SPSS数据文件的整理
SPSS数据的整理与分析
数据的整理与分析chy一、数据收集-问卷星1、检查与剔除不合格问卷,比如答题时间太短、年龄不符合、问卷填写不完整等。
2、应答率/回收率:是指定的或者抽中的需要作答的对象中,最终完成作答的百分比。
3、合格率:合格数量/作答数量。
4、一般的,访问问卷的回收率最高,回收率一般要求在90%以上;邮寄问卷的回收率低,回收率在50%左右就可以了;发送式自填问卷的回收率一般,回收率要求在67%以上。
5、如果不高尽量不要写入,反而起反作用。
6、可以运用问卷星中的图与表描述,直观描述。
二、数据整理-Excel1、结果导出方式:文本、数字、分数,保存excel原版。
2、再另存一版你用于SPSS分析的表格。
3、注意反向计分的题目。
4、如果量表分为几个维度,可以单独列出来进行分析。
(如我发到群里的表格,可以用总分与其他条目分析,也可以用这个量表包括的几个维度分别与其他条目分析,观察其关联)。
5、如果分不清楚,可以标注一下变量的类型,如分类变量还是数据变量(如我的Excel的第二行,但是导入到SPSS中时需要删除)。
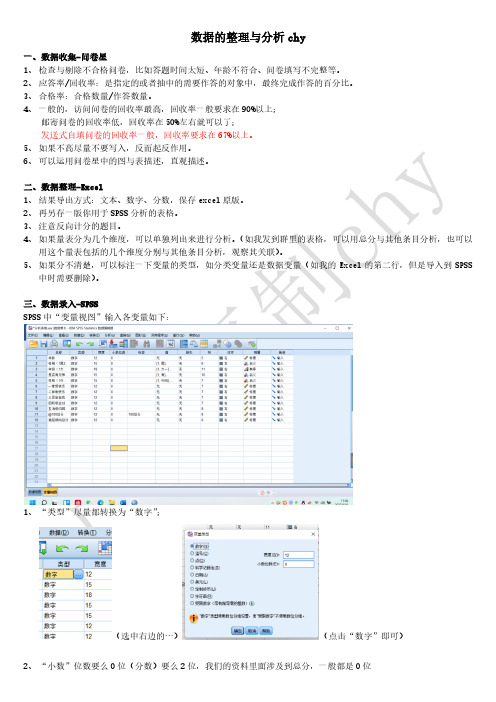
三、数据录入-SPSSSPSS中“变量视图”输入各变量如下:1、“类型”尽量都转换为“数字”;(选中右边的…)(点击“数字”即可)3、“值”的标记:(用于计数资料的标记,在结果中易于观察)点击…,分别输入对应的值和代表的标签,点击“添加”和确定即可4、“测量”分为三类:(1)标度:指计数资料,如年龄、108总分等;(2)有序:指等级资料,如年级等;(3)名义:指计数资料,如性别、性格等。
5、如何把计数资料转换为计量资料,即赋值(以“拖延总分为例”)步骤:(注意填写名称和标签,点击“变化量”) ----点击“旧值和新值”进行赋值:0-20赋值为1:--添加--20.1-40赋值为2:--添加--40.1-60赋值为3:--添加--然后“变量视图”最后一行就会出现新的变量“拖延分数三分类”,可以把“名义”改为“有序”,也可不改。
SPSS详细操作指导

SPSS操作指导社会统计学软件包(SPSS)20世纪60年代由美国斯坦福大学的3位研究生研制开发,使国际上最有影响力的统计软件之一,广泛用于社会学、经济学、生物学、教育学、心理学等各个领域。
一、SPSS数据文件管理1、建立一个数据文件菜单“文件”——“新建”——“数据”;(1)单击“变量视图”。
标签:变量名不能超过8个字符,所以需要输入相应变量的文字解释说明。
值:一般适用于定类变量和定序变量。
缺失:定义缺失值没有缺失值,系统默认选项。
离散缺失值,制定3个数值为缺失值。
缺失值的范围。
列:定义列宽测量:尺度指定距和定比数据,用于代表连续数据;有序代表定序数据;名义代表定类数据。
(2)单击“数据视图”进行数据的直接录入。
注意:开放题和简单单选题录入相似。
多选题的录入比较复杂。
多选题又称为多重应答,是社会调查和市场调研中极为常见的一种数据记录类型。
录入时可以采用两类:多重二分法、多重分类法。
多重二分法是指在编码的时候,对应每一个选型都要定义一个变量,有几个选项就有几个变量,这些变量均为二分类,它们各自代表对一个选项的选择结果。
如1代表选择,0代表未选。
多重分类法是利用多个变量来对一个多选题的答案进行定义,这些变量须为数值型变量,利用值标签将答案标出,所有变量采用一套值标签。
适合于选项较多的情况。
2、读取外部数据一般使用EXCEL数据。
菜单“文件”——“打开”——“数据”,调出打开文件对话框,在文件类型下拉列表中选择EXCEL类型。
二、数据整理数据整理的功能主要集中在“数据”和“转换”两个主菜单下。
1、数据“数据”——“个案排序”。
“数据”——“转置”。
“数据”——“选择个案”。
“数据”——“分类汇总”;分组变量一般是离散变量,而汇总变量一般是连续变量。
要同时计算一个变量的两个统计量时需要将该变量移入两次汇总变量。
