CPU实验报告
单周期CPU设计实验报告

单周期CPU设计实验报告一、引言计算机是现代信息社会必不可少的工具,而CPU作为计算机的核心部件,承担着执行指令、进行运算和控制系统资源的任务。
随着科技的进步和计算能力的需求,CPU的设计也趋于复杂和高效。
本次实验旨在设计一种单周期CPU,探究其设计原理和实现过程,并通过实验验证其正确性和性能。
二、理论基础1.单周期CPU概述单周期CPU即每个时钟周期内只完成一条指令的处理,它包括指令取址阶段(IF)、指令译码阶段(ID)、执行阶段(EX)、访存阶段(MEM)和写回阶段(WB)等多个阶段。
每条指令都顺序地在这些阶段中执行,而不同的指令所需的时钟周期可能不同。
2.控制信号单周期CPU需要根据不同的指令类型产生不同的控制信号来控制各个阶段的工作。
常见的控制信号包括时钟信号(clk)、使能信号(En)、写使能信号(WE)和数据选择信号(MUX)等。
这些信号的产生需要通过译码器、控制逻辑电路和时序逻辑电路等来实现。
三、实验设计本次实验采用的单周期CPU包括以下五个阶段:指令取址阶段、指令译码阶段、执行阶段、访存阶段和写回阶段。
每个阶段的具体操作如下:1.指令取址阶段(IF)在IF阶段,通过计数器实现程序计数器(PC)的自增功能,并从存储器中读取指令存储地址所对应的指令码。
同时,设置PC使能信号,使其可以更新到下一个地址。
2.指令译码阶段(ID)在ID阶段,对从存储器中读取的指令码进行解码,确定指令的操作类型和操作数。
同时,根据操作类型产生相应的控制信号,如使能信号、写使能信号和数据选择信号等。
3.执行阶段(EX)在EX阶段,根据ID阶段产生的控制信号和操作数,进行相应的算术逻辑运算。
这里可以包括加法器、乘法器、逻辑运算器等。
4.访存阶段(MEM)在MEM阶段,根据EX阶段的结果,进行数据存储器的读写操作。
同时,将读取的数据传递给下一个阶段。
5.写回阶段(WB)在WB阶段,根据MEM阶段的结果,将数据传递给寄存器文件,并将其写入指定的寄存器。
CPU性能测试实验报告
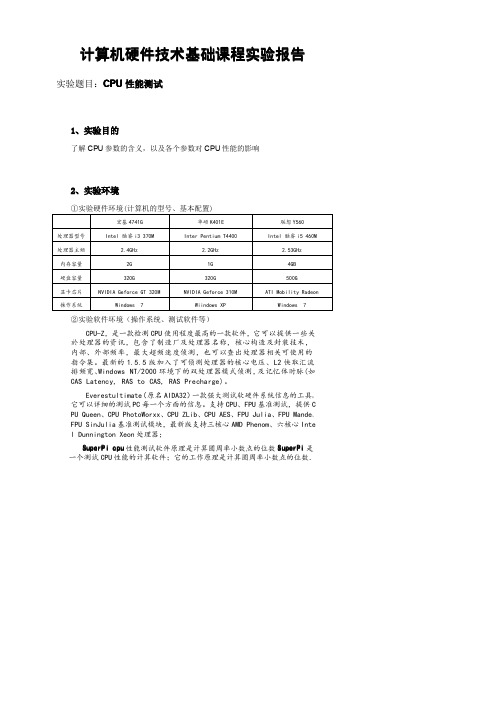
计算机硬件技术基础课程实验报告实验题目:CPU性能测试1、实验目的了解CPU参数的含义,以及各个参数对CPU性能的影响2、实验环境①实验硬件环境(计算机的型号、基本配置)宏基4741G华硕K401E联想Y560处理器型号Intel酷睿i3370M Inter Pentium T4400Intel酷睿i5460M 处理器主频 2.4GHz 2.2GHz 2.53GHz内存容量2G1G4GB硬盘容量320G320G500G显卡芯片NVIDIA Geforce GT320M NVIDIA Geforce310M ATI Mobility Radeon 操作系统Windows7Wiindows XP Windows7②实验软件坏境(操作系统、测试软件等)CPU-Z,是一款检测CPU使用程度最高的一款软件,它可以提供一些关於处理器的资讯,包含了制造厂及处理器名称,核心构造及封装技术,内部、外部频率,最大超频速度侦测,也可以查出处理器相关可使用的指令集。
最新的1.5.5版加入了可侦测处理器的核心电压、L2快取汇流排频宽、Windows NT/2000环境下的双处理器模式侦测,及记忆体时脉(如CAS Latency,RAS to CAS,RAS Precharge)。
Everestultimate(原名AIDA32)一款强大测试软硬件系统信息的工具。
它可以详细的测试PC每一个方面的信息。
