SPSS 第二章 数据收集
SPSS统计分析课件第2章 数据与数据文件

经济管理学院 邓维斌
§第2章 数据与数据文件 §2.1变量与变量值
SPSS 统 计 分 析
视图
变量的定义信息
包括:Name,Type,Width, Decimal,Label,Values,Missing, Columns, Align,Meas变量 Gender Height 变量标签 性别 身高 变量值 f m 1 2 3 4 5 男 女 <=1.49m 1.50~1.59m 1.60~1.69m 1.70~1.79m >=1.80m 4 变量值标签
SPSS 统 计 分 析
§第2章 数据与数据文件
数据定义信息的复制
SPSS 统 计 分 析
SPSS 统 计 分 析
10
§第2章 数据与数据文件
缺失值的处理(Replace Missing Values)
SPSS 统 计 分 析
由于种种原因,在统计表中可能会有一些缺失值,在很多时候需 要在进行分析前进行处理。用Transform菜单的Replace Missing Values 命令项。常用方法;Series mean,Mean of nearby points;Median of nearby points;Linear interpolation和Linear trend at point。(以data02-01为例演 示)
SPSS 统 计 分 析
数据的合并(Merge files)
变量合并 个案合并 注:最好是在EXCEL中进行合并。
9
§第2章 数据与数据文件
数据的选择(Select Cases)
有时为了进行特定的分析,需要从所有的数据资料中选择出一些数 据进行统计分析。Data02-01数据为例,选择女性(sex=F)和变量Maths 在70.00到90数值范围内的观察值。步骤如下: 从Data菜单选择Select Cases命令项,弹出Select Cases对话框。All Cases表示所有的数据;If condition is satisfied表示不按条件选择; Random sample of cases表示对观测值进行随机抽样;Based on time of case range表示顺序抽样。 点击“If”按钮,弹出如图1-12所示对话框,先选择变量,然后定义条 件,假设要定义的是Maths成绩在70到100之间的女生,则对话框中的 表达式为:sex=’f’ AND Maths>=70.00 AND Maths<=100.00。
统计分析与Spss应用第二章(数据与数据文件)

2、保存数据文件
在数据编辑器中定义变量输入修改数据形成 一个可供SPSS 分析的数据文件,使用Edit 菜单 项中的各种功能可以对数据文件进行编辑处理。 如果将数据文件存盘磁盘数据文件的扩展名 为SAV ,利用菜单项File 的Data或Save As 功能 展开的对话框指定存储路径位置和磁盘文件名, 将数据窗中的数据保存为.sav格式的数据文件 或者其他的数据文件如数据库文件等。
2 操作符与表达式 (1) 算术运算符与算术表达式 (2) 比较算符与比较表达式 (3) 逻辑运算符与逻辑表达式
数学运算操作符 关系运算符 逻辑运算符 +加 <(LT) :小于 & (And) :与 -减 >(GT) :大于 | Or :或 *乘 <=(LE): 小于等于 ~ Not 非 /除 >=(GE) : 大于等于 **幂 = EQ 等于 ( ) 括号 ~= NT 不等于
2.1.2一手数据与二手数据 一手数据:针对特定的研究问题,通过专门收集、 调查或试验取得的数据称为一手数据。(要通过 建立文件才能使用SPSS进行分析) 二手数据:由各种媒体、机构发布的数据,如证 券市场行情、物价指数、利率、国民生产总值等, 对于数据分析人员来说,可以根据研究的问题, 从这些数据中加以选择,这样间接得到的数据称 为二手数据。(要通过外部文件引入才能使用 SPSS进行分析) 一手数据和二手数据是根据数据分析人员获取数 据的方式是直接还是间接的来划分的。
