人大版_贾俊平_统计学_第三版_课后习题答案
统计学(第三版课后习题答案

Hah 和网速是无形的1:各章练习题答案2.1 (1)属于顺序数据。
(2)频数分布表如下:服务质量等级评价的频数分布服务质量等级家庭数(频率)频率%A1414B2121C3232D1818E1515合计100100(3)条形图(略)2.2 (1)频数分布表如下:(2)某管理局下属40个企分组表按销售收入分组(万元)企业数(个)频率(%)先进企业良好企业一般企业落后企业11119927.527.522.522.5合计40 100.02.3 频数分布表如下:某百货公司日商品销售额分组表按销售额分组(万元)频数(天)频率(%)25~30 30~35 35~40 40~45 45~5046159610.015.037.522.515.0合计40 100.0 直方图(略)。
2.4 (1)排序略。
(2)频数分布表如下:100只灯泡使用寿命非频数分布按使用寿命分组(小时)灯泡个数(只)频率(%)650~660 2 2660~670 5 5670~680 6 6680~690 14 14690~700 26 26700~710 18 18710~720 13 13720~730 10 10730~740 3 3740~750 3 3合计100 100 直方图(略)。
2.5 (1)属于数值型数据。
(2)分组结果如下:分组 天数(天)-25~-20 6 -20~-15 8 -15~-10 10 -10~-5 13 -5~0 12 0~5 4 5~10 7 合计60(3)直方图(略)。
2.6 (1)直方图(略)。
(2)自学考试人员年龄的分布为右偏。
(2)A 班考试成绩的分布比较集中,且平均分数较高;B 班考试成绩的分布比A 班分散,且平均成绩较A 班低。
2.82.9 L U 。
(2)17.21 s (万元)。
2.10 (1)甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
贾俊平统计学第一章课后思考题答案

1.什么是统计学?答:统计学是关于数据的科学,它所提供的是一套有关数据收集、处理、分析、解释并从数据中得出结论的方法,统计所研究的是来自各领域的数据。
数据收集即取得统计数据;数据处理是将数据用图表等形式展示出来;数据分析则是选择适当的统计方法研究数据,并从数据中提取有用信息进而得出结论。
2.解释描述统计和推断统计。
答:数据分析所用的方法可分为描述统计方法和推断统计方法。
(1)描述统计研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法。
(2)推断统计是研究如何利用样本数据来推断总体特征的统计方法。
比如,对产品的质量进行检验,往往是破坏性的,不可能对每个产品进行测量。
这就需要抽取部分个体即样本进行测量,然后根据获得的样本数据对所研究的总体特征进行推断,这就是推断统计要解决的问题。
3.统计数据可分为哪几种类型?不同类型的数据各有什么特点?答:统计数据是对现象进行测量的结果,可以从不同角度对统计数据进行分类:(1)按照所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据。
①在分类数据中,各类别之间是平等的并列关系,无法区分优劣或大小,各类别之间的顺序是可以改变的;②顺序数据也表现为类别,但这些类别之间是有顺序的;③数值型数据具有分类数据和顺序数据的特点,并且还可以进行加、减、乘、除运算。
(2)按照统计数据的收集方法,可以将其分为观测数据和实验数据。
①观测数据是通过调查或观测而收集到的数据,这类数据是在没有对事物进行人为控制的条件下得到的,有关社会经济现象的统计数据几乎都是观测数据;②实验数据是在实验中通过控制实验对象收集到的数据,自然科学领域的大多数数据都是实验数据。
(3)按照被描述的现象与时间的关系,可以将统计数据分为截面数据和时间序列数据。
①截面数据是在相同或近似相同的时间点上收集的数据,这类数据通常是在不同的空间上获得的,用于描述现象在某一时刻的变化情况;②时间序列数据是在不同时间上收集到的数据,这类数据是按时间顺序收集到的,用于描述现象随时间变化的情况。
统计学课后习题答案(统计学第三版_高等_袁卫、庞皓、曾五一、贾俊平)

