es中英文分词
es 分词检索高亮显示 剔除html java案例

对于这个主题,我们需要对es 分词检索高亮显示进行深入的讨论。
ES (Elasticsearch)是一个开源的分布式搜索引擎,提供了全文搜索功能,可以对大规模数据进行快速的检索和分析。
而分词检索高亮显示则是ES在搜索过程中非常重要的一个功能,它能够将搜索结果中的关键词进行高亮显示,方便用户快速找到所需信息。
接下来,我们将从以下几个方面进行讨论。
1. ES 分词ES在进行检索时,会对文档内容先进行分词处理,将文本分割成一个个的词语,这些词语就是ES进行搜索的基本单位。
ES内置了一些常用的分词器,比如standard、simple、whitespace等,用户也可以根据自己的需求自定义分词器。
分词的好坏直接影响到搜索的准确性,因此选择合适的分词器非常重要。
2. 检索ES的检索功能非常强大,可以通过各种查询方式来实现不同的检索需求,比如term查询、match查询、bool查询等。
在进行检索时,ES 会使用之前提到的分词器对搜索关键词进行分词,然后再在分词后的词语中进行匹配,找到符合条件的文档。
3. 高亮显示高亮显示是ES在搜索结果中非常常用的一个功能,在搜索结果中将匹配的关键词进行特殊标记,让用户一眼就能看出哪些部分是与搜索条件匹配的。
通过高亮显示,用户可以更直观地了解搜索结果与搜索条件的关联程度,提高了搜索的可用性。
4. 剔除html在实际应用中,文档内容通常是包含有HTML标签的,而在搜索结果中我们通常不希望看到HTML标签,因此需要将搜索结果中的HTML 标签进行剔除,只显示纯文本内容。
ES提供了一些过滤器可以用来实现这个功能,比如HTML strip字符过滤器。
5. Java案例我们将以一个Java案例来演示如何在Java程序中使用ES进行分词检索和高亮显示。
首先需要引入ES的Java客户端库,然后通过编写相应的代码来实现搜索功能,包括构造查询条件、实现分词和高亮显示等。
这个案例将帮助大家更好地理解ES分词检索高亮显示的具体实现方法。
es基于match_phrasefuzzy的模糊匹配原理及使用

es基于match_phrasefuzzy的模糊匹配原理及使⽤ 在业务中经常会遇到类似数据库的"like"的模糊匹配需求,⽽es基于分词的全⽂检索也是有类似的功能,这个就是短语匹配match_phrase,但往往业务需求都不是那么简单,他想要有like的功能,⼜要允许有⼀定的容错(就是我搜索"东⽅宾馆"时,"⼴州花园宾馆酒店"也要出来,这个就不是单纯的"like"),下⾯就是我需要解析的问题(在此吐槽⼀下业务就是这么变态。
) 描述⼀个问题时⾸先需要描述业务场景:假设es中有⼀索引字段name存储有以下⽂本信息:doc[1]:{"name":"⼴州东⽅宾馆酒店"}doc[2]:{"name":"⼴州花园宾馆酒店"}doc[3]:{"name":"东⽅公园宾馆"}需求要求在输⼊:"东⽅宾馆"的时候doc[1]排最前⾯doc[3]排第⼆doc[2]排第三,对于这个需求从简单的全⽂检索match来说,doc[3]:{"name":"东⽅公园宾馆"}应该是第⼀位(注意:为了简化原理分析,分词我们使⽤standard即按单个字分词) 业务分析:显然对于上⾯的业务场景如果单独使⽤match的话,显然是不合适,因为按照standard分词,doc[3]的词条长度要⽐doc[1]的词条长度短,⽽词频⼜是都出现了[东][⽅][宾][馆]4个词,使⽤match匹配的话就会吧doc[3]排到最前⾯,显然业务希望把输⼊的⽂字顺序匹配度最⾼的数据排前⾯,因为我确实要找的是"⼴州东⽅宾馆酒店"⽽不是"东⽅公园宾馆"你不能把doc[3]给我排前⾯,OK业务逻辑好像是对的那么怎么解决问题; 解决问题前介绍⼀哈match_phrase原理(match的原理我就不说了⾃⼰回去看⽂档),简单点说match_phrase就是⾼级"like"。
es中英文分词

es中英文分词Elasticsearch(简称为es)是一种开源分布式搜索引擎,广泛用于各种应用场景中,如全文搜索、日志分析、实时推荐等。
在多语言环境下,es对中英文的分词处理尤为重要。
