统计学贾俊平期末考试模拟试题二
统计学(第五版)贾俊平版期末考试模拟试题一

模拟试题一一。
单项选择题(每小题2分,共20分)9名大学生每月的手机话费支出(单位:元)分别是:64.3,60.4,77。
6,51.2,53.1,57.5,53。
9,47。
8,53。
5。
手机话费支出的平均数是()A。
53。
9B。
57。
7C. 55.2D。
56.5一项调查表明,在所抽取的2000个消费者中,他们每月在网上购物的平均花费是200元,这项调查的总体是()A. 2000个消费者B。
2000个消费者的平均花费金额C. 所有在网上购物的消费者D。
所有在网上购物的消费者的总花费额在参数估计中,要求用来估计总体参数的统计量与总体参数的离差越小越好。
这种评价标准称为()A.无偏性B.有效性C.一致性D.充分性下面关于回归模型的假定中不正确的是( )A. 误差项是一个期望值为0的随机变量B。
对于所有的x值,的方差都相同C。
误差项是一个服从正态分布的随机变量,且独立D。
自变量x是随机的某药品生产企业采用一种新的配方生产某种药品,并声称新配方药的疗效远好于旧的配方。
为检验企业的朔方是否属实,医药管理部门抽取一个样本进行检验,提出的假设为。
该检验所犯的第Ⅱ类错误是指( )A.新药的疗效有显著提高,得出新药疗效没有显著提高的结论B.新药的疗效有显著提高,得出新药的疗效有显著提高的结论C.新药的疗效没有显著提高的结论,得出新药疗效没有显著提高的结论D.新药的疗效没有显著提高,得出新药疗效有显著提高的结论一家研究机构从事水稻品种的研发.最近研究出3个新的水稻品。
为检验不同品种的平均产量是否相同,对每个品种分别在5个地块上进行试验,共获得15个产量数据.在该项研究中,反映全部15个产量数据之间称为()A. 总误差B。
组内误差C. 组间误差D。
处理误差趋势变动的特点是()A. 呈现出固定长度的周期性变动B. 呈现出波浪形或振荡式变动C. 在一年内重复出现的周期性波动D。
呈现出某种持续向上或持续下降的变动一般而言,选择主成分的标准通常是要求所选主成分的累积方差总和占全部方差的()A. 60%以上B。
统计学(第五版)贾俊平期末考试模拟试题二教学文案

模拟试题二一.单项选择题(每小题2分,共20分)一辆新购买的轿车,在正常行使条件下,一年内发生故障的次数及相应的概率如下表所示:故障次数()0 1 2 3概率()0.05 0.25 0.40 0.30正好发生1次故障的概率为()A.0.05B.0.25C.0.40D.0.30要观察200名消费者每月手机话费支出的分布状况,最适合的图形是()A.饼图B.条形图C.箱线图D.直方图从某种瓶装饮料中随机抽取10瓶,测得每瓶的平均净含量为355毫升。
已知该种饮料的净含量服从正态分布,且标准差为5毫升。
则该种饮料平均净含量的90%的置信区间为()A.B.C.D.根据最小二乘法拟合线性回归方程是使()A.B.C.D.一项调查表明,大学生中因对课程不感兴趣而逃课的比例为20%。
随机抽取由200名学生组成的一个随机样本,检验假设,,得到样本比例为。
检验统计量的值为()A.B.C.D.在实验设计中,将种“处理”随机地指派给试验单元的设计称为()A.试验单元B.完全随机化设计C.随机化区组设计D.因子设计某时间序列各期观测值依次为10、24、37、53、65、81,对这一时间序列进行预测适合的模型是()A.直线模型B.二次曲线模型C.指数曲线模型D.修正指数曲线模型在因子分析中,变量的共同度量反映的是()A.第个公因子被变量的解释的程度B.第个公因子的相对重要程度C.第个变量对公因子的相对重要程度D.变量的信息能够被第个公因子所解释的程度如果要检验两个独立总体的分布是否相同,采用的非参数检验方法是()A.Mann-Whitney检验B.Wilcoxon符号秩检验C.Kruskal-Wallis检验D.Spearman秩相关及其检验在二元线性回归方程中,偏回归系数的含义是()A.变动一个单位时,的平均变动值为B.变动一个单位时,因变量的平均变动值为C.在不变的条件下,变动一个单位时,的平均变动值为D.在不变的条件下,变动一个单位时,的平均变动值为二.简要回答下列问题(每小题10分,共20分)画出时间序列预测方法选择的框图。
统计学第四版答案(贾俊平)

统计学第四版答案(贾俊平)第1章统计和统计数据1.1 指出下⾯的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员⼯对企业某项改⾰措施的态度(赞成、中⽴、反对)。
