spss 双变量回归与相关ppt课件
合集下载
《SPSS回归分析》PPT课件

电子工业出版社
(1)确定性关系与非确定性关系
变量与变量之间的关系分为确定性关系和非确定性关系, 函数表达确定性关系。研究变量间的非确定性关系,构造变量 间经验公式的数理统计方法称为回归分析。
(2)回归分析基本概念
回归分析是指通过提供变量之间的数学表达式来定量描述 变量间相关关系的数学过程,这一数学表达式通常称为经验公 式。我们不仅可以利用概率统计知识,对这个经验公式的有效 性进行判定,同时还可以利用这个经验公式,根据自变量的取 值预测因变量的取值。如果是多个因素作为自变量的时候,还 可以通过因素分析,找出哪些自变量对因变量的影响是显著的 ,哪些是不显著的。
➢打开“统计量”对话框,选上“估计”和“模型拟合度”。
➢单击“绘制(T)…”按钮,打开“线性回归:图”对话框,选 用DEPENDENT作为y轴,*ZPRED为x轴作图。并且选择“直方图” 和“正态概率图”
➢作相应的保存选项设置,如预测值、残差和距离等。
h
10
10
SPSS 19(中文版)统计分析实用教程
可以看出两变量具有较强 的线性关系,可以用一元 线性回归来拟合两变量。
h
9
9
SPSS 19(中文版)统计分析实用教程
电子工业出版社
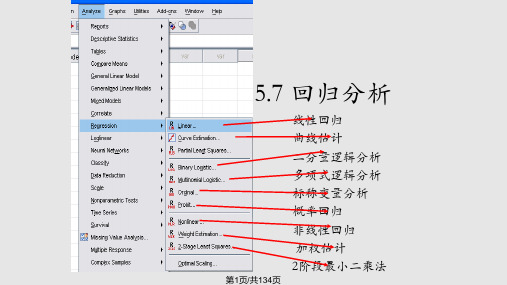
8.2 线性回归分析
第4步 一元线性回归分析设置:
➢选择菜单“分析→回归→线性”,打开“线性回归”对话框,将 变量“财政收入”作为因变量 ,“国内生产总值”作为自变量。
电子工业出版社
8.2线性回归分析
8.2.2 SPSS实例分析
【例8-1】现有1992年-2006年国家财政收入和国内生产总值的 数据如下表所示,请研究国家财政收入和国内生产总值之间的 线性关系。
年份
《SPSS回归分析》ppt课件

.
-3.666
.002
从表中可知因变量与自变量的三次回归模型为: y=-166.430+0.029x-5.364E-7x2+5.022E-12x3
9.2 曲线估计
➢拟合效果图
从图形上看出其拟合效果非常好。
8.3 曲线估计
说明:
曲线估计是一个自变量与因变量的非线性回归过程,但 只能处理比较简单的模型。如果有多个自变量与因变量呈非 线性关系时,就需要用其他非线性模型对因变量进行拟合, SPSS 19中提供了“非线性”过程,由于涉及的模型很多,且 非线性回归分析中参数的估计通常是通过迭代方法获得的, 而且对初始值的设置也有较高的要求,如果初始值选择不合 适,即使指定的模型函数非常准确,也会导致迭代过程不收 敛,或者只得到一个局部最优值而不能得到整体最优值。
8.1 回归分析概述
(3)回归分析的一般步骤
第1步 确定回归方程中的因变量和自变量。 第2步 确定回归模型。 第3步 建立回归方程。 第4步 对回归方程进行各种检验。
➢拟合优度检验 ➢回归方程的显著性检验 ➢回归系数的显著性检验
第5步 利用回归方程进行预测。
主要内容
8.1 回归分析概述 8.2 线性回归分析 8.3 曲线估计 8.4 二元Logistic回归分析
8.3 曲线估计
(2) 统计原理
在曲线估计中,有很多的数学模型,选用哪一种形式的回 归方程才能最好地表示出一种曲线的关系往往不是一个简单的 问题,可以用数学方程来表示的各种曲线的数目几乎是没有限 量的。在可能的方程之间,以吻合度而论,也许存在着许多吻 合得同样好的曲线方程。因此,在对曲线的形式的选择上,对 采取什么形式需要有一定的理论,这些理论是由问题本质决定 的。
spss中的回归分析PPT课件
6、Statistics(统计)对话框 单击“Statistics”按钮,进入统计对话框如图:
第19页/共134页
Estimates(默认选择项):回归系数的估计值(B)及其标准误(Std.Error)、 常数(Constant);标准化回归系数(Beta);B的t值及其双尾显著性水平(Sig.)。
第5页/共134页
H0:1 0, 2 0,, k 0
