NMR数据处理流程
核磁数据处理方法

核磁数据处理方法一、引言核磁共振(NMR)技术是一种非常重要的分析方法,广泛应用于化学、生物、医学等领域。
在核磁共振实验中,获取到的原始数据需要进行处理和分析,以提取实用的信息。
本文将介绍一种常用的核磁数据处理方法,包括数据校正、峰识别、峰积分和峰归属等步骤。
二、数据校正数据校正是核磁数据处理的第一步,其目的是消除仪器和样品造成的系统误差。
常见的数据校正方法包括零点校正和相位校正。
零点校正是通过将信号的基线调整为零来消除仪器本底信号的影响。
相位校正则是调整信号的相位,以使得实部和虚部的峰值对齐,以获得最佳的信号质量。
三、峰识别峰识别是核磁数据处理的关键步骤,其目的是确定样品中存在的化合物的峰。
常用的峰识别方法包括基线平滑、峰搜索和峰拟合。
基线平滑是通过滤波算法去除噪声信号,使得峰更加清晰可见。
峰搜索是在平滑后的数据中寻觅峰的位置,常用的方法有阈值法和导数法。
峰拟合则是对峰进行数学拟合,以获得峰的面积、峰宽等参数。
四、峰积分峰积分是核磁数据处理的重要步骤,其目的是计算峰的面积,以获得化合物的相对含量。
常见的峰积分方法包括峰高积分和峰面积积分。
峰高积分是通过测量峰的最大高度,并与标准品进行比较,计算出化合物的相对含量。
峰面积积分则是通过对峰下面积进行积分计算,得到化合物的相对含量。
五、峰归属峰归属是核磁数据处理的最后一步,其目的是确定每一个峰代表的化合物。
常用的峰归属方法包括化学位移对照和二维核磁共振谱的解析。
化学位移对照是通过与已知化合物的化学位移进行比对,确定峰的化学位移范围,从而猜测峰所代表的化合物。
二维核磁共振谱的解析则是通过与已知的二维谱图进行比对,确定峰的结构和化学位移,从而准确归属峰的化合物。
六、总结核磁数据处理是核磁共振实验中不可或者缺的一部份,它可以匡助我们从原始数据中提取出实用的信息。
本文介绍了一种常用的核磁数据处理方法,包括数据校正、峰识别、峰积分和峰归属等步骤。
通过合理应用这些方法,可以提高核磁共振实验的数据处理效率和准确性,为化学、生物、医学等领域的研究提供有力支持。
NMR数据处理流程要点

NMR数据处理流程要点NMR(核磁共振)是一种强大的分析技术,可用于研究各种物质的结构和性质。
在进行NMR数据处理时,需要遵循一定的流程和方法,以确保数据的准确性和可靠性。
下面将介绍NMR数据处理的主要要点,帮助您更好地理解和应用这一技术。
1.数据采集:NMR数据处理的第一步是进行数据采集。
在NMR实验中,样品被置于磁场中,并通过不同的脉冲序列来激发核磁共振信号。
在数据采集过程中,需要控制采集参数,如扫描次数、采集时间和采集磁场强度,以确保获得高质量的数据。
2.频域处理:采集到的原始数据是时域数据,需要进行傅立叶变换以将其转换为频域数据。
这一步骤可以通过数据处理软件进行自动处理,也可以根据需要进行手动处理,以优化数据质量和信噪比。
3.相位校正:相位校正是NMR数据处理的重要步骤,用于消除不同核之间或同一核不同谱线之间的相位差异。
相位校正可以提高峰信号的清晰度和分辨率,有利于后续的数据解析和结构分析。
4.基线校正:在NMR谱图中,可能存在由于仪器漂移或其它杂散信号所产生的基线漂移问题。
基线校正是为了消除这些干扰信号,使谱图更加清晰和准确。
通常可以通过多项式拟合或先进的谱图处理技术进行基线校正。
5.积分处理:NMR谱图中的峰值面积可以反映出不同核的数量和化学环境。
因此,进行积分处理是NMR数据分析的重要一步,有助于定量分析和结构确认。
可以使用自动积分软件或手动积分的方法,根据需要选择适当的方法。
6.化学位移标定:化学位移是NMR谱图中的一个关键参数,用于确定不同核的化学环境。
进行化学位移标定是确保NMR数据准确性和可比性的重要步骤,可以通过内部标准品或外部参考品进行标定。
7.数据解析:NMR数据解析是通过比对实验数据和参考数据来确定样品的结构和性质。
需要使用各种谱图库和数据处理软件来辅助数据解析,以确定化合物的分子式、官能团和结构。
8.结果分析:最后一步是对处理后的数据进行结果分析。
通过比对实验数据和文献数据,可以确认化合物的结构、纯度和性质,并对实验结果进行解释和总结。
核磁数据处理方法

核磁数据处理方法核磁共振(Nuclear Magnetic Resonance,NMR)是一种重要的分析技术,广泛应用于化学、生物、医学等领域。
核磁共振实验产生的数据需要进行处理和分析,以提取有用的信息。
