《统计分析和SPSS的应用(第五版)》课后练习答案与解析(第5章)
《统计分析和SPSS的应用(第五版)》课后练习答案与解析(第5章)
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
《统计分析与SPSS的应用 第五版 》课后练习答案 第 章

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS 统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing Value)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“?”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
如何在SPSS中指定变量的计算尺度?变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。
《统计分析和SPSS的应用(第五版)》课后练习答案(第5章)

《统计分析和SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值 = 75t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
《统计分析与SPSS的应用(第五版)》课后练习答案.doc-(1)

《统计剖析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、 SPSS的中文全名是:社会科学统计软件包(后更名为:统计产品与服务解决方案)英文全名是: Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、 SPSS的两个主要窗口是数据编写器窗口和结果查察器窗口。
数据编写器窗口的主要功能是定义SPSS数据的结构、录入编写和管理待剖析的数据;结果查察器窗口的主要功能是现实管理SPSS统计剖析结果、报表及图形。
3、 SPSS的数据集:SPSS 运转时可同时翻开多个数据编写器窗口。
每个数据编写器窗口分别显示不一样的数据会合(简称数据集)。
活动数据集:此中只有一个数据集为目前数据集。
SPSS 只对某时辰的目前数据集中的数据进行剖析。
4、 SPSS的三种基本运转方式:完好窗口菜单方式、程序运转方式、混淆运转方式。
完好窗口菜单方式:是指在使用SPSS的过程中,所有的剖析操作都经过菜单、按钮、输入对话框等方式来达成,是一种最常有和最广泛的使用方式,最大长处是简短和直观。
程序运转方式:是指在使用 SPSS的过程中,统计剖析人员依据自己的需要,手工编写 SPSS命令程序,而后将编写好的程序一次性提交给计算机履行。
该方式合用于大规模的统计剖析工作。
5、 .sav混淆运转方式:是前二者的综合。
是数据编写器窗口中的SPSS数据文件的扩展名.spv是结果查察器窗口中的SPSS剖析结果文件的扩展名.sps是语法窗口中的SPSS程序6、 SPSS 的数据加工和管理功能主要集中在编写、数据等菜单中;统计剖析和画图功能主要集中在剖析、图形等菜单中。
7、概率抽样 (probability sampling):也称随机抽样,是指按必定的概率以随机原则抽取样本,抽取样本时每个单位都有必定的时机被抽中,每个单位被抽中的概率是已知的,或是能够计算出来的。
《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)

《统计分析与S P S S的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t 统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
(1)分析→描述统计→描述、频率(2)分析→比较均值→单样本T检验每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)

鼠号
1
2
3
4
5
6
7
8
9
饲料1
33.1
33.1
26.8
36.3
39.5
30.9
33.4
31.5
28.6
饲料2
36.7
28.8
35.1
35.2
43.8
25.7
36.5
37.9
28.7
方式2:甲组有12只喂饲料1,乙组有9只喂饲料2所测得的钙留存量数据如下:
-9.640
381
.000
-.420
.044
-.505
-.334
假设方差不相等
-9.815
345.536
.000
-.420
.043
-.504
-.336
