数学建模 SPSS 典型相关分析
典型相关分析的spss操作流程

典型相关分析的spss操作流程1.首先,打开SPSS软件并创建一个新的数据文件。
First, open the SPSS software and create a new data file.2.导入你要进行典型相关分析的数据到SPSS中。
Import the data for canonical correlation analysis into SPSS.3.确保数据变量的命名和类型是正确的。
Make sure the data variable names and types are correct.4.确认数据的缺失值情况,并进行适当的处理。
Check for missing values in the data and handle them appropriately.5.选择“分析”菜单中的“相关”选项。
Select the "Correlate" option from the "Analysis" menu.6.选择“典型相关”作为分析的方法。
Choose "Canonical Correlation" as the method for analysis.7.将想要进行分析的自变量和因变量添加到对应的框中。
Add the predictor and criterion variables to their respective boxes for analysis.8.确定是否需要进行变量的标准化处理。
Decide if standardization of variables is needed.9.点击“OK”开始进行典型相关分析。
Click "OK" to start the canonical correlation analysis.10.解释典型相关分析的结果和统计显著性。
Interpret the results and statistical significance of the canonical correlation analysis.11.对典型相关分析的结果进行图表展示。
如何在SPSS中实现典型相关分析

如何在SPSS中实现典型相关分析什么是典型相关分析?典型相关分析是指对于两个变量集合,分别找出它们的主成分,使得两个主成分之间相关系数最大,称为典型相关分析,也叫双重主成分分析。
典型相关分析可用于研究两个变量集合之间的联系,特别是当变量集合具有相关结构时,可发现更深入的联系。
SPSS中如何实现典型相关分析?1.打开数据文件:首先要打开SPSS软件,然后点击“文件”选项卡,从下拉菜单中选择“打开”命令。
在弹出的打开文件对话框中选择自己的典型相关分析数据文件并打开。
2.设置典型相关分析:点击“分析”选项卡,在下拉菜单中选择“典型相关”命令。
在弹出的对话框中选择两组变量集合并输入相关变量的名称,然后点击“确定”按钮。
3.进行典型相关分析:在弹出的典型相关分析结果窗口中,SPSS会输出典型相关系数矩阵和变量权重矩阵,以及典型变量的相关性和累积方差贡献等信息。
4.结果解释:通过观察典型相关系数矩阵和变量权重矩阵,可发现两个变量集合之间的相关性状况。
同时,通过观察典型变量的相关性和累积方差贡献,获取变量集合对联结的贡献度和对典型变量的解释能力。
典型相关分析的应用实例举例来说,假设我们想研究人的身体状况与心理健康之间的关系。
我们将人的身体状况因素归为一组变量集(如身高、体重、BMI指数等),将人的心理健康因素归为另一组变量集(如焦虑得分、抑郁得分、快乐得分等),然后进行典型相关分析。
结果显示,两组变量集之间存在强关联,其中第一对典型变量是身高、体重、BMI指数、焦虑得分和抑郁得分;第二对典型变量是快乐得分、嗜睡得分和心境得分。
这些变量集代表两方面不同的人类特征。
因此我们可以得到人类身体和心理健康之间的关系非常密切。
典型相关分析是一种用于寻找两组变量集合之间关联的有用工具。
在SPSS中实现典型相关分析,需要首先打开数据文件,然后选择指定变量集合并进行典型相关分析。
最后通过观察典型相关系数矩阵、变量权重矩阵、典型变量的相关性和累积方差贡献等指标,来解释变量集合之间的关联状况。
SPSS典型相关分析案例

SPSS典型相关分析案例典型相关分析(Canonical Correlation Analysis,CCA)是一种统计方法,用于研究两组变量之间的相关性。
它可以帮助研究人员了解两组变量之间的关系,并提供有关这些关系的详细信息。
在SPSS中,可以使用典型相关分析来探索两个或多个变量之间的关系,并进一步理解这些变量如何相互影响。
下面我们将介绍一个典型相关分析的案例,以展示如何在SPSS中执行该分析。
案例背景:假设我们有一个医学研究数据集,包含30名患者的多个生物标记物和他们的疾病严重程度评分。
