西交大模式识别实验报告
模式识别 实验报告一

402
132
识别正确率
73.36
84.87
99.71
70.31
82.89
86.84
结果分析:
实验中图像3的识别率最高,图像1和图像2的识别率次之。图像1和图像2的分辨率相对图像3更低,同时图像2有折痕影响而图像1则有大量噪声。通过阈值处理能较好的处理掉图像1的噪声和图像2的折痕,从而使得图像1的识别率有所提升,而图像2的识别率变化不大。从而可以得出结论,图像3和图像2识别率不同的原因主要在于图像分辨率,而图像2和图像1识别率的不同则在于噪声干扰。
实验报告
题目
模式识别系列实验——实验一字符识别实验
内容:
1.利用OCR软件对文字图像进行识别,了解图像处理与模式识别的关系。
2.利用OCR软件对文字图像进行识别,理解正确率的概念。
实验要求:
1.利用photoshop等软件对效果不佳的图像进行预处理,以提高OCR识别的正确率。
2.用OCR软件对未经预处理和经过预处理的简体和繁体中文字符图像进行识别并比较正确率。
图像4内容既有简体又有繁体,从识别结果中可了解到错误基本处在繁体字。
遇到的问题及解决方案:
实验中自动旋转几乎没效果,所以都是采用手动旋转;在对图像4进行识别时若采用系统自己的版面分析,则几乎识别不出什么,所以实验中使用手动画框将诗的内容和标题及作者分开识别。
主要实验方法:
1.使用汉王OCR软件对所给简体和繁体测试文件进行识别;
2.理,再次识别;
实验结果:
不经过图像预处理
经过图像预处理
实验图像
图像1
图像2
图像3
图像4
图像1
图像2
字符总数
458
《模式识别》实验报告 K-L变换 特征提取

基于K-L 变换的iris 数据分类一、实验原理K-L 变换是一种基于目标统计特性的最佳正交变换。
它具有一些优良的性质:即变换后产生的新的分量正交或者不相关;以部分新的分量表示原矢量均方误差最小;变换后的矢量更趋确定,能量更集中。
这一方法的目的是寻找任意统计分布的数据集合之主要分量的子集。
设n 维矢量12,,,Tn x x x ⎡⎤⎣⎦=x ,其均值矢量E ⎡⎤⎣⎦=μx ,协方差阵()T x E ⎡⎤⎣⎦=--C x u)(x u ,此协方差阵为对称正定阵,则经过正交分解克表示为x =T C U ΛU ,其中12,,,[]n diag λλλ=Λ,12,,,n u u u ⎡⎤⎣⎦=U 为对应特征值的特征向量组成的变换阵,且满足1T -=U U 。
变换阵T U 为旋转矩阵,再此变换阵下x 变换为()T -=x u y U ,在新的正交基空间中,相应的协方差阵12[,,,]x n diag λλλ==x UC U C 。
通过略去对应于若干较小特征值的特征向量来给y 降维然后进行处理。
通常情况下特征值幅度差别很大,忽略一些较小的值并不会引起大的误差。
对经过K-L 变换后的特征向量按最小错误率bayes 决策和BP 神经网络方法进行分类。
二、实验步骤(1)计算样本向量的均值E ⎡⎤⎣⎦=μx 和协方差阵()T x E ⎡⎤⎣⎦=--C x u)(x u 5.8433 3.0573 3.7580 1.1993⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦=μ,0.68570.0424 1.27430.51630.04240.189980.32970.12161.27430.3297 3.1163 1.29560.51630.1216 1.29560.5810x ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦----=--C (2)计算协方差阵x C 的特征值和特征向量,则4.2282 , 0.24267 , 0.07821 , 0.023835[]diag =Λ-0.3614 -0.6566 0.5820 0.3155 0.0845 -0.7302 -0.5979 -0.3197 -0.8567 0.1734 -0.0762 -0.4798 -0.3583 0.0755 -0.5458 0.7537⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦=U 从上面的计算可以看到协方差阵特征值0.023835和0.07821相对于0.24267和4.2282很小,并经计算个特征值对误差影响所占比重分别为92.462%、5.3066%、1.7103%和0.52122%,因此可以去掉k=1~2个最小的特征值,得到新的变换阵12,,,new n k u u u -⎡⎤⎣⎦=U 。
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。
模式识别实验

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中。
二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中。
