使用SPSS进行探索式因素分析的教程
用SPSS做探索性因子分析
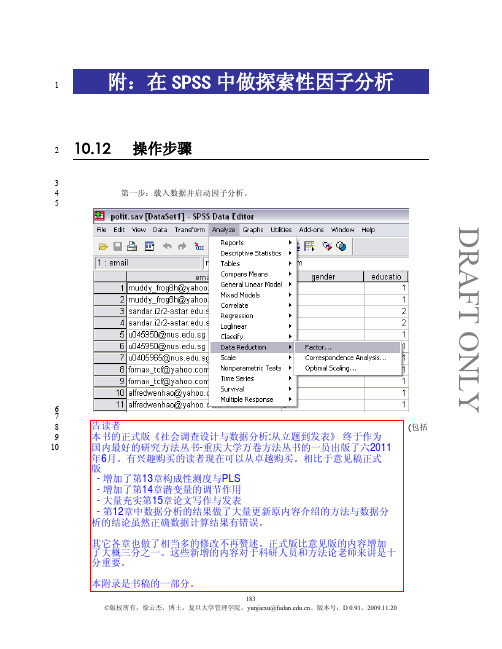
DRAFT ONLY附:在SPSS 中做探索性因子分析110.12操作步骤23 第一步:载入数据并启动因子分析。
4567 第二步:选择因子所对应的测度项。
在这个研究中,我们选择对应于七个变量(包括8 自变量、因变量、与控制变量) 的测度项。
910告读者丗本书的正式版丆《社会调查设计与数据分析:从立题到发表》丆 终于作为国内最好的研究方法丛书-重庆大学万卷方法丛书的一员出版了乮六2011年6月乯。
有兴趣购买的读者现在可以从卓越购买。
相比于意见稿丆正式版丗- 增加了第13章丆构成性测度与PLS•C - 增加了第14章丆潜变量的调节作用 - 大量充实第15章丆论文写作与发表- 第12章中数据分析的结果做了大量更新丆原内容介绍的方法与数据分析的结论虽然正确丆数据计算结果有错误。
其它各章也做了相当多的修改丆不再赘述。
正式版比意见版的内容增加了大概三分之一。
这些新增的内容对于科研人员和方法论老师来讲是十分重要。
本附录是书稿的一部分。
DRAFT ONLY12第三步:设定因子求解办法为主成分分析法。
使用相关系数矩阵,并设定主要因子的34特征根大于1。
5678第四步:设计因子旋转方法为“Varimax”。
然后在“Factor Analysis”窗口中按“ok”开始计算。
910DRAFT ONLY1210.13主成分分析的结果34 对应于27个测度项,主成分分析法一共产生了27个因子。
这是可以产生的因子个数5 的上限。
“Total ”列报告了每一个因子所对应的特征值。
“% of Variance ”表示这个特征6 值在所有特征值和中的比例。
“Extraction Sums of Squared Loadings ”这一列反映了特征根7 大于1的因子。
在这个例子中,我们顺利地得到了7个因子。
相应地,在用碎石坡法对因8 子进行目测时,我们得到的结果是一致的。
请读者参看本章中的相应图例。
值得一提的9 是,第八个因子的特征根为0.967,十分接近1。
使用SPSS进行探索式因素分析的教程

第4章 探索式因素分析在社会及行为科学研究中,研究者经常会搜集实证性量化资料來做验证,而要证明这些资料可靠性及正确性,则必须依靠测量或调查工具信度或效度(杨国枢等,2002b )。
一份好量表应该要能够将欲研究主题构念(Construct ,它是心理学上一种理论构想或特质,无法直接观测得到)清楚且正确呈现出来,而且还需具有「效度」,即能真正衡量到我们欲量测特性,此外还有「信度」,即该量表所衡量结果应具有一致性、稳定性,因此为达成「良好之衡量」目标,必须有以下两个步骤:第一个步骤是针对量表题项作项目分析,以判定各项目区别效果好坏;第二步骤则是建立量表信度及效度。
量表之项目分析、信度检验已于第2、3章有所说明,本章将探讨量表之效度问题。