支持CPU、FPU基准测试,提供C PU Queen、CPU PhotoWorxx、CPU ZLib、CPU AES、FPU Julia、FPU Mande、FPU SinJulia基准测试模块,最新版支持三核心AMD Phenom、六核心Inte l Dunnington Xeon处理器;SuperPi cpu性能测试软件原理是计算圆周率小数点的位数SuperPi是一个测试CPU性能的计算软件;它的工作原理是计算圆周率小数点的位数.例如:SuperPi100万位就是CPU计算到圆周率小数点后100万的意思,时间越短表示CPU的计算能力越强!Fritz Chess Benchmark是一款国际象棋测试软件,是国际象棋软件Fr itz自带的电脑棋力测试程序,由于支持多线程,而且它做的是大量科学计算,所有经常被用来测试电脑的科学运算能力。
cpu的实验报告

cpu的实验报告CPU的实验报告引言:计算机是现代社会不可或缺的工具,而CPU(Central Processing Unit)则是计算机的核心部件之一。
CPU负责执行计算机指令,处理数据和控制计算机的各种操作。
本文将对CPU进行实验,并对实验结果进行分析和总结,以便更好地理解和掌握CPU的工作原理。
一、实验目的本次实验的目的是通过对CPU的实验,深入了解CPU的结构和工作原理,掌握CPU的运行过程和性能评估方法。
二、实验过程1. CPU的结构CPU主要由控制单元和算术逻辑单元组成。
控制单元负责解析和执行指令,算术逻辑单元负责进行算术和逻辑运算。
实验中,我们对CPU的各个部件进行了详细的分析和研究。
2. CPU的指令执行过程CPU的指令执行过程包括取指、译码、执行和写回四个阶段。
在实验中,我们通过模拟CPU的指令执行过程,对每个阶段进行了详细的观察和记录,并分析了每个阶段的作用和影响因素。
3. CPU的性能评估为了评估CPU的性能,我们进行了一系列的实验。
通过改变CPU的主频、缓存大小和指令集等因素,观察CPU的运行速度和效率,并进行性能比较和分析。
实验结果表明,这些因素对CPU的性能有着重要的影响。
三、实验结果与分析1. CPU的结构分析通过对CPU的结构进行分析,我们发现控制单元和算术逻辑单元之间的协作非常重要。
控制单元负责解析和执行指令,而算术逻辑单元负责进行计算和逻辑运算。
两者之间的紧密配合使得CPU能够高效地运行。
2. 指令执行过程分析通过对CPU的指令执行过程进行分析,我们发现每个阶段都有其特定的作用。
取指阶段负责从内存中读取指令,译码阶段负责解析指令,执行阶段负责执行指令,写回阶段负责将结果写回内存。
每个阶段的效率和性能都对CPU的整体运行速度有着重要的影响。
3. 性能评估结果通过对CPU的性能评估实验,我们发现主频、缓存大小和指令集等因素对CPU 的性能有着重要的影响。
提高主频可以加快CPU的运行速度,增加缓存大小可以提高数据读取和存储的效率,而优化指令集可以提高CPU的指令执行效率。
测量电脑的CPU温度实验及实验报告

测量电脑的CPU温度实验及实验报告
实验目的
本实验旨在测量电脑的CPU温度,并通过实验报告记录测量结果。
实验材料
- 电脑主机
- 温度计
实验步骤
1. 打开电脑主机,并确保CPU正常运行。
2. 将温度计放置于CPU散热器上,确保与CPU接触紧密且位置稳定。
3. 开始测量CPU温度,记录每隔一段时间的温度数据。
4. 持续测量一段时间后,停止测量。
实验结果
以下为测量得到的CPU温度数据:
实验结论
根据以上测量数据,我们可以得出以下结论:
- 随着时间的推移,CPU温度逐渐上升。
- CPU的最高温度达到了57摄氏度。
实验注意事项
- 在进行实验时,务必小心操作,避免造成任何损坏或伤害。
- 实验过程中,确保测量环境的稳定性,尽量减少外界干扰。
- 在进行实验前,确保温度计的准确性和稳定性。
实验改进建议
为了进一步提高测量准确度和实验可靠性,可以考虑以下改进措施:
- 使用更精确的温度计进行测量。
- 增加测量时间和数据点,以获取更全面的温度趋势。
- 在进行实验时,控制室温和湿度等环境因素对测量的影响。
结束语
通过这次实验,我们成功测量了电脑的CPU温度,并总结了测量数据和结论。
通过实验报告的记录和分析,我们能够更好地了解CPU的热量产生和散热情况,为日后的电脑维护和散热优化提供了参考。
cpu组成与机器指令执行实验实验报告

