自动录音系统中人声判别的实现
语音识别技术的原理及其实现方法

语音识别技术的原理及其实现方法语音识别技术是一种将人类语音转化为文字的技术,它正被越来越广泛地应用于智能助理、语音输入、自动翻译等领域。
本文将详细讨论语音识别技术的原理及其实现方法,以帮助读者更好地了解这一技术并掌握其应用。
一、语音识别技术的原理语音识别技术的原理可以分为三个主要步骤:信号处理、特征提取和模型匹配。
1. 信号处理:语音信号在传输过程中可能受到多种噪声的干扰,如环境噪声、话筒噪声等。
因此,首先需要对音频信号进行预处理,以提高识别准确率。
该步骤通常包括音频去噪、降噪、增强等技术。
2. 特征提取:在预处理后,需要对语音信号进行特征提取,即将连续的语音信号转换为更具区分度的特征向量。
常用的特征提取方法有MFCC (Mel Frequency Cepstral Coefficients)和PLP(Perceptual Linear Prediction)等。
这些特征提取方法通过对不同频率的声音进行分析,提取出语音信号的关键特征,如音高、音频的形态和时长等。
3. 模型匹配:在特征提取后,需要建立一个匹配模型,将特征向量与预先训练好的语音模型进行比对,以确定输入语音对应的文字内容。
常用的模型包括隐马尔可夫模型(HMM)和深度神经网络(DNN)等。
这些模型通过学习大量的语音样本,使模型能够根据输入的特征向量判断最有可能的文字结果。
二、语音识别技术的实现方法语音识别技术的实现需要借助特定的工具和算法。
以下是常用的语音识别技术实现方法:1. 基于统计模型的方法:该方法主要基于隐马尔可夫模型(HMM)和高斯混合模型(GMM)。
隐马尔可夫模型用于描述语音信号的动态性,而高斯混合模型则用于对特征向量进行建模。
这种方法的优点在于其模型简单,容易实现,但其处理长时语音和噪声的能力较弱。
2. 基于神经网络的方法:随着深度学习技术的发展,深度神经网络(DNN)成为语音识别领域的热门技术。
该方法使用多层神经网络模型来学习语音信号的特征表示和模式匹配。
人声哼唱精确识别算法及数字记谱方法与制作流程
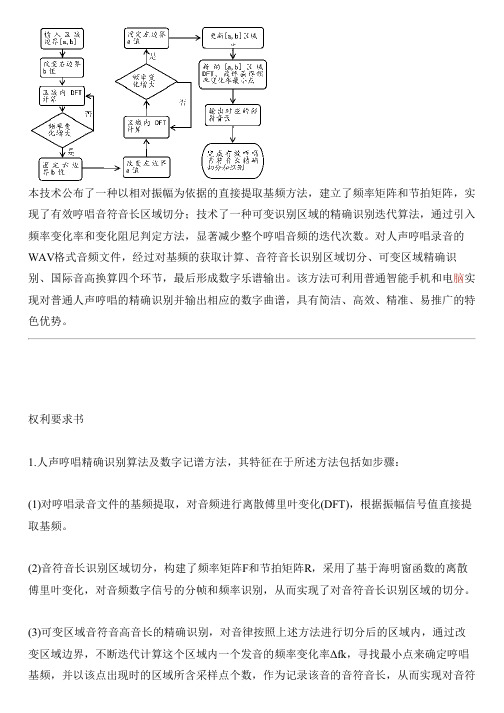
本技术公布了一种以相对振幅为依据的直接提取基频方法,建立了频率矩阵和节拍矩阵,实现了有效哼唱音符音长区域切分;技术了一种可变识别区域的精确识别迭代算法,通过引入频率变化率和变化阻尼判定方法,显著减少整个哼唱音频的迭代次数。
对人声哼唱录音的WAV格式音频文件,经过对基频的获取计算、音符音长识别区域切分、可变区域精确识别、国际音高换算四个环节,最后形成数字乐谱输出。
该方法可利用普通智能手机和电脑实现对普通人声哼唱的精确识别并输出相应的数字曲谱,具有简洁、高效、精准、易推广的特色优势。
权利要求书1.人声哼唱精确识别算法及数字记谱方法,其特征在于所述方法包括如步骤:(1)对哼唱录音文件的基频提取,对音频进行离散傅里叶变化(DFT),根据振幅信号值直接提取基频。
(2)音符音长识别区域切分,构建了频率矩阵F和节拍矩阵R,采用了基于海明窗函数的离散傅里叶变化,对音频数字信号的分帧和频率识别,从而实现了对音符音长识别区域的切分。
(3)可变区域音符音高音长的精确识别,对音律按照上述方法进行切分后的区域内,通过改变区域边界,不断迭代计算这个区域内一个发音的频率变化率Δfk,寻找最小点来确定哼唱基频,并以该点出现时的区域所含采样点个数,作为记录该音的音符音长,从而实现对音符音高音长的精确识别。
