人民大学统计学在职题库统计综述答案
统计学课后题答案第四版中国人民大学出版社
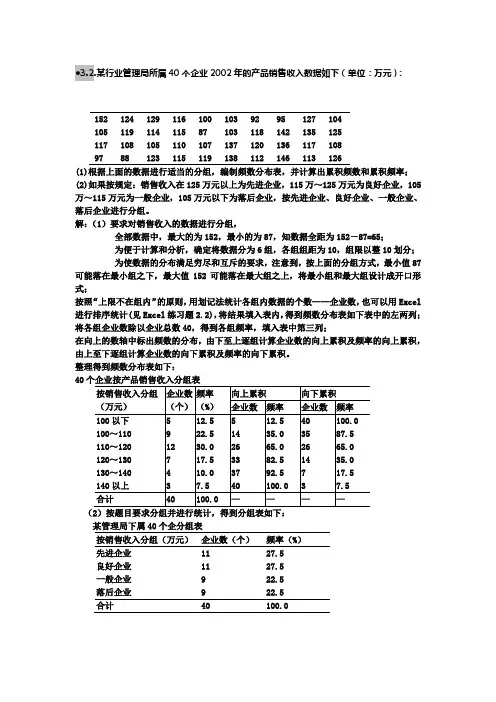
●3.2.某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):1521241291161001039295127104105119114115871031181421351251171081051101071371201361171089788123115119138112146113126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
解:(1)要求对销售收入的数据进行分组,全部数据中,最大的为152,最小的为87,知数据全距为152-87=65;为便于计算和分析,确定将数据分为6组,各组组距为10,组限以整10划分;为使数据的分布满足穷尽和互斥的要求,注意到,按上面的分组方式,最小值87可能落在最小组之下,最大值152可能落在最大组之上,将最小组和最大组设计成开口形式;按照“上限不在组内”的原则,用划记法统计各组内数据的个数——企业数,也可以用Excel 进行排序统计(见Excel练习题2.2),将结果填入表内,得到频数分布表如下表中的左两列;将各组企业数除以企业总数40,得到各组频率,填入表中第三列;在向上的数轴中标出频数的分布,由下至上逐组计算企业数的向上累积及频率的向上累积,由上至下逐组计算企业数的向下累积及频率的向下累积。
整理得到频数分布表如下:40个企业按产品销售收入分组表(2)按题目要求分组并进行统计,得到分组表如下:某管理局下属40个企分组表按销售收入分组(万元)企业数(个)频率(%)先进企业良好企业一般企业落后企业11119927.527.522.522.5合计40100.0●7.1. 从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。
人民大学统计学在职题库统计综述答案

1中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:1(取值均在、季节项更新、未来第期的预测值期的季节调整因子,,其中2中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:2=142.3中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:3)样本均值服从正态分布。
通过中心极限定理:设从均值为、方差30= 264中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:4此处5中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:56中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:67中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:78中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:8 (1)你认为该用什么样的统计量来反映投资的风险?9国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:910中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:10以看出,出口额随着时间的增长,成曲线增长趋势。
、如下图所示,用指数方程t 3994.0e 0202.8ˆ=tY 拟合出口额的增长趋势,拟合的R 值高达0.9896。
11中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:1112中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:12。
统计工作题库及答案详解

统计工作题库及答案详解统计工作是一项涉及数据收集、分析和解释的专业活动,广泛应用于经济、社会、科学研究等多个领域。
为了帮助统计学的学生和专业人士更好地掌握统计知识,以下是一些统计工作题库及答案详解。
1. 题目一:描述统计数据的类型。
答案详解:统计数据主要分为定性数据和定量数据。
定性数据反映的是事物的属性,如性别、种族等,通常用于分类。
定量数据则反映事物的数量特征,如年龄、收入等,可以进行数值运算。
2. 题目二:解释什么是中心趋势度量。
