结构方程模型案例汇总
结构方程模型在金融案例研究中的应用

结构方程模型在金融案例研究中的应用近年来,结构方程模型已经成为许多社会科学研究的重要工具之一,其中包括金融领域。
通过结构方程模型,研究人员可以评估不同变量之间的关系,并探究这些关系对金融决策的影响。
在本文中,我们将探讨结构方程模型在金融案例研究中的应用。
一、背景介绍金融领域的研究往往需要考虑多个变量,这些变量之间的相互作用可能非常复杂,因此需要一种相对完备的统计模型来评估它们之间的关系。
在这种情况下,结构方程模型已成为一个常用的工具。
结构方程模型是一种多变量统计模型,可以用来研究多个因果变量之间的关系。
这种模型可以用来评估一个变量的影响,以及其他变量之间的直接和间接影响。
它还可以在多个模型之间进行比较,以寻找最佳拟合解,从而得到更准确的预测和结论。
二、结构方程模型的基本原理结构方程模型的基本原理可以通过以下步骤来说明:1. 指定模型:首先,研究人员需要指定一个结构方程模型,其中包括测量模型和结构模型。
测量模型是指定义测量指标和构造指标所依赖的潜在变量之间关系的模型。
结构模型是指定义因果关系的模型。
2. 估计参数:研究人员需要使用统计软件来估计模型中的参数。
这些参数包括指标因子载荷、潜变量之间的协方差、以及结构模型中的回归系数和误差项方差。
3. 模型拟合:研究人员需要评估模型的拟合度,这可以通过计算各种统计指标来完成。
例如,可以计算似然比统计量、均方误差逼近(RMSEA)和比较拟合指数(CFI)等指标。
4. 模型修正:如果模型拟合度不佳,研究人员可能需要对模型进行修改。
这可以包括添加或删除指标、调整因素载荷或回归系数等。
5. 模型解释:最后,研究人员可以使用拟合的结构方程模型来解释不同变量之间的关系,并生成有关影响金融决策的结论。
三、结构方程模型在金融案例研究中的应用结构方程模型已经应用于许多金融案例研究中,以下是一些例子:1. 信用风险评估:结构方程模型可以用于评估不同因素对贷款违约率的影响。
例如,一个研究人员可以使用一个结构方程模型来探究个人信用得分、收入、工作经验等因素对违约率的影响,并确定哪些因素最有影响力。
以结构方程模型为例-精品文档

以结构方程模型为例一、引言在20世纪的大部分时间里,由实证主义支撑的定量方法主宰着社会科学研究领域,研究者信奉价值中立“客观的”实证方法来研究人类行为和社会现象。
在人文社会科学领域,定性研究方法也有着久远的历史脉络。
20世纪60年代定性研究出现严重危机,对于定量研究话语霸权反抗,这一时期在北美地区,格拉泽和斯特劳斯提出扎根理论,为定性研究挽救了些许余地。
定性方法的出现源于20世纪最后20所发生的所谓“定性革命”,其出现受到了相关的重视。
“混合方法”一种结合定性方法和定量方法的结合,产生于两大阵营的长期争论对垒中。
他是一种未预料的结果,尽管这种方法仍未完全成熟,但是作为定性和定量之外的第三种选择,逐渐被西方学者看成是“第三条道路”国内学者沈崇麟(2011)指出定性和定量的结合有以下三个新趋势:①将质性数据尽可能量化,用统计分析来验证理论假设。
②多元方法论,在应用过程中,通过核心概念的测量模型,把质性研究和量化研究结合在一起。
③量化研究者对过度形式化的量化方法不满,试图通过质性方法弥补量化研究的不足。
如杜晓新等在研究中所说,结构方程模型为定性与定量分析的结合提供了有效的手段,但都未做出进一步的讨论,本研究从定量分析方法的结构方程模型原理和步骤来解析定性中代表性的扎根理论,以此为切入点讨论定性和定量的融合。
二、结构方程模型和扎根理论(一)结构方程模型简介上世纪70年代,由K?Joreskog等人提出了结构方程模型(Structureal Equation Modeling SEM)至80年代相应的数据分析软件LISREL已经趋成熟,被称为近年来统计学三大发展之一。
从90年代初至今,其在社会科学研究领域中已得到了广泛的应用。
结构方程模型属于高级定量统计方法,同时考虑了多个变量的相互影响,从多个维度考察事物的性质。
允许变量含测量误差,结构方程模型包含了方差分析、回归分析、路径分析等统计分析技术,还有诸如聚类、迭代、拟合等定量的方法,弥补了传统回归和因子分析的不足。
结构方程SEM模型案例分析

结构方程SEM模型案例分析什么是SEM模型?结构方程模型(Structural equation modeling, SEM)是一种融合了因素分析和路径分析的多元统计技术。
它的强势在于对多变量间交互关系的定量研究。
在近三十年内,SEM大量的应用于社会科学及行为科学的领域里,并在近几年开始逐渐应用于市场研究中.顾客满意度就是顾客认为产品或服务是否达到或超过他的预期的一种感受。
结构方程模型(SEM)就是对顾客满意度的研究采用的模型方法之一。
其目的在于探索事物间的因果关系,并将这种关系用因果模型、路径图等形式加以表述。
如下图:图: SEM模型的基本框架在模型中包括两类变量:一类为观测变量,是可以通过访谈或其他方式调查得到的,用长方形表示;一类为结构变量,是无法直接观察的变量,又称为潜变量,用椭圆形表示。
