实验6-1 卡方检验
卡方检验的基本原理

卡方检验的基本原理卡方检验是一种常用的统计方法,用于判断两个或多个分类变量之间是否存在显著性关联。
它基于卡方统计量的计算,通过比较实际观察值与理论预期值之间的差异来判断变量之间的关系。
本文将介绍卡方检验的基本原理及其应用。
一、卡方检验的基本原理卡方检验的基本原理是基于观察频数与期望频数之间的差异来判断变量之间的关联性。
在进行卡方检验之前,我们需要先了解以下几个概念:1. 观察频数(O):指实际观察到的频数,即实际发生的次数。
2. 期望频数(E):指在假设条件下,根据总体比例计算得到的预期频数。
3. 自由度(df):指用于计算卡方统计量的自由变量的个数。
卡方统计量的计算公式如下:χ² = Σ((O-E)²/E)其中,Σ表示对所有分类进行求和。
卡方统计量的计算结果服从自由度为(df = (行数-1) * (列数-1))的卡方分布。
通过查表或计算卡方分布的p值,我们可以判断卡方统计量是否达到显著水平。
二、卡方检验的应用卡方检验可以应用于多种场景,以下是几个常见的应用示例:1. 拟合优度检验:用于判断观察频数与期望频数之间的差异是否显著。
例如,我们可以使用卡方检验来判断一组数据是否符合某个理论分布。
2. 独立性检验:用于判断两个分类变量之间是否存在关联。
例如,我们可以使用卡方检验来判断性别与喜好之间是否存在关联。
3. 分类变量的比较:用于比较两个或多个分类变量之间的差异。
例如,我们可以使用卡方检验来比较不同地区的人口分布是否存在差异。
4. 配对数据的比较:用于比较配对数据之间的差异。
例如,我们可以使用卡方检验来比较同一组人在不同时间点的健康状况是否存在差异。
三、卡方检验的限制虽然卡方检验是一种常用的统计方法,但也存在一些限制:1. 样本量要求:卡方检验对样本量的要求较高,特别是在分类变量较多或期望频数较低的情况下,需要保证样本量足够大。
2. 数据独立性:卡方检验要求观察数据之间相互独立,如果数据存在相关性或依赖性,可能会导致检验结果不准确。
卡方检验,秩和检验

(2) 2 分布的一个基本性质是可加性: 如果两个独立的随
机变量X1和X2分别服从自由度ν1和ν2的分布,即
X1~
21,
X2~
2
2
,那么它们的和( X1+X2 )服从自由度( ν1+ν2 )的 2 分布,
即 (X1 X2)
~ 2 1 2
。
(3) 2 界值:当 确定后, 2 分布曲线下右侧尾部的
R×C表的χ2检验通用公式
理 论 频 数 T 行 合 计 列 合 计 n R n C 代 入 基 本 公 式 总 例 数 n
可 推 导 出 : 基 本 公 式 通 用 公 式
2 ( A T ) 2 2 n ( A 2 1 )
T
n R n C
自 由 度 = ( 行 数 1 ) ( 列 数 1 )
问:两种方法何者为优?