4-1 效度效度即为正确性,也就是测量工具确实能测出其所欲测量特质或功能之程度。
一般研究中最常使用「内容效度」(Content Validity )及「建构效度」(Construct Validity )来检视该份研究之效度。
所谓「内容效度」,是指该衡量工具能足够涵盖主题程度,此程度可从量表内容代表性或取样适切性来加以评估。
若测量内容涵盖所有研究计划所要探讨架构及内容,就可说是具有优良内容效度。
在一般论文中,常使用如下描述来「交代」内容效度:而所谓「建构效度」系指测量工具内容,即各问项是否能够测量到理论上构念或特质程度。
建构效度包含收敛效度(Convergent Validity )及区别效度(Discriminant Validity ),收敛效度主要测试以一个变量(构念)发展出多项问项,最后是否会收敛于一个因素中(同一构念不同题目相关性很高);而区别效度为判别问项可以及其它构念之问项区别程度(不同构念不同题目相关性很低)。
衡量收敛效度统计方式可使用探索式因素分析法(Exploratory factor analysis),简称因素分析。
进行因素分析时,若发现各构念衡量项目皆可收敛于同一个共同因素之下,则表示该量表收敛效度是可被接受。
使用SPSS进行数据探索性分析的步骤

使用SPSS进行数据探索性分析的步骤数据探索性分析是研究者在进行数据分析之前的一项重要工作。
它可以帮助研究者了解数据的基本特征、发现数据中的规律和异常情况,并为后续的数据分析提供参考。
SPSS是一款常用的统计软件,它提供了丰富的功能和工具,方便研究者进行数据探索性分析。
下面将介绍使用SPSS进行数据探索性分析的步骤。
1. 导入数据在SPSS中,首先需要将待分析的数据导入软件中。
可以通过点击菜单栏中的"文件"-"打开"来选择数据文件,或者直接将数据文件拖入SPSS的工作区。
导入数据后,SPSS会自动将数据显示在数据视图中。
2. 查看数据在导入数据后,可以通过查看数据视图来了解数据的整体情况。
数据视图显示了数据表格,每一列代表一个变量,每一行代表一个观察值。
可以通过滚动条或者快捷键来浏览数据。
同时,还可以通过点击菜单栏中的"数据"-"描述统计"-"频数"来查看每个变量的频数分布情况。
3. 处理缺失值在数据分析过程中,经常会遇到缺失值的情况。
缺失值可能对后续的数据分析产生影响,因此需要对缺失值进行处理。
SPSS提供了多种处理缺失值的方法,如删除含有缺失值的观察值、替换缺失值等。
可以通过点击菜单栏中的"数据"-"选择"-"筛选"来选择处理缺失值的方法。
4. 描述性统计分析描述性统计分析是数据探索性分析的重要部分,它可以帮助研究者了解数据的基本特征。
在SPSS中,可以通过点击菜单栏中的"分析"-"描述统计"-"统计量"来进行描述性统计分析。
在弹出的对话框中,选择需要进行描述性统计分析的变量,并选择需要计算的统计量,如均值、标准差、最小值、最大值等。
点击确定后,SPSS会自动计算并显示结果。
(整理)spss因素分析教程.