第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
统计学(第三版课后习题答案
18.29(元);原因:尽管两个企业的单位成本相同,但单位
成本较低的产品在乙企业的产量中所占比重较大,因此拉低了
总平均成本。
2.11 =426.67(万元);(万元)。
2.12 (1)(2)两位调查人员所得到的平均身高和标准差应该差不
多相同,因为均值和标准差的大小基本上不受样本大小的影
响。
(3)具有较大样本的调查人员有更大的机会取到最高或最低者,因
错误。
6.5 (1)检验统计量,在大样本情形下近似服从标准正态分布;
Hah 和网速是无形的
1:各章练习题答案
2.1 (1) 属于顺序数据。
(2)频数分布表如下:
服务质量等级评价的频数分布
服务质 家庭数 频率%
量等级 (频率)
A
14
14
B
21
21
C
32
32
D
18
18
E
15
15
合计 100
100
(3)条形图(略)
2.2 (1)频数分布表如下:
40个企业按产品销售收入分组表
幼儿组身高的离散系数:;
由于幼儿组身高的离散系数大于成年组身高的离散系数,说明幼儿
组身高的离散程度相对较大。
2.15 下表给出了一些主要描述统计量,请读者自己分析。
方法
方法
方法
A
B
C
平均 165.6 平均 128.73 平均 125.53
中位
中位
中位
数 165 数 129 数 126
众数 164 众数 128 众数 126
为样本越大,变化的范围就可能越大。
2.13 (1)女生的体重差异大,因为女生其中的离散系数为0.1大于
统计学贾俊平第三章课后答案

一、思考题3.1数据的预处理包括数据审核,数据筛选,数据排序,数据透视表。
3.2分类数据整理:频数分布表(频数,比例,百分比,比率)图示方法:条形图,对比条形图,帕累托图,饼图。
顺序数据的整理:频数分布表(累计频数,累计频率)图示方法:环形图。
3.3数值型数据的分组方法是组距分组,步骤:1.确定组数:组数的确定应以能够显示数据的分布特征和规律为目的。
在实际分组时,组数一般为5≤K ≤152.确定组距:组距(Class Width)是一个组的上限与下限之差,可根据全部数据的最大值和最小值及所分的组数来确定,即组距=( 最大值 - 最小值)÷ 组数3.统计出各组的频数并整理成频数分布表3.4直方图和条形图区别:1.条形图是用条形的长度(横置时)表示各类别频数的多少,其宽度(表示类别)则是固定的2.直方图是用面积表示各组频数的多少,矩形的高度表示每一组的频数或百分比,宽度则表示各组的组距,其高度与宽度均有意义3.直方图的各矩形通常是连续排列,条形图则是分开排列4.条形图主要用于展示分类数据,直方图则主要用于展示数值型数据3.5绘制线图应该注意的问题:一般情况下,纵轴数据下端应从“0”开始,以便于比较。
数据与“0”之间的间距过大时,可以采取折断的符号将纵轴折断3.6饼图和环形图的不同:饼图只能显示一个总体各部分所占的比例,环形图则可以同时绘制多个样本或总体的数据系列,每一个样本或总体的数据系列为一个环。
3.7茎叶图与直方图相比的优点与各自的应用场合:直方图可观察一组数据的分布状况,但没有给出具体的数值;茎叶图既能给出数据的分布状况,又能给出每一个原始数值,保留了原始数据的信息。
直方图适用于大批量数据,茎叶图适用于小批量数据3.8鉴别图表优劣的准则有:3.9制作统计表时应注意的问题:二、练习题3.1为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别为:A.好;B.较好;C.一般;D.较差;E.差。
统计学习题答案-贾俊平
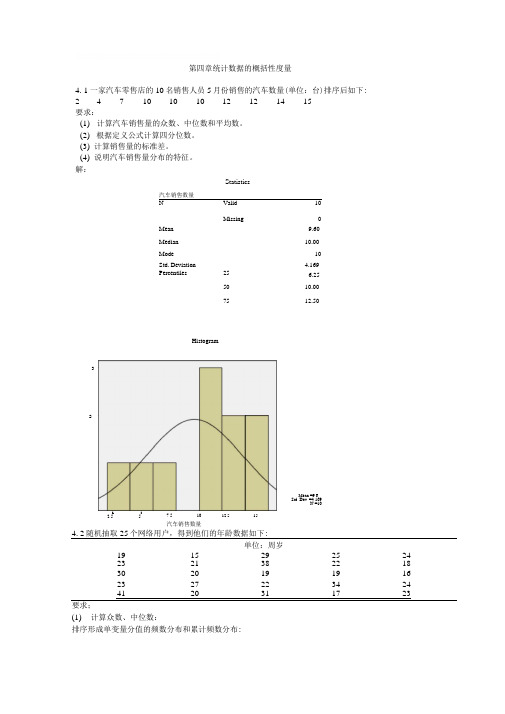
第四章统计数据的概括性度量4. 1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下: 2 4 7 10 10 10 12 12 14 15要求:(1) 计算汽车销售量的众数、中位数和平均数。
(2) 根据定义公式计算四分位数。
(3) 计算销售量的标准差。
(4) 说明汽车销售量分布的特征。