七、行×列(R×C)表资料的χ2检验
前述四格表,即 2×2 表,是最简单的一种 R×C 表 形式。因为其基本数据有 R 行 C 列,故通称行×列表或 R×C 列联表(contingency table),简称 R×C 表。
R×C 表的资料形式有: 1. 多个样本率的比较 2. 多组构成比的比较
上述基本公式由Pearson提出,因此软件上常称这种 检验为Pearson卡方检验,下面将要介绍的其他卡方检验 公式都是在此基础上发展起来的。它不仅适用于四格表 资料,也适用于其它的“行×列表”。
检验统计量 2 值反映了实际频数与理论频
数的吻合程度。
若检验假设H0:π1=π2成立,四个格子的实际频数A 与
数固定的情况下,4个基本数据当中只有一个可
以自由取值。
χ2检验的步骤
(1)建立检验假设:假设两总体率相等 H0:两种疗法病死率相同,即π1=π2; H1:两种疗法有病死率不同,即π1≠π2; α=0.05。
卡方检验医学统计学

卡方检验医学统计学卡方检验是医学统计学中最常用的检验方法之一,它可用于测量两组数据之间的关联性。
在研究中,我们常常需要探究二者之间是否存在某种关联,卡方检验就是我们解决这个问题的利器。
卡方检验的原理卡方检验的原理是基于期望频数和实际频数的差异来检验两个变量之间的关系。
期望频数指的是在假设两个变量独立的情况下,我们可以根据样本量和其他条件,计算出不同组之间的理论值。
而实际频数则是实验中观察到的实际结果。
卡方检验的步骤如下:1.建立零假设和备择假设。
零假设指的是假设两个变量之间不存在任何关系,备择假设则是反之。
2.确定显著性水平 alpha,通常取值为0.05。
3.构建卡方检验统计量。
计算方法为将所有观察值与期望值的差平方后,再除以期望值的总和。
4.根据自由度和显著性水平,查卡方分布表得到 P 值。
5.如果 P 值小于显著性水平,拒绝零假设;否则无法拒绝零假设。
卡方检验的应用卡方检验可以应用于多个领域,其中医学统计学是最为常见的一个。
卡方检验可以用来分析两个疾病之间的相关性或者测量一种治疗方法的效果。
举个例子,某药厂要研发一种新的药物来治疗心脏病。
为了验证该药的疗效,实验组和对照组各50 人。
在 6 个月的治疗后,实验组和对照组中分别有 10 人和 15 人痊愈了。
卡方检验的作用就在于此时可以用来检验两组之间的差异是否具有统计学意义。
除了医学统计学之外,卡方检验在社会学、心理学、市场营销、物理等领域也都有广泛应用。
卡方检验的限制虽然卡方检验被广泛应用于各种实验和研究中,但它也有着自己的限制。
其中比较明显的一点就是对样本量有一定的要求。
当样本量较小的时候,期望频数的计算就会出现一定的误差,进而导致检验结果不准确。
此外,在面对非常态分布数据时,卡方检验也会出现问题。
当数据呈现正态分布时,卡方检验的准确性最高。
然而,实际上,很多数据都呈现出非正态分布,这时需要使用一些修正方法来解决。
卡方检验是医学统计学中最常用的统计方法之一,它可以用来测量两个变量之间的关联性。
医学统计学6卡方检验

卡方检验的卡方值
卡方值是卡方检验的统计量,用于衡量实际观测值和期望值之间的差异。 卡方值越大,就表示观测值与期望值之间的差异越大,这意味着结论更可信。
如何进行卡方检验
第一步
确定研究的问题和相关变量, 并给出所需的假设。
第二步
收集数据并整理成交叉列联 表。
第三步
计算卡方值和自由度。
第四步
查阅卡方分布表,确定相应置信度水准下的临 界值。
2
应用
概率常用于医学研究中,以测量一种治疗对患者的疗效。
3
公式
概率=事件发生的次数/总次数。
统计学中的假设