二、利用SPSS对量表进行因素分析【例6-9】现要对远程学习者对教育技术资源的了解和使用情况进行了解,设计一个里克特量表,如表6-27所示。
将该量表发放给20人回答,假设回收后的原始数据如表6-28所示。
操作步骤:⒈录入数据定义变量“A1”、“A2”、“A3”、“A5”、“A6”、“A7”、“A8”、“A9”、“A10”,并按照表输入数据,如图6-33所示。
⒉因素分析(1)选择“AnalyzeData ReductionFactor…”命令,弹出“Factor Analyze”对话框,将变量“A1”到“A10”选入“Variables”框中,如图6-34所示。
(2)设置描述性统计量单击图6-34对话框中的“Descriptives…”按钮,弹出“Factor Analyze:Desc riptives”(因素分析:描述性统计量)对话框,如图6-35所示。
①“Statistics”(统计量)对话框A “Univariate descriptives”(单变量描述性统计量):显示每一题项的平均数、标准差。
B “Initial solution”(未转轴之统计量):显示因素分析未转轴前之共同性、特征值、变异数百分比及累积百分比。
②“Correlation Matric”(相关矩阵)选项框A “Coefficients”(系数):显示题项的相关矩阵B “Significance levels”(显著水准):求出前述相关矩阵地显著水准。
C “Determinant”(行列式):求出前述相关矩阵地行列式值。
D “KMO and Bartlett’s test of sphericity”(KMO与Bartlett的球形检定):显示KMO抽样适当性参数与Bartlett’s的球形检定。
E “Inverse”(倒数模式):求出相关矩阵的反矩阵。
F “Reproduced”(重制的):显示重制相关矩阵,上三角形矩阵代表残差值;而主对角线及下三角形代表相关系数。
SPSS探索性因子分析的过程

SPSS探索性因子分析的过程探索性因子分析(Exploratory Factor Analysis,EFA)是一种统计方法,旨在帮助研究者理解和解释大量变量之间的关系。
它可以用于数据降维、信度分析和测量模型构建等多种研究目的。
以下是SPSS中进行探索性因子分析的详细步骤:1.数据准备:-打开SPSS软件,并导入数据文件。
-确保数据变量符合连续性或有序性测量标准。
如果存在分类变量,需要进行变量转换,如使用哑变量编码。
2.确定分析目的和因变量:-确定研究目的,明确是否要进行因子分析以及预期得到的结果。
-选择用于分析的变量,这些变量应当在理论上与研究目的相关,并且在实践中已经得到应用。
3.进行初始的探索性因子分析:-在「分析」菜单中选择「数据降维」,然后选择「因子」。
-从左侧的变量列表中选择需要进行因子分析的变量,将其添加到右侧的「因子分析」框中。
-在「提取」选项卡中,选择提取的因子数量。
通常,可以通过解释方差方法选择大于1的特征根值,或者根据理论确定因子数量。
-点击「列表」按钮,查看提取出的因子信息,包括特征根值、解释方差和因子载荷。
根据因子载荷大小判断变量与因子之间的关系。
4.进行旋转:-在「提取」选项卡中,点击「旋转」按钮。
- 在旋转选项卡中,选择旋转方法。
常用的旋转方法包括方差最大化(Varimax)、直角旋转(Orthogonal rotation)和斜交旋转(Oblique rotation)。
-点击「列表」按钮,查看旋转后的因子载荷。
选择合适的旋转结果,以使因子载荷更加清晰和解释性更好。
5.进行因子得分估计:-在主对话框中,点击「因子得分」选项卡。
-选择要估计的因子得分的方法。
可选择「最大似然估计」或「预测指标法」。
-点击「存储因子得分」复选框,以将因子得分保存到数据文件中。