我们希望了解这些生物标记物与疾病严重程度之间的关系,并查看是否可以建立一个线性模型来预测疾病严重程度。
以下是执行这个案例的步骤:第1步:准备数据首先,我们需要准备数据,确保所有变量都是数值型。
在SPSS中,我们可以通过检查数据集的描述性统计信息或查看变量视图来做到这一点。
第2步:导入数据在SPSS中,我们可以通过选择菜单中的"File"选项,然后选择"Open"来导入数据集。
我们应该选择包含待分析数据的文件,并确保正确指定变量的类型。
第3步:执行典型相关分析要执行典型相关分析,我们可以选择菜单中的"Analyze"选项,然后选择"Canonical Correlation"。
在弹出的对话框中,我们应该选择我们希望研究的生物标记物变量和疾病严重程度评分变量。
然后,我们可以选择一些选项,如方差-协方差矩阵、相关矩阵和判别系数,并点击"OK"执行分析。
第4步:解释结果完成分析后,SPSS将提供几个输出表。
我们应该关注典型相关系数和标准化典型系数,以了解两组变量之间的关系。
我们可以使用这些系数来解释生物标记物如何与疾病严重程度相关联,并找到最重要的变量。
此外,我们还可以使用SPSS提供的其他统计结果来进一步解释模型的效果和预测能力。
SPSS相关分析案例讲解

相关分析一、两个变量的相关分析:Bivariate 1.相关系数的含义相关分析是研究变量间密切程度的一种常用统计方法。
相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。
①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。
②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。
③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。
如果r=1或–1,则表示两个现象完全直线性相关。
如果=0,则表示两个现象完全不相关(不是直线相关)。
④3.0<r ,称为微弱相关、5.03.0<≤r ,称为低度相关、8.05.0<≤r ,称为显著(中度)相关、18.0<≤r ,称为高度相关⑤r 值很小,说明X 与Y 之间没有线性相关关系,但并不意味着X 与Y 之间没有其它关系,如很强的非线性关系。
⑥直线相关系数一般只适用与测定变量间的线性相关关系,若要衡量非线性相关时,一般应采用相关指数R 。
2.常用的简单相关系数(1)皮尔逊(Pearson )相关系数皮尔逊相关系数亦称积矩相关系数,1890年由英国统计学家卡尔•皮尔逊提出。
定距变量之间的相关关系测量常用Pearson 系数法。
计算公式如下:∑∑∑===----=ni ni i ini i iy y x xy y x xr 11221)()())(( (1)(1)式是样本的相关系数。
计算皮尔逊相关系数的数据要求:变量都是服从正态分布,相互独立的连续数据;两个变量在散点图上有线性相关趋势;样本容量30≥n 。
(2)斯皮尔曼(Spearman )等级相关系数Spearman 相关系数又称秩相关系数,是用来测度两个定序数据之间的线性相关程度的指标。
当两组变量值以等级次序表示时,可以用斯皮尔曼等级相关系数反映变量间的关系密切程度。
它是根据数据的秩而不是原始数据来计算相关系数的,其计算过程包括:对连续数据的排秩、对离散数据的排序,利用每对数据等级的差额及差额平方,通过公式计算得到相关系数。
SPSS相关分析实例操作步骤-SPSS做相关分析

SPSS相关分析实例操作步骤-SPSS做相关分析SPSS(Statistical Product and Service Solutions)是目前在工业、商业、学术研究等领域中广泛应用的统计学软件包之一。
Correlation是SPSS的一个功能模块,可以用于分析两个或多个变量之间的关系。
下面是SPSS进行相关分析的具体步骤:1. 打开SPSS软件,选择“变量视图”(Variable View),输入相关的变量名,包括数字型变量和分类变量。
2. 进入“数据视图”(Data View),输入数据,并保存数据集。
3. 打开菜单栏中的“分析”(Analyze),选择“相关”(Correlate),再选择“双变量”(Bivariate)。
4. 在双变量窗口中,选择包含需要分析的变量的变量名,并将其移至右侧窗口中的变量框(Variables)。
5. 如果需要控制其他变量的影响,可以选择“控制变量”(Options)。
6. 点击“确定”(OK)按钮后,SPSS将输出结果,并将其显示在输出窗口中。
相关系数(Correlation Coefficient)介于-1和1之间,可以用来衡量两个变量之间的线性关系的强度。
7. 如果需要对结果进行图形化展示,可以选择“图”(Plots),并选择适当的图形类型。
需要注意的是,进行相关分析时需要确保变量之间存在线性关系。
