SPSS软件进行主成分分析的应用例子
spss应用之主成分分析方法应用举例

物流工程 S11085240007主成分分析学习报告主成分分析(主分量分析)是一种实用的多元统计分析方法是一种化繁为简将指数尽可能压缩的降维技术,独特之处在于能够消除指标样本之间的相互关联,并在保持样本主要信息量前提下,提取少量具有代表性的主要指标。
同时,在分析过程中得到主要指标的合理权重,用主成分作为决策分析的综合指标值。
换言之:“主成分分析法实质上是用多维的思想,把多指标重新组合成一组相互独立的少数几个综合指标。
并且反映原指标的主要信息的多元统计分析方法。
”正是因为主成分分析方法具有上述特点,所以在多指标综合评价方面得到了广泛应用。
1基于主成分分析的我国省级财政规模综合评价王宝成(三峡大学经济与管理学院,湖北宜昌443002)1.1评价数据为了方便下文对我国省级政府财政规模进行综合评价.笔者按照设计的财政规模评价指标体系收集了2009年度全国31个省区财政规模测度指标的各项统计数据。
具体数据见表:2009年度全国31个省区财政规模测度数据。
如表所示。
我国省级政府财政规模的评价数据包含了财政自给率(X1)、财政收入占比(X2)、财政支出占比(X3)、人均财政(X4)、人均财政支出(X5)、单位面积财政收入(X6)和单位面积财政支出(X7)这7个评价指标的统计数据,所有原始数据均来源于《中国统计年鉴2009)。
1.2具体分析整个评价过程选取表2中的数据作为样本数据。
利用统计分析软件SPSS中的主成分分析方法综合评价我国级政府财政规模,具体评价过程分为以下两步展开:第一步.进行主成分分析的前提条件分析,旨在判断是否适合进行主成分分析;第二步,提取主成分,旨在对原始指标进行指标合并确定主成分及其所占权重。
计算各个样本的主成分得和综合得分。
具体分析过程和结果如下:利用统计分析软件SPSS对表2中的X1、X2、X3、X4、X5、X6和X7这七个原始变量作标准方差处理.然后按照特征根大于l的规则提取2个主成分,记为F1和F2,并采用方差最大法对提取到的2个主成分进行正交旋转。
SPSS软件进行主成分分析的应用例子

SPSS软件进行主成分分析的应用例子主成分分析是一种常用的多变量数据降维方法,它可以将众多相关性较强的变量通过线性组合转化为较少数量的无关变量,方便进行后续的统计分析和可视化。
下面是一个应用SPSS软件进行主成分分析的例子。
假设我们有一份健康调查问卷数据,其中包括了以下一些变量:1.年龄2.身高3.体重4.血压5.血糖6.血脂7.心率8.运动频率9.饮食习惯10.吸烟习惯11.饮酒习惯我们希望通过主成分分析来探索这些变量之间的关系,并找出影响健康的主要因素。
首先,我们需要使用SPSS软件导入数据并进行数据预处理,包括缺失值处理、异常值处理等。
接下来,我们需要进行主成分分析。
在SPSS中,可以通过如下步骤实现:1.打开SPSS软件并导入数据文件。
2.选择"分析"菜单中的"降维",然后选择"主成分"。
3.在弹出的对话框中,选择要进行主成分分析的变量。
在我们的例子中,我们选择所有的量表变量。
4.选择主成分提取的方法。
常用的方法有主成分提取和因子分析,我们选择"主成分"。
5.在主成分提取对话框中,可以选择要保留的主成分数量。
可以使用不同的标准来确定保留的主成分数量,如特征值大于1、方差解释度大于85%等。
根据实际需求,我们选择保留主成分的累积方差解释度达到60%。
6.点击"确定"进行主成分分析。
在主成分分析完成后,SPSS会生成主成分的系数矩阵、特征根表和解释根表等结果。
接着,我们需要对主成分进行解释和命名。
可以通过查看主成分的系数矩阵和特征根表来判断主成分代表的变量或潜在构念。