在统计学中,我们需要制定一个或多个假设进而做出相应的决策。常见的假设有零假设和备择假设。
零假设
零假设是指不存在两个群体之间的差异。
备择假设
备择假设是指存在两个群体之间的差异。
什么是卡方检验
卡方检验是一种用于比较两个或多个群体在某些因素上的分布情况的方法。
卡方检验与其他假设检验的区 别
卡方检验主要用于回答多个分类变量间是否有关联的问题,而 T 检验和 Z 检 验主要用于回答单变量的问题。
卡方检验对于数据的类型并无太多的要求,而 T 检验和 Z 检验只适用于概率 分布为正态分布的数据。
卡方检验的计算公式
卡方检验的计算公式如下: χ² = ∑(O-E)²/E
为什么需要统计学
准确
统计学可以让我们从收集到的数据中得出真正 准确可靠的结论。
决策
统计学有助于做出决策并帮助我们更好地理解 数据背后的信息。
推断
统计学允许我们通过对大量数据的推断得到新 的信息。
掌握
掌握医学统计学对于实现优质医保研究至关重 要。
概率
试验数据的正态性检验、数据的转换及卡方检验
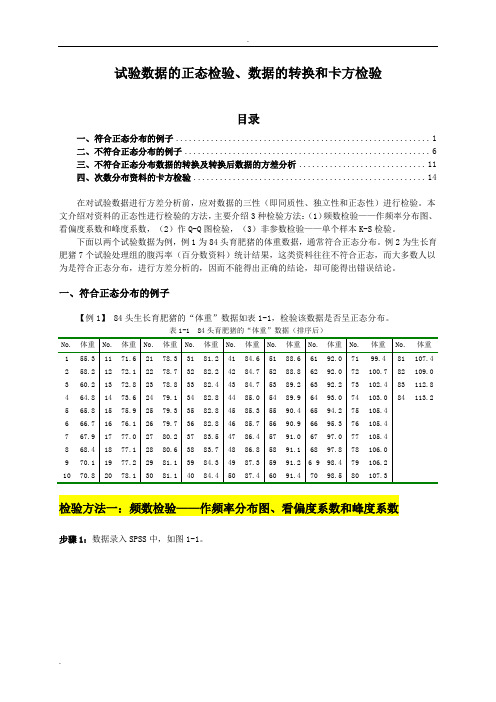
试验数据的正态检验、数据的转换和卡方检验目录一、符合正态分布的例子 (1)二、不符合正态分布的例子 (6)三、不符合正态分布数据的转换及转换后数据的方差分析 (11)四、次数分布资料的卡方检验 (14)在对试验数据进行方差分析前,应对数据的三性(即同质性、独立性和正态性)进行检验。
本文介绍对资料的正态性进行检验的方法,主要介绍3种检验方法:(1)频数检验——作频率分布图、看偏度系数和峰度系数,(2)作Q-Q图检验,(3)非参数检验——单个样本K-S检验。
下面以两个试验数据为例,例1为84头育肥猪的体重数据,通常符合正态分布。
例2为生长育肥猪7个试验处理组的腹泻率(百分数资料)统计结果,这类资料往往不符合正态,而大多数人以为是符合正态分布,进行方差分析的,因而不能得出正确的结论,却可能得出错误结论。
一、符合正态分布的例子【例1】 84头生长育肥猪的“体重”数据如表1-1,检验该数据是否呈正态分布。
表1-1 84头育肥猪的“体重”数据(排序后)检验方法一:频数检验——作频率分布图、看偏度系数和峰度系数步骤1:数据录入SPSS中,如图1-1。
图1-1 体重数据录入SPSS中步骤2:在SPSS里执行“分析—>描述统计—>频率”,然后弹出“频率”对话框(图1-2a),变量选择“体重”;再点右边的“统计量”按钮,弹出图“频率:统计量”对话框(图1-2b),选择“偏度”和“丰度”(图1-2b);再点右边的“图表”按钮,弹出图“频率:图表”对话框(图1-2c),选择“直方图”,并选中“在直方图显示正态曲线”图1-2a “频率”对话框图1-2b “频率:统计量”对话框图1-2c “频率:图表”对话框设置完后点“确定”后,就会出来一系列结果,包括2个表格和一个图,我们先来看看“统计量”表,如下:统计量体重N 有效84缺失0偏度.040偏度的标准误.263峰度-.202峰度的标准误.520偏度系数=0.040,峰度系数-0.202;两个系数都小于1,可认为近似于正态分布。
卡方检验(1)

表11.1 甲、乙两药治疗小儿上消化道出血的效果
2 检验的基本公式:
2 (AT)2 T
从基本公式可以看出, 统计量值反映了实际频数和
2
理论频数的吻合程度。
2 值与什么有关? 1.与A与T的差别/吻合程度有关。 2.与格子数,严格地说是自由度有关。
由 2 统计量的公式(11.2)可以看出,( A T )2 0
问题1:本例资料类型?(此表称为?) 问题2:本例设计类型? 问题3: 研究目的是什么? 问题4: 用什么方法解决?
