判别分析案例(鸢尾花)
基于欧式距离的判别分析

基于欧式距离的判别分析作者:唐宇政来源:《现代商贸工业》2019年第09期摘要:分类判别问题在生活中是一个有着重要应用需求的问题。
例如根据患者肺部阴影大小,是否低烧以及其它理化指标来判断是否为肺结核患者,或是根据邮件的内容或者发件地址来判断其是否属于垃圾邮件。
在现实生活中,我们希望能够准确快速的解决这一类问题,往往需要利用历史数据来建立合理的分类器。
因此重点介绍一种常见的基于距离的判别分类方法——欧氏距离判别法。
首先在第二部分详细介绍这种分类方法以及将其和另外一种常见的基于马氏距离的判别分类法进行比较。
在第三部分,我们将进行实例分析,基于花瓣长度和花瓣宽度利用欧式距离判别法对鸢尾花进行分类。
关键词:分类问题;欧式距离;马氏距离中图分类号:TB 文献标识码:Adoi:10.19311/ki.1672-3198.2019.09.0921 背景分类判别是指根据事物的不同点加以区分辨别,确定事物所属的类别,使具有更多相似点的事物归入一类,使之在大量事物中可以根据一定规律快速鉴别各个事物的所属种类。
例如国家电网在对居民进行供电时,就可以根据以往的用电量数据对居民的用电情况进行划分,对用电量大的居民相应地收取更多的费用,从而达到促进节约用电的目的。
在解决此类问题的过程中需要准确判别个体样本所属的类别,即应该划分的组别。
本文中将介绍的是如何通过数学建模来快速准确完成这个分组判别的过程。
本文中,我们将使用鸢尾花数据集,对150个鸢尾花数据样本进行分类判别,确定样本属于三种鸢尾花中的哪一种,来实例说明欧式距离判别法在现实生活中的可行性。
2 分类方法判别分析法,是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。
常见的判别分析法主要包括基于距离的判别、Fisher判别、Bayes 判别。
本文主要研究对象是通俗易懂、应用范围广泛的基于距离的判别分析法。
2.1 基于距离的判别分析距离判别的基本思想是将距离越近的样本分为一类,距离越大的样本分为不同类。
对鸢尾花kmeans算法的总结

鸢尾花是一种常见的植物,具有多种品种和花色。
鸢尾花的种类繁多,因此如何有效地对鸢尾花进行分类成为一个研究热点。
K均值(k-means)算法是一种常用的聚类分析方法,对鸢尾花进行分类时,k-means算法可以发挥重要作用。
让我们来了解一下k-means算法的基本原理。
K均值算法通过迭代将n个数据点划分到k个集群中,使得同一集群内的点彼此距离的平方和最小。
其中,k是用户指定的聚类数目,而迭代的过程是根据每个数据点与各个中心的距离来不断更新中心点的位置,直至满足停止条件。
接下来,我们将对鸢尾花k-means算法进行总结和回顾性的探讨,以便更全面、深刻地理解这一主题。
在应用k-means算法对鸢尾花进行分类时,我们首先需要收集样本数据,包括鸢尾花的花瓣长度、花瓣宽度、花萼长度和花萼宽度等特征。
通过调用相应的数学库或算法工具,可以将这些样本数据输入到k-means算法中进行聚类分析。
当我们应用k-means算法对鸢尾花进行分类时,关键的一步是确定合适的聚类数目k。
这需要利用一些评价指标,如肘部法则(elbow method)或轮廓系数(silhouette score)来帮助确定最佳的k值。
通过数据点与各个中心的距离计算,不断迭代更新中心点的位置,最终将鸢尾花样本数据划分到不同的集群中。
对于鸢尾花k-means算法的应用而言,我们需要注意的一点是,选择合适的特征和合理地进行数据预处理是非常重要的。
另外,对聚类结果进行可视化分析也是必不可少的,可以通过绘制散点图或热力图来直观地展示聚类效果。
在我个人看来,鸢尾花k-means算法的应用不仅仅是简单的数据分析,更重要的是它可以帮助我们理解聚类分析的基本原理并掌握如何利用算法工具解决实际问题。
通过对鸢尾花k-means算法的总结和回顾性讨论,我对这一主题有了更深入的理解,也更加意识到了数据分析在实际应用中的重要性。
总结而言,通过本文的探讨,我们对鸢尾花k-means算法的原理和应用有了更全面、深刻和灵活的理解。
鸢尾花数学建模论文.