在我们的例子中,主成分的系数较高且与身高、体重、血压等变量相关,可以将其命名为"体型健康"。
最后,我们可以进行主成分得分的计算和解释。
在SPSS中,可以通过如下步骤实现:1.在主成分分析的结果中,选择"得分"选项卡。
用spss做主成分分析例题

用spss做主成分分析例题主成分分析(PrincipalComponentAnalysis,PCA)是一种常用的统计分析方法,它可以将任意数量的变量表示为少量的有意义的新变量,即投影,这样可以大大减少数据量,使研究变得更容易,并且得到更有用的结果。
本文将介绍使用SPSS软件进行主成分分析的一个实例,以便帮助读者更好地理解这种统计技术。
首先,确定数据。
本文将使用来自《美国统计报告》的一些数据,包括人口、收入、就业和犯罪数据。
这些数据将用于分析地区的社会发展情况。
接下来,打开SPSS,在“文件”菜单中选择“新建”,然后从硬盘中加载所需的数据集。
在“数据”菜单中选择“处理变量”,以定义被测变量和控制变量。
接着,在“统计”菜单中选择“主成分分析”,提供必要的参数,如要求的主成分的个数。
然后,选择“运行”,生成结果报表。
这样,就可以计算出数据中不同变量之间的相关性,从而推导出主成分,也就是这些变量之间具有一定关联性的变量组合。
主成分分析的每个主成分都可以用原始数据中的变量组合表示,减少了数据量。
最后,从结果报表中可以查看每个变量与主成分的关联性,以及这些变量组合的贡献率。
因此,可以得出结论,地区的社会发展状况可以归结为人口、收入、就业和犯罪等指标。
利用SPSS软件进行主成分分析,在计算机统计分析领域起着重要作用。
不仅可以把多个变量投影到一个变量上,还可以减少数据量,以便更好地探索各个变量之间的关系,最终得出结论并决定措施。
总之,本文详细讨论了使用SPSS软件进行主成分分析的实例,并且说明了它如何帮助分析变量之间的关系,以便研究论文的作者更好地解释研究数据。
spss主成分分析案例

spss主成分分析案例SPSS主成分分析案例。
主成分分析(Principal Component Analysis, PCA)是一种常用的数据降维方法,它可以将原始变量转换成一组新的互相无关的变量,这些新变量被称为主成分。
主成分分析可以帮助我们发现数据中的模式和结构,从而更好地理解数据的特性。
本文将以一个实际案例来介绍如何在SPSS软件中进行主成分分析,并解释如何解读分析结果。
案例背景:某公司想要了解员工的工作满意度,为了更全面地了解员工对工作的感受,公司设计了一份包含多个问题的调查问卷,涉及到工作内容、工作环境、薪酬福利等方面。
为了简化分析,公司希望利用主成分分析来提取出最能代表员工工作满意度的几个维度。
数据收集:公司对全体员工进行了调查,共有300份有效问卷。
每份问卷包含了20个问题,涉及到不同方面的工作满意度评价。
这些问题涵盖了工作内容、同事关系、上级领导、薪酬福利等多个方面。
数据分析:首先,我们需要将数据导入SPSS软件中,然后依次点击“分析”-“数据降维”-“主成分”命令。
在弹出的对话框中,我们选择需要进行主成分分析的变量,即员工对不同问题的评分。
在选择了变量后,我们可以点击“选项”按钮,对分析进行进一步设置,比如选择旋转方法、提取条件等。
在进行了上述设置后,我们点击“确定”按钮,SPSS将会为我们生成主成分分析的结果。
在结果中,我们可以看到提取的主成分个数、每个主成分的方差解释比例、成分矩阵等信息。
通过这些信息,我们可以判断提取的主成分是否符合要求,以及每个主成分的解释能力如何。
解读结果:在这个案例中,我们提取了3个主成分,这3个主成分分别解释了总方差的60%、25%和15%。
成分矩阵显示了每个问题对应的主成分载荷,通过分析载荷大小,我们可以判断每个主成分所代表的具体内容。
