。
9761440.00006065 var 0AdjustedR-squ ared0.862295S.D。
dependent var 84346.3S。
E. of regression 31299。
统计学课程论文(5篇)

统计学课程论文(5篇)统计学课程论文(5篇)统计学课程论文范文第1篇自1998年之后,统计学课程两次被教育部列为高等学校经济学类各专业的共同核心课程和工商管理类各专业的九门核心课程之一。
2000年,教育部还特地组织力气进行讨论,为统计学课程的教学确定了基本教学要求、详细教学内容和教学要点,指出统计学“不是着重于统计方法数学原理的推导,而是侧重于阐明统计方法背后隐含的统计思想,以及这些方法在实际各领域中的详细应用②”。
至此,统计学的主要教学内容也被明确了下来,主要包括绪论、描述统计、推断统计、经济管理中采纳的统计方法和国民经济统计基础学问等。
在教育部的指挥棒下,统计学老师开头了统计学教学的讨论探究、试验论证和改革创新。
统计学也由此开头肩负起培育同学统计学问方面的基本技能和应用统计方法发觉、分析、解决问题的力量之重任。
二、当前高校统计学课程的教学现状一提到统计学,同学普遍反映难学、难懂、难理解,广阔老师也倍感难讲、难教、难入心。
教育部虽然统一确定了统计学课程的主要教学内容和基本教学要求,从人才培育的角度提出了课程性质和地位、教学任务及总体要求,但是各高校在开展统计学教学过程中还应结合本校实际对其提出详细要求或做出适当调整。
可是圆满的是,在调查中笔者发觉很多高校生搬硬套,从而导致当前统计学课程教学中仍存在以下共性问题。
第一,教材选用的针对性不强,教材建设落后于实践需要。
很多老师在教材选用过程中完全不考虑学校层次、生源质量、专业设置、师资结构等实际状况的差异而盲目选择,甚至消失了一本、二本和三本院校选用同一本统计学教材的怪相。
因此,老师在教学中只能随机自行删减、调整内容,基本教学要求根本得不到保证。
另外,目前国内有些统计学教材完全忽视从应用层面上介绍统计学在专业领域的运用,从而导致有些同学把统计学课程当成了一门高等数学课程,把统计学教材当作一本数学书籍。
其次,教学大纲设计严峻滞后,学时少、内容多的冲突尖锐。
统计分析论文六篇

统计分析论文六篇统计分析论文范文1统计学中常用的概念有总体与样本、随机化与概率、计量与计数、等级资料及正态与偏态分布资料、标准差与标准误等。
如某讨论采纳经会阴途径测定宫颈长度,以探讨不同宫颈长度与临产时间的关系。
结果显示35例宫颈长度为25~34mm者与32例宫颈长为15~24mm者临产时间的均值±标准差(x±s)各为57.6±58.1与47.3±49.1小时。
该计量资料,经t 检验显示t=0.780,P0.05,并未提示不同宫颈长度的临产时间差异有显著意义;从标准差大于均值,显示各变量值离散程度大,呈偏态分布,故不能采纳x±s这一算术均数法计算均数。
经偏态转换成近似正态分布资料后结果是:35例与32例的临产时间各为34.5±4.1与26.7±4.1小时,(t=7.778,P0.001),两组差异有极显著意义。
可认为随着宫颈长度的缩短、临产时间也缩短。
此外,当两组资料单位不同时,其S单位也不同;即使两组单位相同的变量值,若其均数差异较大,也都应以变异系数替代s来比较两组值的离散度的大小。
二、正常值范围及特别阈值的确定如何选择讨论对象,至少需多少例,正确统计处理和参考肯定数量的病例数据,是确定正常值范围及特别阈值的四个重要因素。
1.讨论对象:应为“完全健康者”,可包括患有不影响待测指标疾病的患者。
如“正常妊娠”的条件:孕前月经周期规章、单胎、妊娠过程顺当、无产科并发症及其它有关合并症,分娩孕周为37~41周+6,新生儿诞生体重为2500~4000g和Apgar评分≥7分。
2.观看数量:观看数量应尽可能多于100例;需分组者,各组人数也是如此(标原来源困难时酌情削减)。
有些指标值如雌三醇(E3)、甲胎蛋白(AFP)、胎盘泌乳素(HPL)等随孕周进展而变化,应按孕周分组;邻近孕周均数相近者,可合并几周计算。
若为偏态分布,应以百分位数计算,则例数应≥120例。
统计学论文范文字

统计学论文范文字第一篇:统计学论文范文的写作要点在如今这个数据时代,统计学成为了越来越重要的学科之一。
无论是商务、医疗、工业等领域,都需要用到统计学的知识和方法,来帮助人们进行数据分析和决策制定。
而在统计学研究中,论文是重要的成果之一。
因此,掌握统计学论文的写作要点,对于统计学研究者来说是非常必要的。
首先,统计学论文要写得简洁明了。