cpu组成与机器指令执行实验实验报告CPU组成与机器指令执行实验实验报告一、引言计算机是现代社会不可或缺的工具,而中央处理器(CPU)则是计算机的核心组成部分。
理解CPU的组成和机器指令的执行过程对于深入理解计算机的工作原理至关重要。
本实验旨在通过搭建一个简单的CPU模型,探究CPU的组成结构和机器指令的执行过程。
二、实验原理1. CPU的组成结构CPU主要由运算器、控制器和寄存器组成。
运算器负责进行各种算术和逻辑运算,控制器则负责指挥各个部件的工作,寄存器用于存储数据和指令。
2. 机器指令的执行过程机器指令的执行包括取指令、译码、执行和访存四个阶段。
取指令阶段从内存中读取指令,译码阶段将指令翻译成对应的操作,执行阶段进行运算或逻辑操作,访存阶段用于读取或写入数据。
三、实验过程1. 搭建CPU模型根据实验要求,我们搭建了一个简单的CPU模型,包括运算器、控制器和寄存器。
通过将这些部件连接起来,我们可以模拟CPU的工作过程。
2. 编写指令为了测试CPU的功能,我们编写了一些简单的指令,包括加法、减法和逻辑运算等。
这些指令将被存储在内存中,CPU在执行过程中会逐条读取并执行。
3. 执行指令我们按照预定的顺序执行指令,观察CPU的工作状态和输出结果。
通过这个过程,我们可以更好地理解指令的执行过程和CPU的工作原理。
四、实验结果在实验过程中,我们成功搭建了一个简单的CPU模型,并编写了一些指令进行测试。
通过执行这些指令,我们观察到CPU按照预期工作,并得到了正确的输出结果。
五、实验分析通过本次实验,我们深入了解了CPU的组成结构和机器指令的执行过程。
我们发现,CPU的运算器、控制器和寄存器相互配合,完成了复杂的运算和逻辑操作。
同时,我们也注意到指令的执行过程需要经过多个阶段,每个阶段都起到了重要的作用。
六、实验总结本次实验让我们对CPU的组成与机器指令的执行有了更深入的理解。
通过搭建CPU模型并执行指令,我们亲身体验了CPU的工作过程,加深了对计算机原理的理解。
MIPS单周期CPU实验报告

MIPS单周期CPU实验报告一、实验目的本实验旨在设计一个基于MIPS指令集架构的单周期CPU,具体包括CPU的指令集设计、流水线的划分与控制信号设计等。
通过本实验,可以深入理解计算机组成原理中的CPU设计原理,加深对计算机体系结构的理解。
二、实验原理MIPS(Microprocessor without Interlocked Pipeline Stages)是一种精简指令集(RISC)架构的处理器设计,大大简化了指令系统的复杂性,有利于提高执行效率。
MIPS指令集由R、I、J三种格式的指令组成,主要包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
在单周期CPU设计中,每个指令的执行时间相同,每个时钟周期只执行一个指令。
单周期CPU的主要部件包括指令内存(IM)、数据存储器(DM)、寄存器文件(RF)、运算单元(ALU)、控制器等。
指令执行过程主要分为取指、译码、执行、访存、写回等阶段。
三、实验步骤1.设计CPU指令集:根据MIPS指令集的格式和功能,设计符合需求的指令集,包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
2.划分CPU流水线:将CPU的执行过程划分为取指、译码、执行、访存、写回等阶段,确定每个阶段的功能和控制信号。
3.设计控制器:根据CPU的流水线划分和指令集设计,设计控制器实现各个阶段的控制信号生成和时序控制。
4.集成测试:进行集成测试,验证CPU的指令执行功能和正确性,调试并优化设计。
5.性能评估:通过性能评估指标,如CPI(平均时钟周期数)、吞吐量等,评估CPU的性能优劣,进一步优化设计。
四、实验结果在实验中,成功设计了一个基于MIPS指令集架构的单周期CPU。
通过集成测试,验证了CPU的指令执行功能和正确性,实现了取指、译码、执行、访存、写回等阶段的正常工作。
