es中英文分词
ES系列十一、ES的index、store、_source、copy_to和all的区别

ES系列⼗⼀、ES的index、store、_source、copy_to和all的区别1.基本概念1.1._source存储的原始数据。
_source中的内容就是搜索api返回的内容,如:{"query":{"term":{"title":"test"}}}结果:{"took": 2,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},"hits": {"total": 1,"max_score": 0.2876821,"hits": [{"_index": "book3","_type": "english","_id": "3nuFZ2UBYLvVFwGWZHcJ","_score": 0.2876821,"_source": {"title": "test!"}}]}}默认情况下,Elasticsearch⾥⾯有2份内容,⼀份是原始⽂档,也就是_source字段⾥的内容,我们在Elasticsearch中搜索⽂档,查看的⽂档内容就是_source中的内容。
另⼀份是倒排索引,倒排索引中的数据结构是倒排记录表,记录了词项和⽂档之间的对应关系。
1.2.index:索引index使⽤倒排索引存储的是,分析器分析完的词和⽂档的对应关系。
es 分词检索高亮显示 剔除html java案例

对于这个主题,我们需要对es 分词检索高亮显示进行深入的讨论。
ES (Elasticsearch)是一个开源的分布式搜索引擎,提供了全文搜索功能,可以对大规模数据进行快速的检索和分析。
而分词检索高亮显示则是ES在搜索过程中非常重要的一个功能,它能够将搜索结果中的关键词进行高亮显示,方便用户快速找到所需信息。
接下来,我们将从以下几个方面进行讨论。
1. ES 分词ES在进行检索时,会对文档内容先进行分词处理,将文本分割成一个个的词语,这些词语就是ES进行搜索的基本单位。
ES内置了一些常用的分词器,比如standard、simple、whitespace等,用户也可以根据自己的需求自定义分词器。
分词的好坏直接影响到搜索的准确性,因此选择合适的分词器非常重要。
2. 检索ES的检索功能非常强大,可以通过各种查询方式来实现不同的检索需求,比如term查询、match查询、bool查询等。
在进行检索时,ES 会使用之前提到的分词器对搜索关键词进行分词,然后再在分词后的词语中进行匹配,找到符合条件的文档。
3. 高亮显示高亮显示是ES在搜索结果中非常常用的一个功能,在搜索结果中将匹配的关键词进行特殊标记,让用户一眼就能看出哪些部分是与搜索条件匹配的。
通过高亮显示,用户可以更直观地了解搜索结果与搜索条件的关联程度,提高了搜索的可用性。
4. 剔除html在实际应用中,文档内容通常是包含有HTML标签的,而在搜索结果中我们通常不希望看到HTML标签,因此需要将搜索结果中的HTML 标签进行剔除,只显示纯文本内容。
ES提供了一些过滤器可以用来实现这个功能,比如HTML strip字符过滤器。
5. Java案例我们将以一个Java案例来演示如何在Java程序中使用ES进行分词检索和高亮显示。
首先需要引入ES的Java客户端库,然后通过编写相应的代码来实现搜索功能,包括构造查询条件、实现分词和高亮显示等。
这个案例将帮助大家更好地理解ES分词检索高亮显示的具体实现方法。
es中英文分词

在Elasticsearch(简称ES)中,中英文分词是一个重要的功能,它可以帮助我们更准确地搜索和索引中英文文本。
下面是一些关于ES 中英文分词的基本知识和常用方法:1.内置分词器:Elasticsearch 内置了一些分词器,如Standard 分词器和Simple 分词器,它们都可以处理英文文本的分词。
但对于中文文本,它们可能不太适用,因为它们会将整个中文词语作为一个词项。
2.中文分词器:为了处理中文文本,我们需要使用专门的中文分词器,如IK 分词器、Jieba 分词器等。
这些分词器可以将中文文本分割成一个个有意义的词语,从而提高搜索的准确性。
3.安装插件:要在Elasticsearch 中使用中文分词器,通常需要安装相应的插件。
例如,对于IK 分词器,可以下载相应的插件包并安装到Elasticsearch 中。
4.配置分词器:安装插件后,需要在Elasticsearch 的配置文件中指定要使用的分词器。