(4)国际音高换算,采用国际标准音高(Standard Pitch)度量,按照高度顺序分别为A、Bb、B、C、C#、D、Eb、E、F、F#、G、G#,越靠后表示半音高度越高。
2个半音高度(f1,f2)之间的频率关系由公式:计算,由此计算获得所有音高和频率对照表,并进行存储。
(5)乐谱输出,根据国际标准音高度量,进行频率f′k与音高Yk换算后,产生的对应音高Yk存储于矩阵A中,将已经计算获得的音符音长(步骤(2))存储于矩阵R中,根据矩阵相应储值,通过音高和频率对照表输出该哼唱曲调的数字乐谱。
2.根据权利要求1所述的人声哼唱精确识别算法及数字记谱方法,其特征在于步骤(1)提出了相对基频提取方法,包括如下原理及计算公式。
声音识别原理

声音识别,也称为语音识别或语音识别技术,是一种通过计算机程序识别和理解人类语音的技术。
声音识别的原理涉及声学、信号处理、统计学和机器学习等领域。
以下是声音识别的基本原理:1. 采集声音信号:声音识别的第一步是采集声音信号。
这可以通过麦克风或其他声音传感器来完成。
麦克风会将声音转换为电信号,并传输给计算机进行处理。
2. 预处理:采集到的声音信号通常包含了大量的环境噪音和干扰。
在预处理阶段,对声音信号进行滤波、降噪和放大等处理,以提高信号的质量。
3. 特征提取:在这一阶段,从声音信号中提取出有助于识别的特征。
常见的特征包括声谱图、梅尔频率倒谱系数(MFCC)、基音频率等。
4. 建模:通过使用机器学习算法建立声学模型。
传统方法中,使用的模型包括隐马尔可夫模型(Hidden Markov Model,HMM)等。
而近年来,深度学习技术,特别是循环神经网络(RNN)和长短时记忆网络(LSTM)等深度学习模型,也广泛用于声音识别。
5. 训练模型:利用大量标记好的声音样本来训练声学模型。
训练模型的目标是使其能够准确地识别和分类不同的语音特征。
6. 语音识别:在训练完成后,模型可以用于实时的语音识别。
输入一个未知的声音信号,模型通过比对已知的特征和模式,识别并转换为文本或其他指定的输出。
7. 优化和改进:针对实际应用场景和用户反馈,对模型进行优化和改进,以提高声音识别的准确性和鲁棒性。
总体而言,声音识别的原理结合了信号处理和机器学习的技术,使计算机能够理解并转换声音信号,实现语音与文本或其他形式的交互。
声音识别技术在语音助手、语音搜索、自动语音识别系统等应用中得到了广泛的应用。
语音识别技术中的说话人识别与辨别研究

语音识别技术中的说话人识别与辨别研究随着科技的发展,人们的生活越来越依赖于科技的支持。
语音识别技术是其中的一种,通过将人的声音转换成计算机可以识别的数据,使得我们的交互方式更加智能化和自然化。
在语音识别技术中,识别说话人的身份也成为一个热门研究方向,它可以在很多场景下起到很大的作用。
本文将对说话人识别与辨别的研究进行分析和讨论。
一、说话人识别与辨别的意义说话人识别与辨别是语音识别技术中的一个重要研究方向。
在很多应用场景中,都需要对说话人进行识别和辨别,比如:电话客服、安保系统、远程教育等。
在这些场景下,如果能够高效准确地识别出说话人的身份,就可以帮助进行语义理解和智能交互,提高系统的自适应性和用户体验。
二、说话人识别与辨别的技术原理说话人识别与辨别的技术原理主要是基于语音信号的声学特征。
语音信号中包含声音的频率、幅度和相位等信息,可以通过数字信号处理技术进行提取和分析。
具体来说,说话人识别与辨别的算法主要包括两个方面:声学模型和发音模型。
