概率图模型中的推断
概率图模型的推理方法详解(Ⅰ)

概率图模型的推理方法详解概率图模型是一种用图来表示随机变量之间依赖关系的数学模型。
它通过图的节点表示随机变量,边表示随机变量之间的依赖关系,可以用来描述各种复杂的现实世界问题。
概率图模型包括了贝叶斯网络和马尔可夫网络两种主要类型,它们都可以用来进行推理,即根据已知的信息来推断未知的变量。
在本文中,将详细介绍概率图模型的推理方法,包括贝叶斯网络和马尔可夫网络的推理算法。
一、概率图模型概率图模型是一种用图来表示随机变量之间依赖关系的数学模型。
它通过图的节点表示随机变量,边表示随机变量之间的依赖关系,可以用来描述各种复杂的现实世界问题。
概率图模型包括了贝叶斯网络和马尔可夫网络两种主要类型。
贝叶斯网络是一种有向图模型,用来表示变量之间的因果关系;马尔可夫网络是一种无向图模型,用来表示变量之间的相关关系。
概率图模型可以用来进行概率推理,即根据已知的信息来推断未知的变量。
二、贝叶斯网络的推理方法在贝叶斯网络中,每个节点表示一个随机变量,每条有向边表示一个因果关系。
贝叶斯网络的推理方法主要分为两种:精确推理和近似推理。
1. 精确推理精确推理是指通过精确的计算来得到准确的推理结果。
常用的精确推理算法包括变量消去算法和团树传播算法。
变量消去算法通过逐步消去变量来计算联合概率分布,但是对于大型网络来说计算复杂度很高。
团树传播算法通过将网络转化为一个树状结构来简化计算,提高了计算效率。
2. 近似推理近似推理是指通过近似的方法来得到推理结果。
常用的近似推理算法包括马尔科夫链蒙特卡洛算法和变分推断算法。
马尔科夫链蒙特卡洛算法通过构建马尔科夫链来进行抽样计算,得到近似的概率分布。
变分推断算法通过将概率分布近似为一个简化的分布来简化计算,得到近似的推理结果。
三、马尔可夫网络的推理方法在马尔可夫网络中,每个节点表示一个随机变量,每条无向边表示两个变量之间的相关关系。
马尔可夫网络的推理方法主要分为两种:精确推理和近似推理。
1. 精确推理精确推理是指通过精确的计算来得到准确的推理结果。
概率图模型的推理方法详解(七)

概率图模型的推理方法详解概率图模型(Probabilistic Graphical Models,PGMs)是一种用来表示和推断概率分布的工具。
它是通过图的形式来表示变量之间的依赖关系,进而进行推理和预测的。
概率图模型主要分为贝叶斯网络(Bayesian Network)和马尔科夫网络(Markov Network)两种类型。
本文将从推理方法的角度对概率图模型进行详细解析。
1. 参数化概率图模型的推理方法参数化概率图模型是指模型中的概率分布由参数化的形式给出,如高斯分布、伯努利分布等。
对于这种类型的概率图模型,推理的关键是求解潜在的参数,以及根据参数进行概率分布的推断。
常见的方法包括极大似然估计、期望最大化算法和变分推断等。
极大似然估计是一种常用的参数估计方法,它通过最大化观测数据的似然函数来求解模型的参数。
具体来说,对于给定的数据集,我们可以计算出参数θ下观测数据的似然函数L(θ)。
然后求解参数θ使得似然函数最大化,即max L(θ)。
这样得到的参数θ就是在给定数据下最合理的估计。
期望最大化算法(Expectation-Maximization,EM)是一种迭代算法,用于在潜变量模型中求解模型参数。
EM算法的基本思想是通过迭代交替进行两个步骤:E步骤(Expectation),求解潜变量的期望;M步骤(Maximization),根据求得的期望最大化似然函数。
通过反复迭代这两个步骤,最终可以得到模型的参数估计。
变分推断(Variational Inference)是一种近似推断方法,用于在概率图模型中求解后验分布。
变分推断的核心思想是通过在一些指定的分布族中寻找一个最接近真实后验分布的分布来近似求解后验分布。