(5)购买商品时的⽀付⽅式(现⾦、信⽤卡、⽀票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 ⼀家研究机构从IT从业者中随机抽取1000⼈作为样本进⾏调查,其中60%回答他们的⽉收⼊在5000元以上,50%的⼈回答他们的消费⽀付⽅式是⽤信⽤卡。
(1)这⼀研究的总体是什么?样本是什么?样本量是多少?(2)“⽉收⼊”是分类变量、顺序变量还是数值变量?(3)“消费⽀付⽅式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 ⼀项调查表明,消费者每⽉在⽹上购物的平均花费是200元,他们选择在⽹上购物的主要原因是“价格便宜”。
(1)这⼀研究的总体是什么?(2)“消费者在⽹上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的⽹上购物者”。
(2)分类变量。
1.4 某⼤学的商学院为了解毕业⽣的就业倾向,分别在会计专业抽取50⼈、市场营销专业抽取30、企业管理20⼈进⾏调查。
(1)这种抽样⽅式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章⽤统计量描述数据为7.2分钟,标准差为1.97分钟,第⼆种排队⽅式的等待时间(单位:分钟)如下:5.56.6 6.7 6.87.1 7.3 7.4 7.8 7.8(1)计算第⼆种排队时间的平均数和标准差。
(2)⽐两种排队⽅式等待时间的离散程度。
(3)如果让你选择⼀种排队⽅式,你会选择哪⼀种?试说明理由。
详细答案:(1)(岁);(岁)。
(2);。
第⼀中排队⽅式的离散程度⼤。
贾俊平《统计学》(第5版)章节题库-第2章 数据的搜集【圣才出品】

第2章 数据的搜集一、单项选择题1.二手数据的特点是( )。
A.采集数据的成本低,但搜集比较困难B.采集数据的成本低,搜集比较容易C.数据缺乏可靠性D.不适合自己研究的需要【答案】B【解析】二手数据是指与研究相关的原信息已经存在,只是对原信息重新加工、整理,使之成为进行统计分析可以使用的数据。
二手数据具有搜集方便、数据采集快、采集成本低等优点,但是得到的数据往往缺乏相关性。
2.从含有N个元素的总体中,抽取n个元素作为样本,使得总体中的每一个元素都有相同的机会(概率)被抽中,这样的抽样方式称为( )。
A.简单随机抽样B.分层抽样C.系统抽样D.整群抽样【答案】A【解析】分层抽样也称分类抽样,它是在抽样之前先将总体的元素划分为若干层(类),然后从各个层中抽取一定数量的元素组成一个样本。
系统抽样也称等距抽样,先将总体各素,直至抽取n个元素组成一个样本。
整群抽样是指先将总体划分成若干群,然后以群作为抽样单元从中抽取部分群组成一个样本,再对抽中的每个群总包含的所有元素进行观察。
3.从总体中抽取一个元素后,把这个元素放回到总体中再抽取第二个元素,直至抽取n个元素为止,这样的抽样方法称为( )。
A.重复抽样B.不重复抽样C.分层抽样D.整群抽样【答案】A【解析】重复抽样又称放回式抽样,是指每次从总体中抽取的样本单位,经检验之后又重新放回总体,参加下次抽样,这种抽样的特点是总体中每个样本单位被抽中的概率是相等的。
4.一个元素被抽中后不再放回总体,然后再从剩下的元素中抽取第二个元素,直到抽取”个元素为止,这样的抽样方法称为( )。
A.重复抽样B.不重复抽样C.分层抽样D.整群抽样【解析】不重复抽样亦称不放回抽样,是指每次从总体中抽取的样本单位,经检验之后不再放回总体,在下次抽样时不会再次抽到前面已抽中过的样品单位。
总体每经一次抽样,其样本单位数就减少一个,因此每个样品单位在各次抽样中被抽中的概率是不同的。
5.在抽样之前先将总体的元素划分为若干类,然后从各个类中抽取一定数量的元素组成一个样本,这样的抽样方式称为( )。
统计学贾俊平-第四版课后习题答案-2
(2)绘制第一、二、三产业国内生产总值的线图。
4.1一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:
2 4 7 10 10 10 12 12 14 15
要求:
(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
4.8一项关于大学生体重状况的研究发现.男生的平均体重为60kg,标准差为5kg;女生的平均体重为50kg,标准差为5kg。请回答下面的问题:
(3)两位调查人员得到这l 100名少年儿童身高的最高者或最低者的机会是否相同?如果不同,哪位调查研究人员的机会较大?