第十一章 2 检 验
卡方检验是英国统计学家K. Pearson于1900年提出的,以 卡方分布和拟合优度为理论 依据,一种用途较广的假设 检验方法。
英国生物计量学派 Karl Pearson(1857-1936) 现代统计学之父
问题1: 研究目的是什么? 问题2: 用什么方法解决?
例11.1 某研究者欲比较甲、乙两药治疗小儿上消化道
出血的效果,将90名患儿随机分为两组,一组采用甲药 治疗,另一组采用乙药治疗,一个疗程后观察结果,见 表11.1。问两药治疗小儿上消化道出血的有效率是否有 差别?
表11.1 甲、乙两药治疗小儿上消化道出血的效果
若H0成立,则理论上:
甲药组有效人数为:T11
4567 90
33.5
甲药组无效人数为:
乙药组有效人数为:
T12
452311.5 90 67
T21
45 90
33.5
乙药组无效人数为:
T22
452311.5 90
T nRnC n
T nRnC n
n R 为相应行的合计
n C 为相应列的合计
n 为总例数。
2 检验的基本公式:
6 卡方检验
未知,故由样本去估计( 解 由于总体µ、σ未知,故由样本去估计(采用 点估计): 点估计):
µ = x =95.60 σ = S = 5.274
首先算出各组的理论频率: 首先算出各组的理论频率:
xi +1 − µ xi − µ pi = Φ − Φ σ σ
拟合优度检验(适合性检验) 第一节 拟合优度检验(适合性检验)
所谓拟合优度, 所谓拟合优度,就是指观察到的样本表现与某种理论 拟合优度 模型吻合的程度。 模型吻合的程度。拟合优度检验就是对观察的样本表现与 所选某种理论模型的拟合程度作推断判决。 所选某种理论模型的拟合程度作推断判决。 比如眼下有观察资料, 比如眼下有观察资料,需判明它是来自遵从何种分布 的总体,我们可以根据已有的经验对它作是“ 的总体,我们可以根据已有的经验对它作是“来自某种总 的假定(假设), ),即 体”的假定(假设),即 H0:F(x) = F0(x) 式中, 表示已知的某种分布, 式中,F0(x)表示已知的某种分布,如正态分布、二项分布、 表示已知的某种分布 如正态分布、二项分布、 χ2分布等。值得注意的是在这里建立统计假设不同于以前 分布等。值得注意的是在这里建立统计假设不同于以前 所作的假设检验, 所作的假设检验,前面作假设检验时总是选择欲否定的内 容作成立的假定; 容作成立的假定;而在这里我们通常是选择最有可能接近 的类型作成立的假设。 的类型作成立的假设。
组中值 组频率 f 理论频率 偏差量 83 3 2.381 0.619 86 6 5.637 0.363 89 12 12.40 -0.40 92 20 19.72 0.285 95 23 22.68 0.316 98 19 18.88 0.118 101 10 11.37 -1.37 104 5 4.952 0.048 107 2 1.981 0.019
卡方检验
• (2)分析过程说明 • ①表6-1的资料是经过人为汇总得到的,即是采用频数表 格式来记录的的资料,同组分别有两种互不相容的结果— —杀灭或未杀灭,两组各自的结果互不影响,即相互独立。 对于这种频数表格资料,在卡方检验之前须用Weight Cases命令对频数变量进行预先统计处理,操作如下:单 击Data-Weight Cases命令,则弹出如图6-3所示对话框, 选中Weight cases by,按三角按钮将变量“计数”置入 Frequency Variable框内,定义“计数”为权数,按OK 。 • ②单击主菜单Analyze-Descriptive Statistics-Crosstabs, 则弹出对话框,按三角按钮将行变量“治疗方法” 置入 Row框内,将列变量“治疗效果” 置入Column框内,如 图6-4。 • ③按Stastics按钮,弹出“选择统计方法”对话框(见图 6-5),选中Chi-square,按Continue,返回图6-4,点OK, 输出表6-2、表 6-3。
x 2 1.428, p 0.839 0.05
,差异不显著,可以认为不同的治疗方法与治疗效果无关,即三 种治疗方法对治疗效果的影响差异不显著。
下表为不同灌溉方式下水稻叶片衰老情况的资料,试测验 稻叶衰老的情况是否与灌溉方式有关?
