判别分析的案例分
聚类分析和判别分析实验报告

聚类分析实验报告一、实验数据2013年,在国内外形势错综复杂的情况下,我国经济实现了平稳较快发展。
全年国内生产总值568845亿元,比上年增长7.7%。
其中第三产业增加值262204亿元,增长8.3%,其在国内生产总值中的占比达到了46.1%,首次超过第二产业。
经济的快速发展也带来了就业的持续增加,年末全国就业人员76977万人,其中城镇就业人员38240万人,全年城镇新增就业1310万人。
随着我国城镇化进程的不断加快,加之农业用地量的不断衰减,工业不断的转型升级,使得劳动力就业压力的缓解需要更多的依靠服务业的发展。
(一)指标选择根据指标选择的可行性、针对性、科学性等原则,分别从服务业的发展规模、发展结构、发展效益以及发展潜力等方面选择14个指标来衡量服务业的发展水平,指标体系如表1所示:表1 服务业发展水平指标体系(二)指标数据本次实验采用的数据是我国31个省(市、自治区)2012年的数据,原数据均来自《2013中国统计年鉴》以及2013年各省(市、自治区)统计年鉴,不能直接获得的指标数据是通过对相关原始数据的换算求得。
原始数据如表2所示:表2(续)二、实验步骤本次实验是在SPSS中分别利用系统聚类法和K均值法进行聚类分析,具体步骤如下:(一)系统聚类法⒈在SPSS窗口中选择Analyze—Classify—Hierachical Cluster,调出系统聚类分析主界面,将变量X1-X14移入Variables框中。
在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
⒉点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
这里选择系统默认值,点击Continue按钮,返回主界面。
⒊点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。
贝叶斯判别分析课件

02
03
与决策树比较
贝叶斯判别分析提供了更稳定的预测 ,而决策树可能会因为数据的微小变 化而产生大的预测变化。
05
贝叶斯判别分析的案例分 析
案例一:信用卡欺诈检测
总结词
信用卡欺诈检测是一个经典的判别分析应用场景,通过贝叶斯判别分析可以有效地识别 出欺诈交易,减少经济损失。
详细描述
信用卡欺诈检测是金融领域中一个非常重要的问题。随着信用卡交易量的增长,欺诈行 为也日益猖獗,给银行和消费者带来了巨大的经济损失。贝叶斯判别分析可以通过对历 史交易数据的学习,建立分类模型,对新的交易进行分类,判断是否为欺诈行为。通过
市场细分
在市场营销中,贝叶斯判别分析 可以用于市场细分,通过消费者 行为和偏好等数据,将消费者划 分为不同的群体。
02
贝叶斯判别分析的基本概 念
先验概率与后验概率
先验概率
在贝叶斯理论中,先验概率是指在考 虑任何证据之前对某个事件或假设发 生的可能性所做的评估。它是基于过 去的经验和数据对未来事件的预测。
的类别。
它基于贝叶斯定理,通过将先验 概率、似然函数和决策函数相结 合,实现了对未知样本的分类。
贝叶斯判别分析在许多领域都有 广泛的应用,如金融、医疗、市
场营销等。
贝叶斯判别分析的原理
01
02
03
先验概率
在贝叶斯判别分析中,先 验概率是指在进行观测之 前,各类别的概率分布情 况。
似然函数
似然函数描述了观测数据 在给定某个类别下的概率 分布情况。
后验概率
后验概率是指在考虑了某些证据之后 ,对某个事件或假设发生的可能性所 做的评估。它是基于新的信息和证据 对先验概率的修正。
似然函数与贝叶斯定理
linear discriminate analysis

linear discriminate analysis【实用版】目录1.线性判别分析的定义和基本概念2.线性判别分析的应用场景和问题解决能力3.线性判别分析的具体方法和步骤4.线性判别分析的优缺点和局限性5.线性判别分析的实际应用案例正文线性判别分析(Linear Discriminant Analysis,简称 LDA)是一种常用的监督学习方法,主要用于解决分类问题。
它是一种线性分类方法,通过找到一个最佳的线性分类器,将数据分为不同的类别。