具体来说,我们可以定义一个变分分布q(θ)来逼近真实的后验分布p(θ|D),然后通过最小化变分分布与真实后验分布的KL散度来求解最优的变分分布。
2. 非参数化概率图模型的推理方法非参数化概率图模型是指模型中的概率分布不是由有限的参数化形式给出,而是通过一些非参数的方式来表示概率分布,如核密度估计、Dirichlet过程等。
概率图模型在因果推断、不确定性推理、决策分析、贝叶斯网络等领域的应用研究

概率图模型在因果推断、不确定性推理、决策分析、贝叶斯网络等领域的应用研究摘要概率图模型 (Probabilistic Graphical Model, PGM) 是一种强大的工具,用于表示和推理复杂系统中的不确定性关系。
它通过将变量之间的依赖关系以图的形式表示,结合概率论,对现实世界问题进行建模和分析。
本文将重点探讨概率图模型在因果推断、不确定性推理、决策分析、贝叶斯网络等领域的应用研究。
关键词:概率图模型,因果推断,不确定性推理,决策分析,贝叶斯网络1. 引言在现实世界中,我们经常面临着充满不确定性的问题。
概率图模型提供了一种结构化的框架,帮助我们理解和分析这些不确定性。
它将变量之间的依赖关系以图的形式表示,并将概率论融入其中,以进行推断和预测。
概率图模型的应用范围非常广泛,涵盖了机器学习、人工智能、计算机视觉、自然语言处理、生物信息学等多个领域。
本文将重点探讨概率图模型在以下四个领域的应用研究:*因果推断: 识别变量之间的因果关系,并进行因果推断。
*不确定性推理: 在不确定性环境下进行推理和决策。
*决策分析: 利用概率图模型进行决策分析,选择最佳策略。
*贝叶斯网络: 作为概率图模型的一种特殊类型,在各个领域得到了广泛应用。
2. 概率图模型基础概率图模型由两部分组成:图结构和概率分布。
图结构表示变量之间的依赖关系,而概率分布则量化了变量的概率信息。
*图结构: 图结构由节点和边组成。
每个节点表示一个随机变量,边则表示变量之间的依赖关系。
常见的图结构类型包括:o有向图:边表示变量之间的因果关系。
o无向图:边表示变量之间的相关性。
o混合图:包含有向边和无向边。
*概率分布: 概率分布定义了变量的概率信息。
常用的概率分布包括:o离散概率分布:例如,伯努利分布、多项式分布。
o连续概率分布:例如,高斯分布、指数分布。
概率图模型的优点在于:*结构化的表示: 图结构可以直观地表示变量之间的依赖关系,便于理解和分析。
概率图模型与因果推断的关系与应用(九)

概率图模型与因果推断的关系与应用概率图模型和因果推断是统计学和机器学习领域中两个重要的概念。
它们之间的关系密切,应用广泛。
本文将探讨概率图模型与因果推断的关系,并讨论它们在科学研究和实际应用中的重要性。
概率图模型是一种用图形结构来表达随机变量之间依赖关系的模型。
常见的概率图模型包括贝叶斯网络和马尔可夫网络。
贝叶斯网络是一种有向无环图,用于表示变量之间的因果关系;马尔可夫网络是一种无向图,用于表示变量之间的相关关系。
概率图模型能够清晰地表示变量之间的依赖关系,为因果推断提供了重要的工具。
因果推断是指通过观察数据来推断变量之间的因果关系。
在现实世界中,很多变量之间存在因果关系,例如吸烟与肺癌的关系、教育水平与收入的关系等。
因果推断可以帮助我们理解变量之间的因果关系,从而制定合理的政策和决策。
概率图模型与因果推断之间的关系在于,概率图模型可以用来表示变量之间的因果关系,从而帮助我们进行因果推断分析。
特别是贝叶斯网络,它能够清晰地表示变量之间的因果关系,并且可以利用贝叶斯推断的方法来进行因果推断分析。
因此,概率图模型在因果推断中具有重要的应用价值。
在科学研究中,概率图模型与因果推断被广泛应用。
例如,在医学研究中,研究人员可以利用概率图模型来建立疾病与风险因素之间的关系,从而进行因果推断分析,帮助医生制定有效的治疗方案。
在经济学研究中,研究人员可以利用概率图模型来建立经济变量之间的因果关系,从而进行政策效果评估和决策支持。