本文将介绍es中英文分词的原理和实现方式。
一、中文分词中文文本由一系列汉字组成,而汉字与字之间没有明确的分隔符。
因此,中文分词就是将连续的汉字切分成有意义的词语的过程。
es中的中文分词器使用了基于词典匹配和规则引擎的方式进行分词。
1. 词典匹配基于词典匹配的中文分词器会将待分析的文本与一个中文词典进行匹配。
词典中包含了中文的常用词汇。
当待分析的文本与词典中的词汇相匹配时,就将其作为一个词语进行标记。
这种方法简单高效,适用于大部分中文分词场景。
2. 规则引擎规则引擎是一种基于规则的匹配引擎,它可以根据事先定义好的规则来对文本进行处理。
es中的规则引擎分词器可以根据指定的规则对中文文本进行分词操作。
这种方式的优点是可以根据具体的分词需求编写灵活的规则,适应不同语料库的分词要求。
二、英文分词英文文本中的词语之间通常以空格或标点符号作为分隔符。
因此,英文分词的目标是将文本按照空格或标点符号进行分隔。
es中的英文分词器使用了基于空格和标点符号的切分方式。
它会将空格或标点符号之间的文本作为一个词语进行标记。
如果文本中包含连字符或点号等特殊符号,分词器会将其作为一个整体进行标记。
三、多语言分词es还支持多语言环境下的分词处理。
对于既包含中文又包含英文的文本,es可以同时使用中文分词器和英文分词器进行处理。
这样可以将中文和英文的词语分开,并分别进行索引,提高搜索的准确性和效率。
四、自定义分词器除了内置的中文分词器和英文分词器,es还提供了自定义分词器的功能。
用户可以根据自己的需求,编写自己的分词规则或使用第三方分词工具,然后将其配置到es中进行使用。
在es中,可以通过设置分词器的类型、配置分词规则和添加自定义词典等方式来实现自定义分词器。
es中英文分词

在Elasticsearch(简称ES)中,中英文分词是一个重要的功能,它可以帮助我们更准确地搜索和索引中英文文本。
下面是一些关于ES 中英文分词的基本知识和常用方法:1.内置分词器:Elasticsearch 内置了一些分词器,如Standard 分词器和Simple 分词器,它们都可以处理英文文本的分词。
但对于中文文本,它们可能不太适用,因为它们会将整个中文词语作为一个词项。
2.中文分词器:为了处理中文文本,我们需要使用专门的中文分词器,如IK 分词器、Jieba 分词器等。
这些分词器可以将中文文本分割成一个个有意义的词语,从而提高搜索的准确性。
3.安装插件:要在Elasticsearch 中使用中文分词器,通常需要安装相应的插件。
例如,对于IK 分词器,可以下载相应的插件包并安装到Elasticsearch 中。
4.配置分词器:安装插件后,需要在Elasticsearch 的配置文件中指定要使用的分词器。
这通常涉及到在索引设置中定义分析器(analyzer)和分词器(tokenizer)。
5.测试分词效果:配置好分词器后,可以使用Elasticsearch 的分析API 来测试分词效果。
这可以帮助我们了解分词器是如何处理中英文文本的,并根据需要进行调整。
6.优化分词策略:根据测试结果,我们可以调整分词策略以提高搜索效果。
例如,可以自定义词典来处理一些特殊的词汇或术语,或者调整分词器的参数来改变分词的行为。
7.注意事项:在使用中英文分词时,需要注意一些细节。
例如,要避免过度分词(将一个词分割成过多的词项)或分词不足(未能将长词或短语正确分割)。
此外,还需要考虑如何处理中英文混合文本以及如何处理标点符号等问题。
ES004-Elasticsearch高级查询及分词器
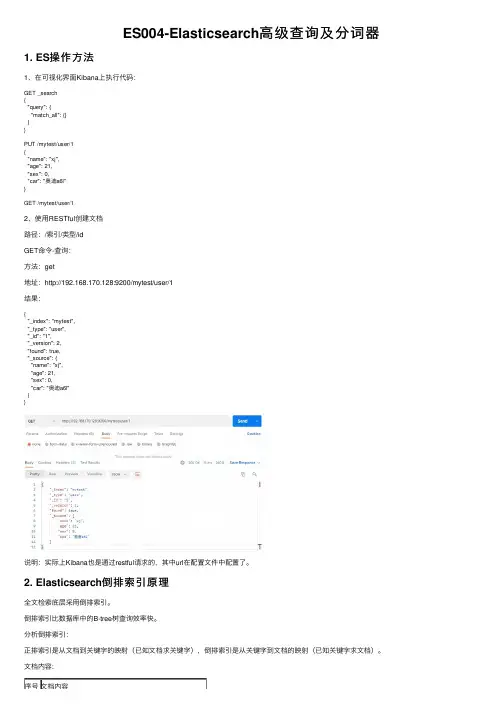
ES004-Elasticsearch⾼级查询及分词器1. ES操作⽅法1、在可视化界⾯Kibana上执⾏代码:GET _search{"query": {"match_all": {}}}PUT /mytest/user/1{"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}GET /mytest/user/12、使⽤RESTful创建⽂档路径:/索引/类型/idGET命令-查询:⽅法:get地址:http://192.168.170.128:9200/mytest/user/1结果:{"_index": "mytest","_type": "user","_id": "1","_version": 2,"found": true,"_source": {"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}}说明:实际上Kibana也是通过restful请求的,其中url在配置⽂件中配置了。