解:汽车销售数量StatisticsNValid 10Missing0 Mean9.60Median10.00Mode10Std. Deviation4.169 Percentiles25 6.255010.007512.504. 2随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 24 23 21 38 22 18 30 20 19 19 16 23 27 22 34 24 41 20 31 17 23要求;(1) 计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:LI2.557.5 10汽车销售数量12.5 15Mean =9.6Std. Dev. =4.169N =10Histogram32网络用尸的年龄FrequencyPercent Cumulative FrequencyCumulative PercentValid15 14.0 14.016 1 4.0 2 8.0 17 1 4.0 3 12.0 18 1 4.0 4 16.0 19 3 12.0 7 28.0 20 2 8.0 9 36.0 21 1 4.0 10 40.0 22 2 8.0 12 48.0 233 12.0 15 60.0 24 2 8.0 17 68.0 25 1 4.0 18 72.0 27 1 4.0 19 76.0 29 1 4.0 20 80.0 30 1 4.0 21 84.0 31 1 4.0 22 88.0 34 1 4.0 23 92.0 38 1 4.0 24 96.0 41 1 4.0 25100.0Total25100.0从频数看出,众数 Mo 有两个:19、23;从累计频数看,中位数 Me=23。
统计学课后习题第六章-贾俊平等

第六章 统计量及其抽样分布6。
1 调节一个装瓶机使其对每个瓶子的灌装量均值为μ盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差 1.0σ=盎司的正态分布。
随机抽取由这台机器灌装的9个瓶子形成一个样本,并测定每个瓶子的灌装量。
试确定样本均值偏离总体均值不超过0。
3盎司的概率。
解:总体方差知道的情况下,均值的抽样分布服从()2,N nσμ的正态分布,由正态分布,标准化得到标准正态分布:x ()0,1N ,因此,样本均值不超过总体均值的概率P 为: ()0.3P x μ-≤=P ⎫≤=x P ⎛⎫≤≤=()0.90.9P z -≤≤=2()0.9φ—1,查标准正态分布表得()0.9φ=0。
8159因此,()0.3P x μ-≤=0。
6318 6。
2 ()0.3P Y μ-≤=P ⎫≤=x P ⎛⎫≤≤=(||P z ≤=(21φ-=0.95查表得: 1.96= 因此n=436。
3 1Z ,2Z ,……,6Z 表示从标准正态总体中随机抽取的容量,n=6的一个样本,试确定常数b ,使得6210.95i i P Z b =⎛⎫≤= ⎪⎝⎭∑ 解:由于卡方分布是由标准正态分布的平方和构成的:设Z 1,Z 2,……,Z n 是来自总体N (0,1)的样本,则统计量222212χ=+++n Z Z Z 服从自由度为n 的χ2分布,记为χ2~ χ2(n)因此,令6221i i Z χ==∑,则()622216i i Z χχ==∑,那么由概率6210.95i i P Z b =⎛⎫≤= ⎪⎝⎭∑,可知: b=()210.956χ-,查概率表得:b=12.596.4 在习题6。
1中,假定装瓶机对瓶子的灌装量服从方差21σ=的标准正态分布.假定我们计划随机抽取10个瓶子组成样本,观测每个瓶子的灌装量,得到10个观测值,用这10个观测值我们可以求出样本方差22211(())1n i i S S Y Y n ==--∑,确定一个合适的范围使得有较大的概率保证S 2落入其中是有用的,试求b 1,b 2,使得212()0.90p b S b ≤≤=解:更加样本方差的抽样分布知识可知,样本统计量:222(1)~(1)n s n χσ--此处,n=10,21σ=,所以统计量22222(1)(101)9~(1)1n s s s n χσ--==- 根据卡方分布的可知:()()2212129990.90P b S b P b S b ≤≤=≤≤= 又因为:()()()222121911P n S n ααχχα--≤≤-=-因此:()()()()22221212299919110.90P b S b P n S n ααχχα-≤≤=-≤≤-=-=()()()()222212122999191P b S b P n S n ααχχ-⇒≤≤=-≤≤-()()()2220.950.059990.90P S χχ=≤≤= 则:()()2210.9520.0599,99b b χχ⇒==()()220.950.051299,99b b χχ⇒== 查概率表:()20.959χ=3。