解:(1)不一定相同,无法判断哪一个更高,但可以判断,样本量大的更接近于总体平均身高。
(2)不一定相同,样本量少的标准差大的可能性大。
(3)机会不相同,样本量大的得到最高者和最低者的身高的机会大。
(2)计算分布的偏态系数和峰态系数。
解:
Statistics
企业利润组中值Mi(万元)
N
Valid
120
Missing
0
Mean
426.6667
Std. Deviation
116.48445
Skewness
0.208
Std. Error of Skewness
0.221
Kurtosis
-0.625
Std. Error of Kurtosis
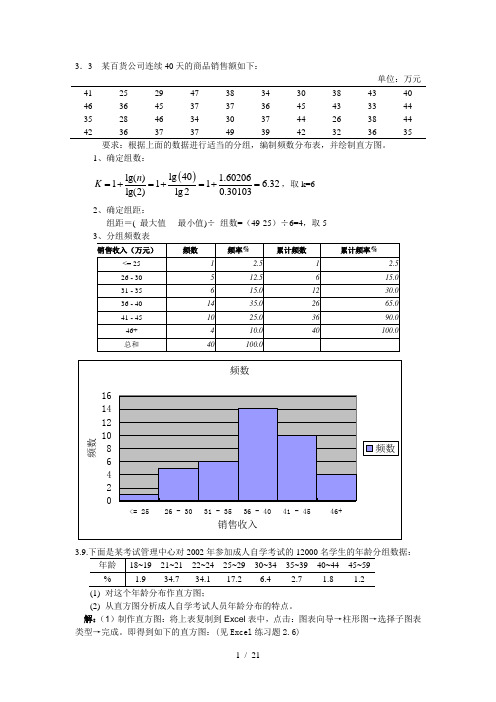
3.3某百货公司连续40天的商品销售额如下:
单位:万元
41
25
29
47
38
34
30
38
43
贾俊平第四版统计学-第二章 习题

第二章习题一、选择题1.含有N个元素的总体中,抽取n个元素作为样本,使得总体中的每一个元素都有相同的机会(概率)被抽中,这样的抽样方式称为()A.简单随机抽样B.分层抽样C.系统抽样D.整群抽样2.为了调查某校学生的购书费用支出,从男生中抽取60名学生调查,从女生中抽取40名学生调查,这种调查方法是()A.简单随机抽样B.整群抽样C.系统抽样D.分层抽样3.为了调查某校学生的购书费用支出,从全校抽取4个班级的学生进行调查,这种调查方法是()A.简单随机抽样B.系统抽样C.分层抽样D.整群抽样4.为了调查某校学生的购书费用支出,将全校学生的名单按拼音顺序排列后,每隔50名学生抽取一名学生进行调查,这种调查方法是()A.简单随机抽样B.整群抽样C.系统抽样D.分层抽样5.为了解女性对某种品牌化妆品的购买意愿,调查者在街头随意拦截部分女性进行调查。
这种调查方式是()A.简单随机抽样B.分层抽样C.方便抽样D.自愿抽样6.下面的哪种抽样方式不属于概率抽样()A.系统抽样B.整群抽样C.分层抽样D.滚雪球抽样7.与概率抽样相比,非概率抽样的缺点是()A.样本统计量的分布是确定的B.无法使用样本的结果对总体相应的参数进行推断C.调查的成本比较高D.不适合于探索性的研究8.为了估计某城市愿意乘坐公交车上下班的人数的比例,在收集数据时,最有可能采用的数据搜集方法是()A.普查B.公开发表的资料C.随机抽样D.实验9.如果一个样本因人故意操纵而出现偏差,这种误差属于()A.抽样误差B.非抽样误差C.设计误差D.实验误差10.指出下面的陈述中哪一个是错误的()A.抽样误差只存在于概率抽样中B.非抽样误差只存在于非概率抽样中C.无论是概率抽样还是非概率抽样都存在非抽样误差D.在全面调查中也存在非抽样误差二、简答题有四种常用的概率抽样方法:简单随机抽样、分层抽样、整群抽样、等距抽样,请分别对其含义进行解释。
统计学原理贾俊平期末考试重点

统计学期末(单选、10个填空、5个判断、三个计算、一道论述)第一章导论1、统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。
分析数据:分为描述统计方法和推断统计方法两种方法。
描述统计:研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法。
推断统计:是研究如何利用样本数据来推断总体特征的统计方法。
推断统计内容包含参数估计和假设检验2、统计数据的类型:(1)按照采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据与数值型数据。
注意:分类数据和顺序数据都是表现事物的品质特征,通常是用文字来表述的,其结果均表现为类别,因此可以通称为定性数据或品质数据(qualitative data)。
数值型数据说明的是现象的数量特征,通常用数值来表现,因此可以统称为定量数据或数量数据(quantitative data)。
(2)按照统计数据的收集方法,可以将统计数据分为观测数据和实验数据。
(3)按照被描述的现象与时间的关系,可以将统计数据分为截面数据、时间序列数据(和面板数据 panal data)。
