广度优先搜索遍历连通图
图的连通性判断算法的时间复杂度

图的连通性判断算法的时间复杂度图是数学中一种常见的数据结构,在计算机科学中也有广泛的应用。
图由节点(顶点)和边组成,表示了不同元素之间的关系。
在图中,如果每个节点都可以通过路径相互到达,则该图被称为连通图,否则被称为非连通图。
图的连通性判断算法指的是判断给定的图是否是连通图的问题。
常见的图的连通性判断算法包括深度优先搜索(DFS)和广度优先搜索(BFS)算法。
接下来,将分别介绍这两种算法,并分析它们的时间复杂度。
一、深度优先搜索(DFS)算法深度优先搜索算法是一种递归的算法,通过访问节点的方式来遍历整个图。
DFS算法首先选择一个节点作为起始节点,然后通过递归地访问与该节点相邻的节点,直到没有未访问过的节点。
如果所有的节点都被访问过,则图是连通的;否则,图是非连通的。
DFS算法的时间复杂度取决于图的大小和结构。
假设图有n个节点和m条边,那么DFS算法的时间复杂度为O(n + m)。
在最坏的情况下,每个节点都需要被访问一次,并且每个节点都需要遍历它的所有相邻节点。
二、广度优先搜索(BFS)算法广度优先搜索算法是一种迭代的算法,通过按层级的方式遍历整个图。
BFS算法首先选择一个节点作为起始节点,然后按照从起始节点开始的顺序,依次访问每个节点的所有相邻节点。
通过不断扩展搜索的范围,直到所有节点都被访问过。
如果所有的节点都被访问过,则图是连通的;否则,图是非连通的。
BFS算法的时间复杂度也取决于图的大小和结构。
假设图有n个节点和m条边,那么BFS算法的时间复杂度为O(n + m)。
在最坏的情况下,每个节点都需要被访问一次,并且每次访问时都需要遍历其所有相邻节点。
总结:图的连通性判断算法的时间复杂度分别为O(n + m)的DFS算法和BFS算法。
其中,n表示图的节点数,m表示图的边数。
这两种算法在连通性判断问题上表现良好,并且可以在较短的时间内找到问题的解答。
需要注意的是,虽然DFS和BFS可以用于判断图的连通性,但它们在处理大规模图时可能存在效率问题。
广度优先搜索的原理及应用是什么

广度优先搜索的原理及应用是什么1. 原理广度优先搜索(Breadth-First Search, BFS)是一种图的遍历算法,它从图的起始顶点开始,逐层地向外探索,直到找到目标顶点或者遍历完整个图。
通过利用队列的数据结构,广度优先搜索保证了顶点的访问顺序是按照其距离起始顶点的距离递增的。
广度优先搜索的基本原理如下:1.选择一个起始顶点,将其加入一个待访问的队列(可以使用数组或链表实现)。
2.将起始顶点标记为已访问。
3.从队列中取出一个顶点,访问该顶点,并将其未访问过的邻居顶点加入队列。
4.标记访问过的邻居顶点为已访问。
5.重复步骤3和步骤4,直到队列为空。
广度优先搜索保证了先访问距离起始点近的顶点,然后才访问距离起始点远的顶点,因此可以用来解决一些问题,例如最短路径问题、连通性问题等。
2. 应用广度优先搜索在计算机科学和图论中有着广泛的应用,下面是一些常见的应用场景:2.1 最短路径问题广度优先搜索可以用来找出两个顶点之间的最短路径。
在无权图中,每条边的权值都为1,那么从起始顶点到目标顶点的最短路径就是通过广度优先搜索找到的路径。
2.2 连通性问题广度优先搜索可以用来判断两个顶点之间是否存在路径。
通过从起始顶点开始进行广度优先搜索,如果能够找到目标顶点,就说明两个顶点是连通的;如果搜索完成后仍然未找到目标顶点,那么两个顶点之间就是不连通的。
2.3 图的遍历广度优先搜索可以用来遍历整个图的顶点。
通过从起始顶点开始进行广度优先搜索,并在访问每个顶点时记录下访问的顺序,就可以完成对整个图的遍历。
2.4 社交网络分析广度优先搜索可以用来分析社交网络中的关系。
例如,在一个社交网络中,可以以某个人为起始节点,通过广度优先搜索找出与该人直接或间接连接的人,从而分析人际关系的密切程度、社区结构等。
2.5 网络爬虫广度优先搜索可以用来实现网络爬虫对网页的抓取。
通过从初始网页开始,一层层地向外发现新的链接,并将新的链接加入待抓取的队列中,从而实现对整个网站的全面抓取。
离散数学图的连通性判定算法

离散数学图的连通性判定算法离散数学中,图是研究事物之间关系的一种可视化表示方式。
而图的连通性判定算法是判断图中各个节点之间是否存在连通路径的一种方法。
本文将介绍常用的离散数学图的连通性判定算法,并对其进行详细说明。
一、深度优先搜索算法深度优先搜索算法(Depth First Search,简称DFS)是一种用于遍历图或树的搜索算法。