贾俊平统计学第三章课后思考题答案

一、思考题1.数据的预处理包括哪些内容?答:数据的预处理是在对数据分类或分组之前所做的必要处理,内容包括数据的审核、筛选、排序等。
(1)数据审核就是检查数据中是否有错误。
对于通过调查取得的原始数据,主要从完整性和准确性两个方面去审核;对于通过其他渠道取得的二手数据,则应着重审核数据的适用性和时效性(2)数据筛选是根据需要找出符合特定条件的某类数据。
(3)数据排序是按一定顺序将数据排列,以便研究者通过浏览数据发现一些明显的特征或趋势,找到解决问题的线索。
除此之外,排序还有助于对数据检查纠错,以及为重新归类或分组等提供方便。
2.分类数据和顺序数据的整理和图示方法各有哪些?答:(1)分类数据的整理方法:首先列出分类数据所分的类别,然后计算出每一类别的频数、频率或比例、比率等,即可形成一张频数分布表。
图示方法:条形图、帕累托图、饼图和环形图。
(2)顺序数据的整理方法:首先按照一定的顺序将数据进行分类,然后计算出每一类别的频数、比例、百分比、比率等,对于顺序数据,除了可使用分类数据的整理和图示技术外,还可以计算累积频数和累积频率(百分比)。
图示方法:条形图、饼图、帕累托图、累积频数分布图和环形图。
3.数值型数据的分组方法有哪些?简述组距分组的步骤。
答:(1)数据分组的方法有单变量值分组和组距分组两种。
①单变量值分组是把每一个变量值作为一组,这种分组通常只适合离散变量,且变量值较少的情况下使用;②在连续变量或变量值较多的情况下,通常采用组距分组。
它是将全部变量值依次划分为若干个区间,并将这一区间的变量值作为一组。
在组距分组中,一个组的最小值称为下限;一个组的最大值称为上限。
(2)组距分组步骤①确定组数。
组数的确定应以能够显示数据的分布特征和规律为目的。
一般情况下,一组数据所分的组数不应少于5组且不多于15组,即5≤K≤15;②确定各组的组距。
组距是一个组的上限与下限的差。
组距可根据全部数据的最大值和最小值及所分的组数来确定,即组距=(最大值-最小值)÷组数;③根据分组编制频数分布表。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第3章 概率与概率分布——练习题(全免)1 .解:设A =女性,B =工程师,AB =女工程师,A+B =女性或工程师(1)P(A)=4/12=1/3(2)P(B)=4/12=1/3(3)P(AB)=2/12=1/6(4)P(A+B)=P(A)+P(B)-P(AB)=1/3+1/3-1/6=1/24. 某项飞碟射击比赛规定一个碟靶有两次命中机会(即允许在第一次脱靶后进行第二次射击)。
某射击选手第一发命中的可能性是80%,第二发命中的可能性为50%。
求该选手两发都脱靶的概率。
解:设A =第1发命中。
B =命中碟靶。
求命中概率是一个全概率的计算问题。
再利用对立事件的概率即可求得脱靶的概率。
)|()()|()()(A B P A P A B P A P B P +==0.8×1+0.2×0.5=0.9脱靶的概率=1-0.9=0.1或(解法二):P (脱靶)=P (第1次脱靶)×P(第2次脱靶)=0.2×0.5=0.18.已知某地区男子寿命超过55岁的概率为84%,超过70岁以上的概率为63%。
试求任一刚过55岁生日的男子将会活到70岁以上的概率为多少?解: 设A =活到55岁,B =活到70岁。
所求概率为:()()0.63(|)0.75()()0.84P AB P B P B A P A P A ==== 9.某企业决策人考虑是否采用一种新的生产管理流程。
据对同行的调查得知,采用新生产管理流程后产品优质率达95%的占四成,优质率维持在原来水平(即80%)的占六成。