如果变量之间存在非线性关系,建议使用其他统计方法进行分析。
同时,SPSS进行相关分析的结果只能描述变量之间的关系,不能用于说明因果关系。
以上是SPSS做相关分析的具体步骤,希望能对大家进行SPSS 数据分析有所帮助。
SPSS典型相关分析结果解读

Correlations for Set-1Y1Y2Y3Y1 1.0000.9983.5012Y2.9983 1.0000.5176Y3.5012.5176 1.0000第一组变量间的简单相关系数Correlations for Set-2X1X2X3X4X5X6X7X8X9X10X11X12X13 X1 1.0000-.3079-.7700-.7068-.6762-.7411-.7466-.5922-.1948-.1285-.2650-.9070-.6874 X2-.3079 1.0000-.0117.0103-.0613-.0283-.0140.3333.4161.3810.3831.1098-.0640 X3-.7700-.0117 1.0000.9905.9860.9973.9990.5892.0421-.0196.2492.9515.9903 X4-.7068.0103.9905 1.0000.9910.9935.9952.5634.0249-.0367.2476.9120.9953 X5-.6762-.0613.9860.9910 1.0000.9887.9912.5717.0363-.0277.2475.8972.9926 X6-.7411-.0283.9973.9935.9887 1.0000.9985.5563.0142-.0453.2210.9355.9950 X7-.7466-.0140.9990.9952.9912.9985 1.0000.5795.0319-.0298.2441.9390.9945 X8-.5922.3333.5892.5634.5717.5563.5795 1.0000.7097.6540.8990.6619.5138 X9-.1948.4161.0421.0249.0363.0142.0319.7097 1.0000.9922.8520.1350-.0228 X10-.1285.3810-.0196-.0367-.0277-.0453-.0298.6540.9922 1.0000.8184.0752-.0801 X11-.2650.3831.2492.2476.2475.2210.2441.8990.8520.8184 1.0000.3093.1840 X12-.9070.1098.9515.9120.8972.9355.9390.6619.1350.0752.3093 1.0000.9040 X13-.6874-.0640.9903.9953.9926.9950.9945.5138-.0228-.0801.1840.9040 1.0000Correlations Between Set-1and Set-2X1X2X3X4X5X6X7X8X9X10X11X12X13 Y1-.7542-.0147.9995.9940.9892.9989.9998.5788.0334-.0280.2426.9430.9937 Y2-.7280-.0234.9965.9958.9954.9977.9988.5859.0485-.0136.2573.9285.9949 Y3-.4485.2952.5096.4955.5230.4760.5048.9695.7610.7071.9073.5449.4500Canonical Correlations1 1.0002 1.0003 1.000第一对典型变量的典型相关系数为CR1=1.....二三Test that remaining correlations are zero:维度递减检验结果降维检验Wilk's Chi-SQ DF Sig.1.000.000.000.0002.000.00024.000.0003.000103.48911.000.000此为检验相关系数是否显著的检验,原假设:相关系数为0,每行的检验都是对此行及以后各行所对应的典型相关系数的多元检验。
数学建模__SPSS_典型相关分析

数学建模__SPSS_典型相关分析典型相关分析(Canonical Correlation Analysis)是一种多变量统计方法,用于分析两组变量之间的关系。
在典型相关分析中,我们尝试找到两组变量之间的线性组合,使得这些线性组合之间的相关性最大化。
典型相关分析可以帮助研究者理解两组变量之间的关系,并发现潜在的相关结构。
典型相关分析适用于有两组或多组相关变量的研究。
典型相关分析既可以用于预测模型的建立,也可以用于变量选择和降维。
下面我们将介绍典型相关分析的基本原理、步骤和应用。
典型相关分析的基本原理是寻找两个组合线性关系,使得两个组合相互之间具有最大的相关性。