Fα
第6页/共134页
(3)回归系数的显著性检验(t检验) 所谓回归系数的显著性检验,就是根据样 本估计的结果对总体回归系数的有关假设进行 检验。 之所以对回归系数进行显著性检验,是因 为回归方程的显著性检验只能检验所有回归系 数是否同时与零有显著性差异,它不能保证回 归方程中不包含不能较好解释说明因变量变化 的自变量。因此,可以通过回归系数显著性检 验对每个回归系数进行考察。
4、 Selection variable(选择变量):可从源变量栏中 选择一个变量,单击Rule后,通过该变量大于、小于或等于某 一数值,选择进入回归分析的观察单位。
5、Case Labels(个案标签):在左侧的源变量框中选择 一变量作为标签变量进入 Case Labels框中。
第18页/共134页
Model fit(默认选择项):列出进入或从模型中剔除的变量;显示下列拟合 优度统计量:复相关系数(R)、判定系数(R2)、调整 R2(Adjusted R Square)、 估计值的标准误以及方差分析表。
Confidence intervals:回归系数 B的 95%可信区间(95%Confidence interval for B)。
第7页/共134页
回归参数显著性检验的基本步骤。 ① 提出假设
第9章 spss的相关分析和线性回归分析PPT课件

t nk2r (1 r2 )
r是相应的偏相关系数。n是观测个数,k是控 制变量的数目,n-k-2是自由度。 在SPSS的偏相关分析过程的输出中只给出偏相 关系数和假设成立的概率p值。
偏相关分析的操作
与简单相关分析操作类似,只不过菜单为
Analyze→Correlate→Partial
实例:利用数据相关回归分析(高校科研研 究).sav,分析发表立项课题数与论文数之间的 偏相关关系,其中投入高级职称的人数为控制变 量。
Pearson相关系数 Spearman 秩相关系数 Kendall t 相关系数
Pearson 相 关 系 数 ( Pearson’s correlation coefficient)又叫相 关系数或线性相关系数。它一般用
字母r表示。
r (xx)(yy) (xx)2 (yy)2
它是由两个变量的样本取值得到,这是一个描 述线性相关强度的量,取值于-1和1之间。当两 个变量有很强的线性相关时,相关系数接近于1 (正相关)或-1(负相关),而当两个变量不 那么线性相关时,相关系数就接近0。
Pearson 相 关 系 数 的 局 限 性 :
①要求变量服从正态分布 ②只能度量线性相关性,对于曲线相关等更为复杂的 情形,该相关系数的大小并不能代表相关性的强弱。 如果Pearson系数很低,只能说明两变量之间没有线 性关系,并不能说明两者之间没有相关关系。也就是 说,该指标只能度量线性相关性,而不是相关性。 (线性相关性隐含着相关性,而相关性并不隐含着线 性相关性)
这很难一概而论。但在计算机输出 中都有和这些相关度量相应的检验
和p-值;因此可以根据这些结果来
判断是否相关
简单相关分析菜单
画散点图
Graphs→Scatter 选择散点图的类型 根据所选择的散点图类型,单击Define对散点图作具体定
r是相应的偏相关系数。n是观测个数,k是控 制变量的数目,n-k-2是自由度。 在SPSS的偏相关分析过程的输出中只给出偏相 关系数和假设成立的概率p值。
偏相关分析的操作
与简单相关分析操作类似,只不过菜单为
Analyze→Correlate→Partial
实例:利用数据相关回归分析(高校科研研 究).sav,分析发表立项课题数与论文数之间的 偏相关关系,其中投入高级职称的人数为控制变 量。
Pearson相关系数 Spearman 秩相关系数 Kendall t 相关系数
Pearson 相 关 系 数 ( Pearson’s correlation coefficient)又叫相 关系数或线性相关系数。它一般用
字母r表示。
r (xx)(yy) (xx)2 (yy)2