大连海事大学2014年数学建模竞赛丙组论文鸢尾花的分类研究姓名学号学院专业班级仇实2220141486 物理系应用物理学2014-1 郭杨喆2220143245 物理系应用物理学2014-1 张逸凡2220143115 物理系应用物理学2014-12014年11月23日摘要加拿大加斯帕半岛上生长着三类不同的鸢尾属的花朵,他们分别是Setosa(刚毛)、Versicolor(变色)和Virginica(弗吉尼亚)。
植物学家从三类鸢尾花中各选15株,分别测量了它们的花瓣长(Pl)、花瓣宽(Pw)、花萼长(Sl)、花萼宽(Sw)。
通过分析数据设计用于鸢尾花识别的数学算法,识别这15株花朵的类属。
本论文分析如何通过花瓣长、花瓣宽、花萼长、花萼宽建立数学模型对测试样本进行准确分类。
经过对数据的分析以及查阅资料,本题可以通过判别分析的Fisher判别模型进行计算分类,由此我们想到了利用SPSS软件对数据进行处理,最终得到Fisher线性判别函数成功地解决了对鸢尾花的分类问题。
关键词:判别分析 Fisher判别模型 SPSS软件 Fisher线性判别函数目录摘要 (1)一、问题重述 (3)二、问题分析 (3)三、建立费歇尔模型 (3)四、检验 (7)五、测试样本的分类结果 (7)六、参考文献 (8)七、附录(SPSS的操作过程) (8)一、问题重述本题是根据观测样本中刚毛、变色、弗吉尼亚的四个度量花瓣长(Pl)、花瓣宽(Pw)、花萼长(Sl)、花萼宽(Sw)对测试样本的鸢尾花进行分类。
二、问题分析根据这个问题,我们可以按照一定的判别准则,建立一个或多个判别函数,用观测样本数据确定判别函数中的待定系数,并计算判别指标,据此可以确定测试样本中的某一样本属于何类。
这类问题属于判别分析问题。
三、建立费歇尔模型1.数据分析在建立模型之前进行一些数据处理。
包括:平均向量、协方差、先验概率、错分成本,这样费歇尔判别函数的期望错判率能达到最小化。
2.判别分析
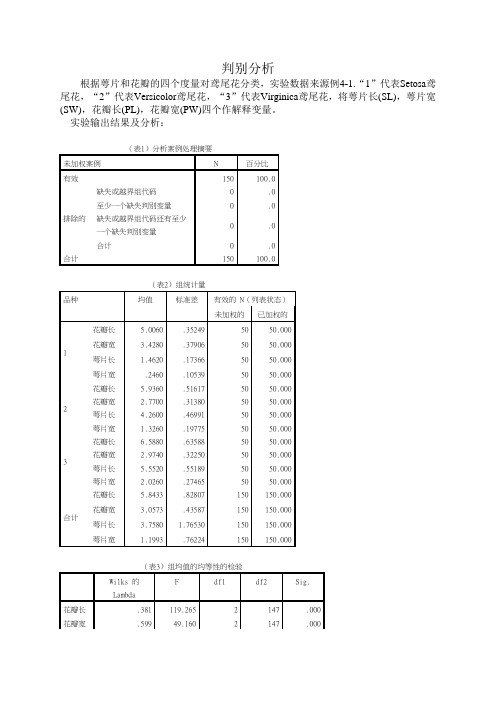
判别分析根据萼片和花瓣的四个度量对鸢尾花分类,实验数据来源例4-1.“1”代表Setosa 鸢尾花,“2”代表Versicolor 鸢尾花,“3”代表Virginica 鸢尾花,将萼片长(SL),萼片宽(SW),花瓣长(PL),花瓣宽(PW)四个作解释变量。
实验输出结果及分析:(表1)分析案例处理摘要未加权案例 N 百分比 有效150 100.0排除的 缺失或越界组代码 0 .0 至少一个缺失判别变量0 .0 缺失或越界组代码还有至少一个缺失判别变量 0 .0 合计0 .0 合计150100.0(表2)组统计量品种均值标准差有效的 N (列表状态) 未加权的已加权的 1花瓣长5.0060 .35249 50 50.000 花瓣宽3.4280.379065050.000萼片长 1.4620 .17366 50 50.000 萼片宽 .2460 .10539 50 50.000 2花瓣长5.9360 .51617 50 50.000 花瓣宽 2.7700 .31380 50 50.000 萼片长 4.2600 .46991 50 50.000 萼片宽 1.3260 .19775 50 50.000 3花瓣长6.5880 .63588 50 50.000 花瓣宽 2.9740 .32250 50 50.000 萼片长 5.5520 .55189 50 50.000 萼片宽 2.0260 .27465 50 50.000 合计花瓣长 5.8433 .82807 150 150.000 花瓣宽3.0573.43587150150.000萼片长 3.7580 1.76530 150 150.000 萼片宽1.1993.76224150150.000表1反映的是有效样本量及变量缺失的情况。
表 2是各组变量的描述统计分析。
表3是对各组均值是否相等的检验。
由表3 可以看出,在0.01的显著水平上,我们拒绝变量萼片长,萼片宽,花瓣长和花瓣宽在三组的均值相等的假设,即认为这四个变量在三组的均值是有显著差异的。
人工智能基础与应用-物以类聚发现新簇群-人工智能案例探究鸢尾花品种

授课人:目录•提出问题•解决方案01•预备知识02•任务1——确定鸢尾花最佳的品种数k值03•任务2——绘制鸢尾花聚类后的结果散点图0405随着数据收集和数据存储技术的不断进步,我们可以迅速积累海量数据,然而,如何提取有用信息和甄别不同数据种群对普通人来说存在不小的挑战。
幸运的是,现在借助一些数据挖掘工具可以较为轻松地完成一些预测任务,例如,预测新物种、探究新信息种类是聚类算法最经典的应用案例。
本案例是基于一群鸢尾花(如下图所示)的数据集(无类别标签),根据花的特征探究将这些鸢尾花分为几个品种是比较合适的。