(b) 字符串常量 字符串常量是被单引号或双引号括起来的 一串字符,如果字符串中带有字符“ ‘ ”, 则该字符串常量必须使用双引号括起来例 如 :“BOY’ S BOOK ”
《统计分析与SPSS的应用》课后练习答案(第2章)

《统计分析与SPSS的应用(第五版)》课后练习答案第2章SPSS数据文件的建立和管理1、S PSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?问:在S P S S中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Miss ing Value )和系统缺失值(System Miss ingValue )。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0” “9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“?”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
如何在SPSS 中指定变量的计算尺度?变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。
spss第二讲数据整理data、transform

38
SPSS统计软件
变量清单
将汇总变量 加入当前数
据 替代当前数
据文件 创建汇 总文件
分组变量
汇总统计 量
汇总统计量清单
39
SPSS统计软件 文件级数据整理 4.文件的拆分
操作提示:Data →Split File…
2)按班号对技能成绩大于60分的成绩进行汇总, 另存为新的数据文件。
3)以姓名定义新变量名,进行行列转置,另存为“转置.sav”。
48
SPSS统计软件
数据管理练习
3、数据:新医学生成绩.sav 要求:1)描述不同班级(号)学生的妇科和儿科平均成绩与标准差,结果保 存为“新成绩.spv”。 2)选出内科成绩大于18的学生,描述其外科成绩平均水平,结果保存为 “外科成绩.spv”。
Recode可以用于字符型变量
23
SPSS统计软件
演示:将数据transform.sav中字符型“city”变量转化为数 值型变量“newcity”。(按照字母排序)
24
SPSS统计软件 变量级数据整理:4.Rank Cases
编秩变量 分组变量
操作提示: Transform →Rank Cases
SPSS统计软件
第二讲 SPSS数据整理
课前复习
1
SPSS统计软件
SPSS的特点
SPSS操作界面----三个窗口 SPSS的保存
(新医学生成绩)
2
SPSS统计软件
SPSS数据格式
1.一条记录占一行(反映某个研究对象具体特征的一组观测值。 ) 2.一个变量占一列(测量指标) 3.SPSS数据分析时特殊数据格式(配对设计、重复测量资料数据) 最终的数据集应当包含原始数据的所有信息
spss第二章,数据的编码、录入与整理
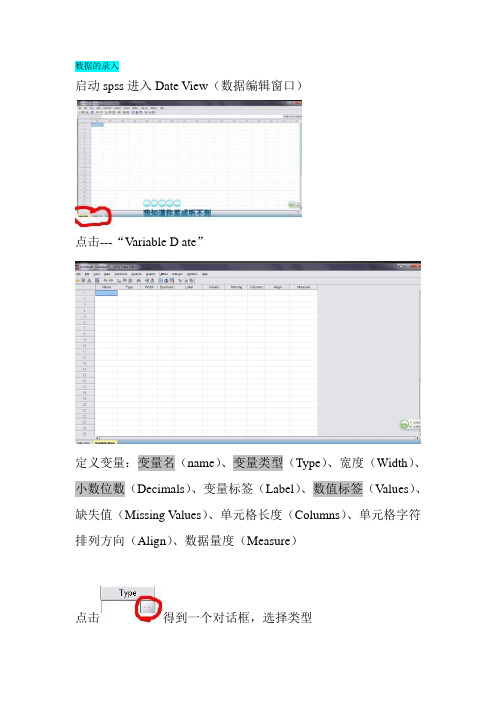
数据的录入启动spss进入Date View(数据编辑窗口)点击---“Variable D ate”定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)点击得到一个对话框,选择类型系统默认宽度为8,小数位2位;一般数字和字符比较常用-------Lable中可以取汉字名字方便查看------Values中可以设定数值标签,既将非数值的记录转换成数值;比如:性别1-女,2-男(一般默认为none)如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”用户可自己定义-------其他几项一般都用默认数据的录入-------回到“Date View”中逐个录入数据------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入-----“File”---“Open”---“Date”数据的整理:数据分值转换数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)----数据输入后----“Transform”--“Recode