线性回归模型
线性统计模型知识点总结

线性统计模型知识点总结一、线性回归模型1. 线性回归模型的基本思想线性回归模型是一种用于建立自变量和因变量之间线性关系的统计模型。
它的基本思想是假设自变量与因变量之间存在线性关系,通过对数据进行拟合和预测,以找到最佳拟合直线来描述这种关系。
2. 线性回归模型的假设线性回归模型有一些假设条件,包括:自变量与因变量之间存在线性关系、误差项服从正态分布、误差项的方差是常数、自变量之间不存在多重共线性等。
3. 线性回归模型的公式线性回归模型可以用如下的数学公式来表示:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε,其中Y 是因变量,X是自变量,β是模型的系数,ε是误差项。
4. 线性回归模型的参数估计线性回归模型的参数估计通常使用最小二乘法来进行。
最小二乘法的目标是通过最小化残差平方和来寻找到最佳的模型系数。
5. 线性回归模型的模型评估线性回归模型的好坏可以通过很多指标来进行评价,如R-squared(R^2)、调整后的R-squared、残差标准差、F统计量等。
6. 线性回归模型的应用线性回归模型广泛应用于经济学、金融学、市场营销、社会科学等领域,用以解释变量之间的关系并进行预测。
二、一般线性模型(GLM)1. 一般线性模型的基本概念一般线性模型是一种用于探索因变量与自变量之间关系的统计模型。
它是线性回归模型的一种推广形式,可以处理更为复杂的数据情况。
2. 一般线性模型的模型构建一般线性模型与线性回归模型相似,只是在因变量和自变量之间的联系上,进行了更为灵活的变化。
除了线性模型,一般线性模型还可以包括对数线性模型、逻辑斯蒂回归模型等。
3. 一般线性模型的假设一般线性模型与线性回归模型一样,也有一些假设条件需要满足,如误差项的正态分布、误差项方差的齐性等。
4. 一般线性模型的模型评估一般线性模型的模型评估通常涉及到对应的似然函数、AIC、BIC、残差分析等指标。
5. 一般线性模型的应用一般线性模型可以应用于各种不同的领域,包括医学、生物学、社会科学等,用以研究因变量与自变量之间的关系。
各种线性回归模型原理

各种线性回归模型原理线性回归是一种广泛应用于统计学和机器学习领域的方法,用于建立自变量和因变量之间线性关系的模型。
在这里,我将介绍一些常见的线性回归模型及其原理。
1. 简单线性回归模型(Simple Linear Regression)简单线性回归模型是最简单的线性回归模型,用来描述一个自变量和一个因变量之间的线性关系。
模型方程为:Y=α+βX+ε其中,Y是因变量,X是自变量,α是截距,β是斜率,ε是误差。
模型的目标是找到最优的α和β,使得模型的残差平方和最小。
这可以通过最小二乘法来实现,即求解最小化残差平方和的估计值。
2. 多元线性回归模型(Multiple Linear Regression)多元线性回归模型是简单线性回归模型的扩展,用来描述多个自变量和一个因变量之间的线性关系。
模型方程为:Y=α+β1X1+β2X2+...+βnXn+ε其中,Y是因变量,X1,X2,...,Xn是自变量,α是截距,β1,β2,...,βn是自变量的系数,ε是误差。
多元线性回归模型的参数估计同样可以通过最小二乘法来实现,找到使残差平方和最小的系数估计值。
3. 岭回归(Ridge Regression)岭回归是一种用于处理多重共线性问题的线性回归方法。
在多元线性回归中,如果自变量之间存在高度相关性,会导致参数估计不稳定性。
岭回归加入一个正则化项,通过调节正则化参数λ来调整模型的复杂度,从而降低模型的过拟合风险。
模型方程为:Y=α+β1X1+β2X2+...+βnXn+ε+λ∑βi^2其中,λ是正则化参数,∑βi^2是所有参数的平方和。