声学模型是对说话人声音特征的建模,通过将语音信号的频谱、倒谱、梅尔频率倒谱系数等信息提取出来,再利用一些统计模型进行训练和分类,最终实现对说话人身份的识别。
发音模型则是对语音信号的发音规律建模。
通过对各种不同音素的声学特征进行描述和比对,发音模型能够较为准确地判断出说话人发音的准确性和流畅性,从而判断身份。
三、说话人识别与辨别的应用现状现在,说话人识别与辨别主要应用于如下四个方面:1.电话客服领域。
在客户拨打电话的时候,就可以自动识别客户的身份,并与客户的编号、账户等信息进行匹配,从而省去了不必要的输入。
2.语音搜索领域。
对于许多语音搜索应用程序,这些请求可能是由多个用户发送的。
在这种情况下,说话人识别可以帮助程序区分用户之间的请求,更好地满足每个请求的需求。
3.远程教育领域。
在线教育平台利用说话人识别技术,可以准确识别学生是否在听课,同时也可以通过语音分析学生的学习习惯并针对性地提供在线学习建议。
录音中对于人声、乐器、声场等的均衡调试方法

由于房间的共振特性、吸声材料对声音频率的吸声系数不同以及扬声器系统的频率响应特性不均匀某原因,会导致出现某些频率声音过强和某些频率声音不足的问题。
因此必须对房间的频率响应特性进行调节。
房间均衡有两种方法:人耳听音结果调整,难度大,不易掌握,必须具有丰富的实践经验和非常熟悉的节目源配合,并且与调整时声压级大小有关,与听音人的年龄也有关。
另一种方法是用粉红噪声源及音频频谱仪进行客观测量和调整。
1.均衡器的调整方法:超低音:20Hz-40Hz,适当时声音强而有力。
能控制雷声、低音鼓、管风琴和贝司的声音。
过度提升会使音乐变得混浊不清。
低音:40Hz-150Hz,是声音的基础部份,其能量占整个音频能量的70%,是表现音乐风格的重要成份。
适当时,低音张弛得宜,声音丰满柔和,不足时声音单薄,150Hz,过度提升时会使声音发闷,明亮度下降,鼻音增强。
中低音:150Hz-500Hz,是声音的结构部分,人声位于这个位置,不足时,演唱声会被音乐淹没,声音软而无力,适当提升时会感到浑厚有力,提高声音的力度和响度。
提升过度时会使低音变得生硬,300Hz处过度提升3-6dB,如再加上混响,则会严重影响声音的清晰度。
中音:500Hz-2KHz,包含大多数乐器的低次谐波和泛音,是小军鼓和打击乐器的特征音。
适当时声音透彻明亮,不足时声音朦胧。
过度提升时会产生类似电话的声音。
中高音:2KHz-5KHz,是弦乐的特征音(拉弦乐的弓与弦的摩搡声,弹拔乐的手指触弦的声音某)。
不足时声音的穿透力下降,过强时会掩蔽语言音节的识别。
高音:7KHz-8KHz,是影响声音层次感的频率。
过度提升会使短笛、长笛声音突出,语言的齿音加重和音色发毛。
极高音:8KHz-10KHz合适时,三角铁和立*的金属感通透率高,沙钟的节奏清晰可辨。
过度提升会使声音不自然,易烧毁高频单元。
2.平衡悦耳的声音应是:150Hz以下(低音)应是丰满、柔和而富有弹性;150Hz-50Hz(中低音)应是浑厚有力百不混浊;500Hz-5KHz(中高音)应是明亮透彻而不生硬;5KHz以上(高音)应是纤细,园顺而不尖锐刺耳。
语音识别的原理和工作流程

语音识别的原理和工作流程语音识别技术是一种将人类语音转换为文字的技术,近年来随着人工智能技术的发展,语音识别技术在各个领域得到了广泛应用。
本文将从语音识别的原理和工作流程两个方面来介绍这项技术。