各式各样的鸢尾花如果你是一名植物学家,这个问题对于你来说是轻而易举的。
但在很多情况下,数据的主人或使用者并不具备本领域丰富的专业知识,那能否可以利用一种人工智能技术,让机器来帮助人类发现新的信息呢?为找到一种相对最佳的鸢尾花品种数k,•首先尽可能获得关于鸢尾花的特征知识,也许它能引导我们找到品种k的有效初值,因为花的特征反映了花的独特之处和一些重要信息,具有重要的参考价值;•然后,选用k-means算法对鸢尾花数据集进行聚类,从性能指标数据和样本可视化分布方面对聚类效果进行评价,•最后,在对比不同k值聚类效果的前提下,确定鸢尾花最佳的品种数量。
本案例的解决方案如下图所示:解决方案1.鸢尾花形态特征猜测:从鸢尾花的形态结构来看,也许花瓣能更好地帮助我们分辨鸢尾花的种类一种鸢尾花植物2.数据降维在衡量采用什么方法来分析数据之前,最好能对数据的全貌有一个可视化的了解,能从中发现一些内在规律或启示,以便能更好地指导我们选择相对合理的方法来解决问题。
我们通常只在二维或三维的空间可视化数据,但原始数据的实际维度可能是四维甚至更多,所有要采用数据降维的方法将原始数据的维度降为二维或三维,以便进行可视化来直观了解数据的分布。
除此之外,降维还可以提高计算、提高模型拟合度等好处。
如何保证原高维空间里的数据关系,经降维后仍然在低维空间保持不变或者近似呢?【引例5-1】降维鸢尾花数据集iris,绘制样本点图。
sklearn iris 案例

sklearn iris 案例Scikit-learn Iris 数据集:机器学习中的经典案例研究Scikit-learn Iris 数据集是一个经典的机器学习数据集,它被广泛用于分类任务的教学和评估。
该数据集包含 150 个鸢尾花样本,属于三个不同的物种:山鸢尾、变色鸢尾和维吉尼亚鸢尾。
数据探索数据集包含以下特征:萼片长度 (sepal length)萼片宽度 (sepal width)花瓣长度 (petal length)花瓣宽度 (petal width)这些特征描述了鸢尾花的物理特性,可用于区分不同的物种。
数据可视化为了可视化数据并理解不同物种之间的关系,我们可以使用散点图或平行坐标图。
这些可视化工具有助于识别不同特征之间的模式和相关性。
数据预处理在将数据用于机器学习模型之前,需要进行一些预处理步骤。
这些步骤包括:标准化:对特征进行缩放,使它们具有相同的量级。
划分训练集和测试集:将数据分成用于训练模型的训练集和用于评估模型的测试集。
模型训练与评估Scikit-learn 提供了各种分类算法,可用于训练鸢尾花数据集。
常见的算法包括:逻辑回归支持向量机决策树随机森林训练模型后,使用测试集评估模型的性能。
评估指标包括:准确性:模型正确预测的样本的比例。
召回率:模型正确识别目标类的样本的比例。
F1 分数:准确率和召回率的加权平均值。
基于鸢尾花数据集的应用鸢尾花数据集已被用于广泛的机器学习应用,包括:分类:将鸢尾花样本分类到正确的物种。
特征重要性:确定不同特征对分类的影响程度。
模型选择:通过比较不同模型的性能来确定最佳模型。
超参数调优:优化模型的超参数以提高性能。
总结Scikit-learn Iris 数据集是机器学习中的一个宝贵资源,它提供了以下好处:简单且易于理解:数据集相对较小,具有明确定义的特征和类别。
广泛使用:该数据集已被广泛用于教学和研究目的。
算法评估:该数据集可用于评估和比较不同的机器学习算法。
降维分析报告
降维分析报告引言降维分析是一种在机器学习和数据科学领域广泛应用的方法,它可以帮助我们从高维数据中提取主要特征,减少数据的维度,并保留尽可能多的有用信息。
在本报告中,我们将介绍降维分析的基本概念和常用算法,并通过一个具体的案例来示范如何应用降维分析。
降维分析的背景和意义在现实生活中,许多问题都涉及大量的特征或变量,这些特征可能存在冗余、噪声或不具有明确的解释。
此时,使用原始高维数据进行分析和建模将导致过拟合、维度灾难等问题。
因此,通过降维分析可以将复杂的高维数据转化为更加简洁、易理解的低维表示,帮助我们更好地理解数据并提取重要特征。
常用的降维分析方法主成分分析(PCA)主成分分析是一种常用的无监督降维算法,它通过线性变换将原始数据投影到新的正交特征空间,使得数据在新特征空间上的方差最大化。
通过计算主成分之间的协方差矩阵的特征值和特征向量,我们可以确定新特征空间的基向量,进而进行降维操作。
线性判别分析(LDA)线性判别分析是一种经典的监督降维算法,它将高维数据映射到一个低维空间中,使得不同类别的数据在该空间中的投影能够最大程度地区分开来。
和PCA相比,LDA在进行降维时考虑了类别信息,因此可能更适用于分类问题。