在典型相关分析中,我们将一个变量集作为自变量,另一个变量集作为因变量,然后寻找这两个变量集之间的最佳线性组合。
典型相关分析的步骤如下:1.收集数据:首先需要收集自变量和因变量的数据。
这些数据可以是观察数据、实验数据或调查数据。
2.数据预处理:在进行典型相关分析之前,我们需要对数据进行预处理。
这包括缺失数据处理、异常值检测和变量归一化等步骤。
3.计算相关系数:接下来,我们需要计算自变量和因变量之间的相关系数。
这可以通过计算皮尔逊相关系数、斯皮尔曼相关系数或肯德尔相关系数来实现。
4.计算典型变量:通过应用典型相关分析模型,我们可以计算出一组自变量和一组因变量的典型变量。
典型变量是自变量和因变量的线性组合,它们具有最大的相关性。
5.进行相关性检验:在典型相关分析中,我们常常需要进行相关性的显著性检验。
这可以通过计算典型相关系数的显著性水平来实现。
6.结果解释和应用:最后,根据典型相关分析的结果,我们可以解释自变量和因变量之间的关系,并根据这些结果进行应用和决策。
典型相关分析的应用非常广泛。
例如,在金融领域,典型相关分析可以帮助分析公司的财务指标与市场指标之间的关系。
在医学研究中,典型相关分析可以用于分析不同变量对医疗结果的影响。
在社会科学研究中,典型相关分析可以帮助分析人们的行为和态度之间的关系。
SPSS 软件应用 相关分析举例
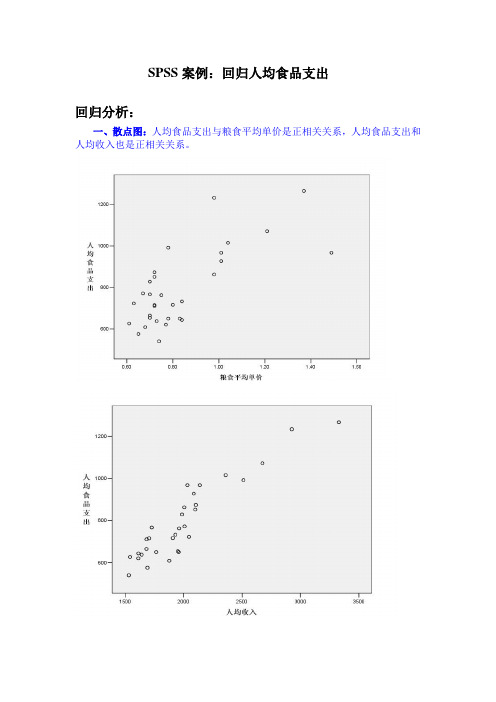
SPSS案例:回归人均食品支出回归分析:一、散点图:人均食品支出与粮食平均单价是正相关关系,人均食品支出和人均收入也是正相关关系。
二、相关性分析:人均食品支出与粮食平均单价的相关系数为0.730,为显著相关,假设检验t检验,sig(2-tailed)=0小于双侧检验的显著水平0.01,所以推翻原假设,人均食品支出与粮食平均单价线性相关。
人均食品支出与人均收入的相关系数为0.921,为显著相关,假设检验t检验,sig(2-tailed)=0小于双侧检验的显著水平0.01,所以推翻原假设,人均食品支出与人均收入线性相关。
三、(1)方程中的自变量列表(方法是进入)(2 )模型拟合概述:可以从表中看出,自变量和因变量之间的相关系数为0.940,拟合线性回归的确定性系数为0.883,经调整后的确定性系数为0.875,标准误的估计为2.766。
这里的R,R^2的值反映两变量的共变量比率高,模型与数据的拟合程度好。
Durbin-Watson=2.766>2,所以他们三者的关系程度显著。
四、方差分析:回归平方和为915129.1,残差平方和为120679.8,总平方和为1035809,对应的F统计量的值为106.164,显著性水平小于0.05,可以认为所建立的回归方程有效。
因为sig=0小于0.05,所以推翻原假设的多个自变量同时为0的假设,所以自变量不同时为0.五、回归系数:非标准化的回归系数X1的估计值为213.423,标准误为73.278,标准化的回归系数为0.243,回归系数显著性检验t统计量的值为2.913,对应显著性水平Sig.=0.007<0.05,可以认为粮食平均单价对人均食品输出有显著影响。
X2的估计值为0.352,标准误为0.038,标准化的回归系数0.767,回归系数显著性检验t统计量的值为9.185,对应显著性水平Sig.=0.000<0.05,可以认为人均收入对人均食品输出有显著影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
典型相关分析
在对经济问题的研究和管理研究中,不仅经常需要考察两个变量之间的相关程度,而且还经常需要考察多个变量与多个变量之间即两组变量之间的相关性。
典型相关分析就是测度两组变量之间相关程度的一种多元统计方法。
典型相关分析计算步骤
(一)根据分析目的建立原始矩阵 原始数据矩阵
⎥
⎥⎥⎥⎥⎦⎤
⎢⎢⎢⎢⎢⎣
⎡nq n n np
n n q
p
q p y y y x x x y y y x x x y y y x x x
2
1
2
1222
21
22211121111211
(二)对原始数据进行标准化变化并计算相关系数矩阵
R = ⎥⎦
⎤
⎢
⎣⎡2221
1211
R R R R 其中11R ,22R 分别为第一组变量和第二组变量的相关系数阵,12R = 21
R '为第一组变量和第二组变量的相关系数
(三)求典型相关系数和典型变量
计算矩阵=A 111-R 12R 122-R 21R 以及矩阵=B 122-R 21R 1
11-R 12R 的特征值和特征向量,分
别得典型相关系数和典型变量。
(四)检验各典型相关系数的显著性
第五节 利用SPSS 进行典型相关分析
第一步,录入原始数据,如下表:X1 X2 X3 X4 X5 分别代表多孩率、综合节育率、初中及以上受教育程度的人口比例、人均国民收入和城镇人口比例。
研究人口出生与教育程度、生活水平等的相关。