语音识别的原理语音识别的原理主要基于数字信号处理和机器学习的技术。
首先,语音信号会经过麦克风采集成为模拟信号,接着经过A/D转换器转换成数字信号。
然后,数字信号会经过端点检测和预处理等步骤,将其转换成特征向量。
通常使用的特征向量包括梅尔频率倒谱系数(MFCC)等,这些特征向量能够提取出语音信号的重要信息。
接下来,特征向量将输入到语音识别系统中,通过机器学习算法进行训练。
常用的机器学习算法包括隐马尔可夫模型(HMM)、深度学习等。
在训练阶段,系统会根据大量的标注语音数据不断调整参数,使得系统能够准确地识别语音信号。
最后,当系统接收到新的语音信号时,它会将信号转换成特征向量,通过之前训练好的模型来识别出对应的文本。
这样就完成了语音识别的过程。
语音识别的工作流程语音识别的工作流程通常可以分为离线识别和在线识别两种方式。
离线识别是指将录制好的语音信号进行处理,而在线识别则是实时地处理正在输入的语音信号。
在离线识别中,首先需要对语音信号进行预处理,包括去除噪音、进行特征提取等。
然后将处理好的语音信号输入到语音识别系统中进行识别,最后输出识别结果。
这种方式适用于一些语音录音文件的处理,比如语音转文字软件、语音识别助手等。
而在线识别则需要实时地处理输入的语音信号。
通常会在语音输入端进行端点检测,确定语音的开始和结束位置。
然后进行特征提取和模式匹配,最后输出识别结果。
这种方式适用于一些实时的语音交互系统,比如智能音箱、语音输入系统等。
除了离线识别和在线识别,语音识别还可以应用在多语种识别、远场识别、语音合成等方面。
多语种识别是指系统能够识别不同语种的语音信号,远场识别是指系统能够在远距离识别语音信号,而语音合成是指系统能够将文字转换为语音信号。
语音识别算法原理及其实现方法

语音识别是一种技术,它能够把人类语音转化为文字或指令,用于控制设备、发送信息或者实现其他功能。
这种技术被广泛应用于许多领域,包括语音助手、自动翻译、远程控制等。
下面我们来介绍语音识别算法的基本原理以及实现方法。
一、语音识别算法原理语音识别算法的主要原理是通过音频信号处理技术,提取出语音信号中的特征,并将其与已知的语音模式进行比较,以识别出说话者的意图。
主要步骤包括特征提取、声学模型建立、声学模型匹配和结果输出。
1. 特征提取:首先需要对语音信号进行特征提取,将语音信号转换为便于处理的数学特征。
常见的特征包括短时傅里叶变换(STFT)、梅尔频率倒谱系数(MFCC)等。
2. 声学模型建立:接下来建立声学模型,也就是从已知的语音样本中学习语音的模式。
常见的声学模型有隐马尔科夫模型(HMM)和深度学习模型等。
3. 声学模型匹配:通过声学模型匹配,将提取的特征与声学模型进行匹配,以确定语音的类别。
4. 结果输出:根据匹配结果输出相应的指令或信息。
二、语音识别算法实现方法实现语音识别算法的方法有很多种,其中比较常见的方法包括基于传统算法的方法和基于深度学习的方法。
1. 基于传统算法的方法:这种方法通常使用声学模型和语言模型进行语音识别。
首先,使用声学模型对输入的语音信号进行特征提取和匹配,然后使用语言模型对匹配结果进行解释和输出。
这种方法需要大量的手工标记数据和专业知识,但实现简单,性能稳定。
2. 基于深度学习的方法:近年来,深度学习在语音识别领域得到了广泛应用。
基于深度学习的方法通常使用深度神经网络(DNN)或循环神经网络(RNN)进行特征学习和建模。
这种方法需要大量的无标注数据,但性能通常优于传统方法,并且具有自学习能力。