在本文中,将介绍一种常用的核磁数据处理方法,包括数据预处理、峰识别、峰积分和谱图解析等步骤。
1. 数据预处理核磁共振实验得到的原始数据通常包含噪声和基线漂移等干扰。
为了提高信噪比和准确性,需要对数据进行预处理。
常见的预处理方法包括零填充、傅里叶变换、基线校正和峰对齐等。
1.1 零填充零填充是指在原始数据的两端添加零值,以增加数据点的数量。
这样可以提高频谱分辨率,使峰更加清晰。
零填充后的数据可以通过快速傅里叶变换(Fast Fourier Transform,FFT)进行频谱分析。
1.2 傅里叶变换傅里叶变换是将时域数据转换为频域数据的数学方法。
通过傅里叶变换,可以将核磁共振信号从时间域转换为频率域,得到谱图。
傅里叶变换可以通过离散傅里叶变换(Discrete Fourier Transform,DFT)或快速傅里叶变换来实现。
1.3 基线校正基线校正是指对数据中的基线漂移进行校正,以消除基线对峰的影响。
常用的基线校正方法包括多项式拟合、小波变换和自适应基线校正等。
1.4 峰对齐峰对齐是指将不同谱图中的峰位置对齐,以便进行比较和分析。
峰对齐可以通过寻找共有峰或使用内部参考物质来实现。
2. 峰识别峰识别是指从处理后的数据中找出峰的位置和强度。
常用的峰识别方法包括阈值法、波形拟合法和小波变换等。
2.1 阈值法阈值法是一种简单直观的峰识别方法,通过设置一个阈值来判断哪些数据点属于峰。
超过阈值的数据点被认为是峰的一部分。
2.2 波形拟合法波形拟合法是一种更精确的峰识别方法,通过拟合峰的形状来确定峰的位置和强度。
常用的拟合函数包括高斯函数、洛伦兹函数和Voigt函数等。
2.3 小波变换小波变换是一种时频分析方法,可以同时提取峰的位置和强度信息。
大物实验~~核磁共振实验数据处理

大物实验~~核磁共振实验数据处理核磁共振(NMR)实验是物理学和化学领域中常用的一种实验方法,其数据处理过程包括多个步骤,包括数据采集、数据预处理、数据分析和数据可视化等。
以下是对这些步骤的详细描述。
一、数据采集在核磁共振实验中,数据采集是实验的核心部分。
实验人员需要设置适当的实验条件,如磁场强度、射频脉冲频率和脉冲宽度等,以获取清晰的核磁共振信号。
在实验过程中,通常使用核磁共振谱仪来收集数据。
核磁共振谱仪可以产生高精度的射频脉冲,并测量它们与原子核之间的相互作用。
二、数据预处理数据预处理是去除噪声和干扰,提高数据质量的过程。
在核磁共振实验中,数据预处理包括对数据进行平滑处理、基线校正、相位调整等操作。
这些操作可以改善数据的信噪比,并使后续的数据分析和可视化更加准确。
三、数据分析数据分析是通过对预处理后的数据进行处理和分析,提取有关样品中原子核分布的信息。
在核磁共振实验中,数据分析包括对谱峰的识别、峰面积的测量、化学位移的计算等操作。
这些操作可以得出原子核在不同磁场下的分布情况,从而了解样品的分子结构和化学性质。
四、数据可视化数据可视化是将数据分析得到的结果以图表的形式呈现出来。
在核磁共振实验中,数据可视化包括绘制核磁共振谱图、制作三维图像等操作。
这些图像可以直观地展示样品中原子核的分布情况,帮助实验人员更好地理解实验结果。
除了以上四个步骤外,核磁共振实验的数据处理还包括其他一些步骤,如实验设计、实验操作、数据处理和结果解释等。
这些步骤需要实验人员具备一定的物理学和化学知识,以及对数据处理方法的了解和应用能力。
在核磁共振实验中,数据处理是一个非常重要的环节。
通过对数据的采集、预处理、分析和可视化,实验人员可以得出有关样品中原子核分布的信息,并了解样品的分子结构和化学性质。
这些信息对于科学研究、化学分析、材料开发等领域都具有重要的意义。
需要注意的是,核磁共振实验的数据处理过程具有一定的复杂性和专业性,需要实验人员具备一定的技能和经验。
核磁数据处理方法

核磁数据处理方法核磁共振(Nuclear Magnetic Resonance,NMR)是一种重要的分析技术,广泛应用于化学、生物医学、材料科学等领域。
核磁共振实验中产生的原始数据需要经过一系列的处理方法,以提取有用的信息并进行数据分析。
本文将介绍常见的核磁数据处理方法,包括数据预处理、峰识别、峰积分和谱图解析等。
1. 数据预处理数据预处理是核磁数据处理的第一步,旨在消除噪声、基线漂移等对后续分析的干扰。
常见的数据预处理方法包括平滑、基线校正和相位校正。
平滑:平滑是一种降低噪声的方法,常用的平滑算法有移动平均、高斯平滑等。
移动平均是将每个数据点替换为其前后若干个数据点的平均值,以减少噪声对信号的影响。