t分布邻域嵌入(t-SNE)t-SNE是一种非线性降维算法,它通过构建高维数据点之间的概率分布和低维数据点之间的概率分布,来保持高维数据的邻域结构。
t-SNE通常被应用于可视化高维数据,特别是在探索复杂数据集时非常有用。
降维分析的案例应用为了更好地理解降维分析的实际应用,我们以鸢尾花数据集为例进行分析。
鸢尾花数据集是一个经典的多分类问题,其中包含了四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
我们可以使用降维分析方法对鸢尾花数据集进行可视化,并探索数据的结构和分布。
首先,我们使用主成分分析(PCA)对鸢尾花数据进行降维。
通过计算主成分之间的协方差矩阵的特征值和特征向量,我们可以选择保留的主成分数量,从而实现数据降维。
关于如何分辨鸢尾花的判别分析报告
关于如何分辨鸢尾花的判别分析报告一、目的与背景:鸢尾花为法国的国花,Setose,Versicolour,Virginica 是三种有名的鸢尾花,其萼片是绚丽多彩的,和向上的花瓣不同,花萼是下垂的。
这三种鸢尾花很像,根据萼片和花瓣的四个度量对鸢尾花分类。
二、分析过程1、组间均值分析H0:组间均值是相等的H1:组间均值是不等的Tests of Equality of Group Means表1的显著性水平上,拒绝在三组均值相等的原假设,即花萼长、花萼宽、花瓣长、花瓣宽在三组的均值是有显著性差异的。
2、协方差阵分析H0:各组协方差阵是相等的H1:各组协方差阵是不相等的Test Results表2Box's M 92.993F Approx. 4.332df1 20df2 23344.026Sig. .000Tests null hypothesis of equal population covariance matrices.表2是对各总体协方差阵是否相等的统计检验。
在0.05的显著性水平下拒绝原假设,即各总体协方差阵不相等。
3、确定非标准化典型判别函数Canonical Discriminant Function Coefficients表3是非标准化的典型判别函数,表示为y1=-2.063-0.083*Sepal.Lenght-0.132*Sepal.Width+0.212*Petal.Leng th+0.239* Petal.Widthy2=-8.045+0.037*Sepal.Lenght+0.211*Sepal.Width-0.104*Petal.Len gth+0.273* Petal.Width4、函数的显著性检验Eigenvalues表4-1Wilks' Lambda差的比例和典型相关系数。
第一判别函数解释了99%的方差,第二判别函数解释了1%的方差,两个判别函数解释了全部的方差。
BP算法实例—鸢尾花的分类(Python)
BP算法实例—鸢尾花的分类(Python)⾸先了解下Iris鸢尾花数据集:Iris数据集(https:///wiki/Iris_flower_data_set)是常⽤的分类实验数据集,由Fisher,1936收集整理。
Iris也称鸢尾花卉数据集,是⼀类多重变量分析的数据集。
数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。
可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪⼀类。
iris以鸢尾花的特征作为数据来源,常⽤在分类操作中。
该数据集由3种不同类型的鸢尾花的50个样本数据构成。
其中的⼀个种类与另外两个种类是线性可分离的,后两个种类是⾮线性可分离的。
该数据集包含了4个属性:Sepal.Length(花萼长度),单位是cm;Sepal.Width(花萼宽度),单位是cm;Petal.Length(花瓣长度),单位是cm;Petal.Width(花瓣宽度),单位是cm;种类:Iris Setosa(1.⼭鸢尾)、Iris Versicolour(2.杂⾊鸢尾),以及Iris Virginica(3.维吉尼亚鸢尾)。