在环境科学研究中,研究人员可以利用概率图模型来建立环境变量与自然灾害之间的关系,从而进行风险评估和应急预案制定。
可见,概率图模型与因果推断在科学研究中具有重要的应用意义。
除了科学研究领域,概率图模型与因果推断在实际应用中也发挥着重要作用。
在医疗保健领域,医生可以利用概率图模型与因果推断来诊断疾病和评估治疗效果,从而提高医疗质量和患者生存率。
在金融领域,投资者可以利用概率图模型与因果推断来分析市场变量之间的因果关系,从而进行风险管理和投资决策。
如何使用马尔可夫链蒙特卡洛进行概率模型推断(六)

马尔可夫链蒙特卡洛(MCMC)是一种用于概率模型推断的强大工具。
它可以帮助我们在复杂的概率模型中进行参数估计、模型比较和预测。
在本文中,我们将讨论MCMC的基本原理、常见算法和一些实际应用。
一、基本原理MCMC的基本原理是利用马尔可夫链来生成模型参数的样本,从而近似计算参数的后验分布。
马尔可夫链是一种具有马尔可夫性质的随机过程,即在给定当前状态下,未来状态的转移只依赖于当前状态,而与过去状态无关。
在MCMC算法中,我们首先选择一个初始参数值作为链的起始点,然后根据一定的转移规则生成下一个状态。
这个过程重复进行,直到生成的样本达到一定的数量,然后我们可以利用这些样本来估计参数的后验分布。
二、常见算法Gibbs抽样是MCMC算法中的一种常见方法。
它适用于高维参数的后验分布推断。
Gibbs抽样的基本思想是对每个参数进行条件抽样,即在给定其他参数的取值时,抽取当前参数的样本。
这样就可以得到参数的联合分布,从而近似计算参数的后验分布。
另一种常见的MCMC算法是Metropolis-Hastings算法。
它是一种接受-拒绝采样方法,可以用于任意维度的参数空间。
Metropolis-Hastings算法通过接受或拒绝提议的参数值来生成马尔可夫链,从而近似计算参数的后验分布。
除了这两种基本的MCMC算法之外,还有许多其他改进的算法,如Hamiltonian Monte Carlo、No-U-Turn Sampler等,它们在不同的概率模型中具有更快的收敛速度和更高的采样效率。
三、实际应用MCMC在概率模型推断中有着广泛的应用。
它可以用于贝叶斯统计推断、概率图模型的学习和推断、以及神经网络的参数估计等领域。
在贝叶斯统计推断中,MCMC可以用来估计参数的后验分布,从而进行模型比较和预测。
它还可以用于参数的贝叶斯推断,比如对参数的置信区间进行估计和预测。
在概率图模型中,MCMC可以用来进行精确推断和近似推断。
它可以帮助我们在复杂的概率图模型中进行参数学习和概率推断,从而实现对未知变量的预测和推理。
如何进行模型推断和概率推理

如何进行模型推断和概率推理模型推断和概率推理是统计学和概率论中重要的概念。
在机器学习和人工智能领域中,模型推断和概率推理经常被用于对数据进行分析、预测和决策。
模型推断(Model Inference)指的是从观测到的数据中推断出潜在模型的参数或结构。
模型可以是统计模型、机器学习模型或深度学习模型。
模型推断通常基于数据的最大似然估计(MaximumLikelihood Estimation,简称MLE)或贝叶斯推断(Bayesian Inference)。
最大似然估计是一种常用的模型推断方法。
其基本思想是找到模型参数的值,使得在给定数据的前提下,发生观测到数据的概率最大。
在给定一个模型的参数下,我们可以计算观测到数据的概率,即似然函数(Likelihood Function)。
然后,通过求解似然函数的最大值,得到最大似然估计的参数。
贝叶斯推断是另一种常用的模型推断方法。
它结合了先验概率和观测到数据的概率,通过贝叶斯定理来推断模型参数。
贝叶斯推断的基本思想是将模型参数视为随机变量,并基于先验概率和数据的似然函数来计算后验概率分布。