-点击「OK」按钮进行分析。
6.结果解读:-分析结果包括提取的因子信息、旋转后的因子载荷、因子得分和信度分析等。
-根据因子载荷和理论知识,解释每个因子代表的潜在构念。
SPSS探索性因素分析之具体步骤探讨

SPSS探索性因素分析之具体步骤探讨探索性因素分析之具体步骤探讨文/哈工程大学应用心理学系曹国兴这主要针对的是预试问卷而言,也就是说在初试问卷经过了语义分析,专家讨论论证之后最终得出的问卷。
以下的经验是根据我编制职业承诺问卷的基础上总结而来,错误之处希望同行指教。
首先要说的是关于样本数量的问题。
按照统计学标准而言,一般样本数应为题目数的5-10倍。
由于我的题目为50,故样本至少为250个。
前期我计划发放样本数为6倍也就是300份,由于样本流失及废卷的原因,最终回收到有效问卷为256份,有效率为85.33%。
当然这是无法避免的。
下面我主要谈一下进行探索性分析的具体步骤:第一:比较明确的一步就是做一下关于各个项目的鉴别度(区分度)的分析。
在这个条件下会删除一部分不适合的题目。
删除程序为SPSS下的Analyze→Scale→ReliabilityAnalysis。
比较保险的的是从比较小的鉴别度一步一步删除,每次删一些较低的题目就看一下科隆巴赫系数的大小,直到满意为止。
当然也可以直接将低于0.3的题目删除。
注意的是删除的应为那些删除后科隆巴赫系数值提高的题目,如果删除后科隆巴赫系数值降低,这就需要重新考虑了。
结合语义分析取舍。
第二:在这种情况下一般而言,进行问卷设计之前所有的题目究竟是属于哪一个维度或者有几个维度应该有一定的假设,此时应该如下操作:(1)首先是反向题目的更改。
这方面需要注意的就是每次关闭文件的时候注意不要保存或者你将反向题目更改后的文件保存下来,一定要注明,因为如果你忘记了,就会混淆到底反向题目有没有修改过。
(2)也就是重点阶段。
顾名思义探索性因子分析就好比你是一个探险家在探索一块未知的领域,你不知道去哪一个方向才是正确的,也许你走了很长的路却与你所期望的目的地相反。
为避免在进行探索性因子分析的时候做无用功,我采用了如下的方法:在最大变异法和极大相等法两种正交旋转下分别对题目进行讨论。
利用SPSS进行因素分析

二、应用SPSS进行量表分析的步骤
问 题 从未 使用 1 很少 使用 2 有时 使用 3 经常 使用 4 总是 使用 5
题 项
A1
A2 A3 A4 A5 A6 A7
电脑
录音磁带 录像带 网上资料 校园网或因特网 电子邮件 电子讨论网
A8
A9
CAI课件
视频会议
A10 视听会议
题目 编号 01 02 03
特征值----是每个变量在某一共同因素之因素负荷量的平 方总和(一直行所有因素负荷量的平方和)。 如F1的特征值 G=(0.896)平方+(0.802)平方 +(0.516)平方+(0.841)平方 +(0.833)平方=3.113
特征值的总和等于实测变量的总数 方差贡献率----指公共因子对实测变量的贡献, 又称变异量 方差贡献率=特征值G/实测变量数p, 如F1的贡献率为3.113/5=62.26%
因子分析案例
公因子 F1 Z1=代数1 0.896 公因子 F2 0.341 共同度 hi 0.919 特殊因子
δi
0.081
Z2=代数2
Z3=几何 Z4=三角
0.802
0.516 0.841
0.496
0.855 0.444
0.889
0.997 0.904
0.111
0.003 0.096
Z56 .474 .401 .495 .605 .633
Extrac ti on Method: Princ ipal Component Anal ysis . a. 3 components extracted.
Extraction Method: Principal Component Analysis.