into different Variables”选中其中一个变量将其移到Numeric Variable->Output V ariable在那么中重编码----点击“Change”----“Old And New Values”例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”表2.13前身量表的统分假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
spss第二章

开放性问卷的处理方法
• 1、对回答进行分类。 • 2、建立回答类别与对应的数量关系, 进行编码。
• • • • 我最适应的是:_________________________ 我最满意的是:_________________________ 最不适应的是:_______________________ 压力最大的是:_______________________
资料的审查 编码
数据资料的形式: • 封闭性问卷资料与开放性问卷资料。 • 不同的资料形式均要求对资料进行审查,但在编 码时有不同的要求。
资料的审查
• 主要考察二个方面: 1.资料的完整性(关键) 2.资料的合理性
资料的完整性审查
包括资料总体上的完整性和每份资料的完 整性。 整性。 资料总体的完整性主要考虑问卷发放的数 回收率等。 量、回收率等。 每份资料的完整性主要看问卷的填答情况, 每份资料的完整性主要看问卷的填答情况, 是否是有效问卷。 是否是有效问卷。
• 问题5 开学以来我经常从事的休闲活动是 (可以重复选择) 1. □运动 2.□KTV 3.□郊游 4.□跳舞 5. □爬山 6.□玩牌 7.□下棋 8.□逛街 9.□聊天 10.□看书 11.□上网打游戏机 12.□看电视 13.□看电影
多项排序选择题
• 问题 您选择职业考虑的主要因素有(依 问题6 您选择职业考虑的主要因素有( 据重要性大小排列,限选三项) 据重要性大小排列,据
上机练习
1、尝试建立一个有五个变量:学号、性别、英语成绩、数学 、尝试建立一个有五个变量 学号 性别、英语成绩、 学号、 成绩、智商的数据文件,要求输入至少6个个案的数据 个个案的数据。 成绩、智商的数据文件,要求输入至少 个个案的数据。 文件名为:姓名SPSS2a 文件名为:姓名
薛薇_《SPSS统计分析方法及应用》第二章__数据录入与数据获取
Variable按钮允许用户指定保存哪些变量,不保存哪些 变量,变量名前画叉的变量将被保存到磁盘中。
将数据保存为Excel文件格式时,Write variables names to spreadsheet选项呈可用状态,它的作用是指定是否将 SPSS变量名写入Excel工作表的第一行上。
h
17
SPSS中说明缺失数据的基本方法是指定用户缺 失值。用户缺失值可以是: o 对字符型或数值型变量,用户缺失值可以是 1至3个特定的离散值(Discrete missing values); o 对一个数值型变量,用户缺失值可以在一个 连续的闭区间内并同时再附加一个区间以外
的离散值(Range plus one optional discrete)。
1.首字符应以英文字母开头,后面可以跟除了!、?、*之外的字母或 数字。下划线、圆点不能为变量名的最后一个字符。SPSS允许用汉 字作为变量名。
2.变量名的字符个数最好不多于8个;变量名不区分大小写字母。 3. SPSS有默认的变量名,以字母“VAR”开头,后面补足5位数字,如
VAR00001,VAR00012等。变量名不能与SPSS内部特有的具有特定 含义的保留字同名,如ALL,BY,AND,NOT,OR等。 4.变量名最好与其代表的数据含义相对应,每个变量名必须具有唯一性。
删除一个个案,在欲删除的个案号码上单击鼠标左 键,于是待删除的个案数据全部反向显示;单击鼠 标右键,从弹出菜单中选择cut选项。