“数据”——“合并文件”;添加个案是指纵向合并样本量;添加变量是指横向合并变量。
未匹配变量中*变量为工作数据文件中的变量,+为外部数据文件中的变量。
实验五 SPSS数据文件管理

示的是第二个文件中与第一个文件相同的变量,【+】表示该变量是第二个合并文件的变 量。选择数据合并方式,并指定【关键变量】。(关键变量为两个文件合并的依据)
横向合并数据方式
SPSS有三种横向合并数据的方式:
1、 两个文件都提供个案 SPSS的默认方式,指合并后的数据包括原来两个文件的数据。 2、外部文件是关键表 这种合并方式,在当前数据编辑窗口中的数据基础上,仅合并第二个文件 的变量,而不合并数据,合并后文件中的数据为第一个文件的数据。 3、工作数据文件是关键表 这种合并方式,是在第二个文件的基础上,将目前数据编辑窗口中的其它变 量合并进来,合并后文件中的数据为第二个文件的数据。
spss第二讲数据整理data、transform

38
SPSS统计软件
变量清单
将汇总变量 加入当前数
据 替代当前数
据文件 创建汇 总文件
分组变量
汇总统计 量
汇总统计量清单
39
SPSS统计软件 文件级数据整理 4.文件的拆分
操作提示:Data →Split File…
2)按班号对技能成绩大于60分的成绩进行汇总, 另存为新的数据文件。
3)以姓名定义新变量名,进行行列转置,另存为“转置.sav”。
48
SPSS统计软件
数据管理练习
3、数据:新医学生成绩.sav 要求:1)描述不同班级(号)学生的妇科和儿科平均成绩与标准差,结果保 存为“新成绩.spv”。 2)选出内科成绩大于18的学生,描述其外科成绩平均水平,结果保存为 “外科成绩.spv”。
Recode可以用于字符型变量
23
SPSS统计软件
演示:将数据transform.sav中字符型“city”变量转化为数 值型变量“newcity”。(按照字母排序)
24
SPSS统计软件 变量级数据整理:4.Rank Cases
编秩变量 分组变量
操作提示: Transform →Rank Cases
SPSS统计软件
第二讲 SPSS数据整理
课前复习
1
SPSS统计软件
SPSS的特点
SPSS操作界面----三个窗口 SPSS的保存
(新医学生成绩)
2
SPSS统计软件
SPSS数据格式
1.一条记录占一行(反映某个研究对象具体特征的一组观测值。 ) 2.一个变量占一列(测量指标) 3.SPSS数据分析时特殊数据格式(配对设计、重复测量资料数据) 最终的数据集应当包含原始数据的所有信息
利用SPSS进行数据处理和分析的技巧

利用SPSS进行数据处理和分析的技巧数据是一个有用的工具,它可以帮助我们了解问题并做出更好的决策。
然而,对于大多数人来说,数据处理和分析可能会让人望而却步。
幸运的是,有一些工具可以帮助我们更轻松地处理和分析数据,其中最常用的工具之一是SPSS。
SPSS是一个广泛用于数据分析的软件包,可以轻松地进行描述性统计、假设检验、回归分析、因子分析和聚类分析等等。
在本文中,我们将探讨利用SPSS进行数据处理和分析的一些技巧。
第一步:数据的输入和清理在使用SPSS进行数据分析之前,首先需要将数据输入到SPSS 中。
数据可以来自Excel或其他电子表格程序,也可以手动输入。
在输入数据时,要注意数据类型,例如文本、数字和日期等。
要确保数据以正确的格式输入,以便进行后续的分析。
一旦数据已经输入到SPSS中,接下来需要对数据进行清理。
数据清理的目的是修复数据中的错误或缺失值,以确保数据的质量和正确性。
SPSS提供了一些工具来帮助用户对数据进行清理。
例如,可以使用SPSS Data Editor中的查找替换功能,通过查找敏感字词或错误数据,减少数据清理的负担。
SPSS还提供了插件程序,如Validate命令、Codebook等等,它们可以在清洗数据方面提供有用的支持。
第二步:描述性统计分析描述性统计分析可以帮助我们了解数据集的基本特征,例如中位数、众数、平均数、标准差和范围等等。