答案详解:中心趋势度量是用来描述数据集中趋势的统计量,常见的中心趋势度量包括均值、中位数和众数。
均值是所有数据值的总和除以数据的个数;中位数是将数据从小到大排序后位于中间位置的数值;众数是数据中出现次数最多的数值。
3. 题目三:什么是标准差,它在数据分析中的作用是什么?答案详解:标准差是衡量数据分布离散程度的一个统计量,它表示数据值与均值的平均偏差。
标准差越大,数据的离散程度越高;标准差越小,数据越集中。
在数据分析中,标准差常用于评估数据的稳定性和一致性。
4. 题目四:描述相关系数的概念及其类型。
答案详解:相关系数是衡量两个变量之间线性关系强度和方向的统计量。
常见的相关系数包括皮尔逊相关系数、斯皮尔曼等级相关系数和肯德尔等级相关系数。
皮尔逊相关系数适用于测量两个连续变量之间的线性关系;斯皮尔曼和肯德尔等级相关系数则适用于测量两个有序变量之间的相关性。
5. 题目五:解释什么是假设检验,以及它的基本步骤。
答案详解:假设检验是一种统计方法,用于基于样本数据对总体参数进行推断。
基本步骤包括:(1) 提出原假设和备择假设;(2) 选择适当的检验统计量和显著性水平;(3) 计算检验统计量的值;(4)根据检验统计量的值和显著性水平做出决策,接受或拒绝原假设。
6. 题目六:什么是回归分析,它在实际应用中的作用是什么?答案详解:回归分析是一种统计方法,用于研究一个或多个自变量与因变量之间的关系。
中国人民大学题库答案详解-高等统计

一、多项选择题1. 有关样本的分布,以下陈述正确的是:ABCA. 如果样本X1,…,X n独立同分布来自Gamma分布,= 在大样本下有近似的正态分布;(中心极限定理)B.如果样本X1,…,X n独立同分布来自N(µ,σ2),= 在大样本情况下有精确分布N(µ,σ2/n);(原分布为正态分布)C.如果样本X1,…,X n独立同分布来自N(µ,σ2),即使样本量不大,= 也服从正态分布;(原分布为正态分布)D.如果样本X1,…,X n来自任意分布,在大样本情况下,由X1,…,X n组成的数据有近似的正态分布;(不符合中心极限定理(样本均值))2.有关检验的p值,下面说法正确的是:BCA. 一般为[0,0.1]之间的一个很小的概率;(P值一般[0,1])B. 接受备择假设的最小显著性水平;C. 如果p值小于显著性水平,则拒绝零假设;D. 样本统计量的分布函数。
(P值是概率值不是分布)3. 请问以下哪些方法可以用来判断数据可能背离正态分布:BA. Q-Q图上,如果数据和基线之间几乎吻合;(要利用QQ图鉴别样本数据是否近似于正态分布,只需要看QQ图上的点是否近似的在一条直线附近,而且,该直线的斜率为标准差,截距为均值。
)B. Kolmogrov-Smirnov正态检验中的统计量所对应的p值小于0.05;(P值小于0.05拒绝原假设,即正态分布不成立)C.对数据直方图做光滑后没有发现数据有很大的发散趋势;(通过形状是否为正态钟形来判断)D.χ2拟合优度检验,统计量的值偏小。
(卡方统计量偏小则不拒绝原假设(H0:分布为正态))4.若抽样误差为5,总体标准差为40,如果样本量足够大,正态分布的0.975分位数近似为2,要估计总体均值的95%的置信区间所需要的样本量大概为:B A 156 B 256 C 356 D 456.(n= = 4*1600/25 = 256)5.关于假设检验,给定一组独立同分布的随机样本,给定显著性水平,如下理解正确的是:DA.单边检验拒绝,双边检验一定拒绝;B.双边检验接受,一定有一个单边检验是拒绝的;C.单边检验拒绝,双边检验一定拒绝。
统计学考试题及答案(中国人民大学第六版)

统计学一、单选1、从某高校随机抽出100名学生,调查他们每月的生活费支出,这研究的统计量是A 该校学生的总人数B 该校学生的月月平均生活费支出C 该校学生的生活费总支出D 100名学生的月平均生活费支出2、下列变量中,顺序变量是A职工人数 B产量 C产品等级 D利润总额3、将总体中所有单位按某种变量划分为若干层,再从各层中随机抽出一些单位组成一个样本。
这种抽样方式是A 简单随机抽样B 分层抽样C 整群抽样D 系统抽样4、指出下面陈述中错误的是A 抽样误差只存在于概率抽样中B 非抽样误差只存在于非概率抽样中。
C概率抽样和非概率抽样都存在非抽样误差。
D在普查中存在非抽样误差。
