【时间管理】eviews时间序列模型
在Eviews中对时间序列进行预测的详细步骤

在Eviews中对时间序列进行预测的详细步骤一、输入数据1.1打开Eviews6.0,按照如图所示打开工作表创建框。
1.2在右上角的data specification框中输入起止年份(start data和end data)1.3输入数据:在输入框中输入data gdp(本文采用的数据为1990—2012年的GDP值)。
当然,data后面可以输入任何你想要定义的“英文名字”输入data gdp后注意按回车键,弹出表格窗口后在其中输入数据(也可复制进去数据:ctrl+v键)二、平稳性检验2.1在打开的数据窗口中点击View→Correlogram(1)在弹出的窗口中直接点OK即可↓2.2自相关图和偏相关图进行分析:最简单粗暴的方法就是看最右边的Prob值(即P值),当这列数据有多数都大于0.05(置信水平)时为白噪声序列=序列是平稳的。
本文中GDP数据P值均小于0.05,则为非白噪声。
需对序列进行差分。
三、取一阶差分3.1在输入框中输入第二列代码,这代表将数据gdp进行一阶差分,一阶差分后的值命名为dgdp.按回车键3.2在dgdp数据的窗口中重复2.1的操作,对序列的平稳性进行检验得到结果如下:惨!还是非白噪声,只能进行二阶差分了!四、取二阶差分4.1如第三列代码所示(记得不能重复命名)4.2对新的序列dgdp2进行平稳性检验,步骤同上,结果如下:MY GOD! 看见了木有,这回是白噪声了,P值多数都大于0.05!五、用最小二乘法对模型进行估计:输入ls dgdp2 c ar(2)(探索性建模)5.1AR(2)模型结果(准确的说这个模型应该是ARIMA的疏系数模型,本文重点不在这!如有需要请私信我!)5.2MA(2)模型结果5.3优化模型:根据AIC和SBC准则选择模型,值越小的拟合效果越好,本文的选择MA(2)模型。
5.4对模型进行检验:View→Residual Tests→Correlogram Q statistics检验结果如下:P值大于0.05,为白噪声序列,则平稳。
时间序列经济模型EVIEWS操作
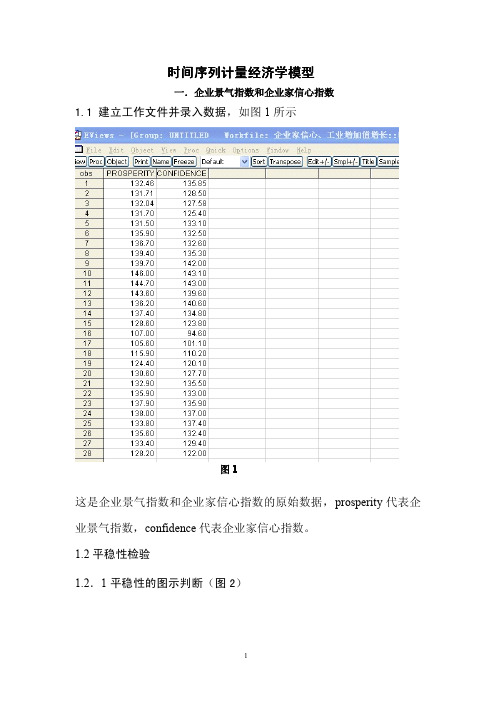
时间序列计量经济学模型一.企业景气指数和企业家信心指数1.1建立工作文件并录入数据,如图1所示图1这是企业景气指数和企业家信心指数的原始数据,prosperity代表企业景气指数,confidence代表企业家信心指数。
1.2平稳性检验1.2.1平稳性的图示判断(图2)图2从图中可以看出企业景气指数和企业家信心指数这两序列都是非平稳的。
1.2.2样本自相关图判断点击主界面Quick\Series Statistics\Correlogram...,在弹出的对话框中输入prosperity,点击OK就会弹出Correlogram Specification对话框,选择Level,并输入要输出的阶数(一般默认为24),点击OK,即可得到prosperity的样本相关函数图,如图3所示。
图3从上述样本相关函数图,可以看到企业景气指数(prosperity)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。
所以,通过企业景气指数(prosperity)的样本相关图,可初步判定该企业景气指数(prosperity)时间序列非平稳。
同理得:confidence的样本相关函数图,如图4所示图4从上述样本相关函数图,可以看到企业家信心指数(confidence)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。