灌溉方式 深水 浅水 湿润 总计 绿叶数 146 183 152 481 黄叶数 7 9 14 30 枯叶数 7 13 16 36
第五章 卡方检验
一、2X2列联表的独立性检验 (一)计算公式
(二)例题及统计分析
例6.1 分别用灭螨A和灭螨B杀灭害虫,结果如表6-1, 问两种灭螨剂的效果差异是否显著? 表6-1 灭螨A和B杀灭害虫试验结果
组别 灭螨A 灭螨B 未杀灭数C1 12 22 TC1=34 杀灭数C2 32 14 TC2=46 TR1=44 TR2=36 T=80
卡方检验基本公式检验方法
配对四格表资料的χ2检验 (McNemar's test)
H0:b,c来自同一个实验总体(B=C);
注:B=C=(b+c)/2
H1:b,c来自不同的实验总体(B C );α=0.05。
当b c 40时, 2 (b c)2 , 1
bc
b c 40时,需作连续性校正, 2 ( b c 1)2 , 1
1122.59 15
18
卡方值
χ2检验的基本公式
2 ( A T )2 ,
T
(R 1)(C 1)
上述检验统计量由K. Pearson提出,因此许多统计软 件上常称这种检验为Pearson’s Chi-square test,下面将要 介绍的其他卡方检验都是在此基础上发展起来的。
二、四格表资料专用公式
2
,(2Biblioteka )服从均数为,方差为2的正态分布χ2分布(Chi-square distribution)
0.5 0.4
f
( 2)
1 2(
/ 2)
2 2
(
/ 21)
e2 / 2
纵高
0.3 0.2 0.1 0.0
0
自由度=1 自由度=2 自由度=3 自由度=6 P=0.05的临界值
3 3.84 6 7.81 9
检验假设: (以P119 例7-6为例,进一步分析)
H0: A
,任两对比组的总体有效率相等
B
H1: A B,任两对比组的总体有效率不等
0.05
检验水准调整:(否则结果会自相矛盾!)
2 31.586 41 3
P 0.005
7.4 行×列表资料的 2检验
07用SPSS进行卡方检验
③单击
,打开图6-5所示对话框,选中“卡方”,
单击
,返回图6-4所示对话框,再单击
,输出
表6-2和表6-3所示结果。
图6-4 行×列分析对话框
图6-5选择统计方法(卡方检验) 对话框
表6-2 灭螨剂A和灭螨剂B杀灭大蜂螨效果
表6-3 2 检验结果表
3.结果说明
表6-2 灭螨剂A和灭螨剂B杀灭大蜂螨效果
图6-2 例6.1数据输入格式
2. 统计分析 (1)简明分析步骤
数据 → 加权个案 加权个案 频率变量:计数 确定
分析→描述统计→交叉表 行:组别 列:效果 统计量: √ 卡方 继续 确定
频率变量为计数
行变量 列变量 要求进行卡方检验
(2)分析过程说明 ①单击“数据 → 加权个案 ”,打开图6-3对话框,选中
总和
34
46
80
◆ 具体步骤: 1.数据输入 (1)点击数据编辑窗口底部的“变量视图”标签,进入 “变量视图”窗口,分别命名3个变量:“组别”、“效果” 和“计数”。“组别”和“效果”两变量的类型选择为 “字符串”,变量“计数”小数位数定义为0,如图6-1。
图6-1 例6.1资料的变量命名
(2)点击数据编辑窗口底部的“数据视图”标签,进入“数据 视窗”界面,按图6-2格式输入数据资料。
五、用SPSS进行卡方检验
内容
一、2×2列联表的独立性检验 二、R×K列联表的独立性检验 三、适合性检验
一、教学目的、要求: 1. 掌握SPSS中进行X2检验分析的基本命令与操作; 2. 理解用SPSS进行X2检验分析所得结果的含义; 3. 了解X2检验的基本原理。
二、本节重点、难点: 1. SPSS中进行X2检验分析的基本命令与操作; 2. SPSS进行X2检验分析所得结果的含义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
20
3. 配对四格表资料卡方检验
例4 用两种不同方法检查已确诊的乳腺癌患者120名,检 查结果见下表,问两种方法何者为优?