高斯平滑则是利用高斯函数对数据进行加权平均,使得噪声的影响更加平滑。
基线校正:基线漂移是指由于仪器等因素导致的信号整体上升或下降的现象。
基线校正旨在消除基线漂移,常用的方法有多项式基线校正和空白样品基线校正。
多项式基线校正通过拟合多项式曲线来估计基线的形状,并将其从原始数据中减去。
空白样品基线校正则是将一个没有目标物的样品作为基线参考,将其信号减去。
相位校正:相位校正是调整信号的相位,以使得信号的峰形更加对称。
常用的相位校正方法有零阶和一阶校正。
零阶校正是通过调整信号的整体相位,使得信号的峰形对称。
一阶校正则是通过调整信号的不同频率分量的相位,使得信号的相位响应更加平滑。
2. 峰识别峰识别是核磁数据处理的关键步骤,旨在确定信号中的峰的位置和强度。
常用的峰识别方法有阈值法、导数法和模型拟合法。
阈值法:阈值法是一种简单直观的峰识别方法,通过设定一个阈值,将信号中高于阈值的部分识别为峰。
阈值的选择对峰的识别结果有较大影响,一般需要根据实际情况进行调整。
导数法:导数法是一种基于信号的斜率变化来识别峰的方法。
通过计算信号的导数,可以找到信号中局部最大值和最小值的位置,从而确定峰的位置。
模型拟合法:模型拟合法是一种利用数学模型对信号进行拟合,从而识别峰的位置和强度。
核磁数据处理步骤

核磁数据处理步骤介绍核磁共振(Nuclear Magnetic Resonance, NMR)是一种重要的分析技术,可用于分析和研究物质的结构和性质。
核磁共振数据处理是核磁共振实验中非常重要的一步,它涉及到数据的预处理、数据解析和数据解释等多个环节。
本文将详细介绍核磁数据处理步骤,并探讨每个步骤的具体内容和作用。
核磁数据处理步骤核磁数据处理通常包括以下几个步骤:1. 数据获取核磁共振实验需要通过核磁共振仪获取原始数据。
在这一步骤中,需要设置实验参数,如磁场强度、扫描方式和扫描范围等,以获取合适的核磁共振谱图。
同时,还需要进行系统校准,以保证数据的准确性和可靠性。
2. 数据预处理数据预处理是核磁数据处理的关键一步,它主要包括去噪、基线校正和谱图平滑处理。
去噪是指去除谱图中的噪声信号,常用的方法有傅里叶变换滤波和小波变换等。
基线校正是指对谱图中的基线进行修正,常用的方法有多项式拟合和简单直线法等。
谱图平滑处理是为了提高数据的信噪比,常用的方法有移动平均法和高斯平滑法等。
3. 数据解析数据解析是将核磁共振谱图中的峰进行定量分析,以确定样品中各组分的相对含量和结构。
这一步骤主要包括峰识别、峰集成和峰归属等。
峰识别是指在谱图中找出所有的峰,并对其进行编号和标记。
峰集成是指对每个峰进行积分,以得到峰面积和峰高等定量信息。
峰归属是指将每个峰与相应的化学位移和耦合常数进行关联,以确定相应的化学结构和相互作用类型。
4. 数据解释数据解释是核磁共振谱图中各峰的化学解释,以确定各个峰的来源和物质的结构。
这一步骤主要包括化学位移解释、耦合常数解释和化学结构解释等。
化学位移解释是指将峰的化学位移与特定化学官能团和化学键联系起来,以确定它们的存在和相对含量。
耦合常数解释是指通过峰之间的耦合常数和相对强度,推断出化学键的取向和相互作用类型。
化学结构解释是将所有的峰归属进行整合,以得到最终的化学结构和分子式。
核磁数据处理步骤的应用核磁数据处理步骤在化学、药学、生物学和材料科学等领域具有广泛的应用。
NMR数据处理流程要点
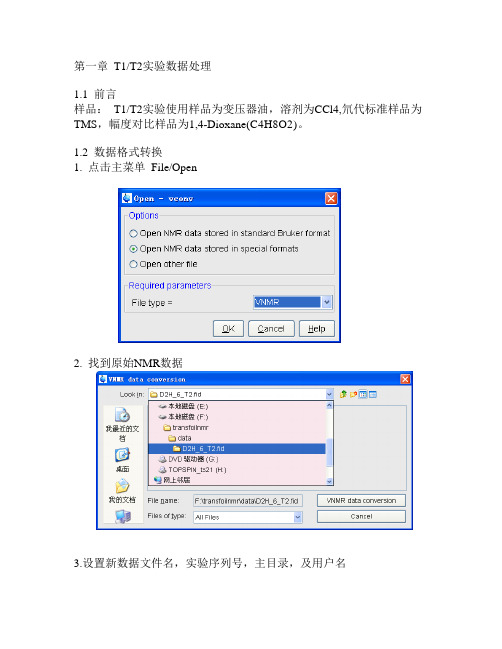
第一章T1/T2实验数据处理1.1 前言样品:T1/T2实验使用样品为变压器油,溶剂为CCl4,氘代标准样品为TMS,幅度对比样品为1,4-Dioxane(C4H8O2)。
1.2 数据格式转换1. 点击主菜单File/Open2. 找到原始NMR数据3.设置新数据文件名,实验序列号,主目录,及用户名4. 保存File/Save全点击1.3 处理1.选择FID注意:步骤1 仅仅用来描述T2 实验为衰减函数。
2.选择ProcPars3.点击显示处理参数4.做出如下改变SI(F1) = 16PH_mod(F1) = noPH_mod(F2) = pk5.键入xf26.键入abs27.键入setdiffparm8.选择Spectrum3.1.5 计算T2弛豫系数注意:如果采样如下步骤,将会弹出具有重要介绍的信息窗口。
请细细阅23读介绍内容。