所以,通过企业家信心指数(confidence)的样本相关图,可初步判定该企业家信心指数(confidence)时间序列非平稳。
1.2.3单位跟检验单位跟检验((ADF检验检验))(1)企业景气指数(prosperity)采用ADF检验对prosperity序列进行平稳性的单位根检验。
点击主界面Quick\Series Statistics\Unit Root Test...,在弹出的Series对话框中输入prosperity,点击OK,就会出现UnitRoot Test对话框,如图5所示。
如何用eviews分析时间序列课程

如何用eviews分析时间序列课程时间序列分析是一种常用的数据分析方法,通过对一系列时间上连续测量的数据进行观察、描述和分析,可以发现其中的规律和趋势,从而预测未来的发展走势。
Eviews是一种专业的时间序列分析软件,具有强大的数据处理和统计分析功能。
本文将介绍如何使用Eviews进行时间序列分析。
首先,打开Eviews软件,并导入需要分析的时间序列数据。
在Eviews的工作区中,选择“File”菜单下的“Open”选项,然后选择需要导入的数据文件,点击“Open”按钮导入数据。
导入数据后,可以在Eviews的对象浏览器中看到导入的数据对象。
接下来,对时间序列数据进行初步的观察和描述分析。
在对象浏览器中,选择需要分析的数据对象,右键点击并选择“Open as Group”选项,将数据对象打开为一个分析组。
然后,在Eviews的对象浏览器中,选择分析组,在右侧窗口中可以看到该组中包含的所有时间序列数据。
可以通过列出每个时间序列的统计概要、绘制时间序列图、查看自相关和偏自相关等方式对数据进行初步的观察和描述分析。
接下来,进行时间序列模型的构建和估计。
在Eviews的操作菜单中,选择“Quick”菜单下的“Estimate Equation”选项,打开方程估计窗口。
在方程估计窗口中,选择需要构建的时间序列模型类型,如AR、MA、ARMA等。
然后,在“Dependent Variable”栏目中选择需要分析的时间序列数据,将其作为因变量。
在“Independent Variables”栏目中选择需要作为自变量的时间序列数据,可以根据需求选择多个自变量。
点击“OK”按钮,Eviews将根据所选择的时间序列模型类型和数据进行模型的估计。
估计完成后,可以查看估计结果。
在方程估计窗口中,可以看到估计结果的统计指标、系数估计值、显著性水平等信息。
可以根据需要查看和分析各个系数的显著性水平、置信区间等信息,判断模型的有效性和可靠性。
时间序列eviews软件课程设计

时间序列eviews软件课程设计一、课程目标知识目标:1. 学生能理解时间序列分析的基本概念,掌握eviews软件操作流程。
2. 学生能描述时间序列数据的特征,并运用eviews软件进行数据预处理。
3. 学生能运用eviews软件进行时间序列模型的建立和预测。
技能目标:1. 学生能运用eviews软件导入、处理和分析时间序列数据。
2. 学生能通过eviews软件绘制时间序列图,识别数据的趋势、季节性和循环性。
3. 学生能运用eviews软件进行时间序列模型的参数估计和假设检验。
情感态度价值观目标:1. 学生培养对经济学、金融学等相关领域数据分析的兴趣,提高实际应用能力。
2. 学生培养合作精神和批判性思维,学会在团队中分享观点,共同解决问题。
3. 学生通过时间序列分析的学习,增强对数据规律的洞察力,形成严谨的科学态度。
课程性质分析:本课程为选修课,旨在让学生掌握时间序列分析的基本方法,学会运用eviews软件进行数据处理和分析,提高实际操作能力。
学生特点分析:学生为高中年级,具备一定的数学基础和计算机操作能力,对经济、金融等领域有一定了解。