1、点击“Files→New→Syntax”打开如下对话框。
2、输入调用命令程序及定义典型相关分析变量组的命令。
如图
输入时要注意“Canonical correlation.sps”程序所在的根目录,注意变量组的格式和空格。
第三步,执行程序。
用光标选择这些命令,使其图黑,再点击运行键,即可得到所有典型相关分析结果。
输出结果1
输出结果2
主要结果的解释:
第一组变量相关系数
Correlations for Set-1
X1 X2
X1 1.0000 -.7610
X2 -.7610 1.0000
第二组变量相关系数
Correlations for Set-2
X3 X4 X5
X3 1.0000 .7712 .8488
X4 .7712 1.0000 .8777
X5 .8488 .8777 1.0000
第一组与第二组变量之间的相关系数
Correlations Between Set-1 and Set-2
X3 X4 X5
X1 -.5418 -.4528 -.4534
X2 .2929 .2528 .2447
典型相关系数
Canonical Correlations
1 .578
2 .025
维度递减检验结果(降维检验)
Test that remaining correlations are zero:
Wilk's Chi-SQ DF Sig.
1 .666 10.584 6.000 .102
2 .999 .017 2.000 .992
标准化典型系数—第一组
Standardized Canonical Coefficients for Set-1 1 2
X1 -1.319 .797
X2 -.486 1.463
粗系数—第一组(没有标准化的,作者注)
Raw Canonical Coefficients for Set-1
1 2
X1 -.131 .079
X2 -.091 .275
_
标准化典型系数—第二组
Standardized Canonical Coefficients for Set-2
1 2
X3 .997 -.261
X4 .292 2.075
X5 -.274 -1.743
粗系数—第二组(没有标准化的,作者注)
Raw Canonical Coefficients for Set-2
1 2
X3 .086 -.023
X4 .000 .002
X5 -.017 -.107
典型负载系数(结构相关系数:典型变量与原始变量之间的相关系数)第一组Canonical Loadings for Set-1
1 2
X1 -.949 -.316
X2 .517 .856
交叉负载系数(某一组中的典型变量与另外一组的原始变量之间的相关系数)—第一组原始变量
Cross Loadings for Set-1
1 2
X1 -.548 -.008
X2 .299 .022
典型负载系数(结构相关系数:典型变量与原始变量之间的相关系数)第二组Canonical Loadings for Set-2
1 2
X3 .990 -.140
X4 .821 .344
X5 .829 -.143
交叉负载系数(某一组中的典型变量与另外一组的原始变量之间的相关系数)—第二组原始变量
Cross Loadings for Set-2
1 2
X3 .572 -.004
X4 .474 .009
X5 .479 -.004
Redundancy Analysis:(冗余分析)
(第一组原始变量总方差中由本组变式代表的比例)
Proportion of Variance of Set-1 Explained by Its Own Can. Var. Prop Var
CV1-1 .584
CV1-2 .416
(第一组原始变量总方差中由第二组的变式所解释的比例)
Proportion of Variance of Set-1 Explained by Opposite Can.Var. Prop Var
CV2-1 .195
CV2-2 .000
(第二组原始变量总方差中由本组变式代表的比例)
Proportion of Variance of Set-2 Explained by Its Own Can. Var. Prop Var
CV2-1 .780
CV2-2 .053
(第二组原始变量总方差中由第一组的变式所解释的比例)
Proportion of Variance of Set-2 Explained by Opposite Can. Var. Prop Var
CV1-1 .261
CV1-2 .000
------ END MATRIX -----
另外,在数据表中还输出了以下结果:
s1_cv001:第一组的第一个典型变量;
s2_cv001:第二组的第一个典型变量;
s1_cv002:第一组的第二个典型变量;
s2_cv002:第二组的第二个典型变量;。