比如,第一个主成分可能代表工作内容满意度,第二个主成分可能代表同事关系满意度,第三个主成分可能代表薪酬福利满意度。
spss主成分分析案例

spss主成分分析案例SPSS主成分分析案例。
主成分分析(Principal Component Analysis, PCA)是一种多变量数据分析方法,它通过线性变换将原始变量转换为一组新的互相无关的变量,称为主成分。
主成分分析可以帮助我们发现数据中的模式和结构,减少变量的维度,提取出数据中的重要信息,从而更好地理解数据的特性和关系。
在本文中,我们将通过一个实际的案例来介绍SPSS软件中主成分分析的应用。
案例背景:某公司在进行市场调研时,收集了一批关于消费者偏好的数据,包括了消费者对不同产品的评价、购买意愿、消费习惯等多个变量。
现在,公司希望通过主成分分析来挖掘这些数据中的潜在结构和规律,以便更好地了解消费者的特点和行为。
数据准备:首先,我们需要将收集到的原始数据导入SPSS软件中。
在SPSS中,选择“文件”-“导入数据”-“从文本文件”命令,打开数据文件并按照向导的指示完成数据导入的操作。
导入数据后,我们可以在数据视图中看到各个变量的取值情况,并对数据进行初步的观察和描述性统计。
主成分分析:在SPSS中进行主成分分析非常简单。
选择“分析”-“降维”-“因子”,在弹出的对话框中选择需要进行主成分分析的变量,然后点击“提取”按钮,设置提取主成分的条件,比如特征值大于1或者累积方差贡献率达到80%以上。
接着点击“旋转”按钮,选择合适的旋转方法,比如方差最大旋转(Varimax)或极大似然旋转(Promax)。
最后点击“确定”按钮,SPSS会自动进行主成分分析,并输出结果。
结果解释:主成分分析的结果包括了特征值、方差贡献率、成分矩阵等多个部分。
我们可以根据特征值的大小来确定保留的主成分个数,一般来说,特征值大于1的主成分才具有实际意义。
方差贡献率则可以帮助我们理解每个主成分所解释的原始变量的方差比例,从而确定主成分的解释能力。
成分矩阵则可以帮助我们理解每个主成分与原始变量之间的关系,从而对主成分进行解释和标注。
SPSS进行主成分分析
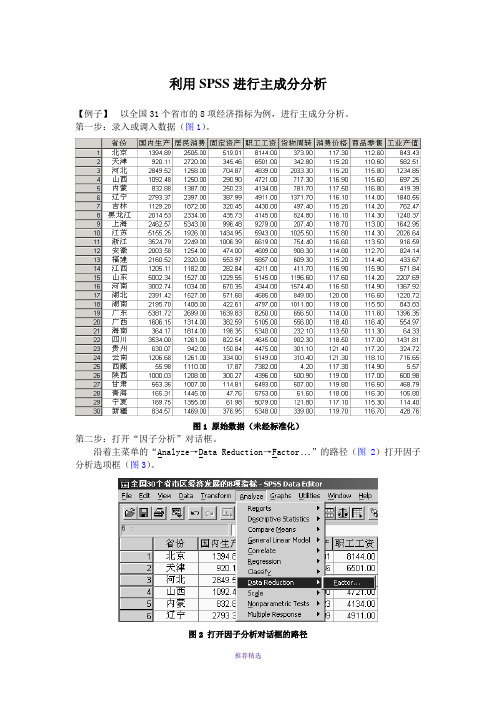
利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(Principal Components ),因此对此栏不作变动,就是认可了主成分分析方法。
SPSS进行主成分分析
欢呼词语的近义词有哪些欢呼词语的意思是什么呢?如何使用欢呼词语造句呢?关于欢呼词语的近义词有哪些呢?小编给大家收集了关于表达欢呼词语的解释呢,希望能帮助大家,欢迎大家学习参考!欢呼词语解释欢呼的近义词:欢庆、呐喊、呼喊、欢叫、欢乐、欢畅、喝彩基本信息拼音:huānhū释义:形容一种欢乐而振臂高呼的激情场面。
基本解释[hail;cheer;acclaim;applaud] 欢乐地喊叫他作为英雄而受到欢呼这场战争尚未正式结束,民众已在欢呼引证解释1. 欢乐地喊叫。
《东观汉记·王霸传》:“贼众欢呼,雨射营中。
” 唐元稹《辨日旁瑞气状》:“其日三将同升,万姓欢呼,四方来贺。
” 元萨都剌《将至太平驿》诗:“到驿欢呼如到家,明日舟行复如此。
” 明冯梦龙《东周列国志》第七十一回:“(齐)景公大悦,于是解衣卸冠,与梁邱据欢呼于丝竹之间,鸡鸣而返。
”毛泽东《中国人民站起来了》:“我们的革命已经获得全世界广大人民的同情和欢呼,我们的朋友遍于全世界。
”2. 懽呼:欢乐地呼喊。
唐薛用弱《集异记·李钦瑶》:“举军懽呼,声振山谷。
” 明张居正《贺瑞雪表》五:“懽呼敢效乎虫鸣,踊跃岂殊於兽舞!” 康有为《将至桂林望诸石峰》诗:“昔游燕吴读园记,每见叠石辄懽呼。