各变量之间均存在一定的关系,这种关系是可以计算的。
计算出来的值就叫参数,参数值的大小,意味着该指标对满意度的影响的大小,都是直接决定顾客购买与否的重要因素。
如果能科学地测算出参数值,就可以找出影响顾客满意度的关键绩效因素,引导企业进行完善或者改进,达到快速提升顾客满意度的目的。
SEM的主要优势第一,它可以立体、多层次的展现驱动力分析。
这种多层次的因果关系更加符合真实的人类思维形式,而这是传统回归分析无法做到的。
SEM根据不同属性的抽象程度将属性分成多层进行分析。
第二,SEM分析可以将无法直接测量的属性纳入分析,比方说消费者忠诚度。
这样就可以将数据分析的范围加大,尤其适合一些比较抽象的归纳性的属性。
第三,SEM分析可以将各属性之间的因果关系量化,使它们能在同一个层面进行对比,同时也可以使用同一个模型对各细分市场或各竞争对手进行比较。
SEM模型案例分析某通信分公司屡次位居榜尾,于是痛下决心改革。
该分公司有三类业务:固话业务、小灵通业务以及上网业务。
围绕着这三类业务产品的销售,该通信分公司还提供了售前、售中和售后三个环节多方面的服务。
结构方程模型估计案例
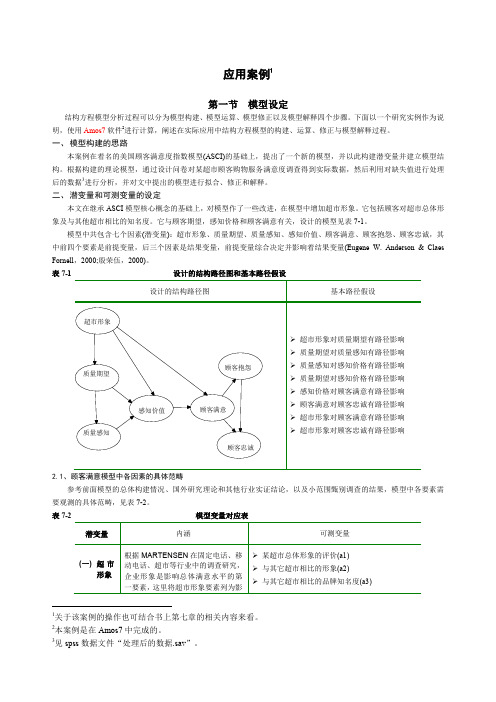
应用案例1第一节 模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、 模型构建的思路本案例在着名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、 潜变量和可测变量的设定本文在继承ASCI 模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell ,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2 模型变量对应表1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,7个人口变量,量表采用了Likert10级量度,如对超市形象的测量:本次调查共发放问卷500份,收回有效样本436份。
AMOS结构方程模型修正经典案例

AMOS结构方程模型修正经典案例第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
2.1、顾客满意模型中各因素的具体范畴1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav”。
参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,3正向的,采用Likert10级量度从“非常低”到“非常高”本次调查共发放问卷500份,收回有效样本436份。
结构方程模型估计案例

应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2 模型变量对应表1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
三、关于顾客满意调查数据的收集4正向的,采用Likert10级量度从“非常低”到“非常高”本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
结构方程模型估计案例
结构⽅程模型估计案例应⽤案例1第⼀节模型设定结构⽅程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下⾯以⼀个研究实例作为说明,使⽤Amos7软件2进⾏计算,阐述在实际应⽤中结构⽅程模型的构建、运算、修正与模型解释过程。
⼀、模型构建的思路本案例在着名的美国顾客满意度指数模型(ASCI)的基础上,提出了⼀个新的模型,并以此构建潜变量并建⽴模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利⽤对缺失值进⾏处理后的数据3进⾏分析,并对⽂中提出的模型进⾏拟合、修正和解释。
⼆、潜变量和可测变量的设定本⽂在继承ASCI模型核⼼概念的基础上,对模型作了⼀些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相⽐的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & ClaesFornell,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设超市形象对质量期望有路径影响质量期望对质量感知有路径影响质量感知对感知价格有路径影响质量期望对感知价格有路径影响感知价格对顾客满意有路径影响顾客满意对顾客忠诚有路径影响超市形象对顾客满意有路径影响超市形象对顾客忠诚有路径影响、顾客满意模型中各因素的具体范畴参考前⾯模型的总体构建情况、国外研究理论和其他⾏业实证结论,以及⼩范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2 模型变量对应表某超市总体形象的评价(a1)与其它超市相⽐的形象(a2)1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