2. Elasticsearch倒排索引原理全⽂检索底层采⽤倒排索引。
倒排索引⽐数据库中的B-tree树查询效率快。
分析倒排索引:正排索引是从⽂档到关键字的映射(已知⽂档求关键字),倒排索引是从关键字到⽂档的映射(已知关键字求⽂档)。
⽂档内容:序号⽂档内容1⼩俊是⼀家科技公司创始⼈,开的汽车是奥迪a8l,加速爽。
[ES]elasticsearch章5 ES的分词(一)
![[ES]elasticsearch章5 ES的分词(一)](https://uimg.taocdn.com/495dbcc377a20029bd64783e0912a21614797fbc.webp)
[ES]elasticsearch章5 ES的分词(⼀)初次接触 Elasticsearch 的同学经常会遇到分词相关的难题,⽐如如下这些场景:1.为什么明明有包含搜索关键词的⽂档,但结果⾥⾯就没有相关⽂档呢?2.我存进去的⽂档到底被分成哪些词(term)了?3.我⾃定义分词规则,但感觉好⿇烦呢,⽆从下⼿1.从⼀个实例出发,如下创建⼀个⽂档:然后我们做⼀个查询,我们试图通过搜索 eat 这个关键词来搜索这个⽂档ES的返回结果为0。
这不太对啊,我们⽤最基本的字符串查找也应该能匹配到上⾯新建的⽂档才对啊!先来看看什么是分词。
2. 分词搜索引擎的核⼼是倒排索引,⽽倒排索引的基础就是分词。
所谓分词可以简单理解为将⼀个完整的句⼦切割为⼀个个单词的过程。
在 es 中单词对应英⽂为 term 。
我们简单看个例⼦:ES 的倒排索引即是根据分词后的单词创建,即我、爱、北京、天安门这4个单词。
这也意味着你在搜索的时候也只能搜索这4个单词才能命中该⽂档。
实际上 ES 的分词不仅仅发⽣在⽂档创建的时候,也发⽣在搜索的时候,如下图所⽰:读时分词发⽣在⽤户查询时,ES 会即时地对⽤户输⼊的关键词进⾏分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
⽽写时分词发⽣在⽂档写⼊时,ES 会对⽂档进⾏分词后,将结果存⼊倒排索引,该部分最终会以⽂件的形式存储于磁盘上,不会因查询结束或者 ES 重启⽽丢失。
ES 中处理分词的部分被称作分词器,英⽂是Analyzer,它决定了分词的规则。
ES ⾃带了很多默认的分词器,⽐如Standard、Keyword、Whitespace等等,默认是Standard。
当我们在读时或者写时分词时可以指定要使⽤的分词器。
3. 写时分词结果回到上⼿阶段,我们来看下写⼊的⽂档最终分词结果是什么。
通过如下 api 可以查看:其中test为索引名,_analyze为查看分词结果的endpoint,请求体中field为要查看的字段名,text为具体值。
Es学习第五课,分词器介绍和中文分词器配置
Es学习第五课,分词器介绍和中⽂分词器配置上课我们介绍了倒排索引,在⾥⾯提到了分词的概念,分词器就是⽤来分词的。
分词器是ES中专门处理分词的组件,英⽂为Analyzer,定义为:从⼀串⽂本中切分出⼀个⼀个的词条,并对每个词条进⾏标准化。
它由三部分组成,Character Filters:分词之前进⾏预处理,⽐如去除html标签Tokenizer:将原始⽂本按照⼀定规则切分为单词Token Filters:针对Tokenizer处理的单词进⾏再加⼯,⽐如转⼩写、删除或增新等处理,也就是标准化预定义的分词器ES⾃带的分词器有如下:Standard Analyzer默认分词器按词切分,⽀持多语⾔⼩写处理⽀持中⽂采⽤的⽅法为单字切分Simple Analyzer按照⾮字母切分⼩写处理Whitespace Analyzer空⽩字符作为分隔符Stop Analyzer相⽐Simple Analyzer多了去除请⽤词处理停⽤词指语⽓助词等修饰性词语,如the, an, 的,这等Keyword Analyzer不分词,直接将输⼊作为⼀个单词输出Pattern Analyzer通过正则表达式⾃定义分隔符默认是\W+,即⾮字词的符号作为分隔符ES默认对中⽂分词是⼀个⼀个字来解析,这种情况会导致解析过于复杂,效率低下,所以⽬前有⼏个开源的中⽂分词器,来专门解决中⽂分词,其中常⽤的叫IK中⽂分词难点中⽂分词指的是将⼀个汉字序列切分为⼀个⼀个的单独的词。
