sas 试题
sas测试题及答案

sas测试题及答案1. SAS中,如何将一个数据集的所有变量的值增加10?A. data dataset; set dataset; +10; run;B. data dataset; set dataset; +10; quit;C. data dataset; set dataset; +10; run;D. data dataset; set dataset; +10;答案:C2. 在SAS中,如何创建一个新的数据集,并将原数据集中的变量`Var1`和`Var2`复制到新数据集中?A. data new_dataset; set old_dataset; Var1 =old_dataset.Var1; Var2 = old_dataset.Var2; run;B. data new_dataset; set old_dataset; Var1 = Var1; Var2 = Var2; run;C. data new_dataset / old_dataset; set old_dataset; Var1 = old_dataset.Var1; Var2 = old_dataset.Var2; run;D. data new_dataset; set old_dataset; Var1 = Var1; Var2 = Var2; quit;答案:A3. SAS中,如何使用`proc print`步骤打印数据集的前10行?A. proc print data=dataset firstobs=10;B. proc print data=dataset firstobs=1 obs=10;C. proc print data=dataset firstobs=10;D. proc print data=dataset firstobs=1 obs=10;答案:B4. 在SAS中,如何使用`if-then`语句来创建一个新的变量`NewVar`,当`Var1`大于10时,`NewVar`的值为`Var1`的两倍,否则为0?A. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; else NewVar = 0; run;B. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; NewVar = 0; run;C. data dataset; set dataset; if Var1 > 10 NewVar = 2 *Var1; else NewVar = 0; run;D. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; else NewVar = 0; quit;答案:A5. SAS中,如何使用`proc means`步骤计算数据集中`Var1`的平均值?A. proc means data=dataset N mean of Var1;B. proc means data=dataset N mean Var1;C. proc means data=dataset N=mean Var1;D. proc means data=dataset N mean Var1;答案:D结束语:以上是SAS测试题及答案,希望能够帮助您更好地理解和掌握SAS编程的基础知识。
SAS统计软件知识要点与试题库

SAS 统计软件知识要点与试题库1. 试述SAS系统中PGM、EDITOR、OUTPUT、EXPLORER、RESULT和LOG窗口的功能。
2. 窗口切换(移至前台并击活)可用以下任一种做法实现:(1)点击窗口本身;(2)由菜单项“窗口(W)”可切换到已打开的窗口,或由查看(View)加入新窗口;(3) Ctrl + T ab 依次切换;(4) 用设置的热键; (5) 发布命令;(6) 点击窗口条中某一窗口图标.3. 发布命令有四种方式:在命令框直接键入命令;使用下拉菜单(弹出菜单);使用工具条;按功能键(KEYS命令显示功能键所表示的命令).4. SAS数据集可以读取的数据类型:数据行直接输入、流行的数据库、其它文件格式5. SAS数据集的描述部分(创建与修改日期,引擎,变量名,类型,长度,标题,格式等)6. 字符型变量的缺失值用空格符表示数值型变量的缺失值用句号“ . ”表示7. SAS逻辑库包括临时库、永久库两种,区别?8. ViewT able窗口提供两种打开数据的方式:Browse模式和Edit模式,区别?9. SAS数据集的变量属性有6个,哪六个?