1.点击主菜单的Analysis2.选择T1/T2 Relaxation3.点击提取部分FID4.点击5.键入16.点击7. 调相位8. 调基线7.点击定义范围8.点击9.点击定义区域10.利用鼠标左键和光标定义区域11.点击12.点击15.在指南窗口中,点击弛豫窗口17.在指南窗口中,点击拟合函数18.点击19.在Fitting Function 部分,选择uxnmrt2 和vdlist 20.点击21.在指南窗口中,点击开始计算22.点击23.在数据窗口中,点击计算所有数据点的拟合参数。
注意:所有计算值显示在数据窗口的简介中。
24.在指南窗口中,点击显示报告。
Dataset :C:\Bruker\TOPSPIN/data/pengsl/nmr/D20_T2/1/pdata/1 INTENSITY fit :I[t]= P*exp(-t/T2)16 points for Peak 1, Peak Point at 7.127 ppmResults Comp. 1P = 9.441e-001T2 = 6.941sSD = 6.171e-002tau ppm integral intensity2.000m 7.127 -1.6399e+006 1.324e+00616.000m 7.127 -1.6347e+006 1.0845e+00680.000m 7.127 -1.7485e+006 1.1653e+006 160.000m 7.127 -1.7617e+006 1.2251e+006 320.000m 7.127 -1.7016e+006 1.2774e+006 480.000m 7.127 -1.2727e+006 1.1777e+006 640.000m 7.127 -1.0013e+006 1.1873e+006 800.000m 7.127 -4.651e+005 1.2293e+006 960.000m 7.127 3.1215e+005 1.1478e+0061.200s 7.127 7.9016e+005 1.0709e+0061.480s 7.127 8.1055e+005 9.7672e+0051.600s 7.127 8.6186e+005 9.0807e+0052.000s 7.127 8.3397e+005 8.3684e+0053.200s 7.127 7.5662e+005 7.71e+0056.400s7.127 6.2275e+005 6.306e+0058.000s 7.127 58941 3.1195e+005 16 points for Peak 2, Peak Point at 1.270 ppm Results Comp. 1P = 1.095e+000T2 = 1.411sSD = 8.582e-002tau ppm integral intensity2.000m 1.269 8.3123e+0073.8776e+00716.000m 1.269 8.1277e+007 3.8207e+00780.000m 1.269 8.6909e+007 3.7916e+007 160.000m 1.269 8.9102e+007 3.7728e+007 320.000m 1.269 9.412e+007 3.691e+007480.000m 1.269 8.0176e+007 3.4291e+007 640.000m 1.269 7.2473e+007 3.3355e+007 800.000m 1.269 6.001e+007 2.9343e+007 960.000m 1.269 3.54e+007 2.1562e+0071.200s 1.269 1.8724e+007 1.5121e+0071.480s 1.269 1.2183e+007 1.1971e+0071.600s 1.269 7.8246e+006 9.5146e+0062.000s 1.2693.9297e+006 6.7795e+0063.200s 1.269 9.0273e+005 3.8742e+0066.400s 1.269 -1.3786e+005 2.2636e+0068.000s 1.269 -4.4636e+005 1.9266e+005 16 points for Peak 3, Peak Point at 0.883 ppm Results Comp. 1P = 1.073e+000T2 = 1.770sSD = 8.594e-002tau ppm integral intensity2.000m 