es中英文分词
ES系列十一、ES的index、store、_source、copy_to和all的区别

ES系列⼗⼀、ES的index、store、_source、copy_to和all的区别1.基本概念1.1._source存储的原始数据。
_source中的内容就是搜索api返回的内容,如:{"query":{"term":{"title":"test"}}}结果:{"took": 2,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},"hits": {"total": 1,"max_score": 0.2876821,"hits": [{"_index": "book3","_type": "english","_id": "3nuFZ2UBYLvVFwGWZHcJ","_score": 0.2876821,"_source": {"title": "test!"}}]}}默认情况下,Elasticsearch⾥⾯有2份内容,⼀份是原始⽂档,也就是_source字段⾥的内容,我们在Elasticsearch中搜索⽂档,查看的⽂档内容就是_source中的内容。
另⼀份是倒排索引,倒排索引中的数据结构是倒排记录表,记录了词项和⽂档之间的对应关系。
1.2.index:索引index使⽤倒排索引存储的是,分析器分析完的词和⽂档的对应关系。
es中英文分词

es中英文分词Elasticsearch(简称为es)是一种开源分布式搜索引擎,广泛用于各种应用场景中,如全文搜索、日志分析、实时推荐等。
在多语言环境下,es对中英文的分词处理尤为重要。
本文将介绍es中英文分词的原理和实现方式。
一、中文分词中文文本由一系列汉字组成,而汉字与字之间没有明确的分隔符。
因此,中文分词就是将连续的汉字切分成有意义的词语的过程。
es中的中文分词器使用了基于词典匹配和规则引擎的方式进行分词。
1. 词典匹配基于词典匹配的中文分词器会将待分析的文本与一个中文词典进行匹配。
词典中包含了中文的常用词汇。
当待分析的文本与词典中的词汇相匹配时,就将其作为一个词语进行标记。
这种方法简单高效,适用于大部分中文分词场景。
2. 规则引擎规则引擎是一种基于规则的匹配引擎,它可以根据事先定义好的规则来对文本进行处理。
es中的规则引擎分词器可以根据指定的规则对中文文本进行分词操作。
这种方式的优点是可以根据具体的分词需求编写灵活的规则,适应不同语料库的分词要求。
二、英文分词英文文本中的词语之间通常以空格或标点符号作为分隔符。
因此,英文分词的目标是将文本按照空格或标点符号进行分隔。
es中的英文分词器使用了基于空格和标点符号的切分方式。
它会将空格或标点符号之间的文本作为一个词语进行标记。
如果文本中包含连字符或点号等特殊符号,分词器会将其作为一个整体进行标记。
三、多语言分词es还支持多语言环境下的分词处理。
对于既包含中文又包含英文的文本,es可以同时使用中文分词器和英文分词器进行处理。
这样可以将中文和英文的词语分开,并分别进行索引,提高搜索的准确性和效率。
四、自定义分词器除了内置的中文分词器和英文分词器,es还提供了自定义分词器的功能。
用户可以根据自己的需求,编写自己的分词规则或使用第三方分词工具,然后将其配置到es中进行使用。
在es中,可以通过设置分词器的类型、配置分词规则和添加自定义词典等方式来实现自定义分词器。
ES004-Elasticsearch高级查询及分词器
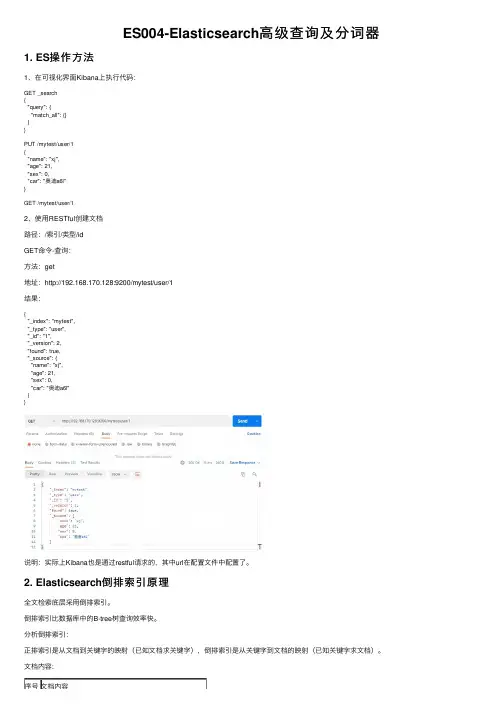
ES004-Elasticsearch⾼级查询及分词器1. ES操作⽅法1、在可视化界⾯Kibana上执⾏代码:GET _search{"query": {"match_all": {}}}PUT /mytest/user/1{"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}GET /mytest/user/12、使⽤RESTful创建⽂档路径:/索引/类型/idGET命令-查询:⽅法:get地址:http://192.168.170.128:9200/mytest/user/1结果:{"_index": "mytest","_type": "user","_id": "1","_version": 2,"found": true,"_source": {"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}}说明:实际上Kibana也是通过restful请求的,其中url在配置⽂件中配置了。