h
33
插入一个变量,即在数据编辑窗口的某个变量前插 入一个新变量:将当前数据单元确定在一个变量上, 选择菜单 Data+Insert Variable
数据分析与软件应用第二讲SPSS统计软件基本操作及数据文件的整理
数据分析与软件应用第二讲SPSS统计软件基本操作及数据文件的整理SPSS统计软件是一款功能强大的数据分析工具,它提供了各种统计方法和分析技术,可以帮助用户进行数据处理、数据分析和结果展示等工作。
本文将介绍SPSS统计软件的基本操作和数据文件的整理方法。
一、SPSS统计软件基本操作:1. 导入数据:在SPSS软件中,可以通过多种方式导入数据,如手动输入数据、从Excel文件中导入数据、从文本文件导入数据等。
选择合适的导入方式,并根据导入数据的特点进行设置和调整。
2.数据清洗:导入数据后,需要对数据进行清洗,包括删除重复数据、删除无效数据、处理缺失数据等。
清洗数据可以提高数据分析的准确性。
4.数据转换:SPSS软件提供了多种数据转换的功能,如变量重编码、变量分组、变量排序等。
根据具体需求,可以选择合适的数据转换方法,对数据进行必要的处理和转换。
5.数据分析:SPSS软件提供了丰富的统计方法和分析技术,可以进行描述统计、频数分析、相关分析、回归分析、因子分析等。
选择合适的数据分析方法,对数据进行统计和分析,得出结论和结果。
6.结果展示:在SPSS软件中,可以将数据分析的结果进行展示和输出,如制作图表、生成报告、导出数据等。
通过合适的结果展示方式,可以直观地呈现数据分析的结果和结论。
二、数据文件的整理:在进行数据分析之前,需要对数据文件进行整理,以便于后续的数据处理和分析。
数据文件的整理主要包括以下几个步骤:1.数据收集:首先需要收集相关的数据,可以通过问卷调查、实验数据、实际观察等方式进行数据收集。
收集的数据应具备一定的代表性和可靠性。
2.数据录入:将收集到的数据进行录入,可以手动录入或者通过扫描仪等设备进行自动录入。
在录入过程中,需要注意录入的准确性和一致性。
3.数据清洗:在数据录入之后,需要对数据进行清洗,包括删除重复数据、删除无效数据、处理缺失数据等。
清洗数据可以提高数据的质量和准确性。
4.数据检查:对清洗后的数据进行检查,确保数据的有效性和完整性。
spss教程第二章
第二章数据文件的管理(上)(医学统计之星:张文彤)最后一次更新时间:2.1 建立与保存数据文件-File菜单2.1.1 新建数据文件2.1.2.1 直接打开2.1.2.2 使用数据库查询打开2.1.2.3 使用文本导入向导读入文本文件2.1.2 打开其他格式的数据文件2.1.3 保存数据文件2.1.4 File菜单中的其他条目2.2 编辑数据文件2.2.1 定义新变量2.2.1.1 直接定义新变量2.2.1.2 从原有变量计算新变量-Transform菜单2.2.2 数据的录入2.2.2.1 直接录入2.2.2.2 数据录入技巧2.3 进一步整理数据文件-Data菜单不言而喻,一切统计分析都是以数据为基础的,因此统计软件的数据管理能力非常重要。
SPSS以其豪华的界面为依托,为用户提供的便捷的数据管理功能,下面我们就来具体看一下。
§2.1建立与保存数据文件和大多数应用软件相同,SPSS中数据文件的管理功能基本上都集中在了File菜单上,该菜单的组织结构和WORD等也极为相似,因此这里我们只介绍比较有特色的几个菜单项。
SPSS 10.0有三个主要窗口界面:数据管理窗口、程序编辑窗口和结果浏览窗口;另有两个不常用的窗口:结果草稿浏览窗口和VBs脚本语言编辑窗口。
他们共享许多菜单项,如File菜单就大部分相同,这里介绍的许多内容在五个窗口中都是通用的。
2.1.1 新建数据文件如果你正从头开始进行一个新的课题,刚刚把数据收集上来,要做统计分析,自然需要新建一个数据库,然后将所有的数据从纸上请到计算机里。
在SPSS 中,新建一个数据库容易的不得了--已经到了什么都不用做的地步!是这样,当你进入SPSS系统时,系统就已经生成了一个空数据文件,即你看到的空白的数据管理界面。
你只要按自己的需要定义变量,输入数据然后存盘就是了(这些操作马上会讲到)。