0.883 1.7282e+008 1.8157e+00716.000m 0.883 1.6741e+008 1.8552e+00780.000m 0.883 1.5808e+008 1.8823e+007 160.000m 0.883 1.5379e+008 1.8855e+007 320.000m 0.883 1.348e+008 1.8835e+007 480.000m 0.884 1.2978e+008 1.7552e+007 640.000m 0.884 1.2009e+008 1.7105e+007 800.000m 0.884 1.0185e+008 1.5205e+007 960.000m 0.884 7.1128e+007 1.1613e+0071.200s 0.884 4.685e+007 8.8601e+0061.480s 0.883 3.5891e+007 7.4629e+0061.600s 0.8832.7577e+007 6.3334e+0062.000s 0.883 1.8885e+007 4.9117e+0063.200s 0.883 1.0139e+007 3.174e+0066.400s 0.883 5.6487e+006 2.1229e+0068.000s 0.883 3.7839e+005 3.095e+005第二章二维J-谱实验数据处理1.1 前言样品:T1/T2实验使用样品为变压器油,溶剂为CCl4,氘代标准样品为TMS,幅度对比样品为1,4-Dioxane(C4H8O2)。
核磁数据处理方法

核磁数据处理方法核磁共振(NMR)是一种重要的分析技术,广泛应用于化学、生物学和医学等领域。
在进行核磁实验时,我们需要对得到的数据进行处理和分析,以获得有用的信息。
本文将详细介绍核磁数据处理的方法和步骤。
一、数据获取和预处理1. 数据获取:通过核磁共振仪器获取样品的核磁共振谱图。
谱图通常包含两个维度的数据,即横轴表示化学位移,纵轴表示信号强度。
2. 数据预处理:对获得的谱图进行预处理,包括去除噪声、基线校正和相位校正等。
去除噪声可以提高信噪比,基线校正可以消除谱图中的基线漂移,相位校正可以调整信号的相位。
二、数据处理和分析1. 峰识别:通过峰识别算法找出谱图中的峰,并确定其化学位移和峰面积。
常用的峰识别算法包括峰拟合法和峰积分法。
2. 化学位移校正:根据已知的内部标准品或参考物质的峰位置,对谱图进行化学位移校正,以提高数据的准确性和可比性。
3. 峰归属:通过与数据库或文献比对,确定峰的归属,即确定峰所代表的化合物或功能基团。
4. 峰积分和积分校正:对峰进行积分,计算峰的面积。
如果需要,还可以进行积分校正,以消除不同峰的积分因子差异带来的影响。
5. 峰定量:根据峰的面积和浓度关系,进行峰定量分析,计算样品中目标物质的含量。
6. 数据可视化:将处理后的数据进行可视化展示,通常使用谱图或曲线图来展示数据的特征和变化趋势。
三、常用的数据处理软件和工具1. NMRPipe:是一个常用的核磁数据处理软件,提供了丰富的数据处理和分析功能。
2. MestReNova:是一款功能强大的核磁数据处理软件,可以进行多维数据处理、峰识别和峰归属等操作。
3. TopSpin:是一款广泛应用于核磁实验室的数据处理软件,提供了直观的用户界面和丰富的数据处理功能。
4. MATLAB:是一种常用的科学计算和数据处理工具,可以编写自定义的数据处理算法和脚本。
四、注意事项和常见问题1. 数据质量:核磁数据处理的结果受到数据质量的影响,因此在进行数据处理前,需要确保获得的数据质量良好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章T1/T2实验数据处理1.1 前言样品:T1/T2实验使用样品为变压器油,溶剂为CCl4,氘代标准样品为TMS,幅度对比样品为1,4-Dioxane(C4H8O2)。
1.2 数据格式转换1. 点击主菜单File/Open2. 找到原始NMR数据3.设置新数据文件名,实验序列号,主目录,及用户名4. 保存File/Save全点击1.3 处理1.选择FID注意:步骤1 仅仅用来描述T2 实验为衰减函数。
2.选择ProcPars3.点击显示处理参数4.做出如下改变SI(F1) = 16PH_mod(F1) = noPH_mod(F2) = pk5.键入xf26.键入abs27.键入setdiffparm8.选择Spectrum3.1.5 计算T2弛豫系数注意:如果采样如下步骤,将会弹出具有重要介绍的信息窗口。