2. Elasticsearch倒排索引原理全⽂检索底层采⽤倒排索引。
倒排索引⽐数据库中的B-tree树查询效率快。
分析倒排索引:正排索引是从⽂档到关键字的映射(已知⽂档求关键字),倒排索引是从关键字到⽂档的映射(已知关键字求⽂档)。
⽂档内容:序号⽂档内容1⼩俊是⼀家科技公司创始⼈,开的汽车是奥迪a8l,加速爽。
Es学习第五课,分词器介绍和中文分词器配置

Es学习第五课,分词器介绍和中⽂分词器配置上课我们介绍了倒排索引,在⾥⾯提到了分词的概念,分词器就是⽤来分词的。
分词器是ES中专门处理分词的组件,英⽂为Analyzer,定义为:从⼀串⽂本中切分出⼀个⼀个的词条,并对每个词条进⾏标准化。
它由三部分组成,Character Filters:分词之前进⾏预处理,⽐如去除html标签Tokenizer:将原始⽂本按照⼀定规则切分为单词Token Filters:针对Tokenizer处理的单词进⾏再加⼯,⽐如转⼩写、删除或增新等处理,也就是标准化预定义的分词器ES⾃带的分词器有如下:Standard Analyzer默认分词器按词切分,⽀持多语⾔⼩写处理⽀持中⽂采⽤的⽅法为单字切分Simple Analyzer按照⾮字母切分⼩写处理Whitespace Analyzer空⽩字符作为分隔符Stop Analyzer相⽐Simple Analyzer多了去除请⽤词处理停⽤词指语⽓助词等修饰性词语,如the, an, 的,这等Keyword Analyzer不分词,直接将输⼊作为⼀个单词输出Pattern Analyzer通过正则表达式⾃定义分隔符默认是\W+,即⾮字词的符号作为分隔符ES默认对中⽂分词是⼀个⼀个字来解析,这种情况会导致解析过于复杂,效率低下,所以⽬前有⼏个开源的中⽂分词器,来专门解决中⽂分词,其中常⽤的叫IK中⽂分词难点中⽂分词指的是将⼀个汉字序列切分为⼀个⼀个的单独的词。
在英⽂中,单词之间以空格作为⾃然分界词,汉语中词没有⼀个形式上的分界符上下⽂不同,分词结果迥异,⽐如交叉歧义问题常见分词系统:实现中英⽂单词的切分,可⾃定义词库,⽀持热更新分词词典:⽀持分词和词性标注,⽀持繁体分词,⾃定义词典,并⾏分词等:由⼀系列模型与算法组成的Java⼯具包,⽬标是普及⾃然语⾔处理在⽣产环境中的应⽤:中⽂分词和词性标注安装配置ik中⽂分词插件# 在Elasticsearch安装⽬录下执⾏命令,然后重启esbin/elasticsearch-plugin install https:///medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip # 如果由于⽹络慢,安装失败,可以先下载好zip压缩包,将下⾯命令改为实际的路径,执⾏,然后重启esbin/elasticsearch-plugin install file:///path/to/elasticsearch-analysis-ik-6.3.0.zipik两种分词模式ik_max_word 和 ik_smart 什么区别?ik_max_word: 会将⽂本做最细粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,中华⼈民,中华,华⼈,⼈民共和国,⼈民,⼈,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,国歌”。
elasticsearch英文分词

一、概述Elasticsearch是一个开源的分布式搜索引擎,其作为一个基于Lucene的搜索引擎,在处理中文搜索时面临很多挑战。
其中一个重要的挑战就是中文分词。
中文分词是将中文文本按照语义进行切分的过程,而在Elasticsearch中,英文分词是先决条件。
在本文中,我们将深入探讨Elasticsearch中的英文分词器。
二、英文分词器概述1. 什么是分词器?在Elasticsearch中,分词器(Tokenizer)是指将文本按照一定规则切分成一个个有意义的词条(Token)的工具。
而在英文中,分词通常是按照空格、标点符号等进行切分。
2. Elasticsearch中的英文分词器Elasticsearch中内置了多种用于英文分词的分词器,常见的包括standard、simple、whitespace等。
每个分词器都有不同的分词规则和性能特点,可以根据需求选择合适的分词器进行配置。