最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离。
(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步。
否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2.1,以下利用的matlab 中的元胞存储10个二维模式样本X{1}=[0;0];X{2}=[1;1];X{3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
《模式识别》线性分类器设计实验报告
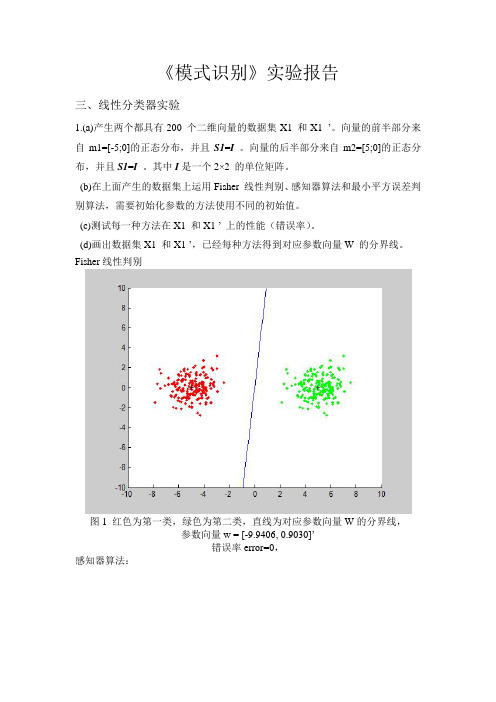
《模式识别》实验报告三、线性分类器实验1.(a)产生两个都具有200 个二维向量的数据集X1 和X1 ’。
向量的前半部分来自m1=[-5;0]的正态分布,并且S1=I 。
向量的后半部分来自m2=[5;0]的正态分布,并且S1=I。
其中I是一个2×2 的单位矩阵。
(b)在上面产生的数据集上运用Fisher 线性判别、感知器算法和最小平方误差判别算法,需要初始化参数的方法使用不同的初始值。
(c)测试每一种方法在X1 和X1 ’ 上的性能(错误率)。
(d)画出数据集X1 和X1 ’,已经每种方法得到对应参数向量W 的分界线。
Fisher线性判别图1 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数向量w = [-9.9406, 0.9030]’错误率error=0,感知器算法:图2 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1;0.1];迭代次数iter=2参数向量w = [-4.8925, 0.0920]’错误率error=0图3 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];迭代次数iter=2参数向量w = [-3.9925, 0.9920]’错误率error=0图4 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[10; 10];迭代次数iter=122参数向量w = [-5.6569, 7.8096]’错误率error=0图5 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 50];迭代次数iter=600参数向量w = [-27.0945, 37.4194]’错误率error=0图6 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 100];迭代次数iter=1190参数向量w = [-54.0048, 74.5875]’错误率error=0最小平方误差判别算法:图7 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1; 0.1];参数向量w = [-0.1908, -0.0001]’错误率error=0图8 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.5; 0.5];参数向量w = [-0.1924, 0.1492]’错误率error=0图9 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 0.5];参数向量w = [-0.1914, 0.0564]’错误率error=0图10 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];参数向量w = [-0.1943, 0.3359]’错误率error= 0.00502.重复1.中的实验内容,数据集为X2 和X2 ’。
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告-贝叶斯分类一、实验目的通过使用贝叶斯分类算法,实现对数据集中的样本进行分类的准确率评估,熟悉并掌握贝叶斯分类算法的实现过程,以及对结果的解释。
二、实验原理1.先验概率先验概率指在不考虑其他变量的情况下,某个事件的概率分布。
在贝叶斯分类中,需要先知道每个类别的先验概率,例如:A类占总样本的40%,B类占总样本的60%。
2.条件概率后验概率指在已知先验概率和条件概率下,某个事件发生的概率分布。
在贝叶斯分类中,需要计算每个样本在各特征值下的后验概率,即属于某个类别的概率。
4.贝叶斯公式贝叶斯公式就是计算后验概率的公式,它是由条件概率和先验概率推导而来的。
5.贝叶斯分类器贝叶斯分类器是一种基于贝叶斯定理实现的分类器,可以用于在多个类别的情况下分类,是一种常用的分类方法。
具体实现过程为:首先,使用训练数据计算各个类别的先验概率和各特征值下的条件概率。
然后,将测试数据的各特征值代入条件概率公式中,计算出各个类别的后验概率。