在实际应用中,我们通常会结合传统方法和深度学习方法,以提高语音识别的准确性和效率。
此外,为了提高语音识别的性能,我们还可以使用一些优化技术,如降噪、回声消除、声学模型参数优化等。
总的来说,语音识别算法的实现需要深入理解算法原理和实现方法,同时需要大量的数据和计算资源。
语音识别技术原理是什么

语音识别技术原理是什么
语音识别技术是指将人的语音信号转化为机器能够理解和处理的文字或命令。
其原理主要包括以下几个步骤:
1. 音频采集:使用麦克风等设备采集人的语音信号,将声音转化为模拟电信号。
2. 信号预处理:对采集到的信号进行预处理,包括消除噪声、滤波等操作,使语音信号更加清晰。
3. 特征提取:将预处理后的语音信号转化为机器可以理解的特征向量。
常用的特征提取方法有MFCC(Mel频率倒谱系数)等。
4. 音频切割:将连续的语音信号切割成单个的语音片段,以便进行后续的处理。
5. 声学建模:通过使用大量标注好的语音数据,训练声学模型。
声学模型将语音片段与对应的文本进行对齐,建立语音与文字之间的映射关系。
6. 语言模型:使用大量的文本数据进行训练,建立语言模型,用于预测语音对应的文字顺序和语法规则。
7. 解码匹配:将特征向量与声学模型和语言模型进行匹配,找到最有可能的文字序列作为识别结果。
8. 后处理:对识别结果进行修正和优化,包括语法纠正、自适应模型更新等。
需要注意的是,语音识别技术涉及到信号处理、机器学习和自然语言处理等多个领域的知识,具体的实现方式和算法会有所不同。
以上仅为一般的语音识别技术原理概述。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
0.7
0.8
0.9
1
0
幅 度 /dB
-50
-100
0
0.1
0.2
0.3
0.4 0.5 0.6 归 一 化 频 率 (f/fs)
0.7
0.8Biblioteka 0.91窗函数 矩形窗 hamming
主瓣宽度 4*pi/N 8*pi/N
旁瓣峰值 13.3dB 42.7dB
2.2 短时能量的分析
由于语音信号的能量随时间变化,清音和浊音之间的能量差别相当显著。因 此对语音的短时能量进行分析, 可以描述语音的这种特征变化情况。定义短时能 量为:
n N w(n) 1,0 0,其他
hamming窗的定义:一个N点的hamming窗函数定义为如下
0.540.46cos(2 Nn1),0 n N w(n)= 0,其他
矩形窗频率响应 0 -20
幅 度 /dB
-40 -60 -80
0
0.1
0.2
0.3
0.4 0.5 0.6 归 一 化 频 率 (f/fs) Hamming窗 频 率 响 应
2.3 短时平均过零率
过零率可以反映信号的频谱特性。 当离散时间信号相邻两个样点的正负号相 异时,我们称之为“过零”,即此时信号的时间波形穿过了零电平的横轴。统计单 位时间内样点值改变符号的次数具可以得到平均过零率。定义短时平均过零率:
Zn
m
sgn[ x[m] sgn[ x(m 1)] w(n m)
X n (e jw )
m
x(m)w(n m)e
jwm
其中 w(n-m)是实窗口函数序列,n 表示某一语音信号帧。令 n-m=k',则得到
X n (e jw )
于是可以得到
k '
w(k ') x(n k ')e
jw( n k ')
X n (e jw ) e jwn