结构方程模型估计案例
结构方程模型估计案例 Prepared on 22 November 2020应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在着名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2 模型变量对应表1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
4正向的,采用Likert10级量度从“非常低”到“非常高”(七) 顾客忠诚顾客忠诚主要可以从三个方面体现:顾客推荐意向、转换产品的意向、重复购买的意向。
同时还有学者指出顾客忠诚可以从顾客对涨价的容忍性、重复购买性两方面衡量。
结构方程模型估计案例
结构方程模型估计案例
一、案例背景
本案例涉及一所位于美国的研究型大学,本案例旨在通过结构方程模
型估计学生参与大学课程的因素。
为此,本案例采用了一份包含180个受
访者的调查数据,每个受访者均为本校大学生。
二、研究假设
●学生投入的时间越多,他们的学习成绩就会越高。
●当学生有充足的资源可用时,他们的学习成绩会更高。
●学生对学习任务的兴趣和动机越高,他们的学习成绩也会越高。
●学生的学习成绩受到家庭背景和家庭环境的影响。
三、研究模型
本案例选择结构方程模型(SEM)进行模型估计,此模型包含四个变量,即学习时间(T)、学习资源(R)、兴趣/动机(I)和家庭环境(E)。
根据协方差矩阵,这四个变量都会对学生学习成绩(O)产生影响。
四、数据收集
本案例的数据收集工作包括:
1.对学生进行面对面访谈,收集学生投入课程的时间、学习资源、兴
趣/动机和家庭环境的信息,以及他们的学习成绩。
2.使用定量数据分析方法(如SPSS和AMOS)进行数据分析,以获得
研究要求的结果。
三、结构方程模型。
结构方程模型估计案例
应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明.使用Amos7软件2进行计算.阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上.提出了一个新的模型.并以此构建潜变量并建立模型结构。
根据构建的理论模型.通过设计问卷对某超市顾客购物服务满意度调查得到实际数据.然后利用对缺失值进行处理后的数据3进行分析.并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上.对模型作了一些改进.在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望.感知价格和顾客满意有关.设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚.其中前四个要素是前提变量.后三个因素是结果变量.前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell.2000;殷荣伍.2000)。
表7-1 设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论.以及小范围甄别调查的结果.模型中各要素需要观测的具体范畴.见表7-2。
表7-2 模型变量对应表1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
4正向的,采用Likert10级量度从“非常低”到“非常高”三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生).并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式.并且为避免样本的同质性和重复填写.按照性别和被访者经常光顾的超市进行控制。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
结构方程模型(Structural Equation Modeling,SEM)20世纪——主流统计方法技术:因素分析回归分析20世纪70年代:结构方程模型时代正式来临结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。
在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。
SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/因变量预测模型的参数估计。