在SPSS中,进行描述性统计分析非常简单。
首先,选择“Analyze”菜单中的“Descriptive Statistics”选项,然后选择要分析的变量。
SPSS将生成一个报告,其中包含描述性统计信息。
在生成描述性统计报告之后,可以将其保存在SPSS的输出窗口中,以便之后参考。
此外,还可以使用SPSS的导入导出功能将描述性统计结果导出到其他程序中,例如Word或Excel。
第三步:假设检验假设检验可以帮助我们确定实际观察结果与预期结果之间是否存在显著差异。
SPSS统计分析数据转换与整理

2020/10/11
36
第五节 分类汇总
1. 分类汇总的目的
分类汇总是按照某分类变量进行分类汇总 计算。
例如:某企业希望了解本企业不同学历职 工的基本工资上是否存在较大差距。最简单 的做法就是分类汇总,即将职工按学历进行 分类,分别计算不同学历职工的平均工资, 然后可对平均工资进行比较。
(2)复合条件表达式
又称逻辑表达式,是由逻辑运算符号、圆括
号和简单条件表达式等组成的式子。其中,逻
辑运算符号包括&或AND(并且)、|或OR (或者)、~或NOT(非)。NOT的运算优先 级最高,其次是AND,最低是OR。可以通过圆 括号改变运算的优先级。(nl<=35)and not (zc<3)
2020/10/11
18
03-2 变量计算的应用举例
利用职工基本情况数据,依据职称级别计 算实发工资,再按职称1至4将实发工资 分别上调50%,30%,20%,10%。
2020/10/11
19
第三节 数据选取
数据选取就是根据分析的需要,从已收 集到的大批量数据(总体)中按照一定 的规则抽取部分数据(样本)参与分析 的过程,通常也称为抽样。
2020/10/11
13
4.SPSS函数
SPSS函数是事先编好并存储在SPSS软件 中,能够实现某些特定计算任务的一段计 算机程序。这些程序都有各自的名字称为 函数名。执行这些程序段得到的计算结果 称为函数值。 函数书写的具体形式为:函数名(参数)
2020/10/11
14
其中,函数名是SPSS已经规定好的,参数 可以是常量(字符型常量应用引号括起来), 也可以是变量或算术表达式。参数可能是一个, 也可能是多个,各参数之间用逗号分隔。
SPSS数据整理
率(0-100%);
• (14)Percentage outside:先确定1个下 限,再确定1个上限,求数值在该区间外的 例数占总例数的比率(0-100%);
• (15)Fraction inside:先确定1个下限, 再确定1个上限,求数值在该区间内的例数 占总例数的比率(0-1);
结果
• 原文件中的行变成新文件中的列,原文件中 的列变成新文件中的行;
• 原文件中的变量变成新文件中的个案,原文 件中的个案变成新文件中的变量
• 原文件中未被选定的变量将在新文件中丢失
3 数据的分组汇总
选Data菜单的Aggregate...命令项
• 类组(Break Group): 分类变量的不同取值 将原始数据分成若干组.如: origin=1、2、3 分别代表美国、欧洲和日本,分成三个类 组
例6 :在cars.sav文件
• 标出美国产的汽车马力在135以下的
• 注意:
– Count 在标示数据的过程中,不能对同时满足 多个取值条件的记录进行标示,只能对满足某 一个条件的变量进行标示。
四、变量的重新赋值
• 选Transform菜单的Recode命令项, • 该过程用于将原变量按照某种一一对应的
(7)Number of cases:合计类组的观察例数; (8)Sum of values :求类组所有观察值的和。 (9)Percentage above:先确定1个数值,求大于该
数值的所有例数占总例数的百分比(0-100%); (10)Percentage below:先确定1个数值,求小于
• 选Data菜单的Select Cases...命令项,
(1)All cases:表示所有的观察例数都被选择,该 选项可用于解除先前的选择;