(变量名及标签,类型,长度,输入输出格式).10. 在SAS系统中浏览和编辑SAS数据集一般必须先设定SAS逻辑库(文件库),然后将要浏览和编辑的数据集存放在已设定的SAS逻辑库(文件库)中.11. 多个SAS逻辑库可与同一个物理位置项连接;一个SAS逻辑库也可与多个物理位置相连接.12. 新建逻辑库(New Library)的方法:1. 按工具条上图标(New Library)可进入设定新的SAS逻辑库的N ew Library窗口;2. 资源管理器(浏览器)窗口击活时,在下拉菜单中选:文件(File) ⇒新建(New… )⇒逻辑库=>可进入设定新建逻辑库(New Library)窗口.3. 在“SAS 环境”(Environment)处击右键,在弹出的菜单中选新建(New …)=>逻辑库,也可进入新建逻辑库(New Library)窗口.13. 上机试题(1).用菜单方法建立新库(库标志名为dsta),此库包含本课程所使用的sas数据集; (2).用两种方法(菜单或命令)进入ViewT able窗口,并浏览数据集class;(3)先浏览class中SEX=…F‟的观测及AGE>=14的观测,然后浏览全部观测;(4)浏览数据集class的描述信息和数据内容;(5)浏览SAS永久库SASUSER的属性和内容,并浏览数据集AIR的描述信息和数据内容.14. 数据集名应由字母或下划线开始且不超过32个(V6为8) 个字节的字符、数字或下划线构成. 变量名,数组名,库名15. 上机(1). 用VT命令进入ViewT able窗口,直接输入数据并进行编辑修改后存为sas数据集; (2). 使用Import窗口菜单系统,将*.txt 转换为sas数据集;(3). 用数据步建立SAS数据集.16. SAS的Import/Export菜单界面提供一个使用菜单的图形界面:17. SAS语句书写的格式较为灵活:语句可以在某一行的任何位置开始和结束;词间可任意加入空格和换行;一个语句可以写成几行,只要语句中的单词不被断开就可以;多个语句可写在一行;SAS语句用大写字母、小写字母或两者混合书写均可以.18. 通常用DAT A步产生SAS数据集,而用PROC步对SAS数据集中的数据进行分析处理并输出结果. 一个SAS程序可由一个DAT A步或一个PROC步组成;或者由DAT A 步和PROC步两部分组成;也可由多个DAT A步和PROC步组成.19. SAS的字符型变量缺省的长度是8个字符,可以用LENGTH语句直接指定变量长度。
sas期末考试试题

sas期末考试试题SAS期末考试试题一、选择题(每题2分,共20分)1. 在SAS中,以下哪个命令用于创建数据集?A. PROC SORTB. DATASETSC. SETD. INPUT2. 下列哪个选项不是SAS数据集中的变量属性?A. 长度B. 格式C. 标签D. 颜色3. SAS中的PROC FREQ过程用于:A. 描述性统计分析B. 频率分布分析C. 回归分析D. 时间序列分析4. 以下哪个命令用于在SAS中生成随机数?A. RANDB. RANDOMC. RNDD. UNIVARIATE5. 在SAS中,如何使用PROC GPLOT创建图形?A. 使用PLOT语句B. 使用SGPLOT过程C. 使用GPLOT语句D. 使用GRAPH语句二、简答题(每题10分,共30分)1. 解释SAS中的宏语言及其用途。
2. 描述如何使用SAS进行数据清洗的基本步骤。
3. 简述SAS中PROC UNIVARIATE过程的功能和应用场景。
三、编程题(每题25分,共50分)1. 编写SAS程序,从一个名为“sales_data”的数据集中提取出所有销售额超过平均销售额的产品,并计算这些产品的总销售额。
```sasdata sales_data;set sales_data;if sales > mean(sales);run;proc means data=sales_data mean;var sales;output out=avg_sales mean=avg_sales;run;data top_sales;set sales_data;where sales > avg_sales.avg_sales;run;proc sql;select sum(sales) into: total_salesfrom top_sales;quit;```2. 编写SAS程序,使用PROC REG过程对一个名为“education_data”的数据集进行线性回归分析,预测学生的考试成绩(变量名为“score”)基于其学习时间(变量名为“study_hours”)。