请细细阅23读介绍内容。
1.点击主菜单的Analysis2.选择T1/T2 Relaxation3.点击提取部分FID4.点击5.键入16.点击7. 调相位8. 调基线7.点击定义范围8.点击9.点击定义区域10.利用鼠标左键和光标定义区域11.点击12.点击15.在指南窗口中,点击弛豫窗口17.在指南窗口中,点击拟合函数18.点击19.在Fitting Function 部分,选择uxnmrt2 和vdlist 20.点击21.在指南窗口中,点击开始计算22.点击23.在数据窗口中,点击计算所有数据点的拟合参数。
注意:所有计算值显示在数据窗口的简介中。
24.在指南窗口中,点击显示报告。
Dataset :C:\Bruker\TOPSPIN/data/pengsl/nmr/D20_T2/1/pdata/1 INTENSITY fit :I[t]= P*exp(-t/T2)16 points for Peak 1, Peak Point at 7.127 ppmResults Comp. 1P = 9.441e-001T2 = 6.941sSD = 6.171e-002tau ppm integral intensity2.000m 7.127 -1.6399e+006 1.324e+00616.000m 7.127 -1.6347e+006 1.0845e+00680.000m 7.127 -1.7485e+006 1.1653e+006 160.000m 7.127 -1.7617e+006 1.2251e+006 320.000m 7.127 -1.7016e+006 1.2774e+006 480.000m 7.127 -1.2727e+006 1.1777e+006 640.000m 7.127 -1.0013e+006 1.1873e+006 800.000m 7.127 -4.651e+005 1.2293e+006 960.000m 7.127 3.1215e+005 1.1478e+0061.200s 7.127 7.9016e+005 1.0709e+0061.480s 7.127 8.1055e+005 9.7672e+0051.600s 7.127 8.6186e+005 9.0807e+0052.000s 7.127 8.3397e+005 8.3684e+0053.200s 7.127 7.5662e+005 7.71e+0056.400s7.127 6.2275e+005 6.306e+0058.000s 7.127 58941 3.1195e+005 16 points for Peak 2, Peak Point at 1.270 ppm Results Comp. 1P = 1.095e+000T2 = 1.411sSD = 8.582e-002tau ppm integral intensity2.000m 1.269 8.3123e+0073.8776e+00716.000m 1.269 8.1277e+007 3.8207e+00780.000m 1.269 8.6909e+007 3.7916e+007 160.000m 1.269 8.9102e+007 3.7728e+007 320.000m 1.269 9.412e+007 3.691e+007480.000m 1.269 8.0176e+007 3.4291e+007 640.000m 1.269 7.2473e+007 3.3355e+007 800.000m 1.269 6.001e+007 2.9343e+007 960.000m 1.269 3.54e+007 2.1562e+0071.200s 1.269 1.8724e+007 1.5121e+0071.480s 1.269 1.2183e+007 1.1971e+0071.600s 1.269 7.8246e+006 9.5146e+0062.000s 1.2693.9297e+006 6.7795e+0063.200s 1.269 9.0273e+005 3.8742e+0066.400s 1.269 -1.3786e+005 2.2636e+0068.000s 1.269 -4.4636e+005 1.9266e+005 16 points for Peak 3, Peak Point at 0.883 ppm