该企业利用新的生产管理流程进行一次试验,所生产5件产品全部达到优质。
问该企业决策者会倾向于如何决策?解:这是一个计算后验概率的问题。
设A =优质率达95%,A =优质率为80%,B =试验所生产的5件全部优质。
P(A)=0.4,P (A )=0.6,P (B|A )=0.955, P(B |A )=0.85,所求概率为:6115.050612.030951.0)|()()|()()|()()|(===A B P A P A B P A P A B P A P B A P + 决策者会倾向于采用新的生产管理流程。
10. 某公司从甲、乙、丙三个企业采购了同一种产品,采购数量分别占总采购量的25%、30%和45%。
这三个企业产品的次品率分别为4%、5%、3%。
如果从这些产品中随机抽出一件,试问:(1)抽出次品的概率是多少?(2)若发现抽出的产品是次品,问该产品来自丙厂的概率是多少?解:令A 1、A 2、A 3分别代表从甲、乙、丙企业采购产品,B 表示次品。
由题意得:P (A 1)=0.25,P (A 2)=0.30, P (A 3)=0.45;P (B |A 1)=0.04,P (B |A 2)=0.05,P (B |A 3)=0.03;因此,所求概率分别为:(1))|()()|()()|()()(332211A B P A P A B P A P A B P A P B P ++==0.25×0.04+0.30×0.05+0.45×0.03=0.0385(2)3506.00385.00135.00.030.450.050.300.040.2503.045.0)|(3==++=⨯⨯⨯⨯B A P 8.某人在每天上班途中要经过3个设有红绿灯的十字路口。
设每个路口遇到红灯的事件是相互独立的,且红灯持续24秒而绿灯持续36秒。
试求他途中遇到红灯的次数的概率分布及其期望值和方差、标准差。
解:据题意,在每个路口遇到红灯的概率是p =24/(24+36)=0.4。
设途中遇到红灯的次数=X ,因此,X ~B(3,0.4)。
其概率分布如下表:9. 一家人寿保险公司某险种的投保人数有20000人,据测算被保险人一年中的死亡率为万分之5。
保险费每人50元。
若一年中死亡,则保险公司赔付保险金额50000元。
试求未来一年该保险公司将在该项保险中(这里不考虑保险公司的其它费用):(1)至少获利50万元的概率;(2)亏本的概率;(3)支付保险金额的均值和标准差。
解:设被保险人死亡数=X ,X ~B (20000,0.0005)。
(1)收入=20000×50(元)=100万元。
要获利至少50万元,则赔付保险金额应该不超过50万元,等价于被保险人死亡数不超过10人。
所求概率为:P(X ≤10)=0.58304。
(2)当被保险人死亡数超过20人时,保险公司就要亏本。
所求概率为:P(X >20)=1-P(X ≤20)=1-0.99842=0.00158(3)支付保险金额的均值=50000×E (X )=50000×20000×0.0005(元)=50(万元)支付保险金额的标准差=50000×σ(X )=50000×(20000×0.0005×0.9995)1/2=158074(元)10.对上述练习题3.09的资料,试问:(1)可否利用泊松分布来近似计算?(2)可否利用正态分布来近似计算?(3)假如投保人只有5000人,可利用哪种分布来近似计算?解: (1)可以。
当n 很大而p 很小时,二项分布可以利用泊松分布来近似计算。
本例中,λ= np =20000×0.0005=10,即有X ~P (10)。
计算结果与二项分布所得结果几乎完全一致。
(2)也可以。
尽管p 很小,但由于n 非常大,np 和np(1-p)都大于5,二项分布也可以利用正态分布来近似计算。
本例中,np=20000×0.0005=10,np(1-p)=20000×0.0005×(1-0.0005)=9.995,即有X ~N (10,9.995)。
相应的概率为:P (X ≤10.5)=0.51995,P(X ≤20.5)=0.853262。
可见误差比较大(这是由于P 太小,二项分布偏斜太严重)。
【注】由于二项分布是离散型分布,而正态分布是连续性分布,所以,用正态分布来近似计算二项分布的概率时,通常在二项分布的变量值基础上加减0.5作为正态分布对应的区间点,这就是所谓的“连续性校正”。