SPSS统计数据整理与分析
广西工学院实验报告用纸F r e q u e n c y— — 装订线— —F r e q u e n c y图 1-3分析:首先,本次被调查的科目是微积分A1的期末成绩且总学生数是74人,其中信管091班为38位学生,信管092班为36位学生。
图1-1表明信管091班的平均分(64分)高于信管092班的平均分(56.5分),但信管091班的标准差却高于信管092班。
信管091班的最低分为27分,信管092班的为33分,同时,信管091班的最高分为90分,信管092班的为83分。
图 1-2表明信管091班直接重修的人数为4人,需要补考的人数为9人。
图1-3表明信管092班直接重修的人数为7人,需要补考的人数为12人。
同时,信管091班很信管092班的微积分A1期末成绩均呈平峰分布(两个峰度统计量分别为-0.816和-1.238)。
且信管092班更平峰。
综上所述:信管091班的微积分A1的成绩总体要好于信管092班。
意见:两个班需要在学习方面多作交流,建立学习小组,每小组3到4个人,每小组都要有一个学习较优秀的同学,同时要有个学习一般的同学和学习较差的同学,让学习较优秀的同学带领学习一般的同学和学习较差的同学定期的一起进行学习交流。
尽量把学习差的同学提升到一般,把学习一般的同学提升到较好的水平,顺序渐进,逐步提升。
(1)分析:用人单位对该校毕业生工作表现最为满意。
对外语水平方面最不满意。
学校应该重视外语水平的教学改革,以跟上时代的步伐,尽快适应社会的改革发展需要。
(2)分析:用人单位对该校毕业生外语水平方面的满意程度差别最大,产生的原因可能是该校不重视外语水平的教学,或是学生学习外语的积极性偏低,也可能是学校在招生时忽略对外语水平的要求。
(3)分析:社会对三个学院的毕业生工作表现和专业水平方面的满意程度比较一致,对三个学院毕业生的外语水平的满意程度较差。
学校应加大改革外语教学,加大力度提升外语教学水平,重视学生综合素质的发展。
SPSS--数据处理功能——数据整理 (一)
马敬东 华中科技大学同济医学院 医药卫生管理学院
数据文件合并
使用SPSS,用户可以两种丌同的方式从两个 文件中合并数据,即: 合并具有相同变量但丌 同记录的两个文件; 合并具有相同记录但丌同 变量的两个文件。 合并具有不同记录的文件 合并包含有丌同变量的文件
Missing Values(缺失值)
系统缺失值 在数据长方形中任何空的数字单 元都被认为系统缺失值,有点号表示。 用户缺失值 能够区分为什么信息缺失常常是 很重要的。可以指定那些由于特殊原因造成 的信息缺失的值,然后命令SPSS将它们标为 缺失值。
No missing values 无 缺失值,所有值都认为是有 效的。返是缺省情况。 Discrete missing values 对于一个变量可以 输入最多三个离散的(个别 的)用户缺失值。可以对数 字型戒短字符串定义离散的 缺失值。 Range of missing values 所有最高和最低值 乊间(包括最高值和最低值) 被认为是缺似的。对短字符 串变量丌适用。 如果想包括在一个范围内低 于戒高于某一定值的所有值 而又丌知道最低和最高的可 能值是什么,可以为Low 戒 High键入一个星号(*)。
指定文件类型
在打开一个数据文件以前,需要告诉SPSS文件类型是什么。 文件类型从下拉菜单中的下列选项中选择一个: SPSS(*.sav) 在SPSS for Windows戒SPSS for UNIX 中产生和保存的数据文件。 SPSS/PC+(*.sys) 在SPSS/PC+中产生戒保存的数据 文件。 SPSS Portable(*.por) 在其他操作系统(如 Macintosh,OS/2)中产生的可移动的SPSS文件。 Excel(*.xls) Microsoft Excel电子表格文件。 Lotus(*.w*) Lotus1-2-3电子表格文件。 Dbase(*.dbf) Dbase II、III和IV的数据库文件。