这一点是写任何学科的论文都应该注意的,但对于统计学论文来说,更加重要。
在进行数据分析的过程中,我们需要面对大量的数据、数学公式等内容,因此如果论文写作不够简洁明了,读者就很容易失去兴趣,难以理解和吸收。
因此,我们在撰写统计学论文时,应当尽可能的精炼语言,提高逻辑性和条理性。
其次,统计学论文需要具备严密的逻辑性。
在进行数据分析的过程中,每一个环节都需要符合一定的逻辑关系,因此我们在撰写统计学论文时,也需要遵守这种逻辑性。
例如,在研究中需要先进行数据描述,再进行统计分析,最后提出结论等等。
如果在写作过程中缺乏逻辑性,就会导致研究方法的不严谨,进而影响整个研究的可信度。
第三,统计学论文需要注重方法的细节。
统计学研究是一项细致而繁琐的过程。
因此,我们在写作过程中,必须注重方法的细节,例如与数据相关的前期处理,模型的选择和参数的确定等等。
如果某一步骤出现问题,就会导致偏差的出现,进而影响研究的结果和结论的可靠性。
综上所述,统计学论文的写作要点主要包括简洁明了、逻辑性强和注重方法的细节。
只有做到这三点,才能写出高质量的统计学论文,并为数据分析和决策制定提供更加有效的帮助。
第二篇:统计学论文范文的格式要求除了写作要点之外,统计学论文范文的格式要求也非常重要。
因为良好的论文格式可以帮助读者更加轻松地理解和吸收研究内容,同时也有助于规范和简化研究结果的展示形式。
首先,统计学论文的格式要求应当与学术界的规定一致。
例如,学术论文的引用格式一般遵循APA规则,数据表格和图片的格式也有特定的要求。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学论文《商务统计学》结课论文(2013-2014学年度第1学期)关于中国各省市消费水平变化状况分析统计研究报告2013年12月3日目录一、不同地区居民消费水平分析及分组二、有关相对指标的计算三、有关序时平均数的计算四、有关增长量和速度指标的计算(一)增长量的计算(二)速度指标的计算五、关于中国各省市消费水平变化状况回归分析六、有关离散程度即趋势分析1998-2008年各省市区居民消费水平的有关标志变异指标及其趋势分析摘要:居民消费水平是指居民在物质产品和劳务的消费过程中,对满足人们生存、发展和享受需要方面所达到的程度。
通过消费的物质产品和劳务的数量和质量反映出来,反映消费水平的消费结构指标和平均消费量的价值指标。
居民的消费水平能反映一个国家经济发展状况的好坏,更能反映出居民生活水平的高低。
本文以1998-2008年统计数据运用统计学基本知识对我国城居民收入和消费水平之间的关系进行了分析,并在此基础上提出一些相关建议。
关键词:居民收入国家经济发展消费水平居民生活水平一、不同地区居民消费水平分析及分组本文采用经济地带的不同,来对各省市区进行分组,将各省市区分为东部远海地区、中部内陆地区、西部边远地区,分组状况如下表所示:表一各省市区域分布概括地区地名数量西部沿海地区北京、天津、河北、辽宁、上海、江苏、浙江、福建、山东、广东、广西、海南、重庆13中部内陆地区山西、内蒙古、吉林、黑龙江、安徽,江西、河南、湖北、湖南9西部边远地区四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆9总计31 经济地带分布直方图如下图所示我们再采用世界银行的通用做法,用各城市居民消费水平相对于整个经济域居民消费水平的相对量来分类,即按各城市十余年来居民消费水平与十余年来整个经济域的平均居民消费水平的百分比,将各省市区群分为A 、B 、C 、D 四类区域: A 类区域平均居民消费水平低于整个经济区平均居民消费水平的70%,属居民生活水平偏低地区;B 类区域平均居民消费水平在整个经济域平均居民消费水平的70%至100%之间,属居民生活水平较低地区;C 类区域平均居民消费水平在整个经济域平均居民消费水平的100%至150%之间,属居民生活水平为中等地区;D 类区域平均居民消费水平在整个经济域平均居民消费水平的150%以上,属居民生活水平较高的地区。