最后,取后验概率最大的类别作为测试数据的分类结果。
三、实验步骤1.数据集准备本次实验使用的是Iris数据集,数据包含150个Iris鸢尾花的样本,分为三个类别:Setosa、Versicolour和Virginica,每个样本有四个特征值:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
2.数据集划分将数据集按7:3的比例分为训练集和测试集,其中训练集共105个样本,测试集共45个样本。
计算三个类别的先验概率,即Setosa、Versicolour和Virginica类别在训练集中出现的频率。
对于每个特征值,根据训练集中每个类别所占的样本数量,计算每个类别在该特征值下出现的频率,作为条件概率。
5.测试数据分类将测试集中的每个样本的四个特征值代入条件概率公式中,计算出各个类别的后验概率,最后将后验概率最大的类别作为该测试样本的分类结果。
6.分类结果评估将测试集分类结果与实际类别进行比较,计算分类准确率和混淆矩阵。
模式识别实习报告

一、贝叶斯估计做分类【问题描述】实习题目一:用贝叶斯估计做分类。
问题描述:给出试验区裸土加水田的tif图像,要求通过贝叶斯估计算法对房屋、水田及植被进行分类。
问题分析:首先通过目视解译法对图像进行分类,获取裸土、水田和植被的DN值,在此基础上,通过该部分各个类别的面积计算先验概率,然后带入公式进行计算,从而对整个图像进行分类。
【模型方法】与分布有关的统计分类方法主要有最大似然/ 贝叶斯分类。
最大似然分类是图像处理中最常用的一种监督分类方法,它利用了遥感数据的统计特征,假定各类的分布函数为正态分布,在多变量空间中形成椭圆或椭球分布,也就是和中个方向上散布情况不同,按正态分布规律用最大似然判别规则进行判决,得到较高准确率的分类结果。
否则,用平行六面体或最小距离分类效果会更好。
【方案设计】①确定需要分类的地区和使用的波段和特征分类数,检查所用各波段或特征分量是否相互已经位置配准;②根据已掌握的典型地区的地面情况,在图像上选择训练区;③计算参数,根据选出的各类训练区的图像数据,计算和确定先验概率;④分类,将训练区以外的图像像元逐个逐类代入公式,对于每个像元,分几类就计算几次,最后比较大小,选择最大值得出类别;⑤产生分类图,给每一类别规定一个值,如果分10 类,就定每一类分别为1 ,2 ……10 ,分类后的像元值便用类别值代替,最后得到的分类图像就是专题图像. 由于最大灰阶值等于类别数,在监视器上显示时需要给各类加上不同的彩色;⑥检验结果,如果分类中错误较多,需要重新选择训练区再作以上各步,直到结果满意为止。
【结果讨论】如图所示,通过贝叶斯算法,较好地对图像完成了分类,裸土、植被和水田三个类别清晰地判别出来。
在计算先验概率时,选择何种数据成为困扰我的一个问题。
既有ENVI自身提供的精确的先验概率值,也可以自己通过计算各个类别的面积,从而获取大致的先验概率值。
最后,在田老师的讲解下,我知道了虽然数据可能不太精确,但是,计算先验概率时,总体的倾向是一致的,所以在最后判别时,因此而引起的误差是微乎其微的,所以,一定要弄清楚算法原理,才能让自己的每一步工作都有理可循。
模式识别实验报告

模式识别实验报告关键信息项:1、实验目的2、实验方法3、实验数据4、实验结果5、结果分析6、误差分析7、改进措施8、结论1、实验目的11 阐述进行模式识别实验的总体目标和期望达成的结果。
111 明确实验旨在解决的具体问题或挑战。
112 说明实验对于相关领域研究或实际应用的意义。
2、实验方法21 描述所采用的模式识别算法和技术。
211 解释选择这些方法的原因和依据。
212 详细说明实验的设计和流程,包括数据采集、预处理、特征提取、模型训练和测试等环节。
3、实验数据31 介绍实验所使用的数据来源和类型。
311 说明数据的规模和特征。
312 阐述对数据进行的预处理操作,如清洗、归一化等。
4、实验结果41 呈现实验得到的主要结果,包括准确率、召回率、F1 值等性能指标。
411 展示模型在不同数据集或测试条件下的表现。
412 提供可视化的结果,如图表、图像等,以便更直观地理解实验效果。
5、结果分析51 对实验结果进行深入分析和讨论。
511 比较不同实验条件下的结果差异,并解释其原因。
512 分析模型的优点和局限性,探讨可能的改进方向。
6、误差分析61 研究实验中出现的误差和错误分类情况。
611 分析误差产生的原因,如数据噪声、特征不充分、模型复杂度不足等。
612 提出减少误差的方法和建议。
7、改进措施71 根据实验结果和分析,提出针对模型和实验方法的改进措施。
711 描述如何优化特征提取、调整模型参数、增加训练数据等。
712 预测改进后的可能效果和潜在影响。
8、结论81 总结实验的主要发现和成果。
811 强调实验对于模式识别领域的贡献和价值。
812 对未来的研究方向和进一步工作提出展望。