LDA 基于数据分布的假设,即不同类别的数据具有不同的分布,通过最大化类内差异和最小化类间差异来实现分类。
LDA 的应用场景非常广泛,可以用于文本分类、图像分类、生物信息学、社会科学等领域。
在这些领域中,LDA 能够有效地解决分类问题,提高分类准确率。
例如,在文本分类中,LDA 可以通过分析词汇分布,将文本分为不同的主题或类别。
线性判别分析的具体方法和步骤如下:1.收集数据并计算数据矩阵。
2.计算数据矩阵的协方差矩阵和矩阵的特征值和特征向量。
3.根据特征值和特征向量构建线性分类器。
4.使用分类器对数据进行分类。
尽管 LDA 在分类问题上表现良好,但它也存在一些优缺点和局限性。
首先,LDA 要求数据矩阵的列向量是线性无关的,这可能会限制其在某些数据集上的表现。
其次,LDA 对数据中的噪声非常敏感,噪声的存在可能会对分类结果产生不良影响。
此外,LDA 是一种基于线性分类的方法,对于非线性分类问题可能无法有效解决。
尽管如此,LDA 在实际应用中仍然具有很高的价值。
例如,在文本分类中,LDA 可以有效地识别不同主题的文本,并为用户提供个性化的推荐。
在生物信息学中,LDA 可以用于基因表达数据的分类,以识别不同类型的细胞或疾病。
在社会科学中,LDA 可以用于对调查数据进行分类,以便更好地理解受访者的需求和偏好。
总之,线性判别分析是一种强大的分类方法,可以应用于各种领域。
时间序列判别分析

时间序列判别分析时间序列判别分析(time series discriminant analysis)是一种应用于时间序列数据的统计分析方法。
它的主要目的是根据所研究的时间序列数据的不同特征,对其进行分类判别。
时间序列数据是在时间上按一定间隔采集而成的一系列数据点的集合,可以按时间顺序排列,用于分析和预测未来的趋势和模式。
时间序列判别分析可以在很多领域中被应用。
例如,在经济学中,我们可以使用时间序列判别分析来对股票市场的涨跌进行预测;在生物医学中,我们可以使用时间序列判别分析对患者的身体指标进行预测和判断;在气象学中,我们可以使用时间序列判别分析来预测气温、降雨等气象变量。
时间序列判别分析的基本思想是基于时间序列数据的统计特征,将其与不同分类标签进行对比。
通常,时间序列数据的统计特征可以包括均值、方差、自相关性、峰度、偏度等。
这些特征可以帮助我们理解时间序列数据的总体分布和变化趋势。
通过计算不同分类标签下时间序列数据的统计特征,我们可以建立判别函数来对未知类型的时间序列进行分类。
为了进行时间序列判别分析,我们首先需要选择合适的特征提取方法。
常用的特征提取方法包括统计方法、频域方法和时域方法等。
统计方法主要是计算时间序列数据的一些统计特征,如均值、标准差等。
频域方法是将时间序列数据转化为频域信号,并提取频谱特征,如功率谱密度、频率成分等。
时域方法是在时间维度上对时间序列数据进行分析,如时间序列的自相关性和偏自相关性等。
在特征提取之后,我们还需要选择合适的判别函数。
常用的判别函数包括线性判别函数和非线性判别函数等。
线性判别函数可以通过线性组合来对时间序列数据进行判别,如线性回归、线性判别分析等。
非线性判别函数则可以对非线性的时间序列数据进行判别,如支持向量机、神经网络等。
时间序列判别分析的性能可以通过交叉验证等方法进行评估。
交叉验证是一种将数据集分为训练集和测试集的方法,用训练集来训练模型,然后用测试集来评估模型的泛化能力。
第7判别分析(共38张PPT)

7.2 距离判别 ❖ 基本思想:
即:首先根据已知分类的数据,分别计算各类 的重心即各组(类)的均值,判别的准则是对任 给样品,计算它到各类重心的距离,哪个距离最
小就将它判归哪个类。
zf
yG1,如d2y,G1d2y,G2, yG2,如d2y,G2d2y,G1
待判, 如d2(y,G1)d2(y,G2)
0.87973×花瓣长-2.28382×花瓣宽 变色鸢尾花: Y=1.100772×花萼长+1.070119×花萼宽 +1.000877×花瓣长+0.197345×花瓣宽
佛吉尼亚鸢尾花: Y=0.865205×花萼长+0.746515×花萼宽
+1.646601×花瓣长+1.694931×花瓣宽
zf