谱,而 为数字角频率。 数字滤波器可以有很多种分类方法,但总体上可分为两大类。一类称为经典 滤波器, 即一般的滤波器, 其特点是输入信号中的有用成分和希望滤除的成分占 用不同的频带,通过合适的选频滤波器可以实现滤波。例如,若输入信号中有干 扰,信号和干扰的频带互不重叠,则可滤出信号中的干扰得到纯信号。但是,如 果输入信号中信号和干扰的频带相重叠,则干扰就不能被有效的滤出。另一类称 为现代滤波器,如维纳滤波器、卡尔曼滤波器等,其输入信号中有用信号和希望 滤除的成分频带重叠。对于经典滤波器,从频域上也可以分为低通、高通、带通 和带阻滤波器。 从时域特性上看,数字滤波器还可以分为有限冲激响应数字滤波 器(FIR)和无限冲激响应数字滤波器(IIR) 。
2.4 短时自相关函数
自相关函数用于衡量信号自身时间波形的相似性。 清音和浊音的发声机理不 同,因而在波形上也存在着较大的差异。浊音的时间波形呈现出一定的周期性, 波形之间相似性较好; 清音的时间波形呈现出随机噪声的特性,样点间的相似性 较差。因此,我们用短时自相关函数来测定语音的相似特性。短时自相关函数定 义为:
所以在语音信号处理中, 自相关函数常用来作以下两种语音信号特征的 估计: 1)区分语音是清音还是浊音; 2)估计浊音语音信号的基音周期。
0.08 0.06 0.04 0.02 0 -0.02 -0.04 -0.06 -0.08 0 50 100 150 200 250 300
清音 0.1
0.05
R(k)
Rn (k )
m
'´
x(m) w(n m) x(m k ) w(n m k )
'
令 m n m ,并且 w(m) w (m) ,可以得到:
Rn (k )
m
[ x(n m)w (m)][ x(n m k )w (m k )] [ x(n m)w (m)][ x(n m k )w (m k )]
、
1
采样幅度
0.5
0
-0.5
0
2000
4000
6000
8000 sample
10000
12000
14000
16000
18000
8 6
短时能量
4 2 0
0
2000
4000
6000
8000 sample
10000
12000
14000
16000
18000
0.5
短时平均过零率
0.4 0.3 0.2 0.1 0 0 2000 4000 6000 8000 sample 10000 12000 14000 16000 18000
' ' ' ' m0
N 1 k
清音接近于随机噪声, 清音的短时自相关函数不具有周期性,也没有明显突 起的峰值,且随着延时 k 的增大迅速减小;浊音是周期信号,浊音的短时自相关 函数呈现明显的周期性, 自相关函数的周期就是浊音信号的周期,根据这个性质 可以判断一个语音信号是清音还是浊音,还可以判断浊音的基音周期。浊音语音 的周期可用自相关函数中第一个峰值的位置来估算。
0
-0.05
-0.1
0
50
100
150 延时k
200
250
300
清音的短时自相关函数
5 N=70
R(k)
0
-5
0
20
40
60
80
100 延时k
120
140
160
180
200
220
5 N=140
R(k)
0
-5
0
20
40
60
80
100 延时k
120
140
160
180
200
220
10 N=210
R(k)
0
j
)
(e j ) arctg
该指标主要用来说明系统的相位特性。 (3)群延时
Im[ H (e j )] j Re[ H (e )]
( )
d [ (e j )] d