分析:由表5-3可以看出,提问方式不同所做的相同决策的平均比例是46%和88%,认为决策者的决策与提问方式有关。由表5-4看出,独立样本在0.05的检验值为0,小于0.05,故拒绝原假设,认为决策者对事实所作出的反应与提问方式有关,心理学家的观点更站得住脚。
3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。然而心理学家则倾向于认为提出事实的方式是有关系的。为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。
原假设:决策与提问方式无关,即u-u0=0
步骤:生成spss数据→分析→比较均值→两独立样本t检验→相关设置→输出结果
甲组饲料1:29.7 26.7 28.9 31.1 31.1 26.8 26.3 39.5 30.9 33.4 33.1 28.6
统计分析与SPSS的应用第五版课后练习答案doc1
《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
数据编辑器窗口的主要功能是定义SPSSa据的结构、录入编辑和管理待分析的数据;结果查看器窗口的主要功能是现实管理SPS必计分析结果、报表及图形。
3、SPSS的数据集:SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:完全窗口菜单方式、程序运行方式、混合运行方式。
完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPS%令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPS的析结果文件的扩展名.sps 是语法窗口中的SPS钠序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计分析和SPSS的应用(第五版)》课后练习答案解析(第5章)教学教材
《统计分析和S P S S 的应用(第五版)》课后练习答案解析(第5章)《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
(1)分析→描述统计→描述、频率(2)分析→比较均值→单样本T检验每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
《统计分析与SPSS的应用(第五版)》课后练习答案
《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
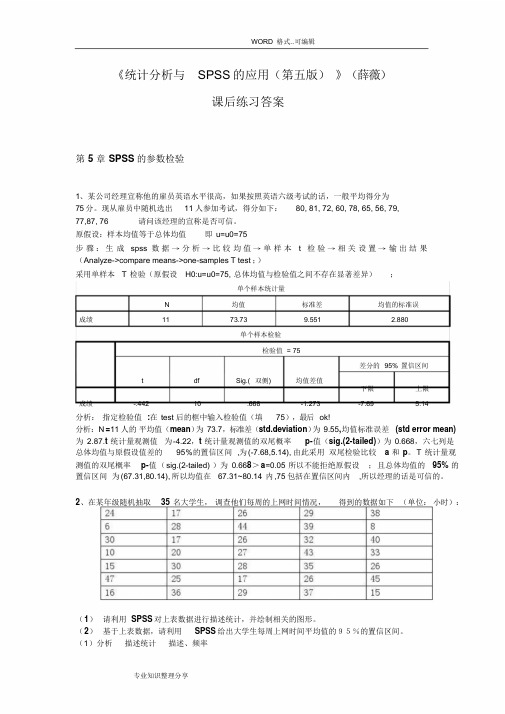
WORD 格式 ..可编辑《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第 5 章 SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即 u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→ 相关设置→ 输出结果(Analyze->compare means->one-samples T test ;)采用单样本 T 检验(原假设 H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值 = 75差分的 95% 置信区间t df Sig.( 双侧 ) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值 :在test后的框中输入检验值(填75),最后 ok!分析:N =11 人的平均值(mean)为 73.7,标准差(std.deviation)为 9.55,均值标准误差(stderror mean)为 2.87.t统计量观测值为 -4.22,t统计量观测值的双尾概率p-值( sig.(2-tailed) )为0.668,六七列是总体均值与原假设值差的95%的置信区间 ,为 (-7.68,5.14), 由此采用双尾检验比较 a 和 p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668> a=0.05所以不能拒绝原假设;且总体均值的95% 的置信区间为 (67.31,80.14), 所以均值在67.31~80.14 内 ,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取 35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用 SPSS 对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用 SPSS 给出大学生每周上网时间平均值的95%的置信区间。