在英⽂中,单词之间以空格作为⾃然分界词,汉语中词没有⼀个形式上的分界符上下⽂不同,分词结果迥异,⽐如交叉歧义问题常见分词系统:实现中英⽂单词的切分,可⾃定义词库,⽀持热更新分词词典:⽀持分词和词性标注,⽀持繁体分词,⾃定义词典,并⾏分词等:由⼀系列模型与算法组成的Java⼯具包,⽬标是普及⾃然语⾔处理在⽣产环境中的应⽤:中⽂分词和词性标注安装配置ik中⽂分词插件# 在Elasticsearch安装⽬录下执⾏命令,然后重启esbin/elasticsearch-plugin install https:///medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip # 如果由于⽹络慢,安装失败,可以先下载好zip压缩包,将下⾯命令改为实际的路径,执⾏,然后重启esbin/elasticsearch-plugin install file:///path/to/elasticsearch-analysis-ik-6.3.0.zipik两种分词模式ik_max_word 和 ik_smart 什么区别?ik_max_word: 会将⽂本做最细粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,中华⼈民,中华,华⼈,⼈民共和国,⼈民,⼈,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;ik_smart: 会做最粗粒度的拆分,⽐如会将“中华⼈民共和国国歌”拆分为“中华⼈民共和国,国歌”。
动词第三人称单数变化规则如下
动词第三人称单数变化规则1) 一般情况下,动词后面直接加-s. 例如:works gets says reads2) 以ch,sh,s,x 或o 结尾的动词,在后面加-es。
例如:go-goes teach-,teache wash-washes brush-brushes ,catch-catches ,do-does ,fix -fixes3) 以辅音字母+ y结尾的动词,把y变为i 再加-es. 例如:study- studies try-tries carry-carries ,fly-flies cry-cries现在分词变化规则1.直接+ ing(例:sleep+ing sleeping)2.去e+ing(例:bite-e+ing biting)3重读闭音节,且末尾只有1个辅音字母,双写辅音字母+ing(例:sit+t+ing sitting)4.特殊变化:die-dying,lie-lying,tie-tying5.不规则变化现在进行时的基本用法:A 表示现在( 指说话人说话时) 正在发生的事情。
例:We are waiting for you.B. 习惯进行:表示长期的或重复性的动作,说话时动作未必正在进行。
例:Mr. Green is writing another novel.(说话时并未在写,只处于写作的状态。
)例:She is learning piano under Mr. Smith.C.已经确定或安排好的将来活动I'm leaving for a trek in Nepal next week.(已经安排了)we're flying to Paris tomorrow.(票已经拿到了)D.有些动词(状态动词不用于进行时态)1.表示知道或了解的动词:believe,doubt,forget,imagine,know, remember,realize,suppose,understand2.表示“看起来”“看上去"appear,resemble,seem3表示喜爱或不喜爱hate,like.lover.prefer4表示构成或来源的动词be come from.contain,include5表示感官的动词hear see smell sound taste6表示拥有的动词belong to.need.own .possess.want wish1、现在进行时的构成现在进行时由"be+v-ing"构成。