(3)由于p =0.0005,假如n =5000,则np =2.5<5,二项分布呈明显的偏态,用正态分布来计算就会出现非常大的误差。
此时宜用泊松分布去近似。
16.某企业生产的某种电池寿命近似服从正态分布,且均值为200小时,标准差为30小时。
若规定寿命低于150小时为不合格品。
试求该企业生产的电池的:(1)合格率是多少?(2)电池寿命在200左右多大的范围内的概率不小于0.9。
解:(1))6667.1()30200150()150(-<-<=<Z P Z P X P ==0.04779合格率为1-0.04779=0.95221或95.221%。
(2) 设所求值为K ,满足电池寿命在200±K 小时范围内的概率不小于0.9,即有:|200|(|200|){||}0.93030X KP X K P Z --<=<≥= 即:{}0.9530KP Z <≥,K /30≥1.64485,故K ≥49.3456。
第5章 参数估计●1. 从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。
(1) 样本均值的抽样标准差x σ等于多少?(2) 在95%的置信水平下,允许误差是多少?解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25,(1)样本均值的抽样标准差x σσ5=0.7906(2)已知置信水平1-α=95%,得 α/2Z =1.96,于是,允许误差是E =α/2σZ 6×0.7906=1.5496。
2.解:(1)已假定总体标准差为σ=15元,则样本均值的抽样标准误差为x σσ15=2.1429(2)已知置信水平1-α=95%,得 α/2Z =1.96,于是,允许误差是E =α/2σZ 6×2.1429=4.2000。
(3)已知样本均值为x =120元,置信水平1-α=95%,得 α/2Z =1.96,这时总体均值的置信区间为±α/2σx Z 0±4.2=124.2115.8 可知,如果样本均值为120元,总体均值95%的置信区间为(115.8,124.2)元。
3.解:⑴计算样本均值x :将上表数据复制到Excel 表中,并整理成一列,点击最后数据下面空格,选择自动求平均值,回车,得到x =3.316667,⑵计算样本方差s :删除Excel 表中的平均值,点击自动求值→其它函数→STDEV →选定计算数据列→确定→确定,得到s=1.6093也可以利用Excel 进行列表计算:选定整理成一列的第一行数据的邻列的单元格,输入“=(a7-3.316667)^2”,回车,即得到各数据的离差平方,在最下行求总和,得到:∑2i(x -x )=90.65 再对总和除以n-1=35后,求平方根,即为样本方差的值。
⑶计算样本均值的抽样标准误差:已知样本容量 n =36,为大样本,得样本均值的抽样标准误差为 x σ=0.2682 ⑷分别按三个置信水平计算总体均值的置信区间:① 置信水平为90%时:由双侧正态分布的置信水平1-α=90%,通过2β-1=0.9换算为单侧正态分布的置信水平β=0.95,查单侧正态分布表得 α/2Z =1.64,计算得此时总体均值的置信区间为±α/2s x Z 7±1.64×0.2682= 3.75652.8769 可知,当置信水平为90%时,该校大学生平均上网时间的置信区间为(2.87,3.76)小时;② 置信水平为95%时:由双侧正态分布的置信水平1-α=95%,得 α/2Z =1.96,计算得此时总体均值的置信区间为±α/2s x Z 7±1.96×0.2682= 3.84232.7910 可知,当置信水平为95%时,该校大学生平均上网时间的置信区间为(2.79,3.84)小时;③ 置信水平为99%时:若双侧正态分布的置信水平1-α=99%,通过2β-1=0.99换算为单侧正态分布的置信水平β=0.995,查单侧正态分布表得 α/2Z =2.58,计算得此时总体均值的置信区间为±α/2s x Z 7±2.58×0.2682= 4.00872.6247 可知,当置信水平为99%时,该校大学生平均上网时间的置信区间为(2.62,4.01)小时。
4. 解:(7.1,12.9)。
5解:(7.18,11.57)。