SPSS探索性因子分析的过程

SPSS探索性因子分析的过程SPSS探索性因子分析(Exploratory Factor Analysis,EFA)是一种统计方法,旨在通过将大量的观测变量分解为较小的、相互关联的潜在因子,来帮助研究者理解潜在的数据结构和模式。
本文将介绍SPSS中进行探索性因子分析的过程,包括数据准备、模型设定、因子提取和解释因子。
一、数据准备在进行探索性因子分析之前,需要确保数据准备工作已经完成。
这包括了数据的清洗、缺失值的处理和变量的选择等。
清洗数据:删除不适用的或异常的数据,确保数据的一致性和可靠性。
处理缺失值:根据缺失数据的性质和缺失的模式,选择适当的处理方法,如删除带有缺失值的观测、替换缺失值(如均值填充)等。
选择变量:根据研究目的和理论基础,选择合适的变量进行因子分析。
二、模型设定在SPSS中,打开要进行因子分析的数据集,选择"数据"菜单下的"概要统计",然后选择"因子"。
选择因子旋转方法:因子旋转是为了使提取出的因子更易解释和理解。
常用的旋转方法有正交旋转(如Varimax旋转)和斜交旋转(如Oblimin旋转)等。
在进行因子旋转时,可以根据理论和实际情况选择适当的旋转方法。
三、因子提取在SPSS的因子分析过程中,需要进行因子提取来确定潜在因子的数量。
选择因子数:在进行因子提取时,需要预设潜在因子的数量。
根据Kaiser准则和Scree图等指标,确定因子的个数。
Kaiser准则建议保留特征值大于1的因子,Scree图则可通过图形分析法确定因子数。
执行因子分析:根据前面设定的方法和参数,执行因子分析。
根据提取出的因子载荷矩阵进行因子解释。
因子载荷矩阵反映了每个观测变量与每个因子之间的关系。
载荷值表示观测变量与因子之间的相关性,值越大表示相关性越大。
四、解释因子根据因子载荷矩阵来解释因子。
通过观察载荷矩阵,找出与每个因子高相关的观测变量(载荷值绝对值大于0.4),根据这些观测变量来解释因子的含义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
使用SPSS进行探索式因素分析的教程
探索性因素分析是一种统计方法,用于确定一组变量之间的潜在结构。
SPSS是一种常用于数据分析的软件工具,它提供了强大的因素分析功能。
以下是一个使用SPSS进行探索性因素分析的简单教程,该教程可以
帮助您了解如何使用SPSS来执行因素分析并对结果进行解释。
步骤1:导入数据
步骤2:准备数据
确保您的数据符合因素分析的前提条件。
确定您要进行因素分析的变
量是否具有线性关系,并进行必要的数据转换(例如,对数转换)以满足
这个条件。
步骤3:执行因素分析
在SPSS的“分析”菜单下,选择“数据准备”和“因子”。
在弹出
的对话框中,选择您要进行因素分析的变量并将其移动到“因子”框中。
选择“萃取方法”(如主成分分析或最大似然估计)并指定要提取的因素
的数量。
您还可以选择执行因子旋转以获得更简单和解释性更强的因子结构。
步骤4:解读结果
SPSS将生成一个因素分析的输出报告,其中包含多个表格和图形。
以下是一些常见的解读步骤:
-总体解释:观察“总体解释”表,了解因子数量和提取方法的解释
力度。
查看“因素”的特征值,了解提取的因子解释的总方差比例。
-因子负荷:查看“因子负荷”表,该表显示了原始变量与提取的因
子之间的相关性。
较高的因子负荷表示原始变量与特定因子之间的较强关联。
-因子旋转:如果您选择了因子旋转,则查看“旋转因子载荷矩阵”表,该表显示了旋转后的因子负荷。
查看这些旋转后的因子负荷以确定是
否存在更简单的因子结构。
-因子得分:根据选定的因子分析方法,可以生成每个观测值的因子
得分。
这些得分表示了每个观测值在每个因子上的得分情况,可以用于后
续的分析和解释。
步骤5:解释因子
根据因子负荷和因子名称,解释每个因子代表的潜在结构。
结合领域
知识和因子负荷,您可以确定每个因子是否与特定概念或潜在维度相关联。
步骤6:结果报告
根据您的研究目的和需要,将因子分析的结果写入报告中。
确保清楚
地描述因子数量、命名以及每个因子代表的结构或概念。
总结:
本教程提供了使用SPSS进行探索性因子分析的简单指南。
从数据导
入到解读结果,包括因子负荷和因子旋转等内容。
探索性因子分析是一种
有用的统计工具,可以帮助研究者发现变量之间的潜在结构,并为进一步
的数据解释和分析提供有用的信息。