它是由两个变量的样本取值得到,这是一个描 述线性相关强度的量,取值于-1和1之间。当两 个变量有很强的线性相关时,相关系数接近于1 (正相关)或-1(负相关),而当两个变量不 那么线性相关时,相关系数就接近0。
Pearson 相 关 系 数 的 局 限 性 :
①要求变量服从正态分布 ②只能度量线性相关性,对于曲线相关等更为复杂的 情形,该相关系数的大小并不能代表相关性的强弱。 如果Pearson系数很低,只能说明两变量之间没有线 性关系,并不能说明两者之间没有相关关系。也就是 说,该指标只能度量线性相关性,而不是相关性。 (线性相关性隐含着相关性,而相关性并不隐含着线 性相关性)
这很难一概而论。但在计算机输出 中都有和这些相关度量相应的检验
和p-值;因此可以根据这些结果来
判断是否相关
简单相关分析菜单
画散点图
Graphs→Scatter 选择散点图的类型 根据所选择的散点图类型,单击Define对散点图作具体定
双变量回归与相关48页PPT

ENDΒιβλιοθήκη 双变量回归与相关41、实际上,我们想要的不是针对犯 罪的法 律,而 是针对 疯狂的 法律。 ——马 克·吐温 42、法律的力量应当跟随着公民,就 像影子 跟随着 身体一 样。— —贝卡 利亚 43、法律和制度必须跟上人类思想进 步。— —杰弗 逊 44、人类受制于法律,法律受制于情 理。— —托·富 勒
45、法律的制定是为了保证每一个人 自由发 挥自己 的才能 ,而不 是为了 束缚他 的才能 。—— 罗伯斯 庇尔
16、业余生活要有意义,不要越轨。——华盛顿 17、一个人即使已登上顶峰,也仍要自强不息。——罗素·贝克 18、最大的挑战和突破在于用人,而用人最大的突破在于信任人。——马云 19、自己活着,就是为了使别人过得更美好。——雷锋 20、要掌握书,莫被书掌握;要为生而读,莫为读而生。——布尔沃
spass教程第五章相关分析和回归分析ppt课件

5.1 下表为青海一月平均气温与海拔高度及纬度的数
据,试分析一月平均气温与海拔高度和纬度的偏相关 系数〔由于第三个变量纬度(海拔)的存在所起的作用, 能够会影响纬度(海拔)与一月平均温度之间的真实关 系〕。
测站 昂欠 清水河 玛多 共和 铁卜加 茫崖 托勒 伍道梁 察尔汗 吉迈 尖扎 西宁
一月气温
曲线回归
检验结果和系数
MODEL: MOD_3.
Independent: 年降水量 Dependent Mth Rsq d.f. F Sigf b0 b1 b2 b3 海拔高度 LIN .462 10 8.60 .015 -780.60 2.0951 海拔高度 LOG .484 10 9.39 .012 -10241 1672.91 海拔高度 INV .477 10 9.13 .013 2504.03 -1.E+06 海拔高度 QUA .506 9 4.60 .042 -2676.6 6.9415 -.0029 海拔高度 CUB .559 8 3.39 .074 5011.03 -23.623 .0356 -2.E-05 海拔高度 COM .665 10 19.85 .001 63.4154 1.0030 海拔高度 POW .710 10 24.54 .001 6.7E-05 2.4296 海拔高度 S .719 10 25.64 .000 8.9234 -1781.4 海拔高度 GRO .665 10 19.85 .001 4.1497 .0030 海拔高度 EXP .665 10 19.85 .001 63.4154 .0030
降水量
多元非线性回归
7.6 某变量受其它两个变量的影响,其中X、Y这两 个变量对y影响的函数表达式为 Z=a+bX+cX2+dY+eY2+fXY,根据下面的数据计算 这个关系式〔不可直线化的多元非线性回归,知曲 线的方式〕 注:多元多项式回归也用此方法
第八章-spss相关分析和回归分析课件

相关分析和回归分析都是分析客观事物之间相关关 系的数量分析方法。
第八章-spss相关分析和回归分析
双变量的关系强度如何测量?