教学要求:结合学生特点,课程设计应注重理论与实践相结合,注重培养学生的实际操作能力和解决问题的能力。
通过分解课程目标为具体学习成果,使学生在课程学习过程中不断提升自身能力。
二、教学内容1. 时间序列分析基本概念:时间序列的定义、平稳性、自相关性和白噪声。
2. eviews软件操作基础:软件界面介绍、数据导入与编辑、图形绘制与数据处理。
3. 时间序列数据的预处理:数据清洗、缺失值处理、异常值检测与处理。
- 教材章节:第一章 时间序列分析概述,第三章 数据的预处理。
4. 时间序列模型建立:- 自回归模型(AR)- 移动平均模型(MA)- 自回归移动平均模型(ARMA)- 自回归积分移动平均模型(ARIMA)- 教材章节:第四章 时间序列模型的建立与预测。
5. 模型参数估计与假设检验:- 参数估计方法- 模型适用性检验:单位根检验、滞后阶数确定- 模型预测效果评估:预测误差分析、预测区间计算- 教材章节:第五章 模型参数估计与假设检验,第六章 模型预测与评估。
eviews时间序列分析

方差分解
❖ 利用VAR模型,还可以进行方差分解研究模 型的动态特征。其主要思想是,把系统中每 个内生变量(m)的波动按其成因分解为与 各方程新息相关联的m个组成部分,从而了 解各新息对模型内生变量的相对重要性。
• 9、春去春又回,新桃换旧符。在那桃花盛开的地方,在这醉人芬芳的季节,愿你生活像春天一样阳光,心情像桃花一样美丽,日子像桃子一样甜蜜。21. 11.1821.11.18Thursday, November 18, 2021
❖ 例3 下面以1949 ~2001年中国人口时间序列 数据(case42)为例介绍: (1)时间序列图; (2)求 中国人口序列的相关图和偏相关图,识别模 型形式; (3)估计时间序列模型; (4)样本外预 测。
❖ 1、画时间序列图
❖ 点击View键,选择Graph/Line功能
❖ 从人口序列y的变化特征看,这是一个非平 稳序列。
yt c t yt1 j yt j t j 1
❖ PP检验
❖ 例1:661天的深证成指(SZ)序列见case37。
❖ 初步选择①ADF检验,②对原序列sz,做单 位根检验,③检验式中不包括趋势项,但包 括截距项。
❖ 因为常数项没有显著性。从检验式中去掉截 距项,继续迸行单位根检验。
第三节 模型的预测
❖ 比如用估计的模型Dyt = 0. 0547 + 0. 6171 Dy t- 1+ vt预测2001年的中国总人口,在窗口 中点击forecast键,弹出对话窗口。在S. E. (optional)选择区填入yfse,把Forecast sample (预测样本区间)改为2001 ~2001,预 测方法(Method)选静态预测(Static)
❖ 输出结果由两部分组成。左半部分是序列的
用EVIEWS处理时间序列分析

应用时间序列分析实验手册目录目录1第二章时间序列的预处理2一、平稳性检验2二、纯随机性检验9第三章平稳时间序列建模实验教程9一、模型识别9二、模型参数估计(如何判断拟合的模型以及结果写法)14三、模型的显著性检验17四、模型优化18第四章非平稳时间序列的确定性分析19一、趋势分析19二、季节效应分析34三、综合分析38第五章非平稳序列的随机分析44一、差分法提取确定性信息44二、ARIMA模型57三、季节模型61第二章时间序列的预处理一、平稳性检验时序图检验和自相关图检验(一)时序图检验根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常数值附近随机波动,而且波动的X围有界、无明显趋势及周期特征例2.1检验1964年——1999年中国纱年产量序列的平稳性1.