表3 两种乳腺癌诊断方法结果比较
乙法
甲法Leabharlann 合计+-
+
42
18
60
-
30
30
60
合计
72
48
120
21
data aa;
do a=1 to 2;
do b=1 to 2;
input x@@;
实际频数和理论频数。
;
proc freq;
weight x;
tables a*b/chisq expected norow nocol nopercent;
run;
因为有一个格子的理论频 数1<T<5,所以选择连续 性校正的结果。
此时,SAS结果中 会给出相应提示
行×列表卡方检验 关联性检验
双向无序分类资料的关联性检验
有序分组资料的线性趋势检验
例:某研究者欲研究年龄与冠状动脉粥样硬化等级间的关 系,将 278 例尸解资料整理成表 6-13,问年龄与冠状动脉 粥样硬化等级间是否存在线性变化趋势?
表 6-13 年龄与冠状动脉硬化的关系
年龄 (岁) (X)
冠状动脉硬化等级(Y) - + ++ +++ 合计
20~ 30~ 40~ ≥50 合计
• 有序分组
3
1. 完全随机设计四格表资料 (两样本率的比较)
• 例1 对甲、乙两种降压药进行临床疗效评价,将某时 间段内入院的高血压病人随机分为两组,每组均为100 人。甲药治疗组80位患者有效,乙药治疗组50位患者 有效,两种降压药有效率有无差别?
四格表资料专用公式: 2
(a
(ad bc)2 n b)(c d )(a c)(b
Φ系数(phi coefficient)
山东大学公卫学院 Liu Yunxia
14
双向无序分类资料的关联性检验
行×列表卡方检验 关联性检验
Cramer氏V系数(Cramer’s V coefficient)
山东大学公卫学院 Liu Yunxia
15
行×列表卡方检验 关联性检验
双向无序分类资料的关联性检验
表1 手术治疗前列腺癌患者合并症发生情况
手术方法
电切术 开放手术 合计
合并症
+
-
11
71
1
38
12
109
合计
82 39 121
12
data aa;
do a=1 to 2;
do b=1 to 2;
input x@@;
output; end; end; cards;
为了简化,仍然只输出
11 71 1 38
• 对于其它三类R*C表及其分析过程,因涉及方法太多,如 有兴趣可参考相关书籍。
6. Cochran Armitage 趋势检验
• 例 为了解某市中学生的吸烟状况,抽样调查了891名中学 生,结果见下表,问该市中学生吸烟率是否有随年级增加 而增高的趋势?
山东大学公卫学院 Liu Yunxia
27
Cochran Armitage 趋势检验
d)
四格表资料校正公式:
c
2=
(|ad-bc|-n/ 2)2 n (a+b)(c+d )(a+c)(b+d
)
4
data aa;
do a=1 to 2;
do b=1 to 2;
input x@@; output; end; end;
ab为行和列 循环语句输入表格数据
cards; 20 80 50 50
data aa; do a=1 to 3; do b=1 to 3; input x@@; output; end; end; cards; 34 62 28 27 28 20 57 105 52 ; proc freq; weight x; tables a*b/chisq expected norow nocol nopercent; run;
25
所有格子的理论频数均 大于5,选择一般卡方 检验的结果即可
26
5. 多个样本率及构成比的比较
• 对于R*C表资料多样本率及构成比的比较,在SAS中所用 程序与前述程序相同,在此不再重复。多个样本率两两比 较时,因为SAS过程可以给出确切概率值,所以可用所得 的每个四格表的概率值与调整后的检验水准比较即可。
output; end; end; cards; 42 18 30 30 ;
用agree选项替换chisq选 项,在结果中将输出 McNemar检验和Kappa一 致性检验结果。
proc freq;
weight x;
tables a*b/agree norow nocol nopercent;
run;
70 22 4 2 98 27 24 9 3 63 16 23 13 7 59 9 20 15 14 58 122 89 41 26 278
29