”关于欢呼造句1, 在荣誉的桂冠下面,在欢呼声的背后,便是孤独,我们的孤独!2, 收到大学录取通知书,她立刻欢呼雀跃起来。
3, 首先是50米跑,运动员们都摩拳擦脚,准备一举夺下桂冠。
随着一声令下,运动员像脱了弦的箭似的飞了出去,同学们不断为自己的班级喝彩加油打气。
观众席上欢呼声拍掌声此起彼伏,久久不断。
4, 最后一个敌人在血泊里倒下,战争胜利了,满目疮痍的战场上响起了震耳欲聋的欢呼声,只是那命悬一线的惊心动魄始终萦绕在每个人的心头。
5, 每个人都有自己的梦,都有自己的偶像,都有自己的爱好,都有自己的个性……生命中有很多事情,可能没人在乎,但说不定会有谁为你而欢呼。
主成分分析在SPSS中的实现和案例
主成分分析在SPSS中的实现和案例
主成分分析(PCA)是一种常用的数据降维方法,可以将多个相关变量转化为少数几个无关的主成分。
在SPSS中实现PCA的步骤如下:
1. 打开SPSS软件,并打开需要进行PCA分析的数据集。
2. 选择“分析”菜单下的“降维”选项,再选择“因子”。
3. 在弹出的窗口中,选择需要进行PCA分析的变量,添加至“因子”列表中。
4. 点击“提取”按钮,选择提取主成分的方式,可以选择保留的主成分个数或者保留的方差比例。
5. 点击“确定”按钮,返回因子分析结果窗口,可以查看提取的主成分特征根、方差贡献率以及旋转后的载荷矩阵等信息。
下面介绍一个PCA的案例:假设研究人员要对顾客满意度进行研究,数据集包括顾客的年龄、性别、消费金额、服务态度、产品质量等变量。
为了降低变量维度,可以进行PCA分析。
在SPSS 中进行该分析的步骤如上述操作。
结果表明,经过PCA分析,可以选择保留3个主成分,解释总方差达到了80%以上。
第一主成分代表消费水平,第二主成分代表服务品质,第三主成分代表年龄和性别。
这说明顾客的满意度受到这3个方面的影响较大。
总之,主成分分析在SPSS中的实现方法简单易行,可以有效地解决多变量相关性较强的问题,为研究提供更加深入的解释和认识。
主成分分析法spss经典案例
主成分分析法spss经典案例主成分分析法(PrincipalComponentAnalysis,简称PCA)是为了降低多变量数据集中变量间的关联性而提出的一种统计分析方法。
它用来检查数据点之间是否存在强相关,并在不损失数据信息的基础上将原有的多个变量转化为更少的变量,以便于它们可以更好地表达任务的要求。
PCA的合并变量称为主成分,它们代表了原有变量的重要特征。
主成分分析法在SPSS中的应用SPSS是一种常用的统计分析软件,其中包括PCA分析工具。
为了使用SPSS进行PCA分析,用户首先必须收集数据并将其输入到SPSS 中。
接下来,用户需要使用SPSS的主成分分析工具来进行分析。
首先,用户可以通过选择分析中的“确定转换”选项来确定要建立的主成分的数量。
然后,“每个变量的可变性”和“变量的可变性之间的相关性”等参数将被显示在右侧的表中。
最后,用户可以通过点击“运行”按钮运行PCA分析,并在报告中查看结果。
主成分分析法的经典案例下面我们将讨论一个常见的PCA案例:研究早期教育对学生未来表现的影响。
在这个案例中,研究者需要分析多个变量,包括孩子的出生年龄、家庭经济情况、孩子看到的早期教育环境等,来评估早期教育对学生未来表现的影响。
由于其中有多个变量,因此使用PCA来帮助分析这些变量间的关联性,为获得更准确的分析结果提供帮助。
在使用PCA进行分析之前,首先需要从相关文献中获取研究变量的数据。
之后,将数据输入到SPSS中,并使用SPSS的PCA分析工具来检查变量之间的相关性。
在报告中,可以看到每个变量的可变性以及它们之间的相关性,最后可以得出结论,即早期教育对学生未来表现的影响等。
主成分分析法的优点PCA是一种有用的分析工具,能够从原有的多个变量中提取最重要的特征,从而减少变量之间的关联性。