在Eviews软件中打开案例数据图1:打开外来数据图2:打开数据文件夹中案例数据文件夹中数据文件中序列的名称可以在打开的时候输入,或者在打开的数据中输入图3:打开过程中给序列命名图4:打开数据2.绘制时序图可以如下图所示选择序列然后点Quick选择Scatter或者XYline;绘制好后可以双击图片对其进行修饰,如颜色、线条、点等图1:绘制散点图图2:年份和产出的散点图10020030040050060019601970198019902000YEARO U T P U T图3:年份和产出的散点图(二)自相关图检验 例2.3导入数据,方式同上;在Quick 菜单下选择自相关图,对Qiwen 原列进行分析;可以看出自相关系数始终在零周围波动,判定该序列为平稳时间序列。
图1:序列的相关分析图2:输入序列名称图2:选择相关分析的对象图3:序列的相关分析结果:1.可以看出自相关系数始终在零周围波动,判定该序列为平稳时间序列2.看Q统计量的P值:该统计量的原假设为X的1期,2期……k期的自相关系数均等于0,备择假设为自相关系数中至少有一个不等于0,因此如图知,该P值都>5%的显著性水平,所以接受原假设,即序列是纯随机序列,即白噪声序列(因为序列值之间彼此之间没有任何关联,所以说过去的行为对将来的发展没有丝毫影响,因此为纯随机序列,即白噪声序列.)有的题目平稳性描述可以模仿书本33页最后一段.(三)平稳性检验还可以用:单位根检验:ADF,PP检验等;非参数检验:游程检验图1:序列的单位根检验表示不包含截距项图2:单位根检验的方法选择图3:ADF检验的结果:如图,单位根统计量ADF=-0.016384都大于EVIEWS给出的显著性水平1%-10%的ADF临界值,所以接受原假设,该序列是非平稳的。
Eviews新建和管理系统时间的序列大数据。

4.
纯随机性判断
一个时间序列是否有分析价值,要看序列观测值之间是否有一定的相关性没有显著性差异,序列为白噪声序列,则图中Q统计量正是对序列是否是白噪声序列即纯随机序列进行的统计检验,该检验的原假设和备择假设分别为:
至少存在某个
在图中,由每个Q统计量的伴随概率可以看出,都是拒绝原假设的,说明至少存在某个k,使得滞后k期的自相关系数显著非0,也即拒绝序列是白噪声序列的原假设。
2.点击主菜单Quick/Graph就可作图,分别是折线图(Line graph)、条形图(Bar graph)、散点图(Scatter)等,也可双击序列名,出现显示电子表格的序列观测值,然后点击工具栏的View/Graph。如果选择折线图,出现对话框,在此对话框中键入要做图的序列,点击OK则出现折线图,横轴表示时间,纵轴表示纱产量,图上工具栏options可以对折线图做相应修饰。点击主菜单的Edit/Copy,然后粘贴到文档就变成了折线图。
ADF检验
从图1-11可以看出,在显著性水平0.01下,一阶差分序列拒绝存在一个单位根的原假设,说明经过差分后的序列已经平稳,可以为以后的建模使用。
用EVIEWS处理时间序列分析

应用时间序列分析实验手册AHA12GAGGAGAGGAFFFFAFAF目录目录 (2)第二章时间序列的预处理 (3)一、平稳性检验 (3)二、纯随机性检验 (9)第三章平稳时间序列建模实验教程 (10)一、模型识别 (10)二、模型参数估计(如何判断拟合的模型以及结果写法) (13)三、模型的显著性检验 (17)四、模型优化 (18)第四章非平稳时间序列的确定性分析 (19)一、趋势分析 (19)二、季节效应分析 (34)三、综合分析 (38)第五章非平稳序列的随机分析 (44)一、差分法提取确定性信息 (44)AHA12GAGGAGAGGAFFFFAFAF二、ARIMA模型 (58)三、季节模型 (62)AHA12GAGGAGAGGAFFFFAFAF第二章时间序列的预处理一、平稳性检验时序图检验和自相关图检验(一)时序图检验根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常数值附近随机波动,而且波动的范围有界、无明显趋势及周期特征例2.1检验1964年——1999年中国纱年产量序列的平稳性1.