SAS期末试题及答案解析

5月31日上机作业:《统计分析系统SAS》模拟练习,结果不用上传保险公司为了解车险投保人对保险公司工作的满意程度Y和投保人的年龄X1、事故的严重程度X2及投保人的焦虑程度X3之间的关系,随机调查了该保险公司的23位报险人,得到数据表如下。
将数据作变换:将X2与Y数据上加上你学号的后1位,如学号的最后一位数据为2,则第1位报险人的X2=51+2,Y=48+2,其余数据依此类推。
一、数据集的建立1. 简述建立数据集时,SAS逻辑库的作用2. 若在D盘根目录建立了一个名字为“AA”的逻辑库,,上述数据集名字为temp,在windows 环境下数据集全名为_ ,SAS环境下,数据集名字的完整表示为_ 。
二、基本统计分析1.INSIGHT中,得到变量X2的均值为_ ,标准差为_ ,变异系数为_ _,方差为为__ 2.变量Y的的均值为_ ,标准差为_ ,变异系数为_ _,方差为为_ _。
三、正态性检验对数据进行正态性检验,以0.1为显著性水平进行检验,得到的结果中,变量为正态分布,为非正态分布;变量Y的中位数为,数据中有25%的值小于。
四、相关分析1.变量X1和Y的相关系数为R= ,X2和Y的相关系数R=,X3和Y的相关系数R=,X2和X3的相关系数R= 。
2. 写出用相关系数说明问题时,要注意的几点,至少写出3点。
(答案供参考)答:1)相关系数很强并不表示变量间一定有因果关系,也可能是两个变量同时受第三个变量的影响而使他们有很强的相关;2)相关系数是说明线性联系程度的。
相关系数接近于0的变量间可能存在非线性联系(可能是曲线关系);3)有时个别极端数据可能影响相关系数;4)强相关并不表示一定存在因果关系;5)弱相关并不表示变量间不存在关系。
五、假设检验1.简述假设检验的基本思想。
在假设检验中,P值的含义是什么?(答案供参考)答:首先给定一个原假设H0,H0是关于总体参数的表述,与此同时存在一个与H0相对立的备择假设H1,H0与H1有且仅有一个成立;经过一次抽样,若发生了小概率事件(通常把概率小于0.05的事件称为小概率事件),可以依据“小概率事件在一次实验中几乎不可能发生”的理由,怀疑原假设不真,作出拒绝原假设H0,接受H1的决定;反之,若小概率事件没有发生,就没有理由拒绝H0,从而应作出拒绝H1的决定。
sas测试题

sas测试题SAS(Statistical Analysis System)是一种广泛使用的统计分析软件,它提供了一系列数据分析和统计建模的功能。
本篇文章将围绕SAS测试题展开,就以下几个方面进行介绍和讨论:SAS基础知识、SAS数据的处理、SAS的统计分析和SAS的数据可视化。
一、SAS基础知识在开始探讨SAS测试题之前,先来了解一些SAS的基础知识。
SAS软件由多个组件组成,包括数据步骤(Data Step)和过程步骤(Procedure Step)。
数据步骤用于读取、转换和处理数据,而过程步骤用于执行统计分析和生成报告。
SAS程序由一系列语句和过程组成,语句以分号结尾,每个过程由一个或多个语句组成。
在SAS语言中,使用“=”运算符进行赋值,使用“*”运算符表示乘法,使用“/”运算符表示除法。
此外,SAS还支持各种不同类型的数据,包括字符型、数字型、日期型等。
二、SAS数据的处理SAS具有强大的数据处理功能,可以读取和处理各种格式的数据。
在SAS中,可以使用DATA步骤来读取和处理数据集。
通过使用各种DATA步骤中的语句和函数,可以对数据集进行排序、过滤、拆分和合并等操作。
在SAS中,使用PROC步骤来执行各种统计分析。
通过PROC步骤,可以进行描述统计、频数分析、回归分析等常见的统计分析方法。
此外,SAS还提供了丰富的统计函数,如求和函数、平均值函数、方差函数等,方便用户进行数据分析和计算。
三、SAS的统计分析SAS是一款出色的统计分析软件,提供了多种统计方法和技术。
在SAS中,可以使用PROC步骤执行各种统计分析。
以下是SAS中常用的几种统计分析方法:1. 描述统计:通过使用PROC MEANS和PROC SUMMARY等过程,可以计算数据集的均值、中位数、标准差等统计指标,以便更好地理解数据的特征。