(1)分析描述统计描述、频率专业知识整理分享WORD 格式 ..可编辑(2)分析比较均值单样本 T 检验每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
然而心理学家则倾向于认为提出事实的方式是有关系的。
为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。
原假设:决策与提问方式无关,即u-u0=0步骤:生成 spss数据→分析→比较均值→两独立样本 t检验→相关设置→输出结果表 5-3组统计量提问方式N均值标准差均值的标准误决策丢票再买200 .46 .500 .035丢钱再买183 .88 .326 .024表5-4独立样本检验方差方程的 Levene检验均值方程的t 检验差分的 95% 置信Sig.( 双均值差标准误差区间F Sig. t df侧) 值值下限上限决假设方差相等257.985 .00-9.640 381.000-.420 .044-.505-.334策假设方差不相-9.815 345.536.000-.420 .043-.504-.336等分析:由表 5-3 可以看出,提问方式不同所做的相同决策的平均比例是46%和 88%,认为决策者的决策与提问方式有关。
由表5-4 看出,独立样本在0.05 的检验值为0,小于 0.05,故拒绝原假设,认为决策者对事实所作出的反应与提问方式有关,心理学家的观点更站得住脚。
分析:从上表可以看出票丢仍买的人数比例为46%,钱丢仍买的人数比例为 88%,两种方式的样本比例有较大差距。
1.两总体方差是否相等F 检验: F 的统计量的观察值为257.98, 对应的P 值为 0.00,;如果显著性水平为 0.05,由于概率 P 值小于0.05,两种方式的方差有显著差异。
专业知识整理分享WORD 格式 ..可编辑看假设方差不相等行的结果。
2.两总体均值(比例)差的检验: .T 统计量的观测值为 -9.815, 对应的双尾概率为0.00,T 统计量对应的概率 P 值<0.05, 故推翻原假设 ,表明两总体比例有显著 差异 更倾向心理学家的说法。
. 4、一种植物只开兰花和白花。
按照某权威建立的遗传模型,该植物杂交的后代有75% 的 几率开兰花, 25% 的几率开白花。
现从杂交种子中随机挑选200 颗,种植后发现 142 株 开了兰花,请利用SPSS 进行分析,说明这与遗传模型是否一致? 原假设:开蓝花的比例是 75%,即 u=u0=0.75步骤:生成 spss 数据→分析→比较均值→单样本 t 检验→相关设置→输出结果表 5-5单个样本统计量N 均值 标准差 均值的标准误开花种类 200 1.29 .455 .032 表5-6单个样本检验检验值 =0.75差分的 95% 置信区间t df Sig.( 双侧 ) 均值差值下限 上限 开花种类16.788199.000.540.48.60分析: 由于检验的结果 sig 值为 0,小于 0.05,故拒绝原假设, 由于检验区间为( 1.23,1.35), 0.75 不在此区间内,进一步说明原假设不成立,故认为与遗传模型不一致。
5、给幼鼠喂以不同的饲料,用以下两种方法设计实验:方式 1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下: 鼠号12 3 4 5 6 7 8 9 饲料 1 33.133.1 26.8 36.3 39.5 30.9 33.4 31.5 28.6 饲料 2 36.728.835.135.243.825.736.537.928.7方式 2:甲组有 12 只喂饲料 1,乙组有 9 只喂饲料 2 所测得的钙留存量数据如下 :甲组饲料 1:29.726.7 28.9 31.1 31.1 26.8 26.3 39.5 30.9 33.4 33.1 28.6 乙组饲料 2:28.728.3 29.3 32.2 31.1 30.0 36.2 36.8 30.0 请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显著不同。
原假设:不同饲料使幼鼠体内钙的留存量无显著不同。