在整个实验报告协议中,应确保各项内容的准确性、完整性和逻辑性,以便为模式识别研究提供有价值的参考和借鉴。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模式识别实验报告姓名:班级:学号:提交日期:实验一 线性分类器的设计一、 实验目的:掌握模式识别的基本概念,理解线性分类器的算法原理。
二、 实验要求(1)学习和掌握线性分类器的算法原理;(2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类;(3) 对实现的线性分类器性能进行简单的评估(例如算法使用条件,算法效率及复杂度等)。
三、 算法原理介绍(1)判别函数:是指由x 的各个分量的线性组合而成的函数:00g(x)w ::t x w w w =+权向量阈值权若样本有c 类,则存在c 个判别函数,对具有0g(x)w t x w =+形式的判别函数的一个两类线性分类器来说,要求实现以下判定规则:12(x)0,y (x)0,y i i g g ωω>∈⎧⎨<∈⎩方程g(x)=0定义了一个判定面,它把两个类的点分开来,这个平面被称为超平面,如下图所示。
(2)广义线性判别函数线性判别函数g(x)又可写成以下形式:01(x)w di i i g w x ==+∑其中系数wi 是权向量w 的分量。
通过加入另外的项(w 的各对分量之间的乘积),得到二次判别函数:因为,不失一般性,可以假设。
这样,二次判别函数拥有更多的系数来产生复杂的分隔面。
此时g(x)=0定义的分隔面是一个二阶曲面。
若继续加入更高次的项,就可以得到多项式判别函数,这可看作对某一判别函数g(x)做级数展开,然后取其截尾逼近,此时广义线性判别函数可写成:或:这里y 通常被成为“增广特征向量”(augmented feature vector),类似的,a 被称为“增广权向量”,分别可写成:这个从d维x空间到d+1维y空间的映射虽然在数学上几乎没有变化,但十分有用。
虽然增加了一个常量,但在x空间上的所有样本间距离在变换后保持不变,得到的y向量都在d维的自空间中,也就是x空间本身。
通过这种映射,可以将寻找权向量w和权阈值w0的问题简化为寻找一个简单的权向量a。
(3)样本线性可分即在特征空间中可以用一个或多个线性分界面正确无误地分开若干类样本;对于两类样本点w1和w2,其样本点集合表示为:,使用一个判别函数来划分w1和w2,需要用这些样本集合来确定判别函数的权向量a,可采用增广样本向量y,即存在合适的增广权向量a,使得:则称样本是线性可分的。
所有满足条件的权向量称为解向量。
通常对解区限制:引入余量b,要求解向量满足:余量b的加入在一定程度上可防止优化算法收敛到解区的边界。
(4)感知器准则函数这里考虑构造线性不等式的准则函数的问题,令准则函数J(.)为:其中Y是被权向量a错分的样本集。
当且仅当JP(a*) = min JP(a) = 0 时,a*是解向量。
这就是感知器(Perceptron)准则函数。
(5)基本的感知器设计感知器准则函数的最小化可以使用梯度下降迭代算法求解:其中,k为迭代次数,η为调整的步长。
即下一次迭代的权向量是把当前时刻的权向量向目标函数的负梯度方向调整一个修正量。
即在每一步迭代时把错分的样本按照某个系数叠加到权向量上。
这样就得到了感知算法。
(6)批处理感知器算法(7)单样本感知器算法通常情况,一次将所有错误样本进行修正不是效率最高的做法,更常用是每次只修正一个样本或一批样本的固定增量法:(8)最小均方差算法对于前面提出的不等式组:在线性不可分的情况下,不等式组不可能同时满足。
一种直观的想法就是,希望求一个a*使被错分的样本尽可能少。
这种方法通过求解线性不等式组来最小化错分样本数目,通常采用搜索算法求解。
为了避免求解不等式组,通常转化为方程组:矩阵形式为:。
方程组的误差为:,可以求解方程组的最小平方误差求解,即:Js(a) 即为最小平方误差(Minimum Squared-Error,MSE)的准则函数:准则函数最小化通常有两种方法:违逆法,梯度下降法。
梯度下降法梯度下降法在每次迭代时按照梯度下降方向更新权向量:直到满足或者时停止迭代,ξ是事先确定的误差灵敏度。
参照感知器算法中的单步修正法,对MSE也可以采用单样本修正法来调整权向量:这种算法即Widrow-Hoff算法,也称作最小均方根算法或LMS(Least-mean-squarealgorithm)算法。
四、实验结果及分析(1)单样本感知器算法分析:通过对分类结果的观察知,单样本感知器可以将数据1和数据2的数据进行正确的分类,达到了分类器的设计目的。
同时观察到对两组数据计算的迭代次数都是40次左右,耗时为0.6ms和0.8ms左右。
单样本感知器的算法效率高于批处理感知器的算法效率。
(2)批处理感知器算法分析:通过对分类结果的观察知,批处理感知器可以将数据1和数据2的数据进行正确的分类,达到了分类器的设计目的。
同时观察到对两组数据计算的迭代次数相差较大。
对数据1迭代17次,耗时1.0ms左右,相比于单样本感知器,迭代次数少但是耗时大,主要是因为批处理感知器一次迭代要对所有样本进行计算;对于数据2迭代次数和耗时都比单样本感知器多。