3、抽样独立性问题:总体区分为有限总体和无限总体,目的是为了判别在抽样中每次抽取是否独立(类似抽小球是否放回的问题)。
在统计推断中,通常是针对无限总体的,因而通常把总体看做随机变量(random variable)。
统计上的总体通常是一组观测数据,而不是一群人或者一些物品的简单集合。
4、统计指标按其所反映的数量特点和作用不同,分为数量指标、质量指标。
样本(sample)是从总体中抽取的一部分元素的集合,构成样本的元素的数目称为样本量(sample size)。
抽样的目的是根据样本提供的信息推断总体的特征。
5、总体参数(parameter)是用来描述总体特征的概括性数字度量,是研究者想要了解的某种特征值。
样本统计量(statistic)是用来描述样本特征的概括性数字度量,是根据样本数量计算出来的一个量。
统计学(第五版)贾俊平_课后思考题和练习题答案(最终完整版)

第一部分 思考题
第一章思考题 1.1 什么是统计学 统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得 出结论。 1.2 解释描述统计和推断统计 描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。 推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。 1.3 统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果, 数据表现为类别,用文字来表述; (定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这 些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件 下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 1.4 解释分类数据,顺序数据和数值型数据 答案同 1.3 1.5 举例说明总体,样本,参数,统计量,变量这几个概念 对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百 个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的 数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是 统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 1.6 变量的分类 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。 1.7 举例说明离散型变量和连续性变量 离散型变量,只能取有限个值,取值以整数位断开,比如“企业数” 连续型变量,取之连续不断,不能一一列举,比如“温度” 。 1.8 统计应用实例 人口普查,商场的名意调查等。 1.9 统计应用的领域 经济分析和政府分析还有物理,生物等等各个领域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模拟试题二
一. 单项选择题(每小题2分,共20分)
一辆新购买的轿车,在正常行使条件下,一年内发生故障的次数及相应的概率如下表所示:
故障次数()0 123
概率()
正好发生1次故障的概率为()
A.
B.
C.
D.
要观察200名消费者每月手机话费支出的分布状况,最适合的图形是()
A.饼图
B.条形图
C.箱线图
D.直方图
从某种瓶装饮料中随机抽取10瓶,测得每瓶的平均净含量为355毫升。
已知该种饮料的净含量服从正态分布,且标准差为5毫升。
则该种饮料平均净含量的90%的置信区间为()
A.
B.
C.
D.
根据最小二乘法拟合线性回归方程是使()
A.
B.
C.
D.
一项调查表明,大学生中因对课程不感兴趣而逃课的比例为20%。
随机抽取由200名学生组成的一个随机样本,检验假设,,得到样本比例为。
检验统计量的值为()
A.
B.
C.
D.