三、常见的英文分词器1. Standard分词器Standard分词器是Elasticsearch中默认的英文分词器,其基于Unicode文本分割算法进行分词,能够处理绝大部分英文文本。
然而,在处理专有名词、缩写词等方面可能存在一定的局限性。
2. Simple分词器Simple分词器是一种基本的英文分词器,它仅按照非字母字符进行切分。
由于其简单性,适用于一些特殊场景下的文本处理。
3. Whitespace分词器Whitespace分词器是根据空格进行切分的分词器,适用于处理英文文本中的词语。
然而,在现实场景中,往往需要更为复杂的分词规则来处理文本。
四、自定义英文分词器除了内置的英文分词器外,Elasticsearch还支持自定义分词器。
用户可以根据实际需求,自定义分词规则、添加停用词等,以适配特定的文本处理场景。
1. 自定义分词规则通过配置自定义的分词规则,用户可以根据具体的需求,实现更为精确的文本处理。
针对特定行业的术语、品牌名称等进行定制化分词处理。
es中英文分词

es中英文分词Elasticsearch(简称ES)是一个开源的分布式搜索引擎,拥有强大的全文检索功能。
在ES中,中文和英文的分词处理方式略有不同。
本文将介绍ES中文和英文分词的基本原理和常见的分词策略。
一、中文分词中文分词是将连续的汉字序列切分为一个个独立的词语,是中文文本处理的基本步骤。
ES中文分词默认采用的是基于词表的正向最大匹配算法。
1. 正向最大匹配(Forward Maximum Matching,FMM)正向最大匹配是一种简单而高效的分词方法。
它从文本的最左侧开始,找出匹配词典中最长的词,并将其切分出来。
然后从剩余部分继续匹配最长的词,直到整个文本被切分完毕。
2. 逆向最大匹配(Backward Maximum Matching,BMM)逆向最大匹配与正向最大匹配相反,它从文本的最右侧开始,按照相同的规则进行词语切分。
逆向最大匹配的优点是可以较好地处理人名、地名等固有名词。
3. 双向最大匹配(Bi-directional Maximum Matching,BIMM)双向最大匹配结合了正向最大匹配和逆向最大匹配的优点,它首先使用正向最大匹配和逆向最大匹配进行分词,然后将切分结果进行比对,选择合理的结果作为最终的分词结果。
二、英文分词相比于中文,英文的分词规则相对简单。
ES中的英文分词器使用的是标准分词器(Standard Analyzer),它基于空格和标点符号来进行英文单词的切分。
1. 标准分词器(Standard Analyzer)标准分词器将文本按空格和标点符号进行切分,将切分后的词语作为单词,并进行小写转换。
例如,"Elasticsearch is a distributed search engine."会被切分为"elasticsearch","is","a","distributed","search"和"engine"。
es修改拼音分词器源码实现汉字拼音简拼混合搜索时同音字不匹配
es修改拼⾳分词器源码实现汉字拼⾳简拼混合搜索时同⾳字不匹配[版权声明]:本⽂章由danvid发布于,如需转载或部分使⽤请注明出处 在业务中经常会⽤到拼⾳匹配查询,⼤家都会⽤到拼⾳分词器,但是拼⾳分词器匹配的时候有个问题,就是会出现同⾳字匹配,有时候这种情况是业务不希望出现的。
业务场景:我输⼊"纯⽣pi酒"进⾏搜索,⽂档中有以下数据:doc[1]:{"name":"纯⽣啤酒"}doc[2]:{"name":"春⽣啤酒"}doc[3]:{"name":"纯⽣劈酒"}以上业务点是我输⼊"纯⽣pi酒"理论上业务希望只返回doc[1]:{"name":"纯⽣啤酒"}和doc[3]:{"name":"纯⽣劈酒"}其他的不是我要的数据,因为从业务⾓度来看,我已经输⼊"纯⽣"了,理论上只需要返回有"纯⽣"的数据(当然也有很多情况,会希望把"春⽣"也返回来),正常使⽤拼⾳分词器,会把doc[2]也会返回,原因是拼⾳分词器会把doc[2]变成:{"tokens": [{"token": "c","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "chun","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "s","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "sheng","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "p","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "pi","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "j","start_offset": 