方式 1 步骤:生成 spss 数据→分析→比较均值→配对样本t 检验→相关设置→输出结果表5-7成对样本统计量均值N 标准差均值的标准误专业知识整理分享WORD 格式 ..可编辑对 1 饲料 1钙存量32.578 9 3.8108 1.2703 饲料 2钙存量34.267 9 5.5993 1.8664 表5-8成对样本相关系数N 相关系数Sig .对 1 饲料 1钙存量 & 饲料 2钙存量9 .571.108表5-9成对样本检验成对差分差分的 95% 置信均值的标准区间Sig.( 双均值标准差误下限上限t df 侧 )对 1 饲料 1钙存量 - 饲料 2 -1.6889 4.6367 1.5456 -5.2529 1.8752 -1.093 8 .306钙存量方式 2步骤:生成 spss数据→分析→比较均值→独立样本 t检验→相关设置→输出结果表5-10组统计量饲料类型N 均值标准差均值的标准误钙存量饲料 1 12 30.508 3.6882 1.0647 dimension19 31.400 3.1257 1.0419饲料 2表5-11独立样本检验方差方程的 Levene检验均值方程的t 检验差分的 95%置信Sig.(双均值差标准误差区间F Sig. t df 侧 )值值下限上限钙存假设方差相.059 .811 -.584 19.566-.8917 1.5268-4.087 2.3040量等3假设方差不-.599 18.645 .557-.8917 1.4897-4.013 2.2303相等6分析:采用配对样本t检验法所得结果如表5-7,5-8,5-9 所示,配对样本的分析结果可以看出两组的平均差是 1.789在置信区间内( -5.2529 , 1.8752 )同时 sig 值为 0.153>0.05 不应该拒绝原假设。
采用独立样本 t检验法所得结果如表 5-10,5-11 所示,可以看出均值差为 0.892 在置信区间内 sig 值为 0.405 ,大于 0.05 ,故不能拒绝原假设。
所以,两种饲料使用后的钙存量无显著差异。
6、如果将第 2 章第 9 题的数据看作是来自总体的样本,试分析男生和女生的课程平均分是否存在显著差异?专业知识整理分享WORD 格式 ..可编辑原假设:男女生课程平均分无显著差异步骤:分析→比较均值→单因素分析→因变量选择课程,因子选择性别进行→输出结果:表5-12描述poli均值的95% 置信区间N均值标准差标准误下限上限极小值极大值female 3078.8667 10.41793 1.90205 74.9765 82.7568 56.00 94.00 male 3076.7667 18.73901 3.42126 69.7694 83.7639 .00 96.00 总数6077.8167 15.06876 1.94537 73.9240 81.7093 .00 96.00 表5-13ANOVApoli平方和df 均方 F 显著性组间66.150 1 66.150 .288 .594 组内13330.833 58 229.842总数13396.983 59分析:由表 5-12和 5-13可以看,出男生和女生成绩平均差为1.4021在置信区间内sig值为0.307,大于 0.05,故不能拒绝原假设,即认为男生和女生的平均成绩没有显著差异7、如果将第 2 章第 9 题的数据看作是来自总体的样本,试分析哪些课程的平均分差异不显著。
步骤:计算出各科的平均分:转换→计算变量→相关的设置表5-14组统计量sex N 均值标准差均值的标准误average female 30 67.5208 9.08385 1.65848 male 30 68.9229 9.85179 1.79868重新建立 SPSS数据→分析→比较均值→单因素→进行方差齐性检验→选择Tukey 方法进行检验。
利用配对样本T 检验,逐对检验8 、以下是对促销人员进行培训前后的促销数据:试分析该培训是否产生了显著效果。
培训前440 500 580 460 490 480 600 590 430 510 320 470 培训后620 520 550 500 440 540 500 640 580 620 590 620原假设:培训前后效果无显著差异步骤:生成 spss数据→分析→比较均值→配对样本t检验→相关设置→输出结果表5-15专业知识整理分享WORD 格式 ..可编辑 成对样本统计量成对样本检验 成对差分差分的 95% 置信区均值的标准间Sig.( 双均值标准差误下限 上限t df 侧 ) 对 1 培训前- 培 -70.833 106.041 30.611 -138.20 -3.458 -2.314 11 .041训后9均值 N 标准差 均值的标准误对 1 培训前 489.17 12 78.098 22.545培训后560.0012 61.93817.880 表5-16成对样本相关系数N 相关系数 Sig.对 1培训前 & 培训后12-.135 .675 表5-17成对样本检验 成对差分差分的 95% 置信区均值的标准间Sig.( 双均值标准差误下限上限t df 侧 ) 对 1 培训前- 培 -70.833 106.041 30.611 -138.209 -3.458 -2.31411 0.41 训后分析:由表 5-15,5-16,5-17 可以看出,培训前与培训后的均值差为 70.83 ,由 sig 值为0.041,小于 0.05,故拒绝原假设,认为培训前后有显著差异 即培训产生了显著效果专业知识整理分享。