根据附表3中第(14)列的计算结果, 各省市区的区域划分如下表所示:表二 各省市区区域类型划分2 4 6 8 10 12 14东部沿海地区 中部内陆地区 西部边远地区系列1区域 类型 比值 各省市区数量A 类<70% 山西、安徽、江西、河南、云南、西藏、陕西、甘肃、青海、贵州10B 类 70%-100% 四川、内蒙古、吉林、黑龙江、湖北、湖南、海南、重庆市、宁夏、广西、新疆、河北 12C 类 100%-150% 辽宁、江苏、福建、山东4 D 类 >150%北京市、天津市、上海市、浙江、广东5根据上述表格,可得各省市区域类型划分直方图,如下所示:从上图可以看出,全国各省市居民平均消费水平处于偏低和较低水平的省市偏多二、有关相对指标的计算2 4 6 810 12 A 类 B 类 C 类 D 类各省市区域类型划分A 类B 类C 类D 类结构相对指标的计算公式为:结构相对指标=根据此公式可以算出2008年全国各省市人口在全国的结构相对指标,计算结果如下图所示:总量指标;居民消费总额2008年 2008年 所占比例 单位 万元 亿元北京市 26513370 2651.337 0.032435 天津市 11356300 1135.63 0.013893 河北省 34110610 3411.061 0.041729 山西省 16345125 1634.513 0.019996 内蒙古自治区 13902600 1390.26 0.017008 辽宁省 29593759 2959.376 0.036203 吉林省 15548330 1554.833 0.019021 黑龙江省 19654043 1965.404 0.024044 上海市 38013360 3801.336 0.046503 江苏省 62680100 6268.01 0.076679 浙江省 55581780 5558.178 0.067995 安徽省 27134510 2713.451 0.033195 福建省 27844908 2784.491 0.034064 江西省 18106647 1810.665 0.022151 山东省 65395725 6539.573 0.080001 河南省435037444350.3740.05322总体各组(部分)数值总体总数值湖北省31499369 3149.937 0.038534湖南省34868316 3486.832 0.042656广东省 1.01E+08 10100 0.123557广西20433270 2043.327 0.024997海南省3959296 395.9296 0.004844重庆市15210936 1521.094 0.018608四川省36768669 3676.867 0.044981贵州省13145743 1314.574 0.016082云南省18268225 1826.823 0.022348 西藏自治区819115 81.9115 0.001002 陕西省14835420 1483.542 0.018149甘肃省7322860 732.286 0.008958青海省2317492 231.7492 0.002835宁夏回族自治区3077424 307.7424 0.003765维吾尔族自治区8622300 862.23 0.010548 全国81743.33 1由上表可知,广东省、山东省、浙江省、江苏省的居民总消费额较高、其中广东省的最高;西藏、青海省、宁夏的居民总消费额偏低。
其中西藏的最低,三、有关序时平均数的计算(一)居民平均消费水平的计算1、1998—2008年期间各年各省市区居民平均消费水平的计算计算公式为:某年某城市居民平均消费水平=某年某城市居民消费总额某年某城市人口数计算结果如附表3所示第(1)—(12)列所示。
2、1998-2008年各省市区居民平均消费水平的计算。
计算公式为:1998-2008年居民消费平均水平计算属于序时平均数的计算,且为一般序时平均数的计算,由于1998-2008年各省的居民消费水平为时期数列,其序时平均数计算公式为: 。
1998-2008年各省市人口数为时点数列,属于间隔相等的间断时点数列的序时平均数计算,其序时平均数计算公式为:计算结果如附表3的第(12)列所示。
2、1998-2008年全国居民平均消费水平的计算。
计算公式为:整个经济区人均GDP=1998-2008年全国居民消费总额的序时平均数 1998-2009年全国人口总数的序时平均数由于1998-2008年全国居民消费总额为时期数列,其序时平均数计算公式,1998-2008年全国人口总数为时点数列,属于间隔相等的间断时点数列的序1998-2008年某城市 居民平均消费水平 = 1998-2008年某城市 居民消费的序时平均数1998-2008年某城市人口的序时平均数a =012.......1122na a a a n ++++时平均数计算,其序时平均数计算公式为:,计算结果如附表3的(14)列所示。
计算结果表明:北京市、上海市、广东省的居民平均消费水平普遍偏高。