岭回归通过最小化残差平方和和正则化项之和来估计参数。
当λ=0时,岭回归变为多元线性回归,当λ→∞时,参数估计值将趋近于0。
4. Lasso回归(Lasso Regression)Lasso回归是另一种用于处理多重共线性问题的线性回归方法,与岭回归不同的是,Lasso回归使用L1正则化,可以使得一些参数估计为0,从而实现特征选择。
线性回归模型

线性回归模型线性回归是统计学中一种常用的预测分析方法,用于建立自变量和因变量之间的线性关系模型。
该模型可以通过拟合一条直线或超平面来预测因变量的值。
在本文中,我们将探讨线性回归模型的基本原理、应用场景以及如何构建和评估模型。
一、基本原理线性回归模型的基本原理是通过最小二乘法来确定自变量与因变量之间的线性关系。
最小二乘法的目标是使模型预测值与真实观测值的残差平方和最小化。
通过最小二乘法,可以获得模型的系数和截距,从而建立线性回归模型。
二、应用场景线性回归模型适用于连续型变量的预测与分析。
以下是一些常见的应用场景:1. 经济学领域:预测GDP增长、通货膨胀率等经济指标;2. 市场营销:分析广告投入与销售额之间的关系;3. 生物医学:研究药物剂量与治疗效果的关联性;4. 地理科学:探索自然地理因素与社会经济发展之间的关系。
三、构建线性回归模型1. 数据收集:收集自变量和因变量的数据,确保数据的可靠性和完整性;2. 数据探索:通过统计分析、可视化等手段对数据进行初步探索,检查是否存在异常值或缺失值;3. 特征选择:选择与因变量相关性较高的自变量,可以使用统计方法或领域知识进行选择;4. 模型建立:使用最小二乘法等方法拟合线性回归模型,并求解模型的系数和截距;5. 模型评估:使用各种指标(如均方误差、决定系数等)来评估模型的性能和拟合度;6. 模型优化:根据模型评估结果,对模型进行进一步优化,可以考虑添加交互项、多项式项等。
四、评估线性回归模型线性回归模型的评估可以通过以下指标进行:1. 均方误差(Mean Squared Error,MSE):衡量模型预测值与真实观测值之间的误差;2. 决定系数(Coefficient of Determination,R-squared):衡量模型对因变量变异的解释程度;3. 残差分析:通过检查预测残差的正态性、独立性和同方差性来评估模型的拟合效果。
五、总结线性回归模型是一种简单而强大的统计学方法,可用于预测和分析连续型变量。
线性回归模型
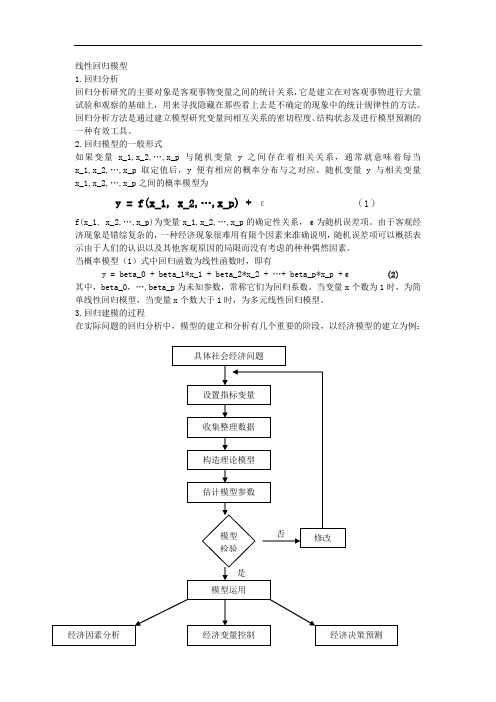
线性回归模型1.回归分析回归分析研究的主要对象是客观事物变量之间的统计关系,它是建立在对客观事物进行大量试验和观察的基础上,用来寻找隐藏在那些看上去是不确定的现象中的统计规律性的方法。
回归分析方法是通过建立模型研究变量间相互关系的密切程度、结构状态及进行模型预测的一种有效工具。
2.回归模型的一般形式如果变量x_1,x_2,…,x_p与随机变量y之间存在着相关关系,通常就意味着每当x_1,x_2,…,x_p取定值后,y便有相应的概率分布与之对应。
随机变量y与相关变量x_1,x_2,…,x_p之间的概率模型为y = f(x_1, x_2,…,x_p) + ε(1)f(x_1, x_2,…,x_p)为变量x_1,x_2,…,x_p的确定性关系,ε为随机误差项。
由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑的种种偶然因素。
当概率模型(1)式中回归函数为线性函数时,即有y = beta_0 + beta_1*x_1 + beta_2*x_2 + …+ beta_p*x_p +ε (2)其中,beta_0,…,beta_p为未知参数,常称它们为回归系数。