这通常涉及到在索引设置中定义分析器(analyzer)和分词器(tokenizer)。
5.测试分词效果:配置好分词器后,可以使用Elasticsearch 的分析API 来测试分词效果。
这可以帮助我们了解分词器是如何处理中英文文本的,并根据需要进行调整。
6.优化分词策略:根据测试结果,我们可以调整分词策略以提高搜索效果。
例如,可以自定义词典来处理一些特殊的词汇或术语,或者调整分词器的参数来改变分词的行为。
7.注意事项:在使用中英文分词时,需要注意一些细节。
例如,要避免过度分词(将一个词分割成过多的词项)或分词不足(未能将长词或短语正确分割)。
此外,还需要考虑如何处理中英文混合文本以及如何处理标点符号等问题。
ES004-Elasticsearch高级查询及分词器
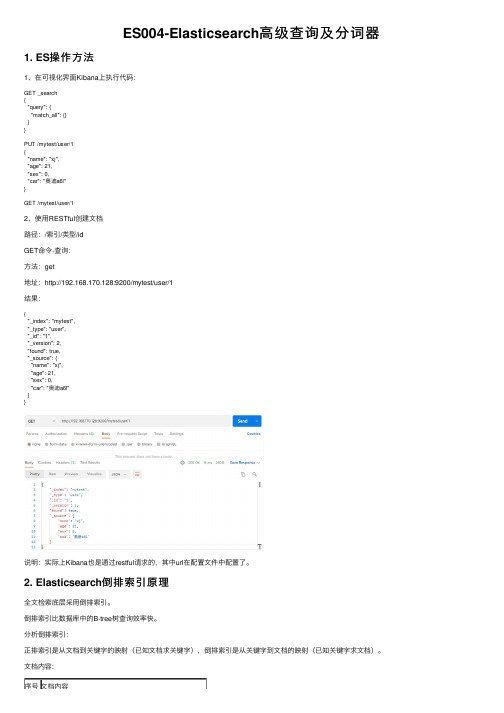
ES004-Elasticsearch⾼级查询及分词器1. ES操作⽅法1、在可视化界⾯Kibana上执⾏代码:GET _search{"query": {"match_all": {}}}PUT /mytest/user/1{"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}GET /mytest/user/12、使⽤RESTful创建⽂档路径:/索引/类型/idGET命令-查询:⽅法:get地址:http://192.168.170.128:9200/mytest/user/1结果:{"_index": "mytest","_type": "user","_id": "1","_version": 2,"found": true,"_source": {"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}}说明:实际上Kibana也是通过restful请求的,其中url在配置⽂件中配置了。
2. Elasticsearch倒排索引原理全⽂检索底层采⽤倒排索引。
倒排索引⽐数据库中的B-tree树查询效率快。
分析倒排索引:正排索引是从⽂档到关键字的映射(已知⽂档求关键字),倒排索引是从关键字到⽂档的映射(已知关键字求⽂档)。
⽂档内容:序号⽂档内容1⼩俊是⼀家科技公司创始⼈,开的汽车是奥迪a8l,加速爽。
[ES]elasticsearch章5 ES的分词(一)
![[ES]elasticsearch章5 ES的分词(一)](https://img.taocdn.com/s3/m/495dbcc377a20029bd64783e0912a21614797fbc.png)
[ES]elasticsearch章5 ES的分词(⼀)初次接触 Elasticsearch 的同学经常会遇到分词相关的难题,⽐如如下这些场景:1.为什么明明有包含搜索关键词的⽂档,但结果⾥⾯就没有相关⽂档呢?2.我存进去的⽂档到底被分成哪些词(term)了?3.我⾃定义分词规则,但感觉好⿇烦呢,⽆从下⼿1.从⼀个实例出发,如下创建⼀个⽂档:然后我们做⼀个查询,我们试图通过搜索 eat 这个关键词来搜索这个⽂档ES的返回结果为0。
这不太对啊,我们⽤最基本的字符串查找也应该能匹配到上⾯新建的⽂档才对啊!先来看看什么是分词。
2. 分词搜索引擎的核⼼是倒排索引,⽽倒排索引的基础就是分词。
所谓分词可以简单理解为将⼀个完整的句⼦切割为⼀个个单词的过程。
在 es 中单词对应英⽂为 term 。
我们简单看个例⼦:ES 的倒排索引即是根据分词后的单词创建,即我、爱、北京、天安门这4个单词。
这也意味着你在搜索的时候也只能搜索这4个单词才能命中该⽂档。
实际上 ES 的分词不仅仅发⽣在⽂档创建的时候,也发⽣在搜索的时候,如下图所⽰:读时分词发⽣在⽤户查询时,ES 会即时地对⽤户输⼊的关键词进⾏分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
⽽写时分词发⽣在⽂档写⼊时,ES 会对⽂档进⾏分词后,将结果存⼊倒排索引,该部分最终会以⽂件的形式存储于磁盘上,不会因查询结束或者 ES 重启⽽丢失。
ES 中处理分词的部分被称作分词器,英⽂是Analyzer,它决定了分词的规则。
ES ⾃带了很多默认的分词器,⽐如Standard、Keyword、Whitespace等等,默认是Standard。
当我们在读时或者写时分词时可以指定要使⽤的分词器。
3. 写时分词结果回到上⼿阶段,我们来看下写⼊的⽂档最终分词结果是什么。