Python源码:1from__future__import division2import math3import random4import pandas as pd567 flowerLables = {0: 'Iris-setosa',8 1: 'Iris-versicolor',9 2: 'Iris-virginica'}1011 random.seed(0)121314# ⽣成区间[a, b)内的随机数15def rand(a, b):16return (b - a) * random.random() + a171819# ⽣成⼤⼩ I*J 的矩阵,默认零矩阵20def makeMatrix(I, J, fill=0.0):21 m = []22for i in range(I):23 m.append([fill] * J)24return m252627# 函数 sigmoid28def sigmoid(x):29return 1.0 / (1.0 + math.exp(-x))303132# 函数 sigmoid 的导数33def dsigmoid(x):34return x * (1 - x)353637class NN:38""" 三层反向传播神经⽹络 """3940def__init__(self, ni, nh, no):41# 输⼊层、隐藏层、输出层的节点(数)42 self.ni = ni + 1 # 增加⼀个偏差节点43 self.nh = nh + 144 self.no = no4546# 激活神经⽹络的所有节点(向量)47 self.ai = [1.0] * self.ni48 self.ah = [1.0] * self.nh49 self.ao = [1.0] * self.no5051# 建⽴权重(矩阵)52 self.wi = makeMatrix(self.ni, self.nh)53 self.wo = makeMatrix(self.nh, self.no)54# 设为随机值55for i in range(self.ni):56for j in range(self.nh):57 self.wi[i][j] = rand(-0.2, 0.2)58for j in range(self.nh):59for k in range(self.no):60 self.wo[j][k] = rand(-2, 2)6162def update(self, inputs):63if len(inputs) != self.ni - 1:64raise ValueError('与输⼊层节点数不符!')6566# 激活输⼊层67for i in range(self.ni - 1):68 self.ai[i] = inputs[i]6970# 激活隐藏层71for j in range(self.nh):72 sum = 0.073for i in range(self.ni):74 sum = sum + self.ai[i] * self.wi[i][j]75 self.ah[j] = sigmoid(sum)7677# 激活输出层78for k in range(self.no):79 sum = 0.080for j in range(self.nh):81 sum = sum + self.ah[j] * self.wo[j][k]82 self.ao[k] = sigmoid(sum)8384return self.ao[:]8586def backPropagate(self, targets, lr):87""" 反向传播 """8889# 计算输出层的误差90 output_deltas = [0.0] * self.no91for k in range(self.no):92 error = targets[k] - self.ao[k]93 output_deltas[k] = dsigmoid(self.ao[k]) * error 9495# 计算隐藏层的误差96 hidden_deltas = [0.0] * self.nh97for j in range(self.nh):98 error = 0.099for k in range(self.no):100 error = error + output_deltas[k] * self.wo[j][k] 101 hidden_deltas[j] = dsigmoid(self.ah[j]) * error 102103# 更新输出层权重104for j in range(self.nh):105for k in range(self.no):106 change = output_deltas[k] * self.ah[j]107 self.wo[j][k] = self.wo[j][k] + lr * change 108109# 更新输⼊层权重110for i in range(self.ni):111for j in range(self.nh):112 change = hidden_deltas[j] * self.ai[i]113 self.wi[i][j] = self.wi[i][j] + lr * change114115# 