当变量x个数为1时,为简单线性回归模型,当变量x个数大于1时,为多元线性回归模型。
3.回归建模的过程在实际问题的回归分析中,模型的建立和分析有几个重要的阶段,以经济模型的建立为例:(1)根据研究的目的设置指标变量回归分析模型主要是揭示事物间相关变量的数量关系。
首先要根据所研究问题的目的设置因变量y,然后再选取与y有关的一些变量作为自变量。
通常情况下,我们希望因变量与自变量之间具有因果关系。
尤其是在研究某种经济活动或经济现象时,必须根据具体的经济现象的研究目的,利用经济学理论,从定性角度来确定某种经济问题中各因素之间的因果关系。
(2)收集、整理统计数据回归模型的建立是基于回归变量的样本统计数据。
统计学中的线性回归模型解释

统计学中的线性回归模型解释线性回归模型是统计学中常用的一种模型,用于解释变量之间的关系、预测未知观测值,并帮助我们理解数据集的特征。
本文将对线性回归模型做详细解释,并探讨其应用领域、优缺点以及解释结果的可靠性。
一、线性回归模型简介线性回归模型是一种用于描述因变量与自变量之间线性关系的模型。
它基于以下假设:1. 因变量与自变量之间存在线性关系;2. 观测误差服从正态分布,且均值为0;3. 不同样本之间的观测误差独立。
线性回归模型的数学表达为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y表示因变量,X1, X2, ..., Xn表示自变量,β0, β1, β2, ..., βn表示模型的参数,ε表示观测误差。
二、线性回归模型的应用领域线性回归模型在实际应用中具有广泛的应用领域,例如:1. 经济学:用于分析经济数据中的因果关系,进行经济预测;2. 社会科学:用于研究社会组织结构、心理行为等因素的影响;3. 医学:用于研究药物的疗效,控制混杂因素对结果的影响;4. 金融学:用于预测股票价格、评估金融风险等。
三、线性回归模型的优缺点线性回归模型的优点在于:1. 简单直观:模型易于理解和解释,适用于初学者;2. 高效稳定:对于大样本量和满足基本假设的数据,模型的估计结果可靠且稳定。
然而,线性回归模型也存在一些缺点:1. 对数据分布假设严格:模型要求观测误差服从正态分布,且独立同分布;2. 无法处理非线性关系:线性回归模型无法有效描述非线性关系;3. 受异常值影响大:异常值对模型参数估计结果影响较大;4. 多重共线性问题:自变量之间存在高度相关性,导致参数估计不准确。
四、线性回归模型结果解释的可靠性线性回归模型的结果解释需要注意其可靠性。
以下是一些需要考虑的因素:1. 参数估计的显著性:通过假设检验确定模型中的自变量对因变量的解释是否显著;2. 拟合优度:通过判定系数(R-squared)评估模型对数据的拟合程度,越接近于1表示拟合效果越好;3. 残差分析:对模型的残差进行检验,确保其满足正态分布、独立性等假设。
线性回归模型的建模与分析方法

线性回归模型的建模与分析方法线性回归模型是一种常用的统计学方法,用于研究自变量与因变量之间的关系。
在本文中,我们将探讨线性回归模型的建模与分析方法,以及如何使用这些方法来解决实际问题。
一、线性回归模型的基本原理线性回归模型假设自变量与因变量之间存在线性关系,即因变量可以通过自变量的线性组合来预测。
其基本形式可以表示为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y表示因变量,X1、X2、...、Xn表示自变量,β0、β1、β2、...、βn表示回归系数,ε表示误差项。
二、线性回归模型的建模步骤1. 收集数据:首先需要收集自变量和因变量的相关数据,确保数据的准确性和完整性。
2. 数据预处理:对数据进行清洗、缺失值处理、异常值处理等预处理步骤,以确保数据的可靠性。