结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。
实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。
多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。
结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。
在许多科学领域的研究中,有些变量并不能直接测量。
实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。
人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。
在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。
自变量测量误差的发生会导致常规回归模型参数估计产生偏差。
虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。
只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。
简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。
与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。
通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。
”目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus.结构方程模型包括测量方程(LV和MV之间关系的方程,外部关系)和结构方程(LV之间关系的方程,内部关系),以ACSI模型为例,具体形式如下:测量方程 y =Λy η+εy , x =Λx ξ+εx=(1)结构方程 η=B η+Гξ+ζ 或 (I-Β)η=Гξ+ζ (2)其中,η和ξ分别是内生LV 和外生LV ,y 和x 分别是和的MV ,Λx 和Λy 是载荷矩阵,Β和Г是路径系数矩阵,ε和ζ是残差。
三种分析方法对比线性相关分析:线性相关分析指出两个随机变量之间的统计联系。
两个变量地位平等,没有因变量和自变量之分。
因此相关系数不能反映单指标与总体之间的因果关系。
负荷量 潜在变量 观察变量 误差线性回归分析:线性回归是比线性相关更复杂的方法,它在模型中定义了因变量和自变量。
但它只能提供变量间的直接效应而不能显示可能存在的间接效应。
而且会因为共线性的原因,导致出现单项指标与总体出现负相关等无法解释的数据分析结果。
结构方程模型分析:结构方程模型是一种建立、估计和检验因果关系模型的方法。
模型中既包含有可观测的显在变量,也可能包含无法直接观测的潜在变量。
结构方程模型可以替代多重回归、通径分析、因子分析、协方差分析等方法,清晰分析单项指标对总体的作用和单项指标间的相互关系。
结构方程模型假设条件⑴合理的样本量(James Stevens的Applied Multivariate Statistics for the Social Sciences一书中说平均一个自变量大约需要15个case;Bentler and Chou (1987)说平均一个估计参数需要5个case就差不多了,但前提是数据质量非常好;这两种说法基本上是等价的;而Loehlin (1992)在进行蒙特卡罗模拟之后发现对于包含2~4个因子的模型,至少需要100个case,当然200更好;小样本量容易导致模型计算时收敛的失败进而影响到参数估计;特别要注意的是当数据质量不好比如不服从正态分布或者受到污染时,更需要大的样本量)⑵连续的正态内生变量(注意一种表面不连续的特例:underlying continuous;对于内生变量的分布,理想情况是联合多元正态分布即JMVN)⑶模型识别(识别方程)(比较有多少可用的输入和有多少需估计的参数;模型不可识别会带来参数估计的失败)⑷完整的数据或者对不完整数据的适当处理(对于缺失值的处理,一般的统计软件给出的删除方式选项是pairwise和listwise,然而这又是一对普遍矛盾:pairwise式的删除虽然估计到尽量减少数据的损失,但会导致协方差阵或者相关系数阵的阶数n参差不齐从而为模型拟合带来巨大困难,甚至导致无法得出参数估计;listwise不会有pairwise的问题,因为凡是遇到case中有缺失值那么该case直接被全部删除,但是又带来了数据信息量利用不足的问题——全杀了吧,难免有冤枉的;不杀吧,又难免影响整体局势)⑸模型的说明和因果关系的理论基础(实际上就是假设检验的逻辑——你只能说你的模型不能拒绝,而不能下定论说你的模型可以被接受)结构方程模型的技术特性:1.SEM具有理论先验性2.SEM同时处理测量与分析问题3.SEM以协方差的运用为核心,亦可处理平均数估计4.SEM适用于大样本的分析——一般而言,大于200以上的样本,才可称得上是一个中型样本。