在tables语句后加选择项 expected,输出理论频数
输出理论频数
9
输出结果的第一部分:
在每个格子中输 出了该格子对应 的理论频数,为 格子中的第二个 数据,其它数据 不变。
10
data aa;
do a=1 to 2;
do b=1 to 2;
input x@@;
output; end; end;
输出原表格
McNemar检验的统计量值和 概率值
Kappa一致性检验结果:给出 Kappa值、渐进标准误和其可信区 间。因可信区间不包含0,因此若 是两种方法比较的话,则说明两 种方法的检测结果具有一致性。
1960年Cohen等提出用Kappa值作为评价判断的 一致性的指标。 经验法则:Kappa大于0.75表示好的一致性 (Kappa最大为1); 小于0.4表示一致性差。 Kappa不考虑评价人间的意见不一致性的程度, 只考虑他们一致与否。 Kappa取值在[-1,1]
cards;
20 80 50 50
;
proc freq;
weight x;
tables a*b/chisq expected norow nocol nopercent;
run;
不输出行和列的百分比以及总百分比, 只输出实际频数和理论频数
11
• 例2 121名前列腺癌患者中,82名接受电切术治疗,术 后有合并症者11人;39名接受开放手术治疗,术后有合 并症1人。试分析两种手术的合并症发生率有无差异?
上述SAS程序的输出结果:
结果第三部分:为Fisher精确概率法结果,第二到第五 行分别为左侧概率、右侧概率、(当前的)表概率和 双侧概率。最下面为总的样本含量。
data aa; do a=1 to 2; do b=1 to 2; input x@@; output; end; end; cards; 20 80 50 50 ; proc freq; weight x; tables a*b/chisq expected; run;
表 2 乙肝免疫球蛋白预防胎儿宫内感染 HBV 的效果
组别 预防注射组
阳性 4
阴性 18
合计 22
感染率(%) 18.18
非预防组
5
6
11
45.45
合计
9
24
33
27.27
18
data aa;
do a=1 to 2;
do b=1 to 2;
input x@@;
output; end; end;
cards; 4 18 5 6 ;
为了简化,仍然只输出 实际频数和理论频数。
proc freq;
weight x;
tables a*b/chisq expected norow nocol nopercent;
run;
总的样本例数小于40,所以要 选择精确概率法的检验结果。 本例选择双侧检验的概率。
此时SAS结果中仍然 会有相应的提示
卡方检验
DIVISION OF BIOSTATISTICS SCHOOL OF PUBLIC HEALTH
SHANDONG UNIVERSITY
2
实验内容
• 四格表资料的 χ2 检验 • 四格表资料的Fisher确切概率法 • 配对四格表资料的 χ2 检验 • 行×列表资料的 χ2 检验 • Cochran-Armitage 趋势检验
Weight指明频数变量 Tables a*b 为行乘列的表格
;
proc freq; weight x;
进行四格表资 料的卡方检验
tables a*b/chisq;
run;
5
上述SAS程序的输出结果:
输出结果的第一部分: 为列联表的内容,每个格中 从上到下4个数值分别为: 实际频数、该格实际频数占 总频数的百分比、每格的实 际频数占行合计的百分比和 每格的实际频数占列合计的 百分比。 列联表右侧为行合计部分, 最下方为列合计部分。
列联系数 (contingency coefficient)
山东大学公卫学院 Liu Yunxia
16
17
2. 四格表资料Fisher确切概率法
• 例3 某医师为研究乙肝免疫球蛋白预防胎儿宫内感染 HBV的效果,将33例HBsAg阳性孕妇随机分为预防注射 组和非预防组,结果见下表。问2组新生儿的HBV总体 感染率有无差别?
6
上述SAS程序的输出结果:
结果第二部分:第一列为各种检验方法,第一到三分别为专 用公式、似然比法、连续性校正、mantel-haenszel法;后面 三列分别为自由度、卡方值及概率值; 第一列四到六分别为关联性统计量phi系数、列联系数和 cramer`s V统计量,绝对值越大说明关系越密切。