PCA的另一个优点是,它可以将复杂的问题简化为较小数量的变量,从而便于进行分析,并且可以有效减少数据中的“噪声”。
此外,PCA还可以用来可视化数据,检测数据中的潜在模式,以及进行定量比较。
如何利用SPSS进行主成分分析
利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据⒋其它。
图8 主成分分析的结果第四步,结果解读。
在因子分析结果(Output )中,首先给出的Descriptive Statistics ,第一列Mean 对应的变量的算术平均值,计算公式为∑==ni ij j x n x 11第二列Std. Deviation 对应的是样本标准差,计算公式为2/112])(11[∑=--=ni j ij j x x n σ 第三列Analysis N 对应是样本数目。
这一组数据在分析过程中可作参考。
Descriptive Statistics1921.0931474.80603301745.933861.6419330511.5083402.88548305457.6331310.2180530666.1400459.9669930117.2867 2.025*******.9067 1.8980830862.9980584.5872630国内生产居民消费固定资产职工工资货物周转消费价格商品零售工业产值Mean Std. Deviation Analysis N接下来是Correlation Matrix(相关系数矩阵),一般而言,相关系数高的变量,大多会进入同一个主成分,但不尽然,除了相关系数外,决定变量在主成分中分布地位的因素还有数据的结构。
相关系数矩阵对主成分分析具有参考价值,毕竟主成分分析是从计算相关系数矩阵的特征根开始的。
相关系数阵下面的Determinant=1.133E-0.4是相关矩阵的行列式值,根据关系式0)det(=-R I λ可知,det(λI )=det(R ),从而Determinant=1.133E-0.4=λ1*λ2*λ3*λ4*λ5*λ6*λ7*λ8。
这一点在后面将会得到验证。
在Communalities(公因子方差)中,给出了因子载荷阵的初始公因子方差(Initial )和提取公因子方差(Extraction ),后面将会看到它们的含义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS软件进行主成分分析的应用例子2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下:第一,将EXCEL中的原始数据导入到SPSS软件中;【1】“分析”|“描述统计”|“描述”。
【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。
【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。
所的结论:标准化后的所有指标数据。
注意:SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。
factor过程对数据进行因子分析(指标之间的相关性判定略)。
【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框;【3】设置“抽取”,勾选“碎石图”复选框;【4】设置“旋转”,勾选“最大方差法”复选框;【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框;【6】查看分析结果。