在图的连通性判定中,DFS算法可以用于检测一个图是否是连通图。
算法步骤如下:1. 选择一个起始节点作为当前节点,并将其标记为已访问;2. 从当前节点出发,沿着一条未访问的边到达相邻节点;3. 若相邻节点未被访问,则将其标记为已访问,并将其设为当前节点,重复步骤2;4. 若当前节点的所有相邻节点都已被访问,则回溯到上一个节点,重复步骤3,直到回溯到起始节点。
通过DFS算法,我们可以遍历图中的所有节点,并判断图的连通性。
若在遍历过程中,所有节点都被访问到,则图是连通的;否则,图是非连通的。
二、广度优先搜索算法广度优先搜索算法(Breadth First Search,简称BFS)也是一种用于遍历图或树的搜索算法。
在图的连通性判定中,BFS算法同样可以用于判断图是否为连通图。
算法步骤如下:1. 选择一个起始节点作为当前节点,并将其标记为已访问;2. 将当前节点的所有相邻节点加入一个队列;3. 从队列中取出一个节点作为当前节点,并将其标记为已访问;4. 将当前节点的所有未访问的相邻节点加入队列;5. 重复步骤3和步骤4,直到队列为空。
通过BFS算法,我们可以逐层遍历图中的节点,并判断图的连通性。
若在遍历过程中,所有节点都被访问到,则图是连通的;否则,图是非连通的。
三、并查集算法并查集算法(Disjoint Set Union,简称DSU)是一种用于处理一些不相交集合的数据结构。
在图的连通性判定中,并查集算法可以用于判断图的连通性。
算法步骤如下:1. 初始化并查集,将每个节点设为一个单独的集合;2. 对于图中的每一条边(u, v),判断节点u和节点v是否属于同一个集合;3. 若节点u和节点v属于不同的集合,则将它们合并为一个集合;4. 重复步骤2和步骤3,直到遍历完所有边。
第7章图的深度和广度优先搜索遍历算法
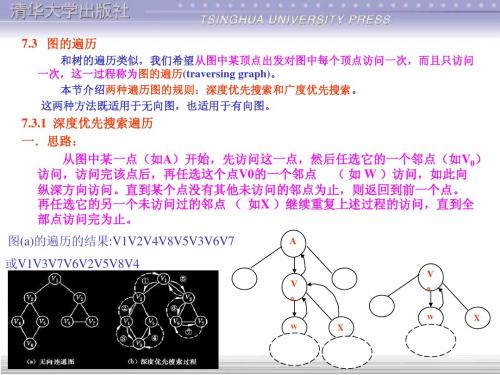
和树的遍历类似,我们希望从图中某顶点出发对图中每个顶点访问一次,而且只访问 一次,这一过程称为图的遍历(traversing graph)。 本节介绍两种遍历图的规则:深度优先搜索和广度优先搜索。 这两种方法既适用于无向图,也适用于有向图。
7.3.1 深度优先搜索遍历 一.思路: 从图中某一点(如A)开始,先访问这一点,然后任选它的一个邻点(如V0) 访问,访问完该点后,再任选这个点V0的一个邻点 ( 如 W )访问,如此向 纵深方向访问。直到某个点没有其他未访问的邻点为止,则返回到前一个点。 再任选它的另一个未访问过的邻点 ( 如X )继续重复上述过程的访问,直到全 部点访问完为止。 图(a)的遍历的结果:V1V2V4V8V5V3V6V7 或V1V3V7V6V2V5V8V4
p
v0 w x v 1
V
0
v 2
V
0
typedef struct {VEXNODE adjlist[MAXLEN]; // 邻接链表表头向量 int vexnum, arcnum; // 顶点数和边数 int kind; // 图的类型 }ADJGRAPH;
W W
X
X
7.3.2 广度优先搜索遍历 一.思路:
V
0
A V
0
W W
XXΒιβλιοθήκη 二.深度优先搜索算法的文字描述: 算法中设一数组visited,表示顶点是否访问过的标志。数组长度为 图的顶点数,初值均置为0,表示顶点均未被访问,当Vi被访问过,即 将visitsd对应分量置为1。将该数组设为全局变量。 { 确定从G中某一顶点V0出发,访问V0; visited[V0] = 1; 找出G中V0的第一个邻接顶点->w; while (w存在) do { if visited[w] == 0 继续进行深度优先搜索; 找出G中V0的下一个邻接顶点->w;} }
广搜的理解 -回复

广搜的理解-回复广搜是指广度优先搜索算法,是图的一种搜索策略。
它从一个节点开始,遍历其所有邻居节点,然后再逐层地遍历每个邻居节点的邻居节点,直到遍历完整个图。
广搜主要用于解决图中的路径问题,如求最短路径、连通性问题等。
广搜的基本思想是通过队列来实现,首先将起始节点加入队列,然后从队列中取出一个节点,访问并标记,再将该节点的邻居节点依次加入队列。
接下来,取出队列中的下一个节点,继续访问并标记,再将其未被访问过的邻居节点加入队列。
如此循环,直到队列为空。
与深度优先搜索(DFS)相比,广度优先搜索能够找到最短路径,而深度优先搜索可能会找到更长的路径。
广搜的时间复杂度为O(V+E),其中V 为节点数,E为边数。
在最坏情况下,广搜需要遍历整个图。
在实际应用中,广搜被广泛应用于解决迷宫问题、连通性问题等。