5、展示广告费支出与商品销售量之间是否有某种数量关系,最适合的图形是 A柱形图 B饼图 C线图 D散点图6、当样本量一定时,置信区间的宽度A 随置信水平的增大而减小B随置信水平的增大而增大C与置信水平的大小无关D与置信水平的平方根成反比7、在检验一个正态总体方差时,使用的分布是A z分布B t分布C X 分布D F分布8、指出下面陈述中的错误的是A 抽样误差可以避免B 抽样误差不可避免C 非抽样误差可以避免D 抽样误差可以控制9、假设检验中,如果计算出的P值越小,说明检验的结果越A 真实B 不真实C 显著D 不真实10、双因素方差分析涉及 自变量A 一个分类型B 一个数值型C 两个分类型D 两个数值型二、填空题1、当一组数据对称分布时,经验法则表明,大约有68%的数据分析在( 平均数±一个标准差 )的范围之内2、对于一组具有单峰分布的数据而言,当数据的m m >时,可判断数据是(左偏)分布3、连续变量在编制组距式变量数列时,其相邻两组的上下限必须重叠。
为解决不重的问题,应按照( 上组限不在内 )的规定确定数据所在的组4、单因素方差分析中,组间平方和SSA 对应的自由度为( k-1 ),组内平方和SSE 对应的自由度( n-k )5、数值型变量根据其取值的不同,可分为( 连续 )型变量和(离散 )型变量。
统计学课后习题答案(全)
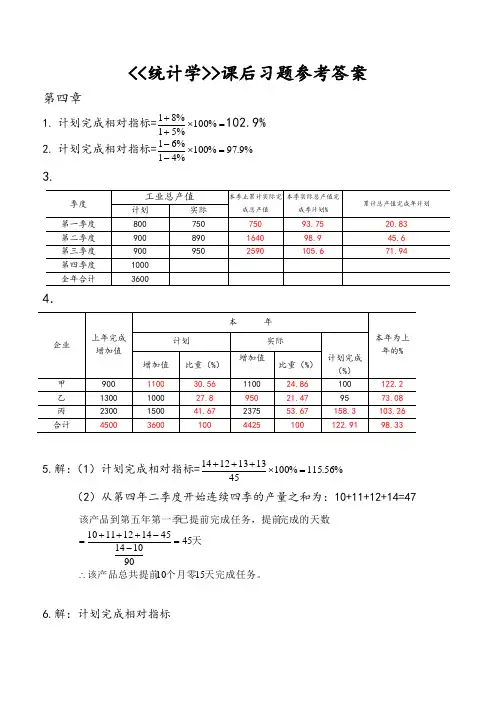
<<统计学>>课后习题参考答案第四章1. 计划完成相对指标==⨯++%100%51%81102.9% 2. 计划完成相对指标=%9.97%100%41%61=⨯-- 3.4.5.解:(1)计划完成相对指标=%56.115%1004513131214=⨯+++(2)从第四年二季度开始连续四季的产量之和为:10+11+12+14=47天完成任务。
个月零该产品总共提前天完成的天数已提前完成任务,提前该产品到第五年第一季1510459010144514121110∴=--+++=6.解:计划完成相对指标=%75.126%100%1.0102005354703252795402301564=⨯⨯⨯++++++(2)156+230+540+279+325+470=2000(万吨) 所以正好提前半年完成计划。
7.8.略第五章 平均指标与标志变异指标1.甲X =.309343332313029282726=++++++++乙X =44.319403836343230282520=++++++++ AD 甲=}22.29303430333032303130303029302830273026=-+-+-+-+-+-+-+-+-AD 乙=}06.594044.313844.313644.313444.313244.313044.312844.312544.3120=-+-+-+-+-+-+-+-+-R 甲=34-26=8 R 乙=40-20=20σ甲 =9)3334()3033()3032()3031()3030()3029()3028()3027()3026(222222222-+-+-+-+-+-+-+-+-=2.58 σ乙=9)44.3140()44.3138()44.3136()44.3134()44.3132()44.3130()44.3128()44.3125()44.3120(222222222-+-+-+-+-+-+-+-+-=6.06V 甲=1003058.2⨯%=8.6% V 乙=%3.19%10044.3106.6=⨯ 所以甲组的平均产量代表性大一些. 2.解:计算过程如下表:甲X =.)(5.101780元= 乙X =(元)9708077600= 3.解:计算过程如下表:甲X =.4.11980=(件) 乙X =8.120809660=(件) σ甲=06.98075.6568=(件) σ乙=81.10809355=(件) V 甲=1004.11906.9⨯%=7.58% V 乙=%94.8%1008.12081.10=⨯ 所以甲厂工人的平均产量的代表性要高些.4. 解:()()94.761018102457047.7610121871871870775121873595128518757653550=⨯-+==⨯-+--+==++++⨯+⨯+⨯+⨯+⨯=e M M X 5.解:(1)上期的平均计划完成程度为:()()第六章元解解度为下期的平均计划完成程tH V P X P P P P /3.2884102950943.5062900255.3212800604.43210943.506255.321604.432:.7%1.32%1009067.0291.0291.0%67.901%67.90%67.90%67.90%10030028300:.6%37.103%1031400%1011200%107810%110961400120081096:)2(%67.99%1001500100070080%951500%1001000%108700%1108044=⨯⎪⎭⎫ ⎝⎛++⨯++==⨯==-⨯====⨯-==++++++=⨯+++⨯+⨯+⨯+⨯σ1.