elasticsearch英文分词
一、概述Elasticsearch是一个开源的分布式搜索引擎,其作为一个基于Lucene的搜索引擎,在处理中文搜索时面临很多挑战。
其中一个重要的挑战就是中文分词。
中文分词是将中文文本按照语义进行切分的过程,而在Elasticsearch中,英文分词是先决条件。
在本文中,我们将深入探讨Elasticsearch中的英文分词器。
二、英文分词器概述1. 什么是分词器?在Elasticsearch中,分词器(Tokenizer)是指将文本按照一定规则切分成一个个有意义的词条(Token)的工具。
而在英文中,分词通常是按照空格、标点符号等进行切分。
2. Elasticsearch中的英文分词器Elasticsearch中内置了多种用于英文分词的分词器,常见的包括standard、simple、whitespace等。
每个分词器都有不同的分词规则和性能特点,可以根据需求选择合适的分词器进行配置。
三、常见的英文分词器1. Standard分词器Standard分词器是Elasticsearch中默认的英文分词器,其基于Unicode文本分割算法进行分词,能够处理绝大部分英文文本。
然而,在处理专有名词、缩写词等方面可能存在一定的局限性。
2. Simple分词器Simple分词器是一种基本的英文分词器,它仅按照非字母字符进行切分。
由于其简单性,适用于一些特殊场景下的文本处理。
3. Whitespace分词器Whitespace分词器是根据空格进行切分的分词器,适用于处理英文文本中的词语。
然而,在现实场景中,往往需要更为复杂的分词规则来处理文本。
四、自定义英文分词器除了内置的英文分词器外,Elasticsearch还支持自定义分词器。
用户可以根据实际需求,自定义分词规则、添加停用词等,以适配特定的文本处理场景。
1. 自定义分词规则通过配置自定义的分词规则,用户可以根据具体的需求,实现更为精确的文本处理。
针对特定行业的术语、品牌名称等进行定制化分词处理。
es修改拼音分词器源码实现汉字拼音简拼混合搜索时同音字不匹配
es修改拼⾳分词器源码实现汉字拼⾳简拼混合搜索时同⾳字不匹配[版权声明]:本⽂章由danvid发布于,如需转载或部分使⽤请注明出处 在业务中经常会⽤到拼⾳匹配查询,⼤家都会⽤到拼⾳分词器,但是拼⾳分词器匹配的时候有个问题,就是会出现同⾳字匹配,有时候这种情况是业务不希望出现的。
业务场景:我输⼊"纯⽣pi酒"进⾏搜索,⽂档中有以下数据:doc[1]:{"name":"纯⽣啤酒"}doc[2]:{"name":"春⽣啤酒"}doc[3]:{"name":"纯⽣劈酒"}以上业务点是我输⼊"纯⽣pi酒"理论上业务希望只返回doc[1]:{"name":"纯⽣啤酒"}和doc[3]:{"name":"纯⽣劈酒"}其他的不是我要的数据,因为从业务⾓度来看,我已经输⼊"纯⽣"了,理论上只需要返回有"纯⽣"的数据(当然也有很多情况,会希望把"春⽣"也返回来),正常使⽤拼⾳分词器,会把doc[2]也会返回,原因是拼⾳分词器会把doc[2]变成:{"tokens": [{"token": "c","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "chun","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "s","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "sheng","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "p","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "pi","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "j","start_offset": 