5.SEM包含了许多不同的统计技术。
6.SEM重视多重统计指标的运用结构方程模型的实施步骤⑴模型设定。
研究者根据先前的理论以及已有的知识,通过推论和假设形成一个关于一组变量之间相互关系(常常是因果关系)的模型。
这个模型也可以用路径表明制定变量之间的因果联系。
⑵模型识别。
模型识别时设定SEM模型时的一个基本考虑。
只有建设的模型具有识别性,才能得到系统各个自由参数的唯一估计值。
其中的基本规则是,模型的自由参数不能够多于观察数据的方差和协方差总数。
⑶模型估计。
SEM模型的基本假设是观察变量的反差、协方差矩阵是一套参数的函数。
把固定参数之和自由参数的估计带入结构方程,推导方差协方差矩阵Σ,使每一个元素尽可能接近于样本中观察变量的方差协方差矩阵S中的相应元素。
也就是,使Σ与S之间的差异最小化。
在参数估计的数学运算方法中,最常用的是最大似然法(ML)和广义最小二乘法(GLS)。
⑷模型评价。
在已有的证据与理论范围内,考察提出的模型拟合样本数据的程度。
模型的总体拟合程度的测量指标主要有χ²检验、拟合优度指数(GFI)、校正的拟合优度指数(A GFI)、均方根残差(RMR)等。
关于模型每个参数估计值的评价可以用“t”值。
⑸模型修正。
模型修正是为了改进初始模型的适合程度。
当尝试性初始模型出现不能拟合观察数据的情况(该模型被数据拒绝)时,就需要将模型进行修正,再用同一组观察数据来进行检验。
探索性分析定义:探索性因子分析法(Exploratory Factor Analysis ,EFA )是一项用来找出多元观测变量的本质结构、并进行处理降维的技术。
因而,EFA 能够将将具有错综复杂关系的变量综合为少数几个核心因子。
探索性因子分析(EFA )致力于找出事物内在的本质结构。
探索性分析的适用情况:在缺乏坚实的理论基础支撑,有关观测变量内部结构,一般用探索性因子分析。
先用探索性因子分析产生一个关于内部结构的理论,再在此基础上用验证性因子分析。
但这必须用分开的数据集来做。
探索性分析步骤:1、辨别、收集观测变量。
按照实际情况收集观测变量,并对其进行观测,获得观测值。
针对总体复杂性和统计基本原理的保证,通常采用抽样的方法收集数据来达到研究目的。
2、获得协方差阵(或Bravais-Pearson 的相似系数矩阵)。
我们所有的分析都是从原始数据的协方差阵(或相似系数矩阵)出发的,这样使我们分析得到的数据具有可比性,所以首先要根据资料数据获得变量协方差阵(或相似系数矩阵)。
3、确定因子个数。
有时候你有具体的假设,它决定了因子的个数;但更多的时候没有这样的假设,你仅仅希望最后的到的模型能用尽可能少的因子解释尽可能多的方差。
如果你有k 个变量,你最多只能提取k 个因子。
通过检验数据来确定最优因子个数的方法有很多,例如Kaiser 准则、Scree 检验。
方法的选择由,具体操作时视情况而定。
因子负荷 潜变量指标 残差4、提取因子。
因子的提取方法也有多种,主要有主成分方法、不加权最小平方法、极大似然法等,我们可以根据需要选择合适的因子提取方法。
其中主成分方法一种比较常用的提取因子的方法,它是用变量的线性组合中,能产生最大样品方差的那些组合(称主成分)作为公共因子来进行分析的方法。
5、因子旋转。
因子载荷阵的不唯一性,使得可以对因子进行旋转。
这一特征,使得因子结构可以朝我们可以合理解释的方向趋近。
我们用一个正交阵右乘已经得到的因子载荷阵(由线性代数可知,一次正交变化对应坐标系的一次旋转),使旋转后的因子载荷阵结构简化。
旋转的方法也有多种,如正交旋转、斜交旋转等,最常用的是方差最大化正交旋转。
6、解释因子结构。
最后得到的简化的因子结构是使每个变量仅在一个公共因子上有较大载荷,而在其余公共因子上的载荷则比较小,至多是中等大小。
通过这样,我们就能知道所研究的这些变量是由哪些潜在因素(也就是公共因子)影响的,其中哪些因素是起主要作用的,而哪些因素的作用较小,甚至可以不用考虑。
7、因子得分。
因子分析的数学模型是将变量表示为公共因子的线性组合,由于公共因子能反映原始变量的相关关系,用公共因子代表原始变量时,有时更利于描述研究对象的特征,因而往往需要反过来将公共因子表示为变量的线性组合,即因子得分。
验证性因子分析定义:验证性因子分析是对社会调查数据进行的一种统计分析。
它测试一个因子与想对应的测度项之间的关系是否符合研究者所设计的理论关系。
验证性因子分析 (confirmatory factor analysis) 的强项在于它允许研究者明确描述一个理论模型中的细节。
因为测量误差的存在,研究者需要使用多个测度项。
当使用多个测度项之后,我们就有测度项的“质量”问题,即效度检验。
而效度检验就是要看一个测度项是否与其所设计的因子有显著的载荷,并与其不相干的因子没有显著的载荷。
对测度模型的检验就是验证性测度模型。
对测度模型的质量检验是假设检验之前的必要步骤。
而验证性因子分析(CFA)是用来检验已知的特定结构是否按照预期的方式产生作用。