()())(7.788%67.41500:2000%67.41500600:.6)(6.62126907106557306806702650600269071061527106556552655730620273068060026806706402670650:2)(7.62327107006907206806202680610271070062527006906452690720640272068062026806206002620680:)1(:.5%63.79%10026206005802580257646245002435:.4%85.105%100%113385%102350%97463%120485%105412%112410%98368%106350%105310%110324%102306%101303385350463485412410368350310324306303::.3872232122221030980329809002290010201210208402284067022670600.2104万吨年该县粮食产量为平均增长速度解元工人的月平均工资为乙工区上半年建筑安装元工人的月平均工资为甲工区上半年建筑安装解解度为全年月平均计划完成程解=+⨯=-==++++++⨯++⨯++⨯++⨯++⨯++⨯+=++++++⨯++⨯++⨯++⨯++⨯++⨯+=⨯++++++==⨯++++++++++++++++++++++=+++++⨯++⨯++⨯++⨯++⨯++⨯+=C a 7解:计算过程如下表:)(94.6653.444.45:1994:3.46025844.4594092万元年的地方财政支出额为则直线趋势方程为=⨯++=======∑∑∑bta y t tyb ny a二次曲线方程为:y = 0.0108x 2 + 4.1918x + 24.143(过程略) 指数曲线方程为:y = 26.996e 0.0978x8.解:计算过程如下表:9.解:(1)同季平均法求季节比率的过程如下表:(2)趋势剔除法测定的季节变动如下表:第七章 统计指数()()()()01001011111175000124000081138.44%5000012350008750002540000182138.03%500002535000181075000940000390.98%127500084000022750002540000425qqzpk q z q zq p q p q z kq z p q k p q⨯+⨯===⨯+⨯⨯+⨯===⨯+⨯⨯+⨯===⨯+⨯⨯+⨯==∑∑∑∑∑∑∑∑111111110102.12%75000184000015602.108.8%1200360110%105%pp q p q k p q p q p p=⨯+⨯====+∑∑∑∑11111560.135.65%1150135.65%124.68%108.8%.120%1800115%90096%6003.114.27%330042003300111.38%114.27%.pqpq qpqpq p qp q k p qk k k q q p q p q k q p q pkk k======⨯+⨯+⨯=======∑∑∑∑∑∑ 110101001013200005.100%128%250000128%123.1%14%320000307692.3104%307692.325000057692.3320000307692.312307.pq pqq PpK K K p qp q K p q p qq p q =⨯====+===-=-=-=-=∑∑∑∑∑∑1解:K 零售量变动对零售额变动影响的绝对值为:(万元)零售物价变动对零售总额变动影响的绝对值为:p 1110010000107350000120%120%180000110%110%116%116%17.6%107.6%350000291666.67120%180000163636.36.110%1pq pq q q pq pq q q K q K q p q Kq p q K p q p q ==+===+==+==+========⨯=∑∑∑∑∑∑∑∑城1城农城农1农1城城城1农农农城城城(万元)6.解:已知p ,,p ,,K ,K p 则p K 0010111101001116%291666.67338333.33107.6%163636.36176072.72350000180000103.03%338333.33176072.723%q pp q p q p q q q k p q p q p q ⨯==⨯=⨯=++====++∴∑∑∑∑∑∑∑∑农农农11城农城农K p p 该地区城乡价格上涨了。