下面将以迷宫问题为例,详细介绍广搜算法的步骤和流程。
迷宫问题是指在一个矩阵中,从起始点出发,找到一条到达目标点的最短路径。
路径只能通过相邻的空地(非墙壁)。
首先我们需要构建一个迷宫矩阵,其中包含起始点、目标点以及墙壁。
假设迷宫矩阵为一个二维数组maze,0代表空地,1代表墙壁,起始点为maze[startX][startY],目标点为maze[targetX][targetY]。
接下来,我们可以定义一个队列queue来存储待访问的节点。
一开始,我们将起始点加入队列,并将其标记为已访问。
同时,我们可以定义一个二维数组visited,用来记录每个节点是否已经被访问过。
然后,我们进入循环,直到队列为空。
在循环中,我们从队列中取出一个节点,记为curr,并获取其坐标currX和currY。
然后,我们遍历curr 的上下左右四个邻居节点。
对于每个邻居节点,首先需要判断其是否为空地且未被访问过。
如果满足条件,则将该邻居节点加入队列,并将其标记为已访问。
同时,我们可以记录当前节点的前驱节点,即通过哪个节点到达当前节点。
若遍历到目标节点,则表示已经找到最短路径,此时我们可以通过回溯从目标节点一直追溯到起始点,即可得到最短路径。
数据结构与算法 图的遍历与连通性

数据结构与算法图的遍历与连通性数据结构与算法:图的遍历与连通性在计算机科学中,数据结构和算法是解决各种问题的基石。
其中,图作为一种重要的数据结构,其遍历和连通性的研究具有至关重要的意义。
让我们先来理解一下什么是图。
简单来说,图是由顶点(也称为节点)和边组成的结构。
顶点代表了事物或者对象,而边则表示顶点之间的关系。
例如,在一个社交网络中,人可以被视为顶点,而人与人之间的好友关系就是边。
图的遍历是指按照一定的规则访问图中的所有顶点。
常见的图遍历算法有深度优先遍历和广度优先遍历。
深度优先遍历就像是一个勇敢的探险家,一头扎进未知的领域,勇往直前,直到走投无路,然后回溯。
它的基本思想是先访问一个顶点,然后沿着一条未访问过的边递归地访问下一个顶点,直到没有可访问的边,再回溯到之前的顶点,继续探索其他未访问的边。
想象一下你在一个迷宫中,选择一条路一直走到底,直到遇到死胡同或者已经没有新的路可走,然后再返回之前的岔路口,选择另一条路继续前进。
广度优先遍历则像是一个谨慎的旅行者,逐层探索。
它先访问起始顶点,然后依次访问其所有相邻的顶点,再依次访问这些相邻顶点的相邻顶点,以此类推。
这就好比你在散播消息,先告诉离你最近的人,然后他们再告诉他们附近的人,一层一层地传播出去。
那么,为什么我们要进行图的遍历呢?这是因为通过遍历图,我们可以获取图的各种信息,比如顶点之间的关系、图的结构特点等。
在实际应用中,图的遍历有着广泛的用途。
例如,在搜索引擎中,通过遍历网页之间的链接关系来抓取和索引网页;在社交网络分析中,遍历用户之间的关系来发现社区结构等。
接下来,我们谈谈图的连通性。
连通性是指图中顶点之间是否存在路径相连。
如果从图中的任意一个顶点都可以到达其他任意一个顶点,那么这个图就是连通图;否则,就是非连通图。
判断图的连通性是一个重要的问题。
一种常见的方法是从某个顶点开始进行遍历,如果能够访问到所有的顶点,那么图就是连通的;否则,图是非连通的。
图论及其应用习题答案

图论及其应用习题答案图论及其应用习题答案图论是数学的一个分支,研究的是图的性质和图之间的关系。
图是由节点和边组成的,节点表示对象,边表示对象之间的关系。
图论在计算机科学、电子工程、物理学等领域有着广泛的应用。
下面是一些图论习题的解答,希望对读者有所帮助。
1. 问题:给定一个无向图G,求图中的最大连通子图的节点数。
解答:最大连通子图的节点数等于图中的连通分量个数。
连通分量是指在图中,任意两个节点之间存在路径相连。
我们可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历图,统计连通分量的个数。
2. 问题:给定一个有向图G,判断是否存在从节点A到节点B的路径。
解答:我们可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历图,查找从节点A到节点B的路径。
如果能够找到一条路径,则存在从节点A到节点B的路径;否则,不存在。
3. 问题:给定一个有向图G,判断是否存在环。
解答:我们可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历图,同时记录遍历过程中的访问状态。
如果在搜索过程中遇到已经访问过的节点,则存在环;否则,不存在。