在Eviews软件中打开案例数据图1:打开外来数据AHA12GAGGAGAGGAFFFFAFAF图2:打开数据文件夹中案例数据文件夹中数据文件中序列的名称可以在打开的时候输入,或者在打开的数据中输入图3:打开过程中给序列命名AHA12GAGGAGAGGAFFFFAFAF图4:打开数据2.绘制时序图可以如下图所示选择序列然后点Quick选择Scatter或者XYline;绘制好后可以双击图片对其进行修饰,如颜色、线条、点等AHA12GAGGAGAGGAFFFFAFAFAHA12GAGGAGAGGAFFFFAFAFAHA12GAGGAGAGGAFFFFAFAF图1:绘制散点图图2:年份和产出的散点图 010020030040050060019601970198019902000YEAR O U T P U T图3:年份和产出的散点图(二)自相关图检验例2.3导入数据,方式同上;在Quick菜单下选择自相关图,对Qiwen原列进行分析;可以看出自相关系数始终在零周围波动,判定该序列为平稳时间序列。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
主要内容
§9.1 序列相关理论 §9.2 平稳时间序列建模 §9.3 非平稳时间序列建模 §9.4 协整和误差修正模型
2019/8/8
2
§9.1 序列相关理论
第6章在对扰动项ut的一系列假设下,讨论了古典线 性回归模型的估计、检验及预测问题。如果线性回归方
程的扰动项ut 满足古典回归假设,使用OLS所得到的估 计量是线性无偏最优的。
对于线性回归模型
yt 0 1x1t 2 x2t k xkt ut
(9.1.1)
随机误差项之间不相关,即无序列相关的基本假设为
cov(ut ,uts ) 0 s 0 , t 1 , 2 ,, T
如果扰动项序列ut表现为:
cov(ut ,uts ) 0 s 0 , t 1 , 2 ,, T
2019/8/8
7
EViews提供了以下几种检测序列相关的方法。
1.D.W.统计量检验
Durbin-Watson 统计量(简称D.W.统计量)用于 检验一阶序列相关,还可估算回归模型邻近残差的线 性联系。对于扰动项ut建立一阶自回归方程:
ut ut1 t
(9.1.6)
D.W.统计量检验的原假设: = 0,备选假设是 0。
但是如果扰动项ut不满足古典回归假设,回归方程的 估计结果会发生怎样的变化呢?理论与实践均证明,扰
动项ut关于任何一条古典回归假设的违背,都将导致回归 方程的估计结果不再具有上述的良好性质。因此,必须
建立相关的理论,解决扰动项不满足古典回归假设所带
来的模型估计问题。
2019/8/83来自§9.1.1 序列相关及其产生的后果
①在线性估计中OLS估计量不再是有效的;
②使用OLS公式计算出的标准差不正确,相应的显 著性水平的检验不再可信 ;
③如果在方程右边有滞后因变量,OLS估计是有偏
的且不一致。
2019/8/8
6
§9.1.2 序列相关的检验方法
EViews提供了检测序列相关和估计方法的工具。但 首先必须排除虚假序列相关。虚假序列相关是指模型 的序列相关是由于省略了显著的解释变量而引起的。 例如,在生产函数模型中,如果省略了资本这个重要 的解释变量,资本对产出的影响就被归入随机误差项。 由于资本在时间上的连续性,以及对产出影响的连续 性,必然导致随机误差项的序列相关。所以在这种情 况下,要把显著的变量引入到解释变量中。