后验概率分布反映了参数的不确定性,并可以用于进行预测、决策和模型评估。
概率推理(Probabilistic Reasoning)是基于概率模型和已知条件进行推理和推断的过程。
概率推理用于推断未知变量的概率分布,基于已知变量和模型参数的信息。
它可以用于数据的分类、回归、聚类、异常检测等任务。
贝叶斯网络和马尔可夫随机场(Markov Random Field, MRF)是常用的概率模型,用于概率推理。
贝叶斯网络是一种图模型,用于表示变量之间的依赖关系,并通过条件概率分布进行推断。
马尔可夫随机场是一种无向图模型,用于建模空间上的变量和它们之间的关系。
概率推理可以通过基于概率模型参数和已知条件的推断方法来实现。
常用的推理算法包括前向算法(Forward Algorithm)、后向算法(Backward Algorithm)、变量消去算法(Variable Elimination Algorithm)和信念传播算法(Belief Propagation Algorithm)等。
机器学习 —— 概率图模型(推理:团树算法)
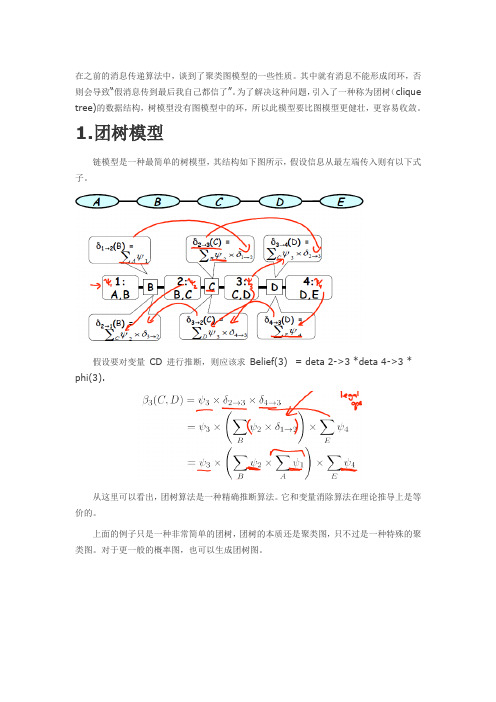
在之前的消息传递算法中,谈到了聚类图模型的一些性质。
其中就有消息不能形成闭环,否则会导致“假消息传到最后我自己都信了”。
为了解决这种问题,引入了一种称为团树(clique tree)的数据结构,树模型没有图模型中的环,所以此模型要比图模型更健壮,更容易收敛。
1.团树模型链模型是一种最简单的树模型,其结构如下图所示,假设信息从最左端传入则有以下式子。
假设要对变量CD 进行推断,则应该求Belief(3) = deta 2->3 *deta 4->3 * phi(3).从这里可以看出,团树算法是一种精确推断算法。
它和变量消除算法在理论推导上是等价的。
上面的例子只是一种非常简单的团树,团树的本质还是聚类图,只不过是一种特殊的聚类图。
对于更一般的概率图,也可以生成团树图。
其中,每个cluster都是变量消除诱导图中的一个最小map。
2.团树模型的计算从上面分析可知,团树模型本质上和变量消除算法还有说不清道不明的关系(团树模型也是精确推理模型)。
但是这个算法的优势在于,它可以利用消息传递机制达到收敛。
之前提过,聚类图模型中的收敛指的是消息不变。
除此之外,聚类图的本质是一种数据结构,它可以储存很多中间计算结果。
如果我们有很多变量ABCDEF,那么我们想知道P(A),则需要执行一次变量消除。
如果要计算P(B)又要执行一次变量消除。
如果中途得到了某个变量的观测,又会对算法全局产生影响。
但是使用团树模型可以巧妙的避免这些问题。
首先,一旦模型迭代收敛之后。
所有的消息都是不变的,每个消息都是可以被读取的。
每个团的belief,实际上就是未归一划的联合概率,要算单个变量的概率,只需要把其他的变量边际掉就行。
这样一来,只需要一次迭代收敛,每个变量的概率都是可算的。
并且算起来方便。
其次,如果对模型引入先验知识比如A = a 时,我们需要对D 的概率进行估计。
按照变量消除的思路又要从头来一次。
但是如果使用团树结构则不用,因为A的取值只影响deta1->2以及左向传递的消息,对右向传递的消息则毫无影响,可以保留原先对右向传递消息的计算值,只重新计算左向传递结果即可。
概率图模型的推理方法详解(十)

概率图模型的推理方法详解概率图模型是一种用于描述随机变量之间关系的数学工具,它通过图的形式表示变量之间的依赖关系,并利用概率分布来描述这些变量之间的关联。
在概率图模型中,常用的两种图结构是贝叶斯网络和马尔可夫随机场。
而推理方法则是通过已知的观测数据来计算未知变量的后验概率分布,从而进行推断和预测。
一、贝叶斯网络的推理方法贝叶斯网络是一种有向无环图,它由节点和有向边组成,每个节点表示一个随机变量,有向边表示变量之间的依赖关系。