3,"end_offset": 4,"type": "word","position": 3},{"token": "jiu","start_offset": 3,"end_offset": 4,"type": "word","position": 3}]}由于"纯⽣"和"春⽣"是同⾳字,分词结果doc[1]和doc[2]是⼀样的,所以把doc[2]匹配上就是理所当然了,那么如何解决? 其实我们的需求是就当输⼊搜索⽂本时(搜索⽂本中可能同时存在中⽂/拼⾳),搜索⽂本中有[中⽂] 则按[中⽂]匹配,有[拼⾳]则按[拼⾳]匹配即可,这样就屏蔽掉了输⼊中⽂时匹配到同⾳字的问题。
es elasticsearch 中文分词
es elasticsearch 中文分词摘要:1.Elasticsearch 简介2.中文分词的重要性3.Elasticsearch 中的中文分词器4.结语正文:一、Elasticsearch 简介Elasticsearch 是一款开源的分布式搜索引擎,它的核心是Lucene,提供了高度可扩展且实时的搜索功能。
Elasticsearch 广泛应用于大数据、日志分析、实时搜索等场景,为用户提供了快速、准确的数据检索服务。
二、中文分词的重要性中文分词是指将连续的文本切分成有意义的词汇序列,对于中文自然语言处理具有重要意义。
准确的分词能够帮助搜索引擎更精确地理解用户查询,从而返回更为相关的搜索结果。
对于Elasticsearch 而言,支持中文分词能够大大提高其在中文搜索场景下的应用价值。
三、Elasticsearch 中的中文分词器Elasticsearch 中提供了多种中文分词器,用户可以根据实际需求选择合适的分词器。
以下是一些常用的中文分词器:1.IK Analyzer:IK Analyzer 是一款高效、易用、精确的中文分词器。
它基于前缀词典实现高效的词图扫描,生成有向无环图(DAG),采用动态规划查找最大概率路径,实现分词。
IK Analyzer 同时支持中文繁简体自动转换,适用于多种应用场景。
2.SmartChineseAnalyzer:SmartChineseAnalyzer 是另一个常用的中文分词器。
它采用基于词频的隐马尔可夫模型(HMM)来实现分词,具有较好的准确性和速度。
SmartChineseAnalyzer 还支持自定义词典,以满足不同用户的需求。
3.CTP Chinese Segmenter:CTP Chinese Segmenter 是阿里巴巴开源的一款中文分词器,它采用基于词典的分词策略,支持多种分词模式。
CTP Chinese Segmenter 在保证分词效果的同时,具有较高的性能和扩展性。
ES-自然语言处理之中文分词器
ES-⾃然语⾔处理之中⽂分词器前⾔中⽂分词是中⽂⽂本处理的⼀个基础步骤,也是中⽂⼈机⾃然语⾔交互的基础模块。
不同于英⽂的是,中⽂句⼦中没有词的界限,因此在进⾏中⽂⾃然语⾔处理时,通常需要先进⾏分词,分词效果将直接影响词性、句法树等模块的效果。
当然分词只是⼀个⼯具,场景不同,要求也不同。
在⼈机⾃然语⾔交互中,成熟的中⽂分词算法能够达到更好的⾃然语⾔处理效果,帮助计算机理解复杂的中⽂语⾔。
根据中⽂分词实现的原理和特点,可以分为:基于词典分词算法基于理解的分词⽅法基于统计的机器学习算法基于词典分词算法基于词典分词算法,也称为字符串匹配分词算法。
该算法是按照⼀定的策略将待匹配的字符串和⼀个已经建⽴好的"充分⼤的"词典中的词进⾏匹配,若找到某个词条,则说明匹配成功,识别了该词。
常见的基于词典的分词算法为⼀下⼏种:正向最⼤匹配算法。
逆向最⼤匹配法。
最少切分法。
双向匹配分词法。
基于词典的分词算法是应⽤最⼴泛,分词速度最快的,很长⼀段时间内研究者在对对基于字符串匹配⽅法进⾏优化,⽐如最⼤长度设定,字符串存储和查找⽅法以及对于词表的组织结构,⽐如采⽤TRIE索引树,哈希索引等。
这类算法的优点:速度快,都是O(n)的时间复杂度,实现简单,效果尚可。
算法的缺点:对歧义和未登录的词处理不好。