2. 频数分析:通过使用PROC FREQ过程,可以对数据集中的变量进行频数统计和交叉表分析,进一步挖掘变量之间的关系。
统计软件SAS试题及答案(新)

滨州医学院2010~2011学年第一学期《统计软件》试题(A卷)(考试时间:120分钟,满分:100分)用题班级:2008级统计学专业一、数据库整理:(1题共42分)做题要求:按照要求写出程序,书写要符合SAS程序的规则。
随机抽取8名医学生的基础课程成绩与医学专业课程成绩,其成绩数据如表:医学基础课医学专业课解剖组胚生化生理内科外科妇产儿科X1 X2 X3 X4 Y1 Y2 Y3 Y470 64 97 77 59 81 63 8177 53 72 62 76 82 77 7975 82 66 68 62 75 72 8274 84 84 58 78 79 59 8275 68 73 72 77 81 73 7674 70 94 79 66 93 64 8274 84 86 82 79 79 55 78 (1)用input和cards语句将以上数据建立一个永久性数据集a1,逻辑库名exam,存放路径为’ d:\sas\exam1’,数据库内包含8个变量,分别为8门功课成绩,变量名如表中所示;(8分)libname exam ' d:\sas\exam1';data exam.a1;input X1 X2 X3 X4 Y1 Y2 Y3 Y4 @@;cards;70 64 97 77 59 81 63 8177 53 72 62 76 82 77 7975 82 66 68 62 75 72 8274 84 84 58 78 79 59 8275 68 73 72 77 81 73 7674 70 94 79 66 93 64 8274 84 86 82 79 79 55 7868 83 79 66 80 67 66 78;run;(2)用set语句建立临时性数据集a2,且该数据集不包括外科成绩低于80分的学生成绩;(6分)data a2;set exam.a1;if y2>=80then output a2;run;(3)将(1)中建立的数据集拆分成医学基础课与医学专业课两个数据集,数据集名称分别为exam_base与exam_spe,并将妇产命名为gyn。
2022年SAS大赛初赛试题

2022年SAS大赛初赛试题Sa数据分析大赛试题注意:建立逻辑库tet保存所有原始数据集,每道题要将代码和运行结果保存在word文档中。
1、(20分)a600605所给数据中包含上证股票600605,1995-2001年的行情信息。
其数据信息如下所示。
[题目要求]1)使用Data步计来计算a600605这支股票在1995-1998年的市场收益,即该股票的月收益率(个股月收益率=[(本月收盘价-上月收盘价)/上月收盘价]某100%),过程中不要使用dif和lag函数。
其中date的格式设置为‘1995-01’的形式,并删除1995年1月的观测数据。
签改为“月收益率”2、(30分)数据集credit_old中存放的是用于构建客户信用模型的数据,其中Target为被解释变量,其他变量为解释变量。
由于字符变量不能用于后续的统计分析工作,因此需要将credit_model中的字符变量重编码为数值变量。
由于分析时并不关心每个水平的具体编码是什么,因此按照从1到K(K为该变量水平数)编码即可,比如Re变量一共用3个水平,分别是U、R、S,编码为1、2、3即可。
但是需要使用宏进行自动处理。
[题目要求]1)将TEST库下的credit_old数据集复制到work逻辑库下,并重命名为credit_new。
(5分)2)使用数据字典读取credit_new数据集下所有解释变量中的字符变量的个数和名称。
(10分)3)编写宏,为每一个字符变量重新编码,以“变量名_cd”的命名方式保存新的编码,并添加到原credit_new数据集的后面,效果如下:(15分)2)对四个变量,进行两两的列联表分析,生成的列联表保存,进行分卡方检验和其他分类数据相关系数的计算。
3)对于2中形成列联表,对于每个格子计算频数占总频数的比例,然后检验任意两个格子间的比例差异是否显著(两比例是否相等检验),z(p1p2)p1(1p1)p2(1p2)n1n2要求计算出检验的P值。
SAS全国大赛初赛试题
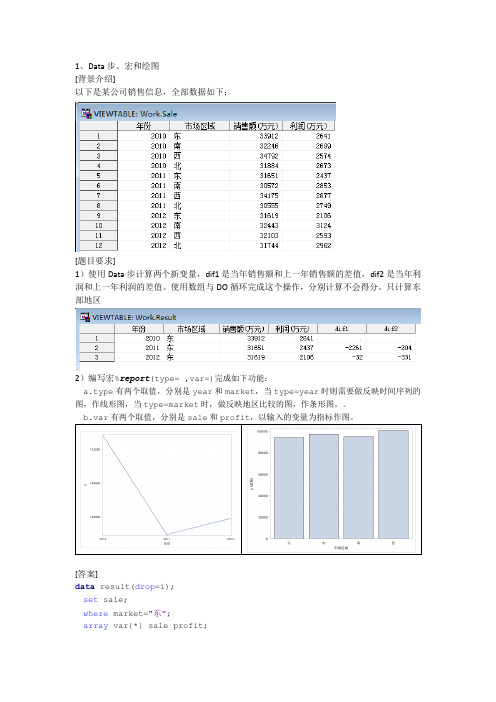