五、判别新样本所属类别 742082 Z ×花萼宽 1、输入历史数据,计算 和 当总体分类不清楚时,先用聚类分析对一批样本进行分类,再用判别分析构建判别式对新样本进行判别。 007192×花萼长+0. 2、聚类分析则是对研究对象的类型未知的情况下,对其进行分类的方法。 二、判别分析的基本要求: Fisher判别的优势在于对分布、方差等都没有什么限制,应用范围较广。 例2:中小企业的破产模型 3、X3:高峰时期每三分钟国际电话的成本 二、判别分析的基本要求: 742082 Z ×花萼宽 分界图,将坐标平面划分为 87973×花瓣长-2. 所谓Fisher判别法,就是用投影的方法将k个不同总体在p维空间上的点尽可能分散,同一总体内的各样本点尽可能的集中。 ⑴ 指定分组变量及其取值范围。 所谓Fisher判别法,就是用投影的方法将k个不同总体在p维空间上的点尽可能分散,同一总体内的各样本点尽可能的集中。 3、X3:高峰时期每三分钟国际电话的成本 06327×花萼长-0. 使用该方法后,按钮“Method”将被激活
多元统计分析案例分析
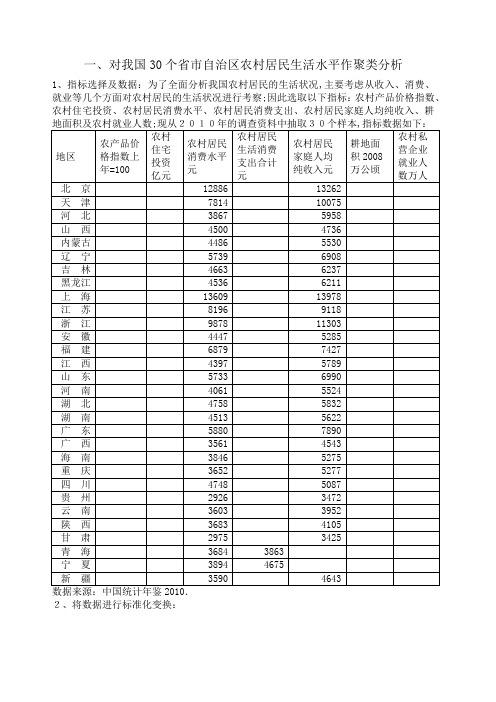
一、对我国30个省市自治区农村居民生活水平作聚类分析1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况进行考察;因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕2、将数据进行标准化变换:第一类:北京、上海、浙江;第二类:天津、、辽宁、、福建、甘肃、江苏、广东;第三类:浙江、河北、内蒙古、吉林、黑龙江、安徽、山东、河南、湖北、四川、云南;第四类:山西、青海、宁夏、新疆、重庆、贵州、陕西、湖南、广西、江西、;从分类结果上看,根据2010年的调查数据,第一类地区的农民生活水平较高,第二类属于中等水平,第三类、第四类属于较低水平;二、判别分析从上可知,只有一个地区判别组和原组不同,回代率为96%; 下面对新疆进行判别:判别函数分别为:Y1= + + + +Y2=+ + + +Y3= + + +将西藏的指标数据代入函数得:Y1=Y2=Y3=计算Y值与不同类别均值之间的距离分别为:D1=D2=D3=D4=经过判别,D4最小,所以新疆应归于第四类,这与实际情况也比较相符;三,因子分析:分析数据在上表的基础上去掉两个耕地面积和农村固定资产投资两个指标;经spss软件分析结果如下:1各指标的相关系数阵:从中可以看出,大部分指标的相关系数都比较高,各变量之间的线性关系较明确,能够从中提取公共因子,适合因子分子;2检验:由上表可知:巴特利特球度检验统计量的观测值为.相应的概率p接近为0.如果显着性水平a为,由于显着性水平小于,拒绝零假设,认为相关系数矩阵与单位阵有显着差异,同时,KOM值为,根据Kaiser给出的度量标准可知原有变量适合进行因子分析3各指标的贡献率如下表:从中可以看出,各个指标的贡献率都在百分之五十之上比较高;从上表中可以看出,第一个因子的特征根为.解释原有五个变量总方差的68%,累积方差贡献率为%;第二个因子的特征根为,解释原有变量总方差%,累计方差贡献率为%;4碎石图:5因子载荷阵如下:由上表可知,各指标在第一个因子上的载荷比较高,说明第一个因子很重要;第二个因子与原有变量的相关性较小,它对原有变量的解释作用不显着;为便于对各因子进行命名,对因子载荷阵实施正交旋转;旋转之后的因子载荷阵:6从上表可见,每个因子只有几个指标的因子载荷较大,因此可根据上表进行分类;将五个指标按高载荷分成两类:四,主成分分析:1各指标间的相关系数矩阵如下表所示:可以看到有些指标之间的相关性较强,如果直接进行综合分析会造成信息重叠,所以用主成分分析将多个指标化成几个不相关的综合指标;2求相关矩阵的特征值和特征向量:从上表可知,前两个特征值累计贡献率已达%;说明前两个主成分基本包含了全部指标具有的信息;因此,取前两个特征值,并计算相应的特征向量:3由上述因子分子的因子载荷阵计算主成分的特征向量阵为:所以,前两个主成分为:第一个主成分:F1= X1++ ++第二个主成分:F2=在第一主成分中第二、三、四个指标的系数较大,这三个指标起主要作用,刻划了农居民的收入支出状况的综合指标;在第二主成分中,第一个指标系数较大,是农产品价格水平指标;4因子得分:根据上表写出以下因子得分函数:F1=农产品价格指数+农村居民消费+消费支出+家庭人均纯收入+就业人数F2=农产品价格指数+农村居民消费消费支出+家庭人均纯收入就业人数5综合评价:以两个因子的方差贡献率为权数,综合评价模型为:Z=+旋转之后的方差贡献率F1= X1++ ++F2=将各地区指标值代入上式得到各地区农村生活水平的综合值及排名:6对结果进行分析:从中可以看出,各地区的农村居民生活水平存在差异;其中,北京、上海、浙江、江苏地区的综合评价值排名前列,说明这几个城市农村居民的生活水平比较高;主要表现在农民收入水平和消费水平两个方面;这几个城市属于沿海地区,经济比较发达,工农业发展遥遥领先于其他地区;其次,天津、山东、福建、辽宁、广东综合评价值相对较低;不过也处于全国前十的地位;青海、贵州、广西、重庆、新疆、甘肃、陕西、云南等几个地区农村居民生活水平发展比较落后;原因是这些地区大多位于中国中西部,地理位置不佳,交通不便,经济发展水平不高,进而影响到农村经济的发展;农村居民收入水平和消费水平均比较低;因此,要提高这些地区农民的生活水平,政府应该加大这些地区的基础设施建设,提高这些地区农村居民的收入水平;。
判别分析
举例 假定只有两类。 假定只有两类。数据中的每个观测 值是二维空间的一个点。见图。 值是二维空间的一个点。见图。 这里只有两种已知类型的训练样本。 这里只有两种已知类型的训练样本。 一类有38个点 个点(用 表示),另一 一类有 个点 用“o”表示 另一 表示 类有44个点 个点(用 类有 个点 用“*”表示 。按原 ”表示)。 来变量(横坐标和纵坐标 ,很难将 来变量 横坐标和纵坐标), 横坐标和纵坐标 这两种点分开。于是就寻找一个方 这两种点分开。 即图上的虚线方向, 向,即图上的虚线方向,沿该方向 朝和这个虚线垂直的一条直线进行 投影会使得这两类分得最清楚。 投影会使得这两类分得最清楚。可 以看出,如果向其他方向投影, 以看出,如果向其他方向投影,判 别效果不会比这个好。 别效果不会比这个好。 有了投影之后, 有了投影之后,再用前面讲到的距 离远近的方法得到判别准则。 离远近的方法得到判别准则。这种 先投影的判别方法就是Fisher判 先投影的判别方法就是 判 别法。 别法。
因变量:分组变量( )。分组类型在两 因变量:分组变量(grouping variable)。分组类型在两 )。 种以上。 种以上。 自变量: 自变量:用以分组的其他特征变量称为判别变量 (discriminant variable)或称为预测变量。各判别变量的 )或称为预测变量。 测度水平在间距测度等级以上。 测度水平在间距测度等级以上。 案例: 案例:用来建立判别函数的数据叫做案例 a每组案例的规模必须至少在一个以上 每组案例的规模必须至少在一个以上 b各分组的案例在各判别变量的数值上能够体现差别 各分组的案例在各判别变量的数值上能够体现差别 c一般来说,要求案例数量(n)比变量的个数(k)多两个, 一般来说, 一般来说 要求案例数量( )比变量的个数( )多两个, 而对判别变量的个数没有限制。 而对判别变量的个数没有限制。
砂土液化判别及案例的思考
1
/
2
(7.3.6)
式中:Vscr ——饱和粉土或砂土剪切波速临界值(m/s);
Kv ——与烈度、土类有关的经验系数。按表 7.3.6 取值;
ds ——剪切波速测点的深度(m);深度为 15m~20m 时,取 ds=15m。d1=1m。
当实测剪切波速值小于按(7.3.6)式计算的剪切波速临界值时,应判为液化土,否则为不
K Dcr
KD0 0.8
0.04(ds
dw)
a
ds dw 0.9(ds
dw) (14
3 4ID
)1/ 2
式中
KDo——液化临界水平应力指数基准值,在 7 度地震且地震加速度 a =0.1g 时取 2.5;
ds ——实测水平应力指数所代表的深度(m); dw ——地下水位深度(m),可采用常年地下水位平均值;
原位测试判别包括:标准贯入试验、静力触探、波速、 扁铲侧胀试验。 标准贯入试验
判别在地面下20m深度范围内,液化判别标准贯入锤 击数临界值可按下式计算:
静力触探试验判别 当采用静力触探试验对地面下15m(8度、9度地区
20m)深度范围内的饱和砂土或饱和粉土进行液化判别 时,可按下式计算。当实测值小于临界值时,可判为液 化土。
石江华(2011)采用波速(选取36个点)对 巴楚地震液化进行研究。
3 汶川地震 2008年5月12日汶川发生Ms8.0级地震,调
查显示,本次地震出现了大量砂砾土液化及 液化震害现象,液化涉及范围广,分布不均 匀,很大程度上受到工程地质条件的影响和 控制。
2 平原液化与岸边液化的不同表现 平原地区的地基失效一般与喷水冒砂有关,
没有喷水冒砂的地方,一般见不到地基失效 导致建筑物破坏的现象,故将喷水冒砂作为 地震液化的宏观标志。
聚类和判别分析课件
图像处理
对图像进行分类和标注。
生物信息学
对基因表达数据进行分类和功 能注释。
市场细分
将消费者按照购买行为和偏好 进行分类。
01
聚类分析算法
K-means算法
一种常见的无监督学习方法,通过迭代将数据划分为K个集群,使得每个数据点与其所在集群的中心点之间的平方距离之和最 小。
K-means算法首先随机选择K个数据点作为初始的集群中心,然后根据数据点到每个集群中心的距离,将每个数据点分配给 最近的集群中心,形成K个集群。接着,算法重新计算每个集群的中心点,并重复上述过程,直到集群中心点不再发生明显变 化或达到预设的迭代次数。
总结词
一种经典的线性分类算法,通过投影将高维数据降维到低维空间,使得同类数据 尽可能接近,不同类数据尽可能远离。
详细描述
LDA通过最小化类内散度矩阵和最大化类间散度矩阵来找到最佳投影方向。它假 设数据服从高斯分布,且各特征之间相互独立。LDA在人脸识别、文本分类等领 域有广泛应用。
支持向量机(SVM)
详细描述
SVM算法通过提取文本的特征,将不同的文本映射到不同的特征空间中。通过分类器 训练,SVM算法能够将不同的文本进行分类和识别,提高文本分类的准确率。在信息
过滤、情感分析等场景中,SVM算法具有广泛的应用价值。
THANKS
THE FIRST LESSON OF THE SCHOOL YEAR
01
判别分析概述
判别分析的定义
01
判别分析是一种统计方法,用于 根据已知分类的观测数据来建立 一个或多个判别函数,从而对新 的观测数据进行分类。
02
它通常用于解决分类问题,通过 找到能够最大化不同类别间差异、 最小化同类数据间差异的函数, 实现对新数据的分类预测。
判别分析
接着,单击“分类”按钮,弹出如下左图所 示对话框,选中“所有组相等”选项,“在 组内”选项,以及“摘要表”选项。 最后,单击“保存”按钮,弹出如下右图所 示对话框,选中“预测组成员”和“判别得 分”选项。
结果分析
从检验结果表中可以看出,Sig 值为0.004<0.05,从而认为判 别分析是显著的。 从Wilks的Lambda值表中, 可以看出,Sig值为 0.000<0.05,从而认为判别 函数有效。
接着,单击“方法”按钮,弹出“判别分析: 步进法”对话框。按照下图进行设置。
接着,单击“分类”按钮,弹出如下左图所 示对话框,选中“所有组相等”选项,“在 组内”选项,以及“摘要表”选项。 最后,单击“保存”按钮,弹出如下右图所 示对话框,选中“预测组成员”和“判别得 分”选项。
结果分析
从检验结果表中可以看出,Sig 值为0.006<0.05,从而认为判 别分析是显著的。 从Wilks的Lambda值表中, 可以看出,Sig值为 0.000<0.05,从而认为判 别函数有效。 从右图可以看出,只有八月降水 天数和八月与六月降水之比两个 变量在判别分析中使用。
下表给出了最后的分类结果。对于原始数据中 属于1区和2区的各10个观测量仍然归于原类, 全部判对。待判的5个观测量有2个归入1区,3 个归入2区。
分类结果
下表给出了最后的分类结果。对于原始数据中 属于1区和2区的各10个观测量仍然归于原类, 全部判对。待判的5个观测量有2个归入1区,3 个归入2区。
分类结果
四、逐步判别分析
逐步判别分析是在分析之前对自变量进 行一次相应筛选的判别分析方法。逐步 判别分析是在判别分析的基础上采用有 进有出的办法,最终在判别式中只保留 数量不多而判别能力强的变量。