在贝叶斯网络中,推理问题通常包括给定证据条件下计算目标变量的后验概率分布,以及对未观测变量进行预测。
常用的推理方法包括变量消去法、固定证据法和采样法。
变量消去法是一种精确推理方法,它通过对贝叶斯网络进行变量消去来计算目标变量的后验概率分布。
这种方法的优点是计算结果准确,但当网络结构复杂时,计算复杂度会很高。
固定证据法是一种近似推理方法,它通过将已知的证据变量固定,然后对目标变量进行推理。
这种方法的优点是计算速度快,但结果可能不够准确。
采样法是一种随机化推理方法,它通过蒙特卡洛采样来计算目标变量的后验概率分布。
这种方法的优点是可以处理复杂的网络结构,但计算效率较低。
二、马尔可夫随机场的推理方法马尔可夫随机场是一种无向图,它由节点和边组成,每个节点表示一个随机变量,边表示变量之间的依赖关系。
在马尔可夫随机场中,推理问题通常包括给定证据条件下计算目标变量的后验概率分布,以及对未观测变量进行预测。
常用的推理方法包括置信传播法、投影求解法和拉普拉斯近似法。
置信传播法是一种精确推理方法,它通过消息传递算法来计算目标变量的后验概率分布。
这种方法的优点是计算结果准确,但当网络结构复杂时,计算复杂度会很高。
投影求解法是一种近似推理方法,它通过对目标变量进行投影求解来计算后验概率分布。
这种方法的优点是计算速度快,但结果可能不够准确。
拉普拉斯近似法是一种随机化推理方法,它通过拉普拉斯近似来计算目标变量的后验概率分布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
概率图模型中的推断王泉中国科学院大学网络空间安全学院2016年11月•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用•已知联合概率分布 P x1,⋯,x n ,估计 –x Q 问题变量;x E 证据变量;x Q ∪x E =x 1,⋯,x nP R =1 P R =0 0 P R =1G =1= ? P B =0.001 P E =0.002 P A B ,E =0.95 P A B ,¬E =0.94 P A ¬B ,E =0.29 P A ¬B ,¬E =0.001P J A =0.9 P J ¬A =0.05 P M A =0.7 P M ¬A =0.01 P B =1E =0,J =1=? P x Q x E =x Q ,x E x E•已知联合概率分布 P x 1,⋯,x n ,估计 –x Q 问题变量;x E 证据变量;x Q ∪x E =x 1,⋯,x n P x Q x E =x Q ,x E x E观测图片 y i 原始图片 x i y �=argmax P y x 朴素贝叶斯x�=argmax P x y 图像去噪•精确推断:计算P x Q x E的精确值–变量消去 (variable elimination)–信念传播 (belief propagation)–计算复杂度随着极大团规模的增长呈指数增长,适用范围有限•近似推断:在较低的时间复杂度下获得原问题的近似解–前向采样 (forward sampling)–吉布斯采样 (Gibbs sampling)–通过采样一组服从特定分布的样本,来近似原始分布,适用范围更广,可操作性更强•精确推断:计算P x Q x E的精确值–变量消去 (variable elimination)–信念传播 (belief propagation)–计算复杂度随着极大团规模的增长呈指数增长,适用范围有限•近似推断:在较低的时间复杂度下获得原问题的近似解–前向采样 (forward sampling)–吉布斯采样 (Gibbs sampling)–通过采样一组服从特定分布的样本,来近似原始分布,适用范围更广,可操作性更强目录•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用精确推断•已知联合概率分布P