3. 模型选择:根据实际问题和数据特点,选择适合的线性回归模型,如简单线性回归模型、多元线性回归模型等。
4. 模型拟合:使用最小二乘法等方法,拟合回归模型,得到回归系数的估计值。
5. 模型评估:通过统计指标如R方值、调整R方值、残差分析等,评估模型的拟合优度和预测能力。
6. 模型应用:利用已建立的模型进行预测、推断或决策,为实际问题提供解决方案。
三、线性回归模型的分析方法1. 回归系数的显著性检验:通过假设检验,判断回归系数是否显著不为零,进一步判断自变量对因变量的影响是否显著。
2. 多重共线性检验:通过计算自变量之间的相关系数矩阵,判断是否存在多重共线性问题。
若存在多重共线性,需要进行相应处理,如剔除相关性较高的自变量。
3. 残差分析:通过观察残差的分布情况,判断模型是否符合线性回归的基本假设,如误差项的独立性、正态性和方差齐性等。
4. 模型诊断:通过观察残差图、QQ图、杠杆值等,判断是否存在异常值、离群点或高杠杆观测点,并采取相应措施进行修正。
5. 模型优化:根据模型评估结果,对模型进行优化,如引入交互项、非线性变换等,以提高模型的拟合效果和预测准确性。
题目什么是线性回归模型请简要解释OLS估计方法

题目什么是线性回归模型请简要解释OLS估计方法线性回归模型是一种常用的统计分析方法,用于探索自变量与因变量之间的线性关系。
它基于一组自变量的观测数据,通过拟合一个线性方程来预测因变量的值。
OLS(Ordinary Least Squares)估计方法是线性回归模型中最常用的参数估计方法之一。
该方法通过最小化残差平方和来估计回归模型中的系数。
线性回归模型的基本形式可以表示为:y = β0 + β1x1 + β2x2 + ... + βpxp + ε其中,y是因变量,x1、x2、...、xp是自变量,β0、β1、β2、...、βp是模型的回归系数,ε是随机误差项。
OLS估计方法的目标是选择使得残差平方和最小化的系数值,具体步骤如下:1. 数据准备:收集自变量和因变量的观测数据,并对数据进行清洗和转换。
2. 模型拟合:根据观测数据,使用OLS方法拟合线性回归模型。
在拟合过程中,计算残差(观测值与模型预测值之间的差异)。
3. 残差分析:对残差进行统计学分析,以评估模型的拟合程度。
常见的分析方法包括残差图和残差分布检验。
4. 参数估计:使用OLS估计方法,通过最小化残差平方和,确定回归系数的估计值。
OLS估计方法可以通过最小二乘法求解,但也涉及复杂的矩阵计算。
5. 统计推断:对回归系数进行统计学检验,评估自变量与因变量之间是否存在显著线性关系。
常见的检验包括t检验和F检验。
6. 模型评估:利用一些指标来评估模型的拟合程度和预测能力,如R方值、调整R方值、残差标准误、置信区间等。
7. 模型应用:利用估计得到的线性回归模型,进行因变量的预测或假设检验等应用。
总结起来,线性回归模型是一种用于探索自变量与因变量之间线性关系的统计分析方法。
OLS估计方法是一种常用的线性回归参数估计方法,通过最小化残差平方和来确定回归系数的估计值。
该方法在模型拟合、残差分析、参数估计、统计推断、模型评估和模型应用等方面都有明确的步骤和方法。
简单线性回归模型

简单线性回归模型线性回归是统计学中一个常见的分析方法,用于建立自变量与因变量之间的关系模型。
简单线性回归模型假设自变量与因变量之间存在线性关系,可以通过最小二乘法对该关系进行拟合。
本文将介绍简单线性回归模型及其应用。
一、模型基本形式简单线性回归模型的基本形式为:y = β0 + β1x + ε其中,y为因变量,x为自变量,β0和β1为常数项、斜率,ε为误差项。
二、模型假设在使用简单线性回归模型之前,我们需要满足以下假设:1. 线性关系假设:自变量x与因变量y之间存在线性关系。