4. 问题:给定一个加权无向图G,求图中的最小生成树。
解答:最小生成树是指在无向图中,选择一部分边,使得这些边连接了图中的所有节点,并且总权重最小。
我们可以使用Prim算法或Kruskal算法来求解最小生成树。
5. 问题:给定一个有向图G,求图中的拓扑排序。
解答:拓扑排序是指将有向图中的节点线性排序,使得对于任意一条有向边(u, v),节点u在排序中出现在节点v之前。
我们可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历图,同时记录节点的访问顺序,得到拓扑排序。
6. 问题:给定一个加权有向图G和两个节点A、B,求从节点A到节点B的最短路径。
解答:我们可以使用Dijkstra算法或Bellman-Ford算法来求解从节点A到节点B的最短路径。
这些算法会根据边的权重来计算最短路径。
图的各种算法(深度、广度等)

vex next 4 p
3
2 ^
2
^
5
5 5 4 3 2 1 0 ^
^
4 ^
top
4
输出序列:6 1
1 2 3 4 5 6
in link 0 2 ^ 1 0 2 0
vex next 4 p
3
2 ^
2
^
5
5 5 4 3 2 1 0 ^
^
4 ^
top 4
输出序列:6 1
1 2 3 4 5 6
in link 0 2 ^ 1 0 2 0
c a g b h f d e
a
b h c d g f
e
在算法中需要用定量的描述替代定性的概念
没有前驱的顶点 入度为零的顶点 删除顶点及以它为尾的弧 弧头顶点的入度减1
算法实现
以邻接表作存储结构 把邻接表中所有入度为0的顶点进栈 栈非空时,输出栈顶元素Vj并退栈;在邻接表中查找 Vj的直接后继Vk,把Vk的入度减1;若Vk的入度为0 则进栈 重复上述操作直至栈空为止。若栈空时输出的顶点个 数不是n,则有向图有环;否则,拓扑排序完毕
^
4
^
top
输出序列:6 1 3 2 4
1 2 3 4 5 6
in link 0 0 ^ 0 0 0 0
vex next 4
3
2 ^
2
^
5
5 5 4 3 2 1 0 ^ p
^
4
^topBiblioteka 5输出序列:6 1 3 2 4
1 2 3 4 5 6
in link 0 0 ^ 0 0 0 0
vex next 4
w2 w1 V w7 w6 w3
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
韩山师范学院
实验题目:
用邻接表实现广度优先搜索遍历连通图的算法实现
班级:2015级软工班作者:黄俊聪
#include<iostream>
using namespace std;
#define MVNum 100//最大顶点数
#define OK 1
#define ERROR 0
typedefint Status;
typedef char VerTexType;
typedefintOtherInfo;
bool visited[MVNum];
typedefstructArcNode//边结点
{
intadjvex;//该边所指向的顶点的位置
structArcNode* nextarc;//指向下一条边的指针
OtherInfo info;//和边相关的信息
}ArcNode;
typedefstructVNode//顶点信息
{
VerTexType data;
ArcNode* firstarc;//指向第一条依附该顶点的边的指针}VNode,AdjList[MVNum];//Adjlist表示邻接表类型
typedefstruct
{
AdjList vertices;
intvexnum,arcnum;//图的当前顶点数
}ALGraph;
typedefstructQNode
{
char data;
structQNode* next;
}QNode,*QueuePtr;
typedefstruct
{
QueuePtr front;
QueuePtr rear;
}LinkQueue;
Status InitQueue(LinkQueue& Q)
{
Q.front=Q.rear=new QNode;
Q.front->next=NULL;
return OK;
}
Status EnQueue(LinkQueue&Q,int e)
{
QueuePtr p;
p=new QNode;
p->data=e;
p->next=NULL;
Q.rear->next=p;
Q.rear=p;
return OK;
}
Status QueueEmpty(LinkQueue& Q) {