统计学课后习题及答案
统计学课后习题及答案统计学课后习题及答案统计学是一门研究数据收集、分析和解释的学科,它在各个领域都有广泛的应用。
作为学习统计学的学生,课后习题是巩固知识、提高技能的重要途径。
本文将提供一些统计学课后习题及其答案,希望对学习者有所帮助。
1. 描述性统计习题:给定以下一组数据:10, 15, 12, 18, 20, 22, 16, 10, 14, 19。
请计算该组数据的均值、中位数和众数,并解释它们的含义。
答案:均值:计算方法是将所有数据相加,然后除以数据的个数。
对于给定的数据,均值为(10+15+12+18+20+22+16+10+14+19)/10 = 16.6。
中位数:将数据按照从小到大的顺序排列,找出中间的数。
对于给定的数据,中位数为16。
众数:出现频率最高的数。
对于给定的数据,众数为10。
这些统计量可以帮助我们了解数据的集中趋势。
均值是所有数据的平均值,中位数是数据的中间值,众数是出现频率最高的值。
在这个例子中,均值告诉我们这组数据的平均水平是16.6,中位数告诉我们大约一半的数据小于16,一半的数据大于16,众数告诉我们10是这组数据中出现次数最多的数。
2. 概率习题:一个骰子有6个面,每个面上的数字分别是1、2、3、4、5、6。
如果投掷一次骰子,求得到奇数的概率。
答案:奇数的个数为3个,即1、3、5。
骰子的总个数为6个。
所以得到奇数的概率为3/6 = 1/2。
概率是事件发生的可能性。
在这个例子中,奇数的个数是3个,总个数是6个,所以得到奇数的概率是3/6,即1/2。
3. 抽样与估计习题:某市有1000名居民,你希望了解他们对某项政策的态度。
你打算进行一次调查,抽取100名居民进行问卷调查。
这个调查结果能否代表整个市民的态度?为什么?答案:这个调查结果不能代表整个市民的态度。
原因是抽样的方式可能引入抽样误差。
如果抽取的100名居民在某些特征上不具有代表性,比如年龄、性别、职业等,那么调查结果可能会偏离整个市民的态度。
人民大学统计学在职题库统计综述答案
1中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:12中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:23中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:34中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:45中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:56中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:67中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:78中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:89国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:910中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:10五、(20分)下表是某贸易公司近几年的出口额数据:年份出口额(万美元) 200213 200319 200424 20053500658 200788 2008 145(1) 从图形上判断,出口额时间序列含有什么成分?(2) 要预测该公司的出口额,应采用哪种趋势线?该趋势线的特点是什么?(3) 根据上面的数据拟合的指数曲线方程为:t tY )4904.01(02.8ˆ+⨯=,这里的0.4909的具体含义是什么?解:(1)、,由图可以看出,出口额随着时间的增长,成曲线增长趋势。
人民大学统计学在职题库统计综述答案
1中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:1(取值均在、季节项更新、未来第期的预测值2中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:2=142.03中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:3)样本均值服从正态分布。