x 1,⋯,x n,计算P x Q x E=x Q,x E x E=x Q,x E–x Q问题变量;x E证据变量;x Q∪x E=x1,⋯,x n–问题的关键:如何高效地计算边际分布P x E=∑P x Q,x Ex Q目录•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用•动机:将变量消去过程中产生的中间结果视为可复用的消息 (message),避免重复计算•消息传递与边际分布–•消息传递与边际分布––•二次扫描算法 (two-pass algorithm)–指定一个根节点,从所有叶节点开始向根节点传递消息,直到根节点收到所有邻接节点的消息–从根节点开始向叶节点传递消息,直到所有叶节点均收到消息目录•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用•隐马尔可夫模型 (hidden Markov model) 是关于时序的概率模型,是最简单的动态贝叶斯网络–状态变量y1,y2,⋯,y n,y t∈Y表示第t时刻的系统状态–观测变量x1,x2,⋯x n,x t∈X表示第t时刻的观测值–观测变量仅依赖于当前时刻的状态变量,即x t由y t确定–当前状态仅依赖于前一时刻的状态,即y t t−1–Y≔s1,s2,⋯,s N o1,o2,⋯,o M•隐马尔可夫模型的三要素 –状态转移概率矩阵 A =a ij N ×N •在时刻 t 处于状态 s i 的条件下在下一时刻转移到状态 s j 的概率 –观测概率矩阵 B =b ij N ×M•在时刻 t 处于状态 s i 的条件下观测到 o j 的概率 –初始状态概率向量 π=π1,π2,⋯,πN•系统的初始状态为 s a ij =P y t+1=s j y t =s i ,1≤i ,j ≤N b ij =P x t =o j y t =s i ,1≤i ≤N ,1≤j ≤Mπi =P y 1=s i ,1≤i ≤N•有向树转化为无向树初始状态概率:P y1状态转移概率:P y t y t−1观测概率:P x t y tψy1=P y1,ψx1=1ψy t=ψx t=1,t=2,⋯,nψy t−1,y t=P y t y t−1ψx t,y t=P x t y t•二次扫描算法•第一次扫描:从左向右–从观测变量向相应状态变量传递的消息•第一次扫描:从左向右–从观测变量向相应状态变量传递的消息m x t→y t s i=P x t y t=s i=b i x t•第一次扫描:从左向右–从当前状态变量向下一状态变量传递的消息m y1→y2=�ψy1ψy1,y2m x1→y1y1∈Y=�P y1P y2y1P x1y1y1∈Y m y t→y t+1=�ψy tψy t,y t+1m y t−1→y t m x t→y t y t∈Y=�m y t−1→y t P y t+1y t P x t y ty t∈Y•第一次扫描:从左向右–从当前状态变量向下一状态变量传递的消息m y1→y2=�ψy1ψy1,y2m x1→y1y1∈Y=�P y1P y2y1P x1y1y1∈Y m y t→y t+1=�ψy tψy t,y t+1m y t−1→y t m x t→y t y t∈Y=�m y t−1→y t P y t+1y t P x t y ty t∈Ym y0→y1t=2,⋯,n−1•第一次扫描:从左向右–从当前状态变量向下一状态变量传递的消息•第一次扫描:从左向右–从当前状态变量向下一状态变量传递的消息m y 0→y 1s i =P y 1=s i =πi ,m y t →y t+1s i =�m y t−1→y t s j a ji b j x t N•第二次扫描:从右向左–从当前状态变量向上一状态变量传递的消息m y n→y n−1=�ψy nψy n−1,y n m x n→y