if(Q.front==Q.rear)
return OK;
else
return ERROR;
}
charDeQueue(LinkQueue&Q,int& e) {
QueuePtr p;
if(Q.front==Q.rear)
return ERROR;
p=Q.front->next;
e=p->data;
Q.front->next=p->next;
if(Q.rear==p)
Q.rear=Q.front;
delete p;
return OK;
}
Status LocateVex(ALGraphG,char v) {
int i;
for(int i=0;i<G.vexnum;i++)
if(G.vertices[i].data==v)
return i;
return ERROR;
}
Status CreateUDG(ALGraph& G) {
ArcNode* p1,*p2;
char v1,v2;
inti,j;
cout<<"输入总顶点数和总边数:"<<endl;
cin>>G.vexnum>>G.arcnum;//输入总顶点数和总边数
cout<<"输入各点,构造表头结点表:"<<endl;
for(int i=0;i<G.vexnum;i++)
{
cin>>G.vertices[i].data;//输入顶点值
G.vertices[i].firstarc=NULL;//初始化表头结点的指针域为NULL
}
cout<<"输入各边,构造邻接表:"<<endl;
for(int k=0;k<G.arcnum;k++)//输入各边,构造邻接表
{
cin>>v1>>v2;//输入一条边依附的两个顶点
i=LocateVex(G,v1);
j=LocateVex(G,v2);//确定v1和v2在G中的位置,即顶点在G.vertices中的序号
p1=new ArcNode;//生成一个新的边结点*p1
p1->adjvex=j;//邻接点序号为j
p1->nextarc=G.vertices[i].firstarc;
G.vertices[i].firstarc=p1;//将新结点*p1插入顶点v1的边表头部
p2=new ArcNode;//生成另一个对称的新的边结点*p2
p2->adjvex=i;//邻接点序号为i
p2->nextarc=G.vertices[j].firstarc;
G.vertices[j].firstarc=p2;//将新结点*p1插入顶点v1的边表头部
}
return OK;
}
Status FirstAdjVex(ALGraphG,int v)
{
ArcNode* p;
p=G.vertices[v].firstarc;
if(p)
{
return p->adjvex;
}
else
return ERROR;
}
Status NextAdjVex(ALGraphG,intv,int w)
{
ArcNode *p;
p=G.vertices[v].firstarc;
while(p&&p->adjvex!=w)
p=p->nextarc;
if(!p->nextarc)
return -1;
else
return p->nextarc->adjvex;
}
void BFS(ALGraph G)
{
int v=0;
LinkQueue Q;
cout<<G.vertices[v].data<<" ";
visited[v]=true;//访问第V个顶点,并置访问标志数组相应分量值
InitQueue(Q);//辅助队列Q初始化,置空
EnQueue(Q,v);//v进队
while(!QueueEmpty(Q))//队列非空
{
DeQueue(Q,v);//队头元素出队并置为V
for(int w=FirstAdjVex(G,v);w>=0;w=NextAdjVex(G,v,w))
//依次检查v的所有邻接点w,FirstAdjVex(G,v)表示v的第一个结点
//NextAdjVex(G,v,w)表示u相对于w的下一个邻接点,w>=0表示存在邻接点
if(!visited[w])//w为v的尚未访问的邻接点
{
cout<<G.vertices[w].data<<" ";
visited[w]=true;//访问w并置访问标志数组相应分量值为true
EnQueue(Q,w);//w进队
}
}
}
int main()
{
ALGraph G;
CreateUDG(G);
cout<<"广度优先遍历:"<<endl;
BFS(G);
}。