2.1.2 打开其他格式的数据文件凡是做过数据输入工作的人都知道:这活又费眼睛又累人,出错太多了还要挨批评,非常影响个人的光辉形象。
SPSS入门课程教学大纲
SPSS⼊门课程教学⼤纲《spss⼊门》课程教学⼤纲⼀、课程的地位、性质和任务课程性质:SPSS⼊门是⼀门实践性、应⽤性很强的课程,它是以多元统计为基础理论,研究如何利⽤有效的⽅法收集、整理与分析受到随机因素影响的数据,从⽽对所涉及问题进⾏统计推断与预测,为科学决策提供依据和建议。
课程地位:本课程是师范类⼼理健康专业的职业拓展能⼒课程。
课程任务:通过本课程的学习,使学⽣了解SPSS统计软件的使⽤⽅法的基本概念、原理、⽅法和⼀般的操作程序,使学⽣在实际⼯作中具备⼀定的数据收集、处理、分析能⼒,并通过数据发现⼼理现象的⼀般特征和规律。
这对于提升⼼理健康专业学⽣专业能⼒、科研素养,以及加强学⽣认识和分析⼼理事实的能⼒等具有⼗分重要的意义。
⼆、总体教学⽬标《spss⼊门》是⼀门重要专业选修课程,通过本课程学习和操作训练,使学⽣掌握spss的基本理论,熟悉sps基本概念、基本原理和基本分析⽅法,能进⾏⼼理数据的统计处理分析能⼒。
三、本课程与其他专业课程的关系学习本课程前,学⽣应具备统计学、⼼理测量学、普通⼼理学和发展⼼理学等知识基础和能⼒。
四、各课程教学时间分配参考各章节教学时间分配表五、教学内容及其⽬的、要求、任务第⼀章spss⼊门(2学时)(⼀)教学⽬的⽬的:spss的发展历史、基本操作、窗⼝及功能和菜单及功能等。
(⼆)教学内容1、软件概述2、SPSS操作⼊门3、SPSS的窗⼝、菜单项和结果输出(三)教学要求1、基本要求(1)了解:spss的发展历史及作⽤(2)掌握:主要窗⼝及其功能;菜单(view)的功能及结果输出类型2、重点、难点重点:主要窗⼝及功能、菜单功能难点:⽆难点(四)教学建议本章节主要采⽤讲授法。
(五)作业、实践环节设计1、检查spss共有⼏个模块,其中包含了哪些功能,并思考平时的统计分析究竟需要哪些模块。
第⼆章数据录⼊与数据获取(2学时)(⼀)教学⽬的⽬的:对spss的数据格式、建⽴数据库、读取外部数据等有了解和进⾏实践应⽤。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
§1.4 变量之间的关系
• 定量变量间的关系 • 定性变量间的关系 • 定性和定量变量间的混合关系
5
第二章 数据的收集
6
§2.1 数据是怎样得到的?
• 数据根据获得的途径可分为一手数据和二手数据.
• 间接得到的(并非自己收集的)数据称为二手数据.
• 一手数据也称为原始数据,它是指研究人员基于当
15
多级抽样 (multistage sampling)
• 在群体很大时,往往在抽取若干群之后,再在其中抽取 若干子群,甚至再在子群中抽取子群等等,最后只对最 后选定的最下面一级进行调查. • 比如在全国调查时,先抽取省,再抽取市地,再抽取县 区,再抽取乡、村直到户. • 在多级抽样中的每一级都可能采取各种抽样方法. 因此, 整个抽样计划可能比较复杂,也称为多级混和型抽样. • 注意:即使是大规模的抽样调查,抽取样本的阶段也应 当尽可能地减少 . 因为每增加一个抽样阶段,就会增加 一份抽样误差,用样本对总体进行估计也更加复杂.
整群抽样 (cluster sampling)
• 整群抽样方法先将总体划分为若干群(cluster) (群内差异 大,群间差异小),再从这些群中随机抽取几群,然后对 被选群内的个体进行全面调查 ( 单级整群抽样 ) 或抽样调 查(两级整群抽样). • 整群抽样主要运用于根据行政或地域形成的群体,例如 学校、企业、县或街道等. • 比如,在某县进行调查,首先在所有村中选取若干村子, 然后只对这些村子的人进行调查. • 整群抽样的优点是样本集中,可以降低调查费用;缺点 是样本的分布不均,代表性差,抽样误差通常较大.
前的研究项目,通过观察、调查、实验等方式专门
收集的数据.
• 原始数据更有针对性,可靠性更高,但是费时费力.
• 二手数据相关性差,可靠性低,但省时省力.