通过如下 api 可以查看:其中test为索引名,_analyze为查看分词结果的endpoint,请求体中field为要查看的字段名,text为具体值。
Es学习第五课,分词器介绍和中文分词器配置

Es学习第五课,分词器介绍和中⽂分词器配置上课我们介绍了倒排索引,在⾥⾯提到了分词的概念,分词器就是⽤来分词的。
分词器是ES中专门处理分词的组件,英⽂为Analyzer,定义为:从⼀串⽂本中切分出⼀个⼀个的词条,并对每个词条进⾏标准化。
它由三部分组成,Character Filters:分词之前进⾏预处理,⽐如去除html标签Tokenizer:将原始⽂本按照⼀定规则切分为单词Token Filters:针对Tokenizer处理的单词进⾏再加⼯,⽐如转⼩写、删除或增新等处理,也就是标准化预定义的分词器ES⾃带的分词器有如下:Standard Analyzer默认分词器按词切分,⽀持多语⾔⼩写处理⽀持中⽂采⽤的⽅法为单字切分Simple Analyzer按照⾮字母切分⼩写处理Whitespace Analyzer空⽩字符作为分隔符Stop Analyzer相⽐Simple Analyzer多了去除请⽤词处理停⽤词指语⽓助词等修饰性词语,如the, an, 的,这等Keyword Analyzer不分词,直接将输⼊作为⼀个单词输出Pattern Analyzer通过正则表达式⾃定义分隔符默认是\W+,即⾮字词的符号作为分隔符ES默认对中⽂分词是⼀个⼀个字来解析,这种情况会导致解析过于复杂,效率低下,所以⽬前有⼏个开源的中⽂分词器,来专门解决中⽂分词,其中常⽤的叫IK中⽂分词难点中⽂分词指的是将⼀个汉字序列切分为⼀个⼀个的单独的词。
在英⽂中,单词之间以空格作为⾃然分界词,汉语中词没有⼀个形式上的分界符上下⽂不同,分词结果迥异,⽐如交叉歧义问题常见分词系统:实现中英⽂单词的切分,可⾃定义词库,⽀持热更新分词词典:⽀持分词和词性标注,⽀持繁体分词,⾃定义词典,并⾏分词等:由⼀系列模型与算法组成的Java⼯具包,⽬标是普及⾃然语⾔处理在⽣产环境中的应⽤:中⽂分词和词性标注安装配置ik中⽂分词插件# 在Elasticsearch安装⽬录下执⾏命令,然后重启esbin/elasticsearch-plugin install https:///medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip # 如果由于⽹络慢,安装失败,可以先下载好zip压缩包,将下⾯命令改为实际的路径,执⾏,然后重启esbin/elasticsearch-plugin install file:///path/to/elasticsearch-analysis-ik-6.3.0.zipik两种分词模式ik_max_word 和 ik_smart 什么区别?ik_max_word: 会将⽂本做最细粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,中华⼈民,中华,华⼈,⼈民共和国,⼈民,⼈,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,国歌”。
elasticsearch英文分词

一、概述Elasticsearch是一个开源的分布式搜索引擎,其作为一个基于Lucene的搜索引擎,在处理中文搜索时面临很多挑战。
其中一个重要的挑战就是中文分词。
中文分词是将中文文本按照语义进行切分的过程,而在Elasticsearch中,英文分词是先决条件。
在本文中,我们将深入探讨Elasticsearch中的英文分词器。
二、英文分词器概述1. 什么是分词器?在Elasticsearch中,分词器(Tokenizer)是指将文本按照一定规则切分成一个个有意义的词条(Token)的工具。
而在英文中,分词通常是按照空格、标点符号等进行切分。
2. Elasticsearch中的英文分词器Elasticsearch中内置了多种用于英文分词的分词器,常见的包括standard、simple、whitespace等。
每个分词器都有不同的分词规则和性能特点,可以根据需求选择合适的分词器进行配置。
三、常见的英文分词器1. Standard分词器Standard分词器是Elasticsearch中默认的英文分词器,其基于Unicode文本分割算法进行分词,能够处理绝大部分英文文本。
然而,在处理专有名词、缩写词等方面可能存在一定的局限性。