• 变量关系强度的含义 指两个变量相关程度的高低。统计学中是以准实 验的思想来分析变量相关的。通常从以下的角度 分析: A)两变量是否相互独立。 B)两变量是否有共变趋势。 C)一变量的变化多大程度上能由另一变量的变 化来解释。
定距
积矩相关 pearson correlation
回归 regression
第八章-spss相关分析和回归分析
•双变量关系强度测量的主要指标
定类
定序
定距
定类
卡方类测量 卡方类测量 Eta 系 数
定序 定距
Spearman Spearman 相 相关系数 关系数
同Ken序da-l异l τ 序 对相关测系量数
r (xix)(yiy) (xix)2•(yiy)2
Pearson简单相关系数的检验统计量为:
r n2 t
1 r2
第八章-spss相关分析和回归分析
8.2.2.2 Spearman等级相关系数
• Spearman等级相关系数用来度量定序变量间的线性
相关关系,设计思想与Pearson简单相关系数相同, 只是数据为非定距的,故计算时并不直接采用原始数
Partial过程,当进行相关分析的两个变量的取值都受到 其他变量的影响时,就可以利用偏相关分析对其他变量进 行控制,输出控制其他变量影响后的偏相关系数。
Distances过程用于对各样本点之间或各个变量之间进行 相似性分析,一般不单独使用,而作为聚类分析和因子分 析等的预分析。
第八章-spss相关分析和回归分析
量之间的线性关系较弱
第八章-spss相关分析和回归分析
双变量的关系强度如何测量?
• 变量关系强度的含义 指两个变量相关程度的高低。统计学中是以准实 验的思想来分析变量相关的。通常从以下的角度 分析: A)两变量是否相互独立。 B)两变量是否有共变趋势。 C)一变量的变化多大程度上能由另一变量的变 化来解释。
定距
积矩相关 pearson correlation
回归 regression
第八章-spss相关分析和回归分析
•双变量关系强度测量的主要指标
定类
定序
定距
定类
卡方类测量 卡方类测量 Eta 系 数
定序 定距
Spearman Spearman 相 相关系数 关系数
同Ken序da-l异l τ 序 对相关测系量数
r (xix)(yiy) (xix)2•(yiy)2
Pearson简单相关系数的检验统计量为:
r n2 t
1 r2
第八章-spss相关分析和回归分析
8.2.2.2 Spearman等级相关系数
• Spearman等级相关系数用来度量定序变量间的线性
相关关系,设计思想与Pearson简单相关系数相同, 只是数据为非定距的,故计算时并不直接采用原始数
Partial过程,当进行相关分析的两个变量的取值都受到 其他变量的影响时,就可以利用偏相关分析对其他变量进 行控制,输出控制其他变量影响后的偏相关系数。
Distances过程用于对各样本点之间或各个变量之间进行 相似性分析,一般不单独使用,而作为聚类分析和因子分 析等的预分析。
第八章-spss相关分析和回归分析
量之间的线性关系较弱
《spss回归与相关》PPT课件

制作:王立芹
a
Met hod
St epwise
(Crit eria: Probabilit
y-of -
F-to-enter
.
<= .050,
Probabilit y-of -
F-to-remo
ve >= . 100).