ny n∈Y=�P y n y n−1P x n y ny n∈Y m y t→y t−1=�ψy tψy t−1,y t m y t+1→y t m x t→y t y t∈Y=�m y t+1→y t P y t y t−1P x t y ty t∈Y•第二次扫描:从右向左–从当前状态变量向上一状态变量传递的消息m y n →y n−1=�ψy n ψy n−1,y n m x n →y n y n ∈Y =�P y n y n−1P x n y n y n ∈Y ×1 m y t →y t−1=�ψy t ψy t−1,y t m y t+1→y t m x t →y t y t ∈Y =�m y t+1→y t P y t y t−1P x t y t y t ∈Ym y n+1→y n =1•第二次扫描:从右向左–从当前状态变量向上一状态变量传递的消息•第二次扫描:从右向左–从当前状态变量向上一状态变量传递的消息Ny n+1→y n s i y t→y t−1s i y t+1→y t s j ij j x t•第二次扫描:从右向左–从状态变量向当前观测变量传递的消息•第二次扫描:从右向左–从状态变量向当前观测变量传递的消息y t →x t x t i x t y t−1→y t s i y t+1→y t s i N•计算条件概率 P y t =s i x 1,⋯,x nP x 1,⋯,x n ,y t =ψy t m x t →y t m y t−1→y t m y t+1→y t =P x t y t m y t−1→y t m y t+1→y t P y t =s i x 1,⋯,x n =P x 1,⋯,x n ,y t =s i P x 1,⋯,x n ,y t =s i N i=1=b i x t m y t−1→y t s i m y t+1→y t s i b i x t m y t−1→y t s i m y t+1→y t s iN i=1•计算条件概率P y t=s i,y t+1=s j x1,⋯,x nP x1,⋯,x n,y t,y t+1=ψy t,y t+1m x t→y t m x t+1→y t+1m y t−1→y t m y t+2→y t+1=P y t+1y t x t y t x t+1y t+1→y t+1 P y t=s i,y t+1=s j x1,⋯,x n=目录•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用•推断:估计条件概率 P x Q x E•基于采样的近似推断–根据 P x Q x E 抽取一组样本 x 1,⋯,x m –计算 1x Q =c Q 在这组样本上的均值来近似 P x Q =c Q x E–问题的关键:如何高效地根据特定概率分布来抽取样本 近似推断P x Q =c Q x E ≈1m �1x m =c Q m i=1目录•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用•直接依照条件概率P x Q x E采样Procedure Gibbs Sampling1 Fix x E and randomly initialize other variables x O≔x1,⋯,x n\x E2 repeat3 foreach x i∈x O do4 Sample x~P x i x1,⋯,x i−1,x i+1,⋯,x n/* x i在其他所有变量当前取值下的条件概率 */5 x i←x6 until Convergence7 return The later samples•直接依照条件概率 P x Q x E 采样–直接从 P x Q x E 采样,解决小概率事件采样难问题 –同时适用于贝叶斯网络和马尔可夫随机场–简单易推导,时间和空间开销合理目录•推断问题回顾•精确推断:信念传播–信念传播算法回顾–信念传播在HMM中的应用•近似推断:吉布斯采样–吉布斯采样算法回顾–吉布斯采样在LDA中的应用•LDA (latent Dirichlet allocation) 是最具代表性的话题模型,属于贝叶斯网络,主要用于挖掘文本数据中潜藏的概念 –话题是词上的分布•ϕt =ϕt1,ϕt2,⋯,ϕtt ,∑ϕtt t t=1=1 •ϕti :第 i 个词在话题中的比重–文档是话题上的分布•θd =θd1,θd2,⋯,θdd ,∑θdt d t=1=1•θdi :第 i 个话题在文档中的比重–文档中的词由话题混合生成 •根据文档在话题上的分布生成话题标号•再根据相应话题在词上的分布生成词 LDA 回顾•狄利克雷分布 (Dirichlet distribution) –参数 α≔α1,⋯,αK ,其中 αk >0–样本空间 x ≔x 1,⋯,x K x k <1 并且 ∑x k K k=1=1–概率分布函数–Γ∙ 是Gamma 函数,满足 Γx +1=xΓx P x α=αk k=1Γαk k=1�x k αk −1K k=1•多项分布 (multinomial distribution)–参数p1,⋯,p K,其中 0<p k<1 并且∑p k K k=1=1–样本空间x∈1,⋯,K–概率分布函数P x=k=p kP x=p11[x=1]⋯p K1[x=K]•模型结构和生成过程Procedure Generative process for LDA1 For each topic t2 Draw word distribution ϕt~Dirichletβ3 For each document d4 Draw topic distribution θd~Dirichletα5 For each word position in d6 Draw topic index z~Multinomialθd7 Draw word w~Multinomialϕz•推断问题:P z w,α,β•采样关键步骤:z i~P z i=t w,z−i,α,β•推断问题:P z w,α,β•采样关键步骤:z i~P z i=t w,z−i,α,βP z i=t w,z−i,α,β=w,z,α,β=P w,z,α,βw−i,z−i,α,βw−i,z−i,α,β∝w,z,α,β=w,zα,β•推断问题:P z w,α,β•采样关键步骤:z i~P z i=t w,z−i,α,βP z i=t w,z−i,α,β=w,z,α,β=P w,z,α,βw−i,z−i,α,βw−i,z−i,α,β∝w,z,α,βP w−i,z−i,α=w,zα,βP w,zα,β=�P w,z,Φ,Θα,βdΦdΘ=�PΘαPΦβP zΘP w z,ΦdΦdΘ•推断问题:P z w ,α,β•采样关键步骤:z i z i =t w ,z −i ,α,β P Θα=�P θd αD d=1=�D d=1P Φβ=�P ϕt βdt=1=�d t=1P z Θ=�P z d θd D d=1=��θd ,t n d ,t d t=1D d=1 n d ,t 表示文档 d 中被指派给话题 t 的词汇数目 w z ,Φw t ϕt d n t ,v t d•推断问题:P z w ,α,β•采样关键步骤:z ~P z i =t w ,z −i ,α,β P zi =t w ,z −i ,α,β∝w ,z α,β=×从当前文档抽取话题 t 从话题 t 中生成相应的观测词 v阅读材料•KDD 2012 tutorial:Graphical Models–http://119.90.25.44//~jerryzhu/pub/ZhuKDD12.pdf •CMU 课程:Probabilistic Graphical Models–/~epxing/Class/10708/。