通过中心极限定理:设从均值为、方差30= 264中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:4此处5中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:56中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:67中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:78中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:8 (1)你认为该用什么样的统计量来反映投资的风险?9国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:910中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:10以看出,出口额随着时间的增长,成曲线增长趋势。
、如下图所示,用指数方程t 3994.0e 0202.8ˆ=tY 拟合出口额的增长趋势,拟合的R 值高达0.9896。
11中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:1112中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:12。
保研人大统计真题答案解析
保研人大统计真题答案解析近年来,随着社会教育的普及,越来越多的学生选择考研究生进一步深造。
而保研成为了一种备选方案,尤其对于在本科阶段成绩优异的学生来说。
然而,保研过程中所需要应对的各种考试,包括人大统计专业的真题答案,依然是保研考生们头疼的问题。
下面,本文将对人大统计专业的真题答案进行解析,为广大考生提供一些参考。
首先,我们先来了解一下人大统计专业的考试形式。
人大统计考试通常由两部分组成:统计学基础知识测试和综合素质面试。
统计学基础知识测试占据了整个考试的主体部分,包括概率论、数理统计等相关知识点。
针对这部分的考试内容,我们可以通过分析往年真题来获取一些解题技巧。
第一题:如何判断一个数据集是否具有正态分布?这是一个经典的考点,也是统计学的基础知识。
一种常见的方法是使用正态概率图进行判断。
如果数据点在图中近似地呈直线分布,则说明数据集具有正态分布。
此外,还可以利用统计学中的假设检验方法,如Shapiro-Wilk测试等。
第二题:给定一个随机变量X的概率密度函数,如何计算其期望值?在这类问题中,我们需要计算随机变量X的期望值,即E(X)。
根据概率论的定义,期望值可以通过对随机变量X乘以其对应的概率,并将所有结果相加得到。
如果是连续型随机变量,则需对其概率密度函数积分,并取积分结果作为期望值。
第三题:如何利用ANOVA分析比较多个样本的均值是否显著不同?这是一个涉及到实际应用的问题。
首先,我们需要将数据按照不同的样本类别进行分组。
然后,计算每个样本的均值,以及整体样本的均值。
接下来,通过计算差异平方和和均方差,得到F值。
最后,利用F分布的临界值进行假设检验,判断均值是否显著不同。
以上是人大统计基础知识测试中的一些典型题目,掌握了这些解题技巧,对于考生们来说是非常有帮助的。
然而,在保研过程中,光凭借这些基础知识可能还不足以顺利通过考试,因为综合素质面试同样重要。
下面,我们来看一下如何提升综合素质面试的表现。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:1除不能导致SSE显著减小为止。
逐步回归:结合向前选择和向后剔除,从没有自变量开始,不停向模型中增加自变量,每增加一个自变量就对所有现有的自变量进行考察,若某个自变量对模型的贡献变得不显著就剔除。
如此反复,直到增加变量不能导致SSE显著减少为止。
五、(20分)如果一个时间序列包含趋势、季节成分、随机波动,适用的预测方法有哪些?对这些方法做检验说明。
可以使用Winter指数平滑模型、引入季节哑变量的多元回归和分解法等进行预测。
(1)Winter指数平滑模型包含三个平滑参数,即(取值均在0~1),以及平滑值、趋势项更新、季节项更新、未来第k期的预测值。
L为季节周期的长度,对于季度数据,L=4,对于月份数据,L=12;I为季节调节因子。
平滑值消除季节变动,趋势项更新是对趋势值得修正,季节项更新是t期的季节调整因子,是用于预测的模型。
使用Winter 模型进行预测,要求数据至少是按季度或月份收集的,而且需要有四个以上的季节周期(4年以上的数据)。
使用Winter 模型进行预测,要求数据至少是按季度或月份收集的,而且需要有四个以上的季节周期(4年以上的数据)。