同时,通过性能评估指标的测量,得到了CPU的性能参数,如CPI、吞吐量等。
通过性能评估,发现了CPU的性能瓶颈,并进行了相应的优化,提高了CPU的性能表现。
cpu设计实验报告
cpu设计实验报告CPU设计实验报告1. 引言计算机是现代社会不可或缺的工具,而中央处理器(CPU)则是计算机的核心组件之一。
本实验旨在设计和实现一个简单的CPU,以加深对计算机组成原理的理解,并通过实践掌握CPU的基本工作原理。
2. CPU设计概述我们的CPU设计基于冯·诺依曼结构,包括指令寄存器(IR)、程序计数器(PC)、算术逻辑单元(ALU)和寄存器文件等关键组件。
CPU的指令集采用RISC(精简指令集计算机)风格,指令长度为32位。
3. 指令集设计我们设计了一套简单的指令集,包括算术运算指令(加法、减法、乘法、除法)、逻辑运算指令(与、或、非)以及数据传输指令(加载、存储)。
指令的格式包括操作码、源操作数和目标操作数。
4. 寄存器文件设计寄存器文件是CPU中用于存储数据的重要组件。
我们设计了一个包含8个通用寄存器的寄存器文件,每个寄存器的宽度为32位。
通过寄存器文件,CPU能够高效地进行数据的读取和存储。
5. 控制单元设计控制单元是CPU中的重要模块,负责解析指令并控制各个组件的操作。
我们设计了一个简单的控制单元,使用有限状态机(FSM)来实现指令的解析和控制信号的生成。
控制单元根据指令的操作码,决定对应的操作,并将操作所需的控制信号发送给其他组件。
6. 数据通路设计数据通路是CPU中各个组件之间的数据传输路径。
我们设计了一个简单的数据通路,包括指令寄存器、程序计数器、寄存器文件、算术逻辑单元等。
数据通路能够将指令中的操作数从寄存器文件中读取出来,并将运算结果写回到寄存器文件。
7. CPU实现与验证我们使用硬件描述语言(HDL)对CPU进行实现,并通过仿真和测试验证其正确性。
通过编写测试程序,我们能够对CPU的各个指令进行测试,并检查其运行结果是否符合预期。
8. 结果与分析经过测试,我们的CPU能够正确执行设计的指令集,并产生正确的运算结果。
通过性能测试,我们还评估了CPU的运行速度和效率,并与其他现有的CPU进行了比较。
CPU实验报告范文
CPU实验报告范文一、实验目的本次实验的目的是设计和实现一个简单的中央处理器(CPU),通过实践掌握CPU的基本工作原理和实现方法。
二、实验原理1.CPU的基本概念中央处理器(CPU)是计算机的核心部件,负责执行计算机指令和控制计算机的操作。
它由运算器、控制器和寄存器组成。
运算器负责执行算术和逻辑运算,包括加法、减法、乘法、除法等。
控制器负责指挥CPU的工作,通过控制总线实现对内存和其他外部设备的访问。
寄存器是CPU内部的存储器,用于暂时存放指令、数据和中间结果。
2.CPU的实现方法CPU的实现采用组合逻辑电路和时序逻辑电路相结合的方法。
组合逻辑电路是由逻辑门构成的电路,它的输入只依赖于当前时刻的输入信号,输出也只与当前时刻的输入信号有关。
而时序逻辑电路则包含存储元件,其输出不仅与当前时刻的输入信号有关,还与之前的输入信号有关。
CPU的实现过程主要包括以下步骤:(1)设计指令集:确定CPU支持的指令集,包括指令的格式和操作码。
(2)设计控制器:根据指令集设计控制器,确定各个指令的执行过程和控制信号。
(3)设计运算器:根据指令集设计运算器,确定支持的算术和逻辑运算。
(4)设计寄存器:确定需要的寄存器数量和位数,设计寄存器的输入输出和工作方式。
3.实验环境和工具本次实验使用的环境和工具如下:(1)硬件环境:计算机、开发板、示波器等。
(2)软件环境:Win10操作系统、Vivado开发工具等。
三、实验步骤1.设计指令集根据实验要求,我们设计了一个简单的指令集,包括加法、减法、逻辑与、逻辑或和移位指令。
每个指令有特定的操作码和操作数。
2.设计控制器根据指令集设计了一个控制器。