3,"end_offset": 4,"type": "word","position": 3},{"token": "jiu","start_offset": 3,"end_offset": 4,"type": "word","position": 3}]}由于"纯⽣"和"春⽣"是同⾳字,分词结果doc[1]和doc[2]是⼀样的,所以把doc[2]匹配上就是理所当然了,那么如何解决? 其实我们的需求是就当输⼊搜索⽂本时(搜索⽂本中可能同时存在中⽂/拼⾳),搜索⽂本中有[中⽂] 则按[中⽂]匹配,有[拼⾳]则按[拼⾳]匹配即可,这样就屏蔽掉了输⼊中⽂时匹配到同⾳字的问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
es中英文分词
Elasticsearch(简称ES)是一个开源的分布式搜索引擎,拥有强大的全文检索功能。
在ES中,中文和英文的分词处理方式略有不同。
本文将介绍ES中文和英文分词的基本原理和常见的分词策略。
一、中文分词
中文分词是将连续的汉字序列切分为一个个独立的词语,是中文文本处理的基本步骤。
ES中文分词默认采用的是基于词表的正向最大匹配算法。
1. 正向最大匹配(Forward Maximum Matching,FMM)
正向最大匹配是一种简单而高效的分词方法。
它从文本的最左侧开始,找出匹配词典中最长的词,并将其切分出来。
然后从剩余部分继续匹配最长的词,直到整个文本被切分完毕。
2. 逆向最大匹配(Backward Maximum Matching,BMM)
逆向最大匹配与正向最大匹配相反,它从文本的最右侧开始,按照相同的规则进行词语切分。
逆向最大匹配的优点是可以较好地处理人名、地名等固有名词。
3. 双向最大匹配(Bi-directional Maximum Matching,BIMM)
双向最大匹配结合了正向最大匹配和逆向最大匹配的优点,它首先使用正向最大匹配和逆向最大匹配进行分词,然后将切分结果进行比对,选择合理的结果作为最终的分词结果。
二、英文分词
相比于中文,英文的分词规则相对简单。
ES中的英文分词器使用
的是标准分词器(Standard Analyzer),它基于空格和标点符号来进行
英文单词的切分。
1. 标准分词器(Standard Analyzer)
标准分词器将文本按空格和标点符号进行切分,将切分后的词语作
为单词,并进行小写转换。
例如,"Elasticsearch is a distributed search engine."会被切分为"elasticsearch","is","a","distributed","search"和"engine"。
2. 字母分词器(Letter Analyzer)
字母分词器将文本按照字母进行切分,忽略标点符号和空格。
例如,"Elasticsearch is a distributed search engine."会被切分为"Elasticsearch","is","a","distributed","search"和"engine"。
3. 单词分词器(Whitespace Analyzer)
单词分词器按照空格进行切分,不考虑标点符号和字母。
例如,"Elasticsearch is a distributed search engine."会被切分为"Elasticsearch","is","a","distributed","search"和"engine"。
以上是ES中英文分词的基本内容,ES还支持自定义分词器,使用
者可以根据实际需求选择合适的分词策略。
对于中文分词,可以结合
将词库和规则的方式进行扩展,提高准确性和效果。
对于英文分词,
也可以根据特定需要选择适合的分词策略。
ES作为一个强大的搜索引擎,分词是其中重要的一环。
合理地进行中英文分词,能够提高搜索的准确性和用户的搜索体验。
在实际应用中,根据不同的场景和需求选择合适的分词策略,将会对搜索结果的质量产生积极的影响。