2. Simple分词器Simple分词器是一种基本的英文分词器,它仅按照非字母字符进行切分。
由于其简单性,适用于一些特殊场景下的文本处理。
3. Whitespace分词器Whitespace分词器是根据空格进行切分的分词器,适用于处理英文文本中的词语。
然而,在现实场景中,往往需要更为复杂的分词规则来处理文本。
四、自定义英文分词器除了内置的英文分词器外,Elasticsearch还支持自定义分词器。
用户可以根据实际需求,自定义分词规则、添加停用词等,以适配特定的文本处理场景。
1. 自定义分词规则通过配置自定义的分词规则,用户可以根据具体的需求,实现更为精确的文本处理。
针对特定行业的术语、品牌名称等进行定制化分词处理。
es 分词器 分词规则

es 分词器分词规则
《es 分词器分词规则》
在使用Elasticsearch(以下简称es)进行搜索时,分词器起着非常重要的作用。
分词器的作用是将文本进行分词处理,将文本中的词语分割成一个个可搜索的词项,以便于搜索引擎的索引和检索。
es提供了多种分词器供用户选择,如标准分词器、简单分词器、语言分析器等。
每种分词器都有其自己的分词规则。
标准分词器是最常用的分词器之一,其分词规则是以空格和标点符号为分隔符,将文本分割成一个个词汇。
此外,标准分词器还会将词汇转化为小写形式,这样可以忽略大小写的差异而进行搜索。
简单分词器则不对词汇进行小写处理,只是以空格和标点符号为分隔符进行分词。
除了内置的分词器,es还支持自定义分词器,用户可以根据自己的需求定义分词规则。
比如利用词干提取器来处理单词的词干,去掉词缀后将单词归一化,以便于搜索时准确匹配词项。
又如可以通过停用词过滤器来排除一些常用词汇,以减小索引的大小并提高搜索效率。
分词器的选择和分词规则的定义对搜索的效果有着直接的影响。
合适的分词器和分词规则能够提高文本的索引质量,提高搜索结果的相关性。
因此,在使用es进行搜索时,需要根据具体的情况选择合适的分词器,并且对分词规则进行灵活的定义和调整,以取得更好的搜索效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
es中英文分词
Elasticsearch(简称为es)是一种开源分布式搜索引擎,广泛用于各种应用场景中,如全文搜索、日志分析、实时推荐等。
在多语言环境下,es对中英文的分词处理尤为重要。
本文将介绍es中英文分词的原理和实现方式。
一、中文分词
中文文本由一系列汉字组成,而汉字与字之间没有明确的分隔符。
因此,中文分词就是将连续的汉字切分成有意义的词语的过程。
es中的中文分词器使用了基于词典匹配和规则引擎的方式进行分词。
1. 词典匹配
基于词典匹配的中文分词器会将待分析的文本与一个中文词典进行匹配。
词典中包含了中文的常用词汇。
当待分析的文本与词典中的词汇相匹配时,就将其作为一个词语进行标记。
这种方法简单高效,适用于大部分中文分词场景。
2. 规则引擎
规则引擎是一种基于规则的匹配引擎,它可以根据事先定义好的规则来对文本进行处理。
es中的规则引擎分词器可以根据指定的规则对中文文本进行分词操作。
这种方式的优点是可以根据具体的分词需求编写灵活的规则,适应不同语料库的分词要求。
二、英文分词
英文文本中的词语之间通常以空格或标点符号作为分隔符。
因此,英文分词的目标是将文本按照空格或标点符号进行分隔。
es中的英文分词器使用了基于空格和标点符号的切分方式。
它会将空格或标点符号之间的文本作为一个词语进行标记。
如果文本中包含连字符或点号等特殊符号,分词器会将其作为一个整体进行标记。
三、多语言分词
es还支持多语言环境下的分词处理。
对于既包含中文又包含英文的文本,es可以同时使用中文分词器和英文分词器进行处理。
这样可以将中文和英文的词语分开,并分别进行索引,提高搜索的准确性和效率。
四、自定义分词器
除了内置的中文分词器和英文分词器,es还提供了自定义分词器的功能。
用户可以根据自己的需求,编写自己的分词规则或使用第三方分词工具,然后将其配置到es中进行使用。
在es中,可以通过设置分词器的类型、配置分词规则和添加自定义词典等方式来实现自定义分词器。
这样可以更好地满足具体业务场景下的分词需求。
总结:
es中的中英文分词功能在全文搜索、日志分析等应用中起着重要的作用。
中文分词使用了词典匹配和规则引擎两种方式,英文分词则基
于空格和标点符号进行切分。
同时,es还支持多语言环境下的分词处理,并提供了自定义分词器的功能,以满足不同业务场景下的需求。