控制器根据指令的操作码产生相应的控制信号,控制CPU内部寄存器、运算器和总线的操作。
3.设计运算器根据指令集设计了一个运算器。
运算器包括加法器、减法器、与门和或门等。
它通过输入的操作数和控制信号完成相应的运算操作。
4.设计寄存器根据实验需求确定了所需的寄存器数量和位数。
cpu组成与机器指令执行实验报告
CPU组成与机器指令执行实验报告1. 引言本实验旨在探究中央处理器(CPU)的组成以及机器指令的执行过程。
通过深入理解CPU的工作原理和机器指令的执行流程,我们可以更好地理解计算机的数据处理过程。
2. CPU的组成CPU是计算机的核心组件之一,它负责执行计算机上的所有任务。
一个典型的CPU由以下几个重要组成部分构成:2.1 控制单元(Control Unit)控制单元是CPU的核心组件之一,负责协调和控制整个CPU的操作。
它从存储器中读取指令,并解码这些指令以确定下一步的操作。
2.2 算术逻辑单元(Arithmetic Logic Unit,ALU)算术逻辑单元是CPU的另一个重要组成部分,负责执行各种算术和逻辑运算,如加法、减法、乘法、除法等。
ALU能够执行基本的数学计算和布尔逻辑运算。
2.3 寄存器(Registers)寄存器是CPU内部的临时存储器,用于存储指令和数据。
CPU拥有多个寄存器,每个寄存器都有特定的功能,如程序计数器(Program Counter,PC)用于存储下一条指令的地址,累加器(Accumulator)用于存储运算结果等。
3. 机器指令的执行过程机器指令是计算机能够理解和执行的指令,它们以二进制的形式表示。
机器指令的执行过程可以分为以下几个步骤:3.1 取指令(Fetch)控制单元从存储器中读取下一条指令,并将其存储在指令寄存器(Instruction Register,IR)中。
3.2 解码指令(Decode)控制单元解码指令寄存器中的指令,确定需要执行的操作类型和操作数。
3.3 执行指令(Execute)根据解码的结果,CPU执行指令中指定的操作。
这可能涉及到从寄存器中读取数据、进行算术运算、修改寄存器的值等。
3.4 存储结果(Store)执行指令后,结果可能需要存储在寄存器或存储器中,以备后续操作使用。
4. 实验步骤在本次实验中,我们将使用一个简单的汇编语言程序来演示机器指令的执行过程。
CPU计算机组成原理实验报告
CPU计算机组成原理实验报告实验名称:CPU计算机组成原理实验一、实验目的:1.了解计算机硬件的基本组成原理,特别是CPU的工作原理;2.掌握计算机的组装和调试技能;3.熟悉计算机操作系统的安装和配置方法;4.学习使用计算机进行基本的应用程序开发。
二、实验设备和材料:1.CPU主机:包括主板、CPU、内存、硬盘等;2.显示设备:显示器、键盘、鼠标等;3.软件:操作系统、开发工具等。
三、实验步骤:1.将主板、CPU、内存、硬盘等硬件组件组装到主机箱中,连接电源、显示器、键盘、鼠标等外设;2.打开电源,按照BIOS界面提示进行主板和硬件设置;3.插入操作系统安装光盘,根据安装界面提示进行操作系统的安装;4.安装完成后,进入操作系统,根据提示进行相应驱动程序的安装和配置;5.打开开发工具,进行编程实践。
四、实验结果与分析:通过以上步骤,成功组装了一台计算机并安装了操作系统。
在操作系统中,能够正常运行各种应用程序,并且能够进行编程开发。
通过实验,可以清楚地了解到计算机硬件的组成原理,特别是CPU的工作原理。
CPU 作为计算机的核心部件,负责指令的执行和数据的处理。
通过对CPU的组装和调试,可以更深入地了解其工作原理和操作方法。
五、实验心得与体会:通过实验,我对计算机硬件的组装和设置有了更深入的理解。
计算机硬件的组成非常复杂,需要我们仔细阅读说明书,按照步骤进行操作。
在实验过程中,我们学会了解决一些常见的硬件问题,如硬件不兼容、连接错误等。
此外,操作系统的安装和配置也是非常重要的一步,只有正确地安装和配置操作系统,才能保证计算机的正常运行。