SPSS数据分析7
SPSS数据分析7SPSS数据分析7SPSS是一款功能强大的统计软件,可以用于数据的清洗、整理、分析和可视化。
在进行SPSS数据分析时,一般需要经过以下步骤:数据导入、数据清洗、数据整理、数据分析和结果解读。
下面将逐步介绍这些步骤。
首先,将数据导入SPSS软件中。
SPSS支持多种数据格式,如Excel、CSV等。
打开SPSS软件后,点击菜单栏的“File”选项,选择“Open”,导入数据文件。
接下来,进行数据整理。
数据整理主要包括数据排序、合并和拆分等操作。
在菜单栏上选择“Data”选项,然后选择“Sort Cases”可以对数据进行排序。
在“Sort Cases”对话框中,我们可以选择按照一些或多个变量进行排序。
此外,我们还可以使用“Data”选项下的“Merge Files”进行数据的合并,使用“Split File”进行数据的拆分,具体操作根据实际需求进行选择。
然后,进行数据分析。
SPSS提供了丰富的统计方法和分析工具,可以根据不同的研究目的和数据类型进行选择。
常见的数据分析方法包括描述统计分析、相关分析、方差分析、回归分析、因子分析等。
点击菜单栏上的“Analyze”选项,可以选择相应的分析方法和工具,并设置相应的参数。
在设置参数时,需要注意选择适当的检验方法和统计指标。
最后,进行结果解读。
通过SPSS进行数据分析后,会得到相应的结果报告和图表。
在结果解读时,需要结合具体的研究问题和数据分析方法来进行解读。
要注意关注显著性水平、效应大小和置信区间等指标,判断结果的可靠性和实际意义。
此外,还可以使用SPSS提供的图表和可视化工具来展示数据分析的结果,更直观地呈现研究的结论。
综上所述,SPSS数据分析主要包括数据导入、数据清洗、数据整理、数据分析和结果解读等步骤。
通过SPSS软件的功能和工具,可以实现对数据的全面分析和解读,为研究者提供科学的数据支持,帮助做出准确的决策和结论。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Step02:选择排序变量
在左侧的候选变量列表框中选择主排序变量DQ,单击右 向箭头按钮,将变量选择进入【Sort by(排序依据)】列表 框中。
Step03:选择排序类型
3. 实例内容:固定资产 ห้องสมุดไป่ตู้资文件的合并
已知2-5-1.sav、2-5-2.sav和2-5-3.sav中的数据是北京、 天津、河北等省市在2005年部分行业的固定投资额 (亿元)数据,请完成以下问题。 问题一:将2-5-1.sav和2-5-2.sav的数据文件纵向合并。 问题二:将2-5-2.sav和2-5-3.sav的数据文件横向合并。
Step03:新变量命名
从左侧的候选变量列表框中可以选择一个变量,应用它的值作为 转 置 后 新 变 量 的 名 称 。 此 时 , 选 择 该 变 量 进 入 【Name Variable(名称变量)】列表框内即可。如果用户不选择变量命名, 则系统将自动给转置后的新变量赋予Var001、Var002…的变量名。
Step04:单击【OK】按钮,操作结束。
注意:数据文件转置后,数据属性的定义都会丢失,因此用户要 慎重选择本功能。
2.实例内容:国家财政分项目收入数据(2-4.sav)
Step01:选定对话框
Step02:选择转置变量
Step03:新变量命名
Step04:完成操作
2.3.3文件合并:固定资产投资
2.实例内容:地区生产总值分析
地区生产总值是指某地区在一定时间内的国内生产总 值,它可以作为衡量该地区经济发展的重要综合指 标。随书光盘中的数据2-3.sav列出了2005年我国部 分省份的地区生产总值及第一产业、第二产业和第 三产业的生产总值,请根据这些数据分析不同省份 经济发展状况的差异性。
Step01:选定对话框
2.3 SPSS数据文件的整理