2. 独立性假设:误差项ε与自变量x之间相互独立。
3. 同方差性假设:误差项ε具有恒定的方差。
4. 正态性假设:误差项ε符合正态分布。
三、模型参数估计为了估计模型中的参数β0和β1,我们使用最小二乘法进行求解。
最小二乘法的目标是最小化实际观测值与模型预测值之间的平方差。
四、模型拟合度评估在使用简单线性回归模型进行拟合后,我们需要评估模型的拟合度。
常用的评估指标包括:1. R方值:衡量自变量对因变量变异的解释程度,取值范围在0到1之间。
R方值越接近1,说明模型对数据的拟合程度越好。
2. 残差分析:通过观察残差分布图、残差的均值和方差等指标,来判断模型是否满足假设条件。
五、模型应用简单线性回归模型广泛应用于各个领域中,例如经济学、金融学、社会科学等。
通过建立自变量与因变量之间的线性关系,可以预测和解释因变量的变化。
六、模型局限性简单线性回归模型也存在一些局限性,例如:1. 假设限制:模型对数据的假设比较严格,需要满足线性关系、独立性、同方差性和正态性等假设条件。
2. 数据限制:模型对数据的需求比较高,需要保证数据质量和样本的代表性。
3. 线性拟合局限:模型只能拟合线性关系,无法处理非线性关系的数据。
简单线性回归模型是一种简单且常用的统计方法,可以用于探索变量之间的关系,并进行预测和解释。
然而,在使用模型时需要注意其假设条件,并进行适当的拟合度评估。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
相关系数:
不相关 负相关 -1XY1
有因果关系 回归分析 无因果关系 相关分析
6-4
统计依 赖关系
非线性 相关
正相关 不相关 负相关
相关、回归与因果关系
不线性相关并不意味着不相关。 有相关关系并不意味着一定有因果关系。 回归分析/相关分析研究一个变量对另一个(些)
变量的统计依赖关系,但它们并不意味着一定有 因果关系。 相关分析对称地对待任何(两个)变量,两个变 量都被看作是随机的。回归分析对变量的处理方 法存在不对称性,即区分应变量(被解释变量) 和自变量(解释变量):前者是随机变量,后者 不是。
6-5
2. 回归分析的基本概念
回归分析(regression analysis)是研 究一个变量关于另一个(些)变量的具 体依赖关系的计算方法和理论。
其目的在于通过后者的已知或设定值,去
估计和(或)预测前者的(总体)均值。
被解释变量(Explained
Variable)或应 (因)变量(Dependent Variable)。 Variable)或自 变量(Independent Variable)。
6-6
解释变量(Explanatory
第二部分 线性回归 模型
Chp 6 线性回归的基本思想 ——双变量模型
主要内容
一、回归的含义 二、总体回归函数(PRF) 三、随机误差项 四、样本回归函数(SRF) 五、“线性”回归的含义 六、参数估计:普通最小二乘法 七、案例分析
6-2
一、回归的含义
1. 变量间的关系 (1)确定性关系或函数关系:研究的是确 定现象非随机变量间的关系。
合计 平均
2420 605
5775 825
11495 1045
21450 2145
21285
15510 2365 6-12 2585
由于不确定因素的影响,对同一收入水平X, 不同家庭的消费支出不完全相同;
但由于调查的完备性,给定收入水平X的消 费支出Y的分布是确定的,即以X的给定值 为条件的Y的条件分布(Conditional distribution)是已知的,例如: P(Y=561|X=800)=1/4。
圆面积=f(,r)= r2 (2)统计依赖或相关关系:研究的是非确定现 象随机变量间的关系。 农作物产量=f (气温,降雨量,阳光,施肥量)