St epwise
(Crit eria:
Probabilit y-of -
F-to-enter
1
Sig. (2-tailed)
.000
N
15
15
**. Correlation is significant at the 0.01 level (2-tailed).
23.11.2020 23:43:55
制作:王立芹
2.秩相关
例13-2 某医生收集12例急性脑梗死(AMI)病人, 记录了患者在抢救期间的总胆固醇,用爱丁堡-斯堪 的那维亚神经病学中SNSS量表评分标准评定患者 的神经功能缺损程度,试分析总胆固醇与神经功能 评分是否相关。
Model
B Std. Error Beta
t
1 (Consta6n.7t)74 .156
43.545
x3
.110 .027
.693 4.079
a.Dependent Variable: y
Sig. .000 .001
23.11.2020 23:43:57
制作:王立芹
R e g re s s io n S ta n d a rd iz e d R e s id u a l
23.11.2020 23:43:57
制作:王立芹 23.11.2020 23:43:57
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Independent Method
Selection Variable
Case Labels WLS Weight
定义回归分析的应变量,只能选一个。在左侧框内单击应变量 名,其前面的小三角符号变成黑色(即被激活),单击选入 定义回归分析的自变量。用法同上 选择自变量的入选方式,默认的是 Enter(即强行进入法)。本 章自变量只有一个,就选择 Enter 法 当只分析某变量符合一定条件的记录时,选入该变量,并用右 侧的 Rule 键建立选择条件。它和我们在分析前利用 Data 菜单中 Select Case 选择记录的功能是一样的 选择一个变量,它的取值将作为每条记录的标签 进行加权最小二乘法的回归分析
Unstandardized
原始残差
Standardized
标准化后的残差,均数为 0,标准差为 1
Studentized Delected
Studentized Delected Prediction Intervals Mean Individual Confidence Interval:
SPSS双变量回归与相关
河北医科大学公共卫生学院 卫生统计学教研组
内容
1
直线回归
2
直线相关与秩相关
3
曲线拟合
2020年6月1日星期一1时20分50秒
(一)直线回归
例1 某地方病研究所调查了8名正常儿童的尿肌酐含量(mmol/24h)如表
1。估计尿肌酐含量(Y)对其年龄(X)的回归方程。
表1 8名正常儿童的年龄(岁)与尿肌酐含量(mmol/24h)
列出 7 个变量名 因变量 标准化残差 调节预测值 学生化剔除残差 标准化预测值 剔除残差 学生化残差 绘制散点图 上一组坐标的变量名 下一组坐标的变量名 输入变量名,作为图形的 X 轴 输入变量名,作为图形的 Y 轴 绘制标准残差图 直方图 正态 P-P 图 绘制出模型中每一个自变量与应变量残差的散点图
2020年6月1日星期一1时20分52秒
2020年6月1日星期一1时20分52秒
操作提示 左侧列表框 DEPENDNT ZRESID ADJPRED SDRESID ZPRED DRESID SRESID Scatter Previous Next X Y Standardized Residual Plots Histogram Normal probability Produces all partial plots
2.统计分析 (1)散点图
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分51秒
(2)直线回归
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分52秒
操作提示 Dependent
Leverage values
Influence Statistics DfBeta(s) Standardized DfBeta(s) DfFit Standardized DfFit Covariance ratio
Save to new file Coefficient statistics Produces all partial plots
2020年6月1日星期一1时20分52秒
2020年6月1日星期一1时20分52秒