所做工作:a.查看KMO和Bartlett 的检验KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;Bartlett 球度度检验的Sig值越小于显著水平0.05,越说明变量之间存在相关关系。
所的结论:符合因子分析的条件,可以进行因子分析,并进一步完成主成分分析。
注意:1.KMO(Kaiser-Meyer-Olkin)KMO统计量是取值在0和1之间。
当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。
Kaiser给出了常用的kmo度量标准: 0.9以上表示非常适合;0.8表示适合;0.7表示一般;0.6表示不太适合;0.5以下表示极不适合。
2.Bartlett 球度检验:巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析。
Bartlett 球度检验的原假设为相关系数矩阵为单位矩阵,Sig值为0.001小于显著水平0.05,因此拒绝原假设,说明变量之间存在相关关系,适合做因子分析。
所做工作:b. 全部解释方差或者解释的总方差(Total Variance Explained)初始特征根(Initial Eigenvalues)大于1,并且累计百分比达到80%~85%以上。
查看相关系数矩阵的特征根及方差贡献率见表3,由于前2个主成分贡献率≥85%、结合表4中变量不出现丢失,所以提取的主成分个数m=2。
所的结论:初始特征根:λ1=1.897 λ2=1.550主成分贡献率:r1=0.47429 r2=0.38740注意:主成分的数目可以根据相关系数矩阵的特征根来判定,如前所说,相关系数矩阵的特征根刚好等于主成分的方差,而方差是变量数据蕴涵信息的重要判据之一。
根据λ值决定主成分数目的准则有三:1.只取λ>1的特征根对应的主成分从Total Variance Explained表中可见,第一、第二和第三个主成分对应的λ值都大于1,这意味着这三个主成分得分的方差都大于1。
本例正是根据这条准则提取主成分的。
2.累计百分比达到80%~85%以上的λ值对应的主成分在Total Variance Explained表可以看出,前三个主成分对应的λ值累计百分比达到89.584%,这暗示只要选取三个主成分,信息量就够了。
3.根据特征根变化的突变点决定主成分的数量从特征根分布的折线图(Scree Plot)上可以看到,第4个λ值是一个明显的折点,这暗示选取的主成分数目应有p≤4。
那么,究竟是3个还是4个呢?根据前面两条准则,选3个大致合适(但小有问题)。
【1】将初始因子载荷矩阵中的两列数据输入( 可用复制粘贴的方法) 到数F1=V1/SQR(λ1)标变量”文本框中输入“F1”,然后在数字表达式中输入“V1/SQR(λ1)”[注:λ1=1.897], 即可得到特征向量F1;【3】然后利用“转换”|“计算变量”, 打开“计算变量”对话框,在“目标变量”文本框中输入“F2”,然后在数字表达式中输入“V2/SQR(λ2)”[注:λ1=1.550], 即可得到特征向量F2;【4】最后得到特征向量矩阵(主成分表达式的系数)。
所做工作:a. 成分矩阵或者初始因子载荷矩阵(Component Matrix)初始因子载荷矩阵见上图,通过初始因子载荷矩阵还不能得出主成分的表达式,还需要把初始因子载荷矩阵中的每列的系数(主成分的载荷)除以其相应主成分的特征根的平方根后才能得到主成分系数向量(主成分的得出系数);所的结论:1.用于计算主成分表达式系数的初始因子载荷矩阵中每个指标的载荷。
2.计算后,得到的主成分表达式的系数矩阵。