(3)最小均方差算法分析:通过观察分类结果知,对于数据1和数据2都存在一个分错的点,主要是由于步长选择不同会导致收敛时的分类结果存在分错的点。
同时如果选择的步长不合适,会导致a 不收敛,所以步长的选择非常重要。
五、源代码(1)单样本感知器算法function [solution iter] = SinglePerceptron(Y,tau)%% solution = SinglePerceptron(Y,tau) 固定增量单样本感知器算法实现%% 输入:规范化样本矩阵Y,裕量tau% 输出:解向量solution,迭代次数iter%[y_k d] = size(Y);a = zeros(1,d);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%k_iter=0;while k_iter<k_maxcount=0;for j=1:1:y_kif a*Y(j,:)'<taua=a+Y(j,:);k_iter=k_iter+1;count=count+1;endendif count==0break;endendk_max=k_iter; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%k = k_max;solution = a;iter = k-1;(2)批处理感知器算法function [solution iter] = BatchPerceptron(Y,tau)%% solution = BatchPerceptron(Y,tau) 固定增量批处理感知器算法实现%% 输入:规范化样本矩阵Y,裕量tau% 输出:解向量solution,迭代次数iter%[y_k d] = size(Y);a = zeros(d,1);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%k_iter=0;Y_temp=zeros(d,1);while k_iter<k_maxcount=0;for j=1:1:y_kif a'*Y(j,:)'<=tauY_temp=Y_temp+Y(j,:)';count=count+1;endendif count==0break;enda=a+Y_temp;k_iter=k_iter+1;endk_max=k_iter; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%k = k_max;solution = a;iter = k-1;(3)最小均方差算法function [solution iter] = Widrow_Hoff(Y,stepsize)%% solution = Widrow_Hoff(Y.tau)最小均方差实现算法%% 输入:规范化样本矩阵Y,裕量tau,初始步长stepsize% 输出:解向量solution,迭代次数iter%[y_k d] = size(Y);a = zeros(1,d);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%b=ones(1,y_k);k_iter=0;while k_iter<k_maxcount=0;for j=1:1:y_kif a*Y(j,:)'~=b(j)a=a+stepsize*(b(j)-a*Y(j,:)')*Y(j,:);k_iter=k_iter+1;count=count+1;endendif count==0break;endendk_max=k_iter; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%k = k_max;solution = a;iter = k-1;实验二人脸检测系统的设计与实现一、实验目的:了解人脸检测及跟踪系统的算法原理及设计实现过程。
二、实验要求(1)学习和了解基于OpenCV的人脸检测算法原理;(2)在VC++环境下基于OpenCV实现一个简单的人脸检测和跟踪程序,要求利用笔记本摄像头或者其他网络摄像头进行实时检测,最好有良好的人机交互界面(如使用MFC编程);(3)对检测到的人脸进行识别(即能识别不同的人)或对检测到的人脸做一些有趣的处理。
三、算法原理介绍(1)人脸检测原理人脸检测属于目标检测(object detection) 的一部分,主要涉及两个方面:1.先对要检测的目标对象进行概率统计,从而知道待检测对象的一些特征,建立起目标检测模型。
2.用得到的模型来匹配输入的图像,如果有匹配则输出匹配的区域,否则什么也不做。
(2)Harr特征级联表OpenCV在物体检测上使用的是haar特征的级联表,这个级联表中包含的是boost 的分类器。
首先,采用样本的haar特征进行分类器的训练,从而得到一个级联的boost分类器。
训练的方式包含两方面:1.正例样本,即待检测目标样本2.反例样本,其他任意的图片首先将这些图片统一成相同的尺寸,这个过程被称为归一化,然后进行统计。