操作提示 Predicted Values Unstandardized Standardized Adjusted S.E of mean predictions Residuals
设置预测值选项 应变量原始预测值 标准化后的预测值,预测值的均数为 0,标准差为 1 不考虑当前记录,当前模型对该记录应变量的预测值 预测值的标准差 设置残差选项,用于模型诊断
采用 t 变换产生的残差,即学生化残差 不考虑当前记录,当前模型对该记录应变量的预测值对观察值的 原始残差,即剔除残差,可发现可疑的强影响点 学生化剔除残差 设置预测区间 条件均数的置信区间 个体 y 值的容许区间 设置置信度,默认 95%
2020年6ahalanobis Cook’s
2020年6月1日星期一1时20分52秒
残差的独立性检验
2020年6月1日星期一1时20分52秒
操作提示 Regression Coefficients Estimates
设置回归系数选项
输出回归系数 及其标准误,t 值,P 值,标准化回归系数 ,
Confident Intervals Covariance matrix Model fit
Descriptives Residuals
默认选项 输出回归系数的 95%置信区间 多重回归中输出各个自变量的相关矩阵和方差、协方差矩阵 输出进入、退出模型的变量列表,并给出有关拟合优度的检验: 相关系数 R,决定系数 R2,和调整的 R2,标准误及方差分析表, 默认选项 输出变量的描述统计量,如有效记录数、均数、标准差等。在 多重回归中,还给出一个自变量的相关矩阵 设置残差选项
设置测量数据点离拟合模型的距离指标 马哈拉诺夫距离,所示的是观察值距样本平均值的距离 表示不考虑该记录,模型残差发生的变化。若 Cook’s 距离大于 1, 该记录可能为影响点 杠杆值。测量数据点的影响强度,若值大于 2*P/N(P 为变量数,N 为 样本含量),该记录可能为影响点 设置诊断影响点的统计量选项 Difference in Beta 的缩写,表示不考虑该观察值后回归系数的变化值 标准化的 DfBeta ,当它大于 2/Sqrt(N)时,该点可能是强影响点 Difference in fit value 的缩写,表示不考虑该观察值后预测值的变化值 标准化的 DfFit 值,当它大于 2/Sqrt(N)时,该点可能是强影响点 在多重回归中表示不考虑该观察值后协方差矩阵与含该观察值协方差 矩阵的比率。它的绝对值大于 3*P/N 时,该点可能为强影响点 保存结果到新文件,默认在当前数据集中生成新的变量 可以将新变量存到新的 SPSS 数据文件中 绘制出模型中每一个自变量与应变量残差的散点图
编号 年龄X 尿肌酐含量Y
1
2
3
4
5
6
7
8
13 11 9
6
8 10 12 7
3.54 3.01 3.09 2.48 2.56 3.36 3.18 2.65
2020年6月1日星期一1时20分51秒
1.建立数据文件 取两个变量: X变量(本例为“年龄”)、 Y变量(本例为“尿肌酐含量”)
2020年6月1日星期一1时20分51秒
Selection Variable
Case Labels WLS Weight
定义回归分析的应变量,只能选一个。在左侧框内单击应变量 名,其前面的小三角符号变成黑色(即被激活),单击选入 定义回归分析的自变量。用法同上 选择自变量的入选方式,默认的是 Enter(即强行进入法)。本 章自变量只有一个,就选择 Enter 法 当只分析某变量符合一定条件的记录时,选入该变量,并用右 侧的 Rule 键建立选择条件。它和我们在分析前利用 Data 菜单中 Select Case 选择记录的功能是一样的 选择一个变量,它的取值将作为每条记录的标签 进行加权最小二乘法的回归分析
Unstandardized
原始残差
Standardized
标准化后的残差,均数为 0,标准差为 1
Studentized Delected
Studentized Delected Prediction Intervals Mean Individual Confidence Interval:
SPSS双变量回归与相关
河北医科大学公共卫生学院 卫生统计学教研组
内容
1
直线回归
2
直线相关与秩相关
3
曲线拟合
2020年6月1日星期一1时20分50秒
(一)直线回归
例1 某地方病研究所调查了8名正常儿童的尿肌酐含量(mmol/24h)如表
1。估计尿肌酐含量(Y)对其年龄(X)的回归方程。
表1 8名正常儿童的年龄(岁)与尿肌酐含量(mmol/24h)