(2)引入季节哑变量的多元回归对于以季度记录的数据,引入3个哑变量,其中=1(第1季度)或0(其他季度),以此类推,则季节性多元回归模型表示为:其中b0是常数项,b1是趋势成分的系数,表示趋势给时间序列带来的影响,b2、b3、b4表示每一季度与参照的第1季度的平均差值。
(3)分解预测第1步,确定并分离季节成分。
计算季节指数,然后将季节成分从时间序列中分离出去,即用每一个时间序列观测值除以相应的季节指数以消除季节性。
第2步,建立预测模型并进行预测。
对消除了季节成分的时间序列建立适当的预测模型,并根据这一模型进行预测。
第3步,计算出最后的预测值。
用预测值乘以相应的季节指数,得到最终的预测值。
2中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:2组间2*210=420I-1=22100.245946组内383630-3=27=142.07——总计420+3836=425629———(2)从P值来看,组装方法与组装产品数量之间的关系强度较弱。
(3)原假设:三种方法每小时组装的产品数量没有差异若显著性水平为0.05,则P>0.05,因此不能拒绝原假设,即不能证明三种方法组装的产品数量之间有显著差异。
五、(20分)简要说明分解预测的基本步骤。
第1步,确定并分离季节成分。
计算季节指数,然后将季节成分从时间序列中分离出去,即用每一个时间序列观测值除以相应的季节指数以消除季节性。
第2步,建立预测模型并进行预测。
对消除了季节成分的时间序列建立适当的预测模型,并根据这一模型进行预测。
第3步,计算出最后的预测值。
用预测值乘以相应的季节指数,3中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:3一、(20分)在2008年8月10日举行的第29届北京奥运会女子10米气手枪决赛中,进入决赛的8名运动员的预赛成绩和最后10枪的决赛成绩如下表:要对各名运动员进行综合评价,使用的统计量有哪些?简要说明这些统计量的用途。
(1)集中趋势:指一组数据向某一中心值靠拢的程度,它可以反映选手射击成绩中心点的位置平均数:一组数据相加后除以数据的个数得到的结果。
若各组数据在组内是平均分布的,则计算的结果还是比较准确的,否则误差会比较大。
(如中国选手发挥很稳定,适合使用平均数判断其成绩)中位数:一组数据排序后处于中间位置上的变量值,但不受极端值的影响。
(如波兰选手大多数成绩比较平均,但有一枪打到8.1,会严重影响其平均值,但不会影响中位数)(2)离散程度:各变量值远离其中心值的程度,它可以反映选手能说“接受原假设”,因为没有足够的证据拒绝原假设并不等于你已经证明了原假设时真的,它仅仅意味着目前我们还没有足够的证据证明原假设,只表示目前的样本提供的证据还不足以拒绝原假设。
(3)假设检验通常是先确定显著性水平α,这等于控制了第Ⅰ类错误的概率;但犯第Ⅱ类错误的概率β却是不确定的。
在拒绝H0时,犯第Ⅰ类错误的概率不超过给定的显著性水平α;当样本结果显示没有充分理由拒绝原假设时,也难以确定第Ⅱ类错误发生的概率。
因此,在假设检验中采用“不拒绝H0”而不采用“接受H0”的表述方法,这样在多数场合下便避免了第Ⅱ类错误发生的风险。
三、 (20分)为估计公共汽车从起点到终点平均行驶的时间,一家公交公司随机抽取36班公共汽车,得到平均行驶的时间为26分钟,标准差为8分钟。
(1) 说明样本均值服从什么分布?依据是什么?(2) 计算平均行驶时间95%的置信区间。
(3) 解释95%的置信水平的含义。
(645.105.0=z ,96.1025.0=z ,860.105.0=t ,306.2025.0=t )(1)样本均值服从正态分布。
通过中心极限定理:设从均值为,方差为(有限)的任意一个总体中抽取样本量为n 的样本,当n 充分大时,样本均值的抽样分布近似服从均值、方差的正态分布。
一般统计学中的n 30为大样本,本题中抽取了36个样本,因此样本均值服从正态分布。
(2)已知n=36,=26,s=8,置信区间95%所以==1.96平均行驶时间95%的置信区间为: = 26 1.96 x = 26 2.61 即(23.39,28.61)(3)一般地,如果将构造置信区间的步骤重复多次,置信区间中包含总体参数真值的次数所占的比例称为置信水平。
如果用某种方法构造的所有区间中有95%的区间包含总体参数的真值,5%的区间不包含总体参数的真值,那么用该方法构造的区间称为置信水平为95%的置信区间。
四、 (20分)设单因素方差分析的数学模型为:ij i ij y εαμ++=。