注意:1.主成分表达式的系数提取出来的全部主成分可以基本反映全部指标的信息,但这些新变量(主成分)的表达却不能从输出窗口中直接得到,即:主成分中每个指标所对应的系数不是初始因子载荷矩阵中的对应指标的载荷,因为“Component Matrix”是指初始因子载荷矩阵, 每一个载荷量表示主成分与对应变量的相关系数。
2.主成分表达式系数的计算方法初始因子载荷矩阵或主成分载荷矩阵(Component Matrix)中的数据除以主成分相对应的特征根(或特征值)开平方根便得到两个主成分中每个指标所对应的系数。
F1=V1/SQR(λ1)3.主成分的指标划分与命名初始因子载荷矩阵或主成分载荷矩阵(Component Matrix)中每列表示相应主成分与对应变量的相关系数,每个主成分所反映的原始指标各有不同,为进一步明确每个主成分侧重反应的具体原始指标,需要对原始指标在每个主成分上的载荷进行比较,其中载荷越大,其对应的主成分反映该原始指标的信息量越大,反之亦然;如果某一原始指标在几个主成分的载荷绝对值不相上下,归类比较含混,导致主成分的原始指标划分不清。
说明有必要作进一步的因子分析。
从Component Matrix即主成分载荷表中可以看出,哪一原始指标在哪一主成分上载荷绝对值较大,亦即与该主成分的相关系数较高【注:相关分为正负相关】。
【1】将得到的特征向量与标准化后的数据.......相乘, 然后就可以得出主成分函数的表达式;Z1= F11*zX1+ F12*zX2+ F13*zX3+ F14*zX4Z2= F21*zX1+ F22*zX2+ F23*zX3+ F24*zX4(其中,zX i为标准化后的数据)【2】然后利用“转换”|“计算变量”, 打开“计算变量”对话框,在“目标变量”文本框中输入“Z1”,然后在数字表达式中输入“0.531*Z (销售净利率)+0.594*Z (资产净利率)+0.261*Z (净资产收益率)+0.546*Z (销售毛利率)”[注:F1=0.531,0.594,0.261,0.546], 即可得到特征向量Z1;【3】同理[注:F2=-0.412,0.404,0.720,-0.383], 可得到特征向量Z2;【4】求出16家上市公司的主成分值。
所做工作:a. 对原始数据标准化后的数据标准化后的数据;所的结论:1.用于计算主成分表达式系数的初始因子载荷矩阵中每个指标的载荷。
注意:1.特征向量矩阵载荷的用运Z1= F11*zX1+ F12*zX2+ F13*zX3+ F14*zX4Z2= F21*zX1+ F22*zX2+ F23*zX3+ F24*zX4(其中,zX i为标准化后的数据)【1】将得到的特征向量与标准化后的数据相乘, 然后就可以得出主成分表Z=r1*Z1+r2*Z2标变量”文本框中输入“Z”,然后在数字表达式中输入“r1*Z1+r2*Z2”[注:r1=0.47429, r2=0.3874], 即可得到综合主成分;【3】综合主成分(赢利能力)值。
所做工作:a. 对原始数据标准化后的数据标准化后的数据;所的结论:1.用于计算主成分表达式系数的初始因子载荷矩阵中每个指标的载荷。
注意:1.综合主成分得分的计算方法Z=r1*Z1+r2*Z2(Z:综合主成分得分;r i:主成分贡献率;Z i:主成分i得分)公司Z1Z2Z烟台万华五粮液雅戈尔红星发展贵州茅台青岛海尔太太药业伊利股份浙江阳光歌华有线方正科技用友软件红河光明中铁二局福建南纸湖北宜化1.211.161.031.201.410.211.31-0.83-0.561.23-1.720.620.09-2.00-2.07-2.291.461.461.410.53-0.310.35-1.081.060.60-1.691.52-1.89-1.880.15-0.72-0.991.141.121.030.770.550.240.200.02-0.03-0.07-0.23-0.44-0.69-0.89-1.26-1.47。