基于理解的分词⽅法这种分词⽅法是通过让计算机模拟⼈对句⼦的理解,达到识别词的效果,其基本思想就是在分词的同时进⾏句法、语义分析,利⽤句法信息和语义信息来处理歧义现象,它通常包含三个部分:分词系统,句法语义⼦系统,总控部分,在总控部分的协调下,分词系统可以获得有关词,句⼦等的句法和语义信息来对分词歧义进⾏判断,它模拟来⼈对句⼦的理解过程,这种分词⽅法需要⼤量的语⾔知识和信息,由于汉语⾔知识的笼统、复杂性,难以将各种语⾔信息组成及其可以直接读取的形式,因此⽬前基于理解的分词系统还在试验阶段。
基于统计的机器学习算法这类⽬前常⽤的算法是HMM,CRF,SVM,深度学习等算法,⽐如stanford,Hanlp分词⼯具是基于CRF算法。
es英文分词
ES英文分词ES(Elasticsearch)是一个流行的分布式搜索和分析引擎,可以快速、准确地对大量文本进行搜索和分析。
在ES中,分词是一个关键的步骤,它将文本拆分成一个个有意义的词语,以便更好地进行搜索和分析。
本文将介绍ES英文分词的原理和常见的分词器。
正文1. ES英文分词的原理ES英文分词的原理是基于词典和规则的匹配。
首先,ES使用内置的英文词典,将文本按照空格、标点符号等进行分割,形成候选词语。
然后,根据一系列的规则,对候选词语进行进一步的细分,例如将复合词拆分成独立的单词。
最后,ES将分词结果返回给用户,用户可以根据需要进行搜索和分析。
2. 常见的ES英文分词器ES提供了多种英文分词器,可以根据不同的需求选择合适的分词器。
以下是几种常见的分词器:(1) Standard Analyzer:标准分词器是ES默认的英文分词器,它根据空格、标点符号等将文本分割成词语。
虽然简单,但在大多数情况下效果还是不错的。
(2) English Analyzer:英文分析器是基于Standard Analyzer 的改进版,它考虑到了英语的特殊性,可以更好地处理英文文本。
例如,它可以正确地将复数形式的单词转换为单数形式。
(3) Keyword Analyzer:关键词分析器是将整个文本作为一个词语进行处理,不进行分词。
适用于需要完整匹配的场景,例如搜索产品型号或者精确匹配的关键字。
(4) Custom Analyzer:自定义分析器是ES提供的一种灵活的分词器,可以根据自己的需求定义分词规则。
用户可以添加自己的词典、停用词等,以达到更准确的分词效果。
3. ES英文分词的应用ES英文分词在各种场景中都有广泛的应用。
例如,在电商网站中,可以使用ES英文分词对商品标题和描述进行分词,以便用户能够更快速地搜索到他们感兴趣的商品。
在新闻网站中,可以使用ES 英文分词对新闻标题和正文进行分词,以便用户能够更方便地找到相关的新闻。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
在Elasticsearch(简称ES)中,中英文分词是一个重要的功能,它可以帮助我们更准确地搜索和索引中英文文本。
下面是一些关于ES 中英文分词的基本知识和常用方法:1.内置分词器:Elasticsearch 内置了一些分词器,如Standard 分词器和
Simple 分词器,它们都可以处理英文文本的分词。
但对于中文文本,它们可能不太适用,因为它们会将整个中文词语作为一个词项。
2.中文分词器:为了处理中文文本,我们需要使用专门的中文分词器,如IK 分
词器、Jieba 分词器等。
这些分词器可以将中文文本分割成一个个有意义的词语,从而提高搜索的准确性。
3.安装插件:要在Elasticsearch 中使用中文分词器,通常需要安装相应的插件。
例如,对于IK 分词器,可以下载相应的插件包并安装到Elasticsearch 中。
4.配置分词器:安装插件后,需要在Elasticsearch 的配置文件中指定要使用的
分词器。
这通常涉及到在索引设置中定义分析器(analyzer)和分词器(tokenizer)。
5.测试分词效果:配置好分词器后,可以使用Elasticsearch 的分析API 来测
试分词效果。
这可以帮助我们了解分词器是如何处理中英文文本的,并根据需要进行调整。
6.优化分词策略:根据测试结果,我们可以调整分词策略以提高搜索效果。
例如,
可以自定义词典来处理一些特殊的词汇或术语,或者调整分词器的参数来改变分词的行为。
7.注意事项:在使用中英文分词时,需要注意一些细节。
例如,要避免过度分词
(将一个词分割成过多的词项)或分词不足(未能将长词或短语正确分割)。
此外,还需要考虑如何处理中英文混合文本以及如何处理标点符号等问题。