7
• 抽样调查(社会科学等)和试验设计(农业、医学
等)是获取原始数据的主要方法. • 抽样调查:调查数据,或者观测数据,它是指客观 上已经存在,但需要观察或询问才能得到的数据 . 例如,关于社会经济现象的调查、民意调查、市场 调查等. • 试验设计:试验数据,它是指在试验方案的指导下,
600 … 1080 2100
F M F M
F … M M
1 1 2 2
1 … 4 3
为一个个 案或观测 值 • 每一列为 一个变量 的不同观 测值
20
• 汇总数据形式
不同性别、教育程度的人群对某项政策的观点表
教育程度
观点
女 不知道 反对 支持 总计 1 7 105 113
H
男 2 8 118 128 女 7 20 170 197
以及在控制有关因素的情况下收集的数据 . 例如,
研究不同医疗手段对某疾病的治疗效果,不同的肥
料和土壤条件对某农作物的产量的影响.
8
§2.2 个体、总体和样本
总体:研究对象的全体构成的集合 研究对象的某个(或某些)数量指标取值的全体
个体:组成总体的每一个元素
样本:从总体中按一定规则抽取的一部分个体 样本量:样本中包含的个体的数量 例如: 某厂生产的一批电子元件的寿命是一个总体, 每个电子元件的寿命是一个个体. 从这一批电子元件 中随机抽取100个,测其寿命,得到一个样本量为100 的样本. 9
第一章 一些基本概念
1
§1.3 变量和数据
常量:取值为一个确定的数目. 变量(或随机变量):可取两个或更多个可能值的 特征、特质或属性. 统计研究的对象是变量. 数据:变量的观测值.
变量按其取值不同可分为定量变量和定性变量两大类.
2
变量按其取值不同可分为定量变量和定性变量两大类.
• 定量变量(或数值变量):如果变量的取值为一些 数量值. • 定量变量包括连续型变量和离散型变量两种.
连续型数值变量:其取值可以是某一区间内的任一
实数. 例如:人的身高和体重、某商场的日销售额
等;
离散型数值变量:一般只在整数范围内取值. 例如: 购买某商品的人数、商品件数等.
3
• 定性变量(或属性变量、分类变量):如果变量的
取值为非数值型. • 定性变量可分为名义变量和有序变量.
名义变量:如性别、民族、季节、婚姻状况、国籍等. 在数据分析中,通常用数值来表示变量的各个类别,如 用数“1”和“2”表示男和女. 但这些数只是一个代码, 没有大小关系,也不能进行运算. 有序变量:如高校教师的职称可分为助教、讲师、副教 授、教授,可分别用“1,2,3,4”表示;再如收入水平可 分为低收入、中等收入、高收入,分别用“1,2,3”表示. 这些数具有大小或高低顺序,但类与类的差别不能计算.
16
非概率抽样方法
• 方便抽样:依据方便原则,以降低调查成本为目的抽 取样本. 典型的形式是“拦截式”调查. 特点是省事省 力,但样本代表性差. • 判断抽样:调查人员依据调查目的和对调查对象的了 解,人为地选择样本. • 定额抽样:与分层抽样类似,先确定总体中各类比例, 然后用方便抽样或判断抽样方法从每一类中按比例选 取需要的个体数. • 滚雪球抽样:先从几个合适的调查对象开始,再由一 个调查对象推荐另一个调查对象,从而扩大样本范围. • 自愿样本:由自愿接受调查的个体所组成的样本. 典型 17 的形式是“网上调查”.
12
系统抽样(systematic sampling)
• 系统抽样方法:首先将总体中Fra bibliotek每个个体编号,接着依 据简单随机抽样方法从总体中随机抽取出第一个个体, 然后按相同的间隔抽取其余个体. • 例如,如果第一个个体为 5 号,“间隔”为 10 ,则下面 的调查对象为15号、25号等等. • 系统抽样的主要优点是实施简单,且样本在总体中的分 布更均匀.