通过这个实验,我不仅学到了理论知识,还锻炼了实际操作的能力。
计算机的组装和调试需要我们仔细、耐心地进行,一丝不苟地对待每一步操作。
只有掌握了计算机组成原理,才能更好地理解和应用计算机技术。
通过实验,我深刻地认识到计算机是一台高度复杂的机器,它可以帮助我们解决各种问题,提高工作效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
C16,C6,C0 00020041
C1
MAR←PC, CAR←0
C10,C2 00000404
D0(SHIFTL)
ACC←ACC<<1, PC←PC+1,
CAR←CAR+1
C19,C6,C0 02000041
D1
MAR←PC, CAR←0
C10,C2 00000404
E0 (DIV)
93
ACC←ACC and BR, CAR←CAR+1
C22,C0
94
MAR←PC,CAR←0
C10,C2 00000404
A0(OR)
MAR←MBR7-0 ,PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
A1
MBR←memory, CAR←CAR+1
C3,C0 00000009
Read RAM
C4
IR←MBR(15..8)
MBR into IR
C5
MAR←MBR[7..0]
MBR into MAR
C6
PC←PC+1
Increase PC
C7
BR←MBR
MBR into BR
C8
ACC←0
reset_ACC
C9
ACC←ACC+BR
ADD
C10
MAR←PC
PC into MAR
MAR←MBR7-0 ,PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
81
MBR←memory, CAR←CAR+1
C3,C0 00000009
82
BR←MBR , CAR←CAR+1
C7,C0 00000081
83
MR←ACC*BR(H), CAR←CAR+1
C17,C0 00040001
53
CAR←0 ,MAR←PC
C10,C2 00000404
60(JMP)
PC←MBR7-0, CAR←CAR+1
C13,C0 00004001
61
CAR←0 ,MAR←PC
C10,C2 00000404
70(HALT)
ACC←0, CAR←0 ,PC←0
C8,C14,C2 00008104
80 (MPY)
C10,C2 00000404
Bit in read-only control memory
(Bit of ROM)
Micro-operation
Control signal name
C0
CAR←CAR+1
Increase CAR
C1
CAR←**
Control addressing
C2
CAR←0
Reset CAR
C3
MBR←memory
44
MAR←PC, CAR←0
C10,C2 00000404
50(JUMPEZ)
(IF flag=1) PC←PC+1, CAR←CAR+1
C6,C0 00000041
51
CAR←0 ,MAR←PC
C10,C2 00000404
52
(IF flag =0) PC←MBR7-0, CAR←CAR+1
C13,C0 00004001
MBR←memory,CAR←CAR+1
C3,C0 00000009
1
IR←MBR15-8,CAR←CAR+1
C4,C0 00000011
2
CAR←**
C1 00000002
10(STORE)
MAR←MBR7-0,PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
11
MBR←ACC, CAR←CAR+1,WE=1
DIV
C19
Shift ACC to left
SHIFTL
C20
ACC←NOTBR
NOT
C21
ACC←ACC or BR
OR
C22
ACC←ACC and BR