解释这一模型的含义,并说明对这一模型的基本假定。
单因素方差分析指的是只有一种处理因素在影响结果,或者说只有一个自变量在影响因变量的情况。
(1)设任何一次实验结果都可以表示成如下形式:Yi=μ+εi其中Yi 是第i 次实验的实际结果,μ是该结果的最佳估计值,其实就是总体均值,εi 是均值和实际结果的偏差也就是随机误差(2)假定εi 服从均值为0,标准差为某个定值的正态分布,把以上形式按照方差分析进行推广,假设我们要研究几种水平之间的差异,每种水平抽取一定样本并收集相关数据,那么模型公式可以表示为:Yij=μi+εij其中Yij 是第i 组水平的第j 个样本的实际结果,μi 是第i 组的均值,εij 是第i 组第j 个样本相对于实际结果的偏差。
同样假定εi 服从4中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:4df SS MS F Sig.回归 3 87803505.46 29267835.15 46.70 3.879E-08残差 16 10028174.54 626760.91总计1997831680Coefficients 标准误差 t Stat P-value Intercept 148.7005 574.42130.2589 0.799 X Variable 1 0.8147 0.512 1.5913 0.1311 X Variable 2 0.821 0.2112 3.8876 0.0013 X Variable 30.1350.06592.05030.0571对所建立的回归模型进行综合评价。
(1)线性回归方程为其中第 (1,2,3)i i =个回归系数ˆiβ的意义是,在其它自变量保持不变时,i x 每变动一个单位,y 就平均变动ˆi β个单位。
例如在房产的评估价值和使用面积都不变的情况下,地产的评估价值每上升1万元,房地产销售价格就上升8147元。
(2)设α=0.05,由p值=3.879*<α知,回归方程的线性关系是显著的。
(3)第1,2,3个回归系数显著性检验p值分别是0.1311>α,0.0013<α,0.0571>α故第2个回归系数显著,第1、3个回归系数不显著。
(4)多重判定系数它反映了因变量变异中能用自变量解释的比例,描述了回归直线拟合样本观测值的优劣程度。
此处,表明回归拟合效果很好。
(5)估计标准误差s是y的标准差的估计,反映了y(房地产销售价格)的波y动程度。
(6)有用。
虽然该变量的部分系数没通过显著性检验,但并不意味着该变量没用,它在经济解释上可能还是有一定意义的,方程总体显著,说明方程包含该变量总体上是有用的。
也可能是多重共线性造成了不显著。
5中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:56中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:67中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:7同一总体参数的两个无偏估计量,有更小方差的估计量更有效。
<3>一致性。
一致性是指随着样本量的增大,点估计量的值越接近总体参数。
一个大样本给出的估计量要比一个小样本给出的估计量更接近总体的参数。
样本均值的标准误差σx=σ/n与样本量的大小有关,样本量越大,σx的值就越小。
因此,大样本量给出的估计量更接近总体均值u,从这个意义上来说,样本均值是总体均值的一个一致估计量。
三、(20分)一家房地产开发公司准备购进一批灯泡,公司打算在两个供货商之间选择一家购买,两家供货商生产的灯泡使用寿命的方差大小基本相同,价格也很相近,房地产公司购进灯泡时考虑的主要因素就是使用寿命。
其中一家供货商声称其生产的灯泡平均使用寿命在1500小时以上。
如果在1500小时以上,在房地产公司就考虑购买。
由36只灯泡组成的随机样本表明,平均使用寿命为1510小时,标准差为193小时。
(1)如果是房地产开发公司进行检验,会提出怎样的假设?请说明理由。
(2)如果是灯泡供应商进行检验,会提出怎样的假设,请说明理由。
(1)设灯泡的平均使用寿命为uH0:u≥1500(使用寿命符合标准) H1:u<1500(使用寿命不符合标准)房地产开发公司倾向于证明灯泡的使用寿命小于1500个小时。
因为这会损害公司的利益(如果房地产公司非常相信灯泡的使用寿8中国人民大学接受同等学历人员申请硕士学位考试试题招生专业:统计学考试科目:统计思想综述课程代码:123201 考题卷号:8一、(20分)在金融证券领域,一项投资的的预期收益率的变化通常用该项投资的风险来衡量。