计算误差116 error = 0.0117 error += 0.5 * (targets[k] - self.ao[k]) ** 2118return error119120def test(self, patterns):121 count = 0122for p in patterns:123 target = flowerLables[(p[1].index(1))]124 result = self.update(p[0])125 index = result.index(max(result))126print(p[0], ':', target, '->', flowerLables[index]) 127 count += (target == flowerLables[index])128 accuracy = float(count / len(patterns))129print('accuracy: %-.9f' % accuracy)130131def weights(self):132print('输⼊层权重:')133for i in range(self.ni):134print(self.wi[i])135print()136print('输出层权重:')137for j in range(self.nh):138print(self.wo[j])139140def train(self, patterns, iterations=1000, lr=0.1):141# lr: 学习速率(learning rate)142for i in range(iterations):143 error = 0.0144for p in patterns:145 inputs = p[0]146 targets = p[1]147 self.update(inputs)148 error = error + self.backPropagate(targets, lr) 149if i % 100 == 0:150print('error: %-.9f' % error)151152153154def iris():155 data = []156# 读取数据157 raw = pd.read_csv('iris.csv')158 raw_data = raw.values159 raw_feature = raw_data[0:, 0:4]160for i in range(len(raw_feature)):161 ele = []162 ele.append(list(raw_feature[i]))163if raw_data[i][4] == 'Iris-setosa':164 ele.append([1, 0, 0])165elif raw_data[i][4] == 'Iris-versicolor':166 ele.append([0, 1, 0])167else:168 ele.append([0, 0, 1])169 data.append(ele)170# 随机排列数据171 random.shuffle(data)172 training = data[0:100]173 test = data[101:]174 nn = NN(4, 7, 3)175 nn.train(training, iterations=10000)176 nn.test(test)177178179if__name__ == '__main__':180 iris()。
判别分析1
2.实验内容(1)自选数据或者使用例题4-1、4-2数据完成判别分析。
(2)对判别分析结果进行分析。
(3)选定两个样本,对样本进行分类。
3.实验步骤例4-1:判别分析的一个重要应用是动植物的分类,最著名的一个例子是1936年费歇的鸢尾花数据。
鸢尾花为法国的国花,Setosa、erisolor、Virginica是三种有名的鸢尾花,其萼片是绚丽多彩的,和向上的花瓣不同,花萼是下垂的。
这三种鸢尾花很像,人们试图建立模型,根据萼片和花瓣的四个角度来对鸢尾花分类。
该数据给出150朵鸢尾花的萼片长(sepal length)、萼片宽(sepal length)、花瓣长(petal width)、花瓣宽(petal width)以及这些分别属于的种类共五个变量。
萼片和花瓣的长度为四个定量变量,而种类为分类变量。
这里三种鸢尾花各有50个观测值。
对数据进行判别分析的得到的分析结果如下:表1-1 分析觀察值處理摘要未加權的觀察值N 百分比有效150 100.0已排除遺漏或超出範圍群組代碼0 .0至少一個遺漏區別變數0 .0遺漏或超出範圍群組代碼及至0 .0少一個遺漏區別變數總計0 .0總計150 100.0输出结果表1-1分析的是各组变量的描述统计量和对各组均值是否相等的检验。