不同教育程度的人群的观点表
教育程度 L 18 52 410 480 M 8 49 586 643 总计 29 116 1219 1364
二维列联表
22
单随机抽样. 抽样的随机性可以使用随机数表实现. 在实践中,获取简单随机样本并不容易. 一般在规模较大 的调查中,很少直接采用简单随机抽样,而把这种方法和 其它抽样方法结合起来使用.
10
§2.4 抽样调查和一些常用的方法
• 抽样调查方法可以分为两类:概率抽样方法和非概率抽 样方法. • 概率抽样方法是以随机原则抽取样本,并且假定每一个 个体被抽中的概率是已知的,这种方法使得数据能够进 行合理的统计推断. • 非概率抽样方法最主要的特征是在抽取样本时不是依据 随机原则,因此不能计算抽样误差,样本数据不能对总 体进行推断 .它的主要在预调查或只需了解总体大致情 况时使用. • 概率抽样是抽样调查中最主要的方式 .下面介绍四类概 率抽样方法.
通常,在无法获得总体数据,或者获得总体数据需要较 大投入时,可通过抽样调查的方式获得来自总体的样本 数据,然后用样本数据来推断总体特征.
从总体中抽取的样本必须要有代表性:
(1) 随机性:每一个个体都可能被抽到,且每一个个体 被抽到的可能性一样. (2) 独立性:每次抽样是独立的(有放回的抽样).
由此得到的样本称为简单随机样本.这种抽样方法称为简
18
§2.3 收集数据时的误差
• 利用抽样调查方法收集数据时会产生误差,数据的误差 分为两类:抽样误差和非抽样误差. 抽样误差是由于抽取样本的随机性造成的样本值和总体 值之间的差异 . 只要采用抽样调查,抽样误差就不能避 免 . 控制抽样误差的方法是改变样本量,在其它条件相 同的情况下,样本量越大,抽样误差越小 . 抽样误差与 样本量的平方根大致呈反比关系. 非抽样误差是指除抽样误差之外的其它原因造成的样本 值和总体值之间的差异,这类误差应尽量避免 . 未响应 误差和响应误差属于非抽样误差.
抽样调查的注意点
• 在实际应用中,每个抽样方案都可能是多种抽样方 法的组合. 在设计抽样方案时,既要考虑精确度 (由误差来表现,误差越小,调查的精度就越高),
还要根据客观情况考虑方便性、可行性和经济性.
• 除了抽样方法之外,问卷设计的质量、调查过程等
对获取高质量的数据都非常重要. 例如,问卷设计
中的问题数量和相应的选择项不宜过多、问题的语 言要准确、问题的次序要合理等.
19
§2.5 计算机中常用的数据形式
• 原始数据形式
对某项政策的观点调查的原始数据形式
被访者编号 观点 1 支持 教育程度 H 月收入 1600 性别 M 地区号 1
• 每一行称
2 3 4 5
6 … 1363 1364
支持 反对 支持 不知道
不知道 … 反对 支持
M L H M
L … L H
1720 700 2000 1000
L
男 11 32 240 283 女 5 12 276 293
M
男 3 37 310 350
总计
29 116 1219 1364
三维交叉表或列联表(第八章)
21
• 汇总数据形式
不同性别的人群的观点表
性别 观点 不知道 反对 支持 总计 女 13 39 551 603 男 16 77 668 761 总计 29 116 1219 1364 观点 不知道 反对 支持 总计 H 3 15 223 241
13
分层抽样(stratified sampling)
• 分层抽样方法先把要研究的总体按照某些性质分类 (stratum)( 组内差异小,组间差异大 ) ,再在各类中分别 独立、随机地抽取样本 . 总的样本由各类样本组成,总 体参数则根据各类样本参数的汇总做出估计. • 在每类中调查的人数通常是按照该类人的比例,但出于 各种考虑,也可能不按照比例,也可能需要加权. • 比如,按照受教育程度把要调查的人群分成几类,再在 每一类中调查和该类成比例数目的人,以确保每一类都 有按比例的代表. • 当总体是由差异明显的几部分组成时,往往选择分层抽 样的方法,它能够提高样本的代表性、以及总体估计值 14 的精度. 还可以得到各类别参数的估计.