6-3
对变量间统计依赖关系的考察主要是通 过相关分析(correlation analysis)或回归 分析(regression analysis)来完成的。
33
32 30 31 25 31.9
30
28 32 32 34 33
32
30 31 33 31
6-9 33.6
每周博彩支出和个人可支配收入散点图
50 45 40 35 30 25 20 15 10 5 0 125 175 225 275 325 375
6-10
例6.1:一个假想的社区有100户家庭组成,要 研究该社区每月家庭消费支出Y与每月家庭可 支配收入X的关系。 即如果知道了家庭的月收 入,能否预测该社区家庭的平均月消费支出水 平。
变量所有可能出现的对应值的平均值。
6-8
例:每周博彩支出和个人可支配收入
个人可 支配收入 (美元)
每周博彩支出
150 28 27 25 33 23 175 33 31 29 27 24 200 35 31 30 28 26 225 36 34 31 29 27 250 38 36 33 30 28 275 40 37 32 30 29 300 42 39 34 31 30 325 43 35 31 30 29 350 45 39 33 30 27 375 46 40 34 31 28
为达到此目的,将该100户家庭划分为组 内收入差不多的10组,以分析每一收入组的家 庭消费支出。
6-11
某社区家庭每月收入与消费支出统计表
每月家庭可支配收入X(元) 800 561 594 627 638 每月 家庭 消费 支出Y (元) 1100 638 748 814 825 847 935 968 1400 869 913 924 979 1012 1045 1078 1122 1155 1188 1210 1700 1023 1100 1144 1155 1210 1243 1254 1298 1331 1364 1408 1430 1485 16445 1265 2000 1254 1309 1364 1397 1408 1474 1496 1496 1562 1573 1606 1650 1716 19305 1485 2300 1408 1452 1551 1595 1650 1672 1683 1716 1749 1771 1804 1870 1947 2002 23870 1705 2600 1650 1738 1749 1804 1848 1881 1925 1969 2013 2035 2101 2112 2200 25025 1925 2900 1969 1991 2046 2068 2101 2189 2233 2244 2299 2310 3200 2090 2134 2178 2266 2354 2486 2552 2585 2640 3500 2299 2321 2530 2629 2860 2871
消费者 1 2 3 4 5
6
7 8 9 10 均值
15
18 12 13 15 20.9
20
18 15 14 10 22.1
22
20 17 16 19 24.4
26
23 21 18 16 26.1
25
23 22 20 18 27.3
27
25 22 18 32 29.2
29
26 24 25 23 30.3
3. 回归分析的目的:
根据样本观察值对经济计量模型参数进行
估计,求得回归方程;
对回归方程、参数估计值进行显著性检验; 利用回归方程进行分析、评价及预测。
6-7
二、总体回归函数(PRF)
Байду номын сангаас
回归分析关心的是根据解释变量的已知或给
定值,考察被解释变量的总体均值,即当解释 变量取某个确定值时,与之统计相关的被解释