反应的是有效样本变量及变量缺失情况。
表1-2 群組統計資料被解释变量平均數標準偏差有效的 N (listwise)表1-5 測試結果Box's M 共變異等式檢定146.663F 近似值7.045df1 20df2 77566.751顯著性.000檢定相等母體共變異數矩陣的虛無假設。
输出结果1-4和表1-5是对各组协方差矩阵是否相等的Boxs’M检验。
表1-4反映协方差矩阵的秩和行列式的对数值。
由行列式值可以看出,协方差矩阵不是病态矩阵。
表1-5是对个总体协方差矩阵是否相等的统计检验。
由F值及其显著性水平,我们在0.05的显著性水平下拒绝原假设。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Wilks 的 Lambda
卡方df Sig.
函数检验Wilks 的
Lambda
1 到
2 .025 538.950 8 .000
2 .774 37.351
3 .000
标准化的典型判别式函数系数
函数
1 2
花萼长-.346 .039
花萼宽-.525 .742
花瓣长.846 -.386
花瓣宽.613 .555
-
=0.613
⨯
⨯
0.846
-
1
+
346
0.525
.0
花萼长z
花萼宽
花瓣长
⨯
z
花瓣宽
z
D⨯
+
z
=0.555
⨯
+
0.386
0.742
⨯
2
0.039
-
⨯
花萼宽
花瓣长
花瓣宽花萼长z
z
D⨯
+
z
z
结构矩阵
函数
1 2
花瓣长.726*.165
花萼宽-.121 .879*
花瓣宽.651 .718*
花萼长.221 .340*
判别变量和标准化典型判别式函数
之间的汇聚组间相关性
按函数内相关性的绝对大小排序
的变量。
*. 每个变量和任意判别式函数间
最大的绝对相关性
0.155
0.196
-
-
=0.299
.0
花瓣宽.2
526
-
063
1
z
z
花萼长z
花萼宽
⨯
z
花瓣长
⨯
D⨯
+
⨯
+
0.089
-
+
-
=0.271 978
⨯
2
.6
0.007
0.218
z
花萼长z
花萼宽
花瓣长
花瓣宽
z
z
⨯
⨯
+
D⨯
+
区域图
典则判别
函数 2
-16.0 -12.0 -8.0 -4.0 .0 4.0 8.0 12.0 16.0
+---------+---------+---------+---------+---------+---------+---------+---------+
16.0 + 13 +
I 13 I
I 13 I
I 123 I
I 123 I
I 12 23 I
12.0 + + + + 12 23 + + + +
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
8.0 + + + + 12 + 23 + + + +
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
4.0 + + + + 12 + 23 + + + +
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 * I
.0 + + + * + 12 + 23 + + +
I 12 * 23 I
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
-4.0 + + + + 12 + + 23 + + +
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
-8.0 + + + +12 + + 23 + + +
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
-12.0 + + + 12 + + 23 + +
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
I 12 23 I
-16.0 + 12 23 +
+---------+---------+---------+---------+---------+---------+---------+---------+ -16.0 -12.0 -8.0 -4.0 .0 4.0 8.0 12.0 16.0
典则判别函数 1
区域图中使用的符号
符号组标签
---- -- --------------
1 1 刚毛鸢尾花
2 2 变色鸢尾花
3 3 佛吉尼亚鸢尾花
* 表示一个组质心。