Results Comp. 1P = 1.073e+000T2 = 1.770sSD = 8.594e-002tau ppm integral intensity2.000m 0.883 1.7282e+008 1.8157e+00716.000m 0.883 1.6741e+008 1.8552e+00780.000m 0.883 1.5808e+008 1.8823e+007 160.000m 0.883 1.5379e+008 1.8855e+007 320.000m 0.883 1.348e+008 1.8835e+007 480.000m 0.884 1.2978e+008 1.7552e+007 640.000m 0.884 1.2009e+008 1.7105e+007 800.000m 0.884 1.0185e+008 1.5205e+007 960.000m 0.884 7.1128e+007 1.1613e+0071.200s 0.884 4.685e+007 8.8601e+0061.480s 0.883 3.5891e+007 7.4629e+0061.600s 0.8832.7577e+007 6.3334e+0062.000s 0.883 1.8885e+007 4.9117e+0063.200s 0.883 1.0139e+007 3.174e+0066.400s 0.883 5.6487e+006 2.1229e+0068.000s 0.883 3.7839e+005 3.095e+005第二章二维J-谱实验数据处理1.1 前言样品:T1/T2实验使用样品为变压器油,溶剂为CCl4,氘代标准样品为TMS,幅度对比样品为1,4-Dioxane(C4H8O2)。
1.2 数据格式转换1. 点击主菜单File/Open2. 找到原始NMR数据3.设置新数据文件名,实验序列号,主目录,及用户名4. 保存File/Save全点击1.3 处理1.选择FID2.选择ProcPars3.点击显示处理参数4.做出如下改变SI(F2) = 16kSI(F1) = 32PH_mod(F1) = mcPH_mod(F2) = pkWDW(F2) = SINEWDW(F1) = SINESSB(F2) =2SSB(F1) = 25.键入xfb6.键入abs28.选择Spectrum20.调整投影水平标准布鲁克参数设置可以在使用AU 程序的条件下自动进行并优化。
在采样(eda)和处理(edp)参数表中AU 程序的名字为AUNM。
开始采样使用xaua 命令。
处理数据,键入xaup 命令4.键入xaupAU 处理程序包含二维傅立叶变换,相位校正,基线校正和出图。
HMBC 实验使用强度模式处理数据,因此只显示正相关3.1.1 准备实验1.遵循基本实验用户指南一维氢谱实验采集一维氢谱图3.12.键入wrpa 23.键入re 24.拓展6ppm 到-2ppm 间的图谱5.点击,设置扫描宽度和O1 频率图3.2186.点击7.键入td 16k8.键入si 8k9.点击zg 开始采样10.键入ef11.键入apk12.键入abs图3.33.1.2 参数设置1.键入iexpno2.选择AcquPars3.点击显示脉冲序列参数4.做出如下改动PULPROG = stebpgp1s1dGPZ6[%] = 2GPZ[%] = -17.13D20[s] = 0.1P30[us] = 18005.键入rga6.键入zg7.加入ef8.键入apk9.键入abs19图3.410.键入iexpno11.选择AcquPars12.点击显示脉冲序列参数13.做出如下改动GPZ6[%] = 9514.键入zg15.键入ef16.键入apk17.键入abs图3.518.点击打开多重显示窗口19.拖动前面实验到多重显示窗口或键入re 320图3.6注意:两个图谱的强度差应该在~50 之间。
如果差异小于50,改变P30 或D20值。
3.1.3 采样1.键入iexpno2.选择AcquPars3.做出如下改变PULPROG = stebpgp1s4.点击改变采样维数图3.75.选择Change dimension from 1D to 2D’6.点击7.变动一下参数TD(F1) = 16FnMODE = QF8.键入dosy21图3.89.键入210.点击图3.911.键入9512.点击图3.1013.键入16 14.点击图3.1115.键入l 16.点击图3.1217.点击开始采样。