(9.1.2) (9.1.3)
2019/8/8
4
即对于不同的样本点,随机扰动项之间不再是完全相互 独立的,而是存在某种相关性,则认为出现了序列相关 性(serial correlation)。由于通常假设随机扰动项都服 从均值为0,同方差的正态分布,则序列相关性也可以 表示为:
E(ut ,uts ) 0 s 0 , t 1 , 2 ,, T
2019/8/8
8
T
(uˆt uˆt1)2
D.W . t2 T
2(1 ˆ )
uˆt2
t 1
如果序列不相关,D.W.值在2附近。
如果存在正序列相关,D.W.值将小于2。
如果存在负序列相关,D.W.值将在2~4之间。
正序列相关最为普遍。根据经验,对于有大于50 个观测值和较少解释变量的方程,D.W.值小于1.5的情 况,说明残差序列存在强的正一阶序列相关。
2019/8/8
9
Dubin-Waston统计量检验序列相关有三个主要不足:
1 . D-W 统 计 量 的 扰 动 项 在 原 假 设 下 依 赖 于 数 据 矩 阵 X 。 2.回归方程右边如果存在滞后因变量,D-W检验不再 有效。 3.仅仅检验是否存在一阶序列相关。
其他两种检验序列相关方法:Q-统计量和BreushGodfrey LM检验克服了上述不足,应用于大多数场合。
其中:rj是残差序列的 j 阶自相关系数,T是观测值的
个数,p是设定的滞后阶数 。
2019/8/8
11
p阶滞后的Q - 统计量的原假设是:序列不存在 p阶自相关;备选假设为:序列存在p阶自相关。
如果Q - 统计量在某一滞后阶数显著不为零, 则说明序列存在某种程度上的序列相关。在实际的 检验中,通常会计算出不同滞后阶数的Q - 统计量、 自相关系数和偏自相关系数。如果各阶Q - 统计量 都没有超过由设定的显著性水平决定的临界值,则 不拒绝原假设,即不存在序列相关,并且此时,各 阶的自相关和偏自相关系数都接近于0。
特别的,如果仅存在
(9.1.4)
E(ut , ut1 ) 0
t 1 , 2 ,, T
(9.1.5)
称为一阶序列相关,这是一种最为常见的序列相关问题。
2019/8/8
5
如果回归方程的扰动项存在序列相关,那么应用 最小二乘法得到的参数估计量的方差将被高估或者低 估。因此,检验参数显著性水平的t统计量将不再可信。 可以将序列相关可能引起的后果归纳为:
2019/8/8
10
2 . 相关图和Q -统计量 我们还可以应用所估计回归方程残差序列的自
相关和偏自相关系数(在本章9.2.4节给出相应的公 式),以及Ljung-Box Q - 统计量来检验序列相关。 Q - 统计量的表达式为:
QLB
T
T 2
p rj2 j1 T j
(9.1.7)
2019/8/8
12
反之,如果在某一滞后阶数p,Q - 统计量超过设定 的显著性水平的临界值,则拒绝原假设,说明残差序列 存在p阶自相关。由于Q-统计量的P值要根据自由度p来估 算,因此,一个较大的样本容量是保证Q- 统计量有效的 重要因素。
在EViews软件中的操作方法:
在方程工具栏选择View/Residual Tests/correlogram-
Q-statistics 。EViews将显示残差的自相关和偏自相关函
第九章 时间序列模型
关于标准回归技术及其预测和检验我们已经在 前面的章节讨论过了,本章着重于时间序列模型的估 计和定义,这些分析均是基于单方程回归方法。
这一部分属于动态计量经济学的范畴。通常是运 用时间序列的过去值、当期值及滞后扰动项的加权和 建立模型,来“解释”时间序列的变化规律。
2019/8/8