列出 7 个变量名 因变量 标准化残差 调节预测值 学生化剔除残差 标准化预测值 剔除残差 学生化残差 绘制散点图 上一组坐标的变量名 下一组坐标的变量名 输入变量名,作为图形的 X 轴 输入变量名,作为图形的 Y 轴 绘制标准残差图 直方图 正态 P-P 图 绘制出模型中每一个自变量与应变量残差的散点图
2020年6月1日星期一1时20分52秒
2020年6月1日星期一1时20分52秒
操作提示 左侧列表框 DEPENDNT ZRESID ADJPRED SDRESID ZPRED DRESID SRESID Scatter Previous Next X Y Standardized Residual Plots Histogram Normal probability Produces all partial plots
2.统计分析 (1)散点图
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分51秒
(2)直线回归
2020年6月1日星期一1时20分51秒
2020年6月1日星期一1时20分52秒
操作提示 Dependent
Leverage values
Influence Statistics DfBeta(s) Standardized DfBeta(s) DfFit Standardized DfFit Covariance ratio
Save to new file Coefficient statistics Produces all partial plots
2020年6月1日星期一1时20分52秒
2020年6月1日星期一1时20分52秒
操作提示 Predicted Values Unstandardized Standardized Adjusted S.E of mean predictions Residuals
设置预测值选项 应变量原始预测值 标准化后的预测值,预测值的均数为 0,标准差为 1 不考虑当前记录,当前模型对该记录应变量的预测值 预测值的标准差 设置残差选项,用于模型诊断
采用 t 变换产生的残差,即学生化残差 不考虑当前记录,当前模型对该记录应变量的预测值对观察值的 原始残差,即剔除残差,可发现可疑的强影响点 学生化剔除残差 设置预测区间 条件均数的置信区间 个体 y 值的容许区间 设置置信度,默认 95%
2020年6ahalanobis Cook’s
2020年6月1日星期一1时20分52秒
残差的独立性检验
2020年6月1日星期一1时20分52秒
操作提示 Regression Coefficients Estimates
设置回归系数选项
输出回归系数 及其标准误,t 值,P 值,标准化回归系数 ,
Confident Intervals Covariance matrix Model fit
Descriptives Residuals
默认选项 输出回归系数的 95%置信区间 多重回归中输出各个自变量的相关矩阵和方差、协方差矩阵 输出进入、退出模型的变量列表,并给出有关拟合优度的检验: 相关系数 R,决定系数 R2,和调整的 R2,标准误及方差分析表, 默认选项 输出变量的描述统计量,如有效记录数、均数、标准差等。在 多重回归中,还给出一个自变量的相关矩阵 设置残差选项
设置测量数据点离拟合模型的距离指标 马哈拉诺夫距离,所示的是观察值距样本平均值的距离 表示不考虑该记录,模型残差发生的变化。若 Cook’s 距离大于 1, 该记录可能为影响点 杠杆值。测量数据点的影响强度,若值大于 2*P/N(P 为变量数,N 为 样本含量),该记录可能为影响点 设置诊断影响点的统计量选项 Difference in Beta 的缩写,表示不考虑该观察值后回归系数的变化值 标准化的 DfBeta ,当它大于 2/Sqrt(N)时,该点可能是强影响点 Difference in fit value 的缩写,表示不考虑该观察值后预测值的变化值 标准化的 DfFit 值,当它大于 2/Sqrt(N)时,该点可能是强影响点 在多重回归中表示不考虑该观察值后协方差矩阵与含该观察值协方差 矩阵的比率。它的绝对值大于 3*P/N 时,该点可能为强影响点 保存结果到新文件,默认在当前数据集中生成新的变量 可以将新变量存到新的 SPSS 数据文件中 绘制出模型中每一个自变量与应变量残差的散点图
编号 年龄X 尿肌酐含量Y
1
2
3
4
5
6
7
8
13 11 9
6
8 10 12 7
3.54 3.01 3.09 2.48 2.56 3.36 3.18 2.65
2020年6月1日星期一1时20分51秒
1.建立数据文件 取两个变量: X变量(本例为“年龄”)、 Y变量(本例为“尿肌酐含量”)
2020年6月1日星期一1时20分51秒