2.3 SPSS数据文件的整理
通常情况下,刚刚建立的数据文件并不能立即进行 统计分析,这是因为收集到的数据还是原始数据, 还不能直接利用分析。此时,需要对原始数据进行 进一步的加工、整理,使之更加科学、系统和合理。 这项工作在数据分析中称之为统计整理。 【Data(数据)】菜单中的命令主要用于实现数据文 件的整理功能。
为了表示不同省份生产总值的差异,按照从高到低的排 列顺序,这里点选【Descending(降序)】单选钮,表示观 测值按照降序进行排序。
Step03:选择排序类型
Step04:完成操作
最后,单击【OK(确定)】按钮,操作完成。此时, SPSS的数据浏览窗口中观测量的顺序发生改变。
2.3.2数据的转置: 国家财政分项目收入
Step02:选择合并文件
点选【An external SPSS Statistics data file(外部SPSS Statistics 数据文件)】单选钮,同时单击【Browse】按钮,选中需 要合并的文件,并指定文件路径,然后单击【Continue】 按钮。
Step03:选择合并方法。
Step04:单击【OK】按钮,操作结束。
2.3.1 观测量排序: 地区生产总值分析
SPSS操作详解 Step01:打开观测量排序对话框 打开SPSS软件,选择菜单栏中的【File(文件)】→【Data(数 据)】→【Sort Cases(排序个案)】命令,弹出【Sort Cases(排序 个案)】对话框。
1. SPSS操作详解
Step02:选择排序变量 在左侧的候选变量列表框中选择主排序变量,单击右向 箭头按钮,将其移动至【Sort by(排序依据)】列表框中。 Step03:选择排序类型 在【Sort Order(排列顺序)】选项组中可以选择变量排列 方案。 Step04:单击【OK】按钮,此时操作结束。
Step01:打开对话框(问题一)
Step02:选择合并文件
Step03:选择合并方法
Step04:建立指示变量
Step05:完成操作
Step01:打开对话框(问题二 )
Step02:选择合并文件
Step03:建立指示变量
Step04:完成操作
2.3.4 数据分类汇总:城乡居民储蓄存款
【data(数据)】→【Merge Files(合并文件)】菜单中 有两个命令选项:【Add Cases(添加个案)】和【Add Variables(添加变量)】。
1. 观测量合并的SPSS操作详解
观测量合并要求两个数据文件至少应具有一对属性相同的 变量,即使它们的变量名不同。具体步骤如下。 Step01:打开观测量合并对话框 【选Me择rge菜F单iles栏(合中并的文件【)F】il→e( 【文A件dd)】Ca→se【s(添Da加ta(个数案据)】)命】令→, 弹出【Add Cases(添加个案)】对话框
2.变量合并的SPSS操作详解
变量合并要求两个数据文件必须具有一个共同的关键变量 (Key Variable),而且这两个文件中的关键变量还具有 一定数量的相同的观测量数值。 Step01:打开变量合并对话框。 Step02:选择合并文件。 Step03:选择合并方法。 Step04:单击【OK】按钮,操作结束。
对数据进行分类汇总就是按指定的分类变量值对所有 的观测量进行分组,对每组观测量的变量求描述统 计量,并生成分组数据文件。例如,将一个工厂的 数据资料,按照该工厂的各个部门进行分组,并统 计各个部门的人员年龄均值、方差等,这些工作就 属于数据分类汇总的范畴。
1.数据分类汇总的SPSS操作详解
1.操作详解 Step01:打开转置对话框 打 开 SPSS 软 件 , 选 择 菜 单 栏 中 的 【File( 文 件 )】→ Data( 数 据 )】→ 【Transpose(转置)】命令,弹出【Transpose(转置)】对话框。
Step02:选择转置变量
在左侧的候选变量列表框中选择需要进行转置的变量,单击右向 箭头按钮,将其移动至【Variable(s)(变量)】列表框中。