AND
C23
WE=1
Memory write
Address(Hex)
Micro-instructions
Control Signals
0 (FETCH)
B1
MBR←memory, CAR←CAR+1
C3,C0 00000009
B2
BR←MBR, CAR←CAR+1
C7,C0 00000081
B3
ACC←notBR, CAR←CAR+1
C20,C0 04000001
B4
MAR←PC, CAR←0
C10,C2 00000404
C0(SHIFTR)
ACC←ACC>>1, PC←PC+1,
A2
BR←MBR, CAR←CAR+1
C7,C0 00000081
A3
ACC←ACC or BR, CAR←CAR+1
C21,C0 08000001
A4
MAR←PC, CAR←0
C10,C2 00000404
B0(NOT)
MAR←MBR7-0 ,PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
MAR←MBR7-0 ,PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
E1
MBR←memory, CAR←CAR+1
C3,C0 00000009
E2
BR←MBR , CAR←CAR+1
C7,C0 00000081
E3
ACC←ACC/BR
C18,C0 00040001
E4
MAR←PC , CAR←0
CAR←CAR+1
C5,C6,C0 00000061
31
MBR←memory, CAR←CAR+1
C3,C0 00000009
32
BR←MBR, CAR←CAR+1
C7,C0 00000081
33
ACC←ACC+BR, CAR←CAR+1
C9,C0 00000201
34
MAR←PC, CAR←0
C10,C2 00000404
C23,C12,C0 00001001
12
memory←MBR, CAR←CAR+1
C11,C0 00000801
13
MAR←PC,CAR←0
C10,C2 00000404
20 (LOAD)
MAR←MBR7-0,PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
21
MBR←memory , CAR←CAR+1
40 (SUB)
MAR←MBR7-0, PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
41
MBR←memory, CAR←CAR+1
C3,C0 00000009
42
BR←MBR, CAR←CAR+1
C7,C0 00000081
43
ACC←ACC-BR, CAR←CAR+1
C15,C0 00010001
84
MAR←PC , CAR←0
C10,C2 00000404
90(AND)
MAR←MBR7-0, PC←PC+1,
CAR←CAR+1
C5,C6,C0 00000061
91
MBR←memory, CAR←CAR+1
C3,C0 00000009
92
BR←MBR, CAR←CAR+1
C7R
RAM _write
C12
MBR←ACC
ACC into MBR
C13
PC←MBR
MBR into PC
C14
PC←0
Reset_PC
C15
ACC←ACC-BR
SUB
C16
Shift ACC to right
SHIFTR
C17
MRACC←ACC*BR
MPY
C18
DRACC←ACC/BR
C3,C0 00000009
22
ACC←0, BR←MBR, CAR←CAR+1
C8,C7,C0 00000181
23
ACC←ACC+BR, CAR←CAR+1
C9,C0 00000201
24
MAR←PC, CAR←0
C10,C2 00000404
30(ADD)
MAR←MBR7-0, PC←PC+1,