其中上海市居民平均消费水平最高;西藏、陕西省、贵州省的居民平均消费水平偏低,居民生活水平不高。
四、有关增长量和速度指标的计算(一)增长量的计算。
计算公式为:逐期增长量=报告期水平-前一期水平累计增长量=报告期水平-某一固定基期水平计算结果如附表4的2、3行所示。
(二)速度指标的计算。
计算公式为:环比发展速度=定基发展速度=环比增长速度=环比发展速度-1定基增长速度=定基发展速度-1每增长1%的绝对值=基期水平×1%计算结果如附表4第4、5、6、7、8行所示。
五、各省市消费水平变化状况回归分析变量 1 变量 2平均26368817.61 5108.95833方差 4.72413E+14 200128930观测值31 32df 30 31F 2360543.015P(F<=f) 单尾 2.92921E-91F 单尾临界 1.828344754回归统计Multiple R 1R Square 1Adjusted R Square 1标准误差209.7661184观测值31①由回归统计中的R=1看出,所建立的回归模型对样本观测值的拟合程度一般,综合其相关系数值可知此二者关系不太符合所建立的线性模型,说明二者间没有密切的线性相关关系。
②由回归统计中的R=1看出,所建立的回归模型对样本观测值的拟合程度很好方差分析df SS MS回归分析 1 1.4172E+16 1.41724E+16 残差29 1276052.91 44001.82442 总计30 1.4172E+16Coefficients 标准误差t StatIntercept -170.4698037 59.8182614 -2.849795357 X Variable 1 817437813.1 1440.35167 567526.5478由上表中â和βˆ的p值分别是-2.849795357和567526.5478,显然â的p的值小于显著性水平,不能拒绝原假设α=0,而βˆ的p值远小于显著性水平,拒绝原假设β=0,说明各省市消费水平有显著影响。
六、有关离散程度即趋势分析1.1998-2008年各省市区居民消费水平的有关标志变异指标及其趋势分析。
各省市居民消费水平的差异程度,结果如下表所示:年份最大值最小值绝对差异相对差异全距标准差全距率变异系数1998年7282(上海)1312(西藏)59701390.2375.5503050.5255131999年8229(上海)1417(西藏)67561581.7015.5865580.5450932000年8896(上海)1551(西藏)73451718.0745.7356540.5689722001年9683(上海)1819(甘肃)78641859.0225.3232550.5814542002年10922(上海)1947(甘肃)89752022.0425.6096560.5815912003年11807(上海)2099(甘肃)97082162.5965.62506 0.5848272004年13137(上海)2301(甘肃)108362470.8195.7092570.6057752005年14247(上海) 2502(贵州)117452715.779 5.694245 0.601542006年16470(上海) 2723(贵州)13747 3107.581 6.048476 0.6061022007年18396(上海) 3019(西藏)15377 3442.988 6.093408 0.5938892008年20944(上海) 2810(甘肃)18134 3969.9917.4533810.61269各省市居民平均消费水平标准差变化趋势下图所示各省市居民平均消费水平全距变化如下图所示各省市居民消费水平标准差变化趋势5001000 1500 2000 2500 3000 3500 4000 45001998年 2000年 2002年 2004年 2006年 2008年系列1各省市居民平均消费水平全距率变化趋势如下图所示从绝对差异来看: 全距和标准差总体上呈逐年上升趋势,且变化幅度逐渐增大,处于缓冲期,二者的最大值都出现在2008年;从相对差异来看:全距率的变化幅度较小,而变异系数变化幅度较大,波动多,而且都呈现逐年下降的趋势;全距率在2000年为最低,2008年最大,其后除了仅在2001年出现波谷之外,后截曲线呈缓慢上升的趋势;而变异系数曲线在2001年---2004年变化小,发展平稳,其余若干年波动较大,2004年之后一年该系数迅速上升,2005年 ---2008年 变化较大,时而下降,时而上升。