1、Data步、宏和绘图[背景介绍]以下是某公司销售信息,全部数据如下:[题目要求]1)使用Data步计算两个新变量,dif1是当年销售额和上一年销售额的差值,dif2是当年利润和上一年利润的差值。
使用数组与DO循环完成这个操作,分别计算不会得分。
只计算东部地区b.var有两个取值,分别是sale和profit,以输入的变量为指标作图。
[答案]data result(drop=i);set sale;where market="东";array var{*} sale profit;array dif{2};array lag_var{2} _temporary_ (.,.);do i=1to dim(var);dif{i}=var{i}-lag_var{i};lag_var{i}=var{i};end;run;%macro report(type=year,var=sale);%if &type=year %then%DO;proc sql;create table temp as select year,sum(&var) as yfrom salegroup by year order by year; quit;proc sgplot data=temp;series x=year y=y; run; quit;%END;%ELSE%DO;proc sql;create table temp as select market,sum(&var) as y from salegroup by market order by market; quit;proc sgplot data=temp;vbar market/response=y; run; quit;%END;%mend select_disp;%report(type=year,var=sale);[取分点]:共30分1、第一问15分:定义一般数组3分,定义数组并且赋初值+3,定义临时数组+3,会写DO循环+3,完成全部+3。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
表1 钢材消费量和国民收入的统计数据。
编号 国民收入 (亿万)
钢材消费 量(万 吨)
编号 国民收入 钢材消费 (亿万) 量(万 吨)
1 910
549
9
1555
1025
2 851
429
10 1917
1316
3 942
538
11 2051
1539
4 1097
698
12 _________,中位数为
____ ,极差为
____ ,该
数据的分布为
(正态/非正态)。
2. “钢材消费量”数据的变异系数为________, “钢材消费
量”数据中有75%的值小于
____ ,该数据的分布为
(正态/非正态)。
三、相关分析和回归分析
1.用SAS对数据集test中的变量进行相关分析,得到变量X与y的相
一、数据集的建立
1.若用NO代表编号,X代表国民收入,Y代表钢材消费量。在D盘根目录
下建立一个名为aa的逻辑库,在数据集aa中建立TEST数据集,将下面的
程序完善:
LIBNAME AA ‘
_____’;
DATA ___
____;
INPUT no x _____;
x=
____ _____;
CARDS;
1 910
549
2 851
5 1284 972
6 1502 988
9 1555 1025 10 1917 1316
13 2286 1785 14 2311 1762
;
_____;
429
3 942
7 1394 807
11 2051 1539
15 2003 1960
二、基本统计分析
1.
“国民收入”数据的均值为____________,标准差为
972
13 2286
1785
6 1502
988
14 2311
1762
7 1394
807
15 2003
1960
8 1303
738
16 2435
1902
将国民收入数据作如下的变换:国民收入+你学号的后1位,例如,你 学号的后1位为2,则编号为1的观测值:国民收入=910+2=912,其余编号的 观测值依此类推,钢材消耗量数据不变。
关系数为: ________ ,检验概率为:________ ,你的结论是:两变量
的相关关系为:
________。
2.设Y为因变量,X为自变量,作线性回归分析,回归方程中截距
为:
________,截距的检验概率为:________ ,因此,截距
项________(应该/不应该)保留。
3.最终得到的回归方程为:________________