理想滤波器具有非因果、 无限长的单位脉冲响应和不连续的频率特性,要用 稳定的线性时不变(LTI)系统来实现这样的特性是不可能的。工程上是用脉冲 响应为有限长的、 因果的、 稳定的线性时不变系统或具有连续频率特性的线性时 不变系统来逼近理想特性。在满足一定的误差要求的情况下来实现理想滤波特 性。因此实际的滤波器的频率特性如图所示
En
n
m
[ x(m)w(n m)]
2
m n N 1
[ x(m) w(n m)]2
,其中 N 为窗长
特殊地,当采用矩形窗时,可简化为:
En
m
x (m)
2
短时能量函数的应用: 1)可用于区分清音段与浊音段。En 值大对应于浊音段,En 值小对应于清 音段。 2)可用于区分浊音变为清音或清音变为浊音的时间(根据 En 值的变化趋 势) 。 3)对高信噪比的语音信号,也可以用来区分有无语音(语音信号的开始点 或终止点)无信号(或仅有噪声能量)时,En 值很小,有语音信号时,能量显 著增大。
数字信号处理论文
题
目
自动录音系统中人声判别的实现
专 学 学 日
业 号 生 期
通信 2 班 12S005107 李声勇 2013 年 11 月 15 日
哈尔滨工业大学
自动录音系统中人声判别的实现
语音信号是一种非平稳的时变信号,它携带着各种信息。在语音编码、语 音合成、语音识别和语音增强等语音处理中无一例外需要提取语音中包含的各 种信息。语音信号分析的目的就在与方便有效的提取并表示语音信号所携带的 信息。语音信号分析可以分为时域和变换域等处理方法. 在信号的傅立叶表示在信号的分析与处理中起着重要的作用。 因为对于线性 系统来说, 可以很方便地确定其对正弦或复指数和的响应,所以傅立叶分析方法 能完善地解决许多信号分析和处理问题。另外,傅立叶表示使信号的某些特性变 得更明显,因此,它能更深入地说明信号的各项红物理现象。 由于语音信号是随着时间变化的,通常认为,语音是一个受准周期脉冲或随 机噪声源激励的线性系统的输出。 输出频谱是声道系统频率响应与激励源频谱的 乘积。 声道系统的频率响应及激励源都是随时间变化的,因此一般标准的傅立叶 表示虽然适用于周期及平稳随机信号的表示,但不能直接用于语音信号。由于语 音信号可以认为在短时间内,近似不变,因而可以采用短时分析法。 本文通过对短时过零率、短时能量、自相关函数等参数的分析,对声音识别 中通过能量检测过滤噪音的理论进行了假设和分析。
x (n ) 0 sgn x (n ) 1, 1, x (n ) 0
其中 sgn[] 为符号函数, 形窗条件下,可以简化为
1 Zn 2N
,在矩
m n N 1
n
sgn[ x(m) sgn[ x(m 1)]
短时过零率可以粗略估计语音的频谱特性。由语音的产生模型可知,发浊音 时,声带振动,尽管声道有多个共振峰,但由于声门波引起了频谱的高频衰落, 因此浊音能量集中于 3KHz 以下。而清音由于声带不振动,声道的某些部位阻塞 气流产生类白噪声,多数能量集中在较高频率上。高频率对应着高过零率,低频 率对应着低过零率,那么过零率与语音的清浊音就存在着对应关系。. 短时平均过零率的应用: 1)区别清音和浊音。例如,清音的过零率高,浊音的过零率低。此外,清 音和浊音的两种过零分布都与高斯分布曲线比较吻合。 2)从背景噪声中找出语音信号。语音处理领域中的一个基本问题是,如何 将一串连续的语音信号进行适当的分割,以确定每个单词语音的信号,亦即找出 每个单词的开始和终止位置。 3)在孤立词的语音识别中,可利用能量和过零作为有话无话的鉴别。