在实验设计中,将种“处理”随机地指派给试验单元的设计称为()
A.试验单元
B.完全随机化设计
C.随机化区组设计
D.因子设计
某时间序列各期观测值依次为10、24、37、53、65、81,对这一时间序列进行预测适合的模型是()
A.直线模型
B.二次曲线模型
C.指数曲线模型
D.修正指数曲线模型
在因子分析中,变量的共同度量反映的是()
A.第个公因子被变量的解释的程度
B.第个公因子的相对重要程度
C.第个变量对公因子的相对重要程度
D.变量的信息能够被第个公因子所解释的程度
如果要检验两个独立总体的分布是否相同,采用的非参数检验方法是()
A.Mann-Whitney检验
B.Wilcoxon符号秩检验
C.Kruskal-Wallis检验
D.Spearman秩相关及其检验
在二元线性回归方程中,偏回归系数的含义是()
A.变动一个单位时,的平均变动值为
B.变动一个单位时,因变量的平均变动值为
C.在不变的条件下,变动一个单位时,的平均变动值为
D.在不变的条件下,变动一个单位时,的平均变动值为
二. 简要回答下列问题(每小题10分,共20分)
画出时间序列预测方法选择的框图。
简述因子分析的基本步骤。
三. 计算与分析下列各题(每小题15分,共60分)
假定其他条件不变,某种商品的需求量()与该商品的价格()有关,现取得以下样本数据:
价格(元)7658754
需求量(公斤)75807060658590
根据上表数据计算得:,,,。
(1)绘制散点图,说明需求量与价格之间的关系。
(2)拟合需求量对价格的直线回归方程,说明回归系数的实际意义。
(3)计算当价格为10元时需求量的点估计值。
一家物业公司需要购买一批灯泡,你接受了采购灯泡的任务。
假如市场上有两种比较知名品牌的灯泡,你希望从中选择一种。
为此,你从两个供应商处各随机抽取了60个灯泡的随机样本,进行“破坏性”试验,得到灯泡寿命数据经分组后如下:
灯泡寿命(小时)供应商甲供应商乙
700~900124
900~11001434
1100~13002419
1300~1500103
合计60 60
(1)请用直方图直观地比较这两个样本,你能得到什么结论
(2)你认为应当采用哪一种统计量来分别描述供应商甲和供应商乙灯泡寿命的一般水平请简要说明理由
(3)哪个供应商的灯泡具有更长的寿命
(4)哪个供应商的灯泡寿命更稳定
为估计每个网络用户每天上网的平均时间是多少,随机抽取了225个网络用户的简单随机样本,得样本均值为小时,样本标准差为小时。
(1)试以95%的置信水平,建立网络用户每天平均上网时间的区间估计。
(2)在所调查的225个网络用户中,年龄在20岁以下的用户为90个。
以95%的置信水平,建立年龄在20岁以下的网络用户比例的置信区间。
(注:,)
对于来自五个总体的样本数据进行方差分析,得到下面的方差分析表()
差异源SS df MS F P-value F crit
组间4B D
组内A15C
总计19<
(1)计算出表中A、B、C、D四个单元格的数值。
(2)B、C两个单元格中的数值被称为什么它们所反映的信息是什么
(3)在的显著性水平下,检验的结论是什么
模拟试题二解答
一、单项选择题(每小题2分,共20分)
;2. D;3. C;4. B;5. A;6. B;7. C;8. D;9. A;10. C。
二、简要回答下列问题(每小题10分,共20分)
1. 框图如下:
2. (1)对数据进行检验,以判断手头的数据是否适合作因子分析。
用于因子分析的变量必须是相关的。
一般来说,相关矩阵中的大部分相关系数小于,就不适合作因子分析了。
(2)因子提取。
根据原始变量提取出少数几个因子,使得少数几个因子能够反映原始变量的绝大部分信息,从而达到变量降维的目的。
(3)因子命名。
一个因子往往包含了多个原始变量的信息,它究竟反映了原始变量的哪些共同信息因子分析得到的因子的含义是模糊的,需要重新命名,以便对研究的问题做出合理解释。
(4)根据因子得分函数计算因子在每个样本上的具体取值,以便对各样本进行综合评价和排序。
三、计算与分析各题(每小题15分,共60分)
1.(1)散点图如下:
从散点图可以看出,需求量与价格之间存在负线性关系,即随着价格的提高,需求量则随之下降。
(2)由最小二乘法可得:
,。
总需求量与价格的一元线性回归方程为:。
回归系数表示:价格每增加1元,总需求量平均减少公斤。
(3)公斤。
2. 两个供应商灯泡使用寿命的直方图如下:
从集中程度来看,供应商甲的灯泡的使用寿命多数集中在1100小时~1300小时之间,供应商乙的灯泡的使用寿命多数集中在900小时~1100小时之间。
从离散程度来看,供应商甲的灯泡的使用的离散程度大于供应商乙的离散程度。
(2)应该采用平均数来描述供应商甲和供应商乙灯泡寿命的一般水平,因为两个供应商灯泡使用寿命的分布基本上是对称分布的。
(3)计算两个供应商灯泡使用寿命的平均数如下:
小时。
小时。
甲供应商灯泡使用寿命更长。
(4)计算两个供应商灯泡使用寿命的标准差和离散系数如下:
小时。
小时。
由于,说明供应商乙的灯泡寿命更稳定。
3. (1)已知:,,,。
网络用户每天平均上网时间的95%的置信区间为:
即(,)。
(2)样本比例。
龄在20岁以下的网络用户比例的95%的置信区间为:
即(%,%)。
4. (1)A=;B=÷4=;C=÷15=;D=÷=。
(2)B=被称为组间方差,反映组间平均误差的大小;C=被称为组内方差,反映组内平均误